| 一
概要介绍
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的,是建立在
Hadoop 上的数据仓库基础构架。作为Hadoop的一个数据仓库工具,Hive可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能。
Hive 主要提供以下功能:
1. 它提供了一系列的工具,可用来对数据进行提取/转化/加载(ETL);
2. 是一种可以存储、查询和分析存储在HDFS(或者HBase)中的大规模数据的机制;
3. 查询是通过MapReduce来完成的(并不是所有的查询都需要MapReduce来完成,比如select
* from XXX就不需要;
Hive设计目的就是用来管理和查询结构化数据,它屏蔽了底层将sql语句转换为MapReduce任务过程,为用户提供的简单的SQL语句,将用户从复杂的MapReduce编程中解脱出来。
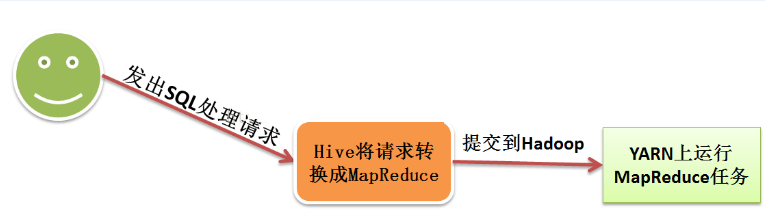
Hive提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在
Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉
SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者开发自定义的 mapper
和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive使用关系数据库中的表、行、列、模式等概念,学起来很容易。学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
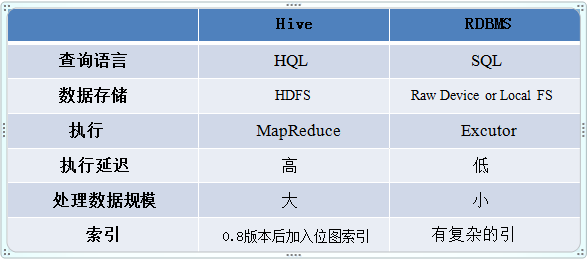
Hive与传统关系数据库的对比
二 Hive的体系架构
Hive的整体架构,如下图所示
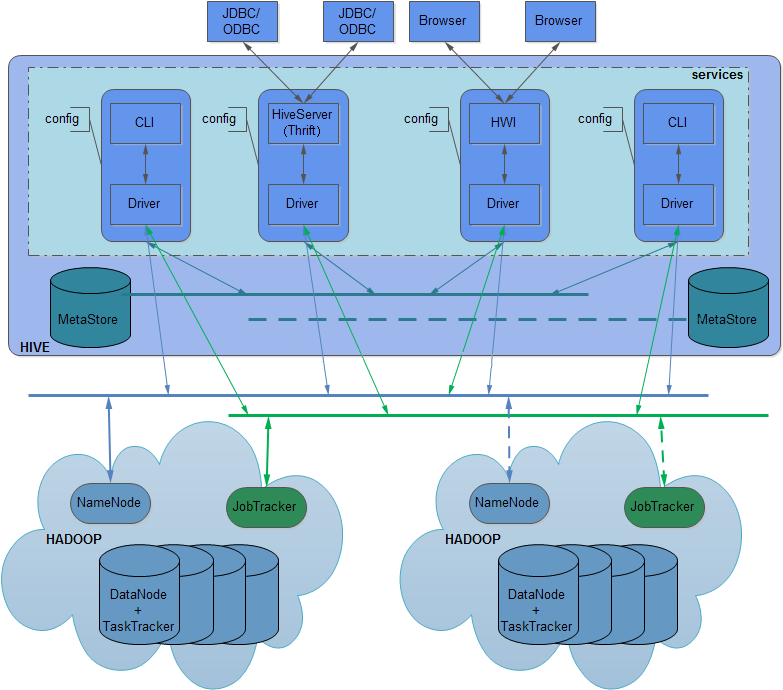
Hive的主要部件如下:
1.用户接口:CLI(command-line interface,命令行界面)、JDBC/ODBC、Broswer
2.Driver: 接受query的组件,该组件实现session的概念,以处理和提供基于JDBC/ODBC执行。
3.编译器: 该组件分析query,在不同的查询块和查询表达式上进行语义分析,并最终通过从metastore中查找表与分区的元信息生成执行计划。
4.Metastore:存储数据仓库里所有的各种表与分区的结构化信息,包括列与列类型信息,序列化器与反序列化器,从而能够读写hdfs中的数据。
Metastore 包含如下的部分:
Database 是表(table)的名字空间。默认的数据库(database)名为‘default’
Table 表(table)的原数据包含信息有:列(list of columns)和它们的类型(types),拥有者(owner),存储空间(storage)和SerDei信息
Partition 每个分区(partition)都有自己的列(columns),SerDe和存储空间(storage)。这一特征将被用来支持Hive中的模式演变(schema
evolution)
注:Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
由于Hive的元数据需要不断的更新、修改,而HDFS系统中的文件是多读少改的,这显然不能将Hive的元数据存储在HDFS中。目前Hive将元数据存储在数据库中,如Mysql、Derby中。
5.执行引擎:此组件执行由compiler创建的执行计划。此计划是一个关于阶段的有向无环图。执行引擎管理不同阶段的依赖关系,并在合适的系统组件上执行这些阶段
Hive查询语言
HiveQL是一个类SQL的查询语言。它模仿SQL语法来创建表,读表到数据,并查询表。HiveQL也允许用户嵌入他们自定义的map-reduce脚本。这些脚本能用任何支持基于行的流式接口的语言写-从标准输入读入并写到标准输出。这种灵活性也有一定的代价:即字符串的转换带来的性能损失。尽管如此,我们看到用户似乎不介意于此,他们自己实现这些脚本。另一个特性是多表插入。在此构造下,用户可以在相同的数据上通过一条HiveQL执行多query。Hive优化这些query,从而能共享输入数据的扫描,这样就增加了这些query的几个数量级的吞吐量。
三 Hive 中的数据模型
Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉
Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。Hive 中所有的数据都存储在 HDFS
中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
注:如果不指定分割符的话,hive默认的分隔符是\001
表=》分区=》桶,它们的对数据的划分粒度越来越小
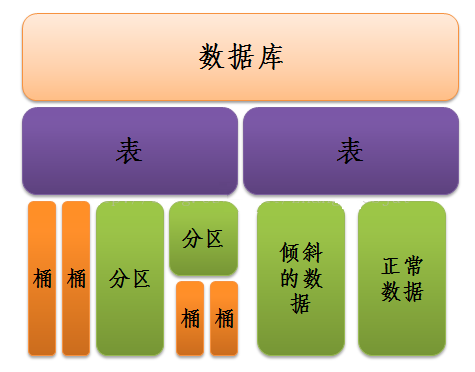
Hive数据抽象结构图
表
Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个
Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh
是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir}
指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
分区
Partition 对应于数据库中的 Partition 列的密集索引,但是
Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition
对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds
和 city 两个 Partition,则对应于 ds = 20090801, ctry = US 的
HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801,
ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
注意:表中可以不包括Partition字段
桶
Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个
Bucket 对应一个文件。例如将 user 列分散至 32 个 bucket,首先对 user 列的值计算
hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash
值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020
Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
外部表, External Table 指向已经在 HDFS 中存在的数据,可以创建
Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。External
Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在
LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 External
Table 时,仅删除元数据,表中的数据不会真正被删。
1. 内部表
create table zz (name string , age string) location '/input/table_data'; |
注:hive默认创建的是内部表
此时,会在hdfs上新建一个zz表的数据存放地
load data inpath '/input/data' into table zz; |
会将hdfs上的/input/data目录下的数据转移到/input/table_data目录下。删除zz表后,会将zz表的数据和元数据信息全部删除,即最后/input/table_data下无数据,当然/input/data下再上一步已经没有了数据!
如果创建内部表时没有指定location,就会在/user/hive/warehouse/下新建一个表目录,其余情况同上。
注:load data会转移数据
2. 外部表
create external table et (name string , age string); |
会在/user/hive/warehouse/新建一个表目录et
load data inpath '/input/edata' into table et; |
把hdfs上/input/edata/下的数据转到/user/hive/warehouse/et下,删除这个外部表后,/user/hive/warehouse/et下的数据不会删除,但是/input/edata/下的数据在上一步load后已经没有了!数据的位置发生了变化!本质是load一个hdfs上的数据时会转移数据!
3. 小结
最后归纳一下Hive中表与外部表的区别:
1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下(如果指定了location的话),也就是说外部表中的数据并不是由它自己来管理的!而内部表则不一样;
2、在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
3. 在创建内部表或外部表时加上location 的效果是一样的,只不过表目录的位置不同而已,加上partition用法也一样,只不过表目录下会有分区目录而已,load
data local inpath直接把本地文件系统的数据上传到hdfs上,有location上传到location指定的位置上,没有的话上传到hive默认配置的数据仓库中。
|






