| БрМЭЦМі: |
БОЮФНЋЬжТлЮЂЗўЮёгы
DDD ЩцМАЕНЕФИХФюЁЂВпЛЎКЭЩшМЦЗНЗЈЃЌВЂЧвГЂЪдНЋвЛИіЕЅЬхгІгУВ№ЗжГЩЖрИіЛљгк DDD
ЕФЮЂЗўЮё ЁЃ
БОЮФРДздгкЙЋжкКХInfoQМмЙЙЭЗЬѕ ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
1
ЮЂЗўЮёЕФЖЈвх
ЮЂЗўЮёжаЕФЁАЮЂЁБЫфШЛБэЪОЗўЮёЕФЙцФЃЃЌЕЋЫќВЂВЛЪЧЪЙгІгУГЬађГЩЮЊЮЂЗўЮёЕФЮЈвЛБъзМЁЃЕБЭХЖгзЊЯђЛљгкЮЂЗўЮёЕФМмЙЙЪБЃЌЫћУЧЕФФПБъЪЧЬсИпУєНнадЃЌМДзджїЧвЦЕЗБЕиВПЪ№ЙІФмЁЃ
вђДЫЃЌКмФбИјЮЂЗўЮёМмЙЙЗчИёЯТвЛИіМђЕЅЕФЖЈвхЁЃЮвЯВЛЖ Adrian Cockcroft ЙигкЮЂЗўЮёЕФМђЖЬЖЈвхЃКЁАУцЯђЗўЮёЕФМмЙЙгЩОпгаНчЯоЩЯЯТЮФЁЂЫЩЩЂёюКЯЕФдЊЫизщГЩЁЃЁБ
ОЁЙметЖЈвхСЫвЛжжИпМЖЕФЩшМЦЦєЗЂЪНЗНЗЈЃЌЕЋЮЂЗўЮёМмЙЙОпгаЕФЬиадЃЌЪЙЦфгаБ№гквдЭљЕФУцЯђЗўЮёМмЙЙЁЃИљОнвдЭљЕФЮФеТЃЌЮвУЧзмНсСЫЮЂЗўЮёМмЙЙгІОпБИЕФвЛаЉЬиеїЃК
ЗўЮёвдвЕЮёЩЯЯТЮФЮЊжааФЖЈвхСЫСМКУЕФБпНчЃЌЖјВЛЪЧвдШЮвтЕФММЪѕГщЯѓЮЊжааФЃЛ
вўВиЪЕЯжЯИНкЃЌВЂЭЈЙ§втЭМНгПкБЉТЖЙІФмЃЛ
ЗўЮёВЛЛсЙВЯэГЌГіЦфБпНчЕФФкВПНсЙЙЃЌР§ШчВЛЙВЯэЪ§ОнПтЃЛ
ЗўЮёОпгаЙЪеЯПьЫйЛжИДФмСІЃЛ
ЭХЖгжАФмЖРСЂЃЌФмЙЛзджїЗЂВМБфИќЃЛ
ЭХЖггЕЛЄздЖЏЛЏЮФЛЏЃЌР§ШчздЖЏЛЏВтЪдЁЂГжајМЏГЩКЭГжајНЛИЖЁЃ
МђЖјбджЎЃЌЮвУЧПЩвдНЋетжжМмЙЙЗчИёзмНсШчЯТЃК
ЫЩЩЂёюКЯЕФУцЯђЗўЮёЕФМмЙЙЃЌЦфжаУПИіЗўЮёЖМЗтзАдкЖЈвхСМКУЕФНчЯоЩЯЯТЮФжаЃЌжЇГжгІгУГЬађПьЫйЁЂЦЕЗБЧвПЩППЕФНЛИЖЁЃ
2
СьгђЧ§ЖЏЩшМЦКЭНчЯоЩЯЯТЮФ
ЮЂЗўЮёЕФЧПДѓжЎДІдкгкЧхЮњЕиЖЈвхСЫЫќУЧЕФжАд№ВЂЛЎЖЈСЫЫќУЧжЎМфЕФБпНчЁЃЫќЕФФПЕФЪЧдкБпНчФкНЈСЂИпФкОлЃЌдкБпНчЭтНЈСЂЕЭёюКЯЁЃвВОЭЪЧЫЕЃЌЧуЯђгквЛЦ№ИФБфЕФЪТЮягІИУЗХдквЛЦ№ЁЃе§ШчЯжЪЕЩњЛюжаЕФаэЖрЮЪЬтвЛбљЃЌЕЋетЫЕЦ№РДШнвззіЦ№РДФбЃЌвЕЮёдкВЛЖЯЗЂеЙЃЌЩшЯывВЫцжЎИФБфЁЃвђДЫЃЌжиЙЙФмСІЪЧЩшМЦЯЕЭГЪБПМТЧЕФСэвЛЯюЙиМќЮЪЬтЁЃ
дкЮвУЧПДРДЃЌСьгђЧ§ЖЏЩшМЦ (DDD) ЪЧЙиМќЃЌЫќЪЧЩшМЦЮЂЗўЮёЪББиВЛПЩЩйЕФЙЄОпЃЌЮоТлЪЧЖдЕЅЬхгІгУНјааВ№ЗжЛЙЪЧДгЭЗПЊЪМЙЙНЈвЛИіаТЯюФПЁЃСьгђЧ§ЖЏЩшМЦвђ
Eric Evans ЕФжјзїЖјГіУћЃЌЫќЪЧвЛзщЫМЯыЁЂддђКЭФЃЪНЃЌПЩвдАяжњЮвУЧЛљгквЕЮёСьгђЕФЕзВуФЃаЭЩшМЦШэМўЯЕЭГЁЃПЊЗЂШЫдБКЭСьгђзЈМввЛЦ№ЪЙгУЭГвЛЕФЭЈгУгябдДДНЈвЕЮёФЃаЭЁЃШЛКѓНЋетаЉФЃаЭАѓЖЈЕНгавтвхЕФЯЕЭГЩЯЃЌдкетаЉЯЕЭГКЭДІРэетаЉЗўЮёЕФЭХЖгжЎМфНЈСЂазїавщЁЃИќживЊЕФЪЧЃЌЫќУЧЩшМЦСЫЯЕЭГжЎМфЕФИХФюТжРЊЛђБпНчЁЃ
ЮЂЗўЮёЩшМЦДгетаЉИХФюжаМГШЁСЫСщИаЃЌвђЮЊЫљгаетаЉдРэЖМгажњгкЙЙНЈПЩвдЖРСЂБфИќКЭЗЂеЙЕФФЃПщЛЏЯЕЭГЁЃ
дкМЬајЩюШыжЎЧАЃЌШУЮвУЧПьЫйфЏРРвЛЯТ DDD ЕФвЛаЉЛљБОЪѕгяЁЃЖдСьгђЧ§ЖЏЩшМЦЕФЭъећИХЪіВЛдкБОЮФЕФЬжТлЗЖЮЇжЎФкЁЃ
СьгђЃЈDomainЃЉЃК ДњБэзщжЏЫљзіЕФЙЄзїЁЃР§ШчСуЪлЛђЕчзгЩЬЮёЁЃ
зггђЃЈSubdomainЃЉЃК зщжЏЛђзщжЏФкЕФвЕЮёВПУХЁЃвЛИіСьгђгЩЖрИізггђзщГЩЁЃ
ЭГвЛгябдЃЈUbiquitous languageЃЉЃКетЪЧгУгкБэДяФЃаЭЕФгябдЁЃдкЯТУцЕФР§згжаЃЈЭМ 1ЃЉЃЌItem
ЪЧвЛИіФЃаЭЃЌЫќЪЧУПИізггђЕФЭГвЛгябдЁЃПЊЗЂШЫдБЁЂВњЦЗОРэЁЂСьгђзЈМвКЭвЕЮёИїЩцжкЗНЖМФмОЭЪЙгУетжжгябдДяГЩвЛжТЃЌВЂдкЫћУЧЕФЙЄМўЃЈДњТыЁЂВњЦЗЮФЕЕЕШЃЉжаЪЙгУИУгябдЁЃ
ЭМ 1ЃКЕчзгЩЬЮёСьгђжаЕФзггђКЭНчЯоЩЯЯТЮФ
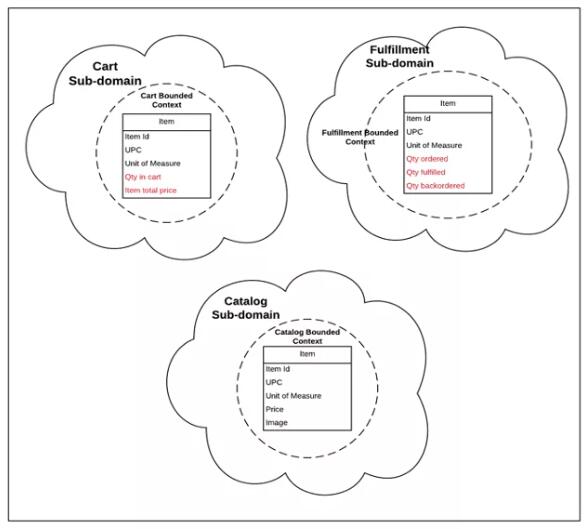
НчЯоЩЯЯТЮФЃЈBounded ContextsЃЉЃКСьгђЧ§ЖЏЩшМЦНЋНчЯоЩЯЯТЮФЖЈвхЮЊЁАвЛИіЕЅДЪЛђгяОфГіЯжЪБШЗЖЈЦфКЌвхЕФЩшжУЁБЁЃМђЖјбджЎЃЌетвтЮЖзХФЃаЭдкБпНчФкЪЧгаКЌвхЕФЁЃдкЩЯУцЕФР§згжаЃЈЭМ
1ЃЉЃЌЁАItemЁБдкУПИіЩЯЯТЮФжаЖМгаВЛЭЌЕФКЌвхЁЃдк Catalog ЩЯЯТЮФжаЃЌItem БэЪОПЩГіЪлЕФВњЦЗЃЌЖјдк
Cart ЩЯЯТЮФжаЃЌЫќБэЪОПЭЛЇвбЬэМгЕНЙКЮяГЕжаЕФЩЬЦЗбЁЯюЁЃдк Fulfillment ЩЯЯТЮФжаЃЌЫќБэЪОНЋвЊдЫЫЭИјПЭЛЇЕФВжПтЮяСЯЁЃетаЉФЃаЭИїВЛЯрЭЌЃЌУПИіФЃаЭЖМгаВЛЭЌЕФКЌвхЃЌВЂЧвПЩФмАќКЌВЛЭЌЕФЪєадЁЃЭЈЙ§НЋетаЉФЃаЭЗжРыВЂНЋЦфИєРыдкИїздЕФБпНчФкЃЌЮвУЧОЭПЩвдздгЩЕиБэДяетаЉФЃаЭЃЌЖјВЛЛсВњЩњЦчвхЁЃ
зЂвтЃК БиаыРэНтзггђКЭНчЯоЩЯЯТЮФжЎМфЕФЧјБ№ЁЃзггђЪєгкЮЪЬтПеМфЃЌМДЮвУЧЕФвЕЮёвЊШчКЮПДД§ЮЪЬтЃЌЖјНчЯоЩЯЯТЮФЪєгкНтОіЗНАИПеМфЃЌМДЮвУЧНЋШчКЮЪЕЪЉЮЪЬтЕФНтОіЗНАИЁЃРэТлЩЯЃЌУПИізггђПЩФмгаЖрИіНчЯоЩЯЯТЮФЃЌОЁЙмЮвУЧХЌСІУПИізггђжЛЬсЙЉвЛИіНчЯоЩЯЯТЮФЁЃ
3
ЮЂЗўЮёКЭНчЯоЩЯЯТЮФШчКЮЙиСЊ
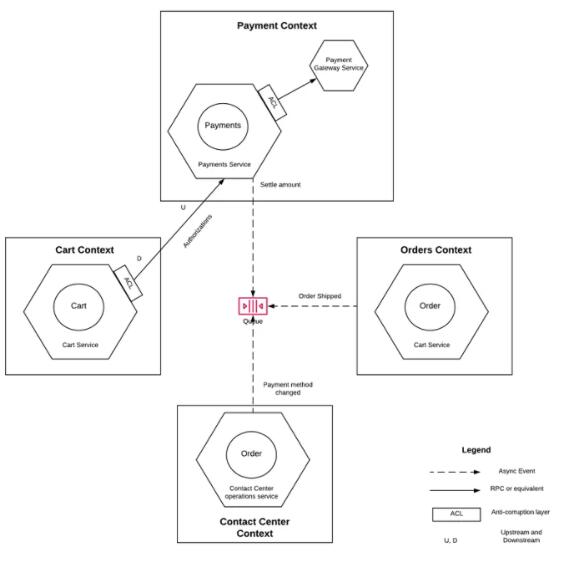
ЯждкЃЌЮЂЗўЮёЪЪгУгкФФаЉЕиЗНЃПУПИіНчЯоЩЯЯТЮФЖМФмгГЩфЕНЖдгІЕФЮЂЗўЮёТ№ЃПВЛвЛЖЈЁЃЮвУЧРДПДПДдвђЁЃдкФГаЉЧщПіЯТЃЌНчЯоЩЯЯТЮФЕФБпНчЛђТжРЊПЩФмЛсЗЧГЃДѓЁЃ
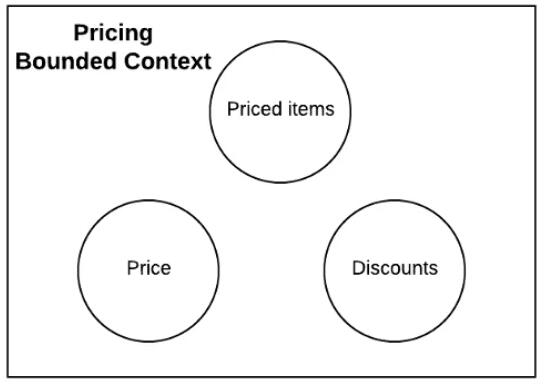
ЭМ 2ЃКНчЯоЩЯЯТЮФКЭЮЂЗўЮё
ПМТЧЩЯУцЕФР§згЁЃЖЈМлНчЯоЩЯЯТЮФгаШ§ИіВЛЭЌЕФФЃаЭЃКМлИёЃЈPriceЃЉЁЂЖЈМлЯюЃЈPriced items)
КЭелПлЃЈDiscountsЃЉЃЌЗжБ№ИКд№ФПТМЯюЕФМлИёЁЂМЦЫуСаБэЯюЕФзмМлвдМАИїздЪЙгУЕФелПлЁЃЮвУЧПЩвдДДНЈвЛИіАќКЌЩЯЪіЫљгаФЃаЭЕФЕЅвЛЯЕЭГЃЌЕЋЫќПЩФмЪЧвЛИіВЛКЯРэЕФДѓаЭгІгУГЬађЁЃШчЧАЫљЪіЃЌУПИіЪ§ОнФЃаЭЖМгаЦфВЛБфадКЭвЕЮёЙцдђЁЃЫцзХЪБМфЕФЭЦвЦЃЌШчЙћЮвУЧВЛаЁаФЕФЛАЃЌетИіЯЕЭГОЭПЩФмЛсБфГЩвЛИіДѓФрЧђЃЌНчЯоФЃК§ЃЌжАд№жиЕўЃЌЩѕжСКмПЩФмЛсЛиЕНЮвУЧПЊЪМЕФЕиЗНЁЊЁЊЕЅЬхгІгУЁЃ
ЖдетИіЯЕЭГНЈФЃЕФСэвЛжжЗНЗЈЪЧНЋЯрЙиФЃаЭЗжРыЛђЗжзщЕНЕЅЖРЕФЮЂЗўЮёжаЁЃдк DDD жаЃЌетаЉФЃаЭЃЈМлИёЁЂЖЈМлЯюКЭелПлЃЉБЛГЦЮЊОлКЯЃЈAggregatesЃЉЁЃОлКЯЪЧгЩЯрЙиФЃаЭзщГЩЕФздАќКЌФЃаЭЁЃЮвУЧжЛФмЭЈЙ§вбЗЂВМЕФНгПкРДБфИќОлКЯЕФзДЬЌЃЌВЂЧвОлКЯПЩвдШЗБЃвЛжТадЃЌЖјЧвВЛБфСППЩвдЪМжеБЃГжСМКУзДЬЌЁЃ
дкаЮЪНЩЯЃЌОлКЯЪЧЙиСЊЖдЯѓЕФМЏШКЃЌБЛЪгЮЊЪ§ОнБфИќЕФЕЅдЊЁЃЭтВПв§гУНіЯогкжИЖЈОлКЯЕФвЛИіГЩдБЃЌМДОлКЯИљЁЃдкОлКЯЕФБпНчФкашгІгУвЛзщвЛжТадЙцдђЁЃ
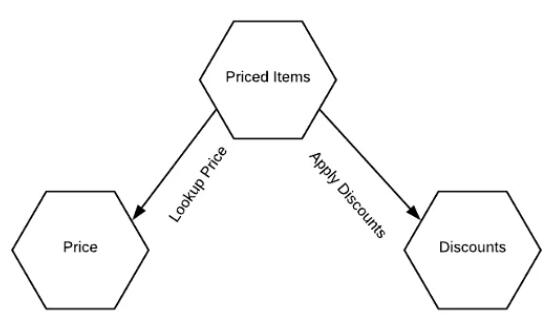
ЭМ 3ЃКЖЈМлЩЯЯТЮФжаЕФЮЂЗўЮё
ЭЌбљЃЌУЛгаБивЊНЋУПИіОлКЯЖМНЈФЃЮЊвЛИіВЛЭЌЕФЮЂЗўЮёЁЃЪТЪЕжЄУїЃЌЭМ 3 жаЕФЗўЮёЃЈОлКЯЃЉОЭЪЧШчДЫЃЌЕЋетВЛвЛЖЈЪЧвЛИіЙцдђЁЃдкФГаЉЧщПіЯТЃЌдкЕЅИіЗўЮёжаЭаЙмЖрИіОлКЯПЩФмЪЧгавтвхЕФЃЌЬиБ№ЪЧдкЮвУЧВЛЭъШЋСЫНтвЕЮёСьгђЕФЧщПіЯТЁЃашвЊзЂвтЕФвЛЕуЪЧЃЌвЛжТаджЛдкЕЅИіОлКЯжаВХФмЕУЕНБЃжЄЃЌВЂЧвОлКЯжЛФмЭЈЙ§вбЗЂВМЕФНгПкНјаааоИФЁЃШЮКЮЮЅЗДетаЉЙцдђЕФааЮЊЖМгадіМггІгУГЬађБфГЩвЛИіДѓФрЧђЕФЗчЯеЁЃ
4
ЩЯЯТЮФгГЩфЃКвЛжжОЋШЗЛЎЗжЮЂЗўЮёБпНчЕФЗНЗЈ
СэвЛИіЛљБОЙЄОпЪЧЩЯЯТЮФгГЩфЃЌЭЌбљЃЌЫќвВЪЧРДздСьгђЧ§ЖЏЩшМЦЁЃвЛИіЕЅЬхгІгУЭЈГЃгЩВЛЭЌЕФФЃаЭзщГЩЃЌетаЉФЃаЭДѓЖрЪЧНєУмёюКЯЕФЃЌФЃаЭжЎМфПЩФмжЊЕРБЫДЫЕФЪЕЯжЯИНкЃЌБфИќвЛИіФЃаЭПЩФмдьГЩСэвЛИіФЃаЭЕФИБзїгУЕШЕШЁЃЕБФуЗжНтЕЅЬхгІгУЪБЃЌШЗЖЈетаЉФЃаЭЃЈдкетРяЪЧОлКЯЃЉМАЦфЙиЯЕЪЧжСЙиживЊЕФЁЃЩЯЯТЮФгГЩфПЩвдАяжњЮвУЧзіЕНетвЛЕуЁЃЫќУЧгУгкЪЖБ№КЭЖЈвхИїжжНчЯоЩЯЯТЮФКЭОлКЯжЎМфЕФЙиЯЕЁЃдкЩЯУцЕФР§згжаЃЌНчЯоЩЯЯТЮФЖЈвхСЫФЃаЭЕФБпНчЃЈМлИёЁЂелПлЕШЕШЃЉЁЃЖјЩЯЯТЮФгГЩфЖЈвхСЫетаЉФЃаЭжЎМфвдМАВЛЭЌЩЯЯТЮФжЎМфЕФЙиЯЕЁЃдкШЗЖЈСЫетаЉвРРЕЙиЯЕжЎКѓЃЌЮвУЧОЭПЩвдШЗЖЈЯТРДЪЕЯжетаЉЗўЮёЕФЭХЖгжЎМфЕФе§ШЗазїФЃаЭСЫЁЃ
ЖдЩЯЯТЮФгГЩфЕФЭъећЬНЫїВЛдкБОЮФЕФЬжТлЗЖЮЇжЎФкЃЌЕЋЮвУЧНЋгУвЛИіЪОР§РДЫЕУїЁЃЯТЭМЯдЪОСЫДІРэЕчзгЩЬЮёЖЉЕЅжЇИЖЕФИїжжгІгУГЬађЁЃ
ЙКЮяГЕЩЯЯТЮФИКд№ЖЉЕЅЕФдкЯпЪкШЈЃЛЖЉЕЅЩЯЯТЮФДІРэЖЉЕЅТФааЭъГЩКѓЕФжЇИЖСїГЬЃЌШчНсЫуЃЛСЊТчжааФДІРэШЮКЮвьГЃЧщПіЃЌШчжЇИЖжиЪдКЭБфИќЖЉЕЅЪЙгУЕФжЇИЖЗНЪНЁЃЮЊСЫМђЕЅЦ№МћЃЌЮвУЧМйЩшЫљгаетаЉЩЯЯТЮФЖМЪЧзїЮЊЕЅЖРЕФЗўЮёЪЕЯжЕФЃЌЫљгаетаЉЩЯЯТЮФЗтзАСЫЭЌвЛИіФЃаЭЁЃЧызЂвтЃЌетаЉФЃаЭдкТпМЩЯЪЧЯрЭЌЕФЁЃвВОЭЪЧЫЕЃЌЫќУЧЖМзёбЯрЭЌЕФЭГвЛСьгђгябдЁЊЁЊжЇИЖЗНЪНЁЂЪкШЈКЭНсЫуЁЃжЛЪЧЫќУЧЪЧВЛЭЌЩЯЯТЮФЕФвЛВПЗжЁЃ
СэвЛИіМЃЯѓБэУїЃЌЭЌвЛИіФЃаЭдкВЛЭЌЕФЩЯЯТЮФжаДЋВЅЃЌЫљгаетаЉФЃаЭЖМжБНггыЕЅИіжЇИЖЭјЙиЯрМЏГЩЃЌВЂЧвБЫДЫжДааЯрЭЌЕФВйзїЁЃ
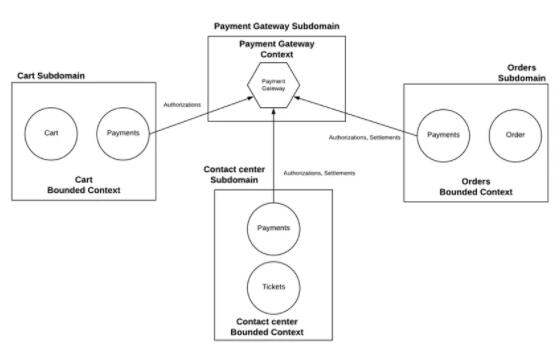
ЭМ 4ЃКЖЈвхДэЮѓЕФЩЯЯТЮФгГЩф
5
жиаТЖЈвхЗўЮёБпНчЃКНЋОлКЯгГЩфЕНе§ШЗЕФЩЯЯТЮФ
дкЩЯУцЕФЩшМЦжагавЛаЉЗЧГЃУїЯдЕФЮЪЬтЃЈЭМ 4ЃЉЁЃжЇИЖОлКЯЪЧЖрИіЩЯЯТЮФЕФвЛВПЗжЁЃдкИїжжЗўЮёжЎМфЧПжЦжДааВЛБфадКЭвЛжТадЪЧВЛПЩФмЕФЃЌИќВЛгУЫЕетаЉЗўЮёжЎМфЕФВЂЗЂЮЪЬтСЫЁЃР§ШчЃЌШчЙћдкЖЉЕЅЗўЮёГЂЪдАДжЎЧАЬсНЛЕФИЖПюЗНЪННјааНсЫуЕФЙ§ГЬжаЃЌСЊТчжааФИќИФСЫгыЖЉЕЅЙиСЊЕФИЖПюЗНЪНЛсЗЂЩњЪВУДЧщПіЁЃСэЭтЃЌЧызЂвтЃЌжЇИЖЭјЙижаЕФШЮКЮИќИФЖМНЋЦШЪЙЖдЖрИіЗўЮёНјааИќИФЃЌПЩФмЛсЩцМАЕНЖрИіЭХЖгЃЌвђЮЊЫќУЧЙВЭЌгЕгаетаЉЩЯЯТЮФЁЃ
ЭЈЙ§вЛаЉЕїећВЂНЋОлКЯгые§ШЗЕФЩЯЯТЮФЖдЦыЃЌЮвУЧОЭПЩвдИќКУЕиБэЪОетаЉзггђСЫЃЈЭМ 5ЃЉЁЃашвЊНјааКмЖрЕФИќИФЁЃ
ЮвУЧРДПДЯТИќИФЕФЕуЃК
жЇИЖОлКЯгаСЫвЛИіаТМвЁЊЁЊжЇИЖЗўЮёЁЃИУЗўЮёЛЙДгЦфЫћашвЊжЇИЖЗўЮёЕФЗўЮёжаЬсШЁСЫжЇИЖЭјЙиЁЃгЩгкЕЅИіНчЯоЩЯЯТЮФЯждкгЕгаСЫЕЅИіОлКЯЃЌЫљвдВЛБфСПКмШнвзЙмРэЃЛЫљгаЪТЮёЖМдкЭЌвЛИіЗўЮёЕФБпНчФкНјааЃЌДгЖјБмУтСЫШЮКЮВЂЗЂЮЪЬтЁЃ
жЇИЖОлКЯЪЙгУСЫЗДИЏВуЃЈACLЃЉНЋКЫаФСьгђФЃаЭгыжЇИЖЭјЙиЕФЪ§ОнФЃаЭИєРыПЊРДЃЌКѓепЭЈГЃЪЧгЩЕкШ§ЗНЬсЙЉЕФЃЌПЩФмЛсЗЂЩњБфЛЏЁЃдквдКѓЕФЮФеТжаЃЌЮвУЧНЋЩюШыбаОПЛљгкЁАЖЫПкКЭЪЪХфЦїЁБФЃЪНЕФгІгУГЬађЩшМЦЁЃACL
ВуЭЈГЃАќКЌНЋжЇИЖЭјЙиЕФЪ§ОнФЃаЭзЊЛЛЮЊжЇИЖОлКЯЪ§ОнФЃаЭЕФЪЪХфЦїЁЃ
ЙКЮяГЕЗўЮёЭЈЙ§жБНгЕїгУ API ЕФЗНЪНРДЕїгУжЇИЖЗўЮёЃЌвђЮЊЕБПЭЛЇдкЭјеОЩЯЙКЮяЪБЃЌЙКЮяГЕЗўЮёашвЊЭъГЩжЇИЖЪкШЈЁЃ
МЧТМЖЉЕЅКЭжЇИЖЗўЮёжЎМфЕФНЛЛЅзїгУЁЃЖЉЕЅЗўЮёЗЂГівЛИігђЪТМўЃЈЩдКѓЛсдкБОЮФжаЖдДЫНјааЯъЯИНщЩмЃЉЁЃжЇИЖЗўЮёМрЬ§ДЫЪТМўВЂЭъГЩЖЉЕЅЕФНсЫу
СЊТчжааФЗўЮёПЩФмгааэЖрОлКЯЃЌЕЋЮвУЧжЛЖдИУгУР§жаЕФЖЉЕЅОлКЯИааЫШЄЁЃЕБИќИФИЖПюЗНЪНЪБЃЌДЫЗўЮёЗЂГівЛИіЪТМўЃЌжЇИЖЗўЮёНЋЭЈЙ§вдЯТЗНЪНЖдДЫЪТМўзіГіЯьгІЃКНЋЯШЧАЪЙгУЕФаХгУПЈГЗЯњЃЌдйДІРэаТЕФаХгУПЈЁЃ
ЭМ 5ЃКжиаТЖЈвхЕФЩЯЯТЮФгГЩф
ЭЈГЃЃЌЕЅЬхЛђвХСєгІгУГЬађгааэЖрОлКЯЃЌЧвБпНчжиЕўЁЃДДНЈетаЉОлКЯМАЦфвРРЕЙиЯЕЕФЩЯЯТЮФгГЩфЃЌНЋгажњгкЮвУЧРэНтДгетаЉЕЅЬхгІгУжаЛёШЁШЮКЮаТЮЂЗўЮёЕФТжРЊЁЃЧыМЧзЁЃЌЮЂЗўЮёМмЙЙЕФГЩАмШЁОігкОлКЯжЎМфЕФЕЭёюКЯвдМАОлКЯжЎФкЕФИпФкОлЁЃ
ЛЙашвЊзЂвтЕФЪЧЃЌНчЯоЩЯЯТЮФБОЩэОЭЪЧКЯЪЪЕФФкОлЕЅдЊЁЃМДЪЙЩЯЯТЮФгаЖрИіОлКЯЃЌвВПЩвдНЋећИіЩЯЯТЮФМАЦфОлКЯзщГЩЕЅИіЮЂЗўЮёЁЃЮвУЧЗЂЯжетжжЦєЗЂЪНЗНЗЈЖдгкгааЉФЃК§ЕФСьгђЬиБ№гагУЃЌБШШчзщжЏе§дкЩцзуЕФаТвЕЮёСьгђЁЃЮвУЧПЩФмЖдЗжРыЕФе§ШЗБпНчУЛгазуЙЛЕФСЫНтЃЌВЂЧвШЮКЮЙ§дчЕФОлКЯЗжНтЖМПЩФмЕМжТАКЙѓЕФжиЙЙЁЃЪдЯывЛЯТЃЌгЩгкЪ§ОнЧЈвЦЃЌВЛЕУВЛНЋСНИіЪ§ОнПтКЯВЂЮЊвЛИіЃЌвђЮЊЮвУЧХМШЛЗЂЯжСНИіОлКЯЪєгкЭЌвЛРрЁЃЕЋЪЧвЊШЗБЃетаЉОлКЯЭЈЙ§НгПкЪЧГфЗжИєРыЕФЃЌетбљЫќУЧОЭВЛжЊЕРБЫДЫЕФИДдгЯИНкСЫЁЃ
6
ЪТМўЗчБЉЃКСэвЛжжЪЖБ№ЗўЮёБпНчЕФММЪѕ
ЪТМўЗчБЉЃЈEvent StormingЃЉЪЧЪЖБ№ЯЕЭГжаОлКЯЃЈвдМАЮЂЗўЮёЃЉЕФСэвЛжжБиВЛПЩЩйЕФММЪѕЁЃЫќЪЧвЛИіЗЧГЃгагУЕФЙЄОпЃЌМШПЩгУгкЗжНтЕЅЬхгІгУЃЌвВПЩгУгкЩшМЦИДдгЕФЮЂЗўЮёЩњЬЌЯЕЭГЁЃЮвУЧвбОЪЙгУетжжММЪѕЗжНтСЫвЛИіИДдгЕФгІгУГЬађЃЌВЂДђЫуаДвЛЦЊЕЅЖРЕФЮФеТРДНщЩмЮвУЧЕФЪТМўЗчБЉОбщЁЃдкБОЮФжаЃЌЮвУЧжЛИјГівЛИіПьЫйЕФИпВуИХЪіЁЃ
МђЖјбджЎЃЌЪТМўЗчБЉЪЧдкгІгУГЬађЭХЖгЃЈетРяЃЌжИЕЅЬхЃЉжаНјааЕФЭЗФдЗчБЉЃЌвдЪЖБ№ЯЕЭГжаЗЂЩњЕФИїжжСьгђЪТМўКЭСїГЬЁЃЭХЖгЛЙашШЗЖЈетаЉЪТМўгАЯьЕФзмКЭЛђФЃаЭЃЌвдМАгЩДЫВњЩњЕФШЮКЮКѓајгАЯьЁЃЕБЭХЖгзіетИіЭЗФдЗчБЉЪБЃЌЫћУЧНЋЪЖБ№ВЛЭЌЕФжиЕўИХФюЁЂФЃРтСНПЩЕФСьгђгябдКЭЯрЛЅГхЭЛЕФвЕЮёСїГЬЁЃЫћУЧЖдЯрЙиЕФФЃаЭНјааЗжзщЃЌжиаТЖЈвхОлКЯВЂЪЖБ№жиИДЕФСїГЬЁЃЫцзХетаЉЙЄзїЕФНјааЃЌетаЉОлКЯЫљЪєЕФНчЯоЩЯЯТЮФБфЕУЧхЮњЦ№РДЁЃШчЙћЫљгаЭХЖгЖМдкЭЌвЛИіЗПМфЃЈЮяРэЛђащФтЃЉРяЃЌВЂПЊЪМдк
Scrum ЗчИёЕФАзАхЩЯЛцжЦЪТМўЁЂУќСюКЭСїГЬЕФгГЩфЃЌФЧУДЪТМўЗчБЉбаЬжОЭЛсЗЧГЃгагУЁЃдкБОСЗЯАНсЪјЪБЃЌЭЈГЃЛсВњГіШчЯТГЩЙћЃК
жиаТЖЈвхЕФОлКЯСаБэЁЃетаЉПЩФмЛсГЩЮЊаТЕФЮЂЗўЮё
ашвЊдкетаЉЮЂЗўЮёжЎМфСїЖЏЕФСьгђЪТМў
ЦфЫћгІгУГЬађЛђгУЛЇжБНгЕїгУЕФУќСю
ЯТУцЪЧЮвУЧдквЛДЮЪТМўЗчБЉбаЬжЛсНсЪјЪБВњЩњЕФвЛИіЪОР§бљАхЁЃЖдгкЭХЖгРДЫЕЃЌОЭе§ШЗЕФОлКЯКЭНчЯоЩЯЯТЮФДяГЩвЛжТЪЧвЛДЮКмАєЕФазїЛюЖЏЁЃДЫЭтЃЌЭХЖгдкБОДЮЛсвщНсЪјЪБЛЙЖдСьгђЁЂЭГвЛгябдКЭОЋШЗЕФЗўЮёБпНчгазХЙВЭЌЕФРэНтЁЃ
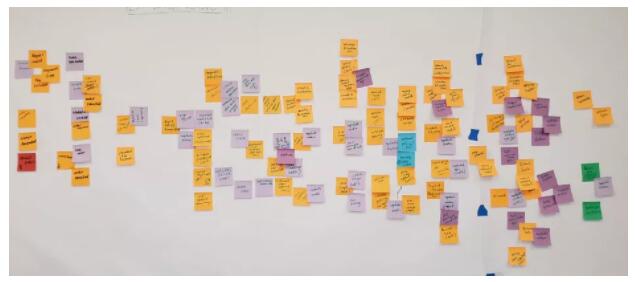
ЭМ 6ЃКЪТМўЗчБЉАх
7
ЮЂЗўЮёжЎМфЕФЭЈаХ
ПьЫйЛиЙЫвЛЯТЃЌвЛИіЕЅЬхгІгУдкЕЅИіСїГЬБпНчФкгЕгаЖрИіОлКЯЁЃвђДЫЃЌПЩвддкетИіБпНчФкЙмРэИїИіОлКЯЕФвЛжТадЁЃР§ШчЃЌШчЙћПЭЛЇЯТСЫЖЉЕЅЃЌЮвУЧПЩвдМѕЩйЩЬЦЗПтДцЃЌВЂЯђПЭЛЇЗЂЫЭЕчзггЪМўЃЌЫљгаетаЉЖМдквЛИіЪТЮёжаЭъГЩЁЃЫљгаВйзївЊУДЖМГЩЙІЃЌвЊУДЖМЛсЪЇАмЁЃЕЋЪЧЃЌЕБЮвУЧЗжНтСЫЕЅЬхВЂНЋОлКЯЗжЩЂЕНВЛЭЌЕФЩЯЯТЮФжаЪБЃЌЮвУЧНЋгЕгаЪ§ЪЎИіЩѕжСЪ§АйИіЮЂЗўЮёЁЃЕЋФПЧАЮЊжЙЃЌДцдкгкЕЅЬхгІгУЕЅвЛБпНчФкЕФСїГЬЃЌЯждкБЛЗжЩЂЕНСЫЖрИіЗжВМЪНЯЕЭГжаЁЃвЊдкЫљгаетаЉЗжВМЪНЯЕЭГжаЪЕЯжЪТЮёЕФЭъећадКЭвЛжТадЪЧЗЧГЃРЇФбЕФЃЌЖјЧввЊвдЯЕЭГЕФПЩгУадЮЊДњМлЁЃ
ЮЂЗўЮёвВЪЧЗжВМЪНЯЕЭГЁЃвђДЫЃЌCAP ЖЈРэвВЪЪгУгкЫќУЧЃКЁАвЛИіЗжВМЪНЯЕЭГжЛФмЬсЙЉШ§ИіЫљашЬиаджаЕФСНИіЃКвЛжТадЁЂПЩгУадКЭЗжЧјШнДэЃЈCAP
жаЕФЁЎCЁЏЁЊЁЊConsistencyЁЂЁЎAЁЏЁЊЁЊAvailability КЭ ЁЎPЁЏЁЊЁЊPartition
ToleranceЃЉЁЃЁБдкЯжЪЕЪРНчЕФЯЕЭГжаЃЌЗжЧјШнДэЪЧВЛПЩаЩЬЕФЁЊЁЊЭјТчЪЧВЛПЩППЕФЁЂащФтЛњПЩвдхДЛњЁЂЧјгђжЎМфЕФбгГйПЩФмЛсБфЕУИќдуЕШЕШЁЃ
вђДЫЃЌЮвУЧПЩвдбЁдёЁАПЩгУадЁБЛђЁАвЛжТадЁБЁЃЯждкЃЌЮвУЧжЊЕРЃЌдкШЮКЮЯжДњгІгУГЬађжаЃЌЮўЩќЁАПЩгУадЁБвВВЛЪЧвЛИіКУжївтЁЃ
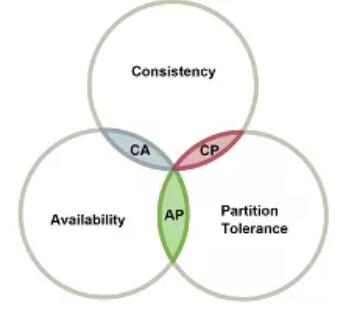
ЭМ 7ЃКCAP ЖЈРэ
8
ЮЇШЦзюжевЛжТадЩшМЦгІгУГЬађ
ШчЙћЮвУЧЯывЊПчЖрИіЗжВМЪНЯЕЭГЙЙНЈЪТЮёЃЌФЧУДЮвУЧНЋдйДЮЯнШыЕЅЬхгІгУЕФРЇОГЁЃЕЋетвЛДЮЫќЛсЪЧзюдуИтЕФвЛжжЕЅЬхЃКвЛИіЗжЩЂЕФЕЅЬхгІгУЁЃШчЙћетаЉЯЕЭГжаЕФШЮКЮвЛИіБфЕУВЛПЩгУЃЌдђећИіСїГЬВЛПЩгУЃЌЭЈГЃЛсЕМжТМЋВюЕФПЭЛЇЬхбщЁЂГаХЕЕФЪЇАмЕШЕШЁЃДЫЭтЃЌЖдвЛИіЗўЮёЕФБфИќЭЈГЃЛсЕМжТСэвЛИіЗўЮёЕФБфИќЃЌДгЖјв§Ц№ИДдгКЭАКЙѓЕФВПЪ№ЁЃвђДЫЃЌЮвУЧзюКУИљОнздМКЕФгУР§РДЩшМЦгІгУГЬађЃЌШнШЬЩдЮЂЕФВЛвЛжТЃЌвдЬсИпПЩгУадЁЃЖдгкЩЯУцЕФР§згЃЌЮвУЧПЩвдЪЙЫљгаСїГЬвьВНЃЌДгЖјДяЕНзюжеЕФвЛжТадЁЃЮвУЧПЩвдЖРСЂгкЦфЫћСїГЬЃЌвьВНЗЂЫЭЕчзггЪМўЃЛШчЙћвбОГаХЕЕФЩЬЦЗвдКѓдкВжПтжаВЛПЩгУЃЌФЧУДИУЩЬЦЗПЩФмашвЊВЙЛѕЃЌЛђепЮвУЧПЩвдЭЃжЙНгЪмГЌГіФГИіуажЕЕФИУЩЬЦЗЕФЖЉЕЅЁЃ
гаЪБЃЌЮвУЧПЩФмЛсгіЕНетбљЕФГЁОАЃКПЩФмашвЊПчдНВЛЭЌСїГЬБпНчЕФСНИіОлКЯЕФЧП ACID ЪНЕФЪТЮёЁЃетЪЧвЛИіжиаТЩѓЪгетаЉОлКЯВЂНЋЫќУЧзщКЯГЩвЛИіОлКЯЕФМЋКУМЃЯѓЁЃПЊЪМдкВЛЭЌСїГЬБпНчжаЗжНтетаЉОлКЯжЎЧАЃЌЪТМўЗчБЉКЭЩЯЯТЮФгГЩфНЋгажњгкЮвУЧМАдчЪЖБ№етаЉвРРЕЙиЯЕЁЃНЋСНИіЮЂЗўЮёКЯВЂЮЊвЛИіЕФГЩБОКмИпЃЌетЪЧЮвУЧгІИУХЌСІБмУтЕФЁЃ
9
жЇГжЪТМўЧ§ЖЏЕФМмЙЙ
ЮЂЗўЮёПЩвдНЋЗЂЩњдкЦфОлКЯЩЯЕФЛљБОИќИФЗЂГіРДЃЌетаЉГЦЮЊСьгђЪТМўЃЈDomain EventЃЉЃЌВЂЧвШЮКЮЖдетаЉИќИФИааЫШЄЕФЗўЮёЖМПЩвдМрЬ§етаЉЪТМўВЂдкЦфСьгђФкжДааЯргІЕФВйзїЁЃетжжЗНЗЈБмУтСЫШЮКЮааЮЊЩЯЕФёюКЯЃЈвЛИіСьгђЮоашЙцЖЈЦфЫћСьгђгІИУзіЪВУДЃЉвдМАЪБМфЩЯЕФёюКЯЃЈвЛИіСїГЬЕФГЩЙІЭъГЩВЛвРРЕгкЫљгаЯЕЭГЭЌЪБПЩгУЃЉЁЃЕБШЛЃЌетНЋвтЮЖзХЯЕЭГзюжеЪЧвЛжТЕФЁЃ
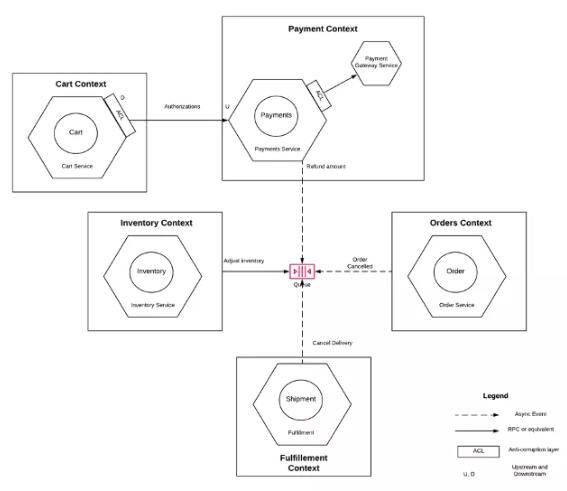
ЭМ 8ЃКЪТМўЧ§ЖЏМмЙЙ
дкЩЯУцЕФЪОР§жаЃЌЖЉЕЅЗўЮёЗЂВМвЛИіЪТМўЃКЖЉЕЅвбШЁЯћЁЃЖЉдФСЫИУЪТМўЕФЦфЫћЗўЮёДІРэИїздЕФСьгђЙІФмЃКжЇИЖЗўЮёЭЫПюЃЌПтДцЗўЮёЕїећЩЬЦЗЕФПтДцЃЌЕШЕШЁЃЮЊШЗБЃДЫМЏГЩЕФПЩППадКЭЕЏадЃЌашвЊзЂвтвдЯТМИЕуЃК
ЩњВњепгІШЗБЃжСЩйЗЂГіСЫвЛДЮЪТМўЁЃШчЙћЙ§ГЬжаГіЯжЪЇАмЃЌдђгІШЗБЃДцдкЛиЭЫЛњжЦвджиаТДЅЗЂЪТМў
ЯћЗбепгІИУШЗБЃвдУнЕШЕФЗНЪНЯћЗбЪТМўЁЃШчЙћдйДЮЗЂЩњЭЌвЛЪТМўЃЌВЛЛсЖдЯћЗбепВњЩњШЮКЮИБзїгУЁЃЪТМўвВПЩФмВЛЪЧЫГађЕНДяЕФЁЃЯћЗбепПЩвдЪЙгУЪБМфДСЛђАцБОКХзжЖЮРДБЃжЄЪТМўЕФЮЈвЛадЁЃ
гЩгкФГаЉгУР§ЕФЬиадЃЌВЛвЛЖЈзмЪЧПЩвдЪЙгУЛљгкЪТМўЕФМЏГЩЁЃЧыПДвЛЯТЙКЮяГЕЗўЮёКЭжЇИЖЗўЮёжЎМфЕФМЏГЩЁЃетЪЧвЛИіЭЌВНМЏГЩЃЌвђДЫЮвУЧашвЊзЂвтвЛаЉЪТЯюЁЃетЪЧвЛИіааЮЊёюКЯЕФР§згЁЊЁЊЙКЮяГЕЗўЮёПЩФмЛсДгжЇИЖЗўЮёЕїгУвЛИі
REST APIЃЌВЂжИЪОЫќЪкШЈЖЉЕЅЕФжЇИЖЃЌЖјЪБМфёюКЯЁЊЁЊжЇИЖЗўЮёашвЊЖдЙКЮяГЕЗўЮёПЩгУЃЌЫќВХФмНгЪмЖЉЕЅЁЃетжжёюКЯНЕЕЭСЫетаЉЩЯЯТЮФЕФзджЮадЃЌвВПЩФмЛсв§ШыВЛБивЊЕФвРРЕЁЃгаМИжжЗНЗЈПЩвдБмУтетжжёюКЯЃЌЕЋЪЧШчЙћЪЙгУСЫЫљгаетаЉбЁЯюЃЌЮвУЧНЋЪЇШЅЯђПЭЛЇЬсЙЉМДЪБЗДРЁЕФФмСІЁЃ
НЋ REST API зЊЛЛЮЊЛљгкЪТМўЕФМЏГЩЁЃЕЋЪЧЃЌШчЙћжЇИЖЗўЮёНіЙЋПЊ REST APIЃЌдђДЫбЁЯюПЩФмВЛПЩгУ
ЙКЮяГЕЗўЮёСЂМДНгЪмЖЉЕЅЃЌВЂЧвгавЛИіХњДІРэзївЕРДНгЙмЖЉЕЅВЂЕїгУжЇИЖЗўЮё API
ЙКЮяГЕЗўЮёЩњГЩвЛИіБОЕиЪТМўЃЌШЛКѓЕїгУжЇИЖЗўЮё API
дкГіЯжЪЇАмКЭЩЯгЮвРРЕЯюЃЈжЇИЖЗўЮёЃЉВЛПЩгУЕФЧщПіЯТЃЌНЋЩЯЪіЗНЗЈгыжиЪдЯрНсКЯЃЌПЩвдВњЩњИќОпЕЏадЕФЩшМЦЁЃР§ШчЃЌдкЗЂЩњЙЪеЯЕФЧщПіЯТЃЌПЩвдЭЈЙ§ЛљгкЪТМўЛђХњДІРэЕФжиЪдРДБИЗнЙКЮяГЕКЭжЇИЖЗўЮёжЎМфЕФЭЌВНМЏГЩЁЃетжжЗНЗЈЛсЖдПЭЛЇЬхбщВњЩњЖюЭтЕФгАЯьЃКПЭЛЇПЩФмЪфШыСЫВЛе§ШЗЕФжЇИЖЯъЯИаХЯЂЃЌЕБЮвУЧРыЯпДІРэжЇИЖЪБЃЌЮоЗЈЧПжЦЫћУЧдкЯпЁЃЛђепЃЌЪеЛиЪЇАмЕФжЇИЖПЩФмЛсдіМгЦѓвЕЕФГЩБОЁЃЕЋдкЫљгаПЩФмЕФЧщПіЯТЃЌШУЙКЮяГЕЗўЮёЖджЇИЖЗўЮёЕФВЛПЩгУадЛђЙЪеЯОпгаЕЏадЃЌРћДѓгкБзЁЃР§ШчЃЌШчЙћЮвУЧЮоЗЈРыЯпЪеПюЃЌЮвУЧПЩвдЭЈжЊПЭЛЇЁЃМђЖјбджЎЃЌдкгУЛЇЬхбщЁЂЕЏадКЭдЫгЊГЩБОжЎМфДцдкзХШЈКтЃЌдкЩшМЦЯЕЭГЪБЃЌУїжЧЕФзіЗЈЪЧГфЗжПМТЧетаЉелждЁЃ
10
БмУтЮЊСЫТњзуЕїгУепЕФЬиЖЈЪ§ОнашЧѓЖјБрХХЗўЮё
ДцдкгкШЮКЮУцЯђЗўЮёМмЙЙЕФвЛИіЗДФЃЪНЪЧЃКЗўЮёгКЯЕїгУепЕФЬиЖЈЗУЮЪФЃЪНЁЃЭЈГЃЃЌЕБЕїгУепЭХЖггыЗўЮёЬсЙЉепЭХЖгНєУмКЯзїЪБЃЌОЭЛсЗЂЩњетжжЧщПіЁЃШчЙћЭХЖге§дкПЊЗЂвЛИіЕЅЬхгІгУГЬађЃЌЫќУЧЭЈГЃЛсДДНЈвЛИіПчдНВЛЭЌОлКЯБпНчЕФ
APIЃЌДгЖјЪЙетаЉОлКЯНєУмёюКЯдквЛЦ№ЁЃЮвУЧРДПДвЛИіР§згЁЃБШШчЫЕ Web жаЕФЖЉЕЅЯъЧщвГУцЃЌвЦЖЏгІгУГЬађашвЊдкЕЅИівГУцЩЯЯдЪОЖЉЕЅЯъЧщКЭЖЉЕЅЭЫПюДІРэЯъЧщЁЃдквЛИіЕЅЬхгІгУГЬађжаЃЌЖЉЕЅЛёШЁ
APIЃЈOrder-GET-APIЃЌМйЩшЫќЪЧ REST APIЃЉашвЊЭЌЪБВщбЏЖЉЕЅКЭЭЫПюЃЌКЯВЂСНИіОлКЯВЂЯђЕїгУЗНЗЂЫЭвЛИіИДКЯЯьгІЁЃгЩгкОлКЯЪєгкЭЌвЛСїГЬБпНчЃЌвђДЫПЩвддкУЛгаЬЋЖрПЊЯњЕФЧщПіЯТЪЕЯжетвЛЕуЁЃЕїгУепПЩвддквЛДЮЛсЛАжаЛёЕУЫљашЕФЫљгаЪ§ОнЁЃ
ШчЙћЖЉЕЅКЭЭЫПюЪЧВЛЭЌЩЯЯТЮФЕФвЛВПЗжЃЌФЧУДЪ§ОнВЛдйГіЯждкЕЅИіЮЂЗўЮёЛђОлКЯБпНчФкЁЃЮЊЕїгУепБЃСєЯрЭЌЙІФмЕФвЛИібЁЯюЪЧЃЌШУЖЉЕЅЗўЮёИКд№ЕїгУЭЫПюЗўЮёВЂДДНЈвЛИіИДКЯЯьгІЁЃетжжЗНЗЈЛсв§Ц№вдЯТМИИіЮЪЬтЃК
ЖЉЕЅЗўЮёЯждкгыСэвЛИіЗўЮёМЏГЩЃЌДПДтЪЧЮЊСЫжЇГжФЧаЉашвЊЭЫПюЪ§ОнКЭЖЉЕЅЪ§ОнЕФЕїгУепЁЃЯждкЖЉЕЅЗўЮёЕФзджЮадНЕЕЭСЫЃЌвђЮЊЭЫПюОлКЯЕФШЮКЮИќИФЖМЛсЕМжТЖЉЕЅОлКЯЕФИќИФЁЃ
ЖЉЕЅЗўЮёгаСэвЛИіМЏГЩЃЌвђДЫашвЊПМТЧСэвЛИіЙЪеЯЕуЃКШчЙћЭЫПюЗўЮёГіЯжЙЪеЯЃЌЖЉЕЅЗўЮёЪЧЗёШдПЩвдЗЂЫЭВПЗжЪ§ОнЃЌВЂЧвЕїгУепЪЧЗёПЩвдгХбХЕиДІРэЙЪеЯФиЃП
ШчЙћЕїгУепашвЊБфИќЃЌвдДгЭЫПюОлКЯжаЛёШЁИќЖрЕФЪ§ОнЃЌФЧУДЯждкашвЊСНИіЭХЖгЭЌЪБНјааБфИќ
ШчЙћПчЦНЬЈЖМзёбетжжФЃЪНЃЌдђПЩФмЛсЕМжТИїжжгђЗўЮёжЎМфаЮГЩИДдгЕФвРРЕЙиЯЕЭјЃЌетЖМЪЧвђЮЊетаЉЗўЮёгКЯСЫЕїгУепЬиЖЈЕФЗУЮЪФЃЪНЁЃ
11
зЈУХЗўЮёгкЧАЖЫЕФКѓЖЫЃЈBFFsЃЉ
вЛжжМѕЧсетжжЗчЯеЕФЗНЗЈЪЧШУЕїгУепЭХЖгЙмРэИїжжгђЗўЮёжЎМфЕФБрХХЁЃБЯОЙЃЌЕїгУЗНИќСЫНтЗУЮЪФЃЪНЃЌВЂЧвПЩвдЭъШЋПижЦЖдетаЉФЃЪНЕФШЮКЮИќИФЁЃетжжЗНЗЈНЋгђЗўЮёДгБэЪОВуНтёюГіРДЃЌШУЫќУЧзЈзЂгкКЫаФвЕЮёСїГЬЁЃЕЋЪЧЃЌШчЙћ
Web КЭвЦЖЏгІгУГЬађПЊЪМжБНгЕїгУВЛЭЌЕФЗўЮёЃЌЖјВЛЪЧДгЕЅЬхжаЕїгУвЛИіИДКЯ APIЃЌетПЩФмЛсИјетаЉгІгУГЬађДјРДадФмПЊЯњЁЊЁЊдкНЯЕЭДјПэЕФЭјТчЩЯНјааЖрДЮЕїгУЃЌДІРэКЭКЯВЂРДздВЛЭЌ
API ЕФЪ§ОнЃЌЕШЕШЁЃ
ЯрЗДЃЌПЩвдЪЙгУСэвЛжжГЦЮЊгУгкЧАЖЫЕФКѓЖЫФЃЪНЃЈBackend for Front-endsЃЉЁЃдкетжжЩшМЦФЃЪНжаЃЌгЩЯћЗбепДДНЈКЭЙмРэЕФКѓЖЫЗўЮёЃЌдкБОР§жаЪЧ
Web КЭвЦЖЏЭХЖгЃЌЫќИКд№ЖдЖрИігђЗўЮёНјааМЏГЩЃЌДПДтЪЧЮЊСЫЯђПЭЛЇЬсЙЉЧАЖЫЬхбщЁЃWeb КЭвЦЖЏЭХЖгЯждкПЩвдИљОнЫќУЧЫљашвЊЕФгУР§РДЩшМЦЪ§ОнЦѕдМЁЃЫќУЧЩѕжСПЩвдЪЙгУ
GraphQL ЖјВЛЪЧ REST API РДСщЛюЕиВщбЏВЂЛёШЁЫљашЕФФкШнЁЃашвЊзЂвтЕФЪЧЃЌИУЗўЮёЪЧгЩЯћЗбепЭХЖггЕгаКЭЮЌЛЄЕФЃЌЖјВЛЪЧЬсЙЉгђЗўЮёЕФЭХЖгЁЃЧАЖЫЭХЖгЯждкПЩвдИљОнЫќУЧЕФашЧѓНјаагХЛЏЁЊЁЊвЦЖЏгІгУГЬађПЩвдЧыЧѓИќаЁЕФгааЇИКдиЃЌМѕЩйРДздвЦЖЏгІгУГЬађЕФЛсЛАДЮЪ§ЃЌЕШЕШЁЃЯТУцЪЧаоЖЉКѓЕФвЕЮёСїГЬЭМЁЃBFF
ЗўЮёЯждкЮЊЦфгУР§ЕїгУЁАЖЉЕЅЁБКЭЁАЭЫПюЁБгђЗўЮёЁЃ
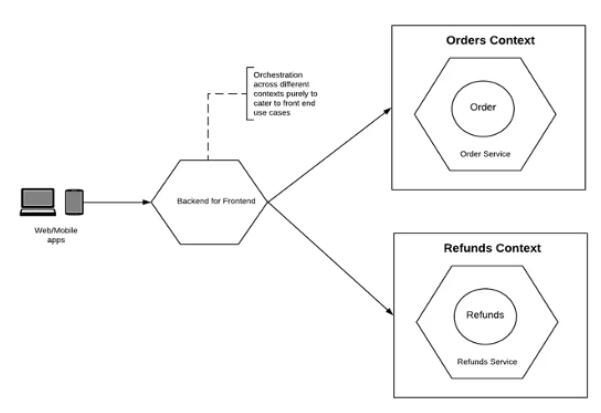
ЭМ 9ЃКгУгкЧАЖЫЕФКѓЖЫ
ОЁдчЙЙНЈ BFF ЗўЮёвВКмгагУЃЌетбљПЩвдБмУтДгЕЅЬхЯЕЭГжаЗжНтГіЙ§ЖрЕФЗўЮёЁЃЗёдђЃЌвЊУДгђЗўЮёБиаыжЇГжгђМфБрХХЃЌвЊУД
Web КЭвЦЖЏгІгУГЬађБиаыжБНгДгЧАЖЫЕїгУЖрИіЗўЮёЁЃетСНИібЁЯюЖМЛсЕМжТадФмПЊЯњЁЂвЛДЮадЙЄзївдМАЭХЖгжЎМфШБЗІзджЮЁЃ
|









