|
DockOne技术分享(八):OpenStack Magnum社区及项目介绍
今天主要跟大家简单介绍下Magnum社区和Magnum项目的一些介绍。Magnum到现在为止,功能做的其实不是很多,希望通过这次机会能和大家多多讨论下,看看怎样让Magnum提供更好的容器服务。
1.Magnum社区
Mangum现在应该是OpenStack里边比较热门的一个和Docker集成的新项目。Magnum是去年巴黎峰会后开始的一个新的专门针对Container的一个新项目,用来向用户提供容器服务。从去年11月份开始在stackforge提交第一个patch,今年3月份进入OpenStack
namespace,这个项目应该是OpenStack社区从stackforge迁移到OpenStack
namespace最快的一个项目。Magnum现在可以为用户提供Kubernetes as a Service、Swarm
as a Service和这几个平台集成的主要目的是能让用户可以很方便的通过OpenStack云平台来管理k8s,swarm,这些已经很成型的Docker集群管理系统,使用户很方便的使用这些容器管理系统来提供容器服务。
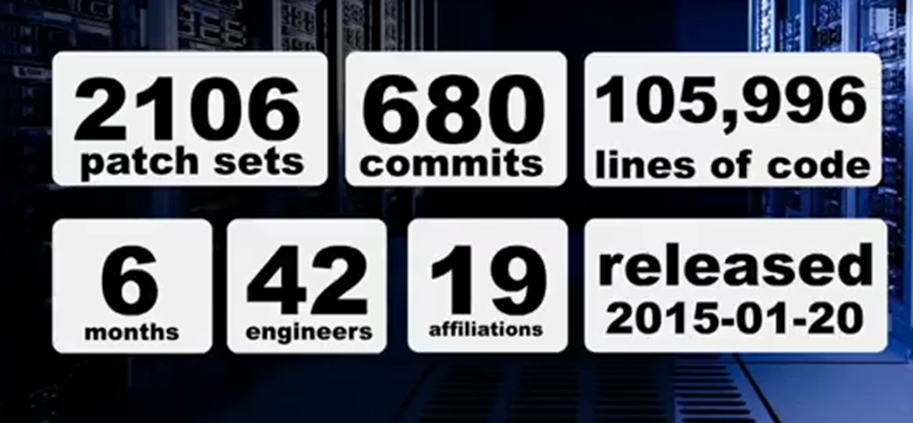
通过这个图主要是想强调下,就是Magnum社区现在发展很迅速,大家可以看一下patch
set和commit的对比,基本上平均三个patch set就会产生一个commit,所以希望对Docker感兴趣的人,可以参与到Magnum的开发中来。
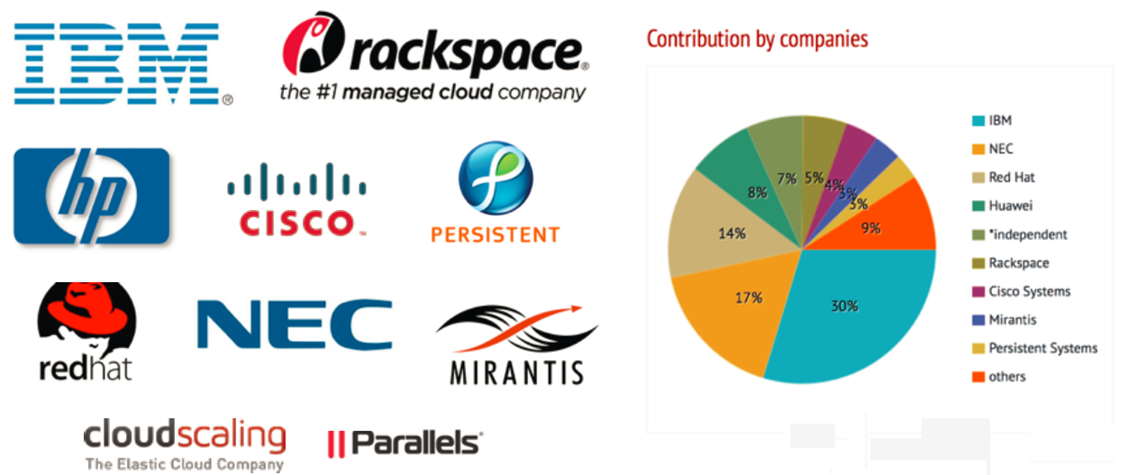
这一页是Magnum社区的一些情况,主要列出了一些为Magnum做贡献的公司,包括IBM、Rackspace、hp、cisco等等,IBM目前在这个项目排第一位。
通常情况下,一个公司对哪些项目比较看重,或者它对OpenStack社区的最近的一些策略,都可以通过分析每个公司对OpenStack的贡献来得到一定的结论。如果某个公司在某个项目贡献比较多的话,可能就意味着这个公司会在相关领域有一些动作。大家如果感兴趣的话,可以通过http://stackalytics.com/去研究一下自己感兴趣的公司最近在OpenStack的一些动态。
在这简单介绍下Magnum的一些主要Contributor,Adrian
Otto是Rackspace的杰出工程师,Magnum和Solum的双重PTL;Steven Dake刚刚从RedHat加入Cisco,他是Heat的创始人之一,现在Kolla的PTL,同时还在积极推动一个新项目Machine
Learning-As-A-Service;Davanum Srinivas (dims)刚刚从IBM加入Mirantis,现在担任Oslo的PTL。
2. Why Magnum
接下来我们看下为什么需要Magnum、OpenStack现在和Docker集成现在主要有三块,包括nova
Docker driver,heat Docker driver和Kilo推出的Magnum,当然还包含一些别的项目,例如Sahara,Murano,Kolla,Solum等等。
2.1 Nova Docker driver
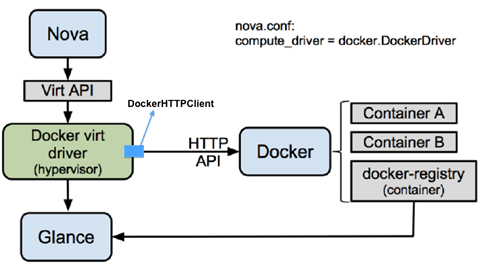
上图是nova Docker driver,这个driver是OpenStack和Docker的第一次集成,相信对Docker和OpenStack感兴趣的人,应该都用过这个driver
这个driver的话,主要是把把Docker作为一种新的Hypervisor来处理,把所有的container当成vm来处理。提供了一个Docker的nova
compute driver。我不知道@Gnep@北京-VisualOp 的Hyper是不是可以考虑先弄个driver试试,我们待会可以讨论。
这个driver的优点是实现比较简单,只需要把nova compute中的一些对虚拟机操作的常用接口实现就可以,现在主要支持创建,启动,停止,pause,unpause等虚拟机的基本操作。
另外一个是因为nova Docker driver也是一个nova的compute driver,所以他可以像其他的compute
driver一样使用OpenStack中的所有服务,包括使用nova scheduler来做资源调度,使用heat来做应用部署,服务发现,扩容缩容等等,同时也可以通过和neutron集成来管理Docker网络。也支持多租户,为不同的租户设置不同的quota,做资源隔离等等。IBM现在的SuperVessel
Cloud使用的就是这个Driver。
他的缺点也很明显,因为Docker和虚拟机差别也挺大的,Docker还有一些很高级的功能是VM所没有的,像容器关联,就是使不同容器之间能够共享一些环境变量,来实现一些服务发现的功能,例如k8s的pod就是通过容器关联来实现的。另外一个是端口映射,k8s的pod也使用了端口映射的功能,可以把一个pod中的所有container的port都通过net
container export出去,便于和外界通信。还有一个是不同网络模式的配置,因为Docker的网络模式很多,包括host模式,container模式等等,以上的所有功能都是nova
Docker driver不能实现的。
2.2 Heat Docker Driver
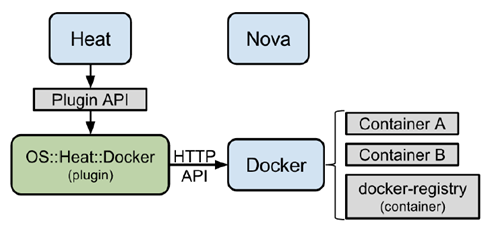
上图是heat Docker driver,因为nova Docker driver不能使用Docker的一些高级功能,所以社区就想了另一个方法,和heat去集成,因为heat采用的也是插件模式,所以就在heat实现了一个新的resource,专门来和Docker集成。这个heat插件是直接通过rest
api和Docker交互的,不需要和nova、cinder、neutron等等来进行交互。
所以这个driver的优点是首先它完全兼容Docker的api,因为我们可以在heat template里边去定义我们关心的参数,可以实现Docker的所有高级功能,用户可以在heat
template定义任意的参数。另外因为和heat集成了,所以默认就有了multi tenat的功能,可以实现不同Docker应用之间的隔离。
但是他的缺点也非常明显,因为他是heat直接通过rest api和Docker交互的,所以heat
Docker driver没有资源调度,用户需要在template中指定需要在哪一台Docker服务器上去部署应用,所以这个driver不适合大规模应用,因为没有资源调度。另外因为没有和neutron去交互,所以网络管理也只能用Docker本身的网络管理功能,没有subnet,网络隔离也做得不是太好,需要依赖于用户手动配置flannel或者ovs等等
3. Magnum简介
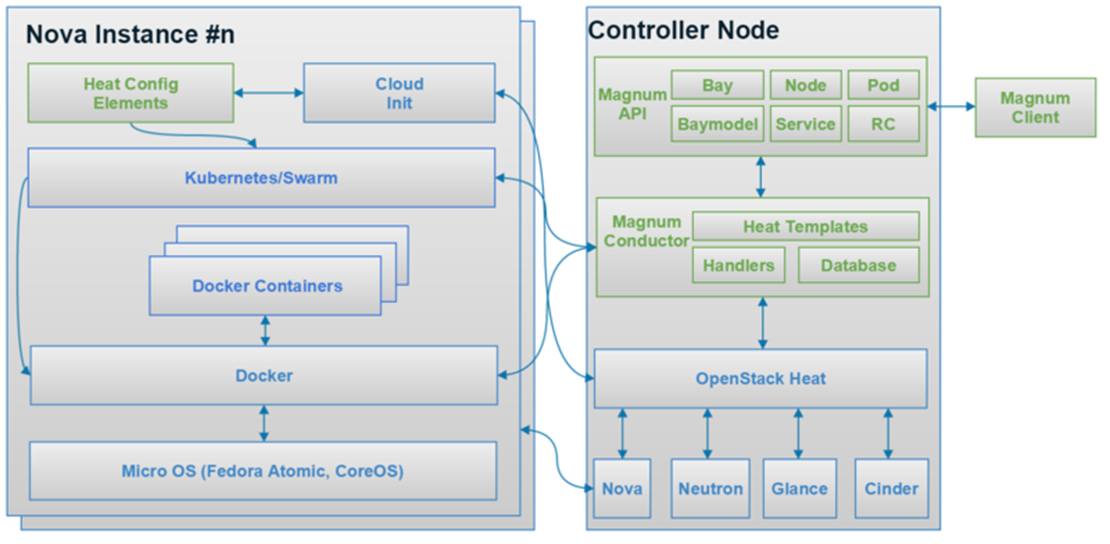
所以社区就推出了Magnum这个项目。上图是Magnum的一个架构图。
3.1 Magnum主要概念
它的结构其实很简单,首先我们看下magnum的主要概念,在这个图的右边,主要有这么几个:Bay、Baymodel、Node、Pod、Service、RC、Container。
Bay:bay在magnum主要表示一个集群,现在通过magnum可以创建k8s和swarm的bay,也就是k8s和swarm的集群。
Baymodel:baymodel是flavor的一个扩展,flavor主要是定义虚拟机或者物理机的规格,baymodel主要是定义一个Docker集群的一些规格,例如这个集群的管理节点的flavor,计算节点的flavor,集群使用的image等等,都可以通过baymodel去定义。
Node主要是指Bay中的某个节点。
Container就是具体的某个Docker容器。
Pod, Replication Controller和Service的意思和在k8s的意思是一样的。在这简单介绍下这三个概念。
Pod是Kubernetes最基本的部署调度单元,可以包含多个container,逻辑上表示某种应用的一个实例。比如一个web站点应用由前端、后端及数据库构建而成,这三个组件将运行在各自的容器中,那么我们可以创建包含三pod,每个pod运行一个服务。或者也可以将三个服务创建在一个pod,这个取决于用户的应用需求。一个pod会包含n
1个container,多出来的那一个container是net container,专门做路由的。
Service:可以理解为是pod的一个路由,因为pod在运行中可能被删除或者ip发生变化,service可以保证pod的动态变化对访问端是透明的。
Replication Controller:是pod的复制抽象,用于解决pod的扩容缩容问题。通常,分布式应用为了性能或高可用性的考虑,需要复制多份资源,并且根据负载情况动态伸缩。通过replicationController,我们可以指定一个应用需要几份复制,Kubernetes将为每份复制创建一个pod,并且保证实际运行pod数量总是与预先定义的数量是一致的(例如,当前某个pod宕机时,自动创建新的pod来替换)。
3.2 Magnum主要服务
接下来看下magnum中的主要服务,现在主要有两个服务,一个是magnum-api,一个是magnum-conductor。具体如上图所示。
Magnum-api和其它的项目的api的功能是一样的,主要是处理client的请求,将请求通过消息队列发送到backend,在magnum,后台处理主要是通过magnum-conductor来做的。
magnum现在支持的backend有k8s,Swarm,Docker等等,Magnum
conductor的主要作用是将client的请求转发到对用的backend,backend在Magnum的官方术语叫CoE(Container
Orchestration Engine)
3.3 Magnum工作流程
第一步需要创建baymodel,就是为需要提供容器服务的bay创建一些集群的定义规格。
第二步就可以在第一步创建的baymodel基础上创建bay了,用户可以选择使用Kubernetes或者Swarm,未来还会有Mesos。
第三步,当bay创建完成后,用户就可以通过调用Magnum API和后台的k8s或者swarm交互来创建container了
3.4 Magnum Notes
另外想强调一下,Magnum现在没有调度模块,因为现在支持的CoE有Swarm和Kubernetes,所以对Container的调度,完全是通过Kubernetes和Swarm本身的调度器来工作的,Magnum只是负责将用户创建container的请求进行转发,转发到对应的CoE,最终的请求由具体的backend去调度。
Magnum现在也支持对Docker进行管理,但是因为没有调度,目前建议对Docker的管理通过Swarm
Bay来进行管理,因为Swarm是Docker官方的Docker集群管理工具。
Magnum现在还支持Multi tenant,每个租户可以有自己的bay,baymodel,pod,service,rc等等,这样可以保证不同租户的资源隔离。每个租户只能看到和操作属于自己的资源。
Magnum现在本身不管理Docker的网络,都是通过上层的CoE自己去管理的,例如Kubernetes的bay现在通过flannel去管理,其实用的还是tunnel技术。
3.5 Magnum Bay
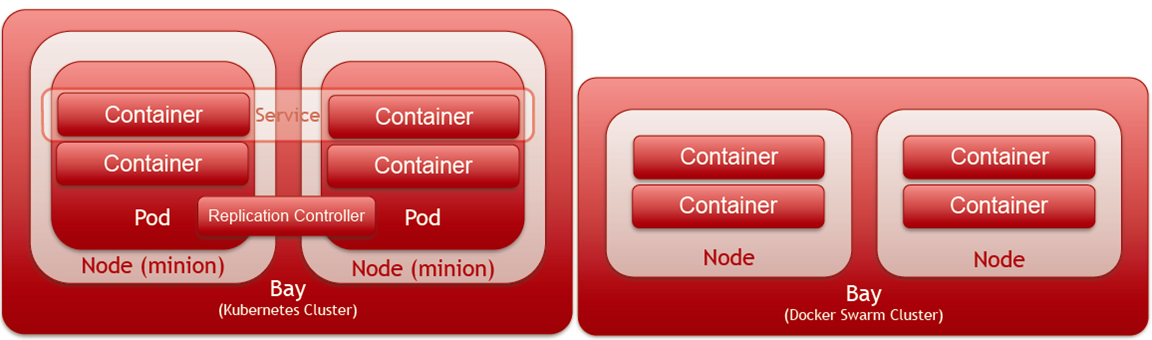
上图是Magnum目前支持的两个bay,Kubernetes和Swarm,Bay创建完成后,可以直接通过Magnum
API和Kubernetes或者Swarm交互创建container。Magnum现在自己通过swagger实现了一套kubernetes
api,magnum通过kubernetest的rest api来和后台的kubernetes交互。
3.6 Magnum Roadmap
3.6.1网络
第一个是网络,网络永远是热门话题,不管是在哪次峰会,现在Magnum也碰到了同样的问题:Container的网络怎样管理,现在主要是通过Kubernetes依赖于overlay
network的flannel来管理,但是因为flannel的性能和扩展性的问题,Magnum社区正在讨论对网络方面进行改进,例如和libnetwork或者neutron集成。这个bp在这https://blueprints.launchpad.net/magnum/
spec/native-Docker-network,非常欢迎对Docker网络感兴趣的人参与讨论及实现。Magnum现在非常需要对网络比较熟的人来共同推动这个bp。我现在在调查libnetwork,看能不能在Magnum去使用。
3.6.2 Mesos支持
另外一个是因为现在能够提供容器服务的工具很多,Mesos也是比较流行的一个,所以Magnum正在计划把Mesos集成进来,提供容器服务。这个bp在这https://blueprints.launchpad.net/magnum/
spec/mesos-bay-type 第一版的Mesos支持,会是Mesos Marathon这样一个组合。因为如果不依赖一个framework的话,mesos很难去使用。
3.6.3 Magnum界面
还有就是Magnum打算在L版做一个GUI界面,让用户更简单的使用Magnum。现在这个bp正在review
https://review.OpenStack.org/#/c/188958/
3.7 使用Magnum
3.7.1 检查所有Baymodel
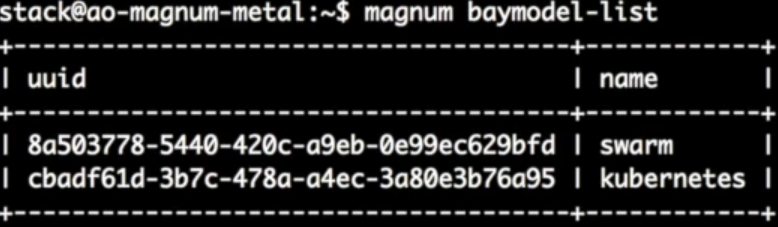
首先是通过命令”Magnum baymodel-list”查看Magnum中现在的所有的baymodel,可以看到现在主要有两个OOB的baymodel:kubernetes和swarm
3.7.2 查看Baymodel详细信息
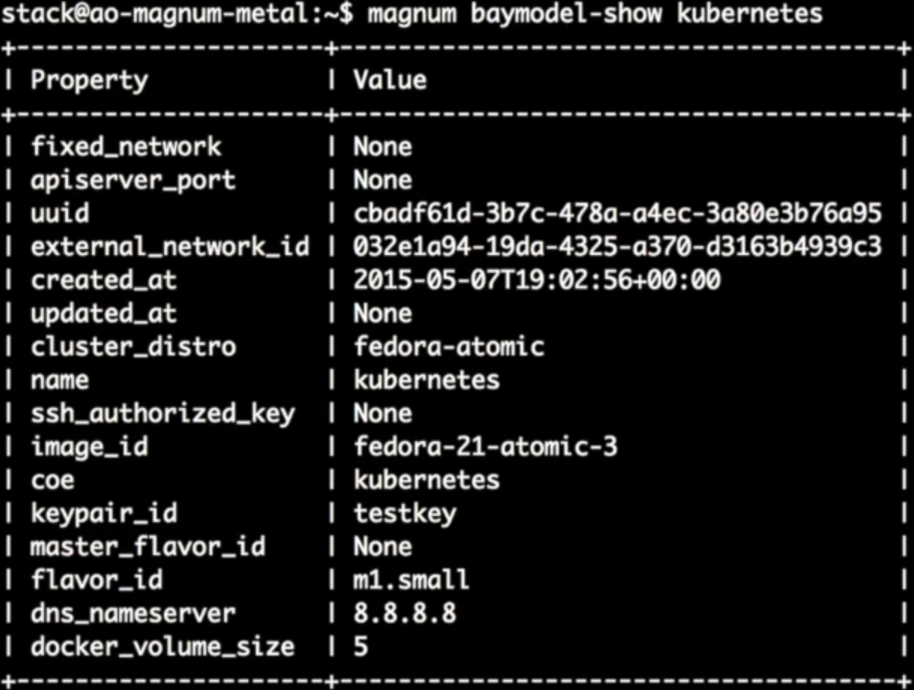
通过“baymodel-show”查看Kubernetes Baymodel的详细信息
3.7.3 创建Kubernetes Bay
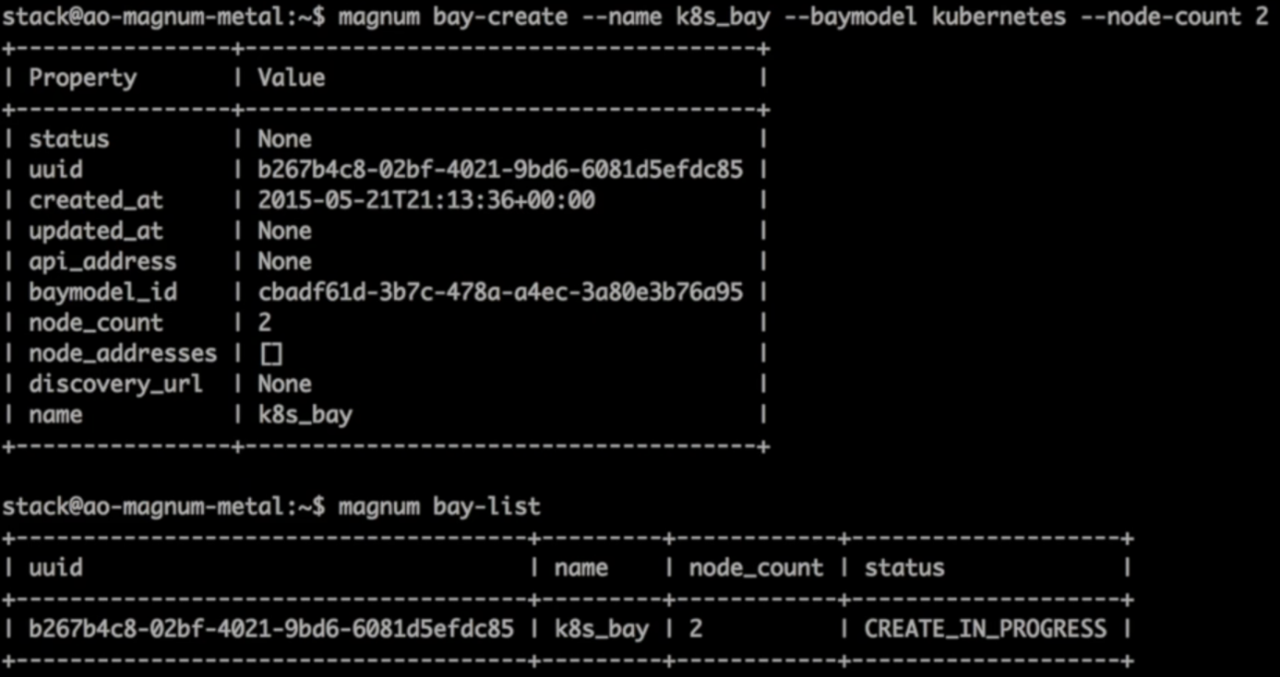
通过“bay-create”创建了一个有两个minions节点的kubernetes
bay
3.7.4 检查Kubernetes Bay拓扑结构
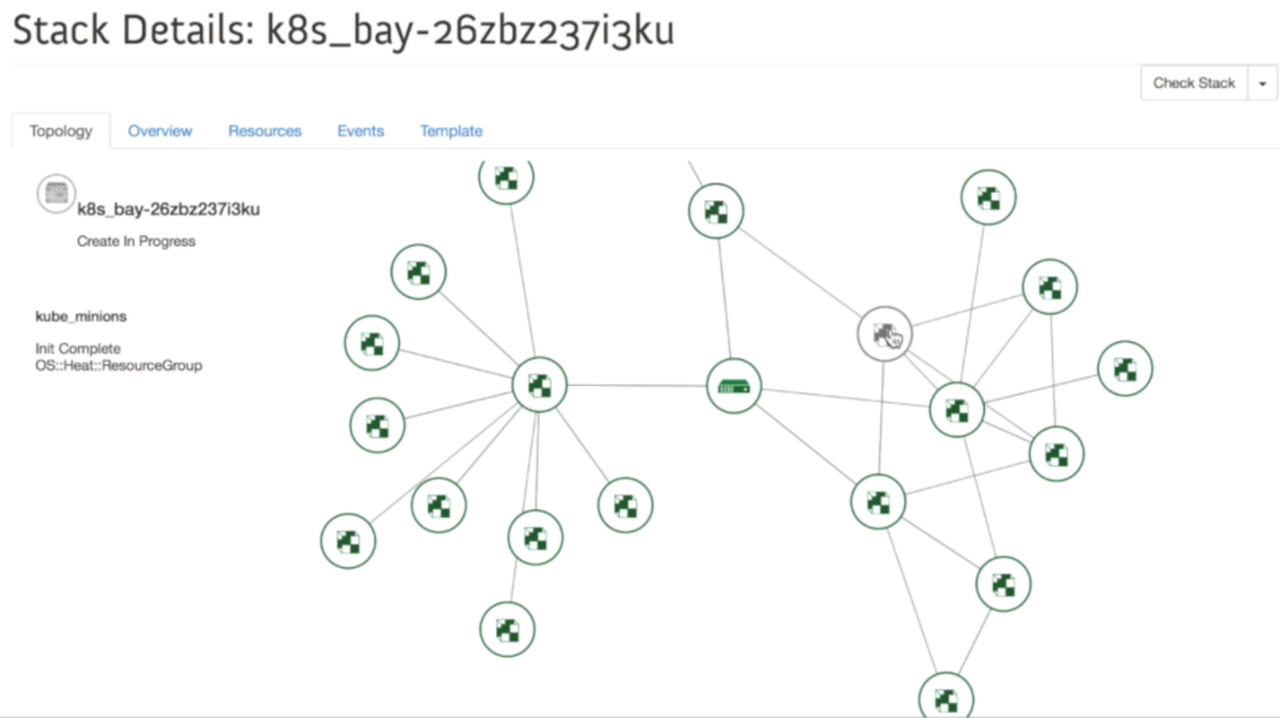
因为Kubernetes的bay实际上是heat的一个stack,所以创建后,可以通过horizon查看stack拓扑结构的显示,从这里边可以看到heat创建kubernetes
bay的所有对象。
3.7.5 检查Magnum Bay

我们可以通过bay-list查看bay的状态,从这个图可以看到Kubernets
Bay已经创建完成了
3.7.6创建Kubernetes Pod
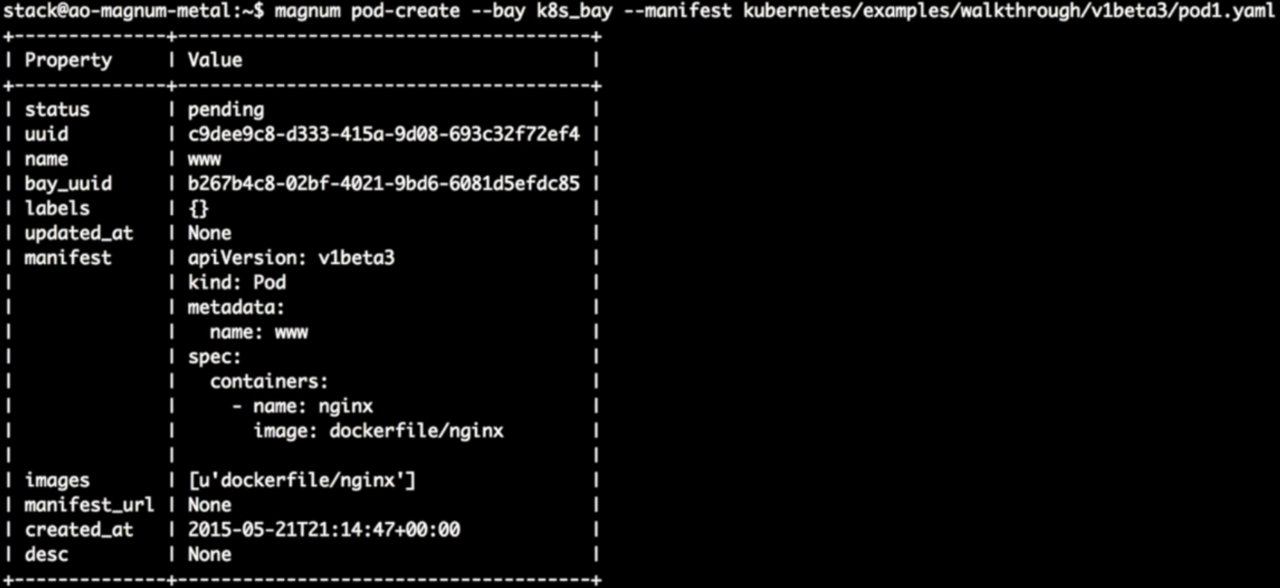
在Kubernetes bay的基础上通过“pod-create”创建一个nginx
pod,在这主要是通过Magnum的命令行创建这个pod。
3.7.7检查Kubernetes Pod
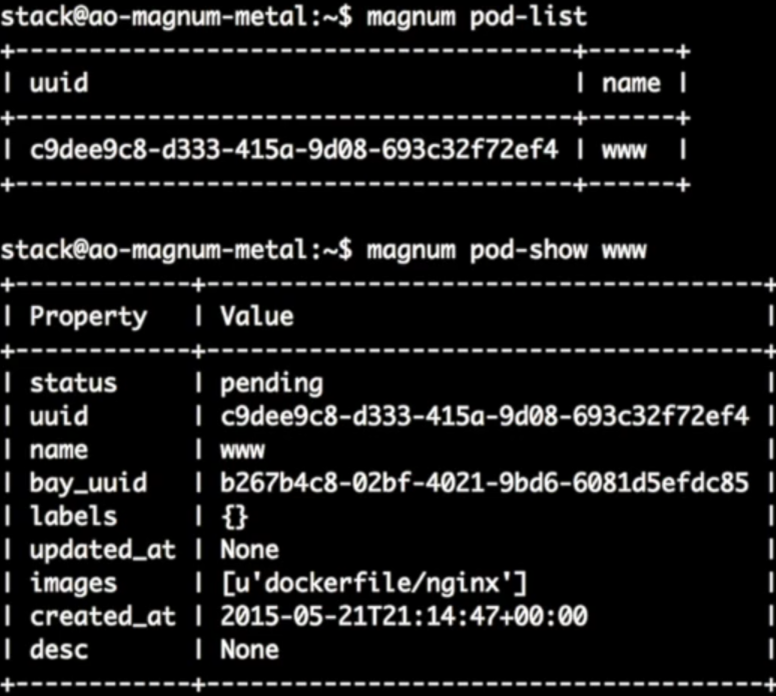
创建完成后,可以通过Magnum “pod-list”,“pod-show”来查看pod状态
3.7.8 Swarm相关
我们可以用同样的方法来创建swarm的bay,通过swarm的bay来提供container
service。
DockOne技术分享(九):持续集成和“云”
今天的话题是,持续集成和“云”,主要部分是我之前两年的工作和我的一些个人思考。
这个话题我之前在中国的ruby大会上讲过,slides在这里 ,供参考,不过但是现在讲的内容根据最近多半年的工作进展又有所变化。
先自我介绍一下,我是软件工程师,从业13年,主要从事的领域都是应用系统开发,涉及OA、电信网管/增值业务、互联网等领域。
2009年底加入阿里,2015年4月离职,主要做的事情:广告应用系统 -> 运维自动化平台 ->
持续集成服务平台。
最后的持续集成服务平台是来自于实践需要,我最先在做广告业务系统的研发工作,广告系统虽然复杂,但是其中的应用系统从软件架构上看并没有什么特别的地方,所以希望将精力投在可以改进团队工作水平的地方。
一开始是一个运维自动化平台,由于团队人手有限,我基本是一个人做的,发现开发效率很好,软件质量也不错,所以在工作中总结了一些质量改进的实践,在团队中推广,这是我从研发进入QA的起点。
经过一段时间摸索,我们发现测试自动化搞不起来的原因之一是成本太高。
我之前习惯用ruby或者rails,所有的测试都可以单机完成,用cucumber这样的工具可以做BDD,用vagrant可以避免环境污染,所以自动化没问题。而java就没有这些条件了,数据库掌握在DBA手里,测试的linux是大家公用的,很容易引起冲突。
于是我和主管商量,决定搞一个平台,通过它降低研发成本,在本团队开展一段时间以后,又带着系统转到技术质量部,把CISE做大,测试部门成立了专门的团队,离职前已经开始在各bu和研发团队广泛运用
对CI的理解
持续集成平台究竟解决什么问题呢?
简单说,就是两个自动化:
构建自动化
测试自动化
测试自动化好理解,构建自动化比想象中要复杂一些,我一般用下面这张图来解释――
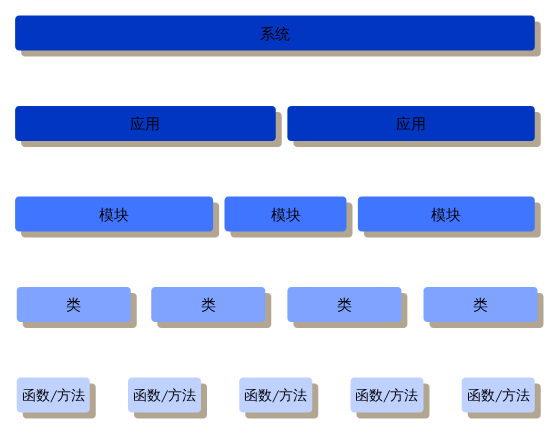
我们手里的软件,总是可以进行不断地分解,从系统到模块,最后到类和方法。由于整体和部分的功能不能完全划等号,所以测试需要在各个层面上进行,但是这些测试的成本和收益有所不同。

如图,我之前感到java开发的痛苦,就源于工程师手中没有更上层的“武器”,所以只能在单测上用力。
所以,如果我们能做好更大尺度系统的自动化的构建,那么研发人员也就有机会使用“高层”的自动化测试,而避免在细节上写太多的用例。
但这个并不容易,我们的努力也只是起到了一部分作用。
平台介绍
下面说一下这个平台本身,由于涉及到阿里巴巴内部系统,有些是不能说的,不过还好,核心部分并没啥技术含量
:-)
很多人对CI的了解是基于jenkins,当然也有些人接触过travis CI或者circle CI,我们的系统更像后者,当然功能上要更强些。
平台的起点是公司的gitlab和svn服务,通过自动监控或者hook触发,每一次代码提交都会触发一个自动化过程,在这个过程中,平台负责分配虚拟机、数据库等必要资源,然后将代码编译打包构建运行。
编译打包构建运行看起来是一个自动化过程,但每个环节实际上都可以有验证――这其实就是各种测试。
编译前可以做代码扫描(有的语言是编译后做代码扫描)
编译之后可以做单测
打包运行后可以做集成测试
......
和travis不同的是,如果目标涉及多个应用,之间存在服务调用,那么我们还会自动的将相关应用也部署好,然后在一个机器群里面做更接近真实场景的功能测试。
做过类似工作的同学一定知道这一点的代价有多大,但这样会有很大好处――我们可以在一次commit后自动进行所有层面的测试――从单测到系统交付测试。
当然这是理论上的,实际中可以根据研发团队需要进行选择。
总结一下,我们认为,CI平台应该能进行所有粒度的测试,最小针对函数,最大可以针对分布式系统。作为前提,CI平台需要支持整个系统的自动化构建。
这个大概是和travis CI之间最大的不同,下面再列几个不是很重要的区别。
使用云平台解决虚机问题,身在阿里巴巴,所以我们使用阿里云的ECS,需要资源是随时申请,用过以后立即释放重置。
这样可以解决环境污染的问题(即使是java应用,有些团队也会留下本地文件操作,这些东西会导致测试不可重复)。
数据库自动分配,我们构建了mysql集群,不过不是一般意义上的那种协作集群,而是一个数据库池,让数据库和虚机一样随用随取,用后重置。
这样做是为了让java程序员也可以像rails的db migration一样可以用到干净的数据库。
对这个平台的介绍就这些,下面讨论一些经验教训。
经验教训
UI应该尽量轻
这个话题要和jenkins/hudson做对比,这两个系统我其实不是很熟,不过也知道它们都是很强大的自动化系统。但是,jenkins/hudson的最大问题是,它们的UI做的太多了,用户可以在UI上做很多事――很多和CI没关系的事情。
举个例子:
jenkins的任务是可以排队调度的,而对于CI来说,排队是什么意思呢?研发工程师养成持续小步提交代码这个好习惯以后,又硬生生由于资源不足而被迫等待,最终可能会放弃这个好习惯,实在是不划算。
我们的办法是――敞开供应,只要有代码提交就分配机器,当然有人会质疑,因为这会导致需要一个很大的资源后备池,不过这可能正是“云”时代的不同思考方式――在“云”的时代,资源的使用毛刺应该通过大规模后备池来抹平。
当然,滥用资源还是要避免的,只是我们认为需要“后置惩罚”,比如通过审计,找出资源消耗大户,打他的板子
:-P
当我们把所有的额外功能都剥掉以后,发现UI其实就一个作用――展现,因为CI需要的是完全的自动化,人工本来就不需要介入,只要最后被notify一下,或者偶尔过来在web上看看报表趋势什么的就够了。
CI是服务加最佳实践
我们理解的第二个经验就是,搞CI,是服务加最佳实践,所以一定要指导研发团队,而不能完全任由研发团队提要求,很多团队的工程师良莠不齐,对各种编程api比较熟悉,但是可能缺乏做事的好习惯,这时需要指导他们,当然前提是你也要对开发很了解才行,否则会被鄙视的
:-P
对CI来说,最大的常见麻烦是不写测试,这个一般是通过管理教育,比较简单。
另外一个隐藏的比较深――开发人员对系统的运行并不了解,比如开发的系统运行在linux上,但是基本的命令都不会。
这个问题我们遇到了挑战,有人认为这涉及到分工,研发工程师不应该了解线上,但是这个观点是有问题的。
因为很多bug和环境相关,如果开发人员不能在”真“的环境中尝试,一旦系统报错,很难不发生扯皮――这个扯皮可能发生在开发和测试之间,更可怕的是发生在线上,光定位就需要N多人参与,成本极大。
插件
最后是插件的问题,这个说来简单――插件能解决一些问题,不过插件设计之初实际上就限制了其使用,所以我总结的教训就是:先别急着做插件,想好了设计再动手。
DockOne技术分享(十):跨主机的 --link
这次技术分享的内容是做到跨主机的容器定位通信,取代了--link无法跨主机和互通的障碍。
阅读本文之前,请先阅读我的上一篇文章,让容器跨主机互相访问,通过自制路由器广播路由条目互相学习。
来让一个LAN里的Docker主机全部知道对方网络的下一跳怎么走,但是解决了刚需之后,又一个很大的问题告诉我,Docker在重启容器或者服务之后会更改自己的IP地址。
就像配置思科路由器的 ip local pool (不是DHCP服务)不会释放地址池等等,所以在不能很轻易固定IP的情况下,我想到了域名解析。但怎么让DNS服务器去知道容器的IP和名字呢?我查阅了一些资料发现DDNS是很适合这个需求。但是DDNS
是配合DHCP的,docker0却不是,Docker容器不会从DHCP服务器请求地址。
在有一天无意中看到了etcd GitHub里的文档,有一些根据etcd开发的开源软件,不仅有服务发现,还有两个DNS服务。比较了学习成本后,我选择了
skydns+etcd,skydns是Golang写的。
只想要etcd里提交信息,skydns就能读取到,无需重启服务,这非常的方便,就是怎么让容器去告诉etcd
域名和IP地址呢?Docker容器的好处就是启动脚本可以自定义。
我在启动脚本里添加一条curl或者etcdctl每次启动容器的时候容器读取自己的hostname还有IP地址发送给etcd服务器就可以。
比如我有2个Tomcat和1个Nginx都是容器化的:
tomcat1.hypers.local tomcat2.hypers.local |
在Nginx的upstream里将server的地址变成tomcat1.hypers.local:8080
tomcat2.hypers.local:8080。这样我就忘记了 容器的IP,也忘记了它在哪台主机上。
只要DNS能解析出他们的IP就可以了,因为 docker容器是取宿主的 nameserver 所以这个dns如何指定地址无需担心。只要宿主是skydns的地址就行,启动etcd+skydns是非常简单的,etcd
启动命令我想大家玩过k8s的都会。
skydns是0配置的,可以读取etcd里的skydns信息。也可以自己 skydns -后面加参数启动,我已经把skydns
Docker化了,就不麻烦大家编译了,在灵雀云上的georce的仓库里能找到。
skydns搭建在etcd服务器上
curl -XPUT http://127.0.0.1:4001/v2/keys/skydns/config \
-d value='{"dns_addr":"0.0.0.0:53", "domain":".local.", "nameservers": ["223.5.5.5:53","114.114.114.114:53"]}'
docker pull index.alauda.cn/georce/skydns
docker run -itd --name=skydns --net=host index.alauda.cn/georce/skydns |
容器启动脚本
curl -XPUT http://$ETCD:4001/v2/keys/skydns/local/$DOMAIN/"`hostname -s`" \
-d value='{"host":"'`ip a | grep "scope global eth0" | awk '{print$2}' | grep -o '\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}'`'"}'
etcdctl -C $ETCD_HOST:4001 --no-sync set /skydns/local/$DOMAIN/"`hostname
-s `" '{"host":"'`ip a | grep
"scope global eth0" | grep -o '\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}'`'"}' |
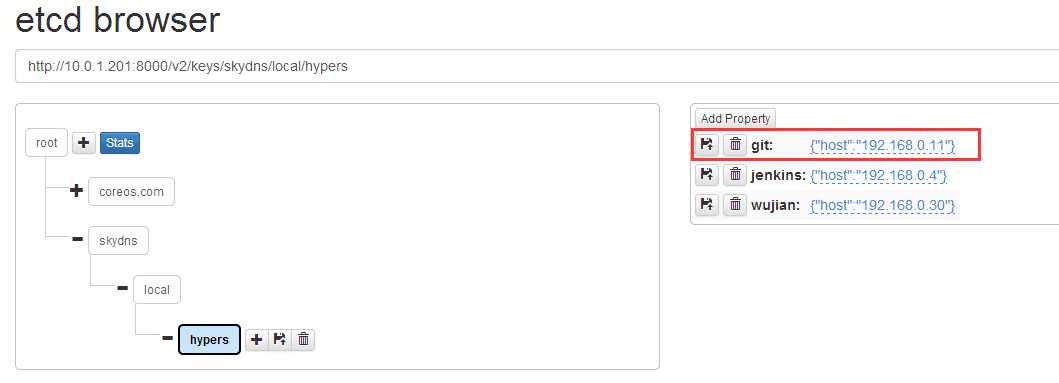
这两条命令代表同一个意思,hostname是根据启动容器时的命令,比如
docker run -itd --name=java --hostname=tomcat1 |
$DOMAIN 是docker run -itd -e DOMAIN=hypers
我默认都是用的local最后根域,连起来就是 tomcat1.hypers.local。就像我网络那篇文章最后用win7访问无端口映射过的Nginx。nginx.hypers.local
也是可以访问的,只要我win7的dns是指向skydns。
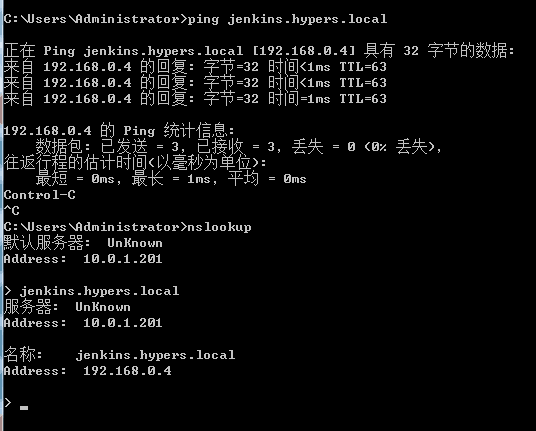
Skydns里可以设置DNS转发给223.5.5.5 或者114.114.114.114 所以无需担心不能上网。
|






