|
我们已经完成了对Hadoop需求的探索,并看到了VPC与EC2搭配起来让EMR服务更具效率的操作。通过建立一个新的VPC,我们看到默认设置如何提供通信,以及构成Hadoop集群的实例需求,并通过修改这些行为来影响EMR。
时下,VPC已经成为发布Amazon EC2实例的默认环境,因此掌握Amazon
VPC环境中的Amazon EMR集群运行原理至关重要。在这篇博文中,我们将弄清楚为什么需要在EC2 VPC环境中运行Hadoop集群。然后,我们将建立一个新的VPC环境,并发布一个EMR集群。这是这系列博文的第一部分,第二部分我们将详细介绍如何定制化DNS。
Hadoop通信需求(1)
通过 Hadoop wiki我们了解到:“为了让Hadoop正常工作,所有的机器必须可以相互感知,并相互通信;因此,它们需要一个识别机制,从而其它主机可以快速找到它们。”在EMR中,主机间的感知和通信通过设置
VPC中的DNS解决方案和DNS主机名称完成。通过启用这些默认设置,你的实例会被自动地指配主机名称――使用公共和私有IP地址(同时,使用“-”替换“.”,比如ip-10-128-8-1.ec2.internal)。从而,实例可以通过
EMR-managed security groups实现通信。
Hadoop 通讯需求(2)
在Hadoop 1中,通信需求是非常简单的,同时大部分情况也是非常宽容的。举个例子,Hadoop 1中,如果HDFS
DataNodes不可以被NameNode解析成一个全称域名,那么它将被回滚到一个IP地址,通信继续。因此,除下环境中出现问题,一个配置得当的Hadoop
1环境很少崩溃。
随着Hadoop项目逐渐成熟,更健壮的 Hadoop安全模型需求也逐渐提升。Kerberos识别、网络加密等功能被加入Hadoop以帮助阻止节点被添加到一个集群,比如下面这个HDFS配置参数:
dfs.namenode.datanode.registration.ip-hostname-check |
在Hadoop 2中,不可以被NameNode解析的DataNode将会被拒绝通信:
org.apache.hadoop.hdfs.server.protocol.DisallowedDatanodeException: Datanode denied communication with namenode |
本质上,Hadoop 1升级到Hadoop 2后并没有引起技术要求的改变。为了保证正常运行,节点间还是需要相互感知并通信。但是在Hadoop
2中,升级引起的改变很可能会造成不适当的环境配置,从而造成HDFS因为UnknownHost、ConnectionRefused和NoRouteToHost异常无法加载文件。
VPC中的设置
EMR位于VPC之外,同时还需要在任何时间可以与所有节点交互。集群中的实例需要定位(通过DNS)以及与EMR和Amazon
S3服务端点交互(使用宽松的安全组和网络ACLs)。以上这些将帮助到集群的创建、CloudWatch监视、日志同步以及提交处理。微了完成这些,EMR集群还需要一个
Inernet网关。
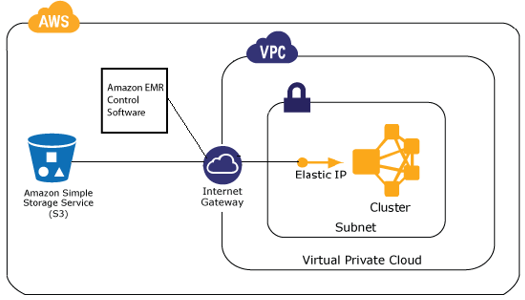
默认路由或者非VGWs的情况下,NAT实例将不被支持。在这两种场景尝试发布一个集群将导致集群终止或者错误:
"The subnet configuration was invalid: Cannot find route to
InternetGateway in main RouteTable rtb-036bc666 for vpc vpc-a33690c6" |
此外,在使用网络ACL子网中发布的EMR集群可能会打断这个通信。这主要因为 ACLs是无状态的,输入和输出规则必须被明确的规定,不像
EMR-managed security groups中使用的有状态规则。如果EMR集群发布在一个使用了ACL的子网中,并且没有提供足够的访问,那么集群将被终止。如果你必须使用ACL,那么请使用
EMR-managed security groups作为IP地址和端口范围导航以满足实例的通信。
理解DNS解决方案和DNS主机名称
在VPC中,节点之间必须要使用DNS查找以做到相互定位。否则,类似Yarn ResourceManager和HDFS
NameNode这样至关紧要的守护进程将出现问题。鉴于集群中名称解析的重要性,任何被忽视的DNS问题将耗费大量的管理时间。
无论你的实例是否自动收到一个完全描述的DNS名称,DNS主机名称都可以在VPC控制中设置。如果你使用的是AmazonProvidedDNS作为DNS服务器的默认配置,禁止这个设置同样阻止你的实例解析任何位于VPC子网CIDR范围的主机名称。
下面这些代码展示了在开启DNS主机名称的实例上查找另一个VPC中的实例:
[ec2-user@ip-192-168-128-5 ~]$ nslookup 192.168.128.6
Server: 192.168.0.2
Address: 192.168.0.2#53
Non-authoritative answer:
6.128.168.192.in-addr.arpa name = ip-192-168-128-6.us-west-2.compute.internal.
Authoritative answers can be found from:
[ec2-user@ip-192-168-128-5 ~]$ nslookup ip-192-168-128-6.us-west-2.compute.internal
Server: 192.168.0.2
Address: 192.168.0.2#53
Non-authoritative answer:
Name: ip-192-168-128-6.us-west-2.compute.internal
Address: 192.168.128.6
[ec2-user@ip-192-168-128-5 ~]$ |
在禁用了DNS主机名称支持、重启后运行相同的查找:
aws ec2 modify-vpc-attribute --vpc-id vpc-a33690c6 --no-enable-dns-hostnames |
[ec2-user@ip-192-168-128-5 ~]$ nslookup 192.168.128.6
Server: 192.168.0.2
Address: 192.168.0.2#53
** server can't find 6.128.168.192.in-addr.arpa.:
NXDOMAIN
[ec2-user@ip-192-168-128-5 ~]$ nslookup ip-192-168-128-6.us-west-2.compute.internal
Server: 192.168.0.2
Address: 192.168.0.2#53
** server can't find ip-192-168-128-6.us-west-2.compute.internal:
NXDOMAIN |
在这个情况下,正反向查找都无法进行。注意,外部的查找仍然可以进行。
[ec2-user@ip-192-168-128-5 ~]$
[ec2-user@ip-192-168-128-5 ~]$ nslookup <a href="http://www.google.com">www.google.com</a>
Server: 192.168.0.2
Address: 192.168.0.2#53 |
Non-authoritative answer:
Name: <a href="http://www.google.com">www.google.com</a>
Address: 216.58.216.132 |
关闭DNS解析会阻止我们解析任何查找。
aws ec2 modify-vpc-attribute --vpc-id vpc-a33690c6 --no-enable-dns-support
[ec2-user@ip-172-31-15-59 ~]$ nslookup google.com |
;; connection timed out; trying next origin
;; connection timed out; no servers could be reached |
当关键保护进程遇到DNS问题时,它们将无法启动。在全部关键系统没有完全正常运行的情况下,EMR不允许集群工作。下面这个日志说明了这个问题:
SHUTDOWN_MSG: Shutting down ResourceManager at java.net.UnknownHostException:
ip-192-168-128-13.hadoop.local: ip-192-168-128-13.hadoop.local: Name or service not known
SHUTDOWN_MSG: Shutting down NameNode at java.net.UnknownHostException:
ip-192-168-128-13.hadoop.local: ip-192-168-128-13.hadoop.local |
这个问题主要由于DNS错误导致的集群终止,错误类型如下:
"On the master instance (i-b3b1e3bf), after bootstrap actions were run Hadoop failed to launch" |
另一个示例:
On 2 slave instances (including i-92f8aa9e and i-8cf8aa80), after bootstrap actions were run Hadoop failed to launch. |
EMR假定你的EC2实例将分配默认的内部主机名称(ec2.internal或者region.compute.internal)或者一个IP地址
(如果你的VPC配置中允许DNS主机名称)。当启动一个定制域名时,Hadoop 1将不会产生错误,因为在Hadoop
1中,没有规定启动前节点必须使用域名解析。
在Hadoop 2中,使用定制化域名将导致集群配置值(主机名称填充)不能正确的解析。反过来,集群会因守护进程启动设失败而终止。这也就是说,如果自定义值可以被解析,Hadoop
2集群就可以使用定制域名。通过使用DNS服务器和 VPC,我们可以便捷地实现这个操作。
为EMR建立一个VPC
到此为止,我们对Hadoop和EMR的共同需求已经有了一定的理解,我们可以建立一个VPC来发布集群。这个操作你可以通过控制台中的VPC
wizard实现,或者是通过下面的CLI步骤。
开启一个/24的VPC,并使用一个/28的子网。
aws ec2 create-vpc --cidr-block 10.20.30.0/24 { "Vpc": { "InstanceTenancy": "default", "State": "pending",
"VpcId": "vpc-055ef660", "CidrBlock": "10.20.30.0/24", "DhcpOptionsId": "dopt-a8c1c9ca" } } |
建立一个拥有子网的VPC,并为其指定一个VPC ID和一个子网范围。在这个示例中,我们将使用10.20.30.0/28。
aws ec2 create-subnet --vpc-id vpc-055ef660 --cidr-block 10.20.30.0/28 |
子网ID和IP地址数量将会被返回,注意这些。
{
"Subnet": {
"VpcId": "vpc-055ef660",
"CidrBlock": "10.20.30.0/28",
"State": "pending",
"AvailabilityZone": "us-west-2a",
"SubnetId": "subnet-907af9f5",
"AvailableIpAddressCount": 11
}
} |
需要一个公共Internet网关和一个路由表。在这之前,我们需要发送一个带有VPC ID的create-route-table命令。下一步,我们将通过create-route建立默认路由。
aws ec2 create-route-table --vpc-id vpc-055ef660 |
这里需要注意返回的路由表ID。
{
"RouteTable": {
"Associations": [],
"RouteTableId": "rtb-4640f623",
"VpcId": "vpc-055ef660",
"PropagatingVgws": [],
"Tags": [],
"Routes": [
{
"GatewayId": "local",
"DestinationCidrBlock": "10.20.30.0/24",
"State": "active",
"Origin": "CreateRouteTable"
}
]
}
} |
因为EMR的需求,这里需要建立一个新的互联网网关。
aws ec2 create-internet-gateway |
{
"InternetGateway": {
"Tags": [],
"InternetGatewayId": "igw-24469141",
"Attachments": []
}
} |
注意这里返回的互联网网关ID。下一步,我们将互联网网关加到VPC上:
{
"InternetGateway": {
"Tags": [],
"InternetGatewayId": "igw-24469141",
"Attachments": []
}
} |
aws ec2 attach-internet-gateway --internet-gateway-id igw-24469141 --vpc-id vpc-055ef660 |
通过之前获得的物联网网关ID和路由表ID,我们将互联网网关作为默认路由使用。
aws ec2 create-route --route-table-id rtb-e743f582 --destination-cidr-block 0.0.0.0/0 --gateway-id igw-24469141 |
我们需要检查DNS主机名称是否被允许。如果不允许,那么打开。
aws ec2 describe-vpc-attribute --vpc-id vpc-055ef660 --attribute enableDnsHostnames
{
"VpcId": "vpc-055ef660",
"EnableDnsHostnames": {
"Value": false
}
} |
aws ec2 modify-vpc-attribute --vpc-id vpc-055ef660 --enable-dns-hostnames |
最终,我们已经做好了在VPC中发布集群的所有先决准备。我们可以使用以下命令来发布一个测试集群,并使用它做word-cout。提醒:测试时记得将下面代码中的输出地址换成你自己的S3
bucket。
aws emr create-cluster --steps Type=STREAMING,Name='Streaming Program&',
ActionOnFailure=CONTINUE,Args=[-files,s3://elasticmapreduce/samples/wordcount/wordSplitter.py,
-mapper,wordSplitter.py,-reducer,aggregate,-input,s3://elasticmapreduce/samples/wordcount/input,
-output,s3://<mybucket>/wordcount/output] --ec2-attributes
SubnetId=subnet-907af9f5 --ami-version 3.3.2 --instance-groups
InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m3.xlarge
InstanceGroupType=CORE,InstanceCount=2,InstanceType=m3.xlarge --auto-terminate |
集群被返回。
{
ClusterId": "j-2TEFHMDR3LXWD"
} |
几分钟后,检查你的集群是否已经完成了word cout作业。
aws emr describe-cluster --cluster-id j-2TEFHMDR3LXWD --query Cluster.Status.StateChangeReason.Message
"Steps completed" |
|






