|
DockOne技术分享(二):集群规模下日志处理和网络方案
本文主要介绍在容器集群中,如何管理容器日志,有哪些方法可以管理日志,这些方法分别有哪些优势和劣势。紧接着讨论了目前网络的几种方案,每种方案都会带来什么样的收益和效果。最后介绍了芒果TV的最佳实践。
我先假定今晚的听众至少小范围的铺开 Docker 容器化技术在线上了,至少熟悉
Docker 的工作原理和 remote API。所以我不会过多的介绍Docker 的基本操作和使用,主要是分享集群化容器中的日志管理和网络管理。
在早期 Docker 实现中,日志这块的功能都不完善,所有容器内的标准输出和错误都会写入到/var/lib/docker/containers/{$cid}/{$cid}-log.json中。因为没有日志自动分卷以及容器绑定,所以一旦到线上就会出现瞬间磁盘打满的情况。而这个文件同时又是
docker logs api 的 data source,加之 docker 1.6 引入的 log-driver
参数,因此对于线上日志的收集管理我们目前有这么几个方法。
监控文件,并通过管道转出数据。这种方案最大的问题是日志文件和容器是绑定的,因此需要有一个
agent 的角色来做这件事,变相的增加了开发成本,还要考虑管道的可靠性问题。另外 CentOS 6系和7系日志地址不一样,如果硬编码则扩展性不佳,如果读取系统配置,那就要考虑跨系统之间的路径问题。
通过docker logs api来远程重定向日志。这种方法最大的问题是你避免不了还是得有
agent 去清理日志这么个操作,否则的话磁盘依然会被打满,当然也可以配合 logrotate 来做这事,不过增加了运维成本。如果是远端调用这个
API 的话,需要考虑连接的可靠性,一旦出现重连,那就要做日志回溯,否则会丢失一部分日志。
容器内进程自己写出日志。这又有两种方案,如下:
进程直接写出,控制权交给了业务方,对业务不透明,可控性降低,毕竟是集群环境。这样一来也要暴露集群结构给上层。
映射日志设备(/dev/log)进容器,容器内进程直接写设备,隔离性减弱,单点问题追踪会很麻烦,因为这时候
stdout 和 stderr 是没有内容的,也就是docker log命令无任何输出。
『进程直接写出』这种方案我们试过,不过要让业务方来改代码,所以整体推进很难了。另外它还暴露了远端日志服务器地址,无论是网络上还是安全上都是有问题的。举个例子,一旦介入
SDN 等管理网络的方式,那么等于就是破坏了整体的隔离性。『映射日志设备进容器』这种方案就是定位问题容器比较麻烦,而且还是要涉及到跟业务方沟通。
使用新版的 log-driver 参数,其中包含支持 syslog,看似很美好,但是在集群环境下要考虑
syslog 单点问题。一般来说会有多个 syslog 或者支持 syslog 协议的远端 server
(logstash)。如果使用远程 syslog 接受日志,大量容器日志输出并不平均,从而会产生性能热点和流量热点。如果走单机
syslog 再汇总,那就和上面的方案『进程直接输出』没多大区别了,同样是跟踪问题比较麻烦。我觉得目前这个实现更多的是方便了之前使用
syslog 方案的。
通过attach 方法截获容器输出流重定向。这种方案需要 agent 支持,有一定开发要求。目前我们采用的就是这种方案,通过一个模块实现了
consistent hash,然后把日志流量打到远端收集服务器上。这个方案只需要让业务把日志输出到 stdout/stderr
中即可,并不会增加开发成本。同时Docker 1.6中可以指定日志驱动为 none,避免了 logs 文件的产生。另外一方面可以把容器自己的
meta info 附加到日志流里面,从而实现远端的日志检索分类聚合等操作。但这个方案最大的问题是开发力量的投入,不同的
dockeclient 实现质量也不一样,当然好处也是很明显的,灵活可控,日志流向和分配都在自己受伤。
所以日志方面,从目前 Docker 实现来看,如果开发力量跟得上,agent
+ attach 方案是灵活性和可控性是最高的。目前 log-driver 对于上规模的集群来说还是不太好用,理想状态下我希望是可以指定多个
log-drivers,通过 hash 方案打到远端。当然具体方案的选取就得看各自公司本身的基础设施和设计目标了。
说完日志来说下网络,目前 Docker 的网络方案主要有这么几个,当然现在大家都在等
1.7,不过我认为对于生产系统而言,已有 SDN 方案的不会太过于在乎 Libnetwork,可能会研究下其和
Docker 是怎样通过 plugin 方式结合的。因为其他它案目前都是 Hook 方式去做的。
1、默认 NAT/BR/HOST,NAT 有性能损失,BR 有网络闪断,HOST
流控不好做,端口冲突靠业务保证没法做到透明。
2、网络层方案
a. 隧道方案
I. OVS,主要是有性能方面的损失,基于 VxLAN 和 GRE 协议,类似的方案还有
Kubernetes/Socketplane 的实现。
II. Weave,UDP 广播,本机建立新的 BR,通过 PCAP 互通。
III. Flannel,UDP 广播,VxLan。
隧道方案非常灵活,但是因为太过于灵活,出了网络问题(A-B 链路抖动)跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个点,毕竟即便是内网也不一定风平浪静。
b. 路由方案
I. Pipework,对于 Docker BR 本身的扩展,当然也支持
OVS macvlan 等方案的结合。现在 libnetwork 出来变相的是废了这个项目了,长远来看后继无人,因此它不是一个很好的选择。
II. Calico,基于 BGP 协议的路由方案,支持很细致的 ACL
控制,对于隔离要求比较严格的场景比较适合,对混合云亲和度比较高,因为它不涉及到二层的支持。
III. Macvlan,从逻辑和 Kernel 层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
路由方案没那么灵活,大多数情况下需要有一个 agent 在容器主机上去操作,一般是从
3 层或者 2 层实现隔离和跨主机容器互通的,出了问题也很容易排查。但是路由方案对本身物理网络依赖会比隧道方案要重。另外
hook 的话毕竟还是不太优美,所以得看看 libnetwork 是怎样和 Docker 结合的。
目前我们选取的是 macvlan 的方案实现的二层隔离,说轻点主要是对容器而言,可以完全当容器为一台虚拟机。说重点,是因为其对物理网络基础设施依赖程度最高。
DockOne技术分享(三):Docker Registry的定制和性能分析
本文介绍了Docker Registry服务几个组件的构成,以及怎么规划定制一个私有镜像库,以及镜像服务pull/push操作性能分析、并发性能分析,帮助大家按照需求搭建自己需要的镜像服务。
Docker Index
Web UI
Meta-data 元数据存储(附注、星级、公共库清单)
访问认证
token管理
Docker Registry
存储镜像、以及镜像层的家族谱系
没有用户账户数据
不知道用户的账户和安全性
把安全和认证委托给docker-hub来做,用token来保证传递安全
不需要重新发明轮子,支持多种存储后端
没有本地数据库
后端存储
因为镜像最终是以tar.gz的方式静态存储在服务端
适用于对象存储而不是块存储
registry存储驱动
官方支持的驱动有文件、亚马逊AWS S3、ceph-s3、Google gcs、OpenStack swift,glance
一次Docker Pull发生的交互
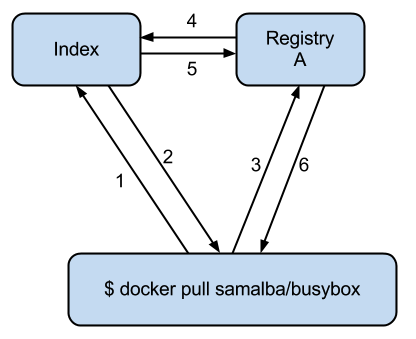
1. Client向Index请求,知道从哪里下载samlba/busybox
2. Index回复:
3. samalba/busybox在RegistryA
4. samalba/busybox的checksum,所有层的token
5. Client向Registry A请求,samalba/busybox的所有层。Registry
A负责存储samalba/busybox,以及它所依赖的层
6. Regsitry A向Index发起请求,验证用户/token的合法性
7. Index返回这次请求是否合法
8. Client从registry下载所有的层
9. Registry从后端存储中获取实际的文件数据,返给Client
搭建私有镜像库的方案
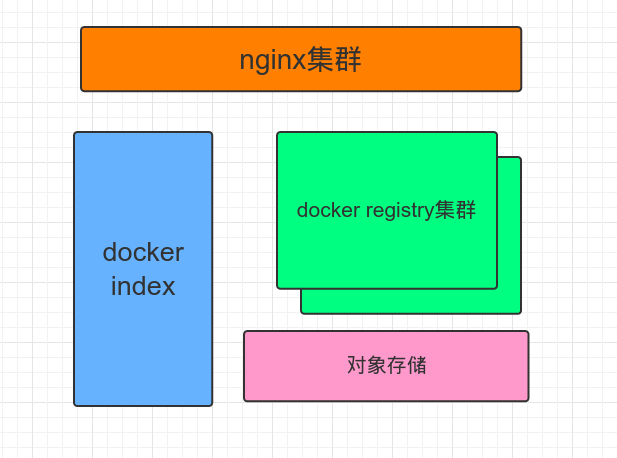
上面的index、nginx、后端存储3者都是可选的。registry分0.9的python版实现和2.0版的go实现。
认证和权限
如果镜像库不直接提供给用户使用,仅仅是私有PaaS的一部分,可以不用index组件,直接上Registry就行。Index的开源实现包括docker-registry-web,docker-registry-frontend。支持较好的是马道长的wharf。
后端存储
我们环境使用的是网易的内部的对象存储NOS,类似于S3。其他的方案没用过,如果要自己搭,可能靠谱的是ceph-s3。如果在公网环境或者已经购买了公有云服务,可以考虑自己实现一个registry-对象存储的驱动。
集群和分布式
Registry本身是无状态的,可以水平扩展,然后在前面做ngix的负载均衡。
性能测试
v1协议 vs v2协议
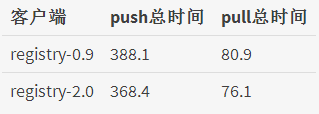
做了性能对比测试,同样为docker1.6,v2协议比v1协议快5-6%左右,基本可以忽略不计。
单次Pull和Push的性能分析


经过对比测试,单次docker pull和push的最大耗时在客户端,也可以观察到每次做docker
pull和push的时候系统CPU占用率都在100%。也就是说50%以上的时间花在本地做的压缩、计算md5等操作。
并发分析
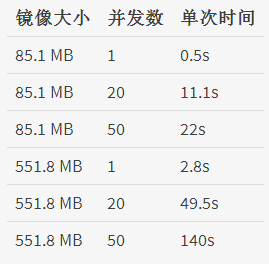
并发测试的结果是在一个2核2G内存的registry-0.9服务器,直接用文件存储,大约能负载50个docker
client的并发。如果换用对象存储的后端,估计10个docker client的并发就是极限了。
registry-2.0的并发性能很奇特,一方面,同样的镜像下载的比registry-1.0要慢,另一方面,只有一个进程,占了20%左右的CPU和内存,对系统资源消耗很少,不像python版的占用了所有的CPU核和内存。
DockOne技术分享(四):AppC和Docker的对比
现在一说到“容器”,几乎所有人首先想到的就是Docker。Docker作为目前最主流的容器标准,掩盖了许多前辈和后续者的光辉。事实上,Docker既不是第一个容器类产品(OpenVZ、Lxc等都远远早于它),也不会是最后一个。今天我们来聊一个最近有点火的新容器标准:AppC。
AppC是 CoreOS 公司在2014年12月发起的社区项目,旨在设计一种新式的跨平台容器在镜像格式、运行方式和服务发现机制等方面的标准。
从官方的表态说,这个项目最初诞生的原因是,主流容器工具 Docker 正在从一个单纯的容器工具成为自成一体的生态圈。而
Docker 的中心式管理方式(由每个主机上的 Docker -d 后台进程统一控制)对于 Systemd
以及第三方的任务编排工具并不友好(具体原因稍后分析)。
因此 CoreOS 希望设计一种去中心化的、功能更纯粹、同时更关注性能和安全的应用容器,将诸如日志管理、容器调度、集群编排等工作都交给外部工具去完成。
Docker 的发起者是 DotCloud 公司,这个公司原本的业务就是做
PaaS 平台,这也决定了 Docker 的发展方向就是成为一个“大而全”的平台性质的产品。这种做法本身也符合占市场绝大多数的“大众用户”希望“一站式解决方案”的诉求。
可以这样说,两者本质的出发点和想解决的问题并不相同。因此,希望大家秉着开放和包容的心态来看待
Docker 和 AppC 的比较。而不是抱着选择“哪一个是最好的容器标准”的目的,因为这个问题可能和“哪个编程语言是最好的语言”一样,只能交给时间去定论。
现在符合 AppC 标准的容器已经有几款了(都十分的小众),不可能挨个对比。下面就只以
CoreOS 官方推出的 Rkt 容器作为与 Docker 的比较对象。以下内容都属个人测试的结果,不代表
Docker 或 CoreOS 任何一方的官方观点。
由浅入深的说。首先是最容易感觉到的一些差异。
操作命令的方式
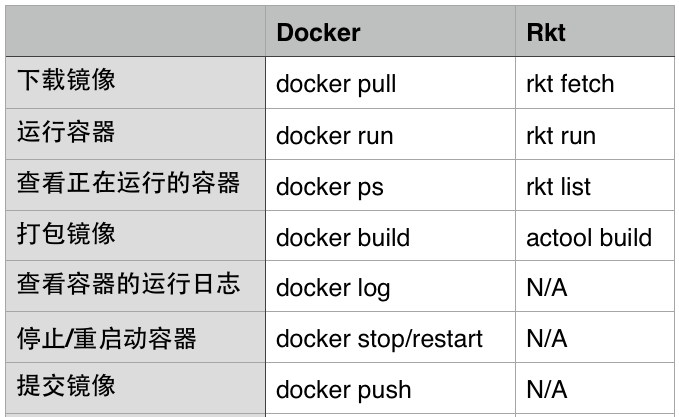
可以看到,Docker的所有命令都包含在了 Docker 这一个命令行工具中。
而 Rkt 中与镜像相关的命令是由 AppC 统一的命令行工具 actool
提供的,而容器本身的操作由各个容器自己提供,例如 rkt。
Docker 的容器停止以后还会被后台的 Docker -d 进程记录,还能够再次
restart,而 Rkt 的容器里运行的应用则更像是一个普通的应用,结束了就真的结束了。
另外也能看出,Rkt 提供的功能只是 Docker 的子集,后者在日志、镜像、管理方面提供的支持完整很多。
然后,来看一下 Docker 和 Rkt 的一个十分重要的差异。
容器进程运行方式
Rkt 的每个容器进程由 rkt 命令直接 fork 出来。而 Docker
的容器进程是由用户执行的 Docker 命令行工具发送消息给后台的 Docker -d 进程,由 Docker
-d 进程间接 fork 的。这咋看起来没什么区别,但是 Docker 的这种方式就给第三方的任务编排工具带来了一些困扰。
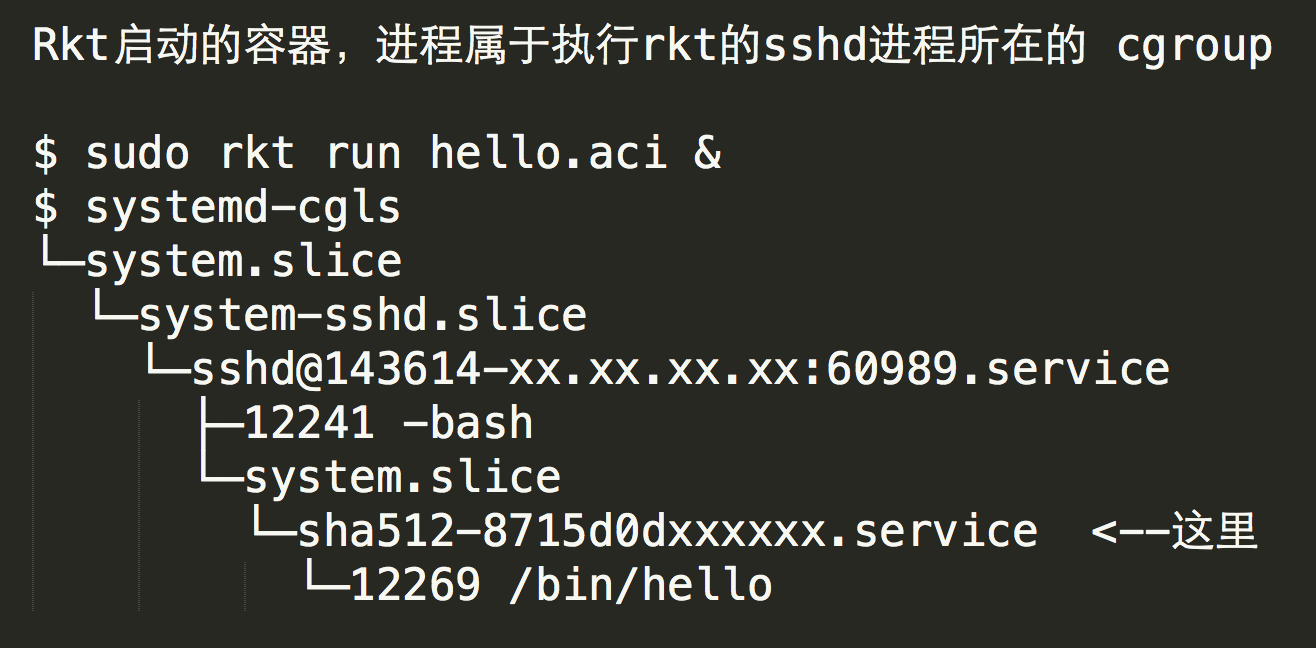
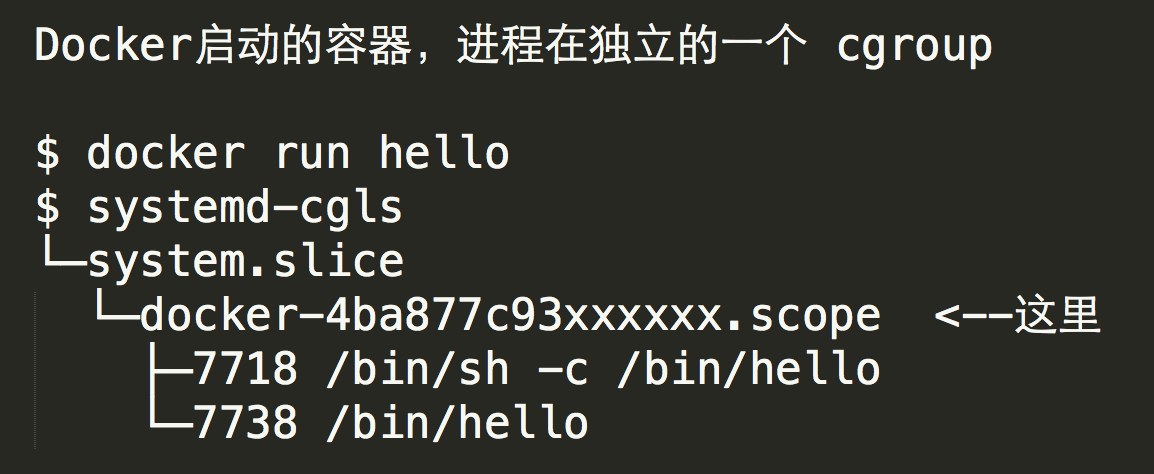
有些进程管理工具,比如 systemd 是通过 cgroup 来控制和跟踪进程的生命周期的,而
SysV 则是通过进程号和继承关系来跟踪进程生命周期。比如说当需要结束一个进程的时候,进程管理工具就会找到相应进程的所有子进程一起结束。
但 Docker 的这种进程运行模型,使得不论是通过进程树还是 cgroup
树都无法看出创建容器的 Docker 命令行与容器本身有任何关系。因此许多任务管理工具如果不对 Docker
进程进行特别对待,就无法正常的管理通过 Docker 启动的容器里的进程。
看镜像的结构
Docker 导出的镜像是一个 tar 文件,里面的内容是分层的。

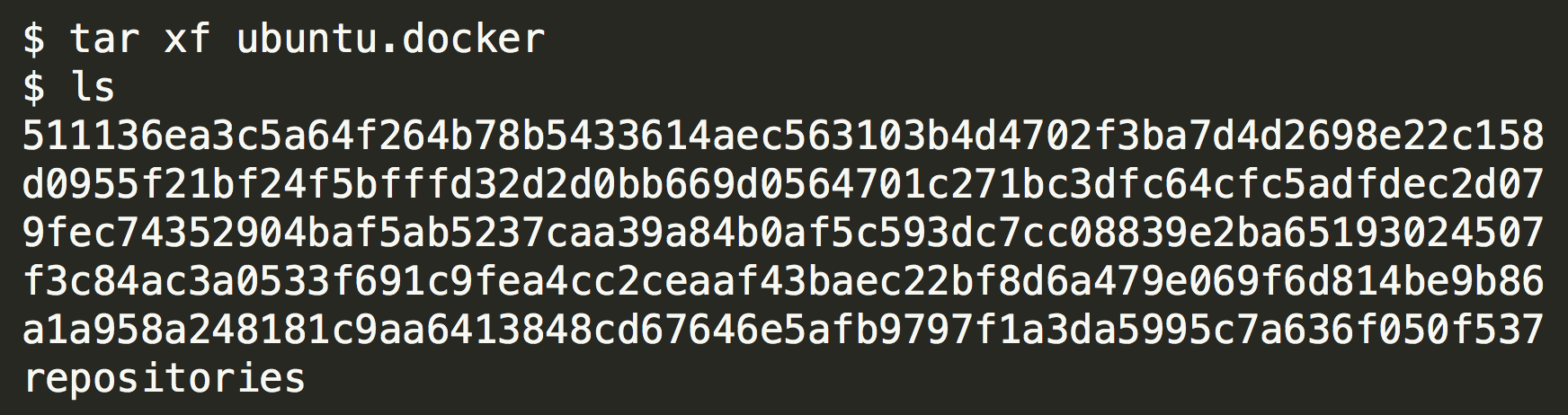
解压以后的每一个目录其实就是镜像的一层。
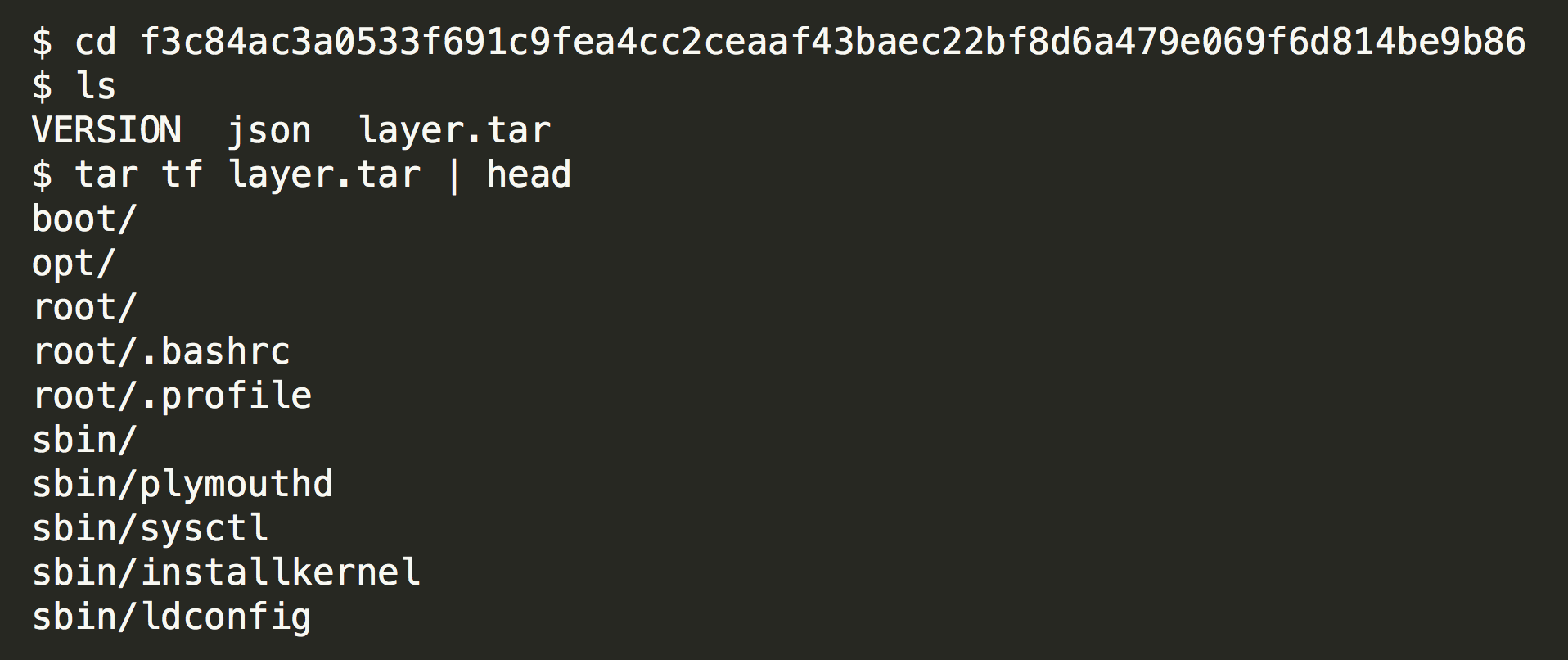
Rkt 的镜像是一个 gzip 文件,里面没有分层,直接就是所有容器中的文件的打包。


个人觉得分层以后虽然复杂了一点,但能够复用空间,其实是比较有用的。
最后来看一下 AppC 比较强调的安全性和性能方面。
安全性
Docker 下载一个镜像,直接 Docker pull 了事,传输过程可加密可不加密,Docker
也不会问你是否了解这个镜像的来源。
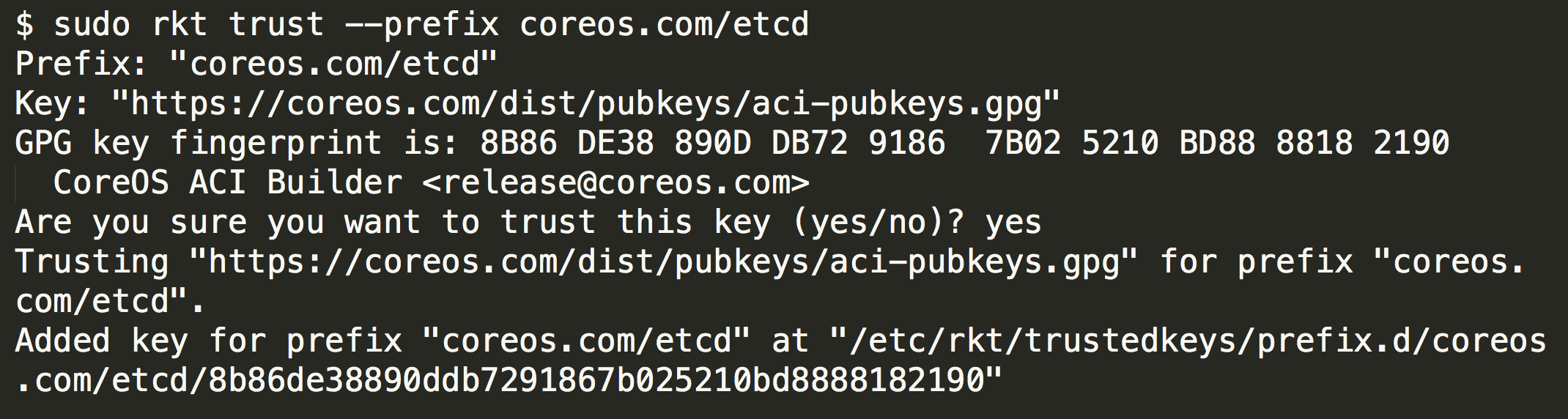
而 Rkt 默认要求所有传输过程加密,并且下载镜像前用户必须首先添加对镜像来源签名的信任,除非用户明确指定取消验证,否则镜像即使下载了
Rkt 也会拒绝运行它。
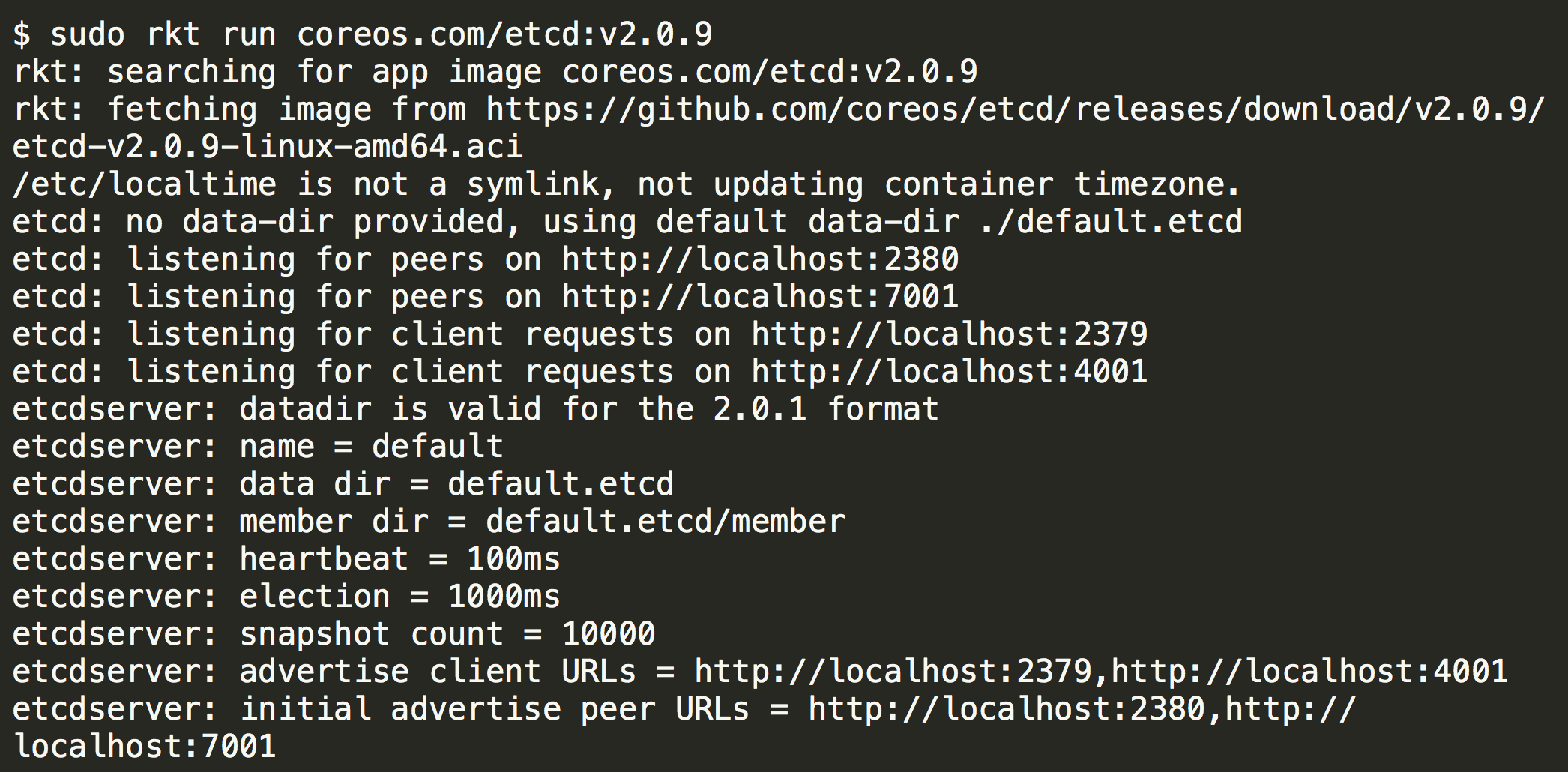
容器性能
性能方面,可以从一个侧面来说明:构建一个最小的可运行镜像需要哪些东西。
下面的 hello 这个文件是一个静态编译(无任何非系统库依赖)的程序,运行的时候会打印一个“Hello
World”。
把它放到一个空白的 Docker 镜像里面。
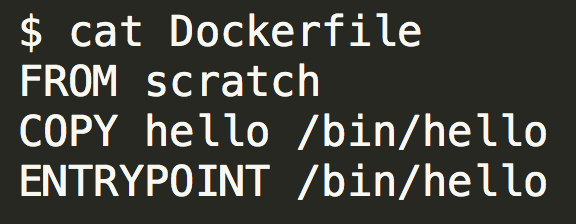
运行容器会发现 Docker 提示找不到 Bash。

将同样的程序放到一个空白的 AppC 镜像里面。
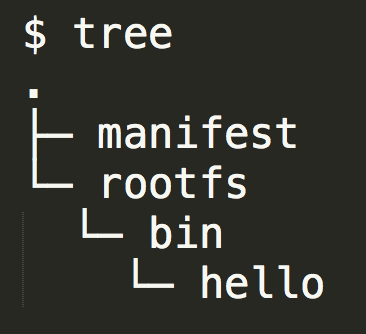
运行容器就能够正常工作。
这一点看出 Docker 在运行容器里的任何程序的时候,实际上都会先在容器里面启动一个
Shell,再由这个 Shell 去容器执行指定的命令。而 Rkt 则是纯纯的直接运行了指定的程序,相比之下在性能和镜像内容的“信噪比”上略占优。
DockOne技术分享(五):Docker网络详解及Libnetwork前瞻
网络基础
Docker现有的网络模型主要是通过使用Network namespace、Linux
Bridge、Iptables、veth pair等技术实现的。
Network namespace:Network namespace主要提供了关于网络资源的隔离,包括网络设备、IPv4和IPv6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、端口(socket)等。
Linux Bridge:功能相当于物理交换机,为连在其上的设备(容器)转发数据帧。如docker0网桥。
Iptables:主要为容器提供NAT以及容器网络安全。
veth pair:两个虚拟网卡组成的数据通道。在Docker中,用于连接Docker容器和Linux
Bridge。一端在容器中作为eth0网卡,另一端在Linux Bridge中作为网桥的一个端口。
容器的网络模式
host模式: 容器和宿主机共享Network namespace。
container模式: 容器和另外一个容器共享Network namespace。
kubernetes中的pod就是多个容器共享一个Network namespace。
none模式: 容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth
pair 和网桥连接,配置IP等。
bridge模式: Bridge模式是Docker的默认模式,下面这张图即为Bridge模式下Docker容器的网络连接图。
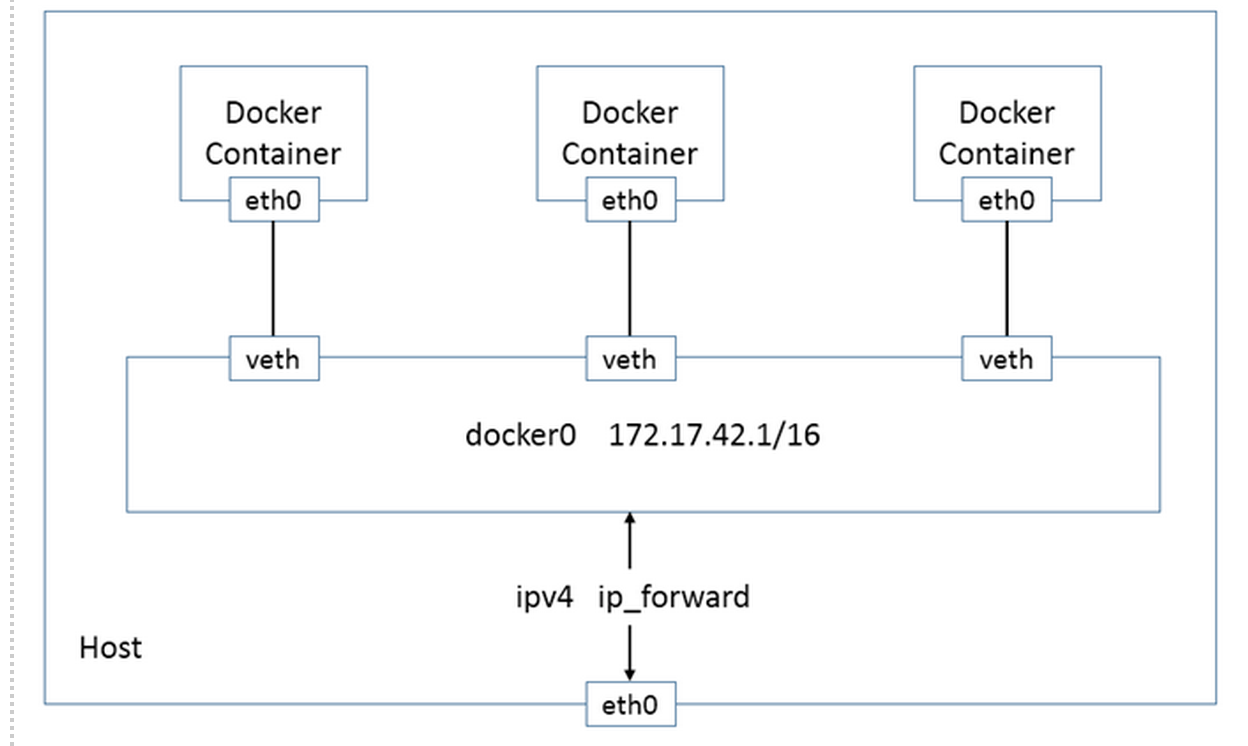
容器eth0网卡从docker0网桥所在的IP网段中选取一个未使用的IP,容器的IP在容器重启的时候会改变。docker0的IP为所有容器的默认网关。容器与外界通信为NAT。
Link 操作
link 操作可以在两个容器间建立一条数据通道,使得接收容器可以看到源容器的指定信息。通过设置接收容器的环境变量和/etc/hosts文件来得到源容器的环境配置信息以及具体的IP地址,一个非常简单的服务发现机制。由于link功能有限,个人觉得用处不是太大。
Docker自身的网络功能比较简单,不能满足很多复杂的应用场景。因此,有很多开源项目用来改善Docker的网络功能,如pipework、weave、flannel、socketplane等。
网络配置工具pipework
pipeork是一个简单易用的Docker容器网络配置工具。由200多行shell脚本实现。通过使用ip、brctl、ovs-vsctl等命令来为Docker容器配置自定义的网桥、网卡、路由等。有如下功能:
支持使用自定义的 Libux Bridge、veth pair为容器提供通信。
支持使用macvlan设备将容器连接到本地网络。
支持DHCP获取容器的IP。
支持Open vSwitch。
支持VLAN划分。
我之前写过一篇介绍pipework的文章,里面通过3个例子介绍了pipwork的使用
(将Docker容器配置到本地网络环境中、单主机Docker容器VLAN划分、多主机Docker容器的VLAN划分),
有兴趣的朋友可以去看下,在这里 http://www.sel.zju.edu.cn/?p=444 (实验室博客,里面有很多Docker相关的文章)
或 http://www.infoq.com/cn/articl ... ctice
Docker容器跨主机通信
在目前Docker默认的网络环境下,单台主机上的Docker容器可以通过docker0网桥直接通信,而不同主机上的Docker容器之间只能通过在主机上做端口映射进行通信。这种端口映射方式对很多集群应用来说极不方便。如果能让Docker容器之间直接使用自己的IP地址进行通信,会解决很多问题。目前使Docker容器跨主机通信主要有一下几种方法:
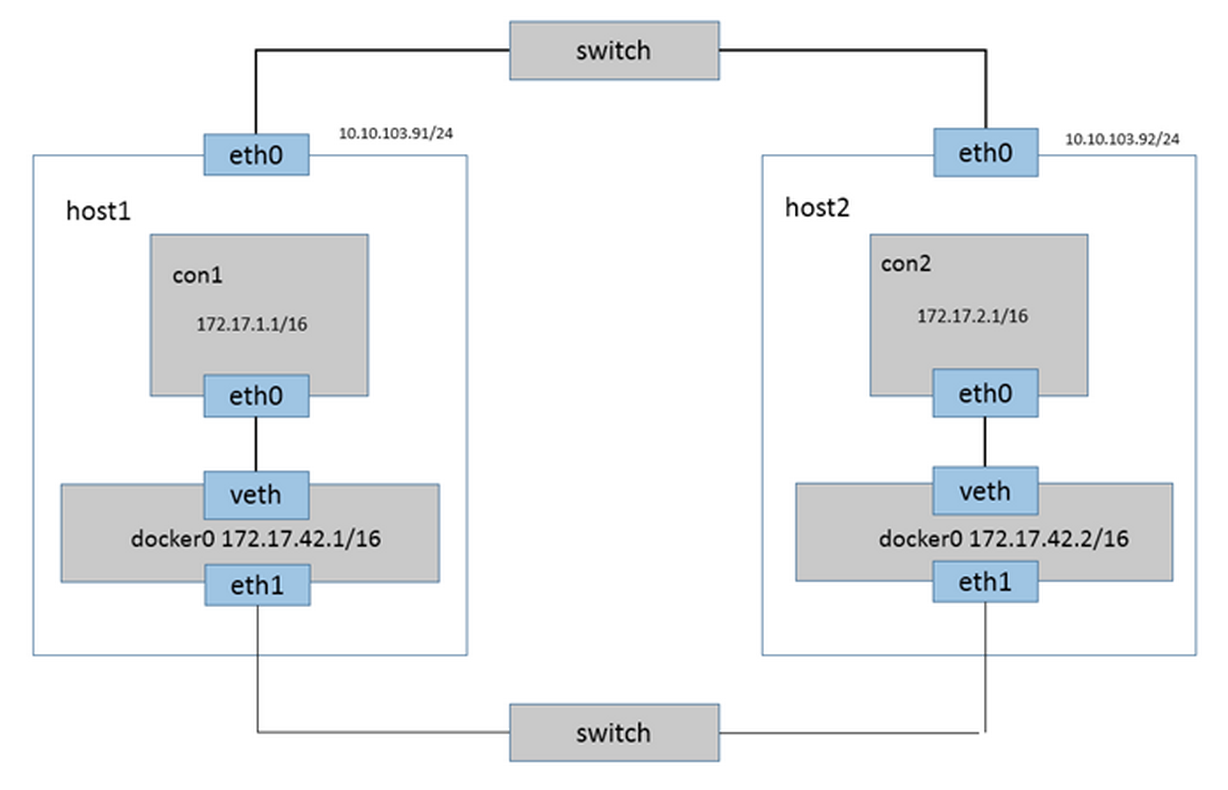
桥接方法: 通过将不同Docker主机上的docker0网桥桥接在同一个二层网络中(使用主机的网卡桥接),使得Docker容器可以跨主机通信。
如下图:
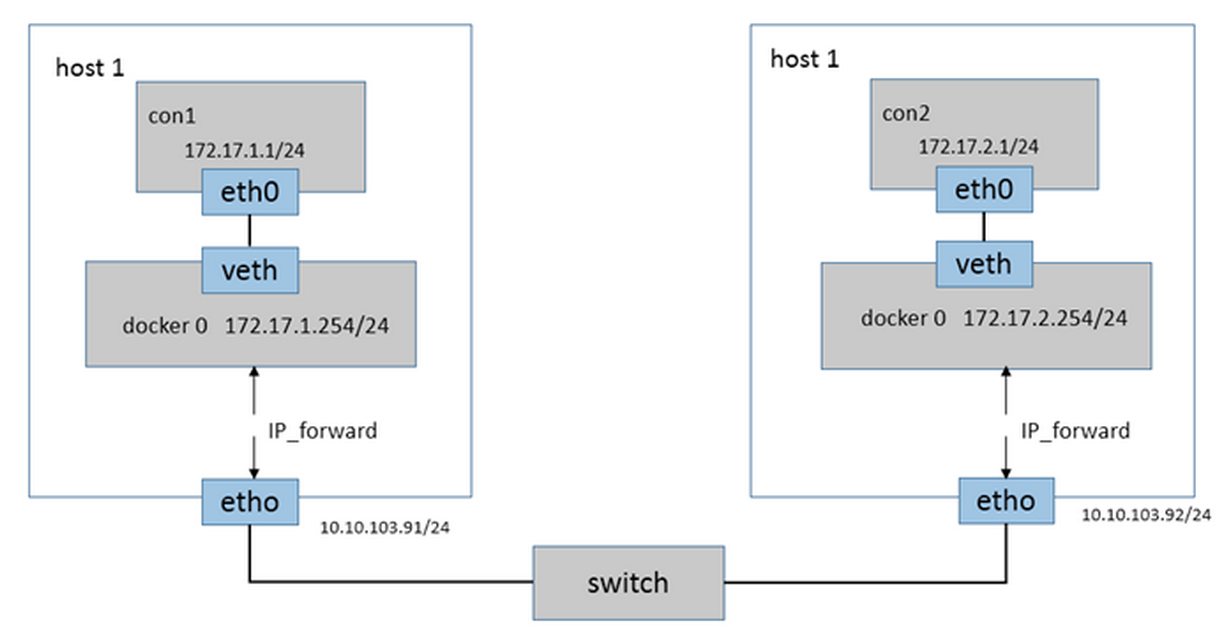
直接路由: 通过在Docker主机上添加静态路由实现跨宿主机通信。如下图:
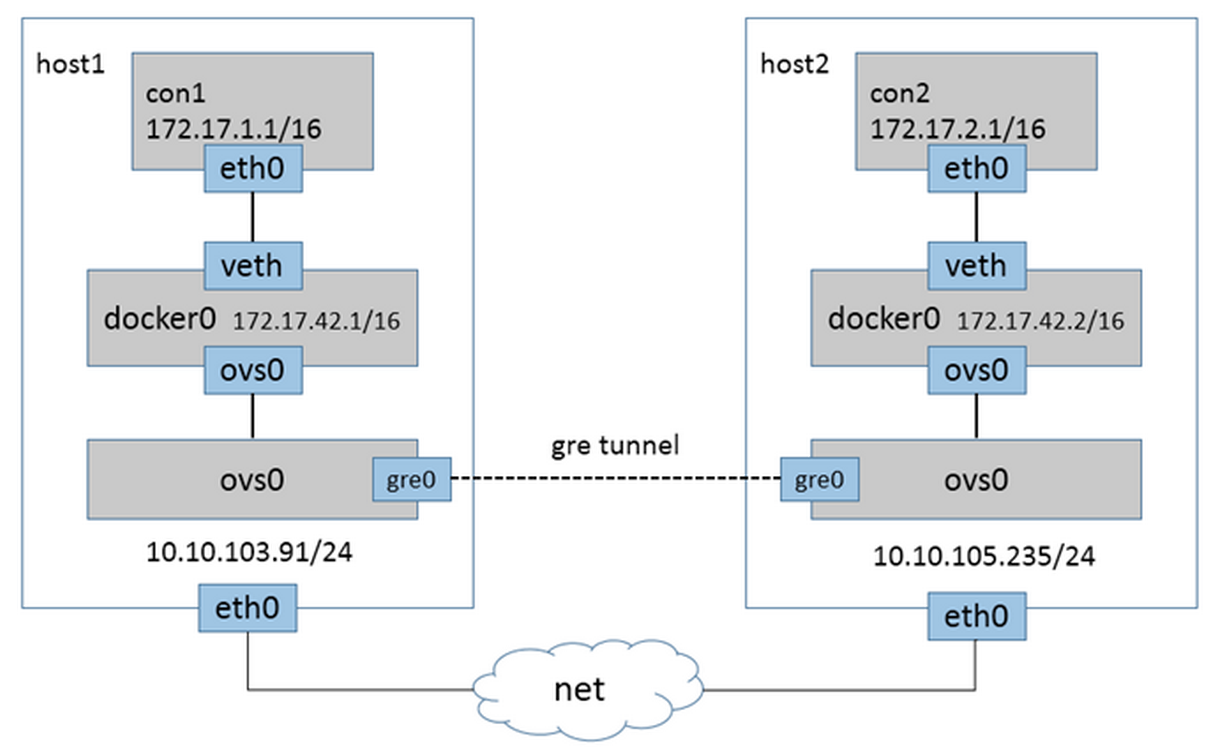
隧道方法:使用GRE、 VxLan隧道实现跨主机通信。
前两种方法要求主机在同一个子网中,不常使用。所以我主要介绍隧道的方法。
Overlay隧道模型
Overlay网络其实就是隧道技术,即将一种网络协议包装在另一种协议中传输的技术。隧道被广泛用于连接那些因使用其他网络而被隔离的主机和网络,结果生成的网络就是所谓的Overlay网络。因为它有效地覆盖在基础网络之上,这个模型就可以很好地解决跨网络使Docker容器实现二层或三层通信的需求。如同一公司不同办公地点间内网连接的VPN技术,就是将三层IP数据包封装在隧道协议中进行传输。
使用gre隧道连接的多主机容器间通信,如下图所示。(OVS + gre)
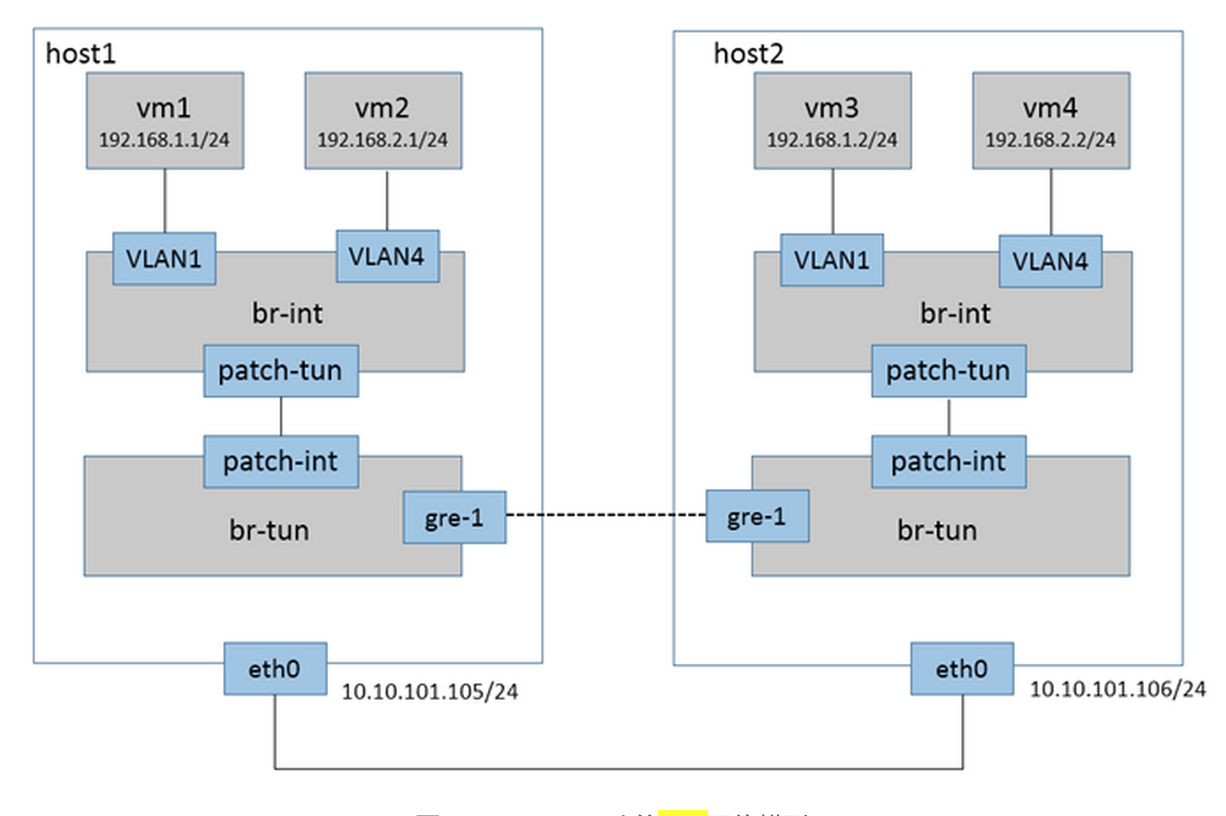
类Neutron的多租户的GRE网络
隧道方案的另一个好处就是可以解决VLAN ID 不足的问题。不同的租户使用不同的
GRE ID在隧道中传输。这样的方案类似于OpenStack的neutron网络。示意图如下:
Libnetwork 前瞻
Libnetwork是Docker官方近一个月来推出的新项目,由这个issue而来。旨在将Docker的网络功能从Docker核心代码中分离出去,形成一个单独的库。
Libnetwork通过插件的形式为Docker提供网络功能。 使得用户可以根据自己的需求实现自己的Driver来提供不同的网络功能。
目前主要由socketplane的那帮人在开发。
官方目前计划实现以下Driver:
Bridge : 这个Driver就是Docker现有网络Bridge模式的实现。
(基本完成,主要从之前的Docker网络代码中迁移过来)
Null : Driver的空实现,类似于Docker 容器的None模式。
Overlay : 隧道模式实现多主机通信的方案。 (还只是个计划,具体实现细节还没定)
Libnetwork所要实现的网络模型基本是这样的: 用户可以创建一个或多个网络(一个网络就是一个网桥或者一个VLAN
),一个容器可以加入一个或多个网络。 同一个网络中容器可以通信,不同网络中的容器隔离。
1.7 版本的Docker将会把Libnetwork整合进来(目前已经整合进去了),但功能并没有太大变化,因为目前仅完成了Bridge
Driver。 之后会继续完善。
Docker网络的发展以后就都在这个项目上了,目前这个项目才刚刚开始,还有很多东西没有确定。大家有兴趣可以多多关注一下。
|






