| 编辑推荐: |
本文主要介绍了复习 pod 相关核心结构、pod 如何对外提供访问及pod 的负载均衡。希望对您的学习有所帮助。
本文来自于微信公众号InfoQ 架构头条,由Linda编辑、推荐。 |
|
1.5 亿,这个数字,是 Capillary 的 Engage+ 产品在新年高峰时段两小时内发送的通信量。即便是这样的小故障,也会影响到我们客户的资本和我们产品的信誉。
故障就像一场大爆炸,它们可以是手榴弹的爆炸,也可以是核弹级别的爆炸,而爆炸造成的破坏取决于爆炸半径。
再好的系统,也会有出故障的一天。若不及早发现并加以处置,也会加剧造成更大的破坏。
请注意,这篇文章将着重于微服务设计中的健壮性和故障恢复,尤其着重于微服务间的通信与故障恢复。
1 动机
在微服务架构环境中,一项服务一旦出现故障,就会对其他服务产生影响,进而造成产品的多次更新,使用户失去对产品的信心。在
Engage+ 中,我们采用了一种编排的微服务架构。因为时间的关系,我将不会详细描述这个模型的细节。简而言之,我的意思是说:
在一个编排的微服务架构中,系统的每个组成部分都不依靠单一的中心控制点,而是涉及有关业务事务工作流程的决策。
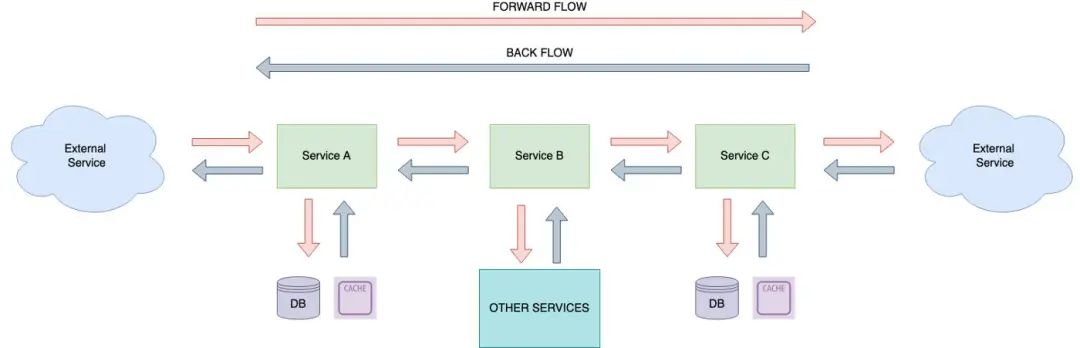
从图中我们可以看到,在决策过程中涉及了许多的服务,所以在这个架构下,处理任何故障就如同在干草垛中寻找一根针那样艰难。所以,我们怎样才能在它把整个干草垛都烧掉之前,检测出这些故障,然后再控制它们的爆炸半径?
2 故障与恢复
其基本可以分成两大大类:
服务之间的故障:这些是在 Capillary 内运行的其他微型服务
基础设施级别的通信故障:这些故障可能包含基础设施组件,如数据库(MySQL)、队列(RabbitMQ)等。
让我们看看更多的细节:
服务之间的故障
下游服务可能会因为各种各样的原因而失去响应,从而造成故障。
这些故障的原因有很多,比如 CPU 使用率过高会引起很多无响应的调用、应用程序线程的耗尽、服务内存的问题等等。
按照行业标准,一项服务必须具有 99.999% 的可用性,才能被视为高可用性。例如,服务“A”依赖于其他
5 个服务。如果所有的下游服务都有 99% 的可用性,则服务“A”的可用性最多可以达到 95%。
(0.99) ^ 5 = 0.95
(0.999) ^ 5 = 0.995
所以,我们应该怎么做?
识别问题:
任何恢复工作首先要了解故障。了解问题是否存在、问题在何处,以及问题是什么,这对处理故障缓解问题的工程师来说非常关键。比如,像
AppDynamics 和 New Relic 这样的监控工具,就能让工程师了解应用程序的基本概况,以及每分钟请求数、Apdex
和资源指标等关键指标。
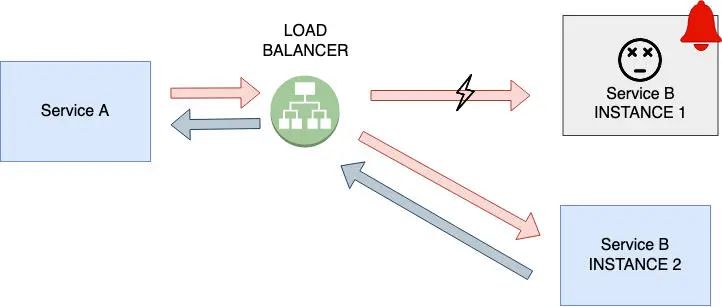
故障恢复前的弹性:
如果其中一个服务实例发生故障,服务的职责仍然必须得到满足。微服务应当横向扩展,以允许多个实例,确保如果服务的一个实例发生故障,其他实例可以接管并响应调用者的服务。这就消除了架构中没有单点故障的问题。
异步通信,可避免短期中断:
从同步通信转换为异步通信,可以减轻短时间的中断。所以,当服务重新启动时,将处理该请求。这可以通过在通信双方之间建立高可用性的队列通信服务来完成。但是,这个方法有一个缺陷,那就是它不适合于单纯的同步与实时系统,所以开发人员在使用这种策略时,要非常慎重。

自动恢复:
假定工程师已经被及时告知,而服务中断的问题已经被处理,所有等待响应的服务都应该重试调用,并从此时开始接收有效的响应。在所有基于重试的调用中,必须强制执行幂等性(Idempotency)。这种方法还可以帮助处理服务之间的网络中断问题。
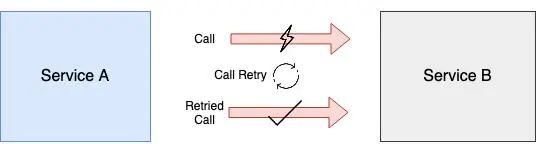
手动恢复:
有时候,恢复服务要花费很长的一段时间,而系统的自动恢复可能会被耗尽。尽管这种方法是最不建议的,但是工程师们也许要试着手动恢复了。这通常包括一系列
API/ 数据操作的步骤,以便将系统恢复到一个一致性的状态。注意,复杂的手动恢复 ToDo 清单常常会使工程师们的士气和自信心下降。

基础设施级别通信故障:
基础设施故障就像一个系统上发生核弹爆炸。像数据库无反应、队列崩溃等问题都属于此类问题。这类故障并不常见,但是却有可能破坏整个系统,而且要想从这种错误中恢复过来,将会变得更加困难,因为很多时候,你可能会丢失数据。
数据库故障:
数据库出了故障肯定会导致整个系统崩溃,下面我们来看看我们可以干些什么:
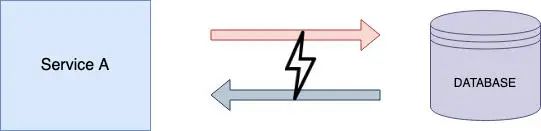
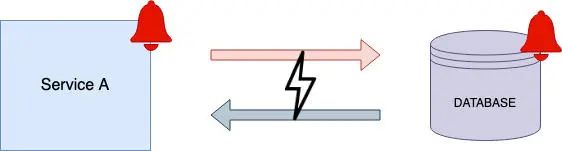
警报:
无论是服务还是数据库,都应当向工程师发出事故通知。长期而言,对数据库资源使用情况的实时监控和警报,将有助于工程师在局势变得极其棘手之前把你救出来。
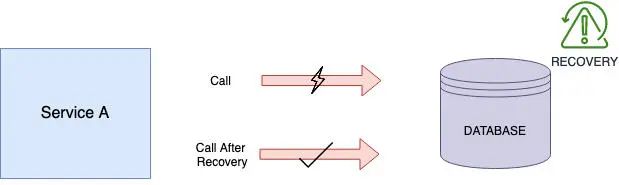
恢复:
人们可以选择利用第三方云管理数据库实现自动恢复。第三方管理的数据库,如
Aurora db 用于基于 SQL 的数据库,MongoDB Atlas 用于基于文档的数据库,都有内置的备份和恢复机制。对于自我维护的数据库,你可以参考这个博客。这里的恢复涉及避免数据丢失,一旦恢复,重试就可以接管,微服务能够恢复正常工作。
队列故障:
这里可能出现的故障可能是队列由于某种原因而无响应,或者在极端情况下与资源有关的队列崩溃,这些故障可能直接导致数据丢失。

写入优先方法:
对于队列故障,重要的是要避免数据丢失。最佳做法是使用写入优先方法。当发生故障时,必须将进入队列的消息持久化到外部磁盘中,这样就可以恢复中断的消息。对于像
RabbitMQ 和亚马逊云科技 SQS 这样的队列,持久化的选项是开箱即用的,而且是基于配置的。
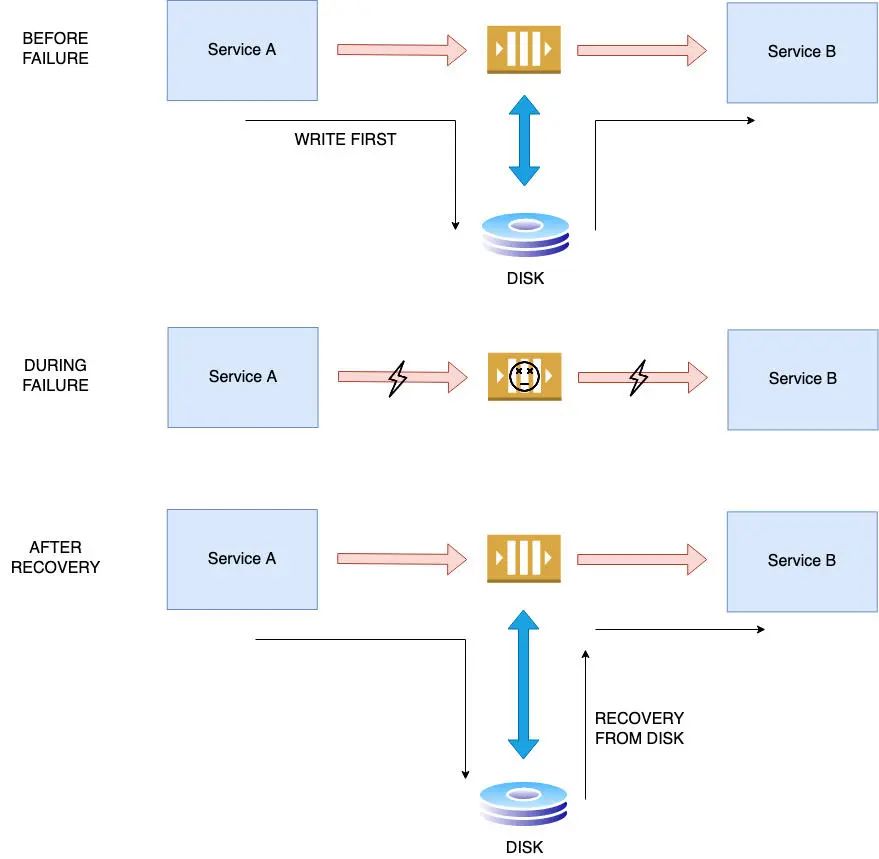
对于 RabbitMQ 来说,一旦可以使用懒惰队列和持久化消息等功能,在崩溃的情况下更有弹性,允许工程师采用写入优先策略,并在出错的情况下将数据保留在磁盘上。
为实现弹性的更多途径:
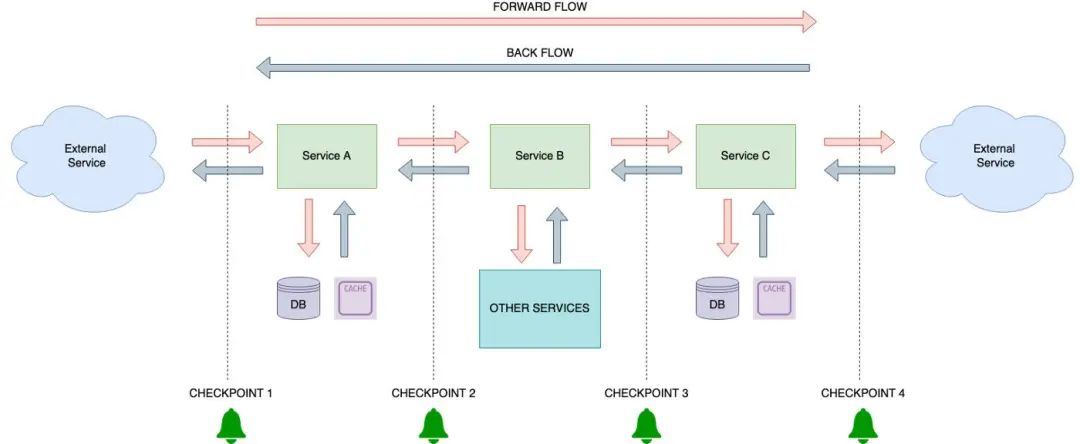
在简单的编排微服务架构中添加了检查点
在一个编排的微服务架构中,我们可以使用检查点。我们把这个过程称为“活动检查”。对于从一个微服务到另一个微服务的消息,添加检查点将有助于实时监控流程,并有助于确定问题的时间点。
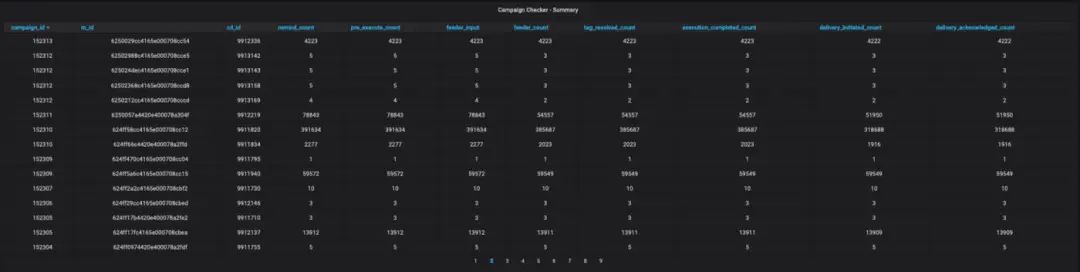
在 Engage+ 检查点仪表板中的活动总数

在活动失败的情况下发出错误通知
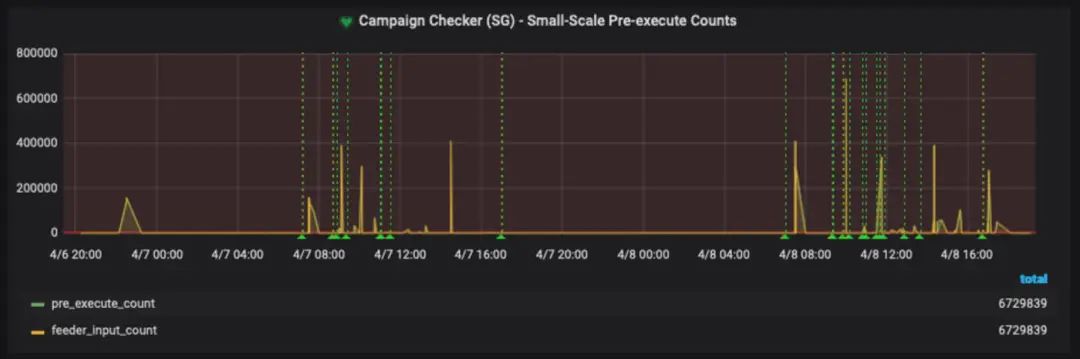
活动趋势和活动失败的心跳
基于服务水平协议的检查点警报将有助于进一步缓解问题。如果在检查点之间没有达到时间阈值,就会触发警报,这可以帮助工程师确定故障的确切位置,并加快缓解。
影响
以下是我们所产生的影响:
产品稳定性:
所有这些变化的最大动力是产品的稳定性。每一次失败都会导致产品升级,并使我们的产品声誉受损。在实施弹性后,我们开始观察到在产品升级方面的显著改善。
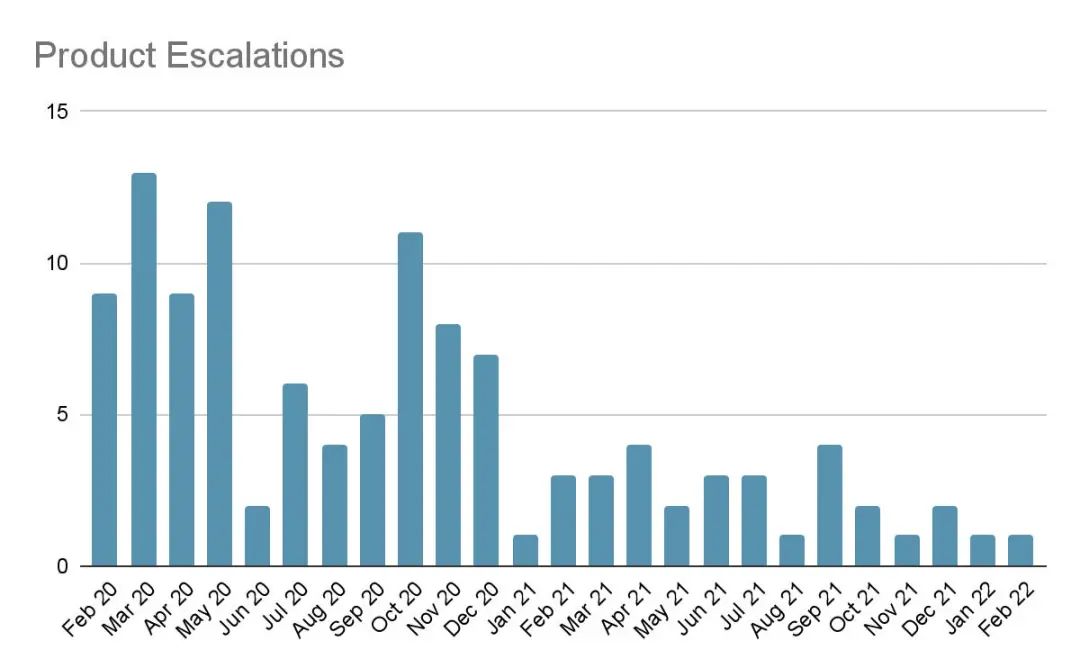
Engage+ 产品升级的两年
工程带宽:
在我们实施这些更改之前,我们的开发团队不得不手动恢复每一个失败的活动。这涉及一个漫长而艰难的手工过程,我们必须调出所有失败的活动数据,然后逐一进行核对。
随着重试和自动恢复特性的引入,数千次对下游服务的呼叫得到了恢复,而无需任何人工干预。同样的情况也可以从我们的仪表盘中看到,我们跟踪所有从一个服务到另一个服务的调用的性能。以前,所有这些故障都与整个产品的故障相对应,但现在,在重试之后,这些故障得到了自动恢复。

跨服务仪表盘,带有一周内的通讯号码
引入这种产品弹性有助于工程团队迅速从故障中恢复过来,并减少花在解决问题上的精力,增加时间用于开发人员最喜欢的事情,进行开发。
3 总结
基于以上策略,Capillary 的 Engage+ 产品在 2021~2022
财年发出了约 30 亿条信息。即使在这种规模下,我们的系统也能顺利运行。这些修改不仅提高了我们产品的稳定性,而且还使我们作为工程师的工作变得更加轻松,富有成效。
|







 订阅
订阅