|
摘要:本教程展示了改善文本分类的方法,包括:做一个验证集,为AUC预测概率,用线性模型代替随机森林,使用TF-IDF权衡词汇,留下停用词,加上二元模型或者三元模型等。

有一个Kaggle的训练比赛,你可以尝试进行文本分类,特别是电影评论。没有其他的数据――这是使用文本分类做一些实验的绝佳机会。
Kaggle有一个关于本次比赛的tutorial,它会带你走进流行的词袋方法以及word2vec。本教程几乎代表了最佳实践,最有可能让参赛选手的优化变得很容易。而这正是我们要做的。
验证
验证是机器学习的基石。这是因为我们之后会推广到未知的测试实例。通常,评估一个模型推广的唯一明智方式是使用验证:如果你有足够的例子,你可以进行单一训练、验证分割;又或者如果你有几个训练点,你可以进行计算上更昂贵但却很有必要的交叉验证。
一点题外话:在不少Kaggle比赛,来自不同分布而不是训练集的一组测试,意味着它甚至很难成为代表性的验证集。这是一个挑战还是愚蠢的行为,取决于你的观点。
为了激励验证的需求,让我们回顾百度团队参加ImageNet比赛的情况。这些人显然不理解验证,所以他们不得不求助于排行榜来评估自己的努力。ImageNet每周只允许两次提交,所以他们创造了许多假账户来拓展他们的带宽。不幸的是,主办方不喜欢这样的方法,而百度也因此陷入尴尬。
验证分割
我们的第一个步骤是通过启用验证来修改原始教程代码。因此,我们需要分割训练集。既然我们有25,000个训练例子,我们将取出5,000个进行测试,并留下20,000个进行培训。一种方法是将一个培训文件分割成两个――我们从phraug2中使用split.py脚本:
python split.py train.csv train_v.csv test_v.csv -p 0.8 -r dupa |
使用随机种子“Dupa”来实现再现。Dupa是用于这样场合的波兰码字。我们下面报告的结果是基于这种分割。
训练集是相当小的,所以另一种方式是加载整个训练文件到内存中并把它分割,然后,使用scikit-learn为此类任务提供的好工具:
from sklearn.cross_validation import train_test_split
train, test = train_test_split( data, train_size = 0.8, random_state = 44 ) |
我们提供的脚本使用这种机制以便使用,而不是单独的训练、测试文件。我们需要使用索引因为我们正在处理Pandas框架,而不是Numpy数组:
all_i = np.arange( len( data ))
train_i, test_i = train_test_split( all_i, train_size = 0.8, random_state = 44 )
train = data.ix[train_i]
test = data.ix[test_i] |
度量标准
竞争的度量标准是AUC,它需要概率。出于某种原因,Kaggle教程只预测0和1。这是很容易解决:
p = rf.predict_proba( test_x )
auc = AUC( test_y, p[:,1] ) |
而且我们看到,随机森林成绩大约为91.9%。
词袋的随机森林?不
随机森林是一个强大的通用方法,但它不是万能的,对于高维稀疏数据并不是最好的选择。而BoW表示是高维稀疏数据的一个很好例子。
此前我们覆盖了词袋,例如A bag of words and a nice little network。在那篇文章中,我们使用了神经网络进行分类,但事实是简约的线性模型往往是首选。我们将使用逻辑回归,因为现在留下超参数作为默认值。
逻辑回归的验证AUC是92.8%,并且它比随机森林的训练快得多。如果你打算从这篇文章学点东西:对于高维稀疏数据使用线性模型,如词袋。
TF-IDF
TF-IDF即“术语频率/倒排文档频率(term frequency / inverse document frequency)”,是这样一种方法:用于强调给定文档中的高频词汇,而不再强调出现在许多文档中的高频词汇。
我们TfidfVectorizer和20,000个特征的得分是95.6%,有很大的改进。
停用词和N-grams
Kaggle教程的作者认为有必要去除停用词(Stopwords)。停用词即commonly occuring words,比如“this”,“that”,“and”,“so”,“on”。这是一个很好的决定吗?我们不知道,我们需要检验,我们有验证集,还记得吗?留下停用词的得分为92.9%(在TF-IDF之前)。
反对移除停用词的一个更重要的原因是:我们想尝试n-grams,并且对于n-grams我们最好让所有词留在原地。我们之前涵盖了n-grams,它们由n个连续的词组合在一起,使用二元模型开始(两个词):“cat ate”,“ate my”,“my precious”,“precious homework”。三元模型由三个词组成:“cat ate my”,“ate my homework”,“my precious homework”;四元模型,等等。
为什么n-grams能够work?想想这句话:“movie not good”。它有明显的负面情绪,但是如果你把每个单词都分离,你将不会检测这一点。相反,该模型可能会了解到,“good”是一个积极的情绪,这将不利于判断。
在另一方面,二元模型可以解决问题:模型可能会了解到,“not good”有负面情绪。
使用来自斯坦福大学情感分析页面的更复杂的例子:
This movie was actually neither that funny, nor super witty.
|
对于这个例子,二元模型将在“that funny”和“super witty”上失败。我们需要至少三元模型来捕捉“neither that funny”和“nor super witty”,然而这些短语似乎并不太常见,所以,如果我们使用的特征数量有限,或正规化,他们可能不会让它进入到模型。因此,像神经网络一样的更复杂的模型的动因会使我们离题。
如果计算n-grams听起来有点复杂,scikit-learn量化能够自动地做到这一点。正如Vowpal Wabbit可以,但我们不会在这里使用Vowpal Wabbit。
使用三元模型的AUC得分为95.9%。
维度
每个字都是一个特征:它是否出现在文档中(0/1),或出现多少次(大于等于0的整数)。我们从教程中开始原始维数,5000。这对随机森林很有意义,这是一个高度非线性的、有表现力的、高差异的分类,需要一个配给相对比较高的例子用于维数。线性模型在这方面不太苛求,他们甚至可以在d>>n的情况下work。
我们发现,如果我们不限制维数,即使这样一个小的数据集也会使我们耗尽内存。我们可以在12 GB RAM的机器上带动大约40,000个特征。甚至引起交换。
对于初学者来说,我们尝试20,000个特征。逻辑回归分数为94.2%(在TF-IDF和n-grams之前),与5,000个特征的得分92.9%进行比较。更多的分数甚至更好:30,000个特征的得分96.0%,40,000个特征的得分96.3%(在TF-IDF和n-grams之后)。
为了解决内存问题,我们可以使用hashing vectorizer。然而,相对于之前的96.3%,它只得到了93.2%的分数,部分原因是它不支持TF-IDF。
结语
我们展示了改善文本分类的方法:
- 做一个验证集
-
为AUC预测概率
-
用线性模型代替随机森林
-
使用TF-IDF权衡词汇
-
留下停用词
-
加上二元模型或者三元模型
公众排行榜得分反映了验证得分:都大约是96.3%。在提交的时候,它在500名参赛者中足够进入前20名。
你可能还记得,我们留下了线性回归的超参数作为默认值。此外,向量化有它自己的参数,你可可期望更实际些。微调它们的结果有一个适量的改善,达到96.6%。
再次说明,这篇文章的代码可在Github上得到。
UPDATE:Mesnil,Mikolov,Ranzato和Bengio有一篇情感分类的paper:Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews (code)。他们发现,使用n-gram的线性模型优于递归神经网络(RNN)和使用句子向量的线性模型。
然而,他们使用的数据集(Stanford Large Movie Review Dataset)比较小,有25,000个训练实例。 Alec Radford 表示,在样本数量较大,大致从100,000到1000,000,RNN开始优于线性模型。
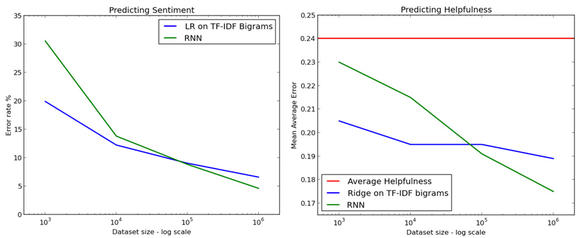
Credit: Alec Radford / Indico, Passage example
对于句子向量,作者用逻辑回归分析法。我们宁愿看到100维向量送入非线性模型随机森林。
这样,我们卑微地发现随机森林的分数只是85-86 %(奇怪……为什么?),这取决于树的数量。该paper准确地说,逻辑回归的精度大约为89%。 |






