|
Heroku已经能很好的满足很多人的需求,但当我们不断壮大,问题和瓶颈频现,为此我们开始寻求解决之道,首先关注的是开源社区中支持Docker的平台,如Flynn、Deis、CoreOS、Kubernetes等,但都不理想,后通过使用亚马逊ECS,最后确定了Empire,用Empire完成从Heroku到亚马逊ECS的无痛迁移,过程与挑战都在文中做了说明。
今天,Remind开源了我们自我托管的PaaS系统 - Empire。Empire能为你提供一个基于Docker容器的集群,符合12因子应用规范,基于强大的亚马逊EC2
Container Service(ECS,EC2 容器服务)构造而来,具有功能完善的的命令行界面。
已经有了Heroku,且Heroku已经能很好的满足很多人的需求,为什么我们还需要自己造一套Empire这样的东西?这篇文章讲述了为什么我们决定从Heroku迁移出来,我们遇到了哪些挑战,和我们怎么用Empire完成从Heroku到亚马逊ECS的无痛迁移。
讲讲一点历史
在2011年的时候,Remind还是一个托管在Heroku的一个整体单一的Rails应用。那个时候一切都很简单:一个应用使用几个dynos已经足以应付当时不大的流量。当时我们选择Heroku因为它让我们能专注于开发产品而无需关心基础设施(infrastructure),对于一个当时不到十个人的团队来说,这很重要。回想过去,这无疑是我们做的最好的一个决定。
但我们开始壮大
而在今天,事情变得有点不同了。我们有超过50个员工,2500万客户,50多个后端服务支撑着产品 - 其中有些是产品的核心部分,其他则是不同团队开发出来用来满足各种需求的。为了满足这种规模,我们用了超过250个dynos。
我们慢慢发现,我们的发展模式在很多方面看来是独一无二的。我们打造的是一个给老师使用的产品,在学生的返校季业务会迅速增长
- 每天有多达到35万新用户,超过500万条消息,每30分钟系统就会出现一个峰值(heavy spike)。
我们开始意识到,如果想有一个能够满足我们业务增长的基础设施,Heroku可能无法完成这一目标。我们遇到的主要问题有:
1.缺乏对安全的控制。我们十分推崇微服务/SOA的架构,然后我们有一大堆内部的服务。在Heroku中,每一个服务都暴露在外网,这些服务本身难免有自己的弱点(nasties),因而需要身份认证,DoS防御(DoS
mitigation),不断的打安全补丁等。这跟我们想象的有很大不同。
2.缺乏可见性(visibility):我们需要对我们的应用的性能有更加透的认识。尽管Heroku提供了这种可能,却跟我们想象中的仍有距离,我们需要知道在操作系统和主机的层面都发生了什么。
3.缺乏灵活性:我们需要构建性能更加强大,不仅仅只是受HTTP管控的服务。我们无法控制路由层(routing
layer),因而实现一些中间件如限制速率,添加常见的认证和将路由某路径的请求到不同的上游服务器等超过了其本应有的难度。
我们的寻道之路
大约半年前,我们开始谈论如何才能从Heroku迁出。我们列出了必须满足的条件和要达到的目标:
1.AWS:我们当时已经使用了很多亚马逊的服务,如Redshift和DynamoDB,因而能直接运行在EC2上是必须的要求。这也能让我们把这些数据存储锁定到特定的安全组(security
groups)。
2.简易化运维(Operational Simplicity):Heroku在让运维的过程(如部署,扩展,配置更新)简易化方面做的十分出色。我们也希望迁移后仍然能够保持这个水准。我们不愿意看到部署新应用的时运维人员必须到场,并且我们希望部署能遵循共同的模式。
3.Docker:这不是一个硬性的要求,但是我们还是想继续使用容器来作为部署的单元,因为:
容器能隔离依赖,封装的包移植性高,易于发布,很类似Go的包。
容器提供了更好的开发环境,因为开发和生产环境的相似度(dev/prod
parity)更高。
容器能限制我们部署的时候那些不确定的部分。基础设施(Imutability
in infrastructure)中的不可变性有很大的好处。
容器能更有效地利用资源,降低成本。
4.容错性(Resilience):我们对宕机这一问题的态度十分严肃。
并且我们知道运行着我们应用和服务的平台本身应该健壮且容错性高。同时,无宕机部署也是要求的一部分。
方案一:使用时下时髦的技术(all the Alphas)
我们开始调查开源社区中支持Docker的平台,我们不想去创造事物。当时,两个看起来最有希望的系统是Flynn和Deis。因为一些原因,我们团队不是很放心将这些项目投入生产环境使用。Flynn当时还尚未发布稳定版本,且正在进行不小的架构调整。并且他们的负载使用的均为完全自有的方案,而一些成熟的方案如HAProxy、Nginx或者ELB都没有用到。我们简单地试用了一下Deis,最终觉得其过于复杂。同时我们也了解到,尚未有一个规模与我们相当且在生产环境使用这两种技术的公司。
基于我们的需求,Remined的一个小队工程师开启了Empire项目,我们借鉴了Deis和Flynn的项目的一些理念,也借鉴了其他项目的长处如Netflix的Asgard和SoundCloud的Bazooka。起初我们决定以CoreOS为基础,使用fleet作为后端来调度机器集群。但是按照我们最初的设计决定,调度的后端应该是插件式(pluggable)的。我们有一个自定义的路由和服务发现的层,使用的是由confd和registrator进行配置的ngixn,这都运行的很好,直到我们开始进行错误测试,我们才开始遇到了很多etcd脆弱的问题(当时etcd的版本还是0.4),也遇到了fleet当中的bug
,并且我们尚未解决不宕机部署的问题。
我们清醒的认识到我们需要一个比fleet更好的调度后端。在研究Kubernetes的时候我们发现其需要运行网络覆盖层(network
overlay))于是我们把它给否决了,因为我们实在不想自己运行并管理集群。
方案二:使用亚马逊ECS
尝试将很多新的或者尚在快速迭代的项目拼凑成一个生产级别的Pass平台结果证明只会给人带来的失望和过头。很显然,我们应该退一步以求海阔天空,尽量简化并剔除不稳定的组件。
巧合的是这个时候亚马逊的ECS发布了,我们立即发现到它几乎能解决我们遇到的所有问题:
这是一个第三方管理(managed service)的服务,因而我们不需要自己运行和维护自己的集群服务。
他集成了AWS的ELB(Elastic Load Balancing),这能解决零宕机,connection
draining和通过基于DNS的服务发现。
失效模式(failure mode)的表现的跟我们预期的效果一样。我们可以将机器池的所有主机(entire
pool of machines)停止,并且当新的机器启动的时候整个服务又能恢复正常。
我们对AWS的服务更加放心。AWS的服务,发展快而且步履稳定,基于它构建生产级别的PaaS十分完美。
经过一些起初的调查和原型,我们把调度后端换回到亚马逊ECS。每一个定义在Procfile里面的进程都会被直接映射成一个亚马逊ECS中的一个服务。因为亚马逊ECS集成了ELB,我们也决定弃用自己的路由层(routing
layer)并使用将ELB依附到一个app的web进程。这个带来一个问题,我们该如何解决系统中的服务发现问题?我们决定选用使用一个私有的Route53然后创建CNAME记录指向每一个应用的web进程。我们使用DHCP的选项集(option
sets)来设置搜索路径为.empire来达到服务只需要知道他们想交流的服务的名称即可(如:http://acme-incc)。我们去除了系统中不稳定的地方,如etcd;我们的主机集群现在只是简单的安装有Docker和亚马逊ECS的代理的Ubuntu主机。
对于我们的架构,这个系统运行十分良好。我们有一个router的应用依附在对公网可见的ELB(在Empire里,这个应用默认是只内部可见,但是可以通过给其添加一个域名让其公共可见)。
这个应用跑着一个nginx,负责到相应的私有应用的路由,不管这是我们的API,Web的控制台(dashboard)或者其他服务。它也会负责请求的ID生成所以我们可以方便的追踪请求在服务间的移动。这里最大的好处是现在router可以以Empire中其他应用一样的方式来管理;一样的部署方式;一样的配置方式;并且可以轻易的开发环境用运行起来,只需要一个简单的docker
run remind101/router命令。在以后,它甚至可以换成如Kong这样的东西。
Empire能给我带来什么?
如今Empire是一个运行简单,自我托管的PaaS,其通过在亚马逊ECS上一个轻量的层的方式实现。他实现了Heroku的一部分Platform
API,这意味着你可以使用hk或者heroku CLI客户端,或者我们的empCLI。这里是一些Empire易用的例子:
部署一个Docker注册表中新的应用就如敲一个emp deploy <image>:<tag>一样简单:
$ emp deploy remind101/acme-inc:latest |
应用部署后我们可以列出这些应用:
$ emp apps acme-inc Jun 4 14:27 |
或者你可以列出那些正在运行的应用:
$ emp ps -a acme-inc v2.web.217e2ddd-c80c-41ed-af16-663717b08a3f 128:20.00mb
RUNNING 1m "acme-inc server” |
我们可以扩展一个在Procfile中单独的一个进程:
$ emp scale worker=2 -a acme-inc $ emp ps -a acme-inc
v2.web.217e2ddd-c80c-41ed-af16-663717b08a3f 256:1.00gb RUNNING 1m "acme-inc server"
v2.worker.6905acda-3af8-42da-932d-6978abfba85d 256:1.00gb RUNNING 1m "acme-inc worker"
v2.worker.6905acda-3af8-42da-932d-6978abfba85d 256:1.00gb RUNNING 1m "acme-inc worker” |
甚至可以明确的指定CPU和内存的限制:
$ emp scale worker=1:256:128mb -a acme-inc # 1/4 CPU Share and 128mb of Ram |
我们可以列出以前的发布版本:
$ emp releases -a acme-inc v1 Jun 4 14:27 Deploy remind101/acme-inc:latest
v2 Jun 11 15:43 Deploy remind101/acme-inc:latest |
我们也可以在几秒钟内回滚到以前的版本:
$ emp rollback v1 -a acme-inc Rolled back acme-inc to v1 as v3. |
这些背后都发生在我们控制的硬件上面。
现在可以上生产环境吗?
Empire现在还没有到1.0(写这篇博文的时候版本为0.9.0),但是我们过去几周,我们亚马逊上的ECS大部分的应用和服务都依靠Empire来管理,其结果十分稳定。这些应用在从Heroku迁移到Empire后的性能显著提升了。基本上我们能观察到99%的请求的响应时间有两倍的减少,变化和峰值也更少了。这里是一些例子:
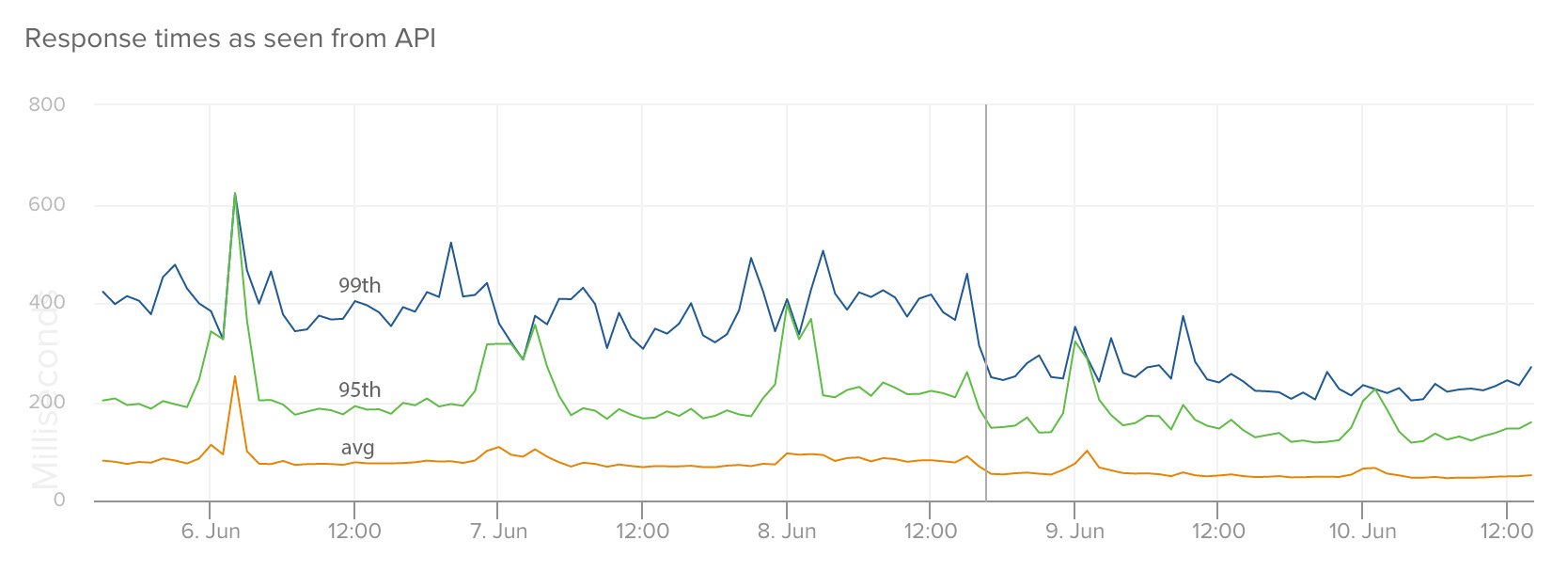
这个图显示了在我们从Heroku到亚马逊ECS迁移以后,我们的从API(RTT)上看到,文件服务的响应时间:
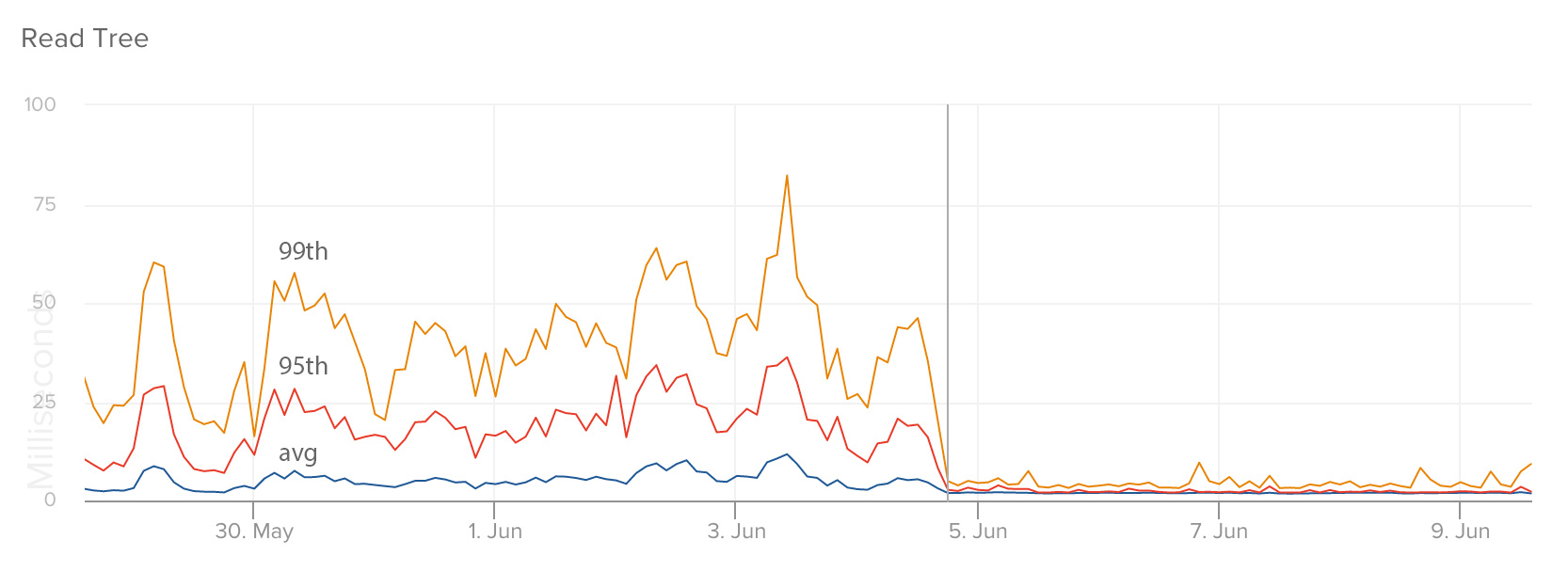
这个图显示了我们服务中特定端点(endpoint)的响应时间,其作用是用来管理一个用户的未读消息数。
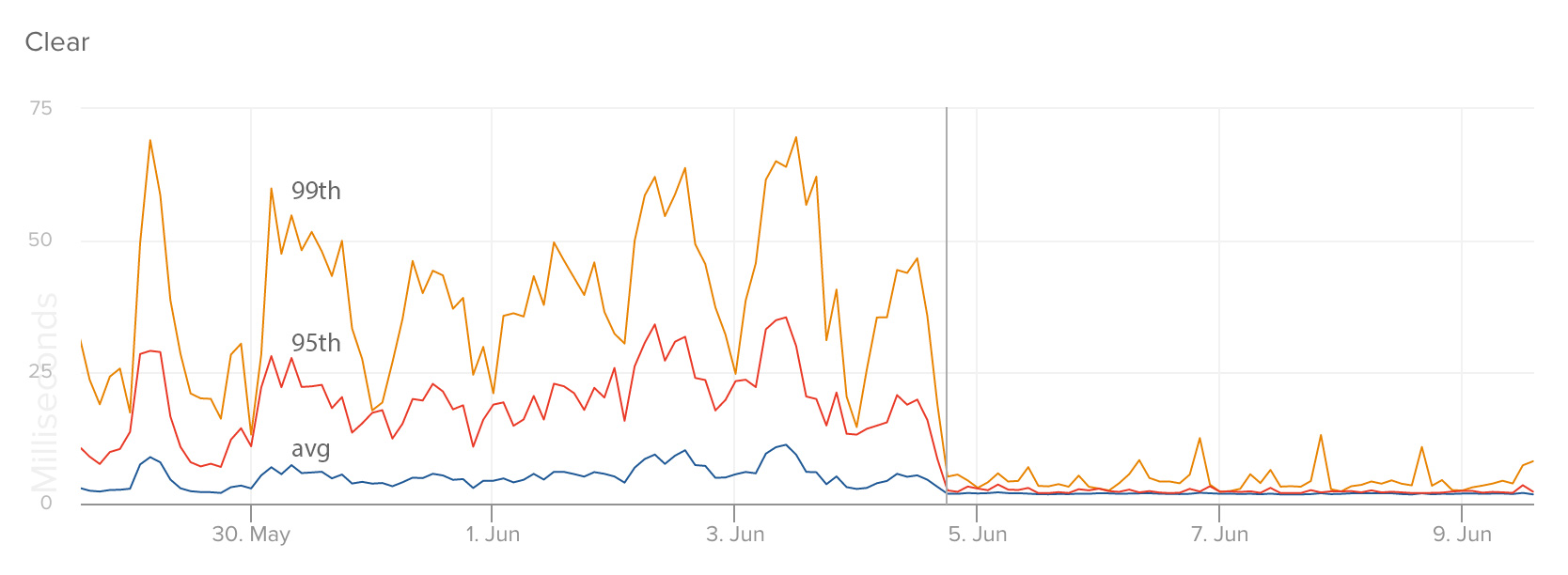
这是我们的API中看到的响应时间的改变(这个应用仍运行在Heroku上面;我们期待在转到Empier后可以减到更少,然后更加平稳)
我应该使用它吗?
这看情况。如果你只是一个小的创业公司,说实在的,使用Heroku就够了。因为这是部署应用最简单的方式。Empire并不是没有成本;你还需要创建你自己的日志和数据量化方面的基础服务(logging
and metrics infrastructure)(这一部分我会在未来的博客里面讲),并且Empire仍处于频繁的开发阶段。我们仍是Heroku的忠实用户,我们会继续在上面运行一些非核心的应用。但是如果你碰到了一些和我们一样的瓶颈,我们希望Empire能一样让你的基础设施更上一层楼。
你们为什么不使用XXX?
我们的终极目的是为我们在Remind碰到的问题,寻求一个简单而健壮的方案。尽管我们不畏惧使用过一些热门的新技术,但是我们更看重稳定且能达到目的(just
work)的技术的价值,它们不会半夜将你吵醒。我们平台的绝大部分都是基于这些稳定的技术创建的,如nginx,postgres,rabbitmq和ELB,并且Amazon
ECS被证明特别的稳定(尽管最新发行的版本 )。
如果有一件事情是确定的,那就是我们的基于容器的域的基础设施在快速的改变。我们现在创造的东西,在1-2年期那还不可能。感谢Dcoker和Amazon
ECS这样的项目,很可能再接下来的念头随着容器化技术变得越来越平常。
未来
我们仍然对Empire有宏大的计划,如将负载均衡器应用到任何进程上,而不仅限于web进程;扩展Profile以在版本控制中支持健康检查,暴露配置;支持sidekiq容器所你可以在linked容器里面运行如statd或者nginx等服务。我们也同时希望,最终也支持使用Kubernetes来作为调度后端。
总之我们整个团队满意现在迁移到亚马逊ECS和Empire之上的成果,我们将其开源希望它也可以帮助到你。 |






