|
DockOne技术分享(十六):闲谈Kubernetes 的主要特性和经验分享
主要介绍 Kubernetes 的主要特性和一些经验。先从整体上看一下Kubernetes的一些理念和基本架构,
然后从网络、 资源管理、存储、服务发现、负载均衡、高可用、rolling upgrade、安全、监控等方面向大家简单介绍Kubernetes的这些主要特性。
我们先从整体上看一下Kubernetes的一些理念和基本架构, 然后从网络、
资源管理、存储、服务发现、负载均衡、高可用、rolling upgrade、安全、监控等方面向大家简单介绍Kubernetes的这些主要特性。
当然也会包括一些需要注意的问题。主要目的是帮助大家快速理解 Kubernetes的主要功能,今后在研究和使用这个具的时候有所参考和帮助。
1.Kubernetes的一些理念:
用户不需要关心需要多少台机器,只需要关心软件(服务)运行所需的环境。以服务为中心,你需要关心的是api,如何把大服务拆分成小服务,如何使用api去整合它们。
保证系统总是按照用户指定的状态去运行。
不仅仅提给你供容器服务,同样提供一种软件系统升级的方式;在保持HA的前提下去升级系统是很多用户最想要的功能,也是最难实现的。
那些需要担心和不需要担心的事情。

更好的支持微服务理念,划分、细分服务之间的边界,比如lablel、pod等概念的引入。
对于Kubernetes的架构,可以参考官方文档。
大致由一些主要组件构成,包括Master节点上的kube-apiserver、kube-scheduler、kube-controller-manager、控制组件kubectl、状态存储etcd、Slave节点上的kubelet、kube-proxy,以及底层的网络支持(可以用Flannel、OpenVSwitch、Weave等)。
看上去也是微服务的架构设计,不过目前还不能很好支持单个服务的横向伸缩,但这个会在
Kubernetes 的未来版本中解决。
2.Kubernetes的主要特性
会从网络、服务发现、负载均衡、资源管理、高可用、存储、安全、监控等方面向大家简单介绍Kubernetes的这些主要特性
-> 由于时间有限,只能简单一些了。
另外,对于服务发现、高可用和监控的一些更详细的介绍,感兴趣的朋友可以通过这篇文章了解。
1)网络
Kubernetes的网络方式主要解决以下几个问题:
a. 紧耦合的容器之间通信,通过 Pod 和 localhost 访问解决。
b. Pod之间通信,建立通信子网,比如隧道、路由,Flannel、Open
vSwitch、Weave。
c. Pod和Service,以及外部系统和Service的通信,引入Service解决。
Kubernetes的网络会给每个Pod分配一个IP地址,不需要在Pod之间建立链接,也基本不需要去处理容器和主机之间的端口映射。
注意:Pod重建后,IP会被重新分配,所以内网通信不要依赖Pod IP;通过Service环境变量或者DNS解决。
2) 服务发现及负载均衡
kube-proxy和DNS, 在v1之前,Service含有字段portalip
和publicIPs, 分别指定了服务的虚拟ip和服务的出口机ip,publicIPs可任意指定成集群中任意包含kube-proxy的节点,可多个。portalIp
通过NAT的方式跳转到container的内网地址。在v1版本中,publicIPS被约定废除,标记为deprecatedPublicIPs,仅用作向后兼容,portalIp也改为ClusterIp,
而在service port 定义列表里,增加了nodePort项,即对应node上映射的服务端口。
DNS服务以addon的方式,需要安装skydns和kube2dns。kube2dns会通过读取Kubernetes
API获取服务的clusterIP和port信息,同时以watch的方式检查service的变动,及时收集变动信息,并将对于的ip信息提交给etcd存档,而skydns通过etcd内的DNS记录信息,开启53端口对外提供服务。大概的DNS的域名记录是servicename.namespace.tenx.domain,
"tenx.domain"是提前设置的主域名。
注意:kube-proxy 在集群规模较大以后,可能会有访问的性能问题,可以考虑用其他方式替换,比如HAProxy,直接导流到Service
的endpints 或者 Pods上。Kubernetes官方也在修复这个问题。
3)资源管理
有3 个层次的资源限制方式,分别在Container、Pod、Namespace
层次。Container层次主要利用容器本身的支持,比如Docker 对CPU、内存、磁盘、网络等的支持;Pod方面可以限制系统内创建Pod的资源范围,比如最大或者最小的CPU、memory需求;Namespace层次就是对用户级别的资源限额了,包括CPU、内存,还可以限定Pod、rc、service的数量。
资源管理模型 -》 简单、通用、准确,并可扩展
目前的资源分配计算也相对简单,没有什么资源抢占之类的强大功能,通过每个节点上的资源总量、以及已经使用的各种资源加权和,来计算某个Pod优先非配到哪些节点,还没有加入对节点实际可用资源的评估,需要自己的scheduler
plugin来支持。其实kubelet已经可以拿到节点的资源,只要进行收集计算即可,相信Kubernetes的后续版本会有支持。
4)高可用
主要是指Master节点的 HA方式 官方推荐 利用etcd实现master
选举,从多个Master中得到一个kube-apiserver 保证至少有一个master可用,实现high
availability。对外以loadbalancer的方式提供入口。这种方式可以用作ha,但仍未成熟,据了解,未来会更新升级ha的功能。
一张图帮助大家理解:
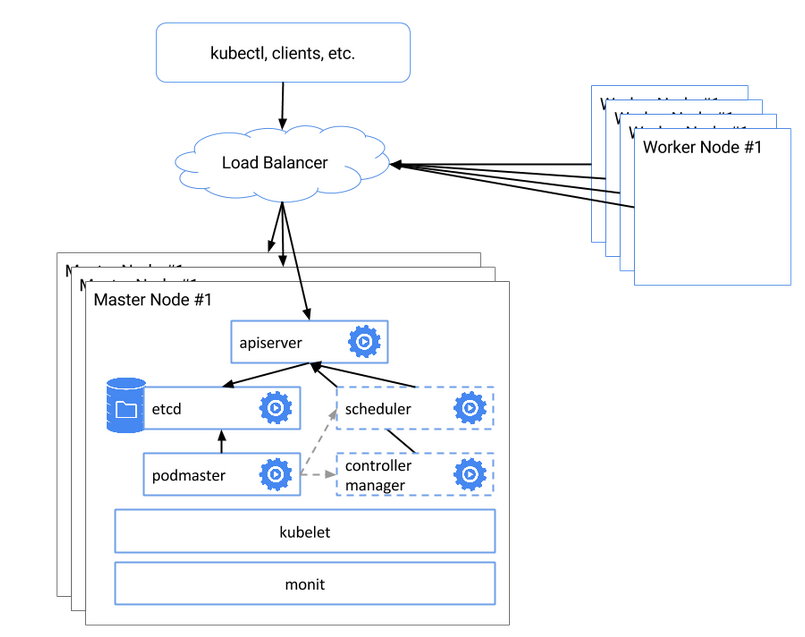
也就是在etcd集群背景下,存在多个kube-apiserver,并用pod-master保证仅是主master可用。同时kube-sheduller和kube-controller-manager也存在多个,而且伴随着kube-apiserver
同一时间只能有一套运行。
5) rolling upgrade
RC 在开始的设计就是让rolling upgrade变的更容易,通过一个一个替换Pod来更新service,实现服务中断时间的最小化。基本思路是创建一个复本为1的新的rc,并逐步减少老的rc的复本、增加新的rc的复本,在老的rc数量为0时将其删除。
通过kubectl提供,可以指定更新的镜像、替换pod的时间间隔,也可以rollback
当前正在执行的upgrade操作。
同样, Kuberntes也支持多版本同时部署,并通过lable来进行区分,在service不变的情况下,调整支撑服务的Pod,测试、监控新Pod的工作情况。
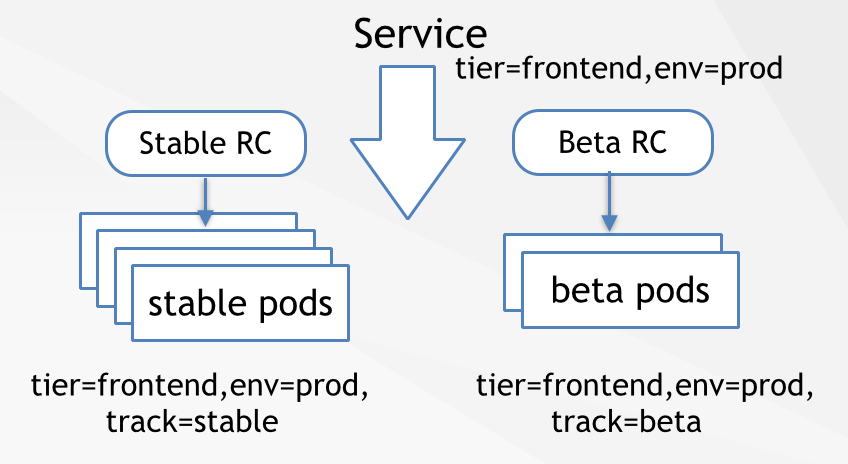
6)存储
大家都知道容器本身一般不会对数据进行持久化处理,在Kubernetes中,容器异常退出,kubelet也只是简单的基于原有镜像重启一个新的容器。另外,如果我们在同一个Pod中运行多个容器,经常会需要在这些容器之间进行共享一些数据。Kuberenetes
的 Volume就是主要来解决上面两个基础问题的。
Docker 也有Volume的概念,但是相对简单,而且目前的支持很有限,Kubernetes对Volume则有着清晰定义和广泛的支持。其中最核心的理念:Volume只是一个目录,并可以被在同一个Pod中的所有容器访问。而这个目录会是什么样,后端用什么介质和里面的内容则由使用的特定Volume类型决定。
创建一个带Volume的Pod:

spec.volumes 指定这个Pod需要的volume信息 spec.containers.volumeMounts
指定哪些container需要用到这个Volume Kubernetes对Volume的支持非常广泛,有很多贡献者为其添加不同的存储支持,也反映出Kubernetes社区的活跃程度。
emptyDir 随Pod删除,适用于临时存储、灾难恢复、共享运行时数据,支持
RAM-backed filesystem hostPath 类似于Docker的本地Volume 用于访问一些本地资源(比如本地Docker)。
gcePersistentDisk GCE disk - 只有在 Google
Cloud Engine 平台上可用。
awsElasticBlockStore 类似于GCE disk 节点必须是
AWS EC2的实例 nfs - 支持网络文件系统。
rbd - Rados Block Device - Ceph
secret 用来通过Kubernetes API 向Pod 传递敏感信息,使用
tmpfs (a RAM-backed filesystem)
persistentVolumeClaim - 从抽象的PV中申请资源,而无需关心存储的提供方
glusterfs
iscsi
gitRepo
根据自己的需求选择合适的存储类型,反正支持的够多,总用一款适合的 :)
7)安全
一些主要原则:
基础设施模块应该通过API server交换数据、修改系统状态,而且只有API
server可以访问后端存储(etcd)。
把用户分为不同的角色:Developers/Project Admins/Administrators。
允许Developers定义secrets 对象,并在pod启动时关联到相关容器。
以secret 为例,如果kubelet要去pull 私有镜像,那么Kubernetes支持以下方式:
通过docker login 生成 .dockercfg 文件,进行全局授权。
通过在每个namespace上创建用户的secret对象,在创建Pod时指定
imagePullSecrets 属性(也可以统一设置在serviceAcouunt 上),进行授权。
认证 (Authentication)
API server 支持证书、token、和基本信息三种认证方式。
授权 (Authorization)
通过apiserver的安全端口,authorization会应用到所有http的请求上
AlwaysDeny、AlwaysAllow、ABAC三种模式,其他需求可以自己实现Authorizer接口。
8)监控
比较老的版本Kubernetes需要外接cadvisor主要功能是将node主机的container
metrics抓取出来。在较新的版本里,cadvior功能被集成到了kubelet组件中,kubelet在与docker交互的同时,对外提供监控服务。
Kubernetes集群范围内的监控主要由kubelet、heapster和storage
backend(如influxdb)构建。Heapster可以在集群范围获取metrics和事件数据。它可以以pod的方式运行在k8s平台里,也可以单独运行以standalone的方式。
注意: heapster目前未到1.0版本,对于小规模的集群监控比较方便。但对于较大规模的集群,heapster目前的cache方式会吃掉大量内存。因为要定时获取整个集群的容器信息,信息在内存的临时存储成为问题,再加上heaspter要支持api获取临时metrics,如果将heapster以pod方式运行,很容易出现OOM。所以目前建议关掉cache并以standalone的方式独立出k8s平台。
DockOne技术分享(十七):360的容器化之路
容器化技术作为“搅局者”,势必面临适配公司已有架构的挑战,本文将为大家介绍360如何让Docker落地。主要包括三方面内容:一,结合公司业务特点,如何使Docker适配现有技术架构
,完成线上环境快速部署扩容;二,“让产品失败的更廉价”,使用Docker构建PaaS环境加速中小业务快速孵化上线;三,使用Docker技术,在构建持续集成环境方面的一些积累。
容器化技术作为“搅局者”,势必面临适配公司已有架构的挑战,本文将为大家介绍360如何让Docker落地。主要包括三方面内容:一,结合公司业务特点,如何使Docker适配现有技术架构
,完成线上环境快速部署扩容;二,“让产品失败的更廉价”,使用Docker构建PaaS环境加速中小业务快速孵化上线;三,使用Docker技术,在构建持续集成环境方面的一些积累。
以Docker为主的容器化技术现在可谓风生水起,大家都觉得它可能会颠覆整个IT格局。我们刚开始接触到Docker的时候也觉得它非常好,有很多优点吸引我们。因为它的颠覆性我们称它为“搅局者”。
改造“搅局者”Docker
我们先来看看这位搅局者的优点:
Namespace、CGroups虚拟化, 相比传统虚拟化会有更好性能,反映在生产环境中就是能更大程度的利用资源。
启动速度快,虚拟机最快也得30秒-1分钟,它的启动创建都是秒级。
镜像分层技术,解决了快速变更环境的问题。
这些优点很吸引我们,我们非常希望把它用在生产环境中,但是我们发现理想很美好,现实很残酷。我们之前基础架构都是使用传统虚拟机化技术就是虚拟机。
我们要使用Docker就会面临这几个问题 :
不能SSH,紧急问题怎么排查?
怎么监控?
基础服务如何对接?
最重要的问题: 这东西稳定么,线上业务当然不能出问题。
所以,在应用Docker的时候,我们犯了犹豫,因为按照它推荐的方式,我们无法直接立马就在线上业务使用。因为Docker本身也对业务的架构设计有一定要求,比如我们常说的容器无状态,容器中不要留中间数据。我们发现公司的业务架构改造起来困难很大,涉及到方方面面,所以我们决定要Docker去适应公司的架构。
接下来我们就是要解决Docker技术”落地”的问题。
我们对Docker改造点主要有:
容器内部绑定独立IP。
容器内部开启多进程服务。
自动添加监控。
CPU配额硬限制。
容器绑定独立IP这样外部可直接SSH了。
我们考虑在容器内部运行多个进程服务,因为默认容器只开启一个进程,这无法满足我们要求,所以我们大胆进行了改造。我们甚至在镜像里实现了chkconfig让以前的RPM包原生可用。
自动添加监控让创建的容器自动添加到Zabbix中。CPU配额硬限制 Docker
1.7版本已经支持了,我们在这之前自己实现了一套。
改造Docker支持这些功能后,我们又开发了一套调度系统,负责管理调度在集群上如何创建容器,我们也调研了一些开源的调度系统,发现都不满足需求,所以自己开发了一套。
通过这些手段我们就可以让Docker技术“落地”了,而带来的好处是,之前的体系我们要上线新的业务大约需要40分钟,使用Docker缩短到了5分钟。
这是分享的第一部分因为“搅局者”Docker使用遇到了困境,所以我们对它进行了一些改造,更好适配公司场景,让技术“落地”。
基于Docker做一个内部PaaS平台
紧接着我们基于Docker做了一个内部PaaS平台。公司每天会上线很多业务,这些业务有些是体量很大的重要业务,有些是带有试错性质的小业务。
传统业务上线的步骤会非常得严谨,流程会比较长,这些流程其实也对业务稳定性会有保障。有些试错性质的小业务,使用同样的流程变得不太合适,所以我们就想加速小业务上线流程,让他们可以快速上线,验证自己得价值。基于这种考虑,而且Docker天生的特点就特别适合干这个。
这是界面的一个截图,主要是前端Web UI去访问一个调度层 ,调度层通过调用Docker
API来创建容器。目前PaaS平台支持PHP、Node.js、Python、Java等语言。
除了创建容器,我们还需要,创建Git仓库、配置访问代理等,总之研发一键就可以让业务进入待上线状态,只要他传完代码就可以上线了。
目前这个平台跑了300+业务,让很多研发只要有一个idea,就可以快速实施上线,很受他们欢迎。
这也是我们应用Docker的第二部分,通过私有PaaS平台,加速业务孵化。
关于持续集成
第三部分是关于持续集成。
持续集成当然是Docker最纯粹的玩法了,通过『Dockerfile-构建镜像-创建新容器』来完成环境的变更。
这块比较复杂,我们大致分了9个模块,比如调度模块、监控模块、存储模块等。
首先我们做了一个配置转换模块来转换Dockerfile,这样即可以统一镜像构建标准,同时也降低了编写Dockerfile的学习成本。
调度模块就直接用的Mesos和Marathon,镜像Registry直接使用了
Registry V2因为它性能更好对高并发支持也很好,最后是镜像构建模块,使用的是Jenkins CI。
但是我们发现一个问题:镜像构建在高并发下其实并不快。 比如装一个RPM包,SSH肯定会比重新build快得多。所以我们做了很多优化在镜像构建这一块,现在结果是100个任务同时构建我们也能达到和传统集群管理如Puppet一样的效率。
DockOne技术分享(十八):Flannel What&How
Flannel是 CoreOS 团队针对 Kubernetes 设计的一个覆盖网络(Overlay
Network)工具,其目的在于帮助每一个使用 Kuberentes 的 CoreOS 主机拥有一个完整的子网。这次的分享内容将从Flannel的介绍、工作原理及安装和配置三方面来介绍这个工具的使用方法。
第一部分:Flannel介绍
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
在Kubernetes的网络模型中,假设了每个物理节点应该具备一段“属于同一个内网IP段内”的“专用的子网IP”。例如:
节点A:10.0.1.0/24
节点B:10.0.2.0/24
节点C:10.0.3.0/24 |
但在默认的Docker配置中,每个节点上的Docker服务会分别负责所在节点容器的IP分配。这样导致的一个问题是,不同节点上容器可能获得相同的内外IP地址。并使这些容器之间能够之间通过IP地址相互找到,也就是相互ping通。
Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
第二部分:Flannel的工作原理
Flannel实质上是一种“覆盖网络(overlay network)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持UDP、VxLAN、AWS
VPC和GCE路由等数据转发方式。
默认的节点间数据通信方式是UDP转发,在Flannel的GitHub页面有如下的一张原理图:
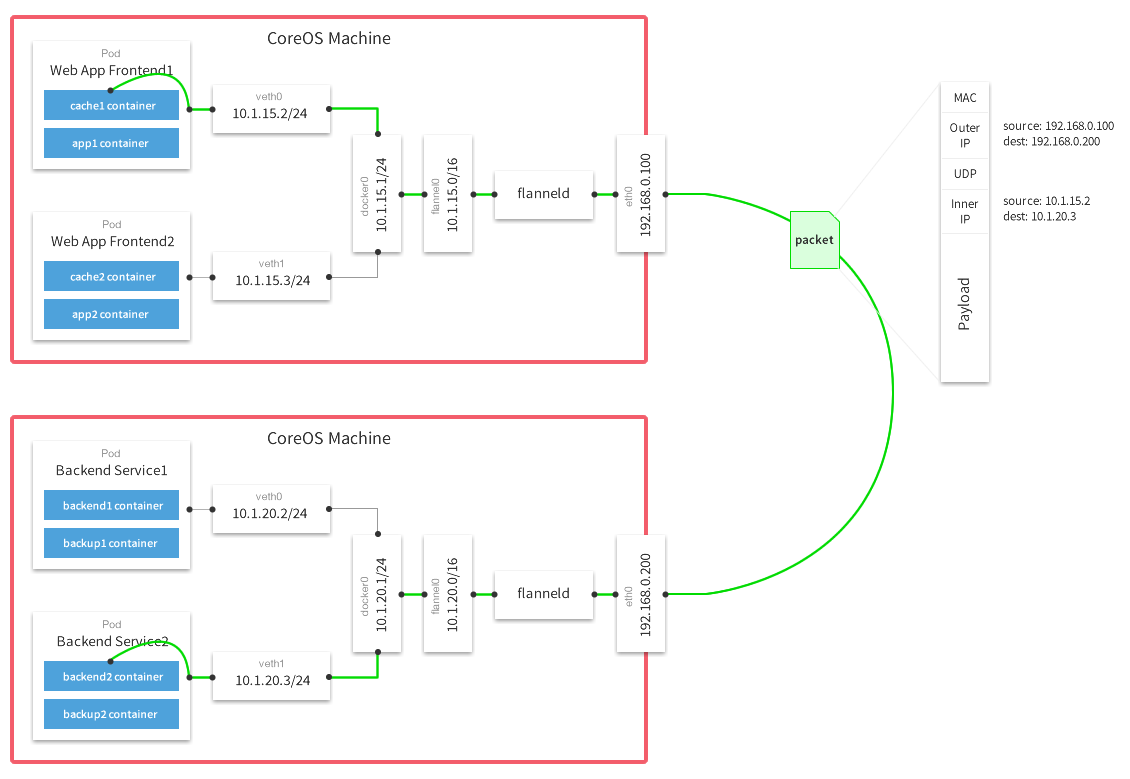
这张图的信息量很全,下面简单的解读一下。
数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
Flannel通过Etcd服务维护了一张节点间的路由表,在稍后的配置部分我们会介绍其中的内容。
源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一下的有docker0路由到达目标容器。
这样整个数据包的传递就完成了,这里需要解释三个问题。
第一个问题,UDP封装是怎么一回事?
我们来看下面这个图,这是在其中一个通信节点上抓取到的ping命令通信数据包。可以看到在UDP的数据内容部分其实是另一个ICMP(也就是ping命令)的数据包。

原始数据是在起始节点的Flannel服务上进行UDP封装的,投递到目的节点后就被另一端的Flannel服务还原成了原始的数据包,两边的Docker服务都感觉不到这个过程的存在。
第二个问题,为什么每个节点上的Docker会使用不同的IP地址段?
这个事情看起来很诡异,但真相十分简单。其实只是单纯的因为Flannel通过Etcd分配了每个节点可用的IP地址段后,偷偷的修改了Docker的启动参数,见下图。

这个是在运行了Flannel服务的节点上查看到的Docker服务进程运行参数。
注意其中的“--bip=172.17.18.1/24”这个参数,它限制了所在节点容器获得的IP范围。
这个IP范围是由Flannel自动分配的,由Flannel通过保存在Etcd服务中的记录确保它们不会重复。
第三个问题,为什么在发送节点上的数据会从docker0路由到flannel0虚拟网卡,在目的节点会从flannel0路由到docker0虚拟网卡?
我们来看一眼安装了Flannel的节点上的路由表。下面是数据发送节点的路由表:
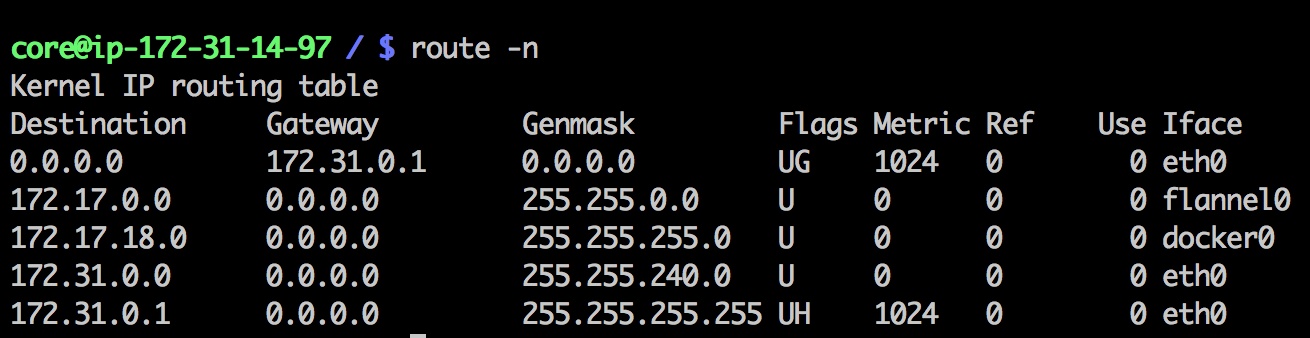
这个是数据接收节点的路由表:
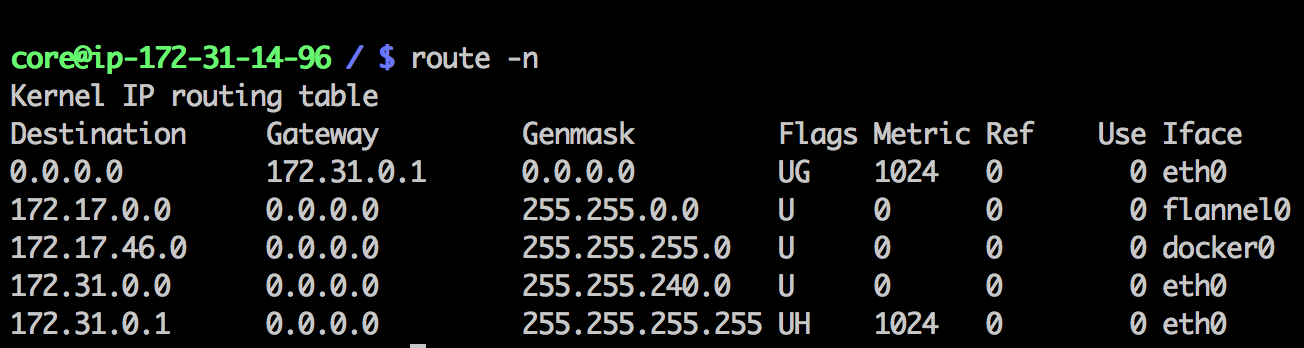
例如现在有一个数据包要从IP为172.17.18.2的容器发到IP为172.17.46.2的容器。根据数据发送节点的路由表,它只与172.17.0.0/16匹配这条记录匹配,因此数据从docker0出来以后就被投递到了flannel0。同理在目标节点,由于投递的地址是一个容器,因此目的地址一定会落在docker0对于的172.17.46.0/24这个记录上,自然的被投递到了docker0网卡。
第三部分:Flannel的安装和配置
Flannel是Golang编写的程序,因此的安装十分简单。
从https://github.com/coreos/flannel/releases和https://github.com/coreos/etcd/releases分别下载Flannel和Etcd的最新版本二进制包。
解压后将Flannel的二进制文件“flanneld”和脚本文件“mk-docker-opts.sh”、以及Etcd的二进制文件“etcd”和“etcdctl”放到系统的PATH目录下面安装就算完成了。
配置部分要复杂一些。
首先启动Etcd,参考https://github.com/coreos/etcd ... overy。
访问这个地址:https://discovery.etcd.io/new?size=3 获得一个“Discovery地址”
在每个节点上运行以下启动命令:
etcd -initial-advertise-peer-urls http://<当前节点IP>:2380 -listen-peer-urls
http://<当前节点IP>:2380 -listen-client-urls http://<当前节点IP>:2379,
http://<当前节点IP>:2379 -advertise-client-urls
http://<当前节点IP>:2379 -discovery <刚刚获得的Discovery地址> & |
启动完Etcd以后,就可以配置Flannel了。
Flannel的配置信息全部在Etcd里面记录,往Etcd里面写入下面这个最简单的配置,只指定Flannel能用来分配给每个Docker节点的拟IP地址段:
etcdctl set /coreos.com/network/config '{ "Network": "172.17.0.0/16" }' |
然后在每个节点分别启动Flannel:
最后需要给Docker动一点手脚,修改它的启动参数和docker0地址。
在每个节点上执行:
sudo mk-docker-opts.sh -i
source /run/flannel/subnet.env
sudo rm /var/run/docker.pid
sudo ifconfig docker0 ${FLANNEL_SUBNET} |
重启动一次docker,这样配置就完成了。
现在在两个节点分别启动一个docker容器,它们之间已经通过IP地址直接相互ping通了。
到此,整个Flannel集群也就正常运行了。
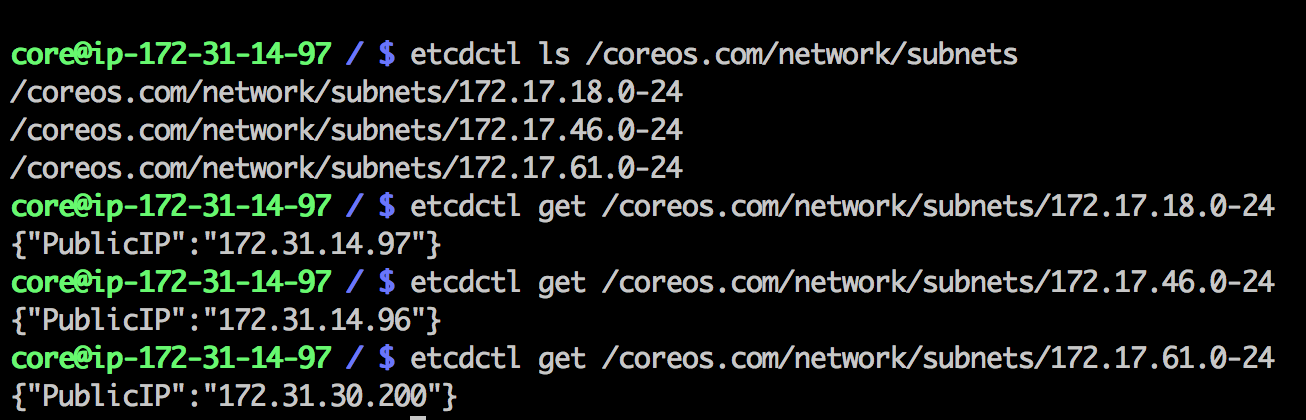
最后,前面反复提到过Flannel有一个保存在Etcd的路由表,可以在Etcd数据中找到这些路由记录,如下图。
|






