| еЊвЊ
12306ЛьКЯдЦГЩЙІАИР§ИјгшзюДѓЕФЦєЗЂОЭЪЧДђдьвЛИіДгЯТЕНЩЯЖМПЩзіЕЏадРЉеЙЕФЁАдЦгІгУЁБЯЕЭГЃЌЦѓвЕПЭЛЇПЩНЋЙиМќвЕЮёЕФЁАзгЯЕЭГЁБВПЪ№дкзЪдДЗсИЛЕФдЦМЦЫуЪ§ОнжааФЃЌЁАдЦЛЏЁБКѓЕФзгЯЕЭГПЩЁААДашЁБЛёШЁЫљашвЊЕФЗўЮёЦїащЛњзЪдДКЭЖЏЬЌЕїећЭјТчДјПэЃЌРћгУетаЉзЪдДНтОідкИпСїСПКЭИпИКдиЧщПіЯТЃЌЯЕЭГЮоЗЈПьЫйЕЏадРЉеЙЕМжТЕФадФмЦПОБЁЃ
ДЫЦЊЮФеТСаОйВЛЭЌРраЭЕФЯЕЭГИФдьЧЈвЦЕНдЦЦНЬЈЗНАИЃЌДгИФдьЫМТЗЬНЬжЃЌЯЕЭГПђМмЩшМЦКЭЯюФПЪЕЪЉЕФећИіЧЈвЦЙ§ГЬЃЌЙЉДѓМвВЮПМКЭНЛСїЁЃдкДЫвдPivotal
GemfireдЦЦНЬЈЮЊР§згЃЌ вђЮЊЫќвбгаДѓЙцФЃВПЪ№ГЩЙІАИР§ЁЃ ПЭЛЇITЛЗОГЪЧЮхЛЈАЫУХЃЌ ЖдЯЕЭГИФдьЕФЫМТЗКЭФПЕФвВВЛОЁЯрЭЌЃЌGemfireЪЧВЛДэЕФбЁдёЃЌЕЋЫќВЛЪЧЮЈвЛЕФбЁЯюЁЃ
ЧАбд
дкЙ§ШЅ20ФъЃЌЯЕЭГМмЙЙЪІзюГЃгУЕФЯЕЭГПђМмЪЧШ§ВуМмЙЙЩшМЦЃЌ МДWebВуЃЌ гІгУвЕЮёТпМВуКЭЪ§ОнПтВуЃЛWebВуКЭгІгУТпМВуПЩЫцзХвЕЮёБфЛЏзіПьЫйЕЏадРЉеЙЃЌЕЋОјДѓВПЗжЙиЯЕаЭЪ§ОнПтВуЮоЗЈЪЕЯжДЫЙІФмЁЃ
дкдЦМЦЫуЃЌДѓЪ§ОнКЭвЦЖЏЛЅСЊЭјЪБДњЃЌгЩгквЕЮёГЩГЄПьЫйЃЌЗўЮёЖрбљЛЏЃЌ Ъ§ОнСПМБОчдіМгЃЌгУЛЇЖдЯЕЭГЯьгІЪБМфгаИќбЯИёЕФвЊЧѓЃЛ
дкИпИКдиЧщПіЯТЃЌЮоЗЈКсЯђРЉеЙЕФЪ§ОнПтВуЭљЭљГЩЮЊЯЕЭГадФмЕФАэНХЪЏЁЃ
дкДЫЦЊЮФеТЃЌЬжТлжиЕуЪЧДгШэМўжаМфМўЦНЬЈЃЈPaaSЃЉКЭгІгУЯЕЭГЃЈSaaSЃЉВуУцГіЗЂЃЌЪЙгУЁАЗжВМЪНФкДцЪ§ОнЭјИё(
In Memory Data Grid)ЁБММЪѕЃЌНЋДЋЭГМмЙЙИФдьЧЈвЦЕНдЦЦНЬЈЁЃЯЕЭГИФдьгаЖржжВЛЭЌЕФЗНЪНЃЌжївЊЪЧвЊПДИФдьЕФФПЕФКЭЫљЪмЕФЯожЦРДОіЖЈ;
ЮЊСЫОпЬхЛЏЫЕУїЃЌ ЮвУЧвдЯТСаШ§ИіАИР§ЬсЙЉИјЖСепВЮПМКЭНЛСїЁЃ
1.12306ЯюФПЃКећИіЪлЦБЛЗНкЕФвЛЯЕСаКЫаФзгЯЕЭГЖМОЙ§ИпЖШЁАдЦЛЏЁБЁЃ
ФПЕФЪЧПЩвдНЋдЦЛЏКѓЕФзгЯЕЭГЁААДашЁБСщЛюВПЪ№дкВЛЭЌЕФЪ§ОнжааФЃЈЙЋгадЦЛђЫНгадЦЃЉЃЌЬсЙЉгХжЪЗўЮёЁЃ дЦЛЏЕФЪжЖЮЪЧНЋзгЯЕЭГвЕЮёТпМКЭЪ§ОнЖМЗХдкGemfireМЏШКЩЯжДааЃЌ
РћгУMap ReduceЕФММЪѕЃЌНЈСЂПЩЕЏадРЉеЙЦНЬЈЃЌЬсЙЉЁАИпадФмCPUМЦЫуФмСІЁБЁЃ
2.ФГЪаЩчБЃЯюФПЃКВЩШЁЖЬЦНПьЕФОжВПЁАзгЯЕЭГдЦЛЏЁБЃЌеыЖдгаИпВЂЗЂашЧѓЛсЕМжТЦПОБЕФзгЯЕЭГНјааИФдьЁЃИФдьЕФЪжЖЮЪЧНЋзгЯЕЭГвЕЮёТпМКЭЪ§ОнЗХдкGemfireНкЕуЩЯжДаа,
НЈСЂПЩЕЏадРЉеЙЦНЬЈЃЌРћгУGemfireЗжВМЪНВЂааВщбЏММЪѕРДНтОіЁАИпВЂЗЂВщбЏЁБЕФвЊЧѓЁЃ
3.Н№ШкЕЅЮЛPOCВтЪдЯюФПЃК ЮЪЬтдкгкЯЕЭГЕФВщбЏвЕЮёСПЖрЃЌЙиСЊБэИёЖрЃЌдкИпВЂЗЂЧщПіЯТЃЌВщбЏЗДгІЪБМфГЄЁЃ
POCФПЕФЪЧвЊбщжЄдкВЛИќИФзгЯЕЭГвЕЮёТпМЯожЦЯТЃЌвдзюаЁЕФДњМлЃЌЖдЁАЪ§ОнЗУЮЪВу ЃЈDAOЃЉЁБНјаааоИФЃЌНЈСЂПЩРЉеЙЕФЁАФкДцЪ§ОнЛКДцВуЁБЃЌНтОіЁАИпВЂЗЂВщбЏЁАЕФЗНАИЃЛСэЭтЃЌЛЙгаЪ§ОнПтгыGemfireМЏШКжЎМфЁАЪЇаЇзЊвЦ
fail overЁБЕФЩшМЦЁЃ вдДЫЮЊЛљДЁЃЌвдКѓдйНЋвЕЮёТпМж№НЅЗХЕНGemfireЦНЬЈЃЌНјааИФдьЩ§МЖЁЃ
вЛЁЂ12306 ЛьКЯдЦЕФЦєЪО
дкЧАСНЦЊЮФеТЬсЕНЃЌ2012ФъДКдЫКѓ12306ГаАьЕЅЮЛ-ЬњПЦдКв§ШыЁБЗжВМЪНФкДцЪ§ОнЭјИёЁБ ММЪѕЃЌНЋгрЦБМЦЫу/ВщбЏзгЯЕЭГИФдьЧЈвЦЕНGemfireдЦЦНЬЈЃЌОжВПНтОі12306ЕФжївЊЦПОБЃЛИФдьКѓЕФзгЯЕЭГдк2013ФъДКдЫЪБЩЯЯпЃЌЦфаЇЙћЪЧЯджјЕФЃЌЫфШЛећИіЯЕЭГдЫааЛЙЪЧгаЁБПЈЃЌЖйЁБЕШВЛзужЎДІЃЌЕЋЬњПЦдКЖдДЫММЪѕЩюОпаХаФМсГжИФИяЃЌВХгаКѓајвЛСЌДЎЕФзгЯЕЭГИФдьГіТЏЁЃдк2015ФъДКдЫЃЌНЈСЂСНЕиШ§жааФЛьКЯдЦЕФЗўЮёФЃЪНЃЌНЋДѓВПЗжгрЦБВщбЏСїСПв§ЕМЕНАЂРядЦЬсЙЉВщбЏЗўЮёЃЛДЫОйЕФФПЕФЪЧвЊНшжњдЦМЦЫуЪ§ОнжааФЕФзЪдДЃЌЁАСйЪБадЁБНтОідкДКдЫЦкМфгЩгкЛЅСЊЭјЙКЦБКЭЫЂЦБШэМўЫљв§ЗЂЕФФбдЄВтЃЌИпСїСПЃЌКЭИпВЂЗЂЧыЧѓЃЌНЕЕЭЯЕЭГВЛЮШЖЈЕФЗчЯеЁЃ
12306ЛьКЯдЦГЩЙІАИР§зюДѓЕФЦєЗЂЪЧИјЦѓвЕПЭЛЇКЭеўИЎВПУХДјРДаТЕФЫМТЗЃЌОЭЪЧНЋЙиМќвЕЮёЕФЁАзгЯЕЭГЁБИФдьЧЈвЦЕНдЦЦНЬЈМмЙЙЃЌИљОнЪЕМЪЧщПіЃЌНЋЁАдЦЛЏЁБКѓЕФзгЯЕЭГВПЪ№дкзЪдДЗсИЛЕФдЦМЦЫуЪ§ОнжааФЃЈЫНгадЦЛђЙЋгадЦЃЉЁЃ
Р§ШчЃЌ 12306КЫаФЯЕЭГдкОЙ§ШЋУцИФдьКЭгХЛЏКѓЃЌ УПИідЦЛЏКѓЕФзгЯЕЭГЖМОпгаЬиЖЈЕФЖРСЂадЃЌвђЮЊЯрЙиЪ§ОнЖМЗХдкGemfireФкДцЪ§ОнЭјИёНкЕуЃЛетвтЮЖзХетаЉзгЯЕЭГРрЫЦЁАдЦЁБвЛбљЃЌ
ПЩвдЫцзХвЕЮёашЧѓБфДѓЛђБфаЁЃЌвЛЗжЮЊЖрЃЌШЮадЕФЦЏвЦЕНЖрИіВЛЭЌЪ§ОнжааФРДаЭЌКЯзїЃЌБмУтдкITЩшБИЗНУцЕФжиИДЭЖзЪЃЌ
ВЂЬсИпзЪдДЕФЪЙгУТЪЁЃ
дЦЛЏКѓЕФзгЯЕЭГВПЪ№дкЖрЪ§ОнжааФЃЌашвЊЬиБ№зЂвтЯТСаСНЕуНЈвщ ЃК
1.ШчЙћНЋзгЯЕЭГВПЪ№дкЙЋгадЦЬсЙЉЗўЮёЪБЃЌЪ§ОнвўЫНЕФБЃЛЄКЭАВШЋадгІЮЊЪзвЊПМТЧЁЃ
2.ШчЙћЙцЛЎНЋзгЯЕЭГВПЪ№дкЖрЪ§ОнжааФЪБЃЌдкЯЕЭГПђМмЩЯБиашПМТЧЩЯЯТгЮзгЯЕЭГжЎМфЕФЪ§ОнДЋЪфЛђЭЌВН/вьВНЕФЩшМЦЁЃ
вд12306ЮЊР§ЃЌСНЕиЖржааФЛьКЯдЦЕФМмЙЙЪОвтЭМШчЯТЃЛдкДКдЫЪлЦБИпЗхЦкМфПЩвдНЋгрЦБВщбЏЙІФмВПЪ№дкЖрИіЙЋгадЦЪ§ОнжааФЬсЙЉПьЫйЗўЮёЃЈР§ШчАЂРядЦКЭЕчаХЬьвэдЦЃЉЁЃ
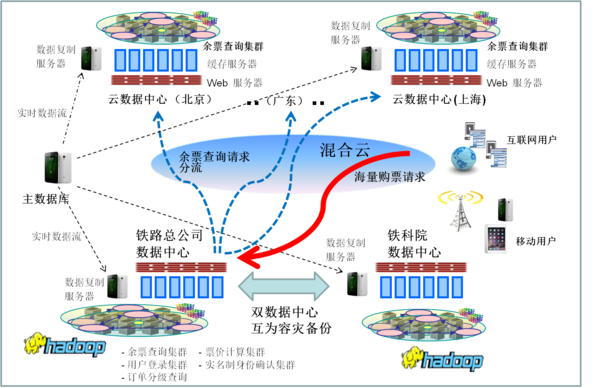
ЖўЁЂЯЕЭГИФдьЧЈвЦЕФЫМТЗКЭашЧѓ
ЫцзХЦѓвЕГЩГЄЃЌЖдгквЛИіИДдгЕФДѓЯЕЭГРДЫЕЃЌ ЦфвЕЮёЙІФмВЛЖЯдіМгЃЌЗўЮёЗНЪНЖрбљЛЏЃЌЪ§ОнДцДЂСПдНРДдНДѓЃЌЕЋЯЕЭГадФмдНРДдНТ§ЃЌЖјгУЛЇЖдЯьгІЪБМфЕФвЊЧѓдНРДдНбЯИёЃЛгШЦфЪЧдкЙ§ШЅ5ФъРяЃЌУПФъЖМгааТММЪѕЕФбнНј
ЃЈДѓЪ§ОнКЭЗжВМЪНФкДцЪ§ОнЦНЬЈЃЉКЭаТвЕЮёЕФбмЩњЃЈЮяСЊЭјгІгУЃЌЩчНЛгІгУЦНЬЈКЭвЦЖЏгІгУЃЉЁЃ
ЕБДЋЭГМмЙЙЯЕЭГвбж№НЅЮоЗЈТњзуШеЧїГЩГЄЕФвЕЮёашЧѓЪБЃЌгаСНжжЗНАИПЩЙЉбЁдёЃЌ вЛЪЧДггВМўзХЪжЃЌscale upЕФбЁЯюЃЌ
ОЭЪЧИќЛЛадФмИќЧПДѓЕФЗўЮёЦїЃЛЖўЪЧscale outЕФбЁЯюЃЌДгШэМўЦНЬЈзХЪжЃЌ НјаагІгУЯЕЭГИФдьЃЌВЩШЁЕЏадПЩРЉеЙЕФПђМмЩшМЦЁЃ
ИќЛЛгВМўЗўЮёЦїЪЧзюМђЕЅЕФзіЗЈЃЌ ЕЋвдКѓИќЛЛГЩБОЛсдНРДдНИпЃЌЯЕЭГадФмЬсЩ§ЪЧдНРДдНгаЯоЁЃ ШэМўгІгУЯЕЭГЕФИФдьЃЌЪЧвЛРЭгРвнДгИљБОзіЦ№ЃЌИФдьГЩБОЪЧгыЯЕЭГЕФИДдгЖШгаЙиЃЌЪЧашвЊШЋУцИФдьЃП
ЛЙЪЧбЁдёадЕФОжВПИФдь ЃПеташвЊИљОнЪЕМЪЪЙгУЧщПіРДОіЖЈЁЃ
еыЖдЯЕЭГЕФscale outЩшМЦЃЌШчЙћвЊЭЦЗвдЧАЕФМмЙЙЃЌжиНЈЯЕЭГЃЌФЧЪЧИіДѓЙЄГЬЃЌГ§ЗЧгаЯТСаШ§жгЧщПіЃК
1.ЯЕЭГвбОЪЧЧЇДЏАйПзЃЌ ЮоЗЈдйДђВЙЖЁвВЮоШЫКѓајЮЌЛЄ
2.дгаЕФПђМмЩшМЦвбгХЛЏЕНМЋжТЃЌЮоТлШчКЮгХЛЏЃЌЖМвбОЮоЗЈТњзуШевцдіМгЕФвЕЮёашЧѓЁЃ
Р§ШчЃЌ12306ОЭЪЧЕфаЭР§згЁЃ
3.вЕЮёСїГЬКЭзщжЏЙмРэЗНЪНгаОоДѓЕФБфЖЏЃЌ ашвЊжиНЈЯЕЭГ
ЗёдђЃЌзюЪЁЧЎКЭзюгааЇЕФЗНЗЈОЭЪЧеыЖдЯЕЭГЦПОБзіЁАОжВПИФдьЁБРДЬсИпадФмЃЌБЃЛЄЙ§ШЅЕФЭЖзЪЁЃР§ШчЃЌЩчБЃЯюФПОЭЪЧЕфаЭР§зг
дкДЫЦЊЮФеТЃЌЬжТлЕФжиЕуЪЧШчКЮНЋЯЕЭГИФдьЧЈвЦЕНдЦгІгУЦНЬЈЃЌ гЩгкУПИіЯЕЭГЖМгаЦфЬиЪтадКЭИДдгадЕФПЊЗЂБГОАЃЌЦфЩшМЦЕФЯЕЭГПђМмЃЌЫљВЩгУЕФШэМўЦНЬЈКЭПЊЗЂММЪѕвВЖМЫцзХЪБМфбнНјЖјВЛвЛбљЁЃ
вђДЫИФдьЕФЗНЪНашвЊвРОнЪЕМЪЕФЛЗОГРДНјааЁЃ
1. 12306 ЯЕЭГИФдьЫМТЗКЭашЧѓ ЈC АДНзЖЮж№ВНдЦЛЏКЫаФзгЯЕЭГ
дРДЯЕЭГЪЧЪЙгУStored ProcedureПЊЗЂЃЌЯЕЭГвбОгХЛЏЕНМЋжТЃЌКмФбдйНјвЛВНЬсЩ§адФмЁЃ
ШчЙћВЩгУscale upЕФгВМўЩ§МЖЃЌЭЖзЪЙ§гкХгДѓЃЛ ЫцзХЬњТЗЛљДЁНЈЩшВЛЖЯРЉДѓЃЌвЕЮёСПвВЛсЫцзХдіМгЃЌЮоЗЈБЃжЄгВМўЩ§МЖКѓЕФЯЕЭГадФмЛсТњзуЮДРДвЕЮёГЩГЄЕФашЧѓЁЃСэЭтЃЌ
ОЭЪЧДКдЫИпЗхЦкЙ§КѓИУШчКЮДІжУЙ§ЪЃЕФUnixаЁаЭЛњвВБиаыСаЮЊПМТЧЁЃ
ГаАьЕЅЮЛ- ЬњПЦдКОЙ§заЯИЦРЙРКѓЃЌШЯЮЊИпСїСПКЭИпВЂЗЂЮЪЬтБиашВЩгУдЦМЦЫуПЩЕЏадРЉеЙЕФЦНЬЈКЭММЪѕРДНтОіЁЃ
вдЗжВМЪНФкДцЪ§ОнЭјИёЁБ - GemfireММЪѕЮЊЧаШыЕуЃЌвдгрЦБМЦЫу/ВщбЏзгЯЕЭГЮЊЪдЕуЯюФПЁЃ
ВЩШЁЮШЭзЕФИФдьВпТдЃЌ ж№Фъж№ВНИФдьКЭгХЛЏЦфзгЯЕЭГЃЌНтОівЛЯЕСаЛЗНкЩЯЕФЦПОБЃЌБЃжЄдкИФдьЦкМфећИі12306ЯЕЭГЕФЮШЖЈдЫааЁЃ
дкИФдьГѕЦкЃЌаТОЩСНЬзЯЕЭГБиаыЭЌЪБВЂаадЫааЁЃ РћгУCDNЃЈContent
Delivery NetworkЃЉЕФСїСПЙмРэЙІФмЃЌ ж№НЅНЋСїСПМгбЙЕНGemfireМЏШКЃЌВтЪдМЏШКдкИпИКдиЯТЪЧЗёФмЦНЮШЙ§ЖЩИпЗхЪлЦБЦкЁЃ
ВЩгУЁАЖржиGemfireМЏШКЁБЯрЛЅБИЗнЕФЩшМЦЃЌЭЌЪБВЂаадЫааЃЌЮЊЮДРДЁАЖрЪ§ОнжааФЁБЕФВПЪ№ЕБЪдЕуКЭЦЬТЗЁЃ
2. ЩчБЃЯЕЭГИФдьЫМТЗКЭашЧѓ ЈC ЖЬЦНПьЕФОжВПзгЯЕЭГдЦЛЏ
ЩчБЃжЦЖШж№ФъИФИяЃЌаТБржЦзщжЏМмЙЙВЛЖЯРЉДѓЃЌаТвЕЮёВЛЖЯдіМгЃЌЪЁЪаЩчБЃШЫЪ§ДгЪ§АйЭђМЖБ№ЕНФГаЉШЫПкДѓЪЁГЌЙ§вкЕФМЖБ№ЃЛетаЉЩчБЃНЩЗбзЪСЯашвЊБЃДцДяЪ§ЪЎФъвдЩЯЃЌ
гРЫцвЛЩњЃЌ УПФъЖМгаЪ§АйTЩѕжСPСПМЖЕФЪ§ОнДцДЂЕЅЮЛЁЃЩчБЃЕЅЮЛБиаыПМТЧШчКЮДцДЂетаЉзЪСЯЃП ШчКЮдкДѓЪ§ОнСПЧщПіЯТЬсЙЉПьЫйВщбЏЗўЮёЃП
ШчКЮНЈЩшвЛИіITЦНЬЈФмЫцзХЮДРДвЕЮёГЩГЄЖјВЛЖЯЕФЕЏадРЉШнЃЌДЫЮЊжївЊЕФИФдьЫМТЗЁЃ
ЩчБЃЯЕЭГЪЧЖдЭтЕФЙЋЙВЗўЮёЦНЬЈгк2008ФъЩЯЯпЃЌДЫЦНЬЈЪЧвдЛЅСЊЭјЮЊдиЬхЃЌПЊЭЈЦѓвЕЕЅЮЛКЭИіШЫЭјЩЯЩъБЈвЕЮёЕФЗўЮёЁЃ
дкУцЖдШевцдіМгЕФЭјТчвЕЮёАьРэашЧѓЃЌЦНЬЈгВМўЯЕЭГЃЈЖрВПИпЖЫUnixаЁаЭЛњЃЉЫљГадибЙСІж№НЅМгДѓЁЃ ЯЕЭГгВМўвбж№НЅГіЯжЦПОБЁЃдк2012Фъ1дТМЏжаЩъБЈЦкМфЃЌ
ЯЕЭГЕФCPUЃЈАќКЌгІгУЗўЮёЦїКЭЪ§ОнПтЗўЮёЦїЃЉИпДя90%вдЩЯЃЌ ЕМжТЯЕЭГВЛЮШЖЈЃЌЮоЗЈе§ГЃЗУЮЪЃЌгАЯьжиДѓЁЃ
ОЙ§ЩчБЃЯрЙиЕЅЮЛзаЯИЦРЙРЃЌШЗСЂЯЕЭГИФдьЕФВпТдгІгЩСНЗНУцзХЪжЃЌ вЛЪЧНЈСЂащФтЛЏЕФдЦЛЗОГЃЌ
ЖўЪЧеыЖдзгЯЕЭГЦПОБНјааОжВПИФдьЃЌ ИФдьКѓЕФзгЯЕЭГЦНЬЈашвЊжЇГжЁАЕЏадРЉеЙЁБЃЌТњзуЮДРДШевцдіМгЕФЭјЩЯвЕЮёЁЃ
ВЩгУVMwareММЪѕДюНЈащФтЛЏдЦЦНЬЈРДЬсЩ§ЛљДЁМмЙЙЕФРЉеЙФмСІЃЌВЩгУPivotal
Gemfire ПЩЕЏадРЉеЙЕФИпЫйЛКДцЙІФмЃЌ жЇГжИпВЂЗЂЁАШШЕуЪ§ОнЁБВщбЏЗўЮёЃЌНЕЕЭдгаЪ§ОнПтЕФI/OЦПОБЃЌЬсИпећИіЯЕЭГадФмКЭЮШЖЈадЁЃ
3. Н№ШкЕЅЮЛPOCВтЪдИФдьЫМТЗКЭашЧѓ ЈCНЈСЂПЩРЉеЙЕФ ЁАЗжВМЪНФкДцЛКДцЪ§ОнВуЁБ
Н№ШкЕЅЮЛЯЕЭГХгДѓИДдгЃЌЫљгаЕФзгЯЕЭГДгЩшМЦЕНПЊЗЂЖМашвЊбЯИёзёбЭГвЛПЊЗЂСїГЬЃЌ
КЫаФзгЯЕЭГвЕЮёТпМВЛЧсвзИќИФЁЃЖдЯЕЭГЖјбдЃЌВщбЏвЕЮёСПЖрЃЌЪ§ОнСПДѓЃЌЙиСЊБэИёЖрЃЌдкИпВЂЗЂЧщПіЯТЃЌВщбЏЗДгІЪБМфГЄЁЃ
POCВтЪдФПЕФЃК
дкВЛИФЯЕЭГвЕЮёТпМЧщПіЯТ, ЖдЁАЪ§ОнЗУЮЪВу DAO ЈC Data Access
ObjectЁБНјааИФдьЃЌ НЈСЂПЩРЉеЙЕФ ЁАЗжВМЪНФкДцЛКДцЪ§ОнВуЁБЃЛФПЕФЪЧЬсИпвЕЮёВщбЏадФмЃЌПьЫйЗДгІВщбЏНсЙћЃЌНЕЕЭдгаЪ§ОнПтЕФI/OЦПОБЃЌЬсИпећИіЯЕЭГадФмЁЃ
ПМТЧЯЕЭГЮШЖЈадКЭАВШЋадЃЌ ЛЙашвЊбщжЄЁАЗжВМЪНФкДцЛКДцЪ§ОнВуЁБгыЙиЯЕаЭЪ§ОнПтжЎМфЁАЪЇаЇзЊвЦ
fail overЁБЕФЩшМЦЁЃ
Ш§ЁЂ12306ЯЕЭГИФдьЧЈвЦЕНGemfireЦНЬЈ
дкзюГѕЕФПђМмЩшМЦвбПМТЧЯЕЭГадФмЮЪЬтЃЌЫљвдЪЙгУStored ProcedureПЊЗЂРДЬсЩ§ЯЕЭГжДааЫйЖШЁЃДЫЩшМЦЫМТЗЪЧВЮПМЕТЙњКЭгЂЙњЛЅСЊЭјЪлЦБОбщ
ЈC МДзмЪлЦБСП20%ЕФБШТЪЪЧЭИЙ§ЛЅСЊЭјЪлЦБЃЌвВОЭЪЧЫЕЕБГѕ12306ЯЕЭГЙцЛЎЪЧвЊТњзуУПЬьЪлЦБСП100ЭђеХЕФашЧѓРДЩшМЦЁЃ
дк2012ФъДКдЫ12306ЖдЭтПЊЗХЪБЃЌгПШыНЋНќ2ЧЇЭђШЫДЮЕЧТМЃЌдЖдЖГЌЙ§ЕБГѕЕФдЄЩшФПБъЃЌЕЋгжЪмЯогкЯЕЭГМмЙЙЮоЗЈЕЏадРЉеЙЃЌЕМжТећИі12306ЯЕЭГРяРяЭтЭтЖМВЛЮШЖЈЃЌ
ЮоЗЈе§ГЃЗУЮЪЁЃдкВЩгУPivotal-GemfireдЦЛЏКѓЕФ12306ЯЕЭГгаСЫЁАжЪгыСПЁАЕФДѓдОНјЃЌдк2015ФъДКдЫЪлЦБИпЗхШевбДя560ЭђеХЃЌеМСЫећЬхЪлЦБСПЕФ60%ЃЛБмУтЙ§ШЅШевЙХХЖгЙКЦБЕФЭДПрЃЌ
вВНкЪЁДѓСПЩчЛсГЩБОЁЃ
гЩгк12306вЕЮёТпМИДдгЃЌЯЕЭГХгДѓЃЌ дкДЫжЛвдгрЦБМЦЫу/ВщбЏЮЊАИР§ЁЃгаЙиећИіЯЕЭГЕФвЕЮёТпМЩшМЦВЛдкДЫЬжТлЁЃЯТСаЕФУшЪіШчЙћгаЮѓЃЌ
вВЧыИїЮЛЯШНјжИе§ЁЃ
2012Фъ ИФдьЧАЕФгрЦБМЦЫу/ВщбЏзгЯЕЭГМмЙЙУшЪі
1. ТЗОжЁАЪЕЪБЁБЬсЙЉЪлЦБМЧТМ
Л№ГЕЦБЕФЯЏЮЛЯњЪлЪЧгЩУПИіТЗОжЙцЛЎКЭЕїПиЃЈЬњТЗзмЙЋЫОЙВга18ИіТЗОжЃЉЃЌ Жј12306гыУПИіТЗОжЪЧЙВЯэЭЌвЛИіЁАЦБПтЁБЁЃ
ЛЛОфЛАЫЕЃЌЁАЯпЩЯЁБЕФ12306ЪЧгыЁАЯпЯТЁБЕФЛ№ГЕеОЕуЪлЦБДАПкЃЌЕчЛАЪлЦБЃЌКЭИїЕиЕФЪлЦБЕуЧРЦБЁЃУПИіТЗОжНЋУПеХЦБЕФЯњЪлМЧТМЖМЁАЪЕЪБЁАДЋЫЭЕН12306дкЬњзмЪ§ОнжааФЁАжїЪ§ОнПтЗўЮёЦїЁБзіЛузмЁЃ
2. Ъ§ОнПтИДжЦЕНгрЦБМЏШКЃК
дкЬњзмЕФЪ§ОнжааФ - грЦБМЦЫуЗўЮёЦїМЏШКЪЧгЩЁАжїЪ§ОнПтЗўЮёЦїЁБКЭ72ВПUnixаЁаЭЛњзщГЩЃЛжїЪ§ОнПтЗўЮёЦїЛузмИїИіТЗОжДЋЪфЙ§РДЕФЪ§ОнКѓЃЌРћгУЪ§ОнПтИДжЦЕФЛњжЦЃЌЪЕЪБНЋЪ§ОнЁАИДжЦЁАЕН72ВПUnixаЁаЭЛњЁЃ
3. ВЂааДІРэгрЦБМЦЫуЃК Цфжа8ВПаЁаЭЛњзіЪлЦБдЄДІРэЃЌдйНЋдЄДІРэНсЙћЫЭЕН64ВПаЁаЭЛњЃЌ64ВПаЁаЭЛњЁАЭЌЪБВЂааЁБДІРэгрЦБМЦЫуЁЃ
4. гІгУЛКДцЗўЮёЦїЃК 64ВПаЁаЭЛњНЋгрЦБМЦЫуКѓЕФНсЙћЛузмВњЩњгрЦББэЃЌНЋгрЦББэЗХжУдкЧАЖЫЕФгІгУЛКДцЗўЮёЦїМЏШКЃЛДЫОйЪЧвЊНтОідкИпВЂЗЂЕФЧщПіЯТЃЌЛКДцЗўЮёЦїЬсЙЉИќПьЫйЕФгрЦБВщбЏЗўЮёЁЃ
5. CDN(Content Delivery Network)ЗўЮёЦїЃК12306зюЭтЮЇВПЪ№CDNЭјТчЃЌЦфФПЕФЪЧЪЙгУЛЇПЩОЭНќШЁЕУЫљашаХЯЂЃЌНЋгУЛЇЕФЧыЧѓжиаТЕМЯђРыгУЛЇзюНќЕФЗўЮёНкЕуНтОі
InternetЭјТчгЕМЗЕФзДПіЃЌЛЙгаЕїећИКдиОљКтЕФЙІФмЃЌЬсИпгУЛЇЗУЮЪЕФЯьгІЫйЖШЁЃ
6. грЦБаХЯЂИќаТЛњжЦЃКгрЦБаХЯЂИќаТЪЧвдЁАГЕДЮЁАЮЊЛљзМЃЌУПИє10ЗжжгИќаТвЛДЮЁЃЕБгУЛЇЬсНЛЁАЧјМфеОЕуЁБЕФгрЦБВщбЏЪБЃЌЯШДгCDNЗўЮёЦїВщбЏзЪСЯЃЌМйШчCDNЕФзЪСЯвбГЌЙ§10ЗжжгЃЌЛсДггІгУЛКДцЗўЮёЦїЫїШЁзюаТЕФЪ§ОнЁЃЭЌРэЃЌЕБгІгУЛКДцЗўЮёЦїЕФзЪСЯГЌЙ§ЪБаЇЃЌЛсДЅЗЂгрЦБМЦЫуСїГЬЃЌжиаТМЦЫугрЦБВњЩњгрЦББэЃЌ
ЬсНЛИјгІгУЛКДцЗўЮёЦїЁЃУПИє10ЗжжгИќаТЕФВЮЪ§ЪЧПЩЕїећЕФЁЃ
12306ИФдьддђКЭФПБъ
ЃЈ1ЃЉЩшЖЈадФмжИБъЃК
вдгрЦБМЦЫузгЯЕЭГЮЊР§ЃЌGemfireМЏШКЕФгрЦБМЦЫуадФмжИБъашвЊДяЕН10ЃЌ000 TPSвдЩЯЃЌ ВЂПЩвдЫцзХвЕЮёГЩГЄзіЕЏадРЉеЙЁЃХфКЯгІгУЛКДцЗўЮёЦїМЏШККЭзюЧАЖЫЕФCDNИКдиОљКтЗўЮёЦїМЏШКЃЌдЄЙР12306ПЩвджЇГжУПУыДяАйЭђДЮЕФгрЦБВщбЏЁЃДЫВПЗжЕФЯЕЭГадФмЪЧгыЗўЮёЦїCPUРраЭЃЌ
ФкДцДѓаЁЃЌGemfireНкЕуЪ§КЭx86ЗўЮёЦїЪ§СПЖМгаЙиСЊЁЃ
ЃЈ2ЃЉгрЦБМЦЫуДІРэФмСІПЩЫцзХащЛњЕФдіМгЖјЯпаддіМг
грЦБВщбЏЪЧвЊЗДгГзюаТЕФгрЦБЧщПіЃЌзїЮЊЙКЦБЕФвРОнЁЃ дкЩЯЦЊЮФеТвбЬИЕНгрЦБМЦЫуЕФИДдгЖШЃЌашвЊКмЧПДѓЕФCPUДІРэФмСІЮЊКѓЖмРДМЦЫуУПИіЧјМфеОЕуЕФгрЦБСПЃЛНЋМЦЫуНсЙћЗХжУЕНЛКДцЪ§ОнЗўЮёЦїКЭCDNЗўЮёЦїЁЃгрЦБМЦЫуЪЧРћгУGemfire
Data GridКЭMap ReduceЕФММЪѕЬсЙЉОоДѓCPUДІРэФмСІЁЃ
ЃЈ3ЃЉдкВЛИФБфдгаЕФЬхЯЕПђМмЩЯдіМгGemfireМЏШКЃЌ аТОЩСНЬзЯЕЭГВЂаадЫЫу
ЮЊШЗБЃ12306ЩњВњЛЗОГЕФЮШЖЈадКЭЦНЮШЙ§ЖЩЃЌаТОЩСНЬзЯЕЭГБиаыЭЌЪБдЫааЃЌгЩзюЧАЖЫЕФCDNЗўЮёЦїПижЦЗУЮЪСїСПЃЌж№НЅНЋашвЊгрЦБМЦЫуЕФЧыЧѓМгбЙЕНGemfireМЏШКЃЌВтЪдGemfireЕФГадиФмСІЃЌМьбщПЩРЉеЙЕФЙІФмЁЃ
ЃЈ4ЃЉЯЕЭГИпПЩгУадЃЈHigh AvailabilityЃЉ
GemfireЕФЪ§ОнНкЕуЖМгаЦфЫќНкЕуЕФБИЗнЪ§ОнЃЌ вВПЩвдНЋФкДцЪ§ОнГжОУЛЏЕНгВХЬЛђЪЧЭЌВН/вьВНаДЕНЪ§ОнПтЁЃ
ЃЈ5ЃЉx86ЗўЮёЦї
ПМТЧЮДРДЖрЪ§ОнжааФКЭЛьКЯдЦЕФВПЪ№ЃЌБиаыЪЙгУx86ЗўЮёЦїЮЊЩњВњЛњЁЃ
ИљОн12306ИФдьЩшМЦддђдкВЛИФБфдгаЕФЬхЯЕПђМмЩЯдіМгGemfireМЏШКЃЌ дкЙ§ЖЩЦкМфЃЌаТОЩСНЬзЯЕЭГВЂаадЫЫуЃЌдкЙ§ЖЩЦкКѓЃЌвдGemfireМЏШКЮЊжїЁЃ
ЫљвдДЫВНЕФИФдьЪЧеыЖдЩЯЪіЁБИФдьЧАЕФгрЦБМЦЫу/ВщбЏзгЯЕЭГМмЙЙЁБЕФЕк2ЯюКЭЕк3ЯюНјааЗжЮіКЭИФдьЁЃ
12306ИФдьВНжшЃК
ЃЈ1ЃЉЯЕЭГМмЙЙИФдьКЭЪ§ОнЩЯди
ЮЊШЗБЃ12306ЩњВњЯЕЭГЕФЮШЖЈдЫааКЭЦНЮШЙ§ЖЩЃЌдкВЛИФБфдгаЕФЬхЯЕПђМмЩЯдіМгGemfireМЏШКЃЌ аТОЩСНЬзЯЕЭГВЂаадЫЫуЁЃФЧОЭБиаыПМТЧШчКЮНЋЪ§ОнДгЪ§ОнПтЪЕЪБЭЌВНЕНGemfireМЏШКзігрЦБМЦЫуЁЃ
AЃЎЪ§ОнПтИДжЦЗўЮёЦї ЃКдіМгвЛВПЪ§ОнПтЗўЮёЦїЃЌНЋЬњзмЪ§ОнжааФЁАжїЪ§ОнПтЗўЮёЦїЁБЛузмЕФЪ§ОнЪЕЪБИДжЦЕНДЫВПЪ§ОнПтЗўЮёЦїЁЃ
BЃЎЪЕЪБЭЌВНЛњжЦКЭSQLНтЮіЗўЮёЦї ЃК ДЫВНжшЪЧДгЪ§ОнПтШЁГіLogЪ§ОнВЂНтЮіSOLгяОфЃЌвђЮЊдРДДњТыЪЧгУStored
ProcedureПЊЗЂЕФЁЃ
CЃЎRabbit MQЗўЮёЦї ЃКЭЌВНЛњжЦЗўЮёЦїНЋНтЮіЙ§ЕФSQLгяОфЭИЙ§Rabbit MQДЋЪфИјGemfireМЏШКзігрЦБМЦЫуЁЃ
DЃЎGemfireМЏШКНЋгрЦБМЦЫуНсЙћЛузмКѓЃЌЬсНЛИјЧАЖЫЕФгІгУЛКДцЗўЮёЦїЬсЙЉгрЦБПьЫйВщбЏЁЃ
ЃЈ2ЃЉЯЕЭГЪ§ОнНсЙЙЗжЮі
Ъ§ОнНсЙЙЗжЮіКЭЩшМЦЪЧдкИФдьЙ§ГЬжазюЙиМќЕФвЛВНЃЌгАЯьЕНКѓајадФмЕФЬсЩ§ЃЛ РћгУЁАЪ§ОнЭјИёShare NothingЁБЕФЬиад,
НЋЪ§ОнЧаИю, Аб ЁАЪ§ОнЙиСЊадЧПЁБЕФЪ§ОнЗХдкЭЌвЛИіGemfire Ъ§ОнНкЕуЃЌдйХфКЯвЕЮёТпМЕФЩшМЦЃЌНЕЕЭНкЕужЎМфЪ§ОнНЛЛЛЕФбгГйЃЌЬсИпЯЕЭГДІРэФмСІЁЃ
ЃЈ3ЃЉBenchmark ЃЈЛљзМЕуЃЉВтЪд
НјааBenchmarkВтЪд, ЦРЙРУПВПGemfireЗўЮёЦїЕФTPSКЭгрЦБМЦЫуЗДгІЪБМф
-бщжЄGemfireМЏШКадФмПЩЫцзХx86ащЛњЕФдіМгЖјЯпаддіМг
ВтЪдЁАЪЕЪБЭЌВНЁБЛњжЦ, СПВтЪ§ОнЭЌВНЕНGemfireМЏШКЕФЮШЖЈадЃЌбгГйКЭЭЬЭТСП
ЃЈ4ЃЉЯЕЭГЮШЖЈад, АВШЋадКЭHAЩшМЦ
дкGemfireЕФЪ§ОнНкЕуЖМгаЦфЫќНкЕуЕФБИЗнЪ§ОнРДДяЕНHAЕФФПЕФЃЌвВПЩвдНЋФкДцЪ§ОнГжОУЛЏЕНгВХЬЛђЪЧЪ§ОнПтЁЃ
ЪЙгУGemfireИФдьЕФЪЕЪЉСїГЬЃК
1. ашЧѓЗжЮіНзЖЮЃК
ашЧѓЕїбаЃЌШЗЖЈИФдьЗНАИЁЂЗжЮіЪ§ОнБэНсЙЙЁЂбљБОЪ§ОнЁЂЪ§ОнСПМАгІгУЗУЮЪЬиадаХЯЂ
2. МмЙЙЩшМЦЃК
ЩшМЦRegionНсЙЙЃЌШЗЖЈЗжЧјЗНЪНЃЌКЭ ЩшМЦЖўМЖЫїв§
Ъ§ОнЧаИюЃЈpartitionЃЉЗХдкGemfireЕФНкЕуЃЌ УПИіНкЕуЪ§ОнСПДѓаЁЪЧИљОнЮяРэЛњФкДцРДОіЖЈЁЃР§ШчЃЌ
дкАЂРядЦЕФНкЕувЛАуЪЧ30GзѓгвЃЌдкЬњзмЪ§ОнжааФЕФНкЕуЪЧ60G-120GзѓгвЁЃ ДгЯюФПОбщРДЫЕЃЌGemfireЪ§ОнНкЕувдВЛГЌЙ§128GПЩЕУЕНзюМбаЇЙћЁЃ
РћгУData GridКЭMap ReduceЕФЗжВМЪНММЪѕЬсЙЉЧПДѓЕФCPUДІРэФмСІЁЃ
ЪЙгУЕНЕФGemfireЙІФмВЮПМЯТСаУшЪі
3. БрТыКЭЕЅдЊВтЪдЃК
12306ЪЧВЩгУStored ProcedureПЊЗЂЃЌБиаыНЋStored
ProcedureНтЮіЃЌ ВЩгУJavaПЊЗЂКЭБрТыЃЌВЂНЋвЕЮёТпМДњТыКЭЪ§ОнЖМЗХдкGemfireНкЕуЃЌ ДЫОйПЩвдДяЕНзюИпЕФЯЕЭГадФм
ЕЅдЊВтЪд
4. МЏГЩВтЪд/зМШЗЖШВтЪд/адФмЕїгХЃК
дкМЏШКЛЗОГЯТНјаазМШЗЖШВтЪд
дкМЏШКЛЗОГЯТНјааадФмМАбЙСІВтЪд
вРОнВтЪдНсЙћНјааадФмЕїгХ
адФмЕїгХПЩФмашвЊЕїећЯИВПМмЙЙЕФжиаТЩшМЦ
5. HAКЭШШВПЪ№ВтЪд
6. ЯпЩЯдЫЮЌЃК
ДДНЈReleaseАцБОВЂФЩШыЙмРэ
ХфжУВПЪ№ЩњВњЛЗОГВЂНјааГжајМрПи
жївЊЕФGemfireЙІФмЬиадЃК
дк12306ИФдьЙ§ГЬжаЃЌЪЙгУЕНЯТСаGemfireЕФЙІФмЬиадЃК
Rich Objects: вдobjectsЕФаЮЪНЬхЯжКЭБрТыЃЌздМКЖЈвхЪ§ОнНсЙЙ
Elastic Growth w/o pausing ЃК ЕЏадРЉеЙКЭШШВПЪ№
Partitioned Active Data ЃК ИљОнЪ§ОнЪєадЃЌР§ШчЃКПЭЛЇЃЌЖЉЕЅЃЌГЕДЮЃЌеОУћЃЌзіКЯРэЕФЪ§ОнЧаИюЃЌЗХдкВЛЭЌЕФЪ§ОнНкЕуЁЃ
Redundancy for instant FTЃКHAЕФЩшжУ
Colocated Active DataЃК share nothingЕФИХФюЃЌНЋЙиСЊадЧПЕФЪ§ОнЗХдкЭЌвЛИіGemfire
Ъ§ОнНкЕуЃЌ Р§ШчЃЌГЕДЮЃЌеОУћ
Replicated Master DataЃК Ъ§ОнСПВЛДѓЕФГЃгУЪ§ОнЃЌР§ШчЃКеОУћзжЕфКЭЯЏЮЛРрБ№ЕШЃЌдкУПИіGemfireНкЕуЖМгавЛЗнПНБДЃЌДЫОйЪЧвЊМѕЩйЪ§ОнЕФНЛЛЛЁЃ
Server-side Event ListenersЃК ЕБЪ§ОндкServerЖЫВњЩњБфЛЏЪБЃЌЛсДЅЗЂЯргІЕФВйзї
Client-side Durable SubscriptionsЃКЕБServerЖЫТњзуПЭЛЇЖЫЖЉдФЕФФГаЉЬѕМўЪБЃЌЛсЭЦЫЭаХЯЂ
Parallel Map-Reduce Function ExecutionЃК
ГЕДЮгрЦБдкУПИіGemfire НкЕуВЂаадЫЫуЃЌдйЛузмдЫЫуНсЙћ
Parallel OQL Queries
Continuous Queries
LRU Overflow to disk in native format
for fast retrieval
Parallel, Shared Nothing Persistence
to disk w/ online backup
Asynchronous Write Behind, Write Through
or Read Through
ЫФЁЂЩчБЃЯюФПзгЯЕЭГИФдьЧЈвЦЕНGemfireдЦЦНЬЈ
ЩчБЃЩъБЈзгЯЕЭГИФдьддђКЭФПБъ
ДгЗУЮЪСПКЭВЂЗЂСПЙцФЃРДЫЕЃЌЩчБЃЫљгіЕНЕФЮЪЬтдЖдЖбЗгк12306ЫљХіЕНЕФЬєеНЁЃзгЯЕЭГИФдьЪЧЛљгкVMwareащФтЛЏдЦЦНЬЈЛљДЁЩЯЬсЩ§ЩъБЈЯЕЭГЕФВщбЏадФмЁЃ
ЃЈ1ЃЉЩшЖЈадФмжИБъЃК
адФмжИБъашвЊДяЕНдгазгЯЕЭГадФм50БЖвдЩЯ
ЃЈ2ЃЉеыЖдЯТСаСНИізгЯЕЭГЦПОБНјааОжВПИФдь
НЩЗбЙЄзЪЩъБЈ
ГЧеђжАЙЄдіМг
ЃЈ3ЃЉИФдьКѓЕФзгЯЕЭГадФмПЩЫцзХGemfireНкЕуащЛњЕФдіМгЖјЯпаддіМг
ЃЈ4ЃЉЯЕЭГИпПЩгУадЃЈHAЃЉ
ВЮПМ12306УшЪіЁЃ
згЯЕЭГЦПОБЕФОжВПИФдьВНжшЃК
ЩчБЃЯЕЭГЪЧКмИДдгХгДѓЕФЯЕЭГЃЌгЩЩЯАйИіФЃПщЙЙГЩЁЃДЫЯЕЭГВЩШЁШ§ВуМмЙЙЩшМЦЃЌ ЪЙгУJavaПЊЗЂЁЃжївЊЮЪЬтдкгкИпВЂЗЂЩъБЈЙ§ГЬжаЃЌ
ЦЕЗБЕФЪ§ОнПтаДШыКЭДѓСПВщбЏЕМжТгВМўЦНЬЈИпИКдиЃЌзгЯЕЭГВЛЮШЖЈЃЌ ЮоЗЈе§ГЃЗУЮЪЁЃ
згЯЕЭГЕФИФдьЪЧеыЖдЪ§ОнПтЦПОБЬсГіИФСМЗНАИ
ВЩШЁЪ§ОнПтЁАЖС/аДЗжРыЁАЕФЗНЪНЃЌНЋЪ§ОнЁАаДШыЁБЙиЯЕаЭЪ§ОнПтЃЛНЋЁАЖСЁБЕФВйзїгЩGemfireМЏШКРДЬсЙЉЃЌвђЮЊВщбЏЕФЗУЮЪСПЪ§ЪЎБЖгкЪ§ОнЕФаДШыСПЁЃ
ПЭЛЇЖЫзЪСЯаДШыЪБЃЌЭЌЪБНЋЪ§ОнаДШыGemfireНкЕуКЭЙиЯЕаЭЪ§ОнПт
НЋЁАгћИФдьЁАЕФзгЯЕЭГвЕЮёТпМДњТыИФаДКѓвЦЕНGemfireНкЕужДаа
GemfireМЏШКЬсЙЉИеТМШыЁАШШЕуЪ§ОнЁАЕФПьЫйВщбЏ
ВЛЭЌзгЯЕЭГЪ§ОнПтжЎМфЕФЪ§ОнХњСПЭЌВНЃЌНЋЦфЫќзгЯЕЭГЁАЭъећЁБЕФШШЕуЪ§ОнЩЯдиЕНGemfireМЏШКЬсЙЉПьЫйВщбЏ
ЯрЙиЕФИФдьВНжшКЭЪЕЪЉСїГЬЧыВЮПМЩЯЪіЕФ12306еТНкЃЌИФдьКѓЕФМмЙЙШчЯТЭМЫљЪОЁЃ
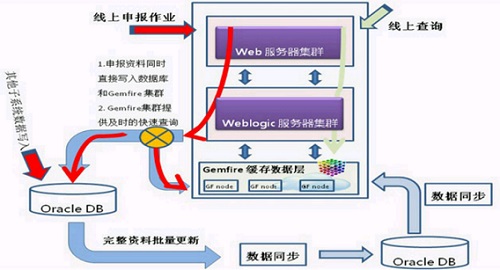
ЮхЁЂФГН№ШкЕЅЮЛPOCЯюФП - НЈСЂПЩРЉеЙЕФ ЁАЗжВМЪНФкДцЛКДцЪ§ОнВуЁБ
Н№ШкЕЅЮЛЯЕЭГЪЧгЩЩЯАйИізгЯЕЭГЙЙГЩЃЌ ЫљгаЕФзгЯЕЭГДгЩшМЦЕНПЊЗЂЖМвЊзёбБъзМЭГвЛПЊЗЂСїГЬЃЌзгЯЕЭГВЩШЁШ§ВуМмЙЙЩшМЦЃЌгІгУТпМВугыЪ§ОнЗУЮЪВуЩшМЦВуДЮЗжУїЁЃгЩгквЕЮёВщбЏСПДѓЃЌЧЃЩцЕНЪЎМИеХЙиСЊБэЕФВщбЏЃЌЯЕЭГЗДгІЪБМфГЄЁЃЪ§ОнПтЖСаДЦЕЗБЃЌCPUЪБГЃТњИКдиЃЌЕМжТЯЕЭГадФмЦПОБЁЃ
POCзгЯЕЭГИФдьФПБъ
ИФдьЗНЪНЪЧдкВЛИФБфзгЯЕЭГвЕЮёТпМЧщПіЯТЃЌЖдЪ§ОнЗУЮЪВуНјаааоИФDAOНгПкЃЌв§ШыЁАЗжВМЪНЛКДцЪ§ОнВуЁБМмЙЙЁЃ
ЃЈ1ЃЉЩшЖЈадФмжИБъЃК
адФмжИБъашвЊДяЕНдгазгЯЕЭГадФм20БЖвдЩЯ
ЃЈ2ЃЉеыЖдСНИізгЯЕЭГНјааDAOНгПкИФдь
ЃЈ3ЃЉбщжЄИФдьКѓЕФзгЯЕЭГВщбЏадФмПЩЫцзХGemfireащЛњЕФдіМгЖјЯпаддіМг
ЃЈ4ЃЉЯЕЭГИпПЩгУадЃЈHAЃЉ
Г§СЫGemfireМЏШКЕФHAвдЭтЃЌЛЙвЊПМТЧЯЕЭГЮШЖЈадКЭАВШЋадЃЌ ВЩгУЁАЪЇаЇзЊвЦ fail overЁБЩшМЦЃЌЭђвЛGemfireМЏШКвьГЃЪБЃЌИФгЩЪ§ОнПтЬсЙЉВщбЏЗўЮё
Ъ§ОнЗУЮЪВуЃЈDAOЃЉИФдьВНжшЃК
ИљОнПЭЛЇГЁОАЕФвЊЧѓЃЌзгЯЕЭГЕФИФдьЪЧеыЖдЪ§ОнПтЬсГіИФСМЗНАИЃЌЖдЪ§ОнЗУЮЪВуНјаааоИФDAOНгПкЃЌЧЖШыЁАЛКДцЪ§ОнДњРэВуЁБ
ЃЈDelegatorЃЉМмЙЙЁЃ
ЛКДцЪ§ОнДњРэВугаШчЯТЙІФмЩшМЦЃК
ЛКДцЪ§ОнДњРэВуЯђЩЯЗтзАЪ§ОнЗУЮЪНгПкЃЌЯђЯТЭЌЪБжЇГжDBКЭGemfireЛКДцЪ§ОнВу
гывЕЮёТпМЯрЙиЕФAPIПЩвдЫцзХвЕЮёашЧѓЃЌАДашЕЏаддіМгAPIНгПкЕФжЇГж
ИљОнGemfireЕФЬиадЃЌЖдSQLгяОфНјаааоИФЃЌЩшМЦГЩВЂааВщбЏЙІФм
ПМТЧЪ§ОнвЛжТадЕФвЊЧѓЃЌПЭЛЇЖЫЪ§ОнжБНгаДШыЙиЯЕаЭЪ§ОнПтЃЌдйНЋЪ§ОнЭЌВНЕНGemfireМЏШКЬсЙЉПьЫйВщбЏЁЃ
ЭђвЛGemfireМЏШКгавьГЃЃЌПЭЛЇЖЫПЩжБНгЗУЮЪЪ§ОнПтЃЌЪЕЯжЛКДцЪ§ОнВуКЭDBжЎМфЕФЮоЗьЧаЛЛ
СэЭтЃЌЦфЫћЪ§ОнПтЛђHadoopМЏШКДцДЂШЋСПвЕЮёЪ§ОнЃЌПЩНЋЁАШШЕуЪ§ОнЁБЩЯдиЕНЛКДцЪ§ОнВу
ЭЈЙ§GemfireвьВНЖгСавВПЩвдНЋGemfireЕФЁАШШЕуЪ§ОнЁБГжОУЛЏЕНDBЛђHadoopМЏШК
ЕБВщбЏдкGemfireЛКДцЪ§ОнВуЮДУќжаЪБЃЌЭЈЙ§Cache loaderДгDBЛђHadoopМЏШКМгдиЪ§ОнЕНЛКДцЪ§ОнВуЃЌ
ЬсЙЉВщбЏЗўЮёЁЃ
ЯрЙиЕФИФдьВНжшКЭЪЕЪЉСїГЬЧыВЮПМЩЯЪіЕФ12306еТНкЃЌИФдьКѓЕФМмЙЙЪОвтЭМШчЯТЃК
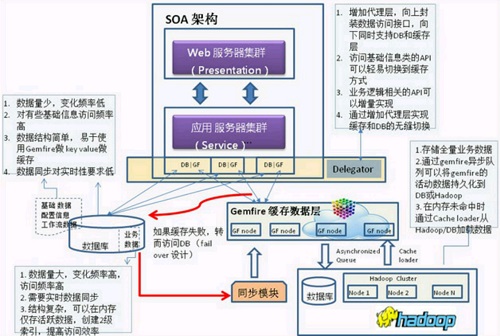
СљЁЂНсТлКЭЦєЪО
гЩЩЯУцМИИіАИР§ЫЕУїЃЌВЛЭЌЕФгУЛЇгаВЛЭЌЕФЫпЧѓЃЌВЛЭЌЕФЯЕЭГПЊЗЂЛЗОГКЭВЛЭЌЕФЯожЦЬѕМўЫљВЩгУЕФИФдьЗНЪНвВВЛвЛбљЁЃзмНсШчЯТЃК
ЃЈ1ЃЉ12306ЯюФПЃК СїСПИпЃЌВЂЗЂадЧПЃЌЗўЮёЦїИКдиИпЃЌЗДгІЪБМфвЊЧѓбЯИёЃЛЮЊСЫБмУтФГвЛИіЛЗНкЕФЦПОБЃЌашвЊРэЫГећИіСїГЬ,
НЋвЛЯЕСаЕФзгЯЕЭГзіЁАдЦЛЏЁБЕФИФдьЁЃИљОнЪЕМЪашЧѓЃЌНЋдЦЛЏКѓЕФзгЯЕЭГАДашВПЪ№дкЙЋгадЦЬсЙЉЗўЮёЁЃ ИФдьЕФЪжЖЮЪЧгУЁАЗжВМЪНЪ§ОнЭјИёЁБЕФММЪѕЃЌНсКЯвЕЮёТпМЬиадКЭЪ§ОнНсЙЙЃЌНЋвЕЮёТпМКЭЙиСЊадЧПЕФЪ§ОнЗХдкЭЌИіGemfireЪ§ОнНкЕуЃЌРћгУMap
ReduceЕФММЪѕЬсЙЉЧПДѓЕФCPUМЦЫуФмСІРДНтОіЮЪЬтЁЃ
ЃЈ2ЃЉ ЩчБЃЯюФПЃК ЩчБЃЪдЕуЯюФПЕФИФдьжиЕуЪЧеыЖдЛсЗЂЩњЦПОБЕФзгЯЕЭГНјааИФдьЃЌНЋзгЯЕЭГвЕЮёТпМКЭЙиСЊадЧПЕФЪ§ОнЗХдкЭЌИіGemfireЪ§ОнНкЕуЃЌРћгУGemfireЗжВМЪНВЂааВщбЏММЪѕРДНтОіИпВЂЗЂВщбЏЕФвЊЧѓЃЌВЂЮЊеўИЎааеўВПУХЙмРэЭИУїЛЏЃЌФкШнИќЗсИЛЕФЁАOpen
DataЁБЗўЮёЦНЬЈЦЬТЗЁЃ
ЖдгкШЫПкДѓЪЁЃЌР§ШчЙуЖЋЃЌКгФЯЃЌНЫеКЭЫФДЈШЫПкНгНќЩЯвкЕФЪЁЗнЃЌЫцзХЩчБЃЬхжЦЕФИФИяЃЌИќвЊПМТЧЁАДѓЪ§ОнЁБЕФДцДЂКЭВщбЏЃЌвђЮЊетаЉЩчБЃзЪСЯДяPСПМЖЃЌашвЊДцДЂЪ§ЪЎФъвдЩЯЁЃ
ДѓЪ§ОнКЭПьЪ§ОнЕФЩшМЦПЩвдНшМј 12306 ЖЉЕЅЗжМЖВщбЏЕФЛњжЦЃЌНЋЁАШШЕуЪ§ОнЁБЗХдкGemfireЛКДцМЏШКЬсЙЉПьЫйВщбЏЃЌНЋРњЪЗЪ§ОнДцЗХдкHadoopМЏШКЁЃЕБВщбЏдкGemfireЛКДцЪ§ОнВуЮДУќжаЪБЃЌЭЈЙ§Cache
loaderДгDBЛђHadoopМЏШКМгдиЪ§ОнЕНЛКДцЪ§ОнВуЃЌЬсЙЉВщбЏЗўЮёЁЃ
ЃЈ3ЃЉ Н№ШкЕЅЮЛPOCЯюФПЃК ДЫPOCЕФИФдьгыЩЯЪіСНИіЯюФПВЛвЛбљЃЌдк12306КЭЩчБЃЯюФПИФдьЖМЪЧашвЊНЋвЕЮёТпМИФаДдкGemfireМЏШКЃЛ
ДЫН№ШкЕЅЮЛPOCЕФВтЪдФПЕФЪЧдкВЛИФаДвЕЮёТпМЕФЧщПіЯТЃЌЖддРДЯЕЭГЕФЪ§ОнЗУЮЪВуЃЈDAOЃЉНјааИФдьЃЌ ЬсЙЉПЩРЉеЙЕФЗжВМЪНЛКДцЪ§ОнВуЬсЙЉПьЫйЗўЮёЃЌВЂЬсЙЉЪЇаЇзЊвЦЕФЩшМЦЁЃ
|






