| БрМЭЦМі: |
|
БОЮФжївЊзмНсСЫБОЕиЪТЮёЁЂШЋОжЪТЮёЁЂзюжевЛжТадЕШЗНЪНЪЕЯжЪ§ОнздЧЂЁЃжиЕуНщЩмСЫЪЕЯжзюжевЛжТадЕФМЏжаФЃЪНЃКПЩППЪТМўФЃЪНЁЂTCC
ФЃЪНЁЂSAGA ФЃЪНЕШЁЃЪ§ОнЕФвЛжТадвЛжБЪЧИіФбЬтЃЌЫцзХЮЂЗўЮёЛЏжЎКѓЃЌЪ§ОнвЛжТадИќМгРЇФбЃЌгаРЇФбВЛХТЃЌжЛвЊВЛЗХЦњЃЌзмЛсНтОіЕФ
ЁЃ
БОЮФРДздгкCSDNЃЌгЩLindaБрМЁЂЭЦМіЁЃ |
|
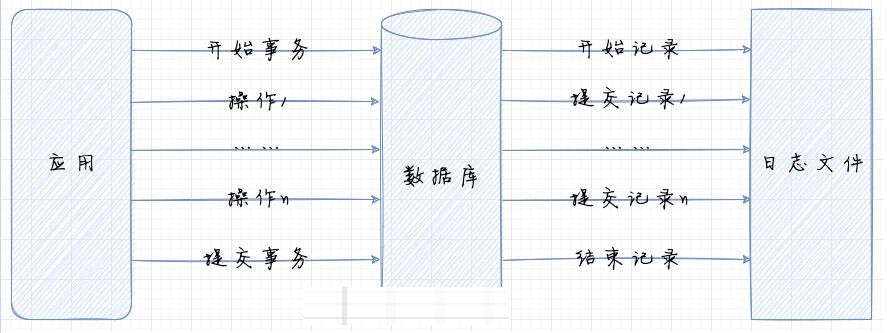
ДгЕЅЬхМмЙЙЕНЗжВМЪНМмЙЙЃЌДгОоЪЏМмЙЙЕНЮЂЗўЮёМмЙЙЁЃЯЕЭГжЎМфЕФНЛЛЅдНРДдНИДдгЃЌЯЕЭГМфЕФЪ§ОнНЛЛЅСПМЖвВЪЧжИЪ§МЖдіГЄЁЃзїЮЊвЛИіЯЕЭГЃЌЮвУЧвЊБЃжЄТпМЕФздЧЂКЭЪ§ОнЕФздЧЂЁЃ
Ъ§ОнздЧЂгаСНЗНУцвЊЧѓЃК
ХзПЊДњТыЃЌЪ§ОнФмЙЛздМКбщжЄздМКЕФзМШЗадЃЌвВОЭЪЧЪ§ОнБЫДЫжЎМфВЛУЌЖм
ЫљгаЪ§ОнзМШЗЧвЗћКЯЦкЭћ
ЮЊСЫЪЕЯжетСНЕуЃЌашвЊЪЕЯжЪ§ОнЕФвЛжТадЃЌЮЊСЫЪЕЯжвЛжТадЃЌОЭашвЊгУЕНЪТЮёЁЃ
ашвЊзЂвтвЛЯТЃЌБОЮФЫљЩшМЦЕФЪ§ОнвЛжТадЃЌВЛЪЧЖрЪ§ОнИББОжЎМфБЃГжЪ§ОнвЛжТадЃЌЖјЪЧЯЕЭГжЎМфЕФвЕЮёЪ§ОнБЃГжвЛжТадЁЃ
БОЕиЪТЮё
дкдчЦкЕФЯЕЭГжаЃЌЮвУЧПЩвдЭЈЙ§ЙиЯЕаЭЪ§ОнПтЕФЪТЮёБЃжЄЪ§ОнЕФвЛжТадЁЃетжжЪТЮёгаЫФИіЛљБОвЊЫиЃКACIDЁЃ
AЃЈAtomicityЃЌдзгадЃЉЃКећИіЪТЮёжаЕФЫљгаВйзїЃЌвЊУДШЋВПЭъГЩЃЌвЊУДШЋВПЪЇАмЃЌВЛПЩФмЭЃжЭдкжаМфФГИіЛЗНкЁЃЪТЮёдкжДааЙ§ГЬжаЗЂЩњДэЮѓЃЌЛсБЛЛиЙіЃЈRollbackЃЉЕНЪТЮёПЊЪМЧАЕФзДЬЌЃЌОЭЯёетИіЪТЮёДгРДУЛгажДааЙ§вЛбљЁЃ
CЃЈConsistencyЃЌвЛжТадЃЉЃКвЛИіЪТЮёПЩвдЗтзАзДЬЌИФБфЃЈГ§ЗЧЫќЪЧвЛИіжЛЖСЕФЃЉЁЃЪТЮёБиаыЪМжеБЃГжЯЕЭГДІгквЛжТЕФзДЬЌЃЌВЛЙмдкШЮКЮИјЖЈЕФЪБМфВЂЗЂЪТЮёгаЖрЩйЁЃ
IЃЈIsolationЃЌИєРыадЃЉЃКИєРызДЬЌжДааЪТЮёЃЌЪЙЫќУЧКУЯёЪЧЯЕЭГдкИјЖЈЪБМфФкжДааЕФЮЈвЛВйзїЁЃШчЙћгаСНИіЪТЮёЃЌдЫаадкЯрЭЌЕФЪБМфФкЃЌжДааЯрЭЌЕФЙІФмЃЌЪТЮёЕФИєРыадНЋШЗБЃУПвЛЪТЮёдкЯЕЭГжаШЯЮЊжЛгаИУЪТЮёдкЪЙгУЯЕЭГЁЃетжжЪєадгаЪБГЦЮЊДЎааЛЏЃЌЮЊСЫЗРжЙЪТЮёВйзїМфЕФЛьЯ§ЃЌБиаыДЎааЛЏЛђађСаЛЏЧыЧѓЃЌЪЙЕУдкЭЌвЛЪБМфНігавЛИіЧыЧѓгУгкЭЌвЛЪ§ОнЁЃ
DЃЈDurabilityЃЌГжОУадЃЉЃКдкЪТЮёЭъГЩвдКѓЃЌИУЪТЮёЖдЪ§ОнПтЫљзїЕФИќИФБуГжОУЕФБЃДцдкЪ§ОнПтжЎжаЃЌВЂВЛЛсБЛЛиЙіЁЃ
етЫФИівЊЫиЪЧЙиЯЕаЭЪ§ОнПтЕФИљБОЁЃЮоТлЯЕЭГЖрУДИДдгЃЌжЛвЊЪЙгУЭЌвЛИіЙиЯЕаЭЪ§ОнПтЃЌЮвУЧОЭПЩвдНшжњЪТЮёБЃжЄЪ§ОнвЛжТадЁЃЛљгкЖдЙиЯЕаЭЪ§ОнПтЕФаХШЮЃЌЮвУЧПЩвдШЯЮЊБОЕиЪТЮёЪЧПЩППЕФЃЌПЊЗЂЙ§ГЬжаВЛашвЊЖюЭтЕФЙЄзїЁЃДгМмЙЙЕФНЧЖШЃЌЙиЯЕаЭЪ§ОнПтвВЪЧвЛИіЕЅЖРЕФЯЕЭГЃЌФЧЙиЯЕаЭЪ§ОнПтгыгІгУжЎМфвВЪЧаЮГЩСЫЗжВМЪНЁЃЫљвдЮвУЧЯШбаОПвЛЯТетжжМђЕЅЕФЗжВМЪНЯЕЭГШчКЮЪЕЯж
ACIDЁЃ
ЪзЯШЃЌAЃЈдзгадЃЉКЭ DЃЈГжОУадЃЉЪЧБЫДЫжЎМфУмВЛПЩЗжЕФСНИіЪєадЃКдзгадБЃжЄСЫЪТЮёЕФЫљгаВйзїЃЌвЊУДШЋВПЭъГЩЃЌвЊУДШЋВПЪЇАмЃЌВЛПЩФмЭЃжЭдкжаМфФГИіЛЗНкЃЛГжОУадБЃжЄСЫвЛЕЉЪТЮёЭъГЩЃЌИУЪТЮёЖдЪ§ОнПтЫљзїЕФИќИФБуГжОУЕФБЃДцдкЪ§ОнПтжЎжаЃЌВЛЛсвђЮЊШЮКЮдвђЖјЕМжТЦфаоИФЕФФкШнБЛГЗЯњЛђЖЊЪЇЁЃ
жкЫљжмжЊЃЌЪ§ОнБиаыаДШыЕНДХХЬКѓВХФмБЃжЄГжОУЛЏЃЌНіНіБЃДцдкФкДцжаЃЌвЛЕЉГіЯжЯЕЭГБРРЃЁЂжїЛњЖЯЕчЕШЧщПіЃЌЪ§ОнОЭЛсЖЊЪЇЁЃЫљвдЃЌЙиМќЪЧЁАаДШыДХХЬЁБвЊЪЕЯждзгадКЭГжОУадЃЌШЛЖјетИіЖЏзїДцдкжаМфЬЌЃКе§дкаДШыЁЃЫљвдЃЌЯжДњЕФЙиЯЕаЭЪ§ОнПтЭЈГЃВЩгУзЗМгШежОМЧТМЕФЗНЪНЁЃНЋаоИФЪ§ОнЫљашЕФШЋВПаХЯЂЃЈАќРЈаоИФЪВУДЪ§ОнЁЂЪ§ОнЮяРэЩЯЮЛгкФФИіФкДцвГКЭДХХЬПщжаЁЂДгЪВУДжЕИФГЩЪВУДжЕЃЌЕШЕШЃЉЃЌвдЫГађзЗМгЕФаЮЪНМЧТМЕНДХХЬжаЁЃжЛгадкШежОМЧТМШЋВПТфХЬЃЌЪ§ОнПтдкШежОжаПДЕНДњБэЪТЮёГЩЙІЬсНЛЕФЁАЬсНЛМЧТМЁБКѓЃЌВХЛсИљОнШежОЩЯЕФаХЯЂЖдеце§ЕФЪ§ОнНјаааоИФЁЃаоИФЭъГЩКѓЃЌдйдкШежОжаМгШывЛЬѕЁАНсЪјМЧТМЁББэЪОЪТЮёвбЭъГЩГжОУЛЏЃЌетжжЪТЮёЪЕЯжЗНЗЈБЛГЦЮЊЁАЬсНЛШежОЁБЁЃ
ЮвУЧФмЙЛЭЈЙ§ШежОБЃжЄвЛИіЪТЮёЕФдзгадКЭГжОУадЃЌФЧШчЙћГіЯжЖрИіЪТЮёЗУЮЪЭЌвЛИізЪдДФиЃПзїЮЊГЬађдГЖМжЊЕРЃЌЖрИіЯпГЬ/НјГЬЗУЮЪЭЌвЛИізЪдДЃЌетИізЪдДОЭГЦЮЊСйНчзЪдДЃЌЯывЊНтОіСйНчзЪдДеМгУГхЭЛЕФЗНЪНКмМђЕЅЃЌОЭЪЧМгЫјЁЃЙиЯЕаЭЪ§ОнПтЮЊЮвУЧзМБИСЫШ§жжЫјЃК
аДЫјЃЈWrite LockЃЉЃКЭЌвЛИіЪБПЬЃЌжЛгагавЛИіЪТЮёЖдЪ§ОнМгаДЫјЃЌЫљвдаДЫјвВБЛГЦЮЊХХЫќЫјЃЈexclusive
LockЃЉЁЃЪ§ОнБЛМгСЫаДЫјКѓЃЌЦфЫћЪТЮёВЛФмаДШыЪ§ОнЃЌвВВЛФмЖдЦфЬэМгЖСЫјЃЈзЂвтЃЌЪЧВЛФмМгЖСЫјЃЌЕЋЪЧПЩвдЖСШЁЪ§ОнЃЉЁЃ
ЖСЫјЃЈRead LockЃЉЃКЭЌвЛЪБПЬЃЌЖрИіЪТЮёПЩвдЖдЪ§ОнЬэМгЖСЫјЃЌЫљвдЖСЫјвВБЛГЦЮЊЙВЯэЫјЃЈShared
LockЃЉЁЃЪ§ОнПтБЛЬэМгЖСЫјКѓЃЌЪ§ОнВЛФмБЛЬэМгаДЫјЁЃ
ЗЖЮЇЫјЃЈRange LockЃЉЃКЖдвЛИіЗЖЮЇЕФЪ§ОнЬэМгаДЫјЃЌетИіЗЖЮЇЕФЪ§ОнВЛФмБЛаДШыЁЃвВПЩвдЫузїаДЫјЕФХњСПааЮЊЁЃ
ИљОнетШ§жжЫјЕФВЛЭЌзщКЯЃЌЮвУЧПЩвдЪЕЯжЫФжжВЛЭЌЕФЪТЮёИєРыМЖБ№ЃК
ПЩДЎааЛЏЃЈSerializableЃЉЃКаДШыЕФЪБКђМгаДЫјЃЌЖСШЁЕФЪБКђМгЖСЫјЃЌЗЖЮЇЖСаДЕФЪБКђМгЗЖЮЇЫјЁЃ
ПЩжиИДЖШЃЈRepeatable ReadЃЉЃКаДШыЕФЪБКђМгаДЫјЃЌЖСШЁЕФЪБКђМгЖСЫјЃЌЗЖЮЇЖСаДЕФЪБКђВЛМгЫјЃЌетбљЛсГіЯжЖСШЁЯрЭЌЗЖЮЇЪ§ОнЕФЪБКђЃЌЗЕЛиНсЙћВЛЭЌЃЌМДЛУЖСЃЈPhantom
ReadЃЉЁЃ
ЖСвбЬсНЛЃЈRead CommittedЃЉЃКаДШыЕФЪБКђМгаДЫјЃЌЖСШЁЕФЪБКђМгЖСЫјЃЌЖСШЁЭъГЩКѓСЂТэЪЭЗХЖСЫјЁЃетбљЛсГіЯжЭЌвЛИіЪТЮёЖрДЮЖСШЁЯрЭЌЪ§ОнЃЌЗЕЛиНсЙћВЛЭЌЃЌМДВЛПЩжиИДЖСЃЈNon-Repeatable
ReadЃЉЁЃ
ЖСЮДЬсНЛЃЈRead UncommittedЃЉЃКаДШыЕФЪБКђМгаДЫјЃЌЖСШЁЕФЪБКђВЛМгЫјЁЃетбљОЭЛсЖСШЁЕНСэвЛИіЛЙЮДЬсНЛЕФЪТЮёаДШыЕФЪ§ОнЃЌМДдрЖСЃЈDirty
ReadЃЉЁЃ
ШЋОжЪТЮё
ЫцзХЯЕЭГЙцФЃВЛЖЯРЉДѓЃЌвЕЮёСПВЛЖЯдіМгЁЃЕЅЬхгІгУВЛдйТњзуашЧѓЃЌЮвУЧЛсВ№ЗжЯЕЭГЃЌШЛКѓВ№ЗжЪ§ОнПтЁЃДЫЪБЃЌЭЌвЛИіЧыЧѓжаЃЌОЭЛсГіЯжЭЌЪБЗУЮЪЖрИіЪ§ОнПтЕФЧщПіЁЃЮЊСЫНтОіетжжЧщПіЕФЪ§ОнвЛжТадЮЪЬтЃЌX/Open
зщжЏдк 1991 ФъЃЈФЧИіЪБКђЮвЛЙаЁЃЉЬсГіСЫвЛЬз X/Open XA ЕФДІРэЪТЮёЕФМмЙЙЁЃXA ЕФКЫаФФкШнЪЧЖЈвхСЫШЋОжЕФЪТЮёЙмРэЦїЃЈTransaction
ManagerЃЌгУгкаЕїШЋОжЪТЮёЃЉКЭОжВПЕФзЪдДЙмРэЦїЃЈResource ManagerЃЌгУгкЧ§ЖЏБОЕиЪТЮёЃЉжЎМфЕФЭЈаХНгПкЃЌдквЛИіЪТЮёЙмРэЦїКЭЖрИізЪдДЙмРэЦїЃЈResource
ManagerЃЉжЎМфаЮГЩЭЈаХЧХСКЃЌЭЈЙ§аЕїЖрИіЪ§ОндДЕФвЛжТЖЏзїЃЌЪЕЯжШЋОжЪТЮёЕФЭГвЛЬсНЛЛђепЭГвЛЛиЙіЁЃгы
XA МмЙЙХфЬзЕФЪЧСННзЖЮЬсНЛавщЃЈ2PCЃЌTwo Phase Commitment ProtocolЃЉЁЃдкетИіавщжаЃЌзюЙиМќЕФЕуОЭЪЧЃЌЖрИіЪ§ОнПтЕФЛюЖЏЃЌОљгЩвЛИіЪТЮёаЕїЦїЕФзщМўРДПижЦЁЃОпЬхЕФЗжЮЊ
5 ИіВНжшЃК
гІгУГЬађЕїгУЪТЮёЙмРэЦїжаЕФЬсНЛЗНЗЈ
ЪТЮёЙмРэЦїНЋСЊТчЪТЮёжаЩцМАЕФУПИіЪ§ОнПтЃЌВЂЭЈжЊЫќУЧзМБИЬсНЛЪТЮёЃЈетЪЧЕквЛНзЖЮЕФПЊЪМЃЉ
НгЪеЕНзМБИЬсНЛЪТЮёЭЈжЊКѓЃЌЪ§ОнПтБиаыШЗБЃФмдкБЛвЊЧѓЬсНЛЪТЮёЪБЬсНЛЪТЮёЃЌЛђдкБЛвЊЧѓЛиЙіЪТЮёЪБЛиЙіЪТЮёЁЃШчЙћЪ§ОнПтЮоЗЈзМБИЪТЮёЃЌЫќЛсвдвЛИіЗёЖЈЯьгІРДЛигІЪТЮёЙмРэЦїЁЃ
ЪТЮёЙмРэЦїЪеМЏРДздИїЪ§ОнПтЕФЫљгаЯьгІЁЃ
дкЕкЖўНзЖЮЃЌЪТЮёЙмРэЦїНЋЪТЮёЕФНсЙћЭЈжЊИјУПИіЪ§ОнПтЁЃШчЙћШЮвЛЪ§ОнПтзіГіЗёЖЈЯьгІЃЌдђЪТЮёЙмРэЦїЛсНЋвЛИіЛиЙіУќСюЗЂЫЭИјЪТЮёжаЩцМАЕФЫљгаЪ§ОнПтЁЃШчЙћЪ§ОнПтЖМзіГіПЯЖЈЯьгІЃЌдђЪТЮёЙмРэЦїЛсжИЪОЫљгаЕФзЪдДЙмРэЦїЬсНЛЪТЮёЁЃвЛЕЉЭЈжЊЪ§ОнПтЬсНЛЃЌДЫКѓЕФЪТЮёОЭВЛФмЪЇАмСЫЁЃЭЈЙ§вдПЯЖЈЕФЗНЪНЯьгІЕквЛНзЖЮЃЌУПИізЪдДЙмРэЦїОљвбШЗБЃЃЌШчЙћвдКѓЭЈжЊЫќЬсНЛЪТЮёЃЌдђЪТЮёВЛЛсЪЇАмЁЃ 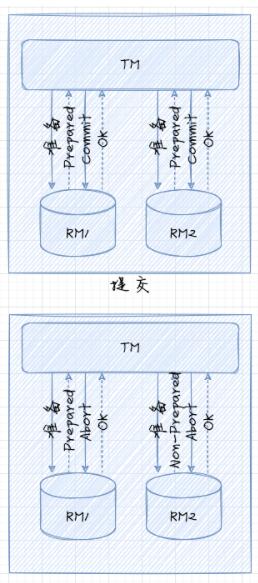
СННзЖЮЬсНЛавщЪЕЯжМђЕЅЃЌЕЋДцдкМИИіУїЯдШБЯнЃК
ЕЅЕуЮЪЬтЃКЪТЮёЙмРэЦїдкСНЖЮЬсНЛжаОпгаОйзуЧсжиЕФзїгУЃЌЪТЮёЙмРэЦїЕШД§зЪдДЙмРэЦїЛиИДЪБПЩвдгаГЌЪБЛњжЦЃЌдЪаэзЪдДЙмРэЦїхДЛњЃЌЕЋзЪдДЙмРэЦїЕШД§ЪТЮёЙмРэЦїжИСюЪБЮоЗЈзіГЌЪБДІРэЁЃвЛЕЉхДЛњЕФВЛЪЧЦфжаФГИізЪдДЙмРэЦїЃЌЖјЪЧЪТЮёЙмРэЦїЕФЛАЃЌЫљгазЪдДЙмРэЦїЖМЛсЪмЕНгАЯьЁЃШчЙћЪТЮёЙмРэЦївЛжБУЛгаЛжИДЃЌУЛгае§ГЃЗЂЫЭ
Commit Лђеп Rollback ЕФжИСюЃЌФЧЫљгазЪдДЙмРэЦїЖМБиаывЛжБЕШД§ЁЃ
адФмЮЪЬтЃКСНЖЮЬсНЛЙ§ГЬжаЃЌЫљгазЪдДЙмРэЦїЯрЕБгкБЛАѓЖЈГЩЮЊвЛИіЭГвЛЕїЖШЕФећЬхЃЌЦкМфвЊОЙ§СНДЮдЖГЬЗўЮёЕїгУЃЌШ§ДЮЪ§ОнГжОУЛЏЃЈзМБИНзЖЮаДжизіШежОЃЌЪТЮёЙмРэЦїзізДЬЌГжОУЛЏЃЌЬсНЛНзЖЮдкШежОаДШы
Commit RecordЃЉЃЌећИіЙ§ГЬНЋГжајЕНзЪдДЙмРэЦїМЏШКжазюТ§ЕФФЧвЛИіДІРэВйзїНсЪјЮЊжЙЃЌетОіЖЈСЫСНЖЮЪНЬсНЛЕФадФмЭЈГЃЖМНЯВюЁЃ
вЛжТадЗчЯеЃКОЁЙмЬсНЛНзЖЮЪБМфКмЖЬЃЌЕЋетШдЪЧвЛЖЮУїШЗДцдкЕФЮЃЯеЦкЁЃШчЙћЪТЮёЙмРэЦїдкЗЂГізМБИжИСюКѓЃЌИљОнЪеЕНИїИізЪдДЙмРэЦїЗЂЛиЕФаХЯЂШЗЖЈЪТЮёзДЬЌЪЧПЩвдЬсНЛЕФЃЌЪТЮёЙмРэЦїЛсЯШГжОУЛЏЪТЮёзДЬЌЃЌВЂЬсНЛздМКЕФЪТЮёЃЌШчЙћетЪБКђЭјТчЖЯПЊЃЌЮоЗЈдйЭЈЙ§ЭјТчЯђЫљгазЪдДЙмРэЦїЗЂГі
Commit жИСюЕФЛАЃЌОЭЛсЕМжТВПЗжЪ§ОнЃЈЪТЮёЙмРэЦїЕФЃЉвбЬсНЛЃЌЕЋВПЗжЪ§ОнЃЈзЪдДЙмРэЦїЕФЃЉМШЮДЬсНЛЃЌвВУЛгаАьЗЈЛиЙіЃЌВњЩњСЫЪ§ОнВЛвЛжТЕФЮЪЬтЁЃ
ФмЙЛЗЂЯжЮЪЬтЃЌОЭФмЙЛЯыЕНАьЗЈНтОіЁЃЮвУЧИпжаРЯЪІЫЕСЫЃЌжЛвЊвтЪЖВЛЛЌЦТЃЌАьЗЈзмБШРЇФбЖрЁЃЫљвдгжЗЂеЙГіСЫШ§НзЖЮЬсНЛавщЃЈ3PCЃЌThree
Phase Commitment ProtocolЃЉЃЌФмЙЛЛКНтЕЅЕуЮЪЬтКЭзМБИНзЖЮЕФадФмЮЪЬтЁЃетИіавщАб
2PC жаЕФзМБИНзЖЮВ№ЗжЮЊ CanCommit КЭ PreCommitЃЌАбЬсНЛНзЖЮИФУћЮЊ DoCommitЁЃCanCommit
ЪЧбЏЮЪНзЖЮЃЌШУУПИізЪдДЙмРэЦїИљОнздЩэЧщПіХаЖЯИУЪТЮёЪЧЗёгаПЩФмЭъГЩЁЃ
3PC БОжЪЪЧЭЈЙ§вЛДЮЮЪбЏЃЌШчЙћДѓМвЖМЫЕздМКПЩвдЃЌФЧГЩЪТЕФПЩФмадКмДѓЃЌМѕЩйСЫзМБИНзЖЮжБНгЫјЖЈзЪдДЕФжиВйзїЁЃгЩгкЪТЮёЪЇАмЛиЙіИХТЪБфаЁЕФдвђЃЌдкШ§ЖЮЪНЬсНЛжаЃЌШчЙћдк
PreCommit НзЖЮжЎКѓЗЂЩњСЫЪТЮёЙмРэЦїхДЛњЃЌМДзЪдДЙмРэЦїУЛгаФмЕШЕН DoCommit ЕФЯћЯЂЕФЛАЃЌФЌШЯЕФВйзїВпТдНЋЪЧЬсНЛЪТЮёЖјВЛЪЧЛиЙіЪТЮёЛђепГжајЕШД§ЃЌетОЭЯрЕБгкБмУтСЫЪТЮёЙмРэЦїЕЅЕуЮЪЬтЕФЗчЯеЁЃ
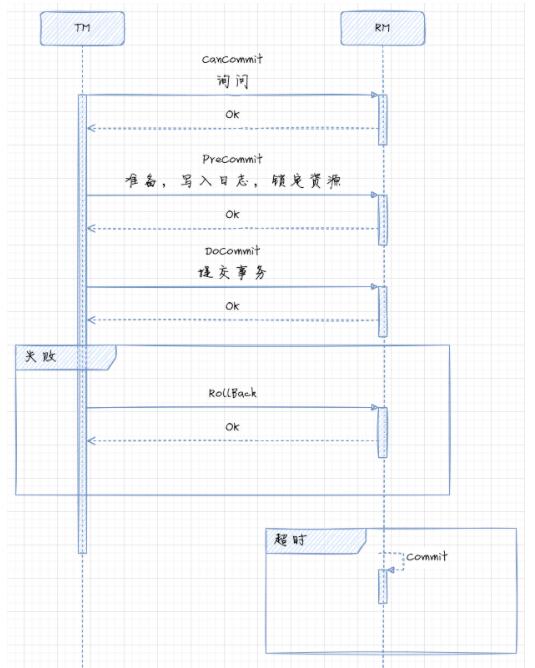
ЗжВМЪНЪТЮё
ЫЕЕНЗжВМЪНЪТЮёЃЌВЛЕУВЛЬс CAP РэТлЃКШЮКЮЗжВМЪНЯЕЭГжЛПЩЭЌЪБТњзувЛжТадЃЈConsistencyЃЉЁЂПЩгУадЃЈAvailabilityЃЉЁЂЗжЧјШнДэадЃЈPartition
toleranceЃЉжаЕФСНЕуЃЌУЛЗЈШ§епМцЙЫЁЃ
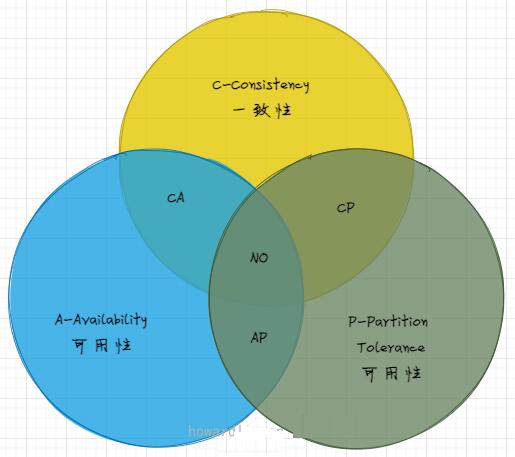
вЛжТадЃЈConsistencyЃЉЃКЪ§ОндкШЮКЮЪБПЬЁЂШЮКЮЗжВМЪННкЕужаЫљПДЕНЕФЖМЪЧЗћКЯдЄЦкЕФЁЃ
ПЩгУадЃЈAvailabilityЃЉЃКЯЕЭГВЛМфЖЯЕиЬсЙЉЗўЮёЕФФмСІЃЌПЩгУадЪЧгЩПЩППадЃЈReliabilityЃЉКЭПЩЮЌЛЄадЃЈServiceabilityЃЉМЦЫуЕУГіЕФБШР§жЕЁЃПЩППадЭЈЙ§ЦНОљЮоЙЪеЯЪБМфЃЈMean
Time Between FailureЃЌMTBFЃЉРДЖШСПЃЛПЩЮЌЛЄадЭЈЙ§ЦНОљПЩаоИДЪБМфЃЈMean Time
To RepairЃЌMTTRЃЉРДЖШСПЁЃПЩгУадКтСПЯЕЭГПЩвде§ГЃЪЙгУЕФЪБМфгызмЪБМфжЎБШЃЌЙЋЪНЮЊЃКA=MTBF/(MTBF+MTTR)ЁЃ
ЗжЧјШнДэадЃЈPartition ToleranceЃЉЃКЗжВМЪНЛЗОГжаВПЗжНкЕувђЭјТчдвђЖјБЫДЫЪЇСЊКѓЃЌЯЕЭГШдФме§ШЗЕиЬсЙЉЗўЮёЕФФмСІЁЃ
CAP РэТлЖЈвхЪЧОЙ§МИДЮаоИФЕФЃЌаоИФКѓЕФЖЈвхБОжЪУЛгаЧјБ№ЃЌжЛЪЧдкТпМЩЯИќМгбЯНїЁЃБОЮФЮЊСЫКУРэНтЃЌЪЙгУСЫзюШнвзШУДѓжкНгЪеВЂРэНтЕФЖЈвхЁЃ
МШШЛ CAP ВЛФмМцЙЫЃЌФЧЮвУЧРДПДПДШБЩйЦфжавЛЛЗЛсГіЯжЪВУДЧщПіЃК
бЁдё CA ЗХЦњ PЃКМДЮвУЧШЯЮЊЭјТчПЩППВЛЛсГіЯжЗжЧјЧщПіЃЌетжжПЩППЪЧИїИіНкЕужЎМфВЛЛсГіЯжЭјТчбгГйЁЂжаЖЯЕШЧщПіЃЌЯдШЛЪЧВЛГЩСЂЕФЁЃ
бЁдё CP ЗХЦњ AЃКетбљзіОЭЪЧХзЦњСЫПЩгУадЃЌЮЊСЫБЃжЄЪ§ОнвЛжТадЃЌвЛЕЉГіЯжЭјТчвьГЃЃЌНкЕужЎМфЕФаХЯЂЭЌВНЪБМфПЩвдЮоЯожЦЕибгГЄЁЃЪЙгУ
CP зщКЯЕФвЛАугУгкЖдЪ§ОнжЪСПвЊЧѓКмИпЕФГЁКЯЃЌвВОЭЪЧЮЊСЫБЃжЄЪ§ОнЭъШЋвЛжТЃЌднЪБВЛЬсЙЉЗўЮёЃЌжБЕНЭјТчЭъШЋЛжИДЃЌетПЩФмГжајвЛИіВЛШЗЖЈЕФЪБМфЃЌгШЦфЪЧдкЯЕЭГвбОБэЯжГіИпбгГйЪБЛђепЭјТчЙЪеЯЕМжТЪЇШЅСЌНгЪБЁЃ
бЁдё AP ЗХЦњ CЃКвтЮЖзХвЛЕЉЗЂЩњЭјТчЗжЧјЃЌгХЯШЬсЙЉЗўЮёПЩгУЃЌЗХЦњЪ§ОнвЛжТадЁЃетЪЧФПЧАЗжВМЪНЯЕЭГЕФжїСїбЁдёЃЌвђЮЊЭјТчБОЩэОЭЪЧСДНгВЛЭЌЧјгђЕФЗўЮёЦїЕФЃЌЭјТчгжЪЧВЛПЩППЕФЃЌЫљвд
P ВЛФмБЛЩсЦњЁЃЭЌЪБЃЌЮвУЧЪЕЯжЗжВМЪНЯЕЭГОЭЪЧЮЊСЫЬсИпПЩгУадЃЌетЪЧЮвУЧЕФФПЕФЃЌВЛФмЩсЦњЁЃ
етРяашвЊдйЫЕУївЛЯТЃЌЮвУЧбЁдё AP ЗХЦњ C ВЛЪЧЗХЦњЪ§ОнвЛжТЃЌЖјЪЧднЪБЗХЦњЧПвЛжТадЃЈStrong
ConsistencyЃЉЃЌЖјЪЧбЁдёШѕвЛжТадЃЌМДзюжевЛжТадЃЈEventual ConsistencyЃЉЃКЯЕЭГжаЕФЫљгаЪ§ОнИББООЙ§вЛЖЮЪБМфКѓЃЌзюжеФмЙЛДяЕНвЛжТЕФзДЬЌЁЃетРяЫљЫЕЕФвЛЖЮЪБМфЃЌвВвЊЪЧгУЛЇПЩНгЪмЗЖЮЇФкЕФвЛЖЮЪБМфЁЃ
зюжевЛжТадвВгавЛИіРэТлжЇГХЃКBASE РэТлЃЈВЛЕУВЛЫЕЃЌРэТлНчЕФЫѕаДецХЃАЁЃЌACID ЪЧЫсЃЌCAP ЪЧУБзгЃЌBASE
ЪЧМюЃЉЃЌФкШнжївЊАќРЈЃК
ЛљБОПЩгУЃЈBasically AvailableЃЉЃКЕБЯЕЭГдкГіЯжВЛПЩдЄжЊЙЪеЯЕФЪБКђЃЌдЪаэЫ№ЪЇВПЗжПЩгУадЁЃБШШчЃЌдЪаэЯьгІЪБМфдіГЄЃЌдЪаэВПЗжЗЧЙиМќНгПкНЕМЖЛђШлЖЯЕШЁЃ
ШэзДЬЌЃЈSoft StateЃЉЃКШэзДЬЌвВГЦЮЊШѕзДЬЌЃЌКЭгВзДЬЌЯрЖдЁЃЪЧжИдЪаэЯЕЭГжаЕФЪ§ОнДцдкжаМфзДЬЌЃЌВЂШЯЮЊИУжаМфзДЬЌЕФДцдкВЛЛсгАЯьЯЕЭГЕФећЬхПЩгУадЃЌМДдЪаэЯЕЭГдкВЛЭЌНкЕуЕФЪ§ОнИББОжЎМфНјааЪ§ОнЭЌВНЕФЙ§ГЬДцдкбгЪБЁЃ
зюжевЛжТадЃЈEventually ConsistentЃЉЃКзюжевЛжТадЧПЕїЕФЪЧЯЕЭГжаЫљгаЕФЪ§ОнИББОЃЌдкОЙ§вЛЖЮЪБМфЕФЭЌВНКѓЃЌзюжеФмЙЛДяЕНвЛИівЛжТЕФзДЬЌЁЃвђДЫЃЌзюжевЛжТадЕФБОжЪЪЧашвЊЯЕЭГБЃжЄзюжеЪ§ОнФмЙЛДяЕНвЛжТЃЌЖјВЛашвЊЪЕЪББЃжЄЯЕЭГЪ§ОнЕФЧПвЛжТадЁЃ
дкЙЄГЬЪЕМљжаЃЌзюжевЛжТадЗжЮЊ 5 жжЃЌет 5 жжЗНЪНЛсНсКЯЪЙгУЃЌЙВЭЌЪЕЯжзюжевЛжТадЃК
вђЙћвЛжТадЃЈCausal consistencyЃЉЃКШчЙћНкЕу A дкИќаТЭъФГИіЪ§ОнКѓЭЈжЊСЫНкЕу BЃЌФЧУДНкЕу
B жЎКѓЖдИУЪ§ОнЕФЗУЮЪКЭаоИФЖМЪЧЛљгк A ИќаТКѓЕФжЕЁЃгкДЫЭЌЪБЃЌКЭНкЕу A ЮовђЙћЙиЯЕЕФНкЕу C ЕФЪ§ОнЗУЮЪдђУЛгаетбљЕФЯожЦЁЃ
ЖСМКжЎЫљаДЃЈRead your writesЃЉЃКНкЕу A ИќаТвЛИіЪ§ОнКѓЃЌЫќздЩэзмЪЧФмЗУЮЪЕНздЩэИќаТЙ§ЕФзюаТжЕЃЌЖјВЛЛсПДЕНОЩжЕЁЃ
ЛсЛАвЛжТадЃЈSession consistencyЃЉЃКЛсЛАвЛжТадНЋЖдЯЕЭГЪ§ОнЕФЗУЮЪЙ§ГЬПђЖЈдкСЫвЛИіЛсЛАЕБжаЃЌЯЕЭГФмБЃжЄдкЭЌвЛИігааЇЕФЛсЛАжаЪЕЯжЁАЖСМКжЎЫљаДЁБЕФвЛжТадЃЌвВОЭЪЧЫЕЃЌжДааИќаТВйзїжЎКѓЃЌПЭЛЇЖЫФмЙЛдкЭЌвЛИіЛсЛАжаЪМжеЖСШЁЕНИУЪ§ОнЯюЕФзюаТжЕЁЃ
ЕЅЕїЖСвЛжТадЃЈMonotonic read consistencyЃЉЃКШчЙћвЛИіНкЕуДгЯЕЭГжаЖСШЁГівЛИіЪ§ОнЯюЕФФГИіжЕКѓЃЌФЧУДЯЕЭГЖдгкИУНкЕуКѓајЕФШЮКЮЪ§ОнЗУЮЪЖМВЛгІИУЗЕЛиИќОЩЕФжЕЁЃ
ЕЅЕїаДвЛжТадЃЈMonotonic write consistencyЃЉЃКвЛИіЯЕЭГвЊФмЙЛБЃжЄРДздЭЌвЛИіНкЕуЕФаДВйзїБЛЫГађЕФжДааЁЃ 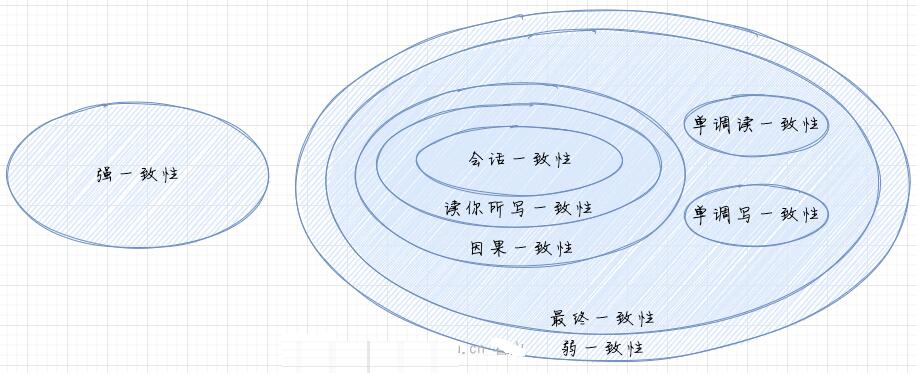
гаСЫРэТлжЎКѓЃЌЮвУЧРДЫЕвЛЯТЪЕЯжзюжевЛжТадЕФМИжжФЃЪНЁЃ
ПЩППЪТМўФЃЪН
ПЩППЪТМўФЃЪНЪєгкЪТМўЧ§ЖЏМмЙЙЃКЕБФГИіЪТМўЗЂЩњЪБЃЌР§ШчИќаТвЛИівЕЮёЪЕЬхЃЌЗўЮёЛсЯђЯћЯЂДњРэЗЂВМвЛИіЪТМўЁЃЯћЯЂДњРэЛсЯђЖЉдФЪТМўЕФЗўЮёЭЦЫЭЪТМўЃЌЕБЖЉдФетаЉЪТМўЕФЗўЮёНгЪеДЫЪТМўЪБЃЌОЭПЩвдЭъГЩздМКЕФвЕЮёЃЌвВПЩФмЛсв§ЗЂИќЖрЕФЪТМўЗЂВМЁЃ
ЮвУЧЭЈЙ§вЛИіР§згРДНтЪЭвЛЯТетжжФЃЪНЃЌгУЛЇЯТЕЅГЩЙІКѓЃЌЖЉЕЅЯЕЭГашвЊЭЈжЊПтДцЯЕЭГМѕПтДцЁЃ
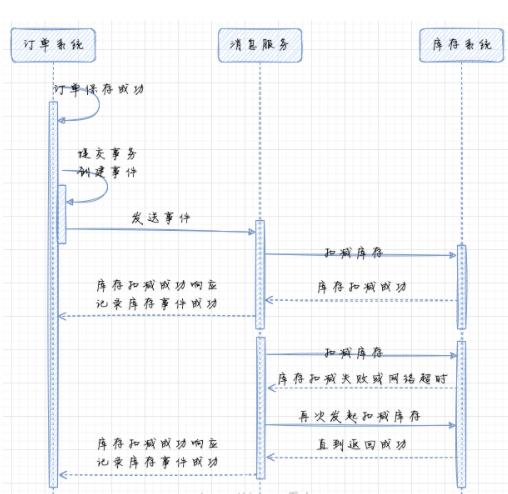 ЖЉЕЅЯЕЭГИљОнгУЛЇВйзїЭъГЩЯТЕЅВйзїЁЃДЫЪБЛсЪЙгУЭЌвЛИіБОЕиЪТЮёБЃДцЖЉЕЅаХЯЂКЭаДШыЪТМўЁЃ
СэЭтвЛИіЯћЯЂЗўЮёЛсТжбЏЪТМўБэЃЌНЋзДЬЌЪЧЁАНјаажаЁБЕФЪТМўвдЯћЯЂаЮЪНЗЂЫЭЕНЯћЯЂЗўЮёжаЁЃШчЙћЗЂЫЭЪЇАмЃЌвђЮЊЪЧТжбЏШЮЮёЃЌЛсдкЯТвЛДЮТжбЏЕФЪБКђдйДЮЗЂЫЭЁЃЃЈДЫДІгавЛаЉгХЛЏЕуЃЌБОР§ЮЊСЫМђЛЏФЃаЭЃЌВЛеЙПЊЃЉ
ЯћЯЂЗўЮёЯђЖЉдФЯТЕЅЯћЯЂЕФПтДцЗўЮёЗЂЫЭЯТЕЅГЩЙІЯћЯЂЃЌПтДцЗўЮёПЊЪМДІРэЁЃДЫЪБЛсгаетУДМЏжаЧщПіЃК
ПтДцЗўЮёПлМѕПтДцГЩЙІЃЌЯћЯЂЗўЮёНгЪеЕНДІРэГЩЙІЯьгІЁЃЯћЯЂЗўЮёНЋЯьгІНсЙћЗЕЛиИјЖЉЕЅЗўЮёЃЌЖЉЕЅЗўЮёжаЪТМўНгЪеЦїНЋЪТМўаоИФЮЊЁАвбЭъГЩЁБЁЃ
ПтДцЗўЮёПлМѕПтДцЪЇАмЃЌЯћЯЂЗўЮёНгЪеЕНДІРэЪЇАмЯьгІЁЃДЫЪБЯћЯЂЗўЮёЛсдйДЮЯђПтДцЗўЮёЗЂЫЭЯћЯЂЃЌжБЕНЕУЕНГЩЙІЯьгІЁЃШчЙћЪЇАмДЮЪ§ДяЕНуажЕЃЌПЩвдИцОЏЭЈжЊШЫЙЄНщШыЁЃ
ЯћЯЂЗўЮёИјЖЉЕЅЗўЮёЗЕЛиНсЙћЪБЃЌЗЂЩњЪЇАмЃЌЖЉЕЅЗўЮёУЛгаНгЪеЕНГЩЙІЯьгІЁЃетИіЪБКђЃЌЪТМўТжбЏТпМЛсдйДЮНЋЪТМўЗЂЫЭИјЯћЯЂЗўЮёЁЃетбљЃЌПтДцЗўЮёЛсжиИДЪеЕНПлМѕПтДцЕФЯћЯЂЃЌЫљвдвЊЧѓПтДцЗўЮёзіКУУнЕШЁЃПтДцЗўЮёЗЂЯжЯћЯЂвбОДІРэЙ§ЃЌжБНгЗЕЛиГЩЙІЁЃ
етжжППзХГжајжиЪдРДБЃжЄПЩППадЕФНтОіЗНАИЃЌНазіЁАзюДѓХЌСІНЛИЖЁБЃЈBest-Effort DeliveryЃЉЃЌвВЪЧЁАПЩППЁБСНИізжЕФРДдДЁЃ
ПЩППЪТМўФЃЪНЛЙгавЛжжИќЦеЭЈЕФаЮЪНЃЌБЛГЦЮЊЁАзюДѓХЌСІвЛДЮЬсНЛЁБЃЈBest-Effort 1PCЃЉЃЌжИЕФОЭЪЧНЋзюгаПЩФмГіДэЛђзюКЫаФЕФвЕЮёвдБОЕиЪТЮёЕФЗНЪНЭъГЩКѓЃЌВЩгУВЛЖЯжиЪдЕФЗНЪНЃЈВЛЯогкЯћЯЂЗўЮёЃЉРДДйЪЙЭЌвЛИіЗжВМЪНЪТЮёжаЕФЦфЫћЙиСЊвЕЮёШЋВПЭъГЩЁЃевЕНзюПЩФмГіДэЕФЗНЪНЪЧЬсЧАзіКУГіДэИХТЪЕФЯШбщЦРЙРЃЌВХФмЙЛжЊЕРФФПщзюШнвзГіДэЁЃевЕНзюКЫаФЕФвЕЮёЕФЗНЪНЪЧевЕНФЧжжжЛвЊГЩЙІЃЌЦфЫћвЕЮёБиаыГЩЙІЕФФЧПщвЕЮёЁЃ
етРяЮвУЧдйВЙГфСНИіИХФюЃК
вЕЮёвьГЃЃКвЕЮёТпМВњЩњДэЮѓЕФЧщПіЃЌБШШчеЫЛЇгрЖюВЛзуЁЂЩЬЦЗПтДцВЛзуЕШЁЃ
ММЪѕвьГЃЃКЗЧвЕЮёТпМВњЩњЕФвьГЃЃЌШчЭјТчСЌНгвьГЃЁЂЭјТчГЌЪБЕШЁЃ
TCC ФЃЪН
TCCЃЈTry-Confirm-CancelЃЉЪЧвЛжжвЕЮёЧжШыЪННЯЧПЕФЪТЮёЗНАИЃЌвЊЧѓвЕЮёДІРэЙ§ГЬБиаыВ№ЗжЮЊЁАдЄСєвЕЮёзЪдДЁБКЭЁАШЗШЯ/ЪЭЗХЯћЗбзЪдДЁБСНИізгЙ§ГЬЃЌгЩЭГвЛЕФЗўЮёаЕїЕїЖШВЛЭЌвЕЮёЯЕЭГЕФзгЙ§ГЬЁЃЗжЮЊвдЯТШ§ИіНзЖЮЃК
TryЃКГЂЪджДааНзЖЮЃЌЭъГЩЫљгавЕЮёПЩжДааадЕФМьВщЃЈБЃеЯвЛжТадЃЉЃЌВЂЧвдЄСєКУШЋВПашвЊгУЕНЕФвЕЮёзЪдДЃЈБЃеЯИєРыадЃЉЁЃ
ConfirmЃКШЗШЯжДааНзЖЮЃЌВЛНјааШЮКЮвЕЮёМьВщЃЌжБНгЪЙгУ Try НзЖЮзМБИЕФзЪдДРДЭъГЩвЕЮёДІРэЁЃConfirm
НзЖЮПЩФмЛсжиИДжДааЃЌашвЊТњзуУнЕШадЁЃ
CancelЃКШЁЯћжДааНзЖЮЃЌЪЭЗХ Try НзЖЮдЄСєЕФвЕЮёзЪдДЁЃCancel НзЖЮПЩФмЛсжиИДжДааЃЌашвЊТњзуУнЕШадЁЃ 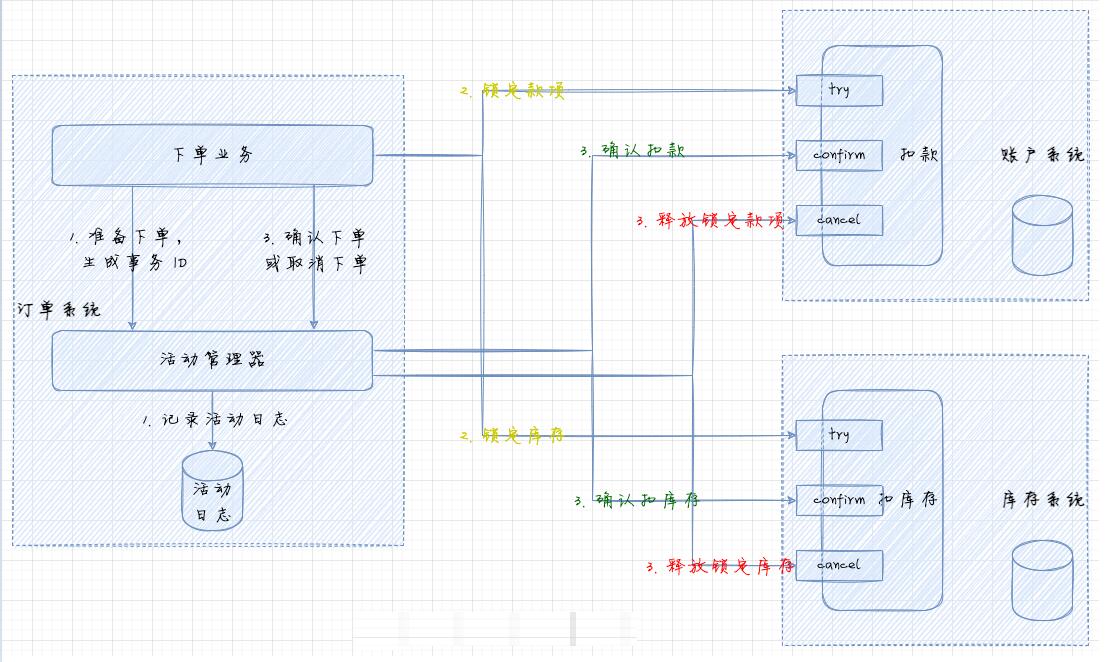 ЖЉЕЅЯЕЭГДДНЈЪТЮёЃЌЩњГЩЪТЮё
IDЃЈгУгкзїЮЊЪЖБ№ЧыЧѓУнЕШЕФБъЪЖЃЉЃЌЭЈЙ§ЛюЖЏЙмРэЦїМЧТМЛюЖЏШежОЁЃ
НјШы Try НзЖЮ
ЕїгУеЫЛЇЯЕЭГЃЌМьВщеЫЛЇгрЖюЪЧЗёГфзуЃЌШчЙћГфзуЃЌЖГНсашвЊЕФН№ЖюЃЌДЫЪБеЫЛЇгрЖюЪЧСйНчзЪдДЃЌашвЊЭЈЙ§ХХЫќЫјЛђРжЙлЫјБЃжЄЖГНсВйзїЕФАВШЋадЁЃ
ЕїгУПтДцЯЕЭГЃЌМьВщЩЬЦЗПтДцЪЧЗёГфзуЃЌШчЙћГфзуЃЌЫјЖЈашвЊЕФПтДцЃЌЫјПтВйзївВашвЊМгЫјБЃжЄАВШЋ
ШчЙћЫљгавЕЮёЗЕЛиГЩЙІЃЌМЧТМЛюЖЏШежОЮЊ ConfirmЃЌНјШы Confirm НзЖЮЃК
ЕїгУеЫЛЇЯЕЭГЃЌПлМѕЖГНсЕФН№Жю
ЕїгУПтДцЯЕЭГЃЌПлМѕЫјЖЈЕФПтДц
Ек 3 ВНВйзїжаШчЙћШЋВПЭъГЩЃЌЪТЮёаћИцНсЪјЁЃШчЙћЕк 3 ВНжаШЮКЮвЛЗНГіЯжвьГЃЃЌЖМЛсИљОнЛюЖЏШежОжаЕФМЧТМЃЌжиИДжДаа
Confirm ВйзїЃЌМДНјаазюДѓХЌСІНЛИЖЁЃЫљвдИївЕЮёЯЕЭГЕФ Confirm ВйзїашвЊЪЕЯжУнЕШадЁЃ
ШчЙћЕк 2 ВНгаШЮКЮвЛЗНЪЇАмЃЈАќРЈвЕЮёвьГЃКЭММЪѕвьГЃЃЉЃЌНЋЛюЖЏШежОМЧТМЮЊ CancelЃЌНјШы Cancel
НзЖЮЃК
ЕїгУеЫЛЇЯЕЭГЃЌЪЭЗХЖГНсЕФН№Жю
ЕїгУПтДцЯЕЭГЃЌЪЭЗХЫјЖЈЕФПтДц
Ек 5 ВНВйзїжаШчЙћШЋВПЭъГЩЃЌЪТЮёаћИцЪЇАмЁЃШчЙћЕк 5 ВНжаШЮКЮвЛЗНГіЯжвьГЃЃЈАќРЈвЕЮёвьГЃКЭММЪѕвьГЃЃЉЃЌЖМЛсИљОнЛюЖЏШежОжаЕФМЧТМЃЌжиИДжДаа
Cacel ВйзїЃЌМДзюДѓХЌСІНЛИЖЁЃЫљвдИївЕЮёЯЕЭГЕФ Cancel ВйзївВашвЊЪЕЯжУнЕШадЁЃ
ЪЧВЛЪЧИаОѕ TCC гы 2PC ЕФКмЯёЃЌСНепЕФЧјБ№дкгкЃЌTCC ЮЛгквЕЮёДњТыВуУцЃЌЪєгкАзКаЃЌ2PC
ЮЛгкЛљДЁЩшЪЉВуУцЃЌЪєгкКкКаЁЃЫљвд TCC гаИќИпЕФСщЛюадЃЌПЩвдИљОнашвЊЃЌЕїећзЪдДЫјЖЈЕФСЃЖШЁЃ
TCC дквЕЮёжДааЙ§ГЬжаПЩвддЄСєзЪдДЃЌНтОіСЫПЩППЪТМўФЃЪНЕФзЪдДИєРыЮЪЬтЁЃЕЋЪЧЃЌTCC ЛЙгаСНИіУїЯдШБЕуЃК
TCC НЋЛљДЁЩшЪЉВуЕФТпМЩЯвЦЕНвЕЮёДњТыЃЌЖдвЕЮёгаКмИпЕФЧжШыадЃЌашвЊИќИпЕФПЊЗЂГЩБОЃЌПЊЗЂГЩБОЬсЩ§ЃЌЯрЖдгІЕФЮЌЛЄГЩБОЁЂПЊЗЂШЫдБЕФЫижЪЕШЃЌЖМЛсгаИќИпЕФвЊЧѓЁЃ
TCC вЊЧѓзЪдДПЩвдЫјЖЈЁЂеМгУЛђЪЭЗХЃЌЕЋЪЧгаЕФзЪдДЪєгкЭтВПЯЕЭГЃЌУЛгаАьЗЈЪЕЯжЫјЖЈЁЃ
МјгкЩЯУцЕФСНИіШБЕуЃЌЮвУЧПДПД SAGA ЪЧЗёПЩвдУжВЙЁЃ
SAGA ФЃЪН
SAGA дкгЂЮФжаЪЧЁАГЄЦЊЙЪЪТЁЂГЄЦЊМЧа№ЁЂвЛГЄДЎЪТМўЁБЕФвтЫМЁЃSAGA ФЃЪНЕФЬсГідЖдчгкЗжВМЪНЪТЮёИХФюЕФЬсГіЃЈдйДЮЖдЧАБВДѓРаХхЗўЕФЮхЬхЭЖЕиЃЉЃЌЫќдДгк
1987 ФъЦеСжЫЙЖйДѓбЇЕФ Hector Garcia-Molina КЭ Kenneth Salem
дк ACM ЗЂБэЕФвЛЦЊТлЮФЁЖSAGASЁЗЁЃЮФжаЬсГіСЫвЛжжЬсЩ§ЁАГЄЪБМфЪТЮёЁБЃЈLong Lived TransactionЃЉдЫзїаЇТЪЕФЗНЗЈЃЌДѓжТЫМТЗЪЧАбвЛИіДѓЪТЮёЗжНтЮЊПЩвдНЛДэдЫааЕФвЛЯЕСазгЪТЮёМЏКЯЃЌКѓРДЗЂеЙГЩНЋвЛИіЗжВМЪНЛЗОГжаЕФДѓЪТЮёЗжНтЮЊвЛЯЕСаБОЕиЪТЮёЕФЩшМЦФЃЪНЁЃдкгаЕФЮФеТжаЃЌНЋетжжФЃЪНГЦЮЊвЕЮёВЙГЅФЃЪНЃЌSAGA
ЪЧЖдЪТЮёаЮЪНЕФУшЪіЃЌвЕЮёВЙГЅЪЧЖдЪТЮёааЮЊЕФУшЪіЃЌЦфБОжЪЪЧвЛбљЕФЁЃ
SAGA ФЃЪНгаСНжжЪЕЯжЃК
е§ЯђЛжИДЃЈForward RecoveryЃЉЃКЫГађжДааИїИізгЪТЮёЃЌШчЙћгіЕНФГИізгЪТЮёжДааЪЇАмЃЌНЋвЛжБжиЪдИУВйзїЃЌжЊЕРГЩЙІЃЌШЛКѓМЬајжДааЯТвЛИізгЪТЮёЁЃБШШчгУЛЇЯТЕЅжЇИЖГЩЙІСЫЃЌОЭвЛЖЈвЊПлМѕПтДцЁЃ
ЗДЯђЛжИДЃЈBackward RecoveryЃЉЃКЫГађжДааИїИізгЪТЮёЃЌШчЙћгіЕНФГИізгЪТЮёжДааЪЇАмЃЌНЋжДааИУзгЪТЮёЕФВЙГЅВйзїЃЈБмУтвђЮЊММЪѕвьГЃдьГЩЕФЪЇАмЃЌВЙГЅВйзїашвЊУнЕШЃЉЃЌШЛКѓЕЙађжДаавбОГЩЙІЕФзгЪТЮёЕФВЙГЅВйзїЁЃетжжвЛАуЪЧПЩШЁЯћЕФХњСПВйзїЃЌБШШчГіааЖЉЦБЃЌашвЊЙКТђЗЩЛњЦБЁЂЖЉОЦЕъЁЂТђУХЦБЃЌШчЙћТђУХЦБЪЇАмСЫЃЌЗЩЛњЦБКЭОЦЕъОЭПЩвдШЁЯћСЫЁЃ 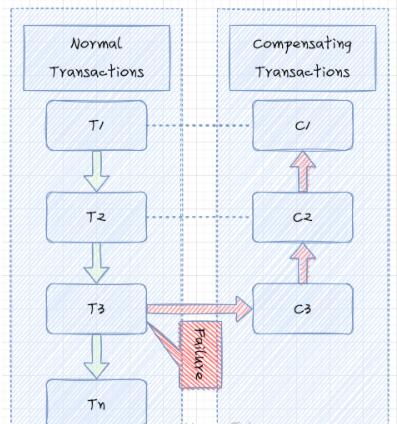
ИљОнетСНжжЪЕЯжЃЌSAGA
ПЩвдЗжЮЊСНВПЗжЃК
згЪТЮёЃЈNormal TransactionsЃЉЃКДѓЪТЮёВ№ЗжШєИЩИіаЁЪТЮёЃЌНЋећИіЪТЮё T ЗжНтЮЊ n
ИізгЪТЮёЃЌУќУћЮЊ T1ЁЂT2ЁЂЁЁЂTnЁЃУПИізгЪТЮёЖМгІИУЪЧЛђепФмБЛЪгЮЊЪЧдзгааЮЊЁЃШчЙћЗжВМЪНЪТЮёФмЙЛе§ГЃЬсНЛЃЌЦфЖдЪ§ОнЕФгАЯьЃЈзюжевЛжТадЃЉгІгыСЌајАДЫГађГЩЙІЬсНЛ
Ti ЕШМлЁЃ
ВЙГЅЪТЮёЃЈCompensating TransactionsЃЉЃКУПИізгЪТЮёЖдгІЕФВЙГЅЖЏзїЃЌУќУћЮЊ C1ЁЂC2ЁЂЁЁЂCnЁЃ
згЪТЮёгыВЙГЅЖЏзїашвЊТњзувЛаЉЬѕМўЃК
Tiгы CiБиаыЖдгІ
ВЙГЅЖЏзї CiвЛЖЈЛсжДааГЩЙІЃЌМДашвЊЪЕЯжзюДѓХЌСІНЛИЖЁЃ
Tiгы CiашвЊОпБИУнЕШад
ЮФФЉзмНс
БОЮФжївЊзмНсСЫБОЕиЪТЮёЁЂШЋОжЪТЮёЁЂзюжевЛжТадЕШЗНЪНЪЕЯжЪ§ОнздЧЂЁЃжиЕуНщЩмСЫЪЕЯжзюжевЛжТадЕФМЏжаФЃЪНЃКПЩППЪТМўФЃЪНЁЂTCC
ФЃЪНЁЂSAGA ФЃЪНЕШЁЃЪ§ОнЕФвЛжТадвЛжБЪЧИіФбЬтЃЌЫцзХЮЂЗўЮёЛЏжЎКѓЃЌЪ§ОнвЛжТадИќМгРЇФбЃЌгаРЇФбВЛХТЃЌжЛвЊВЛЗХЦњЃЌзмЛсНтОіЕФЁЃ
|









