���������˻�����������������һ����ܡ�Ϊ��ʹ�������Ӿ��壬����Ϊ��ܵIJ���ѡ����һЩֵ��������Щֵ�д�����֤�������Dz������Ǵ���ġ�������һ�����������ݵ��Ѽ������ֹ���Ӧ�ø���ʵ����������¹��ƵIJ���ֵ���в��ԡ����ֿ�ܶ��ڲ�ͬ�����ϵͳ������������Ρ���ģ���Ӷȵ�˼�룬���Ҳ��ٲ�ȡϸ���ȵĹ��ֽܷ⡣Ϊ�������ĸ�������������
Estimate Professional �����Ĺ��ߣ����Թ���һ��ǰ�ˣ��Ӷ��ṩһ�ֻ��������Ĺ�ģ����IJ�ͬ�ķ�����
ֱ���Ͽ������ƺ���������ģ�͵����������ԶԿ�����������Ĺ�ģ���������й��ơ��Ͼ�������ģ�Ͳ����˹�����������ô�ѵ���Ӧ���л��ڵȼ��ڹ��ܵ����������������������ѣ�
- �����ͬ�����������ʽ����ʽ�����Ѷ���һ�������������磬ij�˿���ϣ���ܹ����������ij��ȣ�
- ����Ӧ�ô����ⲿ�����߶���ϵͳ�Ĺ۵㣬��ˣ�500,000 sloc ϵͳ���������� 5,000
sloc ��ϵͳ����������ȫ��ͬ�IJ���ϣ�Cockburn 97 �����˲�κ�Ŀ��ĸ����
- ���������ڸ����Է��治ͬ����дʱ����ʽ�ģ�ʵ��ʱ������ʽ�ġ�
- ����Ӧ�ôӲ����ߵĽǶ���������Ϊ������������൱���ӣ��ر��ǵ�ϵͳ����״̬ʱ�������������������ģ�����������������Ϊ��Ҫϵͳ��ģ�ͣ���ʵ������֮ǰ��������ͼ������Ϊ����ʱ���⽫���¹���Ĺ��ֽܷ��κ�ϸ�ڡ�
���ԣ�Ϊ���ܹ������������Ƿ��б�Ҫʵ��һЩ����������أ������Ƕ���ֱ�Ӹ����������й��Ƶ��������ߣ������ڹ��ܵ��������ĸ���֮��ֱ�ӻ��ȺŶ����Dz����������ܵ������ļ���������ζ���Ҫһ��ϵͳģ�͡������������������Ĺ��ܵ���Ҫ�ﵽ����������һ�µIJ�Σ�����ֻ�дﵽ�ò��ʱ�����Dz��ܹ��Թ��ܵ�����������ġ�Fetcke
97 ������һ�ִ����������ܵ��ӳ�䣬���ǣ������IJ�α����ʵ�������ӳ�������Ч�������ķ���ʹ�û��������ڶ���Ķ�������Ϊ��Դ��PRICE
Object Points ����һ������������(Minkiewicz 96)��
����������ʽ����������Ĺ����൱�걸�D�DHurlbut 97 �Դ��кܺõĸ����������������������ƵĶ�����ȴ��������Graham
95 �� Graham 98 �а����˶��������൱�ϸ�������������Ҳ�����ȫ����Ϊʲô����Ϊ�����뷨�������Ǵ��ྶͥ�ģ������ҽ��齫"����"��Ϊ�˷���������ķ����D�D�������ǵı仯�ij��Ⱥ��Ӷȡ�Graham
��"ԭ������"��"�����"�����ռ��Ļ�����ԭ���������ڵ������������ڵͲ㣺����
Graham��˵��������������������Ϊһ����һ�ľ��ӣ������������ʹ�ñ������������ô���ܸ���һ�����зֽ⡣Graham
��"������"����һ�����߸����ԭ������������ÿһ��������"�ڳ�ʼ���ƻ������У���һ��ϵͳ�������ö�Ӧ"
(Graham 98)����Щ���������ҿ����ƺ��dz���Ͳ�������������Щԭ��������ͬ�������������еIJ��衣Ȼ�������ֲ�η����������Ȼû�н����
Karner��Karner 93����Major��Major 98����Armour���Լ�Catherwood��Armour
96���� Thomson��Thomson 94���������������Ĺ�����Karner ��������ָ���˼����������һ�ַ��������Ǹ÷�����Ȼ������Щ��������һ��ͨ�������ʵ�ֵķ�ʽ������ģ����磬��һ�ָ����ʵ�ϸ�ڲ���϶�������ϵͳ�ϣ���
��ô������Ӧ�ò�ʹ�����������ƶ���������ʵ�ֵķ�����������������������������Ƶ������������������Ѿ���ȡ�ü�������Ŀ�����ߵ�Ҫ��D�D��Ҫ������Ʋ��Ҳ��ò�ʹ������������������Ŀ��������˵��Ϊ������Ŀ�滮������ܹ�������������Ȼ��������о����������������������Һ���ͷ���ؽ��й�����
������������һ����ܣ��ڸÿ���п���ʹ���κβ�ε��������γɹ��������ơ�Ϊ��չʾ��Щ�۵㣬����������һЩ�Ĺ淶�ṹ����Щ�ṹ������ص�һ��ʵ�������ϵ�ά�Ⱥ�ģ�������д���Ǵģ�����Ӧ��˵ȱ�����ݵģ��Ʋ⣬��Ϊ��û�������ķ�����������������ȱ�ٵĹ��������ݵ����⡣����������"����ϵͳ���ɵ�ϵͳ"˼�롣
���������ҽ���ʱƲ������������һЩ�������뱾�������һЩ�����뷨��
���ֽܷ��˼������������������е���������˵��һ��"����"���ҶԹ��ֽܷ������������еļ��ˣ���һ���ܴ��������ͼ����
3000 ��ԭʼת����������������ڳ��˻�����ʩ����û��ʹ���κι��ܵ�˼����������ɣ������Ҹе��쳣���ۡ��ڸ������д��ڵ����ⲻ�����빦�ֽܷ�˼���йأ��������������뷨�йأ���ֱ���ֽ���ܵ�ԭʼ��β�����һ�����̡��ڸò���Ϲ��˵���ij���Ӧ������һҳ��
���õ��Ľ����������D�D����Ҫ�ĸ��߲�ε���Ϊ��δ���Щԭʼת�������ֳ�������һ����Ѹ���������⣬���ܽṹ���ӳ�䵽�����ṹ�����������ܺ��������������Ҫ�����ر����ԡ���Ͳ�����һ������ì�����������һֱ���зֽ�ֱ���ﵽ���ܹ�"�������"��ԭʼ��Σ�����һ�㣬���ǣ���Щԭʼ���Ƿ��ܹ�ʵ����Эͬ������������߲��Ŀ��ȴ����������߿��Ա�֤����û�а취�����ַ�ʽ�����Ƿǹ��������������Ͻ������ܺͻ�����ʩ��ͨѶ������ϵͳ�ȵȣ���Ӧ�����ŷֽ�������ݽ�������ÿһ�ηֽⶼӦ�ö������ֽ����Ӱ�졣
��ô Bauhaus ����"��ʽ���ӹ���"������أ� ������õ����Դ�Թ������巽������Ҳ����һЩ������ơ����磬�洦�ɼ���ƽ�ݶ��ṹ��ʹ�á������ֻ�����ݶ��Ĺ��ܣ����ҽ�����ȫ���Ϊ���������һ�����ǣ���ô������һЩ�ض����������Dz��ܹ����������
�������ݶ����ѷ�ˮ����������ѩ��
������Щ������Խ���ˣ�������һ������ķ�Χ�ڶ����������Ѿ�ѡ��IJ�ͬ����С����ܿ���ȥ��Щ��ʱ��������ʽ����Ӧ�÷������еĹ��ܺͷǹ����������Լ���������ѧҪ�ܹ�ʦ��Ե����⾭���Ƿǹ�������������ģ�������ҹ���������ڼܹ�ʦ��"�����Ӧ��������"�ľ��顣���������ֽܷ���������������ܣ����ֽ�����˼������µIJ�β��ҹ��ܵ�ԭʼ�����"ģ��"һһƥ�䣩�Ͷ�����ӿڣ���ô��һ���Ǵ���
�������Ŀ���ʹ��ȷ�ţ�����ɹ��ܹ���֮ǰ�����������·ֽ������ˮƽ�������ͨ�����Э����ʵ�֣�����û���κ����塣����һ����ģ��ϵͳ���ԣ���Щ�ֽ�ȷʵ��Ҫ�����μ�
Jacobson 97�����Ƿֽ�ı���ʵʩ����������Ҫ�D�D�ر��ǵ����ֽܷⲻ���㹻�õ�ʱ��
ϵͳ����ʦ��ɹ��ܷ��������ֽܷ���ܷ��乤�������ۺ�һ�����ʱ�������ǹ��ܲ�����ϵͳ���ܵ�Ψһ�������أ�һ��ר�ŵĹ���ʦ�ŶӾ��ܹ���������ͬ����Ʒ����������ס�IEEE
Std 1220��ϵͳ���̹��̵�Ӧ�ú�������Standard for Application and
Management of the Systems Engineering Process���� 6.3
���������˹��ֽܷ��ʹ�ã����ܷ�����Functional Analysis���� 6.3.1 �ڣ����ֽܷ⣨Functional
Decomposition������ϵͳ��Ʒ����������ۺ��� 6.5 ���С�6.5.1 �ڰ�����һЩ�ر���Ȥ�����ݣ����飨Group�����ܺͷ��䣨Allocate�����ܣ�6.5.2
�����������������ѡ��Physical Solution Alternatives������ 6.3.1
����ָ�����ֽ�����������������ϵͳ���������Щ���ܣ�����һ�������һ��ֽ���㹻�ˡ�
ע�⣬���ֽܷ��Ŀ�IJ�����Ϊϵͳ���ͣ����ۺϹ���������ɶ��ͣ������������ͨϵͳ�������ʲô�D�D����ģ�����ܹ������Щ�ĺõķ�ʽ�����ۺ��У��ӹ������ȱ��������������Ľṹ��Ȼ�����������������D�D���뿼�����е��������ַ����Ͷ�㹦�ֽܷ�֮��IJ�֮ͬ�����ڣ���ÿһ�㶼��ͼ�����Ҫ�����Ϊ�������ھ����Ƿ����Ϊ����һ����Ҫ���������Լ����䵽���Ͳ�������֮ǰ���ҵ�һ�ֽ��������ʵ����
��
���п��Եó�һ�����۾��ǣ����κβ����ʹ�����ٸ�������������Ϊ��û�б�Ҫ�ġ����ܺ��������ⲿ����������س��������ܹ�ǡ���ظ�����Ҫ�����Ķ���ϵͳ����ϵͳ���ࣩ����Ϊ����Ӧ�ý�һ������˵���ⲿ������ָʲô����һ������ϵͳ��ɵ�ϵͳ���ӣ���Щ��ϵͳ��������ɡ�����ϵͳ��������ߵ��������ҳ�֮Ϊ�ⲿ��������ϵͳ�����������Լ��������D�D���Ƕ���ϵͳ��˵���ڲ����������Ƕ�����ϵͳ��˵���ⲿ������������������һ���Ӵ�ϵͳ������
100 ���д��룩���ⲿ�������ڲ��������������������ټƣ���Ϊ������ģ��ϵͳ����������ϵͳ���������ٰ�����ϵͳ��
����������
�� IBM Rational �У�������Ϊ����������Ӧ�ú�С��10��50 ������������ʶ������������100
��������������������Ҫ���й��ֽܷ⣬�ڹ��ֽܷ����������ڲ����ߺ���ֵ��Ȼ������ʵ����Ŀ��������Ȼ�ܹ����ִ�������������������"����"�������ڲ������ȫ��ġ����磬��
Rational �ڲ��ĵ����ʼ��У�����������һ�� Ericsson ���ӣ�
- Ericsson���Դֵ���һ���绰�������Ľ�ģ������Ҫ���� 600 �����꣨��࣬3 ��400
��������Ա����200 ��������ʹ�ò�ֹһ����������ο�"����ϵͳ���ɵ�ϵͳ"������һ������
600 ���꣨���ж���أ�150���� C++ �����𣿣���ϵͳ����������������������ϵͳ�����ijһ���ϣ�Ҳ����˵�����һ���˶�����һ��
7000 �� 10000 �д������ϵͳ�������������������������ӡ�
��ˣ�����Ȼǿ�����ֹ۵㼴�������ⲿ�������ʺϵġ�Ϊ��ƥ������������Ľṹ����Ҷ��� 10 ���ⲿ������ÿ����������
30 ����س��� �������������Ϊ�Ǻ��ʵ� �����ʵ�������������������� 10 ��������ȷʵ���ⲿ��������ô������������ϵͳҪ����Ӧ�Ĺ淶ϵͳ���и����ģ�����������ҽ��ṩһЩ֧��������˵����Щ�����Ǻ����ġ�
�ṹ�ֲ�
����Ľṹ�ֲ����£�
4 - ���ϵͳ��ɵ�ϵͳ
3 - ϵͳ
2 - ��ϵͳ��
1 - ��ϵͳ
0 - ��
�����ϵͳ�� UML �ж���Ϊ���� UML �и���ľۺ�����ϵͳ��������ϵͳ����Ϊ�˸��Ľ����������ҽ����˲�ͬ��������������Щ֪��
2167 �� 498 ������������ϵͳΪ CSC������Ϊ CSU���е����������˵����ϵͳ�飨subsystemGroup���Ĺ�ģ��
CSCI -����ʾ���Ҽǵã����� 2167 ��Ĺ��� Ada �ĽṹӦ��ӳ�䵽��һ��ε����ۺ����䶨��Ada
��ͨ��ӳ��Ϊ CSU���Ҳ�������ϵͳ�����ϸ����ѭ���ֲ�νṹ���������ڲ��֮��Ļ�ϣ����ֲ�νṹʹ���ܹ����õ��˽��ģ����ÿ��������������Ӱ�졣
��ÿһ���϶��������������ܶ��ڵ���������ܲ������������������ǵ����Ĵ���ϸ�ڶ��� ��������������Ǹ����ϵ�ÿ�������������ϵͳ����ϵͳ�飬�ȵȣ������������������Զ���ÿһ���ÿһ���������
10 �������D�D�������������ƽ���� 10 ҳ����ô�������һ��DZ�ڵġ���Լ 100 ҳ���ȵ�˵���ĵ�����Ҫ�������ƵĻ�����һЩ�Ĺ��ڷ�ϵͳ���������Ӧ˵����������
Stevens 98 �ᳫ�����֣����Һ�Royce98�Ƽ������ֺܽӽ�������Ϊʲô�� 10 �������أ�Ϊ�˵ó�������֣����ڶ�ÿһ����ϵͳ�������������Ĺ�ģ��������ģ�ȵ�����Ϊ�ĺ����Ĺ�ģ���ҽ������������ϵ���������Щ���������蹲ͬ�Ѽ����±��й�������á�

��û�д����ľ������ݣ��ᴩ���е�������ġ���ɢ�����ݣ�Lorentz 94 �� Henderson-Sellers
96 ��һЩ���ݣ���Ҳ��һЩ�ڰĴ����ǵ���Ŀ�еó������ݣ���Ҫ���ھ��ú��պ��������κ�����£�������Σ�����ܻ����ٵĶ�λ�����ʵ�λ���Ƿdz���Ҫ�ġ�
������Ӧ��ָ�����ǣ�������ʹ�ô���������������Ĵ�С���������˲�ϲ�����ֶ�������Щ�� C++��������ͬ��ε����ԣ������У����ԣ�Ҫ�ص����ܵ�dz����ס�
�������е������Ŀ���ܱ������Ϊ�ķḻ��֮��϶��������ϵ����ѡ���� 8 ����/��ϵͳ ��8 ����ϵͳ/��ϵͳ�飬8
����ϵͳ��/��ϵͳ���ȵȡ���ôΪʲô�� 8 ���أ�
1. ���� 7 ��2 ֮�䣻
2. ����ÿ������ 850 slocs��ÿ 70 slocs �� 12 ���������� C++���룬���ó���һ����ϵͳ�Ĺ�ģ��
7000 slocs��һ��������С���Ŷӣ�3��7�ˣ��� 4��9 ���¾��ܹ������Ĺ���/����ij���飬����ϵͳ�ĵ������Ⱦõ�����
30 ��100 ��slocs (RUP 99) �ķ�Χ�� ��
��ô�����������ܹ�����˸������Ϊ���ⲿ�ģ�������Щ��������ϵͳ�IJ����Ѿ�����λ����ϵͳ���ˣ������ḻ�Ե�ԭ����������������������ÿ�������ij������������ڣ���û�ж��ٷ�����ָ������/������չ�D�D��Booch
98�У�Grady Booch ָ��"����һ����������������"����ϵͳ"��һ�����Ӷ��ʵ���ϵͳ�п����м�ʮ�����ڲ���ϵͳ��Ϊ��������ÿ���������ܾ��м�ʮ��������."��Bruce
Powel Douglass �� Douglass 99 ��ָ����"��.Ϊ����ϸ����������Ҫ�ܶೡ����ͨ����Ҫ1����"����ѡ����
30 ������/�����D�D���"����"�Ľϵ͵�һ�ߣ����� Rechtin���� Rechtin
91�У�ָ��������ʦ�ܹ����� 5 �� 10 ���������õı�������������������ҽ���Ϊ����Э���� 5 ��
10 ���ࣩ���� 10 �� 50 �ֽ������ҽ���Ϊ�������������ַ�ʽ���ͣ����������Ϊ�ñ����ռ�Ķ��ʵ����
��ˣ�10 ��������ÿ������ 30 ��������Ҳ����˵һ�� 300 �����������潫���´�Լ 300 ���������������ڸ���
8 ��������������Ϊ��˵�Ѿ��㹻�ˡ��Ƿ��������ļ���������Ǹ������������أ����Ӧ�� Pareto ��
80-20 ������ô20%���ཫ����80%�Ĺ��ܣ�ͬ����80% �Ĺ��ܽ���ÿ������20%�IJ�������������DZ��ص�˵��������Ҫ20%���ࣨ�ȣ����ﵽ75%�Ĺ��ܲ���ͨ�����������һ��
Pareto �ֲ�ͼ����ͼ 1��
ͼ 1: һ�� Pareto ʽ���ķֲ�ͼ
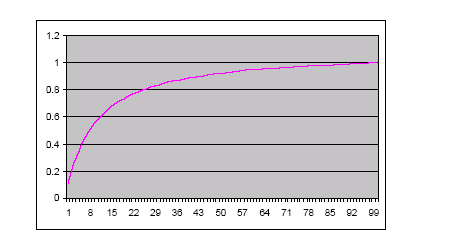
���������Ҫ���� 80% ��ϵͳ��Ϊ�����ҽ� Pareto ����Ӧ�õ��ࡢ�����ͳ����������棬��ô����ÿһ�߶���Ҫ��������Ϊ��
93%(0.933�� 0.8)����Ҳ���Ƕ���ÿһ������Ҫ 50%�����磬4 ����� 5 ������(= (12
�� 2 ������/������)/2)���ڵ����IJ�ͬ�ֲ���������ܴﵽ��ǧ�������нڵ�����������4���༰ÿ����5��������ִ��ģʽ������Ϊÿ���ڵ㴴����
1 �� 3 �����ӣ������ڶ����� 10 ���������ӿڲ������IJ�νṹ�������γ���һ������������⽫����
1000 ��·�����߳��������ԣ�500 ����������õ� 93% �ĸ��ǡ�ʹ�� 300 ������������ͬ�ļٶ������ǿ��Եõ�
73% �ĸ��ǡ�����һ��ѡ�����㷨�����Զ���������������Ӷ�ɾ���������Ϊ˵�����������ٵ���������ȫ���Է���Ҫ��
�ﵽ��Ŀ�ĵ���һ�����������о�һ�¶��� 7000 slocs �� C++������Ҫ���ٲ����������ӳ�����������������Щ�����������ܵ�Ԫ���Բ�ε���Լ��������
Jones 91 �� Boeing 777 ��Ŀ��������֤�ݱ�����������ǰ�ȫ�ģ�����������ʵ������Щ��Դ������
250 �� 280 ֮���Ǻ��ʵġ���һ����ȫ��ͬ�IJ���ϣ����ô��Զ����н�ͨϵͳ��Canadian Automated
Air Traffic System ��CAATS)��Ŀʹ���� 200 ��ϵͳ���ԣ���˽�����Ϥ�ģ���
�����Ĺ�ģ
����Ӧ�þ��ж���ģ�أ��Ƿ�Ӧ���㹻���Լ������㹻��ϸ�ڲ��ܱ�������Ҫ����Ϊ������ȡ������ϵͳ�йص����������ԡ��ڲ��������ⲿ�����������������Ǿ�Ӧ����������ϵͳ���ڲ�����������̽��һ��������⡣�����ԣ����ⲿ��Ϊ����������ϵͳ��Ҫ�����������������������磬�����Ϊ����ʷ��¼���в��Һܸ��ӣ���ô��û��ϵͳ�ڲ���һЩ����ģ�ͼ���Ϊ�Ķ���ʱ���ͺ�����������ע�⣬û�б�Ҫ����һ��ϵͳ����δ��ڲ������ģ����κ�����ǹ����������ƥ��ģ����Ϊ����ƾ��ܹ�����Ҫ��
UML 1.3 ���ṩ�Ķ����ǣ�"�������ࡿ��һ��ϵͳ����ִ�еĶ������������壩���е�˵����������Щ������ϵͳ�����߽��н���"���Ը��ӵ���Ϊ���ڲ����������ܺ����IJ����������Ҳ������ʵ�ֽ��ٽ��ж���D�D����������û���˵�Ǹ���Զ�IJ��衣ҵ�����ҲӦ�����뵽�������Ա�Լ�������ߵ���Ϊ�����磬��һ��ATMϵͳ�У�������Ҫ��һ��������һ�ν����У���ȡ�Ľ��ܳ���
500 ��Ԫ�������˺��е����Ϊ���٣���
�������ֽ��ͣ��¼���������������ҳ������Ϊ 2��20 ���Ӽ���ĽǶ��Ͽ������м���Ϊ��ϵͳ��Ȼ����Ҫ�߳����������������ǿ�����Ϊ������ϵͳͨ����
2 �� 10 ҳ��������ƽ��Ϊ 5 ҳ�����ڸ����ӵ�ϵͳ��˵��ҵ��ϵͳ�Ϳ�ѧϵͳ�� 6 �� 15 ҳ֮�䣬ƽ��Ϊ
9 ҳ�����ӵ�����Ϳ���ϵͳ�� 8 �� 20 ҳ֮�䣬ƽ��Ϊ 12 ҳ����Щ���ʷ�ӳ����ͬ��ģϵͳ�Ĺ�����������֮��ķ����Թ�ϵ����������û��������֧�����ֹ۵㡣�����б������������Ե���ʽ������״̬�����ͼ��������Ҫ���ٵ�ƪ�����������Ծ������ڼ�ǿ�ı������Դ˴�������������ʽ���Ͼ�������Ϻ��ٻ��߸���û�С�
��������ģ��ϵͳ����Ŀ���Ӧ�����ó˷���������������Щ��������ϵó���ÿ��������Сʱ�����ҽ�������һ��
COCOMO -��ʽ�ijɱ���������������ϵͳ���͵ģ���ҵ�����͡������ӵ����͡�����������͵ȵȣ��Ĺ۲쵽��ƽ����ģ�����ƽ����ģ��
������ģ����һ�������dz��������������磬һ�� 5 ҳ��������������һ�����кܶ�·���ĸ��ӽṹ����һ�����꣬��Ҫ�������������Լ������������Ϊ
30�������Ҷ���ÿ�������ij������ij������ƣ���������Ϊ�ɱ����������ء�
�õ��Ľ���ǣ����Ǽ�����ڴ�Լ����Ϊ 100 ҳ˵���������������κθ�����ε��ⲿ˵��������˵����˵�������㹻�ġ���Χ��
20 �� 200 ҳ֮�䣨��Щ������ģ���ģ���ע�⣬һ��ϵͳ����ϵͳ�飩����͵IJ���ϵ������� 3��15
ҳ/ ksloc����ҵ��ϵͳ���� 12��30 ҳ/ ksloc�����ӵ�����Ϳ���ϵͳ����������ܹ�����
Royce 98 ���е� 14��9 ��ʵ����Ŀ֮�����Ե�ì��֮����ǰ�ߵĹ�����ռ�õ�ƪ���dz��٣���ʵ����Ŀȴռ���˴�����ҳ�����ĵĹ۵���Ϊ���˵���IJ�β�Ӧ��ҳ�������ơ�����Royce
����ȷ�ģ����ڴ��͵ġ����ӵ�ϵͳ���ԣ���Ҫ���ݵ�˵������汾���������Դﵽ��Χ�����ިD�D200 ҳ
��ϵͳ���
һ����ϵͳ��ο���ȥ��ʲô�أ�������һЩ���ù��ļ�"��"��ʽ��ע�⣬��Щֻ������ʵ��һ��ϵͳ�ĸ�����ʽ��ʵ��ϵͳ�ķ�Χ��������Щ��ʽ�ļ��ϣ�����ÿ����ϵͳ�ⲿ�������ܺ;���ϵͳȫ�����ⲿ��������ˣ�һ��ʵ�ʵ�ϵͳ�����г���
10 ���ⲿ�����������������Ǻ��潫Ҫ�����������������������ġ�ע�⣬���ﲢ���ǽ������еĿ����������ǵ�������ʹ��
4 ��������С��ϵͳ��<5 �� slocs������ֻ�� 1 ����� 2 �㡣
��һ��
�ڵ�һ�㣬����ͨ����������ϵ���ϵͳ�е���ʵ�ֵ�����
ͼ 1: һ�� Pareto ʽ���ķֲ�ͼ
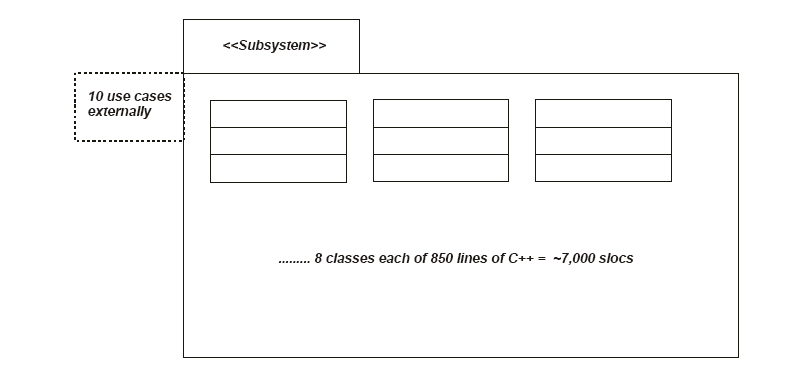
����һ�����ϵͳ��ϵͳ���п�ͨ������ʵ�ֵ���������ģ�ķ�Χ��ʹ��7�����ߣ�2�ĸ����
- 2 �� 9 ���ࣨû���γɵ���ϵͳ�У��D�D1700 slocs �� 8000 slocs ������
- �� 5 ������ɵ���ϵͳ������ 4000 slocs
- �� 7 ������ɵ���ϵͳΪ 9 �������� 53,550 slocs
��ΧΪ 2 �� 76 �����������Ǹ�ģ���Ľ��ޣ����ٶ���������˵�������ĨD�D�ڸ����£������ַ�ʽ����һ��ϵͳ���������ģ�ϣ�����ԶҲ��ʹ�ø��߲����ʽ��������Ҫ�����Ϊ����ô����������Ӧ�ý����㡣������������ִ����㣬��ô���ǻ������㡣
�ڶ���
�ڵڶ�������ϣ�������һ���� 8 ����ϵͳ��ɵ���ϵͳ�顣����Ϊ���ͬ�ڷ����������еļ����ϵͳ�����computer
system configuration item ��CSC I)������һ�㣬������ͨ����ϵͳ��Э����ʵ�ֵģ�
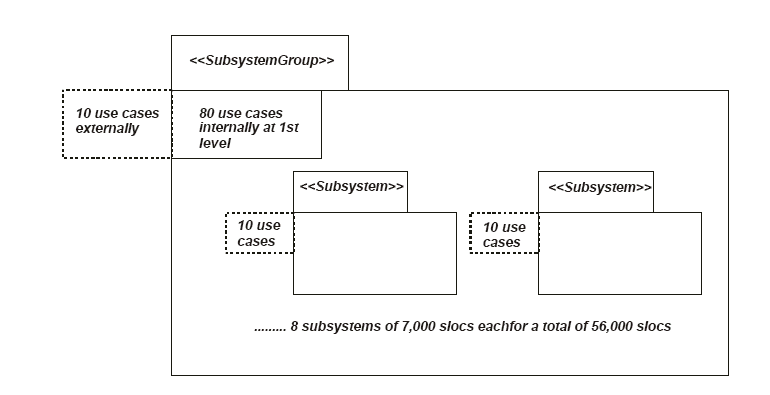
����һ�����ϵͳ��ģ�ķ�Χ��ʹ�� 7�����ߣ�2 �ĸ����
- ���� 5 ����ϵͳ��ÿ����ϵͳ�� 5 ���ࣩ��ɵ���ϵͳ�飬���� 22,000 slocs����
- 9 ���� 7 ����ϵͳ��ÿ����ϵͳ��7���ࣩ��ɵ���ϵͳ�飬���� 370,000 slocs��
�����˵���ⲿ�����ķ�Χ�� 4 �� 66���ٴ����꣬��Щֻ��ģ���Ľ��ޡ�
������
�ڵ����㣬���Ǿ���һ��ϵͳ������ϵͳ�鹹�ɣ�������һ�㣬������ͨ����ϵͳ���Э����ʵ�ֵģ�
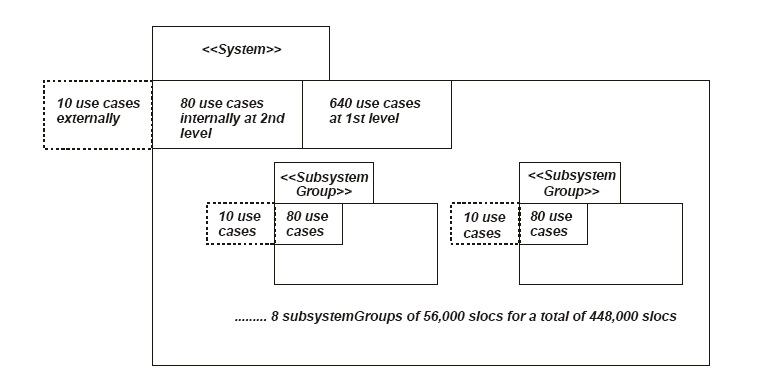
����һ�����ϵͳ��ģ�ķ�Χ��ʹ�� 7�����ߣ�2 �ĸ����
- �� 1 ��ϵͳ���� 5 ����ϵͳ����ɣ�ÿ����ϵͳ������ 5 ����ϵͳ��ÿ����ϵͳ��5���ࣩ��ɣ�����
11 �� slocs����
- 9 ��ϵͳ��ÿһ��ϵͳ���� 7 ����ϵͳ����ɣ�ÿ����ϵͳ������ 7 ����ϵͳ��ÿ����ϵͳ�� 7
���ࣩ��ɣ����� 260 �� slocs ������ɡ��ⲿ�����ķ�Χ�� 3 �� 58���ٴ����꣬��Щ������ģ���ġ�
���IJ�
�ڵ��IJ��У�������һ����ϵͳ��ɵ�ϵͳ������һ�㣬������ͨ��ϵͳ��Э����ʵ�ֵģ�
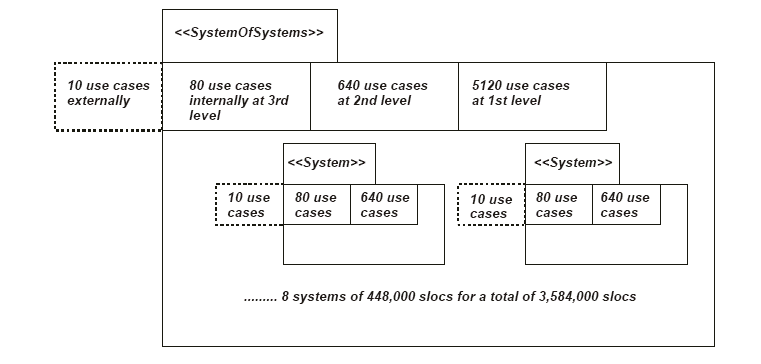
����һ�����ϵͳ��ģ�ķ�Χ��ʹ�� 7�����ߣ�2 �ĸ����
- �� 1 ���� 5 ��ϵͳ��ɵ�ϵͳ��ÿ��ϵͳ���� 5 ����ϵͳ����ɣ�ÿ����ϵͳ������ 5 ����ϵͳ��ÿ����ϵͳ��
5 ���ࣩ��ɣ����� 54 �� slocs����
- 9 ����ϵͳ��ɵ�ϵͳ��ÿ����ϵͳ��7��ϵͳ��ɣ�ÿ��ϵͳ�� 7 ����ϵͳ����ɣ�ÿ����ϵͳ����
7 ����ϵͳ��ÿ����ϵͳ��7���ࣩ��ɣ����� 1800 �� slocs ������ɡ��ⲿ�����ķ�Χ��
2 �� 51��������һ�Σ���Щ������ģ���ġ�
�������ľۺ�Ҳ�ǿ��ܵģ�������ʵ�ڲ����ٿ����ˣ�
ÿ�������Ĺ�����
ͨ����ÿһ��Ķ�Ĺ�ģ�Ĺ��������ƣ����ǿ��Զ�ÿ�������Ĺ�������һЩ�����˽⡣ʹ�� Estimate
Professional? ���� ������ COCOMO 2 �� Putnam's SLIM ģ�ͣ�������������Ϊ
C++�������ɱ�������������Ϊ�ֵ����Ȼ�����ÿһ��ʾ��ϵͳ������ÿ�����ģ��Ĺ����������� 10
���ⲿ���������õ��� 1������������ L1 �� L2 ��Χ���ǵ��˵��������ĸ��ӶȨD�Dʹ�� COCOMO
�Ĵ��븴���Ծ���ͨ����Ƚ��й��ơ��� L2 �㣬�����Ÿ������ڱ�����ϵͳ���͵�����ʱ���ӳ̶ȷ����仯�����һ�����߲�εĸ�������Ϳ���ϵͳ��������������һ���ϵ͵IJ���ϸ����ԵĻ�ϡ���һ������
log-log ������ͼ�ϻ�����Щ���ݣ��õ�ͼ 2��

ͼ 2: ������������ģͼ
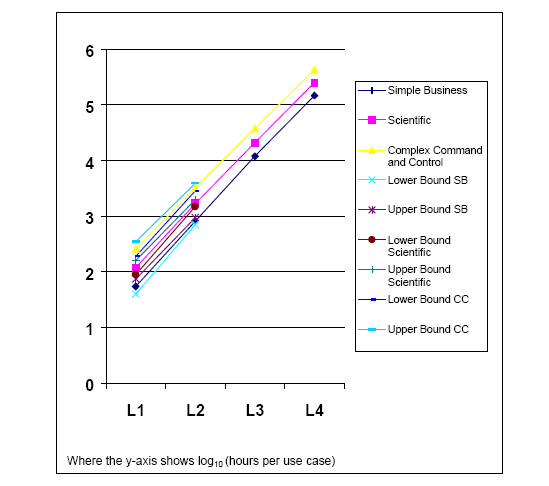
�������ǿ��Կ�����150-350 Сʱ/������10 2.17-10 2.54�����ԭ���� Objectory
������ L1 ���Ϻ��ʺϣ����磬��Щ��������ͨ�����Э����ʵ�֨D�D��˴���һЩ������֧��������֡�Ȼ�������������ڷ�������������������Ŀ�����ҵ�һλͬ�����ڵ����ʼ����ҽ���ʱ˵����̫"Ƭ��"
�ˡ�
��ǰ��ʵ��ϵͳ��������Щ�ۣ�slot��һһƥ�䡣���ԣ�Ϊ�˰����˽�Ӧ���������һ��ϵͳ�����ǽ�ʹ�ôӸ÷����ֵó���ģ���Ľ��������ǻ��Ƴ�����
Figure 3: ÿ����εĹ�ģ��Χ
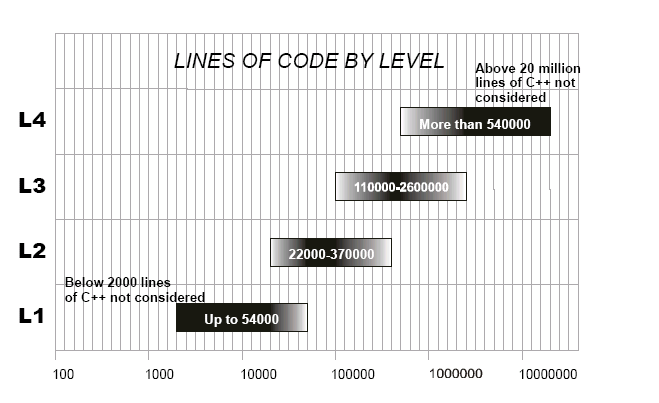
��
��ͼ 3 �У����ǿ��Կ���һ������ 2.2 �� slocs ��ϵͳ��������ڵ�һ��������������������
2 �� 30 ֮�䡣�������ģ�ϣ����ߵ�����������������������̫ϸ�ˡ�
��ģ�� 2.2 �� �� 5.4 �� slocs ֮���ϵͳ��Ӧ��ʹ��һ�����������������Ļ�ϣ�������������
4�����ڵڶ��㣩�� 76 ���ڵ�һ�㣩֮�䣬������ͼ��������������һ�㲻����ּ���ֵ��
��ģ�� 5.4 ��� 11 �� slocs ֮���ϵͳ��һ���ṹ�õ�ϵͳ��ȫ�ڵڶ�����������ǿ��ܵģ�������������
10 �� 20 ֮�䣻������������� L1/L2/L3��1 �� 160 ��������һ�㲻����ּ���ֵ����
��ģ�� 11 �� �� 37 �� slocs ֮���ϵͳ�������ڵڶ���͵�����֮�䣬������������ 3��ȫ���ڵ����㣩��
66��ȫ�ڲ��ڶ��㣩֮�䡣
��ģ�� 37 �� �� 54 �� slocs֮���ϵͳ�������ȫ�ڵ����������������ô������������ 9
�� 12֮�䣻������������ L2/L3/L4��1 �� 100 ��������һ�㲻����ּ���ֵ����
��ģ�� 54 �� �� 260 �� slocs ֮���ϵͳ�������ڵ�����͵��IJ�֮�䣬������������ 2��ȫ���ڵ��IJ㣩��
60��ȫ���ڵ����㣩֮�䡣
��ģ���� 260 �� slocs ��ϵͳ���ڵ��IJ����������Ӧ���� 8 ���ҡ�
�������������㹻��?
��һЩ���鷨���п��Եõ�һЩ��Ȥ�Ĺ۲�������һ�����⾭�����ʼ��������������ǹ������أ��������ʵ������ζ���ڲ�������Ĺ����ж����ǹ��������ƺ��Ƕ���
70 ����������������ϵͳ��˵��70 �������Ҳ�������������˵����̫ϸ�ˡ��� 5 �� 40 ֮���Ƿdz����ʵģ�������ֻ������������û�п��ǵ���Σ������������ƹ�ģ�����������dz�ʼ����������������IJ���Ǻ��ʵġ����һ�����ͳ���ϵͳ���ֽ�Ϊϵͳ��ϵͳ�ֱ��ֽ�Ϊ��ϵͳ���Դ����ƣ���ô��Ҫ���ټƵ����������ֱ����IJ�δﵽ��ſ�����������ô���յ������������ϰٸ���������ǧ��������һ��
140 �ˣ������Ŀ�����߶���ÿ��������15�����ܵ���������Ŀ��˵�� 600 ����������Ȼ������Ϊһ������Ķ�������Ƶ������ֽ���˵���Ⲣ���ᷢ������Щ������Դ��
Jacobson 97 �������Ĺ��̣�Jacobson 97 ��ϵͳ����ϵ�����������Ϊ�������ϵͳ����Ϊ�����п���Ϊ��ϵͳ��д���Ͳ�ε���������������ϵͳ��Ϊ�����ߣ���
���������ƵĹ���
��ν��й����أ������������Ⱦ����������������������������˽�ϵͳ�Ĺ�ģ��ϵͳ���ܣ��Լ�����һ�ν��й��ƣ���ô�Ͳ��ܹ����л��������Ĺ��ơ�
��һ�δ��ԵĹ��ƿ��Ը���ר�ҵĹ۵���߸���ʽ�IJ��� Wideband Delphi �������ü�����Rand
��֯�� 1948 �귢���ģ���ο�Boehm 81 �����������⽫ʹ�������߿��Խ�ϵͳ��ͼ 3 ��ʾ�Ĺ�ģ��Χ�жԺ����䡣���ֲ����ṩ���������ķ�Χ�����ұ�������ʽ�IJ�Σ�L1,
L1/L2 �ȵȣ���Ȼ�������߱�����ڶ����й���֪ʶ�������е�������������Щ�����Ƿ��ʺ�ijһ�㣨�Ƿ������أ��������Dz�ͬ��εĻ�ϣ����¼����ķ�ʽ�������
����Щ�����п��Կ����������Ƿ��������Զ����ģ������磺��� Delphi ������ 60 ���д��루���ߵȼ۵Ĺ��ܵ㣩�����Ҽ���û��ʲô���ܷ���Ĺ�������ô����ϵͳ�ṹ����֪���ò����࣭��ͼ
3 ��������������Ӧ���� 2�����еĵ��IJ㣩�� 14�����еĵ����㣩�����ʵ�������������� 100����ô���������Ѿ���ǰ�����˷ֽ⣬����
Delphi �Ĺ������س��졣
��������������ӣ����ʵ�ʵ������������� 20�����������߾������Ƕ��� L3������һ�����������ij���ƽ��7ҳ������ϵͳ��һ�ָ��ӵ�ҵ��ϵͳ��ÿ��������Сʱ������ͼ
2 �еõ�����20��000��Ϊ�˽����Ӷȣ�Ҫ���� 7/9�����������ij��ȣ������Ը������ַ�������Ĺ�������
20��20000��(7/9) = ~310,000 �ˣ�Сʱ������ 2050 ���¡����� Estimate
Professional������ҵ��ϵͳ���ԣ�60 ���е� C++������Ҫ 1928 ���¡���ˣ��������Ƶ������У������������һ�㡣
���ʵ�ʵ������������� 5�����������߾����� 1 ���������䵽 L4������ 4 �����䵽�����㡣����һ��
L4 ������ 12 ҳ��L3 ����ƽ���� 10 ҳ��Ȼ����㹤�������� 1��250,000��12/9+4��21000��(10/9)
= ~2800 ���¡���ͱ��� Delphi �Ĺ�����Ҫ���½����������ܼ���ϵͳ����Ҫ���ֿ�������Ȼ�ںܸߵIJ���ϣ�����֮�ڱ߽����кܴ�Ĵ���
���ԭ���� Delphi ������ 10 ���� C++���룬ͼ 3 ��������Ӧ���� L2 ����Ӧ���� 18
�������ʵ������ 20 ������ͬǰ�������һ������� Delphi ���ƺ����Ļ�����ô����Ϊ������ʵ��������ζ�Ӧ�ø÷������ó�һ������ȷ�Ľ����
��ˣ������߱����������Ƿ��ڽ���ij���IJ���ϣ�L2�����ҿ���ͨ����ϵͳ��Э����ʵ�֣��Լ�����������ȫ��
L3 �ϣ������� Wideband Delphi ���������Ǿ�����ô��⣨���磬Ԥ�� 10 ��ʵ�����ǽӽ�
60 ����������������������ʹ��ʱʹ��ȱ�����ţ�û�ж�Ļ��߸����ϵĹ��ܣ�����Щ�������Ǻ������IJ����ƥ��ġ�����һ���ڸ�����dz��о������������˵��ģ�Ϳ�����һ���ܹ��ж��γ���һ���������ģ�ͣ�������һ������Ƚ��ٵ����������Ŷ���˵����һЩ���ܽ�ģ���۲�һ����һ������IJ��������ʵ�ֵ���Σ���ʧΪһ������֮�١�
���ڸ��ϱ����������Ҳ����˵����� N �Ͳ�� N+1�Ļ�ϣ�Ӧ�ü���Ϊ n=8(l��������IJ���)
���ó������ڽϵ�һ�����������ˣ�һ���������� 50%�� L1 ���� 50% �� L2����ôӦ�ü���Ϊ
80.5 = 3 �� L1 ������һ������������ L2 �� L3 ֮��� 30%����ôӦ�ü���Ϊ80.3
L2 ����= 2 �� L2 ������һ�������� L2 �� L3 ֮��� 90%����ôӦ�ü���Ϊ 80.9
= 7 �� L2 ������
���Ĺ�ģ����
ʵ���Ͽ����ܵĹ�������ģʱ����Ҫ�Ը���������Сʱ������һ�������D�D������������ֻ�ʺ����ڸù�ģϵͳ���������е�ÿһ������ϡ���ˣ��ڱ�
1 �е� L1 �㣬������һ�� 7000 slocs ��ϵͳʱ��������ÿһ������ 55 Сʱ��ʵ�ʵ����ֽ�ȡ�����ܵ�ϵͳ��ģ�D�D�������Ҫ������ϵͳ�Ĺ�ģ��
40,000 slocs ����ʹ�� 57 �� 1 �������������������ô����һ����ҵ��ϵͳ��˵�������Ͳ���55��57
Сʱ������(40/7)0.11 �� 55 = 66 Сʱ/���������ǻ��ڹ�ģ�������� COCOMO 2
��ϵ������ COCOMO ģ�ͣ���������A �� (size)1.11,����
- size �ĵ�λΪ ksloc
- A Ϊ�ɱ���������
- ��Ŀ��������Ϊ�ֵ���� 1.11 ����ָ����
ע����Щ���������Ϊ�����õ����� Estimate Professional�����Ĺ����У��Ӷ�������㸺�����˴������г������ǡ�
���ÿ ksloc �Ĺ���������ÿ��Ԫ���������� A�� (Size)1.11/Size�������Ƴ� A��
(Size)0.11����ˣ�ÿ��Ԫ�Ĺ������� size Ϊ S1 �� S2 �ı���Ϊ(S1/S2)0.11��
�� Delphi ���ƻ�Ҫ˵��һ�㣬ϵͳ�Ĺ�ģ���ԴӸ����������������������Եؼ������������ڵ�һ����
N1 ���������ڵڶ����� N2 ������������ N3 �������IJ����� N4 ������ô�ܵĹ�ģ����[(N1/10)��7
+ (N2/10)��56 + (N3/10)��448 + (N4/10)��3584] ksloc����ˣ����ǿ��Լ��㹤�������ϱ�
1 �е�ÿ�������Ĺ�������Ȼ���ܵĹ�ģ���Ա�1�е�һ�����г���ÿһ��Ĺ�ģ����λ�� ksloc����
���, �ڵ�һ��, (0.1��N1 + 0.8��N2 + 6.4��N3 + 51.2��N4)0.11��
�ڶ��� (0.0125��N1 + 0.1��N2 + 0.8��N3 + 6.4��N4)0.11��
������, (0.00156��N1 + 0.0125��N2 + 0.1��N3 + 0.8��N4)0.11��
���IJ�, (0.00002��N1 + 0.00156��N2 + 0.0125�� N3 + 0.1��N4)0.11��
��Ȼ���Ե��IJ�Ϊ��������������IJ������������ȣ���һ��������������Ӱ��������
���������˻�����������������һ����ܡ�Ϊ��ʹ�������Ӿ��壬����Ϊ��ܵIJ���ѡ����һЩֵ��������Щֵ�д�����֤�������Dz������Ǵ���ġ�������һ�����������ݵ��Ѽ������ֹ���Ӧ�ø���ʵ����������¹��ƵIJ���ֵ���в��ԡ����ֿ�ܶ��ڲ�ͬ�����ϵͳ������������Ρ���ģ���Ӷȵ�˼�룬���Ҳ��ٲ�ȡϸ���ȵĹ��ֽܷ⡣Ϊ�������ĸ�������������
Estimate Professional �����Ĺ��ߣ����Թ���һ��ǰ�ˣ��Ӷ��ṩһ�ֻ��������Ĺ�ģ����IJ�ͬ�ķ�����
�Ա���Ƥ��������Լ������������ͨ�������ʼ�
jsmith@rational.com �� John Smith ȡ����ϵ��
�����Բ��ı����� developerWorks ȫ��վ���ϵ�
Ӣ��ԭ����
1. Armour96: Experiences Measuring Object Oriented
System Size with Use Cases, F. Armour, B. Catherwood,
et al., Proc. ESCOM, Wilmslow, UK, 1996
2. Boehm81: Software Engineering Economics, Barry W.
Boehm, Prentice-Hall, 1981
3. Booch98: The Unified Modeling Language User Guide,
Grady Booch, James Rumbaugh, Ivar Jacobson, Addison-Wesley,
1998
4. Cockburn97: Structuring Use Cases with Goals, Alistair
Cockburn, Journal of Object-Oriented Programming, Sept-Oct
1997 and Nov-Dec 1997
5. Douglass99: Doing Hard Time, Bruce Powel Douglass,
Addison Wesley, 1999
6. Fetcke97: Mapping the OO-Jacobson Approach into
Function Point Analysis, T. Fetcke, A. Abran, et al.,
Proc. TOOLS USA 97, Santa Barbara, California, 1997.
7. Graham95: Migrating to Object Technology, Ian Graham,
Addison-Wesley, 1995
8. Graham98: Requirements Engineering and Rapid Development,
Ian Graham, Addison-Wesley, 1998
9. Henderson-Sellers96: Object-Oriented Metrics, Brian
Henderson-Sellers, Prentice Hall, 1996
10. Hurlbut97: A Survey of Approaches For Describing
and Formalizing Use Cases, Russell R. Hurlbut, Technical
Report: XPT-TR-97-03,
http://www.iit.edu/~rhurlbut/xpt-tr-97-03.pdf
11. Jacobson97: Software Reuse - Architecture, Process
and Organization for Business Success, Ivar Jacobson,
Martin Griss, Patrik Jonsson, Addison-Wesley/ACM Press,
1997
12. Jones91: Applied Software Measurement, Capers Jones,
McGraw-Hill, 1991
13. Karner93: Use Case Points - Resource Estimation
for Objectory Projects, Gustav Karner, Objective Systems
SF AB (copyright owned by Rational Software), 1993
14. Lorentz94: Object-Oriented Software Metrics, Mark
Lorentz, Jeff Kidd, Prentice Hall, 1994
15. Major98: A Qualitative Analysis of Two Requirements
Capturing Techniques for Estimating the Size of Object-Oriented
Software Projects, Melissa Major and John D. McGregor,
Dept. of Computer Science Technical Report 98-002, Clemson
University, 1998
16. Minkiewicz96: Estimating Size for Object-Oriented
Software, Arlene F. Minkiewicz,
http://www.pricesystems.com/foresight/arlepops.htm,
1996
17. Pehrson96: Software Development for the Boeing
777, Ron J. Pehrson, CrossTalk, January 1996
18. Putnam92: Measures for Excellence, Lawrence H.
Putnam, Ware Myers, Yourdon Press, 1992
19. Rechtin91: Systems Architecting, Creating &
Building Complex Systems, E. Rechtin, Prentice-Hall,
1991
20. Royce98: Software Project Management, Walker Royce,
Addison Wesley, 1998
21. RUP99: Rational Unified Process, Rational Software,
1999
22. Stevens98: Systems Engineering - Coping with Complexity,
R. Stevens, P. Brook, et al., Prentice Hall, 1998
23. Thomson94: Project Estimation Using an Adaptation
of Function Points and Use Cases for OO Projects, N.
Thomson, R. Johnson, et al., Proc. Workshop on Pragmatic
and Theoretical Directions in Object-Oriented Software
Metrics, OOPSLA '94, 1994
| 