| БрМЭЦМі: |
БОЮФНЋДгвдЯТМИИіНЧЖШРДЗжЯэдкЮЂЗўЮёМмЙЙЯТНјааЪ§ОнЩшМЦашвЊЙизЂЕФЕиЗНЃЌжМдкАяжњДѓМвдкЙЙНЈЮЂЗўЮёМмЙЙЪБЃЌЬсЙЉвЛИіДгЪ§ОнЗНУцЕФЪгНЧЃКЮЂЗўЮёЖЈвхЁЂЮЂЗўЮёЕФгХЪЦМАМмЙЙЬиЕуЁЂЮЂЗўЮёМмЙЙЯТЕФЪ§ОнЩшМЦЁЂбЁдёвЛИіКЯЪЪЕФЪ§ОнПтЁЃ
БОЮФРДздгкЙЋжкКХМмЙЙЪІММЪѕСЊУЫ ЃЌгЩЛ№СњЙћШэМўlindaБрМЁЂЭЦМіЁЃ |
|
ЧАбдЃКЮЂЗўЮёЪЧвЛИіШэМўМмЙЙФЃЪНЃЌЖдЮЂЗўЮёЕФЬжТлДѓЖрМЏжадкШнЦїЛђЦфЫћММЪѕЪЧЗёФмКмКУЕФЪЕЪЉЮЂЗўЮёЃЌЖјБОЮФНЋДгвдЯТМИИіНЧЖШРДКЭДѓМвЗжЯэдкЮЂЗўЮёМмЙЙЯТНјааЪ§ОнЩшМЦашвЊЙизЂЕФЕиЗНЃЌжМдкАяжњДѓМвдкЙЙНЈЮЂЗўЮёМмЙЙЪБЃЌЬсЙЉвЛИіДгЪ§ОнЗНУцЕФЪгНЧЃК
ЮЂЗўЮёЖЈвх
ЮЂЗўЮёЕФгХЪЦМАМмЙЙЬиЕу
ЮЂЗўЮёМмЙЙЯТЕФЪ§ОнЩшМЦ
бЁдёвЛИіКЯЪЪЕФЪ§ОнПт
ЪВУДЪЧЮЂЗўЮёЃП
АДее Martin Fowler ЕФЖЈвхЃЌЮЂЗўЮёЪЧвЛИіШэМўМмЙЙФЃЪНЃЌЭЈЙ§ПЊЗЂвЛЯЕСаЕФаЁаЭЗўЮёЕФЗНЪНРДЪЕЯжвЛИігІгУЁЃУПвЛИіетбљЕФаЁЗўЮёЭЈГЃЖМЪЧдЫаадкздМКЕФНјГЬРяУцЃЌВЂЧвЭЈЙ§ЧсСПМЖЕФ
HTTP API ЗНЪННјааЭЈбЖЁЃетаЉЗўЮёЭЈГЃЛсвдвЕЮёФЃПщЮЊНчЯоЃЌФмЙЛБЛЕЅЖРПЊЗЂВПЪ№ЃЌЭљЭљЖМЛсгУздЖЏЛЏЕФВПЪ№ЙЄОпРДНјааВњЦЗЕФЗЂВМЁЃЭЈЙ§ЪЙгУЮЂЗўЮёЗНЗЈЃЌДѓЙЋЫОПЩвдИќПьЭЦГіаТВњЦЗКЭЗўЮёЃЌЪЙЕУПЊЗЂЭХЖггывЕЮёФПБъБЃГжвЛжТЁЃ
ЮЂЗўЮёЕФгХЪЦ
ЮЂЗўЮёЗНЗЈЬхЯжГіаэЖргХЪЦЃЌАќРЈИќПьЕФЩЯЯпЪБМфЁЂСщЛюадЁЂЕЏадЁЂвЛжТадвдМАЯрЖдИќЕЭЕФГЩБОЁЃ
ИќПьЕФЩЯЯпЪБМф
ЪЕЪЉЮЂЗўЮёМмЙЙПЩвдЪЙзщжЏИќПьЕиНЋЦфгІгУГЬађЭЦЯђЪаГЁЁЃЖдећЬхгІгУГЬађЕФИќИФЃЈМДЪЙКмаЁЃЉашвЊжиаТВПЪ№ећИігІгУГЬађЖбеЛЃЌДгЖјв§ШыЗчЯеКЭИДдгадЁЃЯрЗДЃЌЗўЮёЕФИќаТПЩвдСЂМДЬсНЛЁЂВтЪдКЭВПЪ№ЃЌЖдИіБ№ЗўЮёЕФИќИФВЛЛсгАЯьЯЕЭГЕФЦфЫћВПЗжЁЃ
ИќКУЕФСщЛюадКЭПЩРЉеЙад
ЮЂЗўЮёЗНЗЈдкРЉеЙгІгУГЬађЪБвВЬсЙЉСЫСщЛюадЁЃЕЅЦЌгІгУГЬађвЊЧѓећИіЯЕЭГЃЈМАЦфЫљгаЙІФмЃЉЭЌЪБРЉеЙЁЃЪЙгУЮЂЗўЮёЃЌжЛашвЊЫѕЗХашвЊЖюЭтадФмЕФзщМўЛђЙІФмЁЃПЩвдЭЈЙ§ВПЪ№ИќЖрЮЂЗўЮёЪЕР§РДРЉеЙЗўЮёЗЖЮЇЃЌДгЖјЪЕЯжИќгааЇЕФШнСПЙцЛЎВЂНЕЕЭШэМўаэПЩГЩБОЃЌДгЖјНЕЕЭзмЬхгЕгаГЩБОЁЃ
ЕЏад
ЪЙгУЕЅЬхгІгУГЬађЪБЃЌзщМўЕФЙЪеЯПЩФмЛсЮЃМАећИігІгУГЬађЁЃдкЮЂЗўЮёжаЃЌУПЯюЗўЮёЖМЪЧИєРыЕФЃЌвдЗРжЙМЖСЊЪЇАмЕМжТећИіЯЕЭГБРРЃЁЃШчЙћЕЅИіЮЂЗўЮёЕФЫљгаЪЕР§ОљЪЇАмЃЌдђећЬхЗўЮёПЩФмЛсНЕМЖЃЌЕЋЦфЫћзщМўШдПЩЬсЙЉгаМлжЕЕФЗўЮёЁЃ
ИќШнвзЕФЙцФЃЛЏ
ЮЂЗўЮёЪЙММЪѕЭХЖгФмЙЛгызщжЏашЧѓБЃГжвЛжТЃЌВЂЧвПЩвдЕїећЭХЖгЕФДѓаЁвдЦЅХфЫљашЕФШЮЮёЁЃЭЈГЃЃЌЮЂЗўЮёЭХЖгЙцФЃНЯаЁЕЋЪЧПчВПУХЃЈШчвЛАуКИЧ
OpsЁЂDevЁЂQAЃЉЃЌВЂзЈзЂгкећИігІгУГЬађЕФЕЅИізщМўЁЃЭЈЙ§ЬсЙЉЖдИіШЫЗўЮёЕФЫљгаШЈЃЌЖјВЛЪЧЙІФмЧјгђЃЌЮЂЗўЮёЛЙПЩвдДђЦЦЭХЖгжЎМфЕФЙТЕКЃЌВЂИФЩЦазїЁЃетжжЗНЗЈЖдгкЗжВМЪНКЭдЖГЬЭХЖггШЦфЧПДѓЁЃЃЈР§ШчЃЌВЛЭЌЕиЕуЕФЭХЖгПЩвдЖРСЂЗЂВМКЭВПЪ№ЙІФмЁЃЃЉ
ЮЂЗўЮёЕФММЪѕЬиЕу
ШУЮвУЧРДЭЈЙ§вЛИіР§згРДСЫНтЮЂЗўЮёМмЙЙЕФММЪѕЬиЕуЁЃ
СЊАювјааЕФМмЙЙЪІ Jonnathan ЗЧГЃВЛЯВЛЖЫћЕФВњЦЗОРэ MandyЃЌвђЮЊЫћОѕЕУ Mandy
гРдЖгаЮоЧюЮоОЁЕФЯыЗЈвЊЪЕЯжЃЌИуЕУЫћГЩЬьОЭдкВЛЖЯЕиаоИФДњТыЁЃЕЋЪЧ Mandy ЪЧРЯАхЕФКьШЫЃЌЖјЧвгУЛЇЖдВњЦЗЕФЗДЯьвВВЛДэЃЌЫљвдКмЖрЪБКђЫћжЛФмФЌФЌЕФЗўДгЁЃ
етвЛЬь Mandy гжГЩЙІЕФЫЕЗўСЫРЯАхвЊдкЫћУЧЕФПЭЛЇЬхбщЬсЩ§ЯюФПжадіМггпЧщЗжЮіКЭ AI ПЭЛЇЗўЮёФЃПщЃЌЯЃЭћЭЈЙ§ЖдЩчНЛУНЬхЩЯгаЙиСЊАювјааЕФЫљгаЦРТлНјааЪЕЪБЕФМрПиКЭЗжЮіРДМАЪБЗЂЯжСЊАювјааЕФВњЦЗЗДРЁЛђепгУЛЇЬхбщЮЪЬтЁЃJonnathan
вбОдЄИаЕНСЫетбљЧАЫљЮДгаЕФгІгУГЁОАЃЌЛсгаЬЋЖрЕФЮДжЊКЭЬЋЖрЕФИФБфЃЌгкЪЧетДЮОіЖЈГЂЪдЪЙгУ Microservices
РДЙЙНЈетИігІгУЁЃ
етИіЪЧ Jonnathan ЩшМЦЕФМмЙЙЃЌЯЕЭГвЊЧѓЖдПЭЛЇЕФЩчНЛеЫКХШч FacebookЁЂTwitterЁЂGoogle+
МА Snapchat ЙЋПЊЕФаХЯЂМАЦРТлНјааЪеМЏЃЌВЂдкФГаЉКЯЪЪЕФЪБКђЪЙгУ AI ММЪѕжБНгКЭгУЛЇдкЭЈЙ§ЩчНЛЙЄОпНјааЛЅЖЏЁЃ
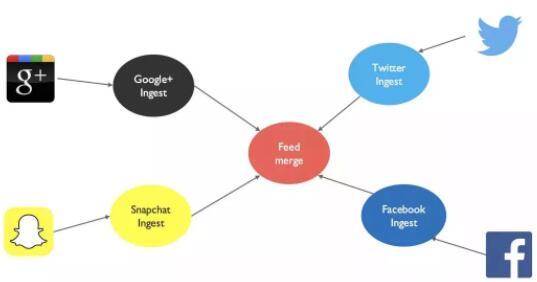
дкЩЯЭМетИіМмЙЙРяУцЃЌJonnathan Аб 4 ИіВЛЭЌЩчНЛУНЬхЕФЪ§ОнВЩМЏКЭНЛЛЅгУ 4 ИіЖРСЂЕФФЃПщНјааЪЕЯжЃЌВЂгУвЛИі
Feed Merge ЗўЮёЃЌвЛИі Aggregate Service Аб 4 ИіРрЫЦЙІФмЕФЮЂЗўЮёФЃПщЕФЪ§ОнКЭЙІФмНјааећКЯЃЌЬсЙЉИјЗжЮіЦНЬЈЪЙгУЁЃетРяУцУПвЛИіЗўЮёАДееЮЂЗўЮёЕФМмЙЙЃЌУПвЛИіЖМЪЧЕЅЖРВПЪ№ЃЌдквЛИіЖРСЂЕФШнЦїФкжДааЃЌВЂЪЙгУздМКЕФвЛИіЪ§ОнПтЁЃ
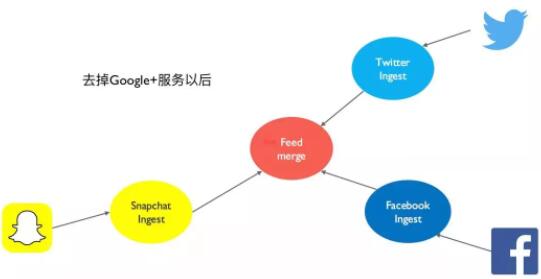
ЙћВЛЦфШЛ, ЯЕЭГЩЯЯпвЛЖЮЪБМфЃЌMandy ЫЕ Google+ ЩЯУцМИКѕУЛгаЪВУДЛюЖЏЃЌВЛжЕЕУМЬајЮЌЛЄетбљЕФвЛЬзЯЕЭГЁЃJonnathan
етДЮКСЮоБЇдЙЃЌжБНгАбИКд№ Google+ ЕФШнЦїЭЃСЫЃЌУЛгаашвЊШЮКЮДњТыИФЖЏЃЌЩѕжСЭъШЋУЛгаашвЊЖдећИіЯЕЭГНјааЭЃЛњЁЃ
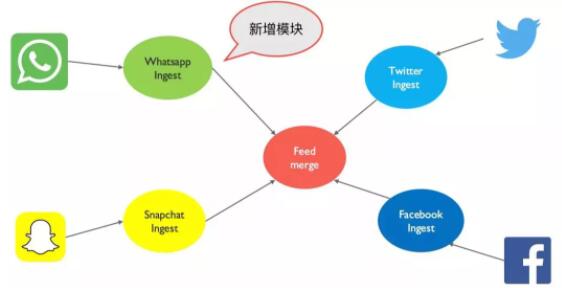
ИеЯТЯп Google+ЃЌMandy гжРДЬсашЧѓЫЕзюНќКЯВЂСЫСэвЛМввјааЃЌПЭЛЇКмЖрЪЙгУ WhatsappЁЃЖўЛАВЛЫЕЃЌJonnathan
жБНгЩЯСЫвЛИіаТЕФФЃПщРДДІРэ Whatsapp:
гжЙ§СЫвЛЖЮЪБМфЃЌетвЛДЮЪЧ Jonnathan здМКвЊЖдЯЕЭГзіЕїећСЫЃЌдРД Snapchat зюНќДѓЛ№ЃЌЫћВПЪ№ЕФЯЕЭГЦЕЪмбЙСІЃЌадФмЯТНЕЁЃЮЊСЫНтОіетИіЮЪЬтЃЌJonnathan
ЙћЖЯдіМгСЫЖюЭт 2 ЬЈШнЦїРДЭЌЪБжЇГХ Snapchat аХЯЂЕФВЩМЏКЭДІРэЁЃ
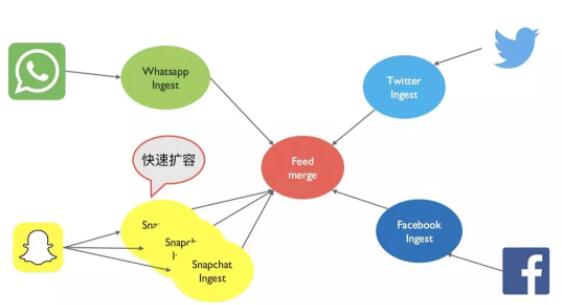
ИааЛЮЂЗўЮёМмЙЙЃЌJonnathan дквЛЯЕСаЕФВњЦЗашЧѓБфЛЏвдМАЯЕЭГРЉШнашЧѓЯТЃЌПЩвдДгШнгІИЖЁЃвЊЪЕЯжЮЂЗўЮёМмЙЙЃЌашвЊФуУњМЧвдЯТМИИіЮЂЗўЮёМмЙЙЕФгІгУЩшМЦддђЃК
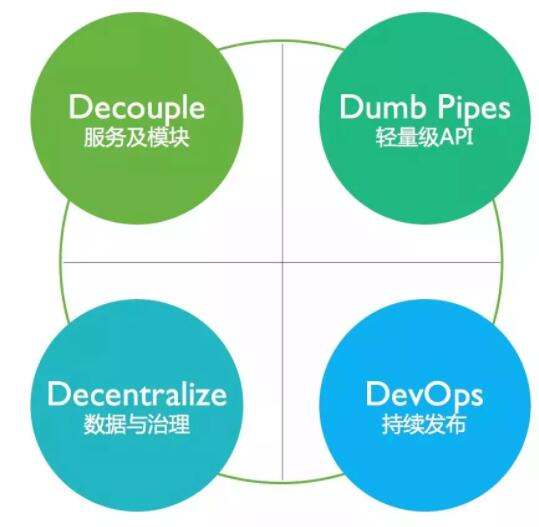
Decouple Нтёю
дкЮЂЗўЮёМмЙЙжаЃЌгІгУГЬађБЛЗжНтЮЊаЁаЭЕФЖРСЂЗўЮёЁЃЗўЮёЭЈГЃзЈзЂгкЬиЖЈЕФРыЩЂФПБъЛђЙІФмЃЌВЂбизХвЕЮёБпНчНтёюЁЃАДвЕЮёНчЯоЗжРыЗўЮёПЩШУЭХЖгзЈзЂгке§ШЗЕФФПБъЃЌВЂШЗБЃЗўЮёжЎМфЕФзджїадЁЃУПЯюЗўЮёЖМЪЧЖРСЂПЊЗЂЃЌВтЪдКЭВПЪ№ЕФЃЌЗўЮёЭЈГЃЪЧзїЮЊЖРСЂЕФНјГЬЛђШэМўШнЦїЗжПЊЕФЃЌЭЈЙ§ЭјТчКЭЩЬЖЈЕФ
API НјааЭЈаХЃЌОЁЙмдкФГаЉЧщПіЯТЃЌЭјТчПЩФмдкБОЕиЁЃЭЈГЃВПЪ№ЯрЭЌЮЂЗўЮёЕФЖрИіЪЕР§ЃЌДгЖјЬсЙЉШпгрКЭПЩРЉеЙадЁЃ
Dump Pipes ЧсСПМЖ API
ЮЂЗўЮёжЎМфЕФЭЈаХвЊЪЙгУЧсСПМЖ APIЃЌШч HTTP RESTful APIЁЃетбљПЩвдЪЙЕУЗўЮёЖд API
ЭЈаХЗНАИЕФвРРЕМѕЕНзюаЁЁЃИДдгЕФЭЈаХДІРэвЊдкЗўЮёЖЫНјааЃЌЖјВЛЪЧЯё ESB Лђеп Data Pipeline
ДІРэзмЯпФЧбљдкЪ§ОнДЋЪфЙ§ГЬжав§ШыЗЧГЃЖрЕФТпМЃЌЕМжТЮЂЗўЮёФЃПщНєНєЕФАѓЖЈдкетИіЪ§ОнЙмЕРЩЯЁЃ
DevOps ГжајМЏГЩ
ЮЂЗўЮёМмЙЙДјРДЕФвЛИіЗЧГЃЯджјЕФИКУцадОЭЪЧжкЖрЪЕР§ЕФВтЪдЗЂВММАЙмРэЁЃДЋЭГгІгУЫфШЛПЊЗЂИДдгЃЌЕЋЪЧВПЪ№КЭдЫЮЌЯрЖдБШНЯМЏжаЃЌвЛЬЈЪ§ОнПтЃЌ2-4
ИігІгУЗўЮёЦїОЭВюВЛЖрСЫЁЃЕЋЪЧЮЂЗўЮёМмЙЙЯТЕЅЖРЗўЮёЕФЪ§СПЧсдђ 10-20ЃЌЖрдђЩЯАйИіЃЌЫљвдЮЂЗўЮёМмЙЙвЛАуашвЊХфЬзЕФ
CI/CD ЗНЗЈРДжЇГХЁЃ
Decentralized ШЅжааФЪ§ОнжЮРэ
Ъ§ОнЕФЙмРэдкЮЂЗўЮёМмЙЙЯТвВЪЧКЭДЋЭГЕЅЬхгаКмДѓЕФВЛЭЌПМСПЁЃДѓВПЗжЪБКђЮвУЧЯЃЭћЪ§ОнОЭКЭЗўЮёвЛбљЃЌвЊгаГфЗжЕФЖРСЂадЃЌПЩвдКЭФГИіЗўЮёвЛЦ№ВПЪ№ЃЌвЛЦ№РЉеЙЃЌЛђепвЛЦ№жиЙЙЁЃетЭЈГЃвтЮЖзХЮвУЧПЩФмвЊдквЛИіЮЂЗўЮёМмЙЙгІгУФкЪЙгУЖрИіЪ§ОнПтЪЕР§ЁЃЕЋЪЧЭЌбљашвЊПМТЧЕНЪ§ОнЗжВМдкЖрЪЕР§жЎМфвдКѓЃЌЭљЭљЛЙашвЊвЛаЉШпгрЃЌвдМАШчКЮБЃГжетаЉЪ§ОндкетаЉЯЕЭГжаЕФвЛжТадЕШЮЪЬтЁЃЯТУцвЛеТЃЌЮвУЧОЭзХжиРДЬжТлЮЂЗўЮёМмЙЙЯТЕФЪ§ОнЩшМЦЕФвЛаЉПМСПвђЫиЁЃ
ЮЂЗўЮёЕФЪ§ОнЩшМЦПМСП
ДгРДУЛгавЛИі one-size-fits-all ЕФМмЙЙЃЌЫљвддкЮЂЗўЮёМмЙЙЯТУцЃЌЮвУЧашвЊСЫНтЕФЃЌвЛбљЪЧМИИіЙиМќЕФМмЙЙПМСПЕуЁЃШЛКѓеыЖдздМКЕФЪЕМЪгІгУЃЌбЁдёФФаЉПМСПЕуЪЧИќМгживЊЁЃетЦЊЮФеТЕФФПЕФЃЌжївЊОЭЪЧИњДѓМвРДЬжТлДгФФМИИіНЧЖШзХЪжРДЩшМЦвЛИіЗћКЯЮЂЗўЮёМмЙЙддђЕФЪ§ОнМмЙЙЁЃБШШчЫЕЃЌЮвУЧПЩвдДгвЛЯЕСаЕФЮЪЬтРДПЊЪМетИіЬжТлЃК
етУДЖрЮЂЗўЮёжЎМфЃЌЮвЪЧЗёПЩвдгУвЛИіЪ§ОнПтЃЌЛЙЪЧЖрИіЪ§ОнПтРДжЇГжЖрИіЮЂЗўЮёЃП
ШчЙћЪЧЖрИіЪ§ОнПтЃЌЮвЪЧЗёЮЊУПвЛИіЮЂЗўЮёЬєбЁвЛИізюКЯЪЪЕФЪ§ОнПтЃЌЛЙЪЧбЁдёЭЌвЛжжРраЭЕФЪ§ОнПтЃП
ЮвШчКЮдкЮЂЗўЮёМмЙЙЯТРЉеЙЮвЕФЪ§ОнПтЃП
ЕБвЛИіЮввРРЕЕФЗўЮёашвЊаоИФЪ§ОнПт Schema ЕФЪБКђЃЌЪЧЗёЛсгАЯьЕНЮвЃП
ЕБЮЂЗўЮёгІгУВЛЖЯбмБфЕФЪБКђЃЌЮвЕФЪ§ОнПтЪЧЗёПЩвдПьЫйЕФЯьгІгІгУашЧѓБфЛЏЃП
етаЉОЭЪЧЮвУЧдкЮЂЗўЮёЪ§ОнМмЙЙЪБКђвЊЙизЂЕФЕиЗНЁЃ
вЛПтвЛЗўЛЙЪЧвЛПтЖрЗў
ЮоТлЪЧЕЅЬхгІгУЃЌЛЙЪЧЮЂЗўЮёгІгУЃЌгавЛЕуЪЧПЯЖЈЕФЃКгІгУЕФИїИіФЃПщжЎМфЖМашвЊНјааНЯЮЊЦЕЗБЕФЭЈаХЃЌЭЈЙ§вЛЦ№аЭЌКЯзїЃЌРДЪЕЯжгІгУЕФећЬхМлжЕЁЃдкЕЅЬхгІгУжаЃЌетжжЭЈаХЪЧЭЈЙ§ЗНЗЈЕїгУРДЭъГЩЕФЁЃдкЮЂЗўЮёжаЃЌдђЭЈЙ§
API ЕїгУРДЭъГЩЁЃетаЉФЃПщЛђепЗўЮёМфЕїгУЃЌДѓВПЗжЪБКђЪЧЮЊСЫЙВЯэЪ§ОнЁЃЙВЯэЪ§ОнзюМњЕФЗНЪНЕБШЛОЭЪЧВЩгУвЛжжЙВЯэЪ§ОнПтЕФФЃЪНЃЌвВОЭЪЧЕЅЬхгІгУГЃгУЕФЗНЪН
- гІгУПЩвдгаЖрИіЯЕЭГФЃПщЃЌЕЋвЛАуЖМЪЧжЛгавЛИіЪ§ОнПтЁЃШчЯТЭМзѓБпЃЌ3 ИіЮЂЗўЮёФЃПщЃЌКѓУцЙВЯэвЛИіЪ§ОнПтЃЌМђГЦвЛПтЖрЗўЮёЃК
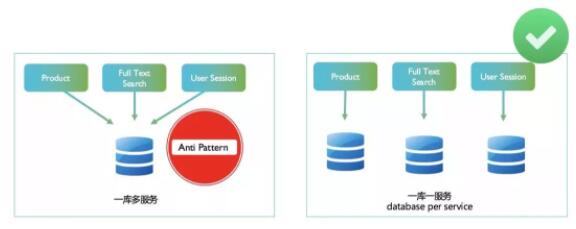
етжжМмЙЙФЃЪНЭЈГЃЛсБЛШЯЮЊЪЧЮЂЗўЮёМмЙЙЯТЕФЗДЗЖЪНЃЌЫќЕФЮЪЬтдкгкЃК
ЕЅЕуЙЪеЯЃКвЛИіЪ§ОнПтЕЙЯТЃЌећХњЗўЮёШЋВПЭЃжЙЁЃКЮРДЕФЗўЮёЖРСЂадЃП
Ъ§ОндкЭЌвЛИіЕиЗНЃЌЛсИјЬАЭМЗНБуЕФПЊЗЂЛђеп DBA ЙЄГЬЪІБраДКмЖрЪ§ОнМфИпЖШвРРЕЕФГЬађЛђепЙЄОпЃЛ
ЮоЗЈеыЖдФГвЛИіЗўЮёНјааОЋзМгХЛЏЛђРЉеЙЃЌШчЩЯЮФЫљНВЕФ Snapchat ЕФР§згЁЃ
ЫљвдвЛАуЭЦМіЕФзіЗЈЃЌЪЧЮЊУПвЛИіЮЂЗўЮёзМБИвЛИіЕЅЖРЕФЪ§ОнПтЃЌвВМДвЛПтвЛЗў (database per
service) ФЃЪНЁЃШчЩЯЭМгвВрЫљЪОЁЃетжжФЃЪНИќМгЪЪКЯЮЂЗўЮёМмЙЙ - ЫќТњзуУПвЛИіЗўЮёЪЧЖРСЂПЊЗЂЁЂЖРСЂВПЪ№ЁЂЖРСЂРЉеЙЕФЬиадЁЃЕБашвЊЖдвЛИіЗўЮёНјааЩ§МЖЛђепЪ§ОнМмЙЙИФЖЏЕФЪБКђЃЌЮоаыгАЯьЕНЦфЫћЕФЗўЮёЁЃашвЊЖдФГИіЗўЮёНјааРЉеЙЕФЪБКђЃЌвВПЩвдЪжЪѕЪНЕФЖдФГвЛИіЗўЮёНјааОжВПРЉШнЁЃСэЭтЃЌШчЙћФГаЉЗўЮёЖдЪ§ОнПтгаЬиЪтЕФашЧѓЃЌетжжФЃЪНвВЮЊЯТЮФЫљНВЕФЛьКЯГжОУЛЏ
(Polyglot Persistence) ЬсЙЉСЫПЩФмадЁЃ
ЛьКЯГжОУЛЏ vs. ЖрФЃЪ§ОнПт
ЛьКЯГжОУЛЏдкДѓаЭЛЅСЊЭјЙЋЫОЪЧвЛИіБШНЯЗчааЕФФЃЪНЁЃЫќБќГаЕФддђОЭЪЧЮЊЬиБ№ЕФШЮЮёЬсЙЉзюКУЕФЙЄОпЁЃБШШчЫЕЃЌШчЙћЮвЯЃЭћЬсЙЉвЛИіИпВЂЗЂЕЭбгГйЕФЙВЯэгУЛЇЛсЛАЗНАИ
(shared session storage)ЃЌ Redis ПЩФмЪЧвЛИіЗЧГЃРэЯыЕФбЁдёЁЃШчЙћЮвЪЧдкЪЕЯжвЛИіВњЦЗФПТМЃЌЩцМАЕНДѓСПВЛЖЈНсЙЙЕФЩЬЦЗЪ§ОнМАЪєадЕФНЈФЃЙмРэЃЌЮвПЩФмЛсВЩгУФЃЪНСщЛюЃЌЖЏЬЌ
schema ЕФ MongoDB РДзїЮЊЮвЕФЪ§ОнПтНтОіЗНАИЁЃШчЙћЮвЯЃЭћжЇГжЗЧГЃЧПДѓЕФШЋЮФЫбЫїЃЌElasticSearch
дђЪЧаавЕжаЕФйЎйЎепЁЃЮЂЗўЮёЕФЙІФмЗжПщЖРСЂВПЪ№ЮЊетжжМмЙЙФЃЪНЬсЙЉСЫЗЧГЃКУЕФЛљДЁЃЌШчЯТЭМзѓВрЫљЪООЭЪЧИіЕфаЭЕФЛьКЯГжОУЛЏЕФАИР§ЃК
ЛьКЯГжОУЛЏ - Polyglot Persistence
ЖрФЃЪ§ОнПт - Multi-model Database
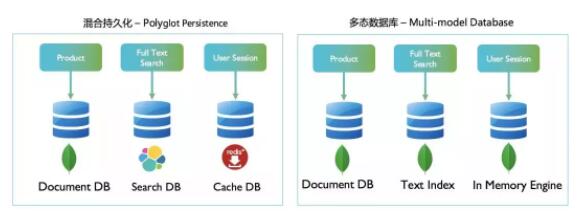
ЕБШЛЃЌгаОфЛАЫЕЕФЪЧМмЙЙЪІЕФЙЄзїОЭЪЧУПЬьзіВЛЖЯЕФШЁЩс (trade off)ЃЌвђЮЊбЁдёЭљЭљЪЧШУШЫКмОРНсЁЃЛьКЯГжОУЛЏЕФгХЪЦКмУїЯдЃЌПЩвдШУУПИіЕЅЖРЕФЗўЮёЪЙгУЕНзюМбЕФЙЄОпКЭММЪѕЁЃЕЋЪЧЫќЕФБзЖЫвВЪЧВЛШнКіЪгЁЃВПЪ№ЁЂМрПиЁЂБИЗнЁЂЩ§МЖЕШЪ§ОнПтЙмРэЙЄзїДгРДЖМЪЧвЛМўРЇФбЕЋЪЧживЊЕФШЮЮёЁЃв§ШыЖрИіВЛЭЌЕФЪ§ОнПтЃЌвВвтЮЖзХЖдЯЕЭГЙмРэЮЌЛЄЕФИДдгЖШКЭГЩБОЬсИпСЫКмЖрЁЃетжжЧщПіЯТПЩФмашвЊБШНЯгазЪдДЕФЙЋЫОЛђепЭХЖгВХПЩвдЪЙгУЁЃетвВНтЪЭСЫетИіФЃЪНдкДѓаЭЛЅСЊЭјЙЋЫОЕУЕННЯЖрЕФВЩгУгыЭЦЙуЁЃеыЖдгкЦфЫћаЁаЭЙцФЃЕФгУЛЇЃЌЛђепЪЧШБЗІзуЙЛеЦЮеИїжжаТаЭММЪѕШЫВХЕФЙЋЫОРДЫЕЃЌСэвЛжжИќЮЊПЩааЕФФЃЪНПЩФмЪЧЖрФЃЪ§ОнПт
(Multi-model)ЁЃШчЩЯЭМгвВрЫљЪОЁЃ
ЖрФЃЪ§ОнПтЕФЬиеїЪЧЃК
вРШЛЪЧвЛПтвЛЗўЮёЃЈЮЊвЛИіЗўЮёВПЪ№вЛИіЕЅЖРЕФЪ§ОнПтЃЉЃЛ
ЕЋЪЧЪЙгУЕФЪЧЭЌвЛжжРраЭЃЌжЇГжЖржжГЁОАЕФЪ§ОнПтЃЌШч NoSQL жаМфЮЊЙІФмзюШЋУцЕФ MongoDBЃЛ
ЫфШЛЪЧЖрЪЕР§ЃЌЕЋЪЧжЛашЮЌЛЄвЛжжРраЭЕФЪ§ОнПтЃЌЙмРэЩЯКЭШЫдБХфБИЩЯЖМНЯЮЊМђЕЅЁЃ
ШчЙћФудкПЊЗЂЕФгІгУЪЧвЛПюЦѓвЕМЖВњЦЗЃЌЛсНЛИЖЕНПЭЛЇЛЗОГВПЪ№АВзАЃЌдђдЫЮЌЙмРэЕФМђЕЅадНЋдкММЪѕбЁаЭжаеМОнЗЧГЃживЊЕФвЛИіБШжиЃЌЮовЩетжжЧщПіЯТЖрФЃЪ§ОнПтИќМгЪЪгУЁЃ
ЮЂЗўЮёРЉеЙФуЕФЪ§Он
ЮЂЗўЮёМмЙЙЕФвЛДѓёдвцЪЧЦфСщЛюЕФРЉеЙадЁЃвдЩЯУцЕФ Snapchat ЮЊР§ЃЌШчЙћашвЊВЩМЏЛђДІРэЕФЪ§ОнСППьЫйдіГЄЃЌдкЮвУЧдіМггІгУЗўЮёЪЕР§ЕФЭЌЪБЃЌжЇГХЪ§ОнДцДЂЕФФЃПщвВвЊЯргІРЉГфЁЃAFK
Partners дкЫћУЧЕФ Scale Cube вЛЮФРяЖдадФмРЉеЙЬсГіСЫетбљЕФЙлЕуЃКвЊЩшМЦвЛИіеце§втвхЩЯЕФПЩРЉеЙЯЕЭГЃЌЮвУЧБиаыПМТЧ
3 ИіЮЌЖШЃЌШчЯТЫљЪОЃК
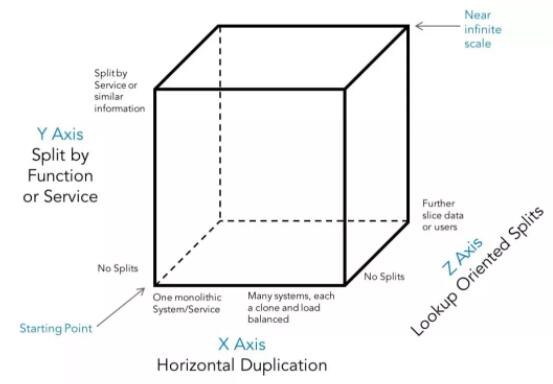
ЁЄ X-жс, ЯЕЭГИДжЦЃЈКсЯђРЉеЙЃЉ
ЁЄ Y-жс, ЗЧжиЕўЙІФмЕФВ№ЗжЃЈЮЂЗўЮёЃЉ
ЁЄ Z-жс, Ъ§ОнЕФЗжЧј (Sharding)
вЛИіКУЕФЪ§ОнМмЙЙЃЌдкЮЂЗўЮёЬхЯЕФкЃЌгІИУОпгаЭЌбљЕФПЩРЉеЙЁЂвзРЉеЙаджЪЃЌДгЖјВЛИјЮЂЗўЮёМмЙЙЭЯКѓЭШЁЃЙигкЪ§ОнЗжЧјРЉеЙгаСНжжзіЗЈЃК
гІгУЪ§ОнЗжЧј
Ъ§ОнПтЗжЧј
гІгУЪ§ОнЗжЧјЃЌЙЫУћЫМвхЃЌОЭЪЧдкгІгУЖЫЖдЪ§ОнЕФДцДЂНјааЗжЧјЙмРэЁЃБШШчЫЕЃЌвЛИіЩчНЛгІгУПЩвдАДЙњМвЛђЕиЧјЮЊНчАбгУЛЇЕФЪ§ОнЗжЗЂЕНВЛЭЌЪ§ОнПтЪЕР§РяУцЁЃетбљЕФЛАУПИіЪ§ОнПтЪЕР§жЛашвЊДцДЂвЛВПЗжЪ§ОнЃЌДгЖјЪЕЯжКЃСПЕФЪ§ОнЙмРэФмСІЁЃЪ§ОнПтЗжЧјЃЌОЭЪЧгЩЪ§ОнПтЕФТЗгЩНкЕуРДЭъГЩЪ§ОнЗжЧјЕФШЮЮёЁЃЪ§ОнПтЗжЧјЕФгХЪЦЪЧЯдШЛЕФ
- ЖдгІгУЭИУїЁЂРЉеЙПьЫйЁЂЮоаыЯТЯпЕШЁЃШчЙћФуЕФгІгУгаЧБдкРЉГфЕФашЧѓЃЌбЁдёвЛИіФмЙЛздЖЏРЉеЙЕФЗжВМЪНЪ§ОнПтЪЧвЛИіБШНЯУїжЧЕФбЁдёЁЃ
ЖЏЬЌФЃЪНжЇГжМАПьЫйПЊЗЂФмСІ
етЪЧвЛИіКмЖрМмЙЙЪІПЩФмЛсКіТдЃЌЕЋЪЧЗЧГЃживЊЕФЙизЂЕуЁЃЮвУЧдкЕќДњЪНПЊЗЂ DevOps ЮЂЗўЮёЩЯЕФКмЖрХЌСІЃЌЖМЪЧЮЊСЫПьЫйПЊЗЂЃЌПьЫйЩЯЯпЃЌвдМАПьЫйЯьгІБфЛЏЕФашЧѓЁЃДгЪ§ОнМмЙЙЪІЕФНЧЖШРДПДЃЌШчКЮВЛГЩЮЊдкетИіПьЫйПЊЗЂЗНЗЈФЃЪНжаЕФвЛИіЦПОБЃЌгавЛИіКмживЊЕФЛЗНкОЭЪЧЪЧЗёгавЛИіФмЙЛМАЪБЯьгІБфЛЏЕФЪ§ОнФЃаЭЁЃДЋЭГЕФЪ§ОнПтЖМЪЧЧПФЃЪНЃЌашвЊЖд
schema НјааЧхЮњЖЈвх, дкашЧѓаоИФЕМжТФЃаЭаоИФЕФЪБКђашвЊЖдЪ§ОнПтНјааФЃЪНЩ§МЖЃЌЪЧвЛИіашвЊЯТЯпЁЂКФЪБВЂЧвЪЧИпГЩБОЕФдЫЮЌВйзїЁЃ

дкаТвЛДњЕФ NoSQL Ъ§ОнПтВњЩњжЎЧАЃЌЮвУЧВЂВЛашвЊПМТЧетИіЮЪЬтЃЌЕЋЪЧвд MongoDBЁЂCassandra
ЕШЮЊДњБэЕФ NoSQL ДњБэЕФЪЧСщЛюНЈФЃЃЌЖЏЬЌжЇГжФЃЪНБфЛЏЕФЬиеїЪЙЕУЫќУЧГЩЮЊУєНнПЊЗЂКЭЮЂЗўЮёЬхЯЕФквЛИігаСІЕФОКељепЃЌдкбЁаЭЕФЪБКђвВЪЧвЛИіживЊЕФПМСПвђЫижЎвЛЁЃЮвУЧЫЕвЛПтвЛЗўЕФМмЙЙЪЙЕУЖдвЛИіЗўЮёЕФЪ§ОнПтФЃЪНаоИФВЛЛсгАЯьЕНЦфЫћЗўЮёЁЃЕЋЪЧШчЙћЪЙгУвЛИіЖЏЬЌФЃЪНЃЈгаЪБКђгаШЫЛсЫЕЮоФЃЪНЃЉЕФЪ§ОнПтЃЌдђдкИУЗўЮёБОЩэФЃЪНаоИФЪБКђвВПЩвдзюаЁЛЏЦфзюаЁЛЏЕФЮЌдЫГЩБОЁЃ
вЛИіЪЪКЯЮЂЗўЮёМмЙЙЕФЪ§ОнПт
КьЩМзЪБОЕФКЯЛяШЫ Matt Miller ЪЧЙЋШЯЕФЮЂЗўЮёММЪѕСьгђзЈМвЁЃЫћЕФЙуБЛДЋВЅЕФЁАЮЂЗўЮёЩњЬЌЭМЁБЯъОЁЕФСаГіСЫЮЂЗўЮёМмЙЙЕФЯрЙиММЪѕеЛЁЃдкетРяЫћЭЦМіСЫ
MongoDB зїЮЊжївЊЕФЪ§ОнЙмРэЗНАИЁЃ
MongoDB ЪЧвЛИіЗжВМЪНЮФЕЕаЭЪ§ОнПтЃЌЫќгавдЯТвЛаЉЬиадЪЙЫќЗЧГЃЪЪКЯгкЮЂЗўЮёМмЙЙЃК
ЖрФЃЪ§ОнПт (Multi-model)
дЩњ JSON Ъ§ОнНсЙЙ - API
ЖЏЬЌФЃЪНЁЂЮоФЃЪН (Dynamic schema / Schemaless)
Ъ§ОнБфЛЏСї (Change Stream)
КсЯђРЉеЙФмСІ (Sharding)
ЖрФЃЪ§ОнПт
MongoDB Дг 3.4 АцБОЦ№дкЖрФЃЪ§ОнПтГЁОАЩЯЬсЙЉСЫВЛЩйЙІФмФЃПщЃЌБШШчЫЕЃЌЪЙгУОлКЯПђМм (Aggregation
Framework) ЯждкПЊЗЂепПЩвдЪЙгУ
$graphLookup РДЪЕЯжРрЫЦгкЭМЪ§ОнПтЕФВщбЏ
$facet РДЪЕЯжЗжУцЫбЫїЁЃ
ФкДцв§ЧцЙІФмЃЌгУгкжЇГжРрЫЦгк Redis ЕФИпЫйЛКДц
ШЋЮФМьЫїЃЌгУгкЪЕЯжЫбЫїРраЭГЁОА
JSON Ъ§ОнНсЙЙ
гЩгк MongoDB дЩњОЭЪЧ JSON Ъ§ОнФЃаЭЃЌе§КУЪЧЮЂЗўЮёМмЙЙжагУгкФЃПщМфЭЈаХЕФ HTTP RESTful
API ЕїгУЕФжївЊЪ§ФЃаЭЁЃЪТЪЕЩЯЃЌФуПЩвдЪЙгУвЛаЉПЊдДжаМфМўЃЌПьЫйЕФРДЙЙНЈЦ№ЮЂЗўЮёжЎМфЕФ API ЗўЮёЁЃ
ЖЏЬЌФЃЪН
етвЛЕувЛжБЪЧ MongoDB ЛёЕУПЊЗЂепЧрэљЕФжївЊдвђжЎвЛЁЃMongoDB ЮоаыЯдЪНЕФЖЈвхЪ§ОнФЃЪНМДПЩШУФуПЊЪМЭљЪ§ОнПтаДШыЁЃЕБЪ§ОнФЃаЭгаБфЛЏЪБКђЃЌБШШчЫЕдкЕќДњЪНПЊЗЂжаЗЧГЃГЃМћЕФОЭЪЧдіМгвЛаЉзжЖЮЃЌMongoDB
Ъ§ОнПтВЛашвЊЖдЦфНјаааоИФ schema ВйзїЃЌЖјЪЧПЩвджБНгдкЭЌвЛИіМЏКЯЃЈБэЃЉРяжБНгаДШыаТАцБОЕФЮФЕЕЁЃетИіЖдгкашвЊЪЕЯжПьЫйЕќДњЃЌПьЫйНЛИЖЕФЮЂЗўЮёгІгУПЊЗЂЪЧвЛИіЗЧГЃживЊЕФЬиадЁЃ
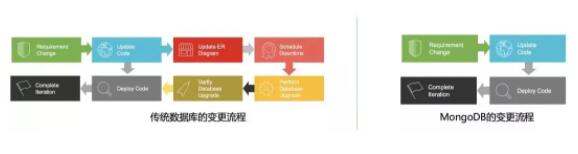
Ъ§ОнИќИФСї
ЮЂЗўЮёМмЙЙжагЩгкЦфЗжВМЬиадЃЌДЋЭГЕФЧПЪТЮёЛњжЦВЛдйЪЪгУЁЃЪ§ОнЕФвЛжТадвЛАуашвЊЭЈЙ§вЛаЉЛљгк Event
Sourcing ЛђепЪТМўЧ§ЖЏФЃаЭЕФНтОіЗНАИЁЃMongoDB 3.6 АцБОЭЦГіЕФЪ§ОнИќИФСїЃЌПЩвдгУРДЪЕЯжвЛИіРрЫЦгк
Kafak вЛбљЕФ Message QueueЃЌЮЊИїИіЮЂЗўЮёМфЕФЪ§ОнаЕїЬсЙЉвЛИіМђЕЅвзгУЕФЯпГЬЗНАИЁЃ
КсЯђРЉеЙФмСІ
MongoDB вЛЯђвдЦфЧПДѓЕФКсЯђРЉеЙФмСІжјГЦЁЃВЛЩй MongoDB гУЛЇЧЈвЦЕФжївЊдвђОЭЪЧЪЙгУ MongoDB
ЕФ sharding ММЪѕПЩвдЭЛЦЦЙиЯЕаЭЪ§ОнПтдкЪ§ОнСПКЭадФмЩЯЕФЦПОБЁЃMongoDB ЕФ sharding
гаМИИіЬиеїЪЙЕУЦфЗЧГЃЪЪКЯЮЂЗўЮёМмЙЙПМТЧЪЙгУЃК
ЕЏадРЉеЙЃКПЩвдРЉШнвВПЩвдЫѕШнЃЛ
ЮоЗьРЉеЙЃКЮоаыЭЃЛњЃЌОЭПЩдкЯпРЉШнЃЛ
здЖЏОљКтЃКЮоаыгІгУВЮгыМДПЩЪЕЯжЪ§ОнЕФздЖЏОљКтЃЌЭъШЋЭИУїЁЃ

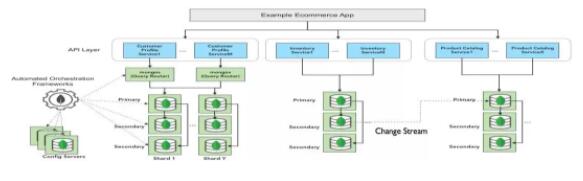
вЛИіЛљгк MongoDB ЕФЮЂЗўЮёВЮПММмЙЙЭМ
|









