|
Graphxʵ������
��Ҫ
ͼ�IJ��л�����һֱ��һ���dz����ŵĻ��⣬����ͷ���ص���������һ����ν�ͼ���㷨���л��������ҵ�һ�����ʵIJ��л�������ܡ�Spark��Ϊһ���dz�����IJ��д�����ܣ�������һЩ���л����㷨Ҳ��������Ȼ��
Graphx��һЩͼ�ij����㷨��Spark�ϵIJ��л�ʵ�֣�ͬʱ�ṩ�˷ḻ��API�ӿڡ����ľ�Graphx�Ĵ���ܹ���PageRank��Graphx�еľ���ʵ����һ��������ѧϰ��
GoogleΪʲôӮ�������������ս
��Google������ʱ����������������Yahoo!���������죬��ķ��ϡ���Ȼ����Google��ǰ����һ�����˼���û���κ�ϣ����ǽ�����������ϣ����ڡ������ʹȸ衱���˲�������ʵ��
����ת������������γɵ��ˣ���һ�������������ģ��Ǿ���Google�����������������ȷ�ʵ�PageRank�㷨�����˵PageRank�㷨������ùȸ�����վ�������������ս�ĽŸ������Ǻ������ŵġ�������Ϊ�����������м���Ҫ���ǵĹؼ����أ�
Ҫ�������û����ͱ���Ҫ�г�ɫ������ȷ��
�����û������������Ͷ�ţ���߹��Ͷ�ŵ�����ԾͿ���ӯ��
�����������涼�зdz�������㷨��
�ϻ��������ص����⡣PageRank�㷨��ͼ�۵�һ������Ӧ�ã�����ת��ͼ�ۡ�
ͼ�ۼ��
ͼ�����
��ɢ��ѧ�зdz���Ҫ��һ�����־���ͼ�ۣ�������һ��������ͨͼ
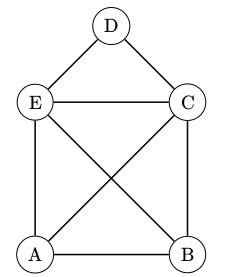
���㣨vertex��
��ͼ�е�A��B��C��D��E��Ϊͼ�Ķ��㡣
��
�����붥��֮������߳�֮Ϊ�ߡ�
ͼ����ѧ��ʾ
����ѧ��ʱ��һֱû��������ΪʲôҪѧ��ʲ�ӵ����Դ�����ֱ�������쿴����ѧ֮����һ��ʱ���ŷ��������Դ�����һЩ�����Ӧ�������Ǽ�ֱ���Dz��ɻ�ȱ����
���DZȽ����������ƽ�漸�κ����弸�Σ�һ���Ƕ�ά��һ������ά���������Դ����������ʵ��һ����ά���⣬������ֱ���ĸ��ܵ������Ժ��ѡ������Ƚ�ͨ������һ����ѧΪʲô����ô��ķ�֧�������ڹ�����ǿ���Ƽ���һ�¡���ѧ�ŶԸߵ���ѧ��һ�ι���֮�á���
����ѧ�У���ʲô����ʾͼ�أ��𰸾������Դ�������ľ������뿴��ͼ�Ĺ�������ͼ���ڽӾ�����֮���Ǿ������Դ���һ���������ˡ�������һ����������ӡ�

ͼ�IJ��л�����
�ղ�˵��ͼ�����þ�������ʾ��ͼ�IJ��л�������ij�̶ֳ��Ͼͱ�ת��Ϊ��������IJ��л����⡣��ô�Ծ���ij˷�Ϊ�����������Ƿ���Բ��л��������Ծ���
A X B Ϊ����˵�����л��������̡�
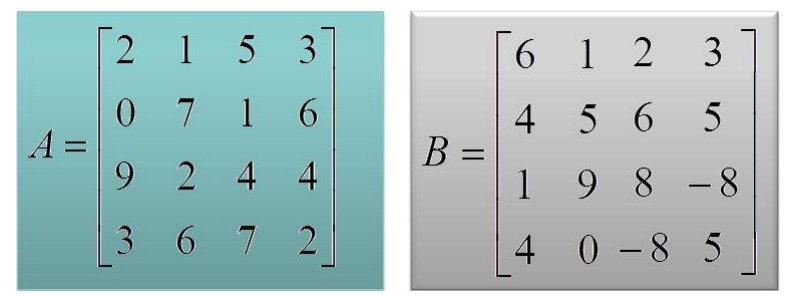
�������ľ���A��B����Ϊ�ĸ����֣�����ͼ��ʾ
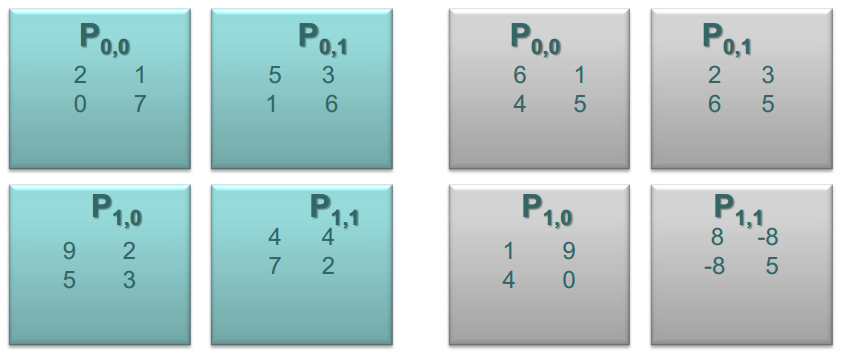
�״ζ���֮��
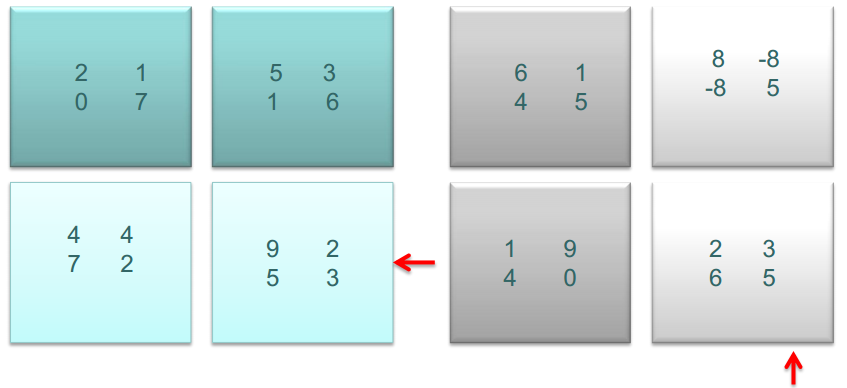
�Ӿ������

���֮��A���Ӿ������ƣ�B���Ӿ�������
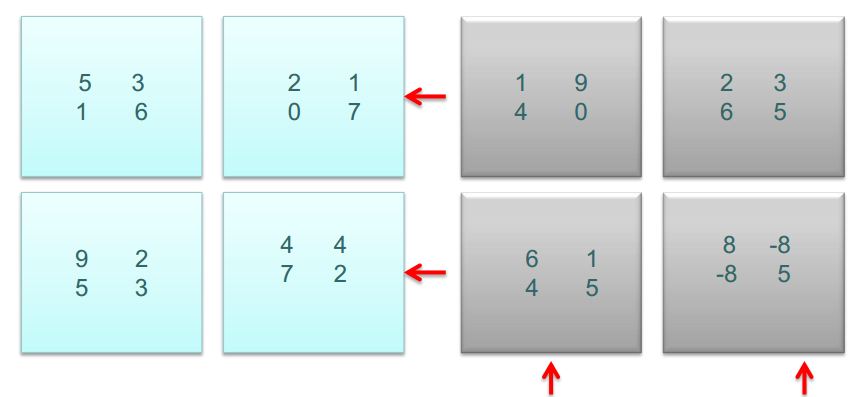
�������ϲ�

ͼ�IJ��л�������ܣ���Pregel˵����һ�ڵ��ص������㣺
ͼ�þ�������ʾ����ͼ��������Ǿ��������
����˷�������Բ��л�����̬��ʾ�䲢�л���ԭ��
����û��һ�ֺ��ʵIJ��л�������ܿ�����������ͼ�ļ����أ�����϶��뵽��MapReduce��MapReduce����Ҳ��һ�������IJ��л�������ܣ�����ͼ���㷽�棬������ȱ�㣬��Ҫ�Ǽ�����м������Ҫ�洢��Ӳ�̣�Ч�ʺܵ͡�Google���ͼ�IJ��д�����ר�������һ���˲���Ŀ��Pregel����ִ��ʱ�Ķ�̬��ͼ������ʾ��Pregel�������ŵ㣺
���������Ժã���Scalability
�ݴ���ǿ
�ܹ��ܺõı�ʾ����ͼ�ij����㷨
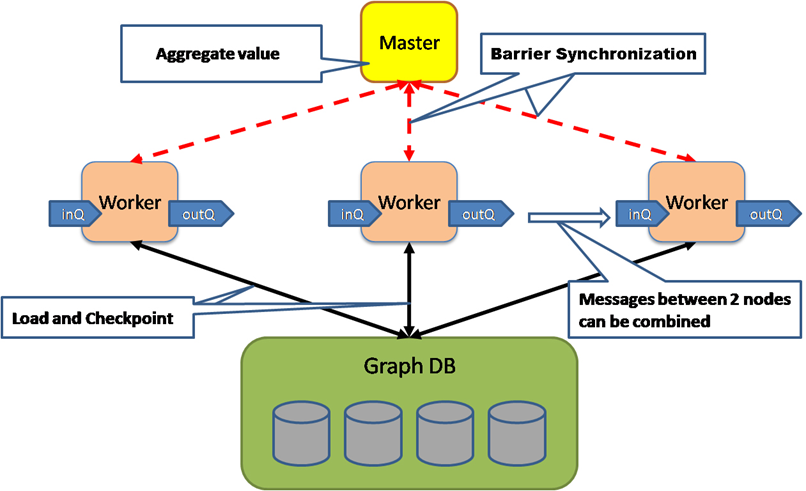
Pregel�ļ���ģ��
����ģ������ͼ��ʾ����Ҫ��������
������ÿ������Ĵ����� vertexProgram
��Ϣ���ͣ��������ڽڵ���ͨѶ sendMessage
��Ϣ�ϲ��� messageCombining

Pregel��Spark�е�ʵ��
�dz���л���ܼ�ֿ������ڣ���ƪ�������ݺܶ࣬�е��ѡ����뻹����һ��ͼ������������һ���ټ���˵��ȥ��
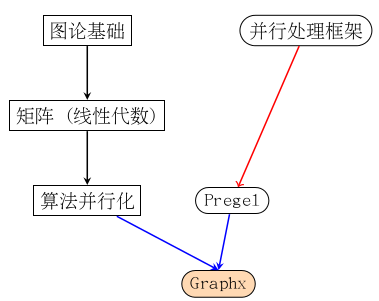
��ͼҪ��ʾ����˼�������ģ�Graphx������Spark������һ�����д��������ʵ����ͼ�ϵ�һЩ�ɲ��л�ִ�е��㷨����ƪ����Ҫ�������˼��������Ӻ����仰������λ������ϸ���⡣
�㷨�Ƿ��ܹ����л���Spark������
�㷨���л����ı�������Ҫͨ����ѧ��֤��
�Ѿ�֤���Ŀɲ��л��㷨������Spark��ʵ�ֻ���һ������ѡ����ΪGraphx֧��pregel��ͼ����ģ��
Graphx�е���Ҫ����
Graph
�������ʣ�ͼ������graphx��һ���dz���Ҫ�ĸ��
��Ա����
Graph����Ҫ�ij�Ա�����ֱ�Ϊ
vertices
edges
triplets
ΪʲôҪ����triplets�أ���Ҫ�Ǻ�Pregel�������ģ����أ���triplets�У�ͬʱ��¼��edge��vertex.
�������Ͳ������ˡ�
��Ա����
�����ֳɼ�����
�����ж����ߵIJ����������ı�ͼ�ṹ��������mapEdges��mapVertices
��ͼ�������ڼ��ϲ����е�filter subGraph
ͼ�ķָ��paritition�������������Spark������˵���ܹؼ���������Ϊ���˲�ͬ��Partition�������˲��д����Ŀ��ܣ���ͬ��PartitionStrategy�������治ͬ���������뵽�ľ�������Hash��������ͼ�ֳɶ������
outerJoinVertices ����������Ӳ���
ͼ������Ͳ��� GraphOps
ͼ�ij����㷨�Ǽ��г���GraphOps������У���Graph��������ʽת������Graphת��
GraphOps
implicit def graphToGraphOps[VD: ClassTag, ED: ClassTag]
(g: Graph[VD, ED]): GraphOps[VD, ED] = g.ops |
֧�ֵIJ�������
collectNeighborIds
collectNeighbors
collectEdges
joinVertices
filter
pickRandomVertex
pregel
pageRank
staticPageRank
connectedComponents
triangleCount
stronglyConnectedComponents
RDD
RDD��Spark��ϵ�ĺ��ģ���ôGraphx����������Щ�µ�RDD�أ��������ֱ�Ϊ
VertexRDD
EdgeRDD
��֮EdgeRdd��VertexRDD��Ϊ��Ҫ�����ϵIJ���Ҳ�ܶ࣬��Ҫ������Vertex֮�����Եĺϲ���˵���ϲ��Ͳ��ò�������ϵ�����ͼ����ۣ�������VertexRdd���ܿ�������������sql�е������
leftJoin
innerJoin
����leftJoin��innerJoin��outerJoin�����𣬽���ȸ�һ�£���������
Graphx��������
ͼ�Ĵ洢�ͼ���
�ڽ�����ѧ�����ʱ��ͼ�����Դ����еľ�������ʾ����ô��ν��д洢�أ�
ѧ���ݽṹ��ʱ����ʦ�϶�˵���ö�İ취�����ن����ˡ�
�����ڴ����ݵĻ����£����ͼ�ܾ�ʾ����ͱߵ����ݲ����Է���һ���ļ�����ô�죿 ��HDFS��
���ص�ʱ��һ̨�������ڴ治����������ô�죿 �ӳټ��أ���������Ҫ����ʱ�������ݷַ�����ͬ�����У����ü�����ʽ��
һ����˵�����ǻὫ�����붥����ص����ݱ�����һ���ļ���vertexFile�����������ص���Ϣ��������һ���ļ���edgeFile��
����ijһ�������ͼʱ����edge�Ϳ��Ա�ʾͼ�ж���Ĺ�����ϵ��ͬʱͼ�ĽṹҲ��ʾ�����ˡ�
GraphLoader
graphLoader��graphx��ר������ͼ�ļ��غ����ɣ�����Ҫ�ĺ�������edgeListFile���������£�
def edgeListFile(
sc: SparkContext,
path: String,
canonicalOrientation: Boolean = false,
minEdgePartitions: Int = 1,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY)
: Graph[Int, Int] =
{
val startTime = System.currentTimeMillis
// Parse the edge data table directly into edge partitions
val lines = sc.textFile(path, minEdgePartitions).coalesce(minEdgePartitions)
val edges = lines.mapPartitionsWithIndex { (pid, iter) =>
val builder = new EdgePartitionBuilder[Int, Int]
iter.foreach { line =>
if (!line.isEmpty && line(0) != '#') {
val lineArray = line.split("\\s+")
if (lineArray.length < 2) {
logWarning("Invalid line: " + line)
}
val srcId = lineArray(0).toLong
val dstId = lineArray(1).toLong
if (canonicalOrientation && srcId > dstId) {
builder.add(dstId, srcId, 1)
} else {
builder.add(srcId, dstId, 1)
}
}
}
Iterator((pid, builder.toEdgePartition))
}.persist(edgeStorageLevel).setName("GraphLoader.edgeListFile - edges (%s)".format(path))
edges.count()
logInfo("It took %d ms to load the edges".format(System.currentTimeMillis - startTime))
GraphImpl.fromEdgePartitions(edges, defaultVertexAttr = 1, edgeStorageLevel = edgeStorageLevel,
vertexStorageLevel = vertexStorageLevel)
} // end of edgeListFile |
Ӧ�þ���֮PageRank
ʲô��PageRank
PageRank��Googleר�е��㷨�����ں����ض���ҳ������������������е�������ҳ���Ե���Ҫ�̶ȡ�����Larry
Page �� Sergey Brin��20����90������ڷ�����PageRankʵ���˽����Ӽ�ֵ������Ϊ�������ء�PageRank����ҳ������ӿ���ͶƱ��ָʾ����Ҫ�ԡ�
PageRank�ĺ���˼��
���ڻ������ϣ����һ����ҳ���ܶ�������ҳ�����ӣ�˵�����ܵ��ձ�ij��Ϻ���������ô���������ͺܸߡ��� ��ժ����ѧ֮����10�£�
��˵��Ҳ̫���˰ɣ����Ǹ�û˵һ��������ô����ѧ����ʾ�أ�
�Ǻǣ������Ҳ��ô��ģ�������˼���֮��������һ��㡣�������������ֱ������£�
��ҳ����ҳ֮��Ĺ�ϵ��ͼ����ʾ
��ҳA����ҳB֮������ӹ�ϵ��ʾ����һ���û�����ҳA��ת����ҳB�Ŀ����ԣ����ʣ�
������ҳ��������һά������B����ʾ
������ҳ֮��������þ���A����ʾ��������ҳ������B����ʾ��
���ڻ������ϣ����һ����ҳ���ܶ�������ҳ�����ӣ�˵�����ܵ��ձ�ij��Ϻ���������ô���������ͺܸߡ�"��ժ����ѧ֮����10�£�
��˵��Ҳ̫���˰ɣ����Ǹ�û˵һ��������ô����ѧ����ʾ�أ��Ǻǣ������Ҳ��ô��ģ�������˼���֮��������һ��㡣�������������ֱ������£�
1.��ҳ����ҳ֮��Ĺ�ϵ��ͼ����ʾ
2.��ҳA����ҳB֮������ӹ�ϵ��ʾ����һ���û�����ҳA��ת����ҳB�Ŀ����ԣ����ʣ�
3.������ҳ��������һά������B����ʾ
������ҳ֮��������þ���A����ʾ��������ҳ������B����ʾ��

pageRank��ν��в��л�
���ˣ��������ѧ����˵���ˡ���ҳ�����ļ���������ճ���Ϊ������ˡ������ڿ�ʼ��ʱ���Ѿ�֤���� ������˿��Բ��л�����
��
�����о������ˣ��������ľ��ǹ���ʵ���ˣ�����Pregelģ�ͣ�PageRank�ж���ĸ���Ҫ�����ֱ����¡�
vertexProgram
def vertexProgram(id: VertexId, attr: (Double, Double), msgSum: Double): (Double, Double) = {
val (oldPR, lastDelta) = attr
val newPR = oldPR + (1.0 - resetProb) * msgSum
(newPR, newPR - oldPR)
} |
sendMessage
def sendMessage(edge: EdgeTriplet[(Double, Double), Double]) = {
if (edge.srcAttr._2 > tol) {
Iterator((edge.dstId, edge.srcAttr._2 * edge.attr))
} else {
Iterator.empty
}
} |
messageCombiner
def messageCombiner(a: Double, b: Double): Double = a + b |
һ�����ʾ
ͨ��pageRank������ӣ������ܹ��������ν�ƽ��ѧϰ����ѧ�������Խ��ʵ�����⡣
��ѧϰ�Ķ��������м�ֵ�ģ������õ����ò��ϣ�ȫ���컯�ˡ�
��������
// Connect to the Spark cluster
val sc = new SparkContext("spark://master.amplab.org", "research")
// Load my user data and parse into tuples of user id and attribute list
val users = (sc.textFile("graphx/data/users.txt")
.map(line => line.split(",")).map( parts => (parts.head.toLong, parts.tail) ))
// Parse the edge data which is already in userId -> userId format
val followerGraph = GraphLoader.edgeListFile(sc, "graphx/data/followers.txt")
// Attach the user attributes
val graph = followerGraph.outerJoinVertices(users) {
case (uid, deg, Some(attrList)) => attrList
// Some users may not have attributes so we set them as empty
case (uid, deg, None) => Array.empty[String]
}
// Restrict the graph to users with usernames and names
val subgraph = graph.subgraph(vpred = (vid, attr) => attr.size == 2)
// Compute the PageRank
val pagerankGraph = subgraph.pageRank(0.001)
// Get the attributes of the top pagerank users
val userInfoWithPageRank = subgraph.outerJoinVertices(pagerankGraph.vertices) {
case (uid, attrList, Some(pr)) => (pr, attrList.toList)
case (uid, attrList, None) => (0.0, attrList.toList)
}
println(userInfoWithPageRank.vertices.top(5)(Ordering.by(_._2._1)).mkString("\n")) |
��
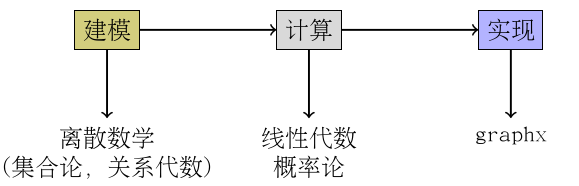
��ƪ������ȥ����ǿ��һ�����⣬Spark��һ���ֲ�ʽ���м����ܡ��ܲ�����Spark����ʵ����ȡ�����������ѧģ�ͱ�����������Բ��л�����������֮���в����������ġ�
��һ������ͼ���ܽ�һ���ᵽ����ѧ֪ʶ�ɡ�
|






