|

ժҪ��ͨ�����Ƕ�һ��ϵͳ���������Ż��ֺ��������衪�����ܼ�غͲ���������������Ҫ������Ҳ�������������ݡ�
ͨ�����Ƕ�һ��ϵͳ���������Ż��ֺ��������衪�����ܼ�غͲ���������������Ҫ������Ҳ�������������ݡ�
���ܼ�ع���
��Spark��ع��ߡ�
Spark�ṩ��һЩ������Web���ҳ�棬�����ճ����ʮ�����á�
1. Application Web UI
http://master:4040��Ĭ�϶˿���4040������ͨ��spark.ui.port�ģ��ɻ����Щ��Ϣ����1��stages��tasks�����������2��RDD��С���ڴ�ʹ�ã���3��ϵͳ������Ϣ����4������ִ�е�executor��Ϣ��
2. history server
��SparkӦ���˳����Կ��Ի����ʷSparkӦ�õ�stages��tasksִ����Ϣ�����ڷ���������ԭ��ҵ�����������÷������£�
��1��$SPARK_HOME/conf/spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.retainedApplications=50
Dspark.history.fs.logDirectory=hdfs://hadoop000:8020/directory"
˵����spark.history.retainedApplica-tions����ʾ���50��Ӧ��spark.history.fs.logDirectory��Spark History Serverҳ��ֻչʾ��·���µ���Ϣ��
��2��$SPARK_HOME/conf/spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop000:8020/directory #Ӧ�������й��������е���Ϣ����¼�ڸ�����ָ����·����
3. spark.eventLog.compress true
��1��HistoryServer����
$SPARK_HOMR/bin/start-histrory-server.sh
��2��HistoryServerֹͣ
$SPARK_HOMR/bin/stop-histrory-server.sh
4. ganglia
ͨ������ganglia�����Է�����Ⱥ��ʹ��״������Դƿ��������Ĭ�������ganglia��δ������ģ���Ҫ��mvn����ʱ����-Pspark-ganglia-lgpl�����������ļ�$SPARK_HOME/conf/metrics.properties��
5. Executor logs
Standaloneģʽ��$SPARK_HOME/logs
YARNģʽ����yarn-site.xml�ļ���������YARN��־�Ĵ��λ�ã�yarn.nodemanager.log-dirs����ʹ�������ȡyarn logs -applicationId��
��������ع��ߡ�
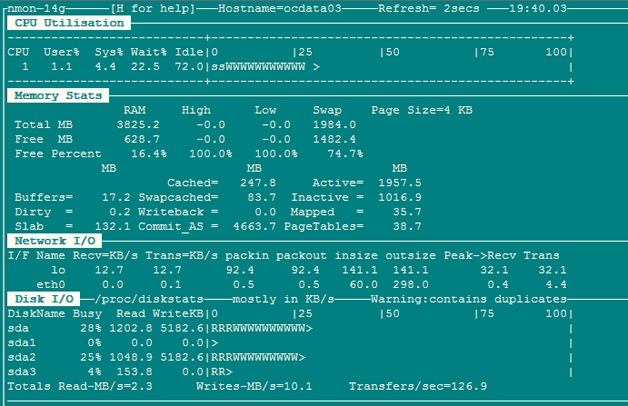
1. Nmon��http://www.ibm.com/developerworks/aix/library/au-analyze_aix/��
Nmon ���룺c��CPU n������ m���ڴ� d������
2. Jmeter��http://jmeter. apache.org/��
ͨ��ʹ��Jmeter��ϵͳ���ܲ�����ʵʱչʾ��JMeter�İ�װ�dz����ӹٷ���վ�����أ���ѹ֮��ʹ�á�����������%JMETER_HOME%/bin�£����� Windows �û���ֱ��ʹ��jmeter.bat��
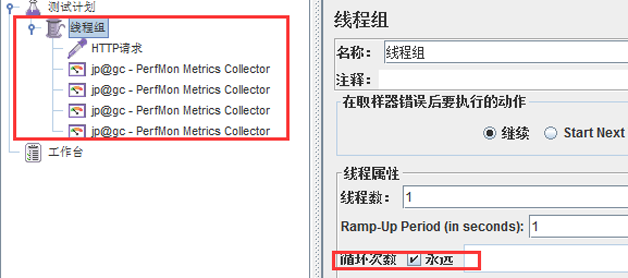
����jmeter���������Լƻ��������߳�������ѭ��������
���Ӽ�������jp@gc - PerfMon Metrics Collector��
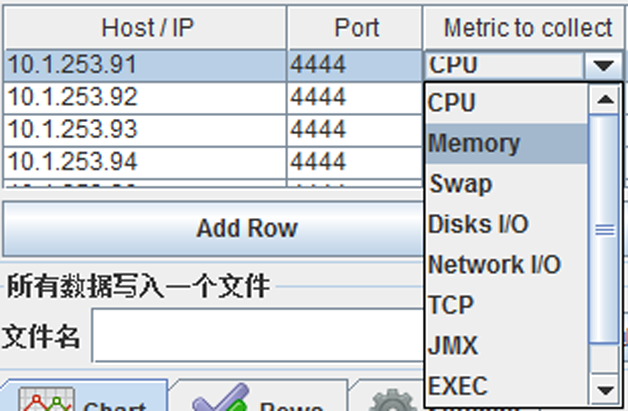
���ü����������������˿ڼ��������ݣ�����CPU��
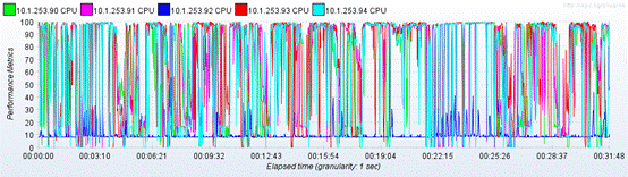
��������������ʵʱ��ýڵ��CPU״̬��Ϣ����ͼ4�ɿ���CPU�ѳ���ƿ����
3. Jprofiler��http://www.ej-technologies.com/products/jprofiler/overview.html��
JProfiler��һ��ȫ���ܵ�Java�������ߣ�profiler����ר���ڷ���J2SE��J2EEӦ�ó�ʽ������CPU���̺߳��ڴ�����������һ��ǿ���Ӧ���С�JProfiler��GUI���Ը�������ҵ�����ƿ����ץס�ڴ�й©��memory leaks������������̵߳����⡣��������ĸ�����ռ�õ��ڴ�Ƚ϶ࣻ�ĸ�����ռ�ýϴ��CPU��Դ�ȣ�����ͨ��ʹ��Jprofiler�����SparkӦ����localģʽ������ʱ������ƿ�����ڴ�й©�����
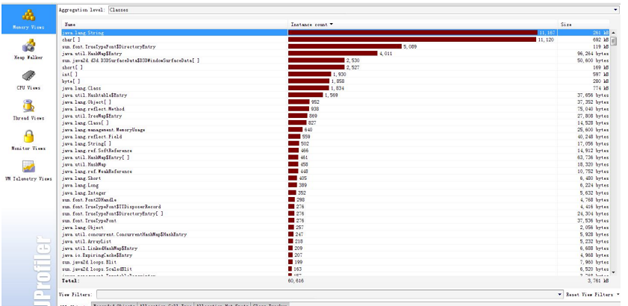
�����������߿���ֱ��ͨ���ṩ�������˽���ϸ��ʹ�÷�����
Spark����
��Spark��Ⱥ���жȡ�
��Spark��Ⱥ�����£�ֻ���㹻�ߵIJ��жȲ���ʹϵͳ��Դ�õ���ֵ����ã�����ͨ����spark-env.sh������Executor��������ʹ����Դ��Standalone��YARN��ʽ��Դ�ĵ��ȹ����Dz�ͬ�ġ�
��Standaloneģʽ��:
1. ÿ���ڵ�ʹ�õ�����ڴ�����SPARK_WORKER_INSTANCES*SPARK_WORKER_MEMORY��
2. ÿ���ڵ�����task����SPARK_WORKER_INSTANCES*SPARK_WORKER_CORES��
��YARNģʽ�£�
1. ��Ⱥtask���жȣ�SPARK_ EXECUTOR_INSTANCES* SPARK_EXECUTOR_CORES��
2. ��Ⱥ�ڴ�������(executor����) * (SPARK_EXECUTOR_MEMORY+ spark.yarn.executor.memoryOverhead)
+(SPARK_DRIVER_MEMORY+spark.yarn.driver.memoryOverhead)��
�ص�ǿ����Spark��Executor��Driver�������Ӷ��ڴ��С��Executor�ˣ���spark.yarn.executor.memoryOverhead���ã�Ĭ��ֵexecutorMemory * 0.07��384�����ֵ��Driver�ˣ���spark.yarn.driver.memoryOverhead���ã�Ĭ��ֵdriverMemory * 0.07��384�����ֵ��
ͨ�����������������������Ⱥ���жȣ���ϵͳͬʱִ�е�������࣬��ô������ͬ�������жȸ��ˣ����Լ�����ѯ����������˵�������һ��stage��100task�����ж�Ϊ50����ôִ�������������Ҫ��ѯ���β�����ɣ�������ж�Ϊ100����ôһ�ξͿ����ˡ�
��������Դ��ͬ����������жȸ��ˣ���Ӧ��Executor�ڴ�ͻ���٣�������Ҫ����ʵ��ʵ��Э���ڴ��core�����⣬Spark�ܹ��dz���Ч��֧�ֶ�ʱ���������磺200ms������Ϊ������е�������JVM�������ܼ�С�������������ģ�Standaloneģʽ�£�core��������1-2��������core���������г��䡣
��Spark��������������
Spark����������stage�е���ʼ������RDD��partition֮������������������Ҫ�˽�ÿ��RDD��partition�ļ��㷽������SparkӦ�ô�HDFS��ȡ����Ϊ����HadoopRDD��partition�зַ�����ȫ�̳���MapReduce�е�FileInputFormat�������partition������HDFS�Ŀ��С��mapred.min.split.size�Ĵ�С���ļ���ѹ����ʽ�ȶ�����ؾ�����������Ҫ�μ�FileInputFormat�Ĵ��롣
��Spark�ڴ���š�
�ڴ��Ż�����������Ŀ��ǣ�������ռ�õ��ڴ棬���ʶ���������Լ�����������ռ�õĿ�����
1. ������ռ�ڴ棬�Ż����ݽṹ
Spark Ĭ��ʹ��Java���л�������ȻJava����ķ����ٶȸ��죬����ռ�õĿռ�ͨ�������ڲ����������ݴ�2-5����Ϊ�˼����ڴ��ʹ�ã�����Java���л���Ķ�����������о�һЩSpark������http://spark.apache.org/docs/latest/tuning.html#tuning-data-structures���ṩ�ķ�����
��1��ʹ�ö��������Լ�ԭʼ���ͣ�primitive type�����������Java����Scala�����ࣨcollection class)��fastutil ��Ϊԭʼ���������ṩ�˷dz�����ļ����࣬�Ҽ���Java����⡣
��2�������ܵر�����ú���ָ���Ƕ�����ݽṹ������С����
��3�����Dz�������ID����ö�������Ա����String���͵�������
��4������ڴ�����32GB������JVM����-XX:+UseCom-pressedOops�Ա㽫8�ֽ�ָ���ij�4�ֽڡ����ͬʱ����Java 7���߸��߰汾������JVM����-XX:+UseC-----ompressedStrings�Ա����8����������ÿһ��ASCII�ַ���
2. �ڴ����
��1����ȡ�ڴ�ͳ����Ϣ���Ż��ڴ�ǰ��Ҫ�˽⼯Ⱥ���ڴ����Ƶ�ʡ��ڴ���պķ�ʱ�����Ϣ��������spark-env.sh������SPARK_JAVA_OPTS=��-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps $ SPARK_JAVA_OPTS������ȡÿһ���ڴ���յ���Ϣ��
��2���Ż������С��Ĭ�����Spark���������ڴ棨spark.executor.memory����60%������RDD���档�����������ִ���ڼ䣬��40%���ڴ�����������ж�����������������ٶȱ�����JVMƵ�������ڴ���գ������ڴ�ռ䲻�㣬��ô���ͻ����С���ÿ��Լ����ڴ����ģ����Խ���spark.storage.memoryFraction�Ĵ�С��
3. Ƶ��GC����OOM
����������������Ҫȷ�������Ƿ�����Driver�˻�����Executor�ˣ�Ȼ���ڷֱ�����
Driver�ˣ�ͨ�����ڼ������Ľ���������յ�Driver�˵��£���Ҫ����Driver�˵��ڴ��������߽�һ�����ٽ������������
Executor�ˣ�
��1�����ⲿ������Ϊ�����Stage������Stage�г���GCͨ������Ϊ��Map�����map-side-combineʱ������group��������ġ����������������partition����������task��������������ÿ��taskҪ���������ݣ�������GC�Ŀ����ԡ�
��2����shuffle��Ϊ�����Stage������Stage�г���GC��ͨ��ԭ��Ҳ�Ǻ�shuffle�йأ�����ԭ����ijһ������group�����ݹ��࣬Ҳ������ν��������б����İ취��������shuffle��task������������SparkSQL������SET spark.sql.shuffle.partitions=400���������shuffle��task��������⣬˵�����������б�����أ�ijһ��group������ԶԶ����������group����Ҫ����ҵ�����Ͻ��е�����Ԥ����Խϴ��group������������
���������
ʹ��Kryo���л�����ΪKryo���л������Java�����л���С�������١����巽����spark-default.conf ������spark.serializerΪorg.apache.spark.serializer.KryoSerializer ��
�ο��ٷ��ĵ���http://spark.apache.org/docs/latest/tuning.html#summary�������ڴ����������ԣ�����Kryo����Լ����л��ܹ����������صĴ����⡣
��Spark ���̵��š�
�ڼ�Ⱥ�����£�������ݷֲ������ȣ���ɽڵ������ֲ������ȣ�Ҳ�ᵼ�½ڵ��Դ���ݲ���Ҫ�����紫�䣬�Ӷ����Ӱ��ϵͳ���ܣ���ô���ڴ��̵�������Ƚ�������Դ�ֲ����ȡ�����֮�⣬�����Զ�Դ������һ���Ĵ�����
1. ���ڴ�������Χ�ڣ���Ƶ�����ʵ��ļ������������ڴ��У�
2. ������̳�ԣ�������ʵ�����Դ������HDFS�ϵı������Լ������紫�䣻
3. Spark֧�ֶ����ļ���ʽ��ѹ����ʽ�����ݲ�ͬ��Ӧ�û������к�����ѡ�����ÿ�μ���ֻ��Ҫ���е�ij���У�����ʹ����ʽ�ļ���ʽ���Լ��ٴ���I/O�����õ���ʽ��parquet��rcfile������ļ�����ԭ�ļ�ѹ�����Լ��ٴ���I/O�����磺gzip��snappy��lzo��
��������
�㲥������broadcast��
��task����Ҫ����һ��Driver�˽ϴ������ʱ������ͨ��ʹ��SparkContext�Ĺ㲥��������Сÿһ������Ĵ�С�Լ��ڼ�Ⱥ��������ҵ�����ġ��ο��ٷ��ĵ�http://spark.apache.org/docs/latest/tuning.html#broadcasting-large-variables��
�����Ʋ����
�Ʋ���ƺ������Ⱥ�У�ijһ̨�����ļ���task�ر������Ʋ���ƻὫ������䵽��������ִ�У����Spark��ѡȡ������Ϊ���ս����
��spark-default.conf �����ӣ�spark.speculation true
�Ʋ���������¼��������йأ�
1. spark.speculation.interval 100��������ڣ���λ���룻
2. spark.speculation.quantile 0.75�����task�İٷֱ�ʱ�����Ʋ⣻
3. spark.speculation.multiplier 1.5���������������ٱ�ʱ�����Ʋ⡣
�ܽ�
Sparkϵͳ�����ܵ�����һ���ܸ��ӵĹ��̣���Ҫ��Spark�Լ�Hadoop���㹻��֪ʶ��������ҵ��Ӧ��ƽ̨��Spark�����洢��HDFS��������ϵͳ��Ӳ���ȶ�����涼������ܲ����ܴ��Ӱ�졣�����ڶ������ܼ�ع��ߣ����ǿ��Ժܺõ��˽�ϵͳ�����ܱ��֣�������������ܵľ�����е����� |






