|
在2015年3月21日的北京Spark Meetup第六次活动上,尹绪森就如何使用PredictionIO打造一个定制化推荐引擎进行了详细介绍,白刚则分享了新浪在大规模多标签分类上的探索。
在2015年3月21日的北京Spark Meetup第六次活动上,一场基于Spark的机器学习专题分享由微软Julien Pierre、新浪网白刚与Intel研究院尹绪森联手打造。
Julien Pierre:Apache Spark in ASG

微软ASG产品经理 Julien Pierre
Julien Pierre首先进行了开场发言,并为大家分享Spark在ASG团队的应用情况。
通过Julien了解到,其团队主要工作集中在Spark SQL和MLlib两个组件,基于Spark做一些交互式分析,其中包括:将Spark与现有的查询工具(Avacado整合)、使用Spark填补SQL Server DB和Cosmos之间规模的数据处理空白,以及使用Spark处理Bing和Office数据集。Julien表示,在小(1TB以内)数据集的处理上,SQL Server DB非常适合,它可以将延时控制在1分钟之内;而在大数据集(100TB以上)的处理上,Cosmos可以在小时级别搞定;而使用Spark,刚好填补了数据处理上1-100TB的空档,在1分钟以内对数据进行处理。
尹绪森:Use PredictionIO to build your own recommendation engine & MLlib 最新成果

Intel研究院工程师 尹绪森
尹绪森在本次Meetup上主要分享了两个话题――使用PredictionIO来打造一个推荐引擎以及MLlib的最新成果。
PredictionIO
尹绪森首先介绍了PredictionIO,他表示,推荐系统打造过程中,除下Spark,系统还需要其他组件,而PredictionIO就是基于Spark一个完整的端到端Pipeline,让用户可以非常简单的从零开始搭建一个推荐系统。
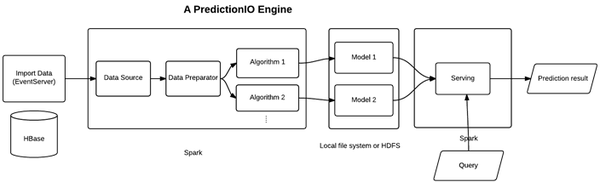
整个Pipeline流程如图所示,其中Spark是整个管道的核心,整个Pipeline主要分为以下几步:
- (可选)PredictionIO使用Event Server来导入数据并存储到HBase中;
- 随后这些数据进入一个基于Spark的PredictionIO Engine,PredictionIO Engine可能包括一个用于导入数据的Data Source,一个用于数据处理ETL等的Data Preparator;同时,一个推荐系统可能包括多个算法,因此数据需要放到不同的Algorithm中做training;
- 在做完training之后生成模型,这里用户可以根据需求来编写持久化方法,确定数据储存的位置,是本地文件系统亦或是HDFS;
- 有了这些model之后,下一步需要做的是serving以响应用户的请求,接受用户的一些查询从而生成结果。
如上所述,一个完整的Pipeline中同时存在多个组件,比如:HBase,为EventServer存储event;Spark,用于数据或者模型的处理;HDFS,用于存储模型;Elasticsearch,用于元数据的处理。而对于用户来说,使用PredictionIO来构建Pipeline只需要实现4个部分:
- Data Source and Data Preparator
- Algorithm
- Serving
- Evaluation Metrics
Engine
在PredictionIO中,Engine是一个比较核心的部分。在这里,尹绪森通过两个用例来讲述:
Engine A:Train predictive model
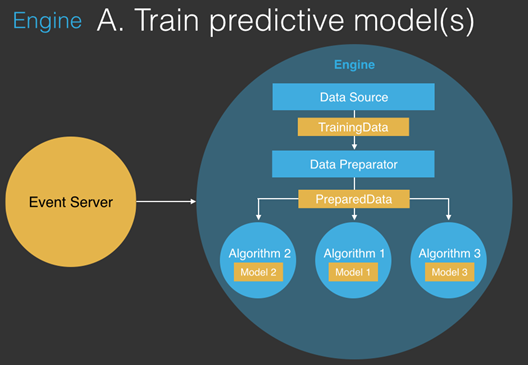
数据从Event Server读取=》通过Data Source后形成TrainingData=》通过Preparator处理后形成PreparedData=》发送到不同的Training模块(Algorithm & model)进行训练。
Engine B:Respond to dynamic query
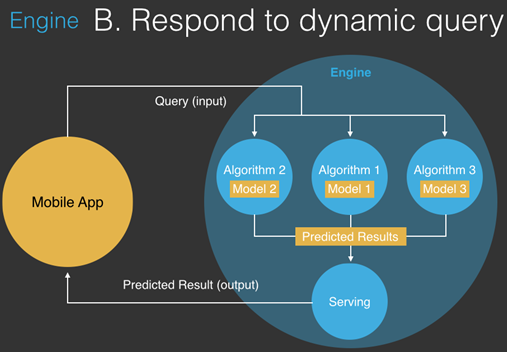
Mobile App向Engine提交查询(输入)请求,随后会发送到3个Training模块(Algorithm & model),生成结果并通过用户自定义的算法将3个结果进行整合,从而产生一个Predicted Results,并交由Serving呈现在Mobile App。
最后,尹绪森通过实际代码讲解了如何使用PredictionIO打造一个基于Spark的Pipeline。
Recent news of MLlib
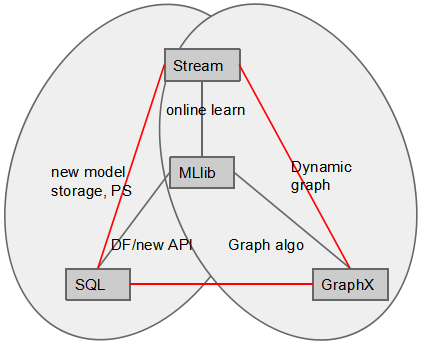
尹绪森表示,在之前版本,Spark的各个组件(比如MLlib、Graphx、Core)相对独立,而在1.3发布后,当下已经有了一个融合的趋势,更加方便用户使用。最明显的变化就是MLlib和Spark SQL,其中SparkSQL把SchemaRDD封装成新的DataFrame API,同时基于MLlib和SQL发展出一个MLPackage,它与DataFrame一起提供了更方便的API为用户使用;而MLlib则与Spark Streaming一起提供了online training的能力,但是目前online training只有3个算法;最后,在1.3发布后,MLlib中添加了很多新的算法,其中多个都是基于GraphX实现,这主要因为很多算法都适合用图来表示,比如LDA(Latent Dirichlet Allocation)。
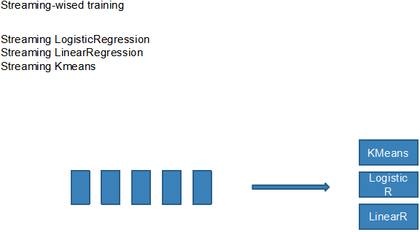
分享最后,尹绪森综述了MLlib近期的几个主要更新,其中包括Streaming-wised training、Feature extraction/transformation、LDA on top of GraphX、Multi-logistic regression、Block matrix abstraction、Gaussian Mixture、Isotonic Regression、Power iteration clustering、FPGrowth、Stat、Random forest以及ML package和 DataFrame,并表示ML package和DataFrame是近期最重要的两个变化。
白刚:Multi-Label Classification with Bossting on Apache Spark

新浪网广告算法部门高级工程师 白刚
白刚在新浪/微博从事广告算法相关工作。而本期Meetup上,白刚的分享主要围绕着新浪门户的大规模多标签分类算法工作(项目已上传到GitHub )。
背景
在类似新浪的媒体中,广告带来收益,同时也会影响到用户体验。为了减少对用户体验的影响(甚至是对用户体验产生帮助),如何区分“用户属于哪个人群,是哪些广告的潜在受众”至关重要,也就是如何做好user profiling。

如上图所示,每个用户都有着不同的兴趣,同时每个人也拥有着多个兴趣,因此实际问题归结于如何给用户打上对应的标签。
问题与求解
在机器学习领域,上述的问题被抽象为模型的建立和预测:根据给出的user feature x,输出符合其兴趣的标签集合L,即F :X →L。这里需要做的则是通过一个superwise的方法对模型进行训练。

所使用数据集:Feature是用户的抽象行为;X,一个N维的向量;L则是具体的Label集合,同样是一个向量,每个维度的值是正一和负一,表示加或者不加某一个Label。训练的最终目标是最小化Hamming Loss――即每个Label的错误率。在这里,白刚从简单的方案介绍,然后针对其缺点,给出了scalable的方案:
1. Per-label bin-classification
为了得到这个vector-valued function F :X →L,这里需要为每个l∈L都训练一个binary classifier,预测时将判断每一个标签上的结果。
- lOne- versus-all implemented in LibSVM、scikit-learn
- lAd targeting往往使用per-campaign model,为每一个ad compaign训练一个二分类模型
这个途径主要基于一些已有技术,比如LR、SVM等二分类模型,因此易于验证。但是这个模型有个比较明显的缺点,即扩展性差――逐个标签训练模型是个比较低效的途径,随着标签数的增加,训练耗时也明显增加。
2. Multi-Label Classification
基于上述思考,新的目标被确定:首先,模型本身的输出就是多标签结果,而不是组合多个二分类的模型去获得最终结果;其次,训练过程是最小化Hamming loss,这样一个目标可以让多标签的分类更准;最后,必须是可扩展的,不管是在Feature的维度上,还是在Label的维度上,亦或是数据集的大小上,都能适应一个很大的规模。
在考量了多个解决问题的方案后,Boosting最终被选择,这主要因为Boosting在这个场景下可以更加的高效和方便,同时在Spark上实现Boosting这个多迭代的方式也非常适合。这个方案主要涉及到两篇文献和一个开源的实现:
文献1:Improved Boosting Algorithms Using Confidence-rated Predictions( Robert E. Schapire & Yoram Singer)。提出了AdaBoost.MH算法,它主要是对AdaBoost的扩展。
文献2:The Return of AdaBoost.MH: Multi-class Hamming Trees,2014年由Kegl提出。该方法主要是对AdaBoost.MH里的base learners做Factorization,将Decision stump和Hamming tree作为base learner。需要注意的是,该方法还处于初级阶段。
开源实现:前述算法的一个CPP单机开源实现。http://multiboost.org。当然,在这里希望得到的是通过Spark实现一个更具扩展性,更容易并行的方案。

分享期间,白刚详细的介绍了上述3点工作原理及学习机制,并针对Spark上的实现进行了详细讲解,其中包括:
- 多标签情况下弱分类器的系数的计算及其数学意义。
- Base learner的训练、根据14年那篇文献的介绍,把弱分类器分解成一个只与feature相关、与label无关的函数和一个只需label相关、与feature无关的向量。前者把feature space做划分,后者在每个label上对前者的划分做修正。
Multiboost on Spark
1. Strong Learner on Apache Spark
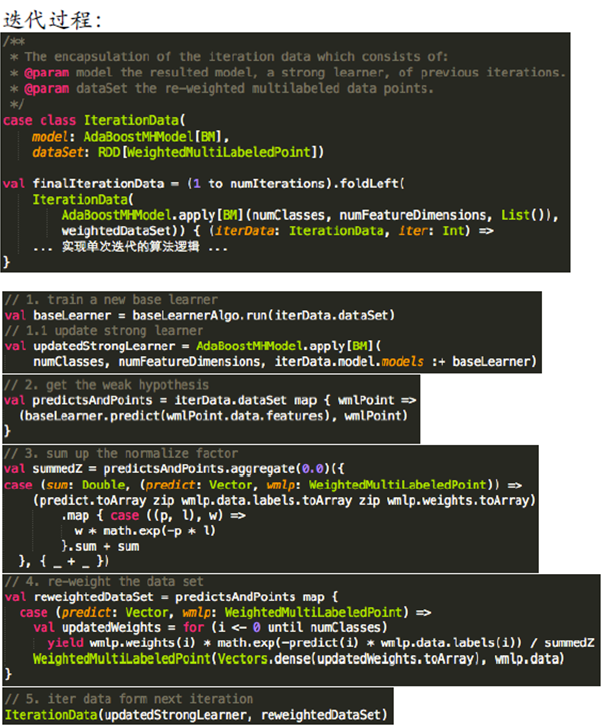
AdaBoost.MH on Apache Spark
与Spark的结合,Strong Learner主要在Spark的driver program中实现算法逻辑,Base Learner类型作为类型参数。其中不同Base Learner可替换,实现可插拔,并实现了Base Learner的training逻辑与strong learner解耦。代码参见GitHub。
2. Base Learner on Apache Spark
这个部分的工作主要是对弱分类器逻辑实现的封装,其最核心内容就是实现baseLearnerAlgo.run(iterData.dataSet)。

通过参考2014年的文献,主要分享了这三个方面的多标签弱分类算法:
Decision stump:一个只有一个节点的决策树,只有两个模型参数。J,feature的index,即选择哪一个维度的feature去考虑;b,是一个threshold,当在这个维度上feature的值大于threshold的时候则划分为正的部分,反之则划分到负的部分。
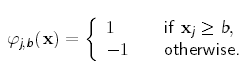
同时期训练过程就是寻找最优的分隔(j, threshold)的过程
Hamming tree:Decision stump作为节点的决策树。
Generalized bin-classifier方案:φ(x)使用任意二分类模型,与v一起来最大化class-wise edge/最小化exp loss。
3. Decision Stump on Apache Spark
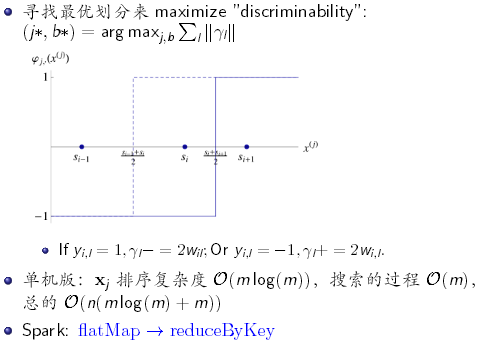
对比单机版,在Spark中的实现并不会真正的去做排序,而是通过flatMap==》reduceByKey的方式实现。
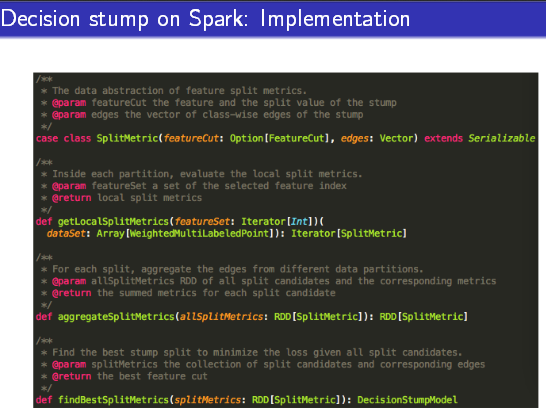
Decision Stump的实现
在具体的实现过程中,白刚展示了Decision Stump的模型效果和训练过程Spark集群负载等数据,分析其中存在的一些问题:首先,它是一个非常弱的二分类模型;其次,Decision stump模型训练的数据传输量很大;最后,Tree-based模型,并不适合高维稀疏数据。因此,需要一个更强的,更易于训练,并且适应高维稀疏数据的φ(.)来针对feature space做二元划分。
4. Generalized binary φ on Apache Spark

白刚表示,通过对Spark的考量发现,Spark.mllib.classification中已有的模型和算法就符合我们的要求:首先,SVM和LR是比较强的二分类模型;其次,训练过程采用GradientDescent或者LBFGS的数值优化方法,易于训练、效率较高;最后使用SparseVector,支持高维稀疏数据。关于使用些模型的正确性的依据,在AdaBoost机制中,只要base learner比random guess(正确率0.5)好,整体就是收敛的,由于弱分类器中的vote vector的存在,可以保证每个label上的错误率都小于0.5。
后续工作

分享最后,白刚对现有的不足之处和可以优化的方向进行了总结,并邀请大家参与这个已经投放在GitHub上的项目,fork及pull request。
|






