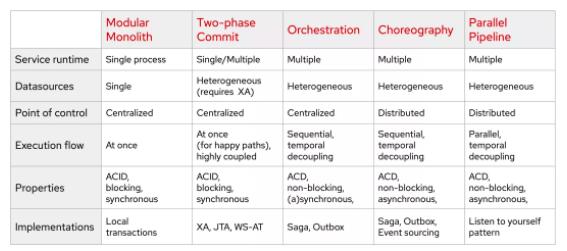
| БрМЭЦМі: |
БОЮФНщЩмСЫЯђЖрИіЪ§ОндДаЕїаДШыВйзїЕФжївЊЗНЪНКЭФЃЪН
ЁЃ
БОЮФРДздгкЙЋжкКХInfoQМмЙЙЭЗЬѕ ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
1
ЫЋжиаДШыЕФЮЪЬт
ЙигкФуЪЧЗёЛсУцСйЫЋжиаДШыЕФЮЪЬтгавЛИіМђЕЅЕФжИБъЃЌФЧОЭЪЧдЄЦквЊВЛвЊЯђЖрИіМЧТМЯЕЭГНјаааДШыВйзїЁЃетбљЕФашЧѓПЩФмВЂВЛУїЯдЃЌдкЗжВМЪНЯЕЭГЩшМЦЕФЙ§ГЬжаЃЌЫќПЩФмЛсвдВЛЭЌЕФЗНЪННјааБэЪіЁЃБШШчЫЕЃК
ФувбОЮЊУПЯюЙЄзїбЁдёСЫзюМбЙЄОпЃЌЯждкдквЛИівЕЮёЪТЮёжаЃЌФуБиаывЊИќаТвЛИі NoSQL Ъ§ОнПтЁЂвЛИіЫбЫїЫїв§КЭвЛИіЛКДцЁЃ
ФуЫљЩшМЦЕФЗўЮёБиаывЊИќаТздМКЕФЪ§ОнПтЃЌЭЌЪБЛЙвЊАбБфИќЯрЙиЕФаХЯЂвдЭЈжЊЕФаЮЪНЗЂЫЭИјСэвЛИіЗўЮёЁЃ
ФуЕФвЕЮёЪТЮёПчдНСЫЖрИіЗўЮёЕФБпНчЁЃ
ФуПЩФмашвЊвдУнЕШЕФЗНЪНЪЕЯжЗўЮёВйзїЃЌвђЮЊЗўЮёЕФЯћЗбепБиаывЊжиЪдЪЇАмЕФЕїгУЁЃ
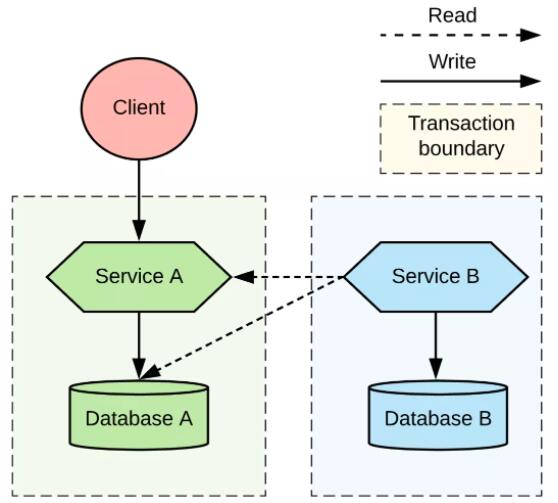
дкБОЮФжаЃЌЮвУЧНЋЛсЪЙгУвЛИіКмМђЕЅЕФЪОЧèОАРДЦРЙРдкЗжВМЪНЪТЮёжаДІРэЫЋжиаДШыЕФИїжжЗНЗЈЁЃЮвУЧЕФГЁОАЪЧвЛИіПЭЛЇЖЫгІгУЃЌЫќЛсдкЗЂЩњБфИќВйзїЕФЪБКђЃЌЕїгУвЛИіЮЂЗўЮёЁЃЗўЮё
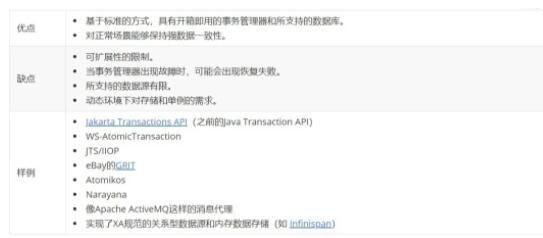
A вЊИќаТздМКЕФЪ§ОнПтЃЌЕЋЪЧЫќЛЙвЊЕїгУЗўЮё B НјаааДШыВйзїЃЌШчЭМ 1 ЫљЪОЁЃжСгкЪ§ОнПтЕФЪЕМЪРраЭвдМАЗўЮёгыЗўЮёжЎМфНјааНЛЛЅЕФавщЃЌетаЉЖдгкЮвУЧЕФЬжТлЖМЮоЙиНєвЊЃЌвђЮЊЮЪЬтЖМЪЧвЛбљЕФЁЃ
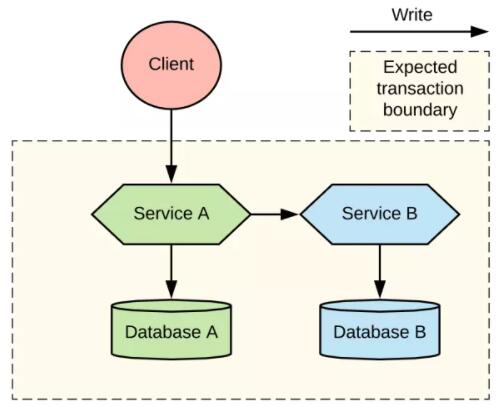
ЮЂЗўЮёжаЕФЫЋжиаДШыЮЪЬт
ЮвУЧМђвЊНтЪЭвЛЯТЮЊЪВУДетИіЮЪЬтУЛгаМђЕЅЕФНтОіЗНАИЁЃШчЙћЗўЮё A аДШыЕНСЫздМКЕФЪ§ОнПтЃЌШЛКѓЗЂЫЭвЛИіЭЈжЊЕНЖгСажаЙЉЗўЮё
B ЪЙгУЃЈЮвУЧНЋетжжЗНЪНГЦЮЊ local-commit-then-publishЃЉЃЌетбљгІгУвРШЛгаПЩФмЮоЗЈПЩППЕидЫааЁЃЕБЗўЮё
A аДШыЕНздМКЕФЪ§ОнПтЃЌШЛКѓЗЂЫЭЯћЯЂЕНЖгСаЪБЃЌвРШЛгаКмаЁЕФИХТЪЗЂЩњетбљЕФЪТЧщЃЌМДгІгУдкЬсНЛЕНЪ§ОнПтКѓЃЌЧвдкЕкЖўИіВйзїжЎЧАЃЌЗЂЩњСЫБРРЃЃЌетбљЕФЛАЃЌОЭЛсЪЙЯЕЭГДІгквЛИіВЛвЛжТЕФзДЬЌЁЃШчЙћЯћЯЂдкаДШыЕНЪ§ОнПтжЎЧАЗЂЫЭЕФЛАЃЈЮвУЧНЋетжжЗНЪНГЦЮЊ
publish-then-local-commitЃЉЃЌгаПЩФмГіЯжЪ§ОнПтаДШыЪЇАмЃЌЛђепЗўЮё B НгЪеЕНЪТМўЕФЪБКђЃЌЗўЮё
A ЛЙУЛгаЬсНЛЕНЪ§ОнПтЃЌетЛсГіЯжЪБаЇадЮЪЬтЁЃВЛЙмЪЧГіЯжФФжжЧщПіЃЌетжжГЁОАЖМЛсЩцМАЕНЖдЪ§ОнПтКЭЖгСаЕФЫЋжиаДШыЮЪЬтЃЌетОЭЪЧЮвУЧвЊЬНЬжЕФКЫаФЮЪЬтЁЃдкЯТУцЕФеТНкжаЃЌЮвУЧНЋЛсЬжТлеыЖдетвЛГЄЦкДцдкЕФЬєеНФПЧАвбгаЕФИїжжНтОіЗНАИЁЃ
2
ФЃПщЛЏЕЅЬх
НЋгІгУГЬађПЊЗЂЮЊФЃПщЛЏЕЅЬхПДЦ№РДЯёвЛжжШЈвЫжЎМЦЃЈhackЃЉЃЌЛђЪЧМмЙЙбнЛЏЕФвЛжжЕЙЭЫЁЃЕЋЪЧЃЌЮвЗЂЯжЫќдкЪЕМљжаФмЙЛКмКУЕидЫааЁЃЫќВЛЪЧвЛжжЮЂЗўЮёЕФФЃЪНЃЌЖјЪЧЮЂЗўЮёЙцдђЕФвЛИіР§ЭтЧщПіЃЌФмЙЛЗЧГЃбЯНїЕигыЮЂЗўЮёЯрНсКЯЁЃШчЙћЧПаДШывЛжТадЪЧЧ§ЖЏадЕФашЧѓЃЌЩѕжСвЊБШЖРСЂВПЪ№КЭРЉеЙЮЂЗўЮёЕФФмСІИќживЊЪБЃЌФЧУДЮвУЧОЭПЩвдВЩгУФЃПщЛЏЕЅЬхЕФМмЙЙЁЃ
ВЩгУЕЅЬхМмЙЙВЂВЛвтЮЖзХЯЕЭГЩшМЦЕУКмВюЛђепЪЧМўЛЕЪТЁЃЫќВЂВЛЫЕУїШЮКЮжЪСПЯрЙиЕФЮЪЬтЁЃЙЫУћЫМвхЃЌетЪЧвЛИіАДееФЃПщЛЏЗНЪНЩшМЦЕФЯЕЭГЃЌЫќжЛгавЛИіВПЪ№ЕЅдЊЁЃашвЊзЂвтЃЌетЪЧвЛИіОЋаФЩшМЦКЭЪЕЯжЕФФЃПщЛЏЕЅЬхЃЌетгыЫцвтДДНЈВЂЫцЪБМфЖјВЛЖЯдіГЄЕФЕЅЬхЪЧВЛЭЌЕФЁЃдкОЋаФЩшМЦЕФФЃПщЛЏЕЅЬхМмЙЙжаЃЌУПИіФЃПщЖМзёбЮЂЗўЮёЕФддђЁЃУПИіФЃПщЛсЗтзАЖдЦфЪ§ОнЕФЫљгаЗУЮЪЃЌЕЋЪЧВйзїЪЧвдФкДцЗНЗЈЕїгУЕФЗНЪННјааБЉТЖКЭЯћЗбЕФЁЃ
ФЃПщЛЏЕЅЬхЕФМмЙЙ
ШчЙћВЩгУетжжЗНЪНЕФЛАЃЌЮвУЧБиаывЊНЋСНИіЮЂЗўЮёЃЈЗўЮё A КЭЗўЮё BЃЉзЊЛЛГЩПЩвдВПЪ№ЕНЙВЯэдЫааЪБЕФПтФЃПщЃЈlibrary
moduleЃЉЁЃШЛКѓЃЌШУетСНИіЮЂЗўЮёЙВЯэЭЌвЛИіЪ§ОнПтЪЕР§ЁЃвђЮЊЗўЮёЪЧдквЛИіЭЈгУЕФдЫаажаБраДКЭВПЪ№ЕФЃЌЫљвдЫќУЧПЩвдВЮгыЯрЭЌЕФЪТЮёЁЃМјгкетаЉФЃПщЙВЯэЭЌвЛИіЪ§ОнПтЪЕР§ЃЌЫљвдЮвУЧПЩвдЪЙгУБОЕиЪТЮёвЛДЮадЕиЬсНЛЛђЛиЙіЫљгаЕФБфИќЁЃдкВПЪ№ЗНЗЈЗНУцвВгаВювьЃЌвђЮЊЮвУЧЯЃЭћФЃПщвдПтЕФЗНЪНВПЪ№ЕНвЛИіИќДѓЕФВПЪ№ЕЅдЊжаЃЌВЂВЮгыЯжгаЕФЪТЮёЁЃ
МДБуЪЧдкЕЅЬхМмЙЙжаЃЌвВгавЛаЉЗНЪНРДИєРыДњТыКЭЪ§ОнЁЃР§ШчЃЌЮвУЧПЩвдНЋФЃПщИєРыГЩЕЅЖРЕФАќЁЂЙЙНЈФЃПщКЭдДТыВжПтЃЌетаЉФЃПщПЩвдгЩВЛЭЌЕФЭХЖгЫљгЕгаЁЃЭЈЙ§НЋБэАДееУќУћЙцдђЁЂФЃЪНЁЂЪ§ОнПтЪЕР§ЃЌЩѕжСЪ§ОнПтЗўЮёЦїЕФЗНЪННјааЗжзщЃЌЮвУЧПЩвдЪЕЯжЪ§ОнЕФВПЗжИєРыЁЃЭМ
2 ЕФСщИаРДдДгк Axel Fontaine ЙигкЮАДѓЕФФЃПщЛЏЕЅЬхЕФбнНВЃЌЫќВћЪіСЫгІгУжаВЛЭЌЕФДњТыКЭЪ§ОнИєРыМЖБ№ЁЃ
гІгУГЬађЕФДњТыКЭЪ§ОнИєРыМЖБ№
ЦДЭМЕФзюКѓвЛПщЪЧЪЙгУвЛИідЫааЪБКЭвЛИіАќзАЦїЗўЮёЃЈwrapper serviceЃЉЃЌИУЗўЮёФмЙЛЯћЗбЦфЫћЕФФЃПщВЂНЋЦфФЩШыЕНЯжгаЪТЮёЕФЩЯЯТЮФжаЁЃЫљгаЕФетаЉЯожЦЪЙФЃПщБШЕфаЭЕФЮЂЗўЮёёюКЯИќНєУмЃЌЕЋЪЧКУДІдкгкАќзАЦїЗўЮёФмЙЛЦєЖЏвЛИіЪТЮёЁЂЕїгУПтФЃПщРДИќаТЫќУЧЕФЪ§ОнПтЃЌВЂЧввдвЛИіВйзїЕФаЮЪНЬсНЛЛђЛиЙіЪТЮёЃЌЖјВЛБиЕЃаФВПЗжЪЇАмЛђзюжевЛжТадЕФЮЪЬтЁЃ
дкЮвУЧЕФбљР§жаЃЌШчЭМ 3 ЫљЪОЃЌЮвУЧНЋЗўЮё A КЭЗўЮё B зЊЛЛЮЊПтЃЌВЂНЋЫќУЧВПЪ№ЕНвЛИіЙВЯэЕФдЫааЪБжаЃЌЛђепвВПЩвдНЋЦфжаЕФФГИіЗўЮёзїЮЊЙВЯэдЫааЪБЁЃЪ§ОнПтЕФБэвВЙВЯэЭЌвЛИіЪ§ОнПтЪЕР§ЃЌЕЋЪЧЫќЛсБЛВ№ЗжЮЊвЛзщгЩИїздЕФПтЗўЮёЙмРэЕФБэЁЃ
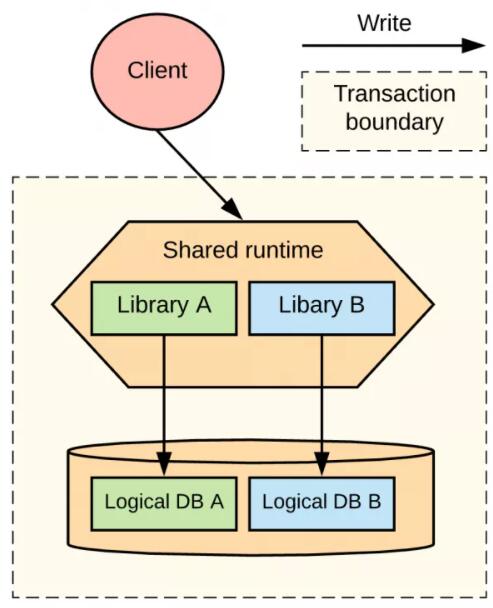
ОпгаЙВЯэЪ§ОнПтЕФФЃПщЛЏЕЅЬх
ФЃПщЛЏЕЅЬхЕФгХЕуКЭШБЕу
дкгааЉаавЕжаЃЌетжжМмЙЙЕФЪевцдЖБШЦфЫћЕиЗНЫљПДжиЕФИќПьЕФНЛИЖвдМАИќПьЕФБфИќНкзрживЊЕУЖрЁЃБэ 1 змНсСЫФЃПщЛЏЕЅЬхМмЙЙЕФгХЕуКЭШБЕуЁЃ

Бэ 1ЃКФЃПщЛЏЕЅЬхМмЙЙЕФгХЕуКЭШБЕу
ЗжВМЪНЪТЮёЭЈГЃЪЧзюКѓЕФЗНАИЃЌЭЈГЃЛсдкШчЯТЕФЧщПіЯТЪЙгУЃК
ЕБЖдВЛЭЌзЪдДЕФаДШыВйзїВЛдЪаэзюжевЛжТадЪБЃЛ
ЕБЮвУЧБиаывЊаДШыЕНВЛЭЌжжРрЕФЪ§ОндДЪБЃЛ
ЕБЮвУЧашвЊШЗБЃЖдЯћЯЂЕФДІРэгаЧвНігавЛДЮЃЌЖјЧвЮоЗЈжиЙЙЯЕЭГвдЪЕЯжВйзїЕФУнЕШадЪБЃЛ
ЕБгыЕкШ§ЗНКкКаЯЕЭГЛђЪЕЯжСЫСННзЖЮЬсНЛЙцЗЖЕФвХСєЯЕЭГНјааМЏГЩЪБЁЃ
дкетаЉЧщПіЯТЃЌШчЙћПЩРЉеЙадВЛЪЧживЊЕФЙизЂЕуЕФЛАЃЌЮвУЧПЩвдПМТЧНЋЗжВМЪНЪТЮёзїЮЊвЛжжПЩбЁЗНАИЁЃ
ЪЕЯжСННзЖЮЬсНЛМмЙЙ
СННзЖЮЬсНЛММЪѕвЊЧѓЮвУЧгавЛИіЗжВМЪНЪТЮёЙмРэЦїЃЈШч NarayanaЃЉКЭвЛИіПЩППЕФЪТЮёШежОДцДЂВуЁЃЮвУЧЛЙашвЊФмЙЛМцШн
DTP XA ЕФЪ§ОндДЃЌвдМАФмЙЛВЮгыЗжВМЪНЪТЮёЕФЯрЙиЕФ XA Ч§ЖЏЃЌБШШч RDBMSЁЂЯћЯЂДњРэКЭЛКДцЁЃШчЙћФузуЙЛавдЫгаКЯЪЪЕФЪ§ОндДЃЌЕЋЪЧдЫаадквЛИіЖЏЬЌЛЗОГжаЃЌБШШч
KubernetesЃЌФЧУДФуЛЙашвЊгавЛИіЯё operator етбљЕФЛњжЦЃЌвдШЗБЃЗжВМЪНЪТЮёЙмРэЦїжЛгавЛИіЪЕР§ЁЃЪТЮёЙмРэЦїБиаыЪЧИпПЩгУЕФЃЌВЂЧвБиаыФмЙЛЗУЮЪЪТЮёШежОЁЃ
ОЭЪЕЯжЖјбдЃЌФуПЩвдГЂЪдЪЙгУ Snowdrop Recovery ControllerЃЌЫќЪЙгУ Kubernetes
StatefulSet ФЃЪНРДЪЕЯжЕЅР§ЃЌВЂЪЙгУГжОУЛЏОэРДДцДЂЪТЮёШежОЁЃдкетИіРрБ№жаЃЌЮвЛЙАќКЌСЫЪЪгУгк
SOAP Web ЗўЮёЕФ Web Services Atomic TransactionЃЈWS-AtomicTransactionЃЉЕШЙцЗЖЁЃЫљгаетаЉММЪѕЕФЙВЭЌЕудкгкЫќУЧЪЕЯжСЫ
XA ЙцЗЖЃЌВЂЧвгавЛИіжааФЛЏЕФЪТЮёаЕїЦїЁЃ
дкЮвУЧЕФбљР§жаЃЌШчЭМ 4 ЫљЪОЃЌЗўЮё A ЪЙгУЗжВМЪНЪТЮёЬсНЛЫљгаЕФБфИќЕНздМКЕФЪ§ОнПтжаЃЌВЂЧвЛсЬсНЛвЛЬѕЯћЯЂЕНЖгСажаЃЌетИіЙ§ГЬжаВЛЛсГіЯжЯћЯЂЕФжиИДКЭЖЊЪЇЁЃРрЫЦЕФЃЌЗўЮё
B ПЩвдЪЙгУЗжВМЪНЗўЮёРДЯћЗбЯћЯЂЃЌВЂдкЭЌвЛИіЪТЮёжаЬсНЛжСЪ§ОнПт BЃЌетИіЙ§ГЬжавВВЛЛсГіЯжШЮКЮЕФжиИДЪ§ОнЁЃЛђепЃЌЗўЮё
B вВПЩвдбЁдёВЛЪЙгУЗжВМЪНЪТЮёЃЌЖјЪЧЪЙгУБОЕиЪТЮёВЂЪЕЯжУнЕШЕФЯћЗбепФЃЪНЁЃдкБОНкжаЃЌвЛИіИќКЯЪЪЕФР§згЪЧЪЙгУ
WS-AtomicTransaction дквЛИіЪТЮёжааЕїЖдЪ§ОнПт A КЭЪ§ОнПт B ЕФаДШыЃЌВЂЭъШЋБмУтзюжевЛжТадЁЃЕЋЪЧЃЌЯждкетжжЗНЪНвбОВЛЬЋГЃМћСЫЁЃ
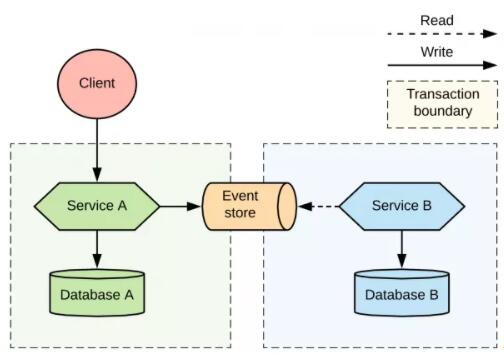
ПчЪ§ОнПтКЭЯћЯЂДњРэЕФЖўНзЖЮЬсНЛ
СННзЖЮЬсНЛМмЙЙгХЕуКЭШБЕу
СННзЖЮЬсНЛавщЫљЬсЙЉЕФБЃеЯгыФЃПщЛЏЕЅЬхжаЕФБОЕиЪТЮёРрЫЦЃЌЕЋгааЉР§ЭтЧщПіЁЃвђЮЊетРягаСНИіЛђИќЖрЕФЖРСЂЪ§ОндДВЮгыЕНдзгИќаТжЎжаЃЌЫљвдЫќУЧПЩФмЛсвдВЛЭЌЕФЗНЪНЪЇАмВЂзшШћећИіЪТЮёЁЃЕЋЪЧЃЌгЩгкДцдквЛИіжааФЛЏЕФаЕїепЃЌЯрЖдгкЮвЯТУцНЋвЊЬжТлЕФЦфЫћЗНЪНЃЌЮвУЧЛЙЪЧФмЙЛКмШнвзЕиЗЂЯжЗжВМЪНЯЕЭГЕФзДЬЌЁЃ
Бэ 2ЃКСННзЖЮЬсНЛЕФгХЕуКЭШБЕу
3
БрХХЪН
ЖдгкФЃПщЛЏЕЅЬхРДНВЃЌЮвУЧЛсЪЙгУБОЕиЪТЮёЃЌетбљЮвУЧЪМжеФмЙЛжЊЕРЯЕЭГЕФзДЬЌЁЃЖдЛљгкСННзЖЮЬсНЛЕФЗжВМЪНЪТЮёЃЌЮвУЧвВФмБЃжЄзДЬЌЕФвЛжТадЁЃЮЈвЛЕФР§ЭтЧщПіЪЧЪТЮёаЕїепГіЯжСЫВЛПЩЛжИДЕФЙЪеЯЁЃЕЋЪЧЃЌШчЙћЮвУЧЯывЊМѕШѕвЛжТадЕФашЧѓЃЌЖјЯЃЭћФмЙЛСЫНтећИіЗжВМЪНЯЕЭГЕФзДЬЌЃЌВЂЧвФмДгвЛИіЕиЗНЖдЦфНјаааЕїЃЌФЧУДЮвУЧИУдѕУДДІРэФиЃП
дкетжжЧщПіЯТЃЌЮвУЧПЩвдПМТЧВЩШЁвЛжжБрХХЃЈorchestrationЃЉЕФЗНЪНЃЌдкетРяЃЌФГИіЗўЮёЛсЕЃШЮећИіЗжВМЪНзДЬЌБфИќЕФаЕїепКЭБрХХепЁЃБрХХепЗўЮёгад№ШЮЕїгУЦфЫћЕФЗўЮёЃЌжБжСЫќУЧДяЕНЫљашЕФзДЬЌЃЌЛђепдкЫќУЧГіЯжЙЪеЯЕФЪБКђжДааОРе§ДыЪЉЁЃБрХХепЪЙгУЫќЕФБОЕиЪ§ОнПтРДИњзйзДЬЌБфИќЃЌВЂЧввЊИКд№ЛжИДгызДЬЌБфИќЕФЫљгаЙЪеЯЁЃ
ЪЕЯжБрХХЪНМмЙЙ
БрХХЪНММЪѕзюСїааЕФЪЕЯжЪЧ BPMN ЙцЗЖЕФИїжжОпЬхЪЕЯжЃЌБШШч jBPM КЭ CamundaЁЃЖдетжжЯЕЭГЕФашЧѓВЂВЛЛсвђЮЊЮЂЗўЮёЛђ
Serverless етбљЕФМЋЖШЗжВМЪНМмЙЙЕФГіЯжЖјЯћЪЇЃЌЯрЗДЃЌетжжашЧѓЛЙЛсдіМгЁЃЮЊСЫжЄУїетвЛЕуЃЌЮвУЧПЩвдПДвЛЯТНЯаТЕФгазДЬЌБрХХв§ЧцЃЌЫќУЧУЛгазёбЪВУДЙцЗЖЃЌЕЋЪЧШДЬсЙЉСЫРрЫЦЕФгазДЬЌааЮЊЃЌБШШч
Netflix ЕФ ConductorЁЂUber ЕФ Cadence КЭ Apache ЕФ AirflowЁЃЯё
Amazon StepFunctionsЁЂAzure Durable Functions КЭ Azure
Logic Apps етбљЕФ Serverless газДЬЌКЏЪ§вВЪєгкетИіРрБ№ЁЃЛЙгавЛаЉПЊдДПтдЪаэЮвУЧЪЕЯжгазДЬЌЕФаЕїКЭЛиЙіааЮЊЃЌШч
Apache Camel ЕФ Saga ФЃЪНЪЕЯжКЭ NServiceBus ЕФ Saga ЙІФмЁЃаэЖрЪЕЯж
Saga ФЃЪНЕФздЖЈвхЯЕЭГвВЪєгкетвЛРрЁЃ
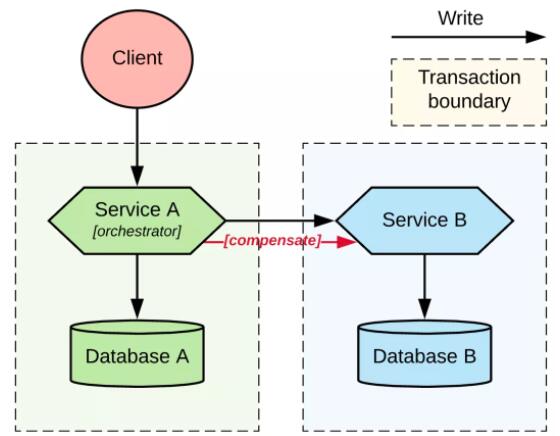
БрХХСНИіЗўЮёЕФЗжВМЪНЪТЮё
дкЮвУЧЕФЪОР§ЭМжаЃЌЮвУЧШУЗўЮё A зїЮЊгазДЬЌЕФБрХХепЃЌИКд№ЕїгУЗўЮё B ВЂдкашвЊЕФЪБКђЭЈЙ§ВЙГЅВйзїДгЙЪеЯжаЛжИДЁЃетжжЗНЪНЕФЙиМќЬиеїЪЧЃЌЗўЮё
A КЭЗўЮё B гаБОЕиЪТЮёЕФБпНчЃЌЕЋЪЧЗўЮё A гааЕїећИіНЛЛЅСїГЬЕФжЊЪЖКЭд№ШЮЁЃетвВЪЧЮЊЪВУДЫќЕФЪТЮёБпНчЛсНгДЅЕНЗўЮё
B ЕФЖЫЕуЁЃдкЪЕЯжЗНУцЃЌЮвУЧПЩвдЪЙгУЭЌВНЕФНЛЛЅЃЌОЭЯёЩЯЭМЫљЪОЃЌвВПЩвддкЗўЮёжЎМфЪЙгУЯћЯЂЖгСаЃЈдкетжжЧщПіЯТЮвУЧвВПЩвдЪЙгУСННзЖЮЬсНЛЃЉЁЃ
БрХХЪНЕФгХЕуКЭШБЕу
БрХХЪНЪЧвЛжжзюжевЛжТЕФЗНЗЈЃЌЫќПЩФмЛсЩцМАЕНжиЪдКЭЛиЙіВХФмЪЙЗжВМЪНЯЕЭГДяЕНвЛжТЕФзДЬЌЁЃЫфШЛБмУтСЫЖдЗжВМЪНЪТЮёЕФашЧѓЃЌЕЋЪЧБрХХЕФЗНЪНвЊЧѓВЮгыЕФЗўЮёЬсЙЉУнЕШЕФВйзїЃЌвдЗРаЕїепБиаыНјаажиЪдВйзїЁЃВЮгыЕФЗўЮёЛЙБиаывЊЬсЙЉЛжИДЖЫЕуЃЌвдЗРаЕїепОіЖЈжДааЛиЙіВЂаоИДШЋОжзДЬЌЁЃетжжЗНЪНЕФзюДѓгХЕуЪЧЃЌФмЙЛНіЭЈЙ§БОЕиЪТЮёОЭФмЧ§ЖЏФЧаЉПЩФмВЛжЇГжЗжВМЪНЪТЮёЕФвьЙЙЗўЮёДяЕНвЛжТЕФзДЬЌЁЃаЕїепКЭВЮгыЕФЗўЮёжЛашвЊБОЕиЪТЮёМДПЩЃЌЖјЧвЪМжеФмЙЛЭЈЙ§аЕїепВщбЏЯЕЭГЕФзДЬЌЃЌМДБуЫќФПЧАПЩФмДІгкВПЗжвЛжТЕФзДЬЌЁЃдкЯТУцЮвЫљУшЪіЕФЦфЫћЗНЪНжаЃЌЪЧВЛПЩФмЪЕЯжетвЛЕуЕФЁЃ
Бэ 3ЃКБрХХЪНЕФгХЕуКЭШБЕу
4
аЭЌЪН
ДгЦљНёЮЊжЙЕФЬжТлжаЃЌЮвУЧПЩвдПДЕНЃЌвЛИівЕЮёВйзїПЩФмЛсЕМжТЗўЮёМфЕФЖрДЮЕїгУЃЌВЂЧввЛИівЕЮёЪТЮёЭъГЩЖЫЕНЖЫЕФДІРэЫљашЕФЪБМфЪЧВЛШЗЖЈЕФЁЃЮЊСЫЙмРэетвЛЕуЃЌБрХХЪНЃЈorchestrationЃЉФЃЪНЛсЪЙгУвЛИіжааФЛЏЕФПижЦЦїЗўЮёЃЌЫќЛсИцЫпВЮгыепИУзіЪВУДЁЃ
БрХХЪНЕФвЛжжЬцДњЗНАИОЭЪЧаЭЌЪНЃЈchoreographyЃЉЃЌдкетжжЗчИёЕФЗўЮёаЕїжаЃЌВЮгыепдкНЛЛЛЪТМўЪБУЛгавЛИіжааФЛЏЕФПижЦЕуЁЃдкетжжФЃЪНЯТЃЌУПИіЗўЮёЛсжДаавЛИіБОЕиЪТЮёВЂЗЂВМЪТМўЃЌДгЖјДЅЗЂЦфЫћЗўЮёжаЕФБОЕиЪТЮёЁЃЯЕЭГжаЕФУПИізщМўЖМвЊВЮгывЕЮёЪТЮёЙЄзїСїЕФОіВпЃЌЖјВЛЪЧвРРЕвЛИіжааФЛЏЕФПижЦЕуЁЃдкРњЪЗЩЯЃЌаЭЌЪНЗНЪНзюГЃМћЕФЪЕЯжОЭЪЧЪЙгУвьВНЯћЯЂВуРДНјааЗўЮёЕФНЛЛЅЁЃЭМ
6 ЫЕУїСЫаЭЌЪНФЃЪНЕФЛљБОМмЙЙЁЃ
ЭЈЙ§ЯћЯЂВуНјааЗўЮёаЭЌЛЏ
ОпгаЫЋжиаДШыЕФаЭЌЪН
ЮЊСЫЪЕЯжЛљгкЯћЯЂЕФЗўЮёаЭЌЃЌЮвУЧашвЊУПИіВЮгыЕФЗўЮёжДаавЛИіБОЕиЪТЮёЃЌВЂЭЈЙ§ЯђЯћЯЂЛљДЁЩшЪЉЗЂВМвЛИіУќСюЛђЪТМўЃЌвдДЅЗЂЯТвЛИіЗўЮёЁЃЭЌбљЕФЃЌЦфЫћВЮгыЕФЗўЮёБиаыЯћЗбвЛИіЯћЯЂВЂжДааБОЕиЪТЮёЁЃДгБОжЪЩЯРДНВЃЌетОЭЪЧдквЛИіНЯИпВуМЖЕФЫЋжиаДШыЮЪЬтжагжГіЯжСЫСэвЛИіЫЋжиаДШыЕФЮЪЬтЁЃЕБЮвУЧПЊЗЂвЛИіОпгаЫЋжиаДШыЕФЯћЯЂВуРДЪЕЯжаЭЌЪНФЃЪНЕФЪБКђЃЌЮвУЧПЩвдАбЫќЩшМЦГЩПчБОЕиЪ§ОнПтКЭЯћЯЂДњРэЕФвЛИіСННзЖЮЬсНЛЁЃдкЧАУцЃЌЮвУЧдјОНщЩмЙ§етжжЗНЪНЁЃСэЭтЃЌЮвУЧвВПЩвдВЩгУ
publish-then-local-commit Лђ local-commit-then-publish
ФЃЪНЃК
Publish-then-local-commitЃКЮвУЧПЩвдЯШГЂЪдЗЂВМвЛЬѕЯћЯЂЃЌШЛКѓдйЬсНЛБОЕиЪТЮёЁЃЫфШЛетжжЗНАИЬ§Ц№РДВЛДэЃЌЕЋЪЧЫќгавЛаЉЧаЪЕЕФЬєеНЁЃОйР§РДЫЕЃЌдкКмЖрЪБКђЃЌЮвУЧашвЊЗЂВМвЛИігЩБОЕиЪТЮёЫљЩњГЩЕФ
IDЃЌЖјетИі ID ДЫЪБЛЙУЛгаЩњГЩЃЌвђДЫЮоЗЈЗЂВМЁЃСэЭтЃЌБОЕиЪТЮёгаПЩФмЛсЪЇАмЃЌЕЋЪЧЮвУЧЮоЗЈЛиЙівбОЗЂВМЕФЯћЯЂЁЃетжжЗНЪНШБЗІЁАЖСШЁздМКЕФаДШыЁБЕФгявхЃЌвђДЫЖдгкДѓЖрЪ§ГЁОАРДЫЕЃЌетВЂВЛЪЧКЯЪЪЕФЗНАИЁЃ
Local-commit-then-publishЃКвЛИіЩдКУвЛЕуЕФАьЗЈЪЧЯШЬсНЛБОЕиЪТЮёЃЌШЛКѓдйЗЂВМЯћЯЂЁЃдкБОЕиЪТЮёЬсНЛжЎКѓКЭЯћЯЂЗЂВМжЎЧАетРягаКмаЁЕФИХТЪЛсГіЯжЙЪеЯЁЃЕЋМДБуЪЧГіЯжетбљЕФЧщПіЃЌФувВПЩвдАбЗўЮёЩшМЦГЩУнЕШЕФВЂЖдВйзїНјаажиЪдЁЃетвтЮЖзХЛсдйДЮЬсНЛБОЕиЪТЮёВЂЗЂВМЯћЯЂЁЃШчЙћФуФмПижЦЯТгЮЕФЯћЗбепВЂЧвШЗБЃЫќУЧЪЧУнЕШЕФЃЌФЧУДетжжЗНЪНОЭЪЧаажЎгааЇЕФЁЃзмЬхЖјбдЃЌетЪЧвЛИіКмКУЕФЪЕЯжЗНАИЁЃ
ЮоЫЋжиаДШыЕФаЭЌЪН
ЪЕЯжаЭЌЪНМмЙЙЕФИїжжЪЕЯжЗНЪНЖМЯожЦУПИіЗўЮёЖМвЊЭЈЙ§БОЕиЪТЮёаДШыЕНЕЅвЛЕФЪ§ОндДжаЃЌЖјВЛФмаДШыЕНЦфЫћЕФЕиЗНжаЁЃЮвУЧПДвЛЯТЃЌШчКЮдкБмУтЫЋжиаДШыЕФЧщПіЯТЪЕЯжетвЛЕуЁЃ
МйЩшЗўЮё A НгЪеЕНвЛИіЧыЧѓВЂвЊЖдЪ§ОнПт A НјаааДШыВйзїЃЌГ§ДЫжЎЭтВЛдйВйзїЦфЫћЕФЪ§ОндДЁЃЗўЮё B
жмЦкадЕиТжбЏЗўЮё A ВЂЬНВтаТЕФБфИќЁЃЕБЫќЖСШЁЕНБфИќЪБЃЌЗўЮё B ЛсЛљгкБфИќИќаТздМКЕФЪ§ОнПтЃЌВЂЧвЛсИќаТЫїв§ЛђЪБМфДСРДБъМЧЛёШЁЕНСЫБфИќЁЃетРяЕФЙиМќдкгкЃЌетСНИіЗўЮёжЛЖдздМКЕФЪ§ОнПтНјаааДШыВйзїЃЌВЂвдБОЕиЪТЮёЕФаЮЪННјааЬсНЛЁЃШчЭМ
7 ЫљЪОЃЌетжжЗНЪНПЩвдУшЪіЮЊЗўЮёаЭЌЃЈservice choreographyЃЉЃЌЛђепЮвУЧвВПЩвдгУЗЧГЃЙХРЯЕФЪ§ОнЙмЕРЕФЪѕгяРДЖдЦфНјааУшЪіЁЃжСгкПЩЙЉбЁгУЕФЪЕЯжЗНАИОЭИќгаШЄСЫЁЃ
ЭЈЙ§ТжбЏЪЕЯжЕФЗўЮёаЭЌ
ЖдгкЗўЮё B РДЫЕЃЌзюМђЕЅЕФГЁОАОЭЪЧСЌНгЕНЗўЮё A ЕФЪ§ОнПтВЂЖСШЁЗўЮё A ЕФБэЁЃЕЋЪЧЃЌвЕНчЛсОЁСПБмУтЙВЯэЪ§ОнБэетжжМЖБ№ЕФёюКЯЃЌдвђдкгкЃКЗўЮё
A ЕФЪЕЯжКЭЪ§ОнФЃаЭЕФШЮвтБфИќЖМПЩФмИЩШХЕНЗўЮё BЁЃЮвУЧПЩвдЖдетжжГЁОАзівЛаЉИФНјЃЌР§ШчЪЙгУЗЂМўЯфЃЈOutboxЃЉФЃЪНЃЌЮЊЗўЮё
A ЬсЙЉвЛИіБэзїЮЊЙЋПЊНгПкЁЃетИіБэПЩвджЛАќКЌЗўЮё B ЫљашЕФФкШнЃЌЫќПЩвдЩшМЦЕУвзгкВщбЏКЭИњзйБфИќЁЃШчЙћФуОѕЕУетЛЙВЛЙЛКУЕФЛАЃЌНјвЛВНЕФИФНјЗНАИЪЧШУЗўЮё
B ЭЈЙ§ API ЙмРэВуВщбЏЗўЮё A ЕФЫљгаБфЛЏЃЌЖјВЛЪЧжБНгСЌНгЪ§ОнПт AЁЃ
ДгИљБОЩЯРДНВЃЌЫљгаЕФетаЉБфжжаЮЪНЖМгавЛИіЯрЭЌЕФШБЕуЃКЗўЮё B ашвЊВЛЖЯЕиТжбЏЗўЮё AЁЃетжжЗНЪНЛсИјЯЕЭГДјРДВЛБивЊЕФГжајИКдиЃЌЛђепдкНгЪеБфИќЪБДцдкВЛБивЊЕФбгГйЁЃТжбЏЮЂЗўЮёЕФБфИќВЂВЛЪЧГЃМћЕФзіЗЈЃЌФЧУДЮвУЧПДвЛЯТШчКЮНјвЛВНИФЩЦетИіМмЙЙЁЃ
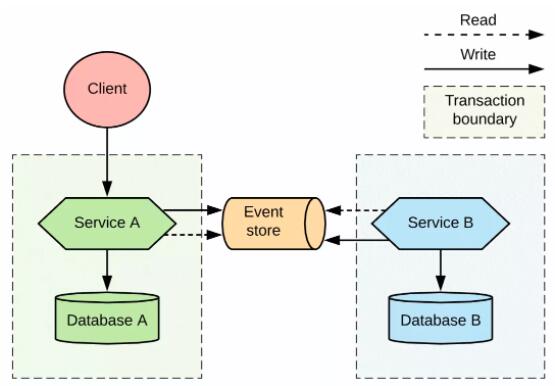
ЪЙгУ Debezium ЕФаЭЌЪН
дкИФНјаЭЌЪНМмЙЙЪБЃЌгавЛжжЗНЪНКмгаЮќв§СІЃЌФЧОЭЪЧв§ШыЯё Debezium етбљЕФЙЄОпЃЌЫќЪЙгУЪ§ОнПт
A ЕФЪТЮёШежОжДааБфИќЪ§ОнВЖЛёЃЈchange data captureЃЌCDCЃЉЁЃетжжЗНЪНШчЭМ 8
ЫљЪОЁЃ
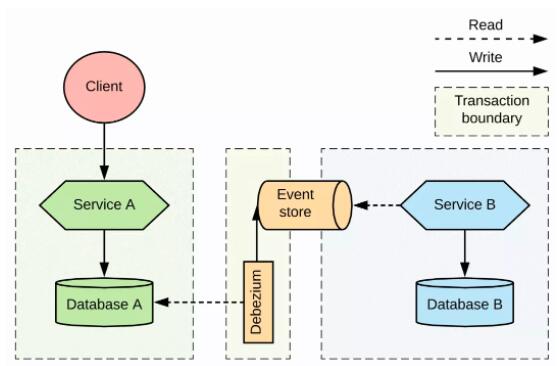
ЭЈЙ§БфИќЪ§ОнВЖЛёЪЕЯжЕФЗўЮёаЭЌ
Debezium ПЩвдМрПиЪ§ОнПтЕФЪТЮёШежОЃЌжДааБивЊЕФЙ§ТЫКЭзЊЛЛЃЌВЂНЋЯрЙиЕФБфИќЭЖЕнЕН Apache
Kafka ЕФжїЬтжаЁЃетбљЕФЛАЃЌЗўЮё B ОЭПЩвдМрЬ§жїЬтжаЕФЭЈгУЪТМўЃЌЖјВЛЪЧТжбЏЗўЮё A ЕФЪ§ОнПтЛђ
APIЁЃЮвУЧЭЈЙ§етжжЗНЪНЃЌНЋЪ§ОнПтТжбЏзЊЛЛГЩСЫСїЪНБфИќЃЌВЂЧвдкЗўЮёМфв§ШыСЫвЛИіЖгСаЃЌетбљЛсЪЙЕУЗжВМЪНЯЕЭГИќМгПЩППЁЂПЩРЉеЙЃЌЖјЧвЮЊаТЕФЪЙгУГЁОАЛсв§ШыЦфЫћЯћЗбепЬсЙЉСЫПЩФмадЁЃDebezium
ЬсЙЉСЫвЛжжгХбХЕФЗНЪНРДЪЕЯжЗЂМўЯфФЃЪНЃЌФмЙЛгУгкЛљгкБрХХЪНКЭаЭЌЪНЕФ Saga ФЃЪНЪЕЯжЁЃ
етжжЗНЪНЕФвЛИіИБзїгУдкгкЃЌЗўЮё B гаНгЪеЕНжиИДЯћЯЂЕФПЩФмадЁЃетПЩвдЭЈЙ§ЪЕЯжУнЕШЕФЗўЮёРДНтОіЃЌПЩвддквЕЮёТпМВуУцРДНтОіЃЌвВПЩвдЪЙгУММЪѕЛЏЕФШЅжиЦїЃЈdeduplicatorЃЌБШШч
Apache ActiveMQ Artemis ЕФжиИДЯћЯЂЬНВтЛђеп Apache Camel ЕФУнЕШЯћЗбепФЃЪНЃЉЁЃ
ЪЙгУЪТМўЫндДЕФаЭЌЪНФЃЪН
ЪТМўЫндДЃЈevent sourcingЃЉЪЧСэЭтвЛжжЗўЮёаЭЌЕФЪЕЯжФЃЪНЁЃдкетжжФЃЪНЯТЃЌЪЕЬхЕФзДЬЌЛсБЛДцДЂЮЊвЛЯЕСаЕФзДЬЌБфИќЪТМўЁЃЕБгааТЕФИќаТЪБЃЌВЛЪЧИќаТЪЕЬхЕФзДЬЌЃЌЖјЪЧЭљЪТМўЕФСаБэжазЗМгвЛИіаТЕФЪТМўЁЃЭљЪТМўДцДЂжазЗМгаТЕФЪТМўЪЧвЛИідзгадЕФВйзїЃЌЛсдквЛИіБОЕиЪТЮёжаЭъГЩЁЃШчЭМ
9 ЫљЪОЃЌетжжЗНЪНЕФКУДІдкгкЃЌЖдгкЯћЗбЪ§ОнИќаТЕФЦфЫћЗўЮёРДНВЃЌЪТМўДцДЂЕФааЮЊвВЪЧвЛИіЯћЯЂЖгСаЁЃ
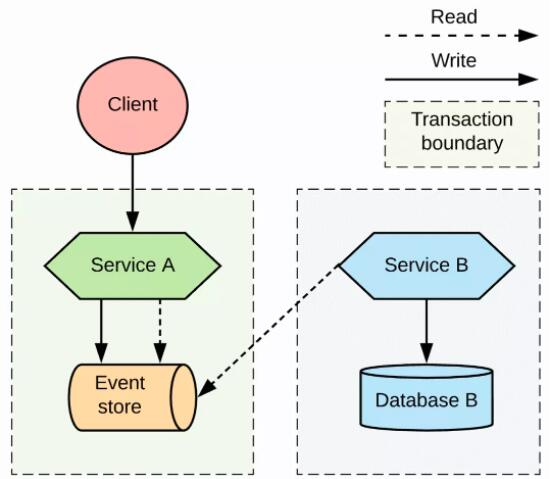
ЭЈЙ§ЪТМўЫндДЪЕЯжЕФЗўЮёаЭЌ
дкЮвУЧбљР§жаЃЌШчЙћвЊзЊЛЛГЩЪЙгУЪТМўЫндДЕФЛАЃЌвЊАбПЭЛЇЖЫЕФЧыЧѓДцДЂдквЛИіжЛФмНјаазЗМгВйзїЕФЪТМўДцДЂжаЁЃЗўЮё
A ПЩвдЭЈЙ§жиЗХЃЈreplayЃЉЪТМўжиаТЙЙНЈЕБЧАЕФзДЬЌЁЃЪТМўДцДЂашвЊШУЗўЮё B вВЖЉдФЯрЭЌЕФИќаТЪТМўЁЃЭЈЙ§етжжЛњжЦЃЌЗўЮё
A ЪЙгУЦфДцДЂВузїЮЊгыЦфЫћЗўЮёЕФЭЈаХВуЁЃОЁЙметжжЛњжЦЗЧГЃећНрЃЌНтОіСЫЕБгазДЬЌБфИќЪБПЩППЕиЗЂВМЪТМўЕФЮЪЬтЃЌЕЋЪЧЫќв§ШыСЫвЛжжКмЖрПЊЗЂШЫдБЫљВЛЪьЯЄЕФБрГЬЗчИёЃЌВЂЧвЮЇШЦзДЬЌжиНЈКЭЯћЯЂбЙЫѕЃЌЛсв§ШыЖюЭтЕФИДдгадЃЌеташвЊзЈУХЕФДцДЂЁЃ
аЭЌЪНЕФгХЕуКЭШБЕу
ВЛЙмЪЙгУФФжжЗНЪНРДМьЫїЪ§ОнБфИќЃЌаЭЌЪНЕФФЃЪНЖМНтёюСЫаДШыЃЌФмЙЛЪЕЯжЖРСЂЕФЗўЮёПЩРЉеЙадЃЌВЂЬсЩ§ЯЕЭГећЬхЕФЕЏадЁЃетжжЗНЪНЕФШБЕудкгкЃЌОіВпСїЪЧЗжЩЂЕФЃЌКмФбЗЂЯжШЋОжЕФЗжВМЪНзДЬЌЁЃвЊВщПДвЛИіЧыЧѓЕФзДЬЌашвЊВщбЏЖрИіЪ§ОндДЃЌетЖдгкЗўЮёЪ§СПжкЖрЕФГЁОАРДЫЕЪЧвЛИіЬєеНЁЃБэ
4 змНсСЫетжжЗНЪНЕФгХЕуКЭШБЕуЁЃ
Бэ 4ЃКаЭЌЪНЕФгХЕуКЭШБЕу
5
ВЂааЙмЕР
дкаЭЌЪНФЃЪНжаЃЌУЛгавЛИіжааФЛЏЕФЕиЗНПЩвдВщбЏЯЕЭГЕФзДЬЌЃЌЕЋЪЧЛсгавЛИіЗўЮёЕФађСаЃЌвдБугкдкЗжВМЪНЯЕЭГжаДЋВЅзДЬЌЁЃаЭЌЪНФЃЪНДДНЈСЫвЛИіДІРэЗўЮёЕФађСаЛЏЙмЕРЃЌЫљвдЮвУЧФмЙЛжЊЕРЕБвЛИіЯћЯЂЕНДяећИіЙ§ГЬЕФЬиЖЈВНжшЪБЃЌЫќПЯЖЈвбОЭЈЙ§СЫЧАУцЕФЫљгаВНжшЁЃШчЙћЮвУЧФмЙЛЗХЫЩетИіЯожЦЃЌдЪаэЖРСЂЕиДІРэетаЉВНжшЕФЛАЃЌЧщПігжЛсдѕбљФиЃПдкетжжГЁОАЯТЃЌЗўЮё
B дкДІРэвЛИіЧыЧѓЕФЪБКђЃЌИљБОВЛгУЙиаФЗўЮё A ЪЧЗёвбОДІРэЙ§ЫќЁЃ
дкВЂааЙмЕРЕФЗНЪНжаЃЌЮвУЧЛсЬэМгвЛИіТЗгЩЗўЮёЃЌИУЗўЮёНгЪеЧыЧѓЃЌВЂдквЛИіБОЕиЪТЮёжаЭЈЙ§ЯћЯЂДњРэНЋЧыЧѓзЊЗЂжСЗўЮё
A КЭЗўЮё BЁЃШчЭМ 10 ЫљЪОЃЌДгетИіВНжшПЊЪМЃЌСНИіЗўЮёПЩвдЖРСЂЁЂВЂааЕиДІРэЧыЧѓЁЃ
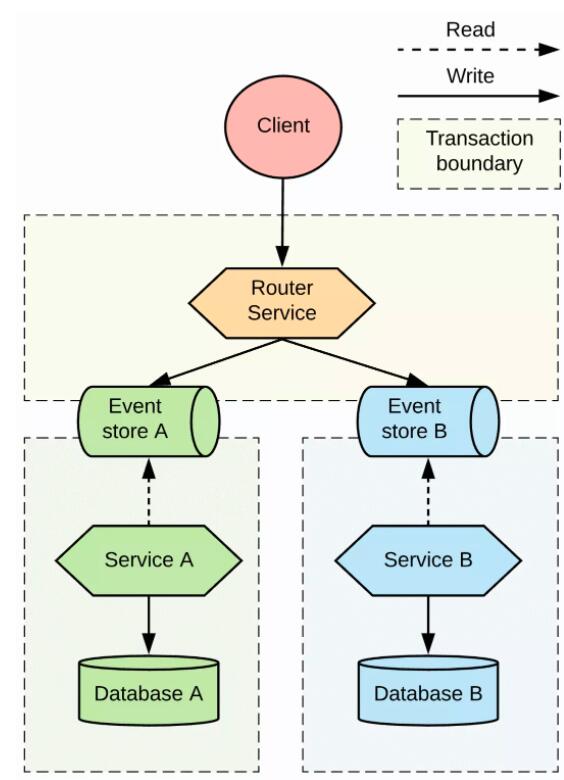
ЭЈЙ§ВЂааЙмЕРНјааДІРэ
ОЁЙметжжФЃЪНКмШнвзЪЕЯжЃЌЕЋЪЧЫќжЛЪЪгУгкЗўЮёжЎМфУЛгаЪБМфдМЪјЕФГЁОАЁЃР§ШчЃЌЗўЮё B ВЛЙмЗўЮё A ЪЧЗёвбОДІРэЙ§ИУЧыЧѓЃЌЫќЖМФмЙЛЖдЧыЧѓНјааДІРэЁЃЭЌЪБЃЌетжжЗНЪНашвЊвЛИіЖюЭтЕФТЗгЩЗўЮёЃЌЛђепПЭЛЇЖЫжЊЕРЗўЮё
A КЭЗўЮё BЃЌДгЖјФмЙЛИјЫќУЧЗЂЫЭЯћЯЂЁЃ
МрЬ§здЩэ
етжжЗНЪНгавЛжжЧсСПМЖЕФЬцДњЗНАИЃЌБЛГЦЮЊЁАМрЬ§здЩэЃЈlisten to yourselfЃЉЁБФЃЪНЃЌдкетРяЃЌЦфжагаИіЗўЮёЛсЭЌЪБЕЃШЮТЗгЩЁЃдкетжжЬцДњЗНЪНЯТЃЌЕБЗўЮё
A НгЪеЕНвЛИіЧыЧѓЪБЃЌЫќВЛЛсаДШыЕНздМКЕФЪ§ОнПтжаЃЌЖјЪЧНЋЧыЧѓЗЂЫЭжСЯћЯЂЯЕЭГжаЃЌЖјЯћЯЂЕФФПБъЪЧЗўЮё B
вдМАЗўЮё A БОЩэЁЃЭМ 11 ВћЪіСЫетжжФЃЪНЁЃ
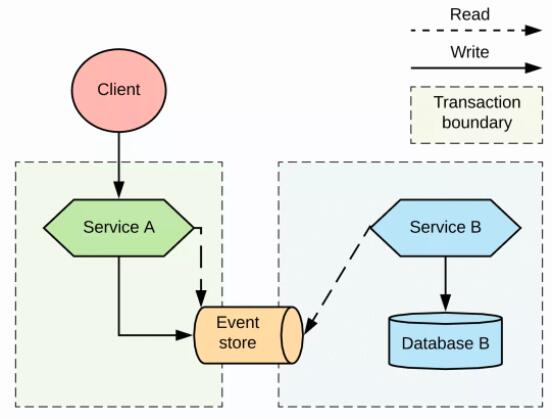
МрЬ§здЩэФЃЪН
дкетРяЃЌВЛаДШыЪ§ОнПтЕФдвђдкгкБмУтЫЋжиаДШыЁЃЕБНјШыЯћЯЂЯЕЭГжЎКѓЃЌЯћЯЂЛсдкЭъШЋЖРСЂЕФЪТЮёЩЯЯТЮФжаНјШыЗўЮё
BЃЌвВЛсжиаТЗЕЛиЗўЮё AЁЃЭЈЙ§етбљвЛИіЧњелЕФДІРэСїГЬЃЌЗўЮё A КЭЗўЮё B ОЭПЩвдЖРСЂЕиДІРэЧыЧѓЃЌВЂаДШыЕНИїздЕФЪ§ОнПтжаСЫЁЃ
ВЂааЙмЕРЕФгХЕуКЭШБЕу 
Бэ 5ЃКВЂааЙмЕРЕФгХЕуКЭШБЕу
6
ШчКЮбЁдёЗжВМЪНЪТЮёВпТд
ДгБОЮФЕФТлЪіжаЃЌФуПЩФмвбОВТЕНЃЌдкЮЂЗўЮёМмЙЙжаЃЌДІРэЗжВМЪНЪТЮёВЂУЛгае§ШЗЛђДэЮѓЕФФЃЪНЁЃУПжжФЃЪНЖМгаЦфгХЕуКЭШБЕуЁЃУПжжФЃЪНЖМФмНтОівЛаЉЮЪЬтЃЌЕЋЪЧЗДЙ§РДгжЛсВњЩњЦфЫћЕФЮЪЬтЁЃЭМ
12 жаЕФЭМБэМђЕЅзмНсСЫЮвЫљВћЪіЕФИїжжЫЋжиаДШыФЃЪНЕФжївЊЬиеїЁЃ
ЫЋжиаДШыФЃЪНЕФЬиеї
ВЛЙмФуВЩгУФФжжЗНЪНЃЌЖМвЊВћЪіКЭМЧТМОіВпБГКѓЕФЖЏЛњЃЌвдМАИУбЁдёдкМмЙЙЩЯЫљДјРДЕФГЄЦкгАЯьЁЃФуЛЙашвЊЕУЕНДгГЄЦкЪЕЯжКЭЮЌЛЄИУЯЕЭГЕФЭХЖгФЧРяЛёШЁжЇГжЁЃдкетРяЃЌЮвИљОнЪ§ОнвЛжТадКЭПЩРЉеЙадЬиеїРДзщжЏКЭЦРЙРБОЮФЫљУшЪіЕФИїжжЗНЗЈЃЌШчЭМ
13 ЫљЪОЁЃ
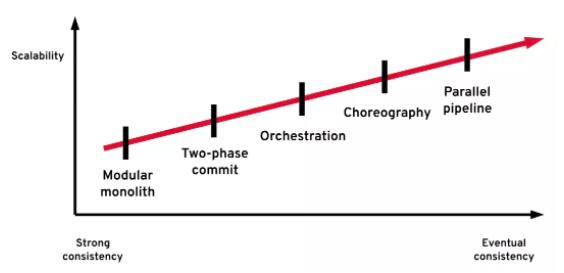
ИїИіЫЋжиаДШыФЃЪНЕФЪ§ОнвЛжТадКЭПЩРЉеЙадЬиеї
ЮвУЧДгПЩРЉеЙадзюЧПЁЂПЩгУадзюИпЕФЗНЗЈЕНПЩРЉеЙадзюВюЁЂПЩгУадзюЕЭЕФЫГађРДЦРЙРИїжжЗНЗЈЁЃ
ИпЃКВЂааЙмЕРКЭаЭЌЪН
ШчЙћФуЕФВНжшдкЪБМфЩЯЪЧНтёюЕФЃЌФЧУДВЩгУВЂааЙмЕРЕФЗНЗЈРДдЫааЪЧКмКЯЪЪЕФЁЃгаПЩФмФужЛФмдкЯЕЭГЕФФГаЉВПЗжЪЙгУетжжФЃЪНЃЌЖјВЛЪЧдкећИіЯЕЭГжаЁЃНгЯТРДЃЌМйЩшВНжшМфДцдкЪБМфЗНУцЕФёюКЯадЃЌЬиЖЈЕФВйзїКЭЗўЮёБиаывЊдкЦфЫћЕФЗўЮёЧАжДааЃЌФЧУДФуПЩвдПМТЧВЩгУаЭЌЪНЕФЗНЪНЁЃНшжњаЭЌЪНЕФЗўЮёЃЌЮвУЧПЩвдДДНЈвЛИіПЩРЉеЙЕФЁЂЪТМўЧ§ЖЏЕФМмЙЙЃЌдкетРяЯћЯЂЛсЭЈЙ§вЛИіШЅжааФЛЏЕФаЭЌЛЏЙ§ГЬдкЗўЮёКЭЗўЮёжЎМфСїЖЏЁЃдкетжжЧщПіЯТЃЌЪЙгУ
Debezium КЭ Apache Kafka ЕФЗЂМўЯфФЃЪНЪЕЯжЃЈШч Red Hat OpenShift
Streams for Apache KafkaЃЉЬиБ№гаШЄЃЌЖјЧвдНРДдНЪмЛЖг
жаЕШЃКБрХХЪНКЭСННзЖЮЬсНЛ
ШчЙћаЭЌЪНФЃЪНВЛЪЧКмКЯЪЪЃЌФуашвЊвЛИіИКд№аЕїКЭОіВпЕФжааФЕуЃЌФЧУДПЩвдПМТЧВЩгУБрХХЪНФЃЪНЁЃетЪЧвЛИіСїааЕФМмЙЙЃЌгаЛљгкБъзМЕФКЭздЖЈвхЕФПЊдДЪЕЯжЁЃЛљгкБъзМЕФЪЕЯжПЩФмЛсЧПЦШФуЪЙгУФГаЉЪТЮёгявхЃЌЖјздЖЈвхЕФБрХХЪНЪЕЯждђдЪаэФудкЫљашЕФЪ§ОнвЛжТадКЭПЩРЉеЙаджЎМфНјааШЈКтЁЃ
ЕЭЃКФЃПщЛЏЕЅЬх
ШчЙћФубизХЭМЪОдйЭљзѓзпЕФЛАЃЌФЧУДКмПЩФмФуЖдЪ§ОнвЛжТадгаЗЧГЃЧПСвЕФашЧѓЃЌЖјЧвЖдЫќЫљашЕФжиДѓШЈКтгаГфЗжЕФЫМЯызМБИЁЃдкетжжЧщПіЯТЃЌеыЖдЬиЖЈЪ§ОндДЃЌЭЈЙ§СННзЖЮЬсНЛЕФЗжВМЪНЪТЮёЪЧПЩааЕФЃЌЕЋЪЧдкзЈУХЮЊПЩРЉеЙадКЭИпЖШПЩгУадЩшМЦЕФЖЏЬЌдЦЛЗОГжаЃЌЫќКмФбПЩППЕиЪЕЯжЁЃШчЙћЪЧетбљЕФЛАЃЌФЧУДФуПЩвджБНгВЩгУБШНЯРЯЪНЕФФЃПщЛЏЕЅЬхЗНЪНЃЌЭЌЪБАщвдДгЮЂЗўЮёдЫЖЏжабЇЕНЕФЪЕМљЁЃетжжЗНЪНПЩвдШЗБЃзюИпЕФЪ§ОнвЛжТадЃЌЕЋДњМлЪЧдЫааЪБКЭЪ§ОндДЕФёюКЯЁЃ
7
НсТл
дкОпгаЪ§ЪЎИіЗўЮёЕФДѓаЭЗжВМЪНЯЕЭГжаЃЌВЂВЛЛсгавЛИіЪЪгУгкЫљгаГЁОАЕФЗНЪНЃЌЮвУЧашвЊНЋЦфжаЕФМИИіЗНЗЈНсКЯЦ№РДЃЌгІгУгкВЛЭЌЕФЛЗОГжаЁЃЮвУЧПЩФмЛсНЋМИИіЗўЮёВПЪ№дквЛИіЙВЯэЕФдЫааЪБЩЯЃЌвдТњзуЖдЪ§ОнвЛжТадЕФЬиЪташЧѓЁЃЮвУЧПЩФмЛсбЁдёСННзЖЮЕФЬсНЛРДгыжЇГж
JTA ЕФвХСєЯЕЭГНјааМЏГЩЁЃЮвУЧПЩФмЛсБрХХИДдгЕФвЕЮёСїГЬЃЌВЂШУЦфгрЕФЗўЮёЪЙгУаЭЌЪНФЃЪНКЭВЂааДІРэЁЃзмЖјбджЎЃЌФубЁдёЪВУДВпТдВЂВЛживЊЃЌживЊЕФЪЧЛљгке§ШЗЕФдвђЃЌОЋаФбЁдёвЛИіВпТдЃЌВЂжДааЫќЁЃ
|









