|
ժҪ�����������������Ķ���ʵ�⣬�Գ�����ƭ������ķ�ʽ���ӹ��߰�װ��ģ��ѵ�������������缰�䱳�����ѧԭ�������»��ṩ����ʾ�������ء�
�����������
���Ҵ�GooglePhotos�����ҵ���Ƭ��������skyline��ʱ�����ҵ������ڰ������������ŦԼ��ƽ�ߵ���Ƭ������֮ǰ��δ���������κα�ǡ�

����������cathedral����Google����������ҵ����������Ĵ���úͽ��á����ƺ������档
��Ȼ�������粢�����棬һ�㶼����������Ķ���һƪ���ģ���ExplainingandHarnessingAdversarialExamples���Կ������Ľ��ͺ����ã�������һ���������Ҷ�����������ظС�
��ƪ���Ľ����������ƭ�����磬���䷸�·dz����˵Ĵ���ͨ�����ñ���������������ԣ�����������ʵ��������һ�㡣���ǻ�ʹ��һ�����Ժ������ƽ�������磡
�ص���Ҫ���⣬�Ⲣ���ܽ��������緸�µ����У����Ǵ���������͵Ĵ����кܶ���ܻ᷸�Ĵ�����ȷʵ��һЩ�ض����͵Ĵ����ϸ�������һЩ��У���dz��á�
���Ķ���ƪ����֮ǰ���Ҷ���������˽����������㣺
- ����ͼƬ�����б��ֵúܳ�ɫ������������baby��ʱ�������ҵ������ѿɰ��ĺ�����Ƭ��
- ��Ҷ�������̸�ۡ���ȡ�������
- �������ɶ��ĺ�����ͨ����sigmoid�����ɣ���ṹ����ͼ��ʾ��
����
�Ҷ��������˽�ĵ��ĵ㣨Ҳ�����һ�㣩�ǣ�������ʱ�᷸�ܿ�Ц�Ĵ���һ�±��ĺ���Ľ������������ͼƬ�����»�չʾ����������ζ�����з���ġ����ǿ����������ţ������ɫ��ͼ����һ��ֽ��������è��ᱻʶ��Ϊһֻͺ�գ�
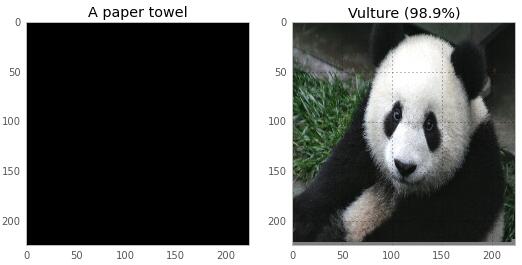
���ڣ�������������˵�����Ծ�����Ϊ����ѧϰ���ҵĹ�����������֪������ѧϰϰ�߲�����ֵĽ���������Ҫ������������ֵĴ������Ǿ���Ҫ�����䱳���ԭ��������ҪѧϰһЩ���������йص�֪ʶ��Ȼ���һ�����������������Ϊ��è����һֻͺ�ա�
����һ��Ԥ��
�������ȼ���һ�������磬Ȼ����һЩԤ�⣬����ٴ�����ЩԤ�⡣�����������������������Ҫ�ڵ����ϵõ�һ�������硣
���ڵ����ϰ�װ��Caffe������һ����������������Berkeley Vision and Learning Center (BVLC) ���������߿����ġ���ѡ��������Ϊ�����ҵ�һ�������ҵ��������������ҿ�������һ��Ԥ��ѵ���õ����硣��Ҳ���Գ�����Theano����Tensorflow��Caffe�зdz������İ�װ˵��������ζ��������ʽʹ�������й���ǰ������ֻ�軨6��Сʱ����Ϥ��
�������Ҫ��װCaffe�����Բο���д�ij������������ʡ�����ʱ�䡣ֻ��ȥtheneural-networks-are-weirdrepo����ֿ⣬Ȼ����˵�����м��ɡ����棺�������ش�Լ1.5G�����ݣ�������Ҫ����һ��ѵĶ����������ǹ��������������3�У�������Ҳ�����ڲֿ��µ�README�ļ����ҵ���
git clone <a href="https://github.com/jvns/neural-nets-are-weird">https://github.com/jvns/neural-nets-are-weird</a>
cd neural-nets-are-weird
docker build -t neural-nets-fun:caffe .
docker run -i -p 9990:8888 -v $PWD:/neural-nets -t neural-nets-fun:caffe /bin/bash
-c 'export PYTHONPATH=/opt/caffe/python && cd /neural-nets && ipython notebook --no-browser --ip 0.0.0.0' |
�������������е�IPythonnotebook����Ȼ����������Python��������Ԥ���ˡ�����Ҫ�ڱ���9990�˿������С�����㲻������������ȫû��ϵ��������ƪ������Ҳ������ʵ��ͼƬ��
һ����������IPtyonnotebook�����к����ǾͿ��Կ�ʼ���д��벢��Ԥ���ˣ�������һ���һЩ���۵�ͼƬ�������Ĵ���Ƭ�Σ��������Ĵ������ϸϸ�ڿ���������鿴��
���ǽ�ʹ��һ������GoogLeNet�������磬����LSVRC2014���������ʤ������ȷ�������ںķ�94%ʱ���ǰ5������²��С������Ҷ�������ƪ���ĵ����硣���������Ҫһ���ܺõ��Ķ���������Ķ�һ������ܱ�GoogLeNet���ø�����ƪ���¡���������ĺ����档��
���ȣ�������ʹ�������һֻ�ɰ���kitten���з��ࣺ

�����Ƕ�kitten���з���Ĵ��룺
image = '/tmp/kitten.png'
# preprocess the kitten and resize it to 224x224 pixels
net.blobs['data'].data[...] = transformer.preprocess('data', caffe.io.load_image(image))
# make a prediction from the kitten pixels
out = net.forward()
# extract the most likely prediction
print("Predicted class is #{}.".format(out['prob'][0].argmax())) |
����Щ������ֻ��3�д��롣ͬ�����ҿ��Զ�һֻ�ɰ���С�����з��࣡
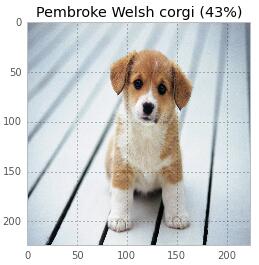
ԭ����ֻ�����ǿ»�Ȯ��ֻ����ɫ�dz����ơ��������Թ����˽������һ��ࡣ
һ��������ʲô���ģ���Ů��Ϊ����
�������ʱ����Ȥ�������ǣ��ҷ�������������ΪӢ��Ů����������ͷ�ϡ�

���ԣ��������ǿ�����������һ����ȷ���£�ͬʱ����Ҳ�������ڲ�����䷸��һ���ɰ��Ĵ���Ů��������ԡñ��������...������������ȥ�������������ĺ��ġ�
���ⷸ����
�����������乤��ԭ��֮ǰ��������Ҫ��һЩ��ѧ�任�����������ǿ������Ժ�ɫ��Ļ��һЩ������
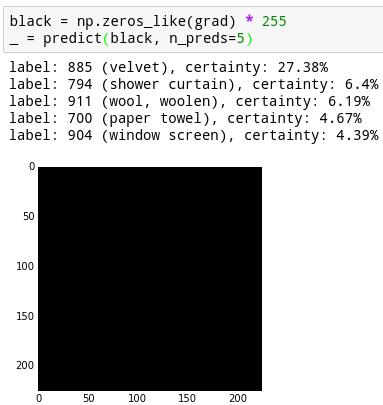
���Ŵ���ɫͼ����Ϊ������ĸ�����27%������Ϊ��ֽ���ĸ���Ϊ4%������һЩ�������ĸ���û���г�������Щ����֮��Ϊ100%��
����Ū�����������������������Ϊ����һ��ֽ����
Ҫ������һ�㣬������Ҫ������������ݶȡ�Ҳ����������ĵ���������Խ��⿴����һ��������ͼ������������Ͽ���������һ��ֽ����
Ҫ�����ݶȣ�����������Ҫѡ��һ��Ԥ�ڵĽ�����ƶ�����������������б���0��ʾ�κη���1��ʾֽ���ķ������㷨��һ�ּ����ݶȵ��㷨����ԭ��Ϊ�������أ�����ʵ����ֻ��һ��ʵ����ʽ������㷨���������֪�����࣬��ƪ������һ������Ľ��͡�
�������ұ�д�Ĵ��룬ʵ���Ϸdz���������һ������������������㣬����ڿ��к�����á�
def compute_gradient(image, intended_outcome):
# Put the image into the network and make the prediction
predict(image)
# Get an empty set of probabilities
probs = np.zeros_like(net.blobs['prob'].data)
# Set the probability for our intended outcome to 1
probs[0][intended_outcome] = 1
# Do backpropagation to calculate the gradient for that outcome
# and the image we put in
gradient = net.backward(prob=probs)
return gradient['data'].copy() |
������ϸ��������ǣ�ʲô���������������һ����Ѱ�ҡ���Ϊ���Ǵ��������ж��������Ա�ʾΪһ��ͼ�����������compute_gradient(black,paper_towel_label)����������ŵ��ɼ�������
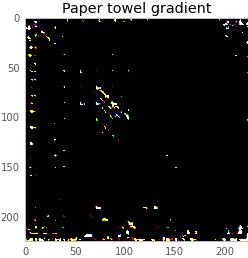
���ڣ����ǿ��Դ����ǵĺ�ɫ��Ļ���ӻ��ȥһ���dz������IJ��֣�ʹ��������Ϊ���ǵ�ͼ���������һ��ֽ���������������ӵ�ͼ��̫��������ֵС��1/256�������Բ�����ȫ����������������������
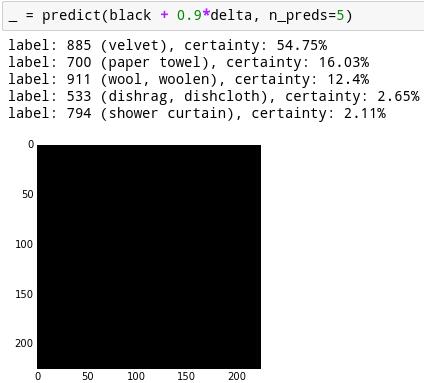
���ڣ���������16%�ĸ��ʿ϶����ǵĺ�ɫ��Ļ��һ��ֽ����������4%�������ɡ����ǣ����ǿ������ĸ��á����ǿ��Բ�ȡ��ʮ��С��������һ���е���ֽ����ÿһ������������ֽ���ķ���ֱ����һ��������������濴����ʱ��仯�ĸ��ʡ����ע�����ֵ��֮ǰ�IJ�ͬ����Ϊ���ǵIJ�����С��ͬ��0.1��������0.9����
���Ľ����
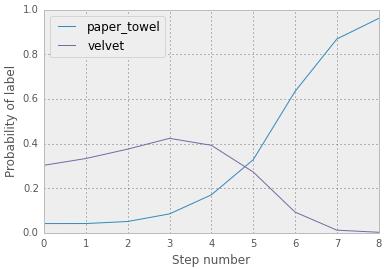
�����ǹ�������ͼ�������ֵ�����Ƕ���0��ʼ����������Կ����������Ѿ�ת�������ǣ�ʹ����Ϊ��ͼ�����ֽ����
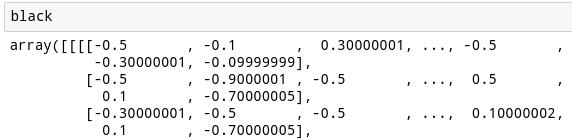
���ǻ�������50�������ͼ��Ӷ����һ�����õ�ͼ���֪��
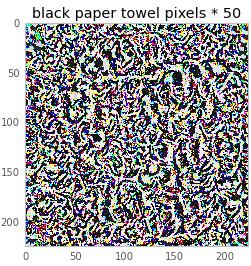
������˵���⿴����������һ��ֽ������������ܾ����Ҳ²�ͼ����������ж�ϷŪ��������ʹ����Ϊ����һ��ֽ������ǣ���������ĸ���֤����һЩ��ѧԭ�����������Ǿ�Ҫ�Ӵ��������ѧ֪ʶ�ˣ������������������Ȥ�ġ�
��ת������
һ������������������ͻ��÷dz���Ȥ�����ǿ��Ի�һֻè���ԡ����
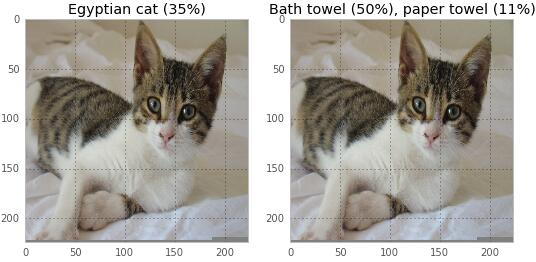
һ������Ͱ���Ա��һ��ˮ��/��β�Ƶ�������
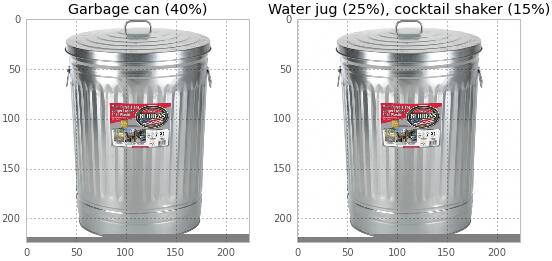
һֻ��è���Ա��ͺ�ա�
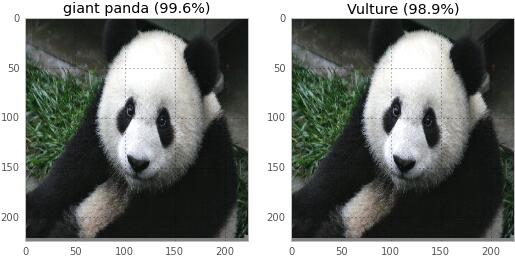
����ͼ�������ڽ���è��Ϊ��ͺӥ��100���ڣ����������ת��غ�Ѹ�١�
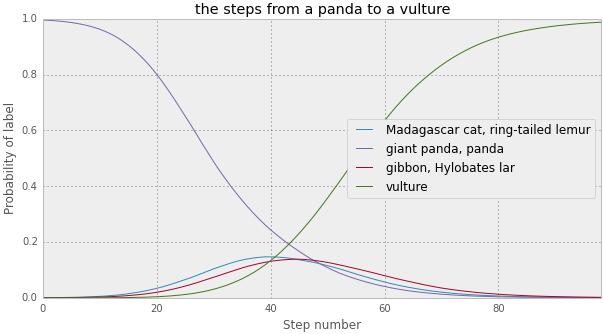
����Բ鿴���룬����Щ������IPythonnotebook�����С���ĺ���Ȥ��
���ڣ���ʱ���һ����ѧԭ���ˡ�
��ι��������ع�
���ȣ�����������һ�����ͼ�������������ع顣ʲô�����ع飿�����������Ž����¡�
��������һ�����Ժ��������ڷ���һ��ͼ���Ƿ�����ܡ���ô�������ʹ�����Ժ����أ����ڼ������ͼ��ֻ��5�����أ�x1,x2,x3,x4,x5����ȡֵ����0��255֮�䡣���ǵ����Ժ�������һ��Ȩ�أ�����ȡֵΪ��23,-3,9,2,5����Ȼ���ͼ����з��࣬���ǻὫ�õ����غ�Ȩ�ص��ڻ���
result=23x13x2+9x3+2x45x5
�������ڵĽ����794����ô794������ζ��������ܻ��߲����أ�794�Ǹ�����794��Ȼ���Ǹ��ʡ�������һ��0��1֮����������ǵĽ���ڡ���֮�䡣���ǽ�һ��ȡֵ�ڡ���֮�����תΪһ������ֵ��һ�㷽����ʹ��һ������logistic�ĺ�����S(t)=1/(1+e^(-t))
�˺�����ͼ��������ʾ��
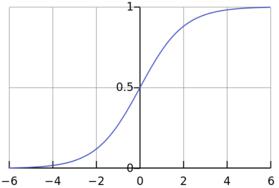
S(794)�Ľ������Ϊ1������������Ǵ���ܵ�Ȩ�صõ�794����ô���ǾͿ϶���100%�Ǹ���ܡ������ģ���С���������ʹ�����Ժ����任���ݣ�Ȼ��Ӧ���������õ�һ������ֵ����������ع飬��������һ�ַdz������еĻ���ѧϰ������
����ѧϰ�еġ�ѧϰ����Ҫ���ڸ�����ѵ�����£���ξ�����ȷ��Ȩ�أ����磨23,-3,9,2,5�������������ǵõ��ĸ���ֵ���ܾ����ܵĺá�ͨ��ѵ����Խ��Խ�á�
��������������ʲô�����ع飬��������������������δ������ɣ�
�������ع�
����һƪ�����IJ��ģ�AndrejKarpathy������BreakingLinearClassifiersonImageNet����������������ش���һ��������ģ�ͣ��������ع飬��������ģ�ͣ����������ǽ�ʹ��ͬ����ԭ�������������硣
����һ�����ӣ�����Karpathy�����£���һЩ���ֲ�ͬʳ��ʻ��Լ���������Է����������ӻ�Ϊ��ͼ������ɷŴ�

����Կ�����GrannySmith�����������������ʡ�����ɫô����������������ķ�ʽ���ҳ�����������menu�����������ֲ˵�ͨ���ǰ�ɫ��Karpathy������͵ķdz������
���磬ƻ������ɫ�ģ��������Է����������еĿռ�λ���У���ɫͨ���ϳ�����Ȩֵ����ɫ�ͺ�ɫͨ���ϳ��ָ�Ȩֵ����ˣ�����Ч�ؼ������м�����ɫ�ɷֵ�����
���ԣ��������Ҫ��GrannySmith��������Ϊ����һ��ƻ��������Ҫ�����ǣ�
- �ҳ�ͼ����һ�����ص��������ɫ
- ��������ɫ�����ص���ɫ
- ֤����
������������֪�����ȥ��ƭһ�����Է����������������粢�������Եģ����Ǹ߶ȷ����Եģ�Ϊʲô������أ�
������������
�����ұ����ʵһ�㣺�Ҳ���������ר�ң��Ҷ�������Ľ��Ͳ�����ܳ�ɫ��MichaelNielsenд��һ��������NeuralNetworksandDeepLearning�����飬д�ĺܺá����⣬ChristopherOlah�IJ���Ҳ������
����֪�����������ǣ������Ǻ�����������һ��ͼ�����õ�һ�������б�����ÿ�����һ�����ʡ���Щ��������ƪ�����п�����ͼ������֡�������һֻ���𣿲�����ԡñ��Ҳ���ǡ�һ��̫���ܵ�أ�YES������
��ˣ�һ�������磬����1000��������ÿ�����ʶ�Ӧһ��������1000����������������˵�dz����ӡ���ˣ�����������ˣ����ǰ���1000��������ϲ�Ϊһ����һ�ġ��÷֡�������֮Ϊ����ʧ��������
ÿ��ͼ�����ʧ����ȡ����ͼ��ʵ����ȷ���������������һ�������ͼƬ��������������һ���������Pj������j=1...1000��������ÿֻ��������Ҫ�õ����Ǹ���yj����ô��ʧ����Ϊ��
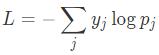
�����롰����Ӧ�ı�ǩֵ��700����ôy700=1��������yj��Ϊ0��L=-logp700��
������ص���Ҫ����������������һ����������������һ��ͼ����è�������õ���ʧ����������ֵ��һ��������2������Ϊ����һ����ֵ�������������ǽ��ú����ĵ��������ݶȣ���ֵ����һ��ͼ��Ȼ����Ϳ���ʹ�����ͼ������ƭ�����磬Ҳ��������������ƪ����ǰ�����۵ķ�����
����������
�����ǹ�����δ���һ�����Ժ���/���ع���������Ĺ�ϵ��Ҳ������һֱ�ڵȴ�����ѧԭ����˼�������ǵ�ͼ�ɰ�����è������ʧ������������
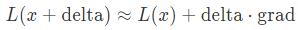
���У��ݶ�grad����L(x)����Ϊ�������֡�Ϊ������ʧ�����ı仯�ĸ��࣬����Ҫ����ƶ���delta���ݶ�grad���ߵĵ����������ͨ��compute_gradient()���������ݶȣ�����������һ��ͼƬ��
ֱ������������Ҫ�����Ǵ���һ��delta�����ص�ǿ����������Ϊ��Ҫ��ͼ�����ء����ڣ�����gradΪ(0.01,0.01,0.01,0.02,0.03).
���ǿ���ȡdelta=(1,1,1,1,1)����ôgraddelta��ֵΪ0.08.�������dz���һ�£��ڴ����У�����delta=np.sign(grad)��������ͨ����������ƶ�ʱ����Ȼ�C������è��ɻ������ˡ�
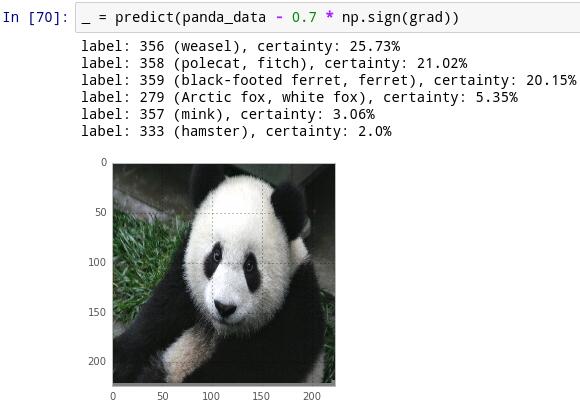
���ǣ�����Ϊʲô�أ���������˼������ʧ���������ǿ�ʼ�����Ľ����ʾ��������è�ĸ���Ϊ99.57%��log(0.9957)=0.0018���dz�С����ˣ�����һ��delta�����������ǵ���ʧ������ʹ��������è��������ȥһ��delta����������ǵ���ʧ������ʹ��������è��������ʵ�����෴���Ҷ���һ�㻹�Ǻ�����
����ƭ���˹�
���������˽�����ѧԭ����һ����̵��������һ�����ȥ��ƭ���磬����ʶ����ǰ��ֻ�ɰ���С����
�����ڹ��������ǿ�ҵصֿ��������Ϊ����֮��Ķ������һ���һЩʱ����ͼ����������ֻ����һ������������Ȼ��һֻ��������������Ĺ�������Ȼ����һֻ����
����һ��������������JeffDean�����ڹȸ��������繤�������������������һ�㡣�������ң����������ѵ��������һ�ѹ�������è�ࡣ������������Ҫѵ�����õ�������ʶ���ƺ��е�����
����Ϊ��dz��ᣬ�����Ҿ���ѵ������ȷ���������ϣ����
��������������һ������Ȥ������C������ͼ��������Ϊ��è��һֻͺ��ʱ�������м仨��һ��ʱ��ȥ˼�����Ƿ�����������JeffDean������è���������ʱ��������ᵽ�ˡ���è����ռ䡱�����Ҳ�û���ᵽ��������Ϊ��è��ͺ��ʱ��˼�������Ƿ�����������ĺܿᣬ�������ݺ���Щ���绨�㹻��ʱ��һ���Ӿ������֪���������è��ij�ֹ�ϵ���ܵؽ����һ��
���ٵ����ظ�
���ҿ�ʼ������µ�ʱ���Ҽ�����֪��ʲô�������硣�����ҿ���ʹ����Ϊ��è��һֻͺӥ��������������δ����ķ������һ�����˽����ǡ��Ҳ�����Ϊ�ȸ��������ĺ������ˣ�����������������Ȼ���ɻ��кܶ���Ҫѧϰ��ʹ�����ַ�ʽȥ��ƭ���ǣ�������һЩ���ظУ��������ڶ����ǵ��˽�����ˡ�
������Ҳ���Եģ������������д��붼��neural-networks-are-weird����ֿ��С���ʹ�õ���Docker��������������ذ�װ�������㲻��Ҫһ��GPU�����µ��ԡ���Щ���붼��������̨����3�����GPU�ʼDZ������еġ�
��Ҫ�˽���࣬���Ķ�ԭ���ģ�ExplainingandHarnessingAdversarialExamples���������ݼ�̣�д�úܺã����������౾��û�ἰ�������ݣ��������ʹ��������ɽ������õ������磡
���лMathieuGuay-Paquet,KamalMarhubi�Լ������ڱ�д��ƪ���°������ҵ��ˣ�
|






