| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЮЂЗўЮёЕФМмЙЙМАЮЂЗўЮёЕФЩшМЦФЃЪН
ЁЃ
БОЮФРДздгкkubernetesжаЮФЩчЧј ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЮЂЗўЮёдкЦѓвЕжаПЩвдДјРДЛ§МЋЕФгАЯьЁЃ вђДЫЃЌШчКЮДІРэЮЂЗўЮёЬхЯЕМмЙЙЃЈMSAЃЉКЭвЛаЉЮЂЗўЮёЩшМЦФЃЪНвдМАЮЂЗўЮёЬхЯЕМмЙЙЕФвЛАуФПБъЛђддђЪЧКмгаБивЊЕФЁЃ
вдЯТЪЧЮЂЗўЮёМмЙЙЪЕЯжжавЊПМТЧЕФЫФИіФПБъЁЃ
НЕЕЭГЩБО ЁЊ MSAНЋНЕЕЭЩшМЦЃЌЪЕЪЉКЭЮЌЛЄITЗўЮёЕФећЬхГЩБО
ЬсИпЗЂВМЫйЖШ ЁЊ MSAНЋЬсИпЯюФПДгЙЙНЈЕНВПЪ№ЕФЫйЖШ
ЬсЩ§ЕЏад ЁЊ MSAНЋЬсЩ§ЮвУЧЗўЮёЭјТчЕФЕЏад
гаПЩМћад ЁЊ MSAЮЊФњЕФЗўЮёКЭЭјТчЩЯЬсЙЉИќКУЕФПЩМћадЁЃ
MSAЪЧНЈСЂдкФФаЉддђЛљДЁжЎЩЯЪЧашвЊФуШЅСЫНтЕФ
ПЩРЉеЙад
ПЩгУад
ЕЏадРЉеЙ
СщЛюад
ЖРСЂадЃЌзджїад
ШЅжааФЛЏжЮРэ
ЙЪеЯИєРы
здЖЏХфжУ
ЭЈЙ§DevOpsГжајНЛИЖ
дкМсГжетаЉддђЛљДЁЩЯЭЦЙуздМКЕФНтОіЗНАИЛђепЯЕЭГЛсДјРДвЛаЉЬєеНКЭЮЪЬтЃЌетаЉЮЪЬтдкаэЖрНтОіЗНАИжаЖМКмГЃМћЃЌЖјЧвПЩвдЭЈЙ§ЪЙгУе§ШЗЕФЩшМЦФЃЪНРДНтОіЃЌ
етаЉОЭЪЧЮЂЗўЮёЕФЩшМЦФЃЪНЃЌетаЉФЃЪНПЩвдЗжЮЊЮхИіДѓРрЃЌЖјУПвЛРргжАќКЌСЫаэЖрЩшМЦФЃЪНЁЃОпЬхШчЯТЭМЫљЪОЃК
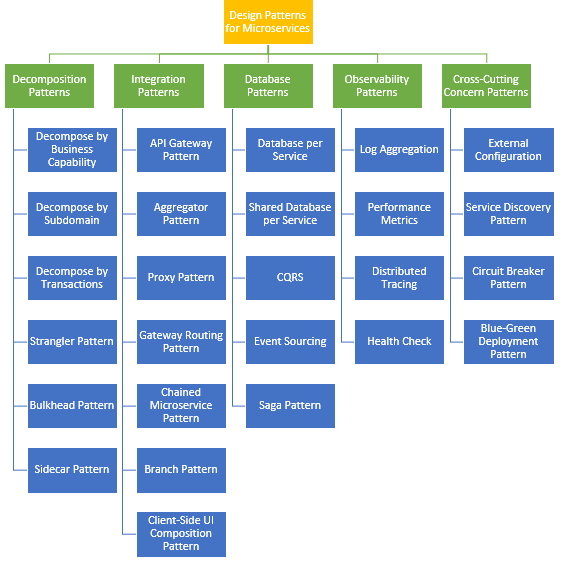
Design Patterns for Microservices
НтёюФЃЪН(Decomposition Patterns)
АДвЕЮёФмСІНтёю
ЭЈЙ§дЫгУЕЅвЛжАд№ддђЃЌЮЂЗўЮёзмЪЧЛсАбЗўЮёжЎМфЕФёюКЯБфЮЊЫЩёюКЯЃЌЮЂЗўЮёЭЈЙ§вЕЮёФмСІНтёюЃЌЖјЧвЗўЮёЕФЖЈвхЪЧЖдгІгквЕЮёФмСІЁЃвЕЮёФмСІетИіИХФюРДздгквЕЮёМмЙЙФЃаЭЃЌФГжжГЬЖШЩЯРДЫЕЃЌвЕЮёШЗЪЕЪЧПЩвдВњЩњМлжЕЃЌвЕЮёФмСІОГЃЪЧЖдгІгквЛИівЕЮёЪЕЬхЖдЯѓЁЃР§ШчЃК
ЖЉЕЅЙмРэЖдгІгкЖЉЕЅ
ПЭЛЇЙмРэЖдгІгкПЭЛЇ
АДеезггђНтёю
АДеевЕЮёФмСІНтёювЛИігІгУПЩФмЪЧвЛИіКУЕФПЊЪМЃЌЕЋЪЧФуПЩФмЛсгіЕНЫљЮНЕФЁАЩёРрЁБ(God Classes),ОЭЪЧФФаЉВЛШнвзНтёюЕФРрЃЌЖјЧветаЉРрдкЖрИіЗўЮёжЎМфКмГЃМћЁЃСьгђЧ§ЖЏЩшМЦ(DDD)
ВЮПМгІгУЮЪЬтПеМфЈCвЕЮёЈCзіЮЊвЛИігђ(domain)ЁЃвЛИігђгЩЖрИізггђзщГЩЃЌЖјУПвЛИізггђЖдгІгквЕЮёЕФВЛЭЌЕФВПЗжЁЃ
зггђПЩвдЗжРрШчЯТЃК
КЫаФ(Core) ЁЊ ЧјЗжвЕЮёЕФЙиМќ КЭ гІгУжазюгаМлжЕЕФВПЗж
жЇГХ(Supporting?) ЁЊ гывЕЮёЯрЙиЃЌЕЋЪЧВЛЪЧЙиМќВПЗжЃЌПЩвдФкВПЪЕЯжЃЌвВПЩвдЭтВПЪЕЯж
ЗКЛЏ(Generic?) ЁЊ ВЛеыЖдЬиЖЈЕФвЕЮёЃЌРэЯыЧщПіЯТЪЙгУЯжГЩЕФШэМўЪЕЪЉ
ЖЉЕЅЙмРэЕФзггђАќРЈЃК
ВњЦЗФПТМЗўЮё
ПтДцЙмРэЗўЮё
ЖЉЕЅЙмРэЗўЮё
НЛИЖЙмРэЗўЮё
АДЪТЮёНтёю/СННзЖЮЬсНЛЃЈ2PCЃЉФЃЪН
ПЩвдЭЈЙ§ЪТЮёЗжНтЗўЮёЃЌШЛКѓЯЕЭГжаНЋЛсгаЖрИіЪТЮёЁЃ ЗжВМЪНЪТЮёДІРэЕФживЊВЮгыепжЎвЛЪЧЪТЮёДІРэаЕїЦї[3]ЁЃЗжВМЪНЪТЮёАќРЈСНИіВНжшЃК
зМБИНзЖЮ ЁЊ дкДЫНзЖЮжаЃЌЪТЮёЕФЫљгаВЮгыепЖМзМБИЬсНЛВЂЭЈжЊаЕїЦїЫћУЧвбзМБИКУЭъГЩЪТЮё
ЬсНЛЛђепЛиЙіНзЖЮ ЁЊ дкДЫНзЖЮжаЃЌЪТЮёаЕїЦїЯђЫљгаВЮгыепЗЂГіЬсНЛЛђЛиЙіУќСю
2PCЕФЮЪЬтЪЧКЭЕЅИіЮЂЗўЮёжДааЪБМфРДЖдБШКФЪБГЄЁЃМДЪЙЮЂЗўЮёдкЯрЭЌЕФЭјЖЮжаЃЌаЕїЮЂЗўЮёжЎМфЕФЪТЮёвРОЩЛсЭЯТ§ећИіЯЕЭГЁЃвђДЫетИіНтОіЗНАИвЛАуВЛЪЙгУдкИпИКдиЕФГЁОАжа
ЖѓЩБФЃЪН
вдЩЯШ§жжЩшМЦФЃЪНгУгкЖдЮДПЊЗЂЕФгІгУ(greenfield apps)ЕФНтёю, ЕЋЪЧЮвУЧ80%ЕФЙЄзїЖМЪЧКЭХгДѓЖјНЉЛЏЕФгІгУ(вХСєДњТыПт)ДђНЛЕРЁЃЖѓЩБФЃЪН(Strangler
Pattern)ОЭЪЧЮЊСЫНтОіетИіЮЪЬтЖјРДЕФЁЃдкЯрЭЌЕФURIПеМфжаДДНЈСНИіЖРСЂЙВДцЕФгІгУЃЌЫцзХЪБМфЕФЭЦвЦЃЌжиЙЙЙ§ЕФаТгІгУНЋЁАЖѓЩБЁБЛђепЬцДњдРДЕФгІгУЃЌжБЕНзюжеАбХгДѓЖјНЉЛЏЕФгІгУЙиБеЕєЁЃЖѓЩБгІгУЃЈStrangler
ApplicationЃЉЕФВНжшЗжЮЊзЊЛЛЃЌЙВДцКЭЯћУ№Ш§ВН[4]ЃК
зЊЛЛ(Transform?) ЁЊ? гУЯжДњЗНЪНДДНЈвЛИіаТЕФЦНааЕФеОЕу
ЙВДц(Coexist?) ЁЊ? НЋвбгаЕФеОЕужиЖЈЯђЕНаТЕФеОЕуЃЌаТеОЕуж№ВНЪЕЯжРЯеОЕуЕФЙІФм
ЯћУ№(Eliminate?) ЁЊ? вЦГ§вбгаЕФеОЕуЕФОЩЕФЙІФм
ИєАхФЃЪН
НЋгІгУГЬађЕФдЊЫиИєРыЕНГижаЃЌвдБуШчЙћЦфжавЛИіЪЇАмЃЌЦфЫћгІгУГЬађНЋМЬајдЫааЬсЙЉЗўЮёЃЌетИіЩшМЦФЃЪНГЦЮЊИєАхФЃЪН(Bulkhead),
вђЮЊЫћРрЫЦгкДЌЬхжавЛИіИіБЛИєРыЕФЗжЧјЁЃИљОнЪЙгУепИКдиКЭПЩгУадвЊЧѓЃЌетаЉЗжЧјЗўЮёЪЕР§БЛЗжИюЕНВЛЭЌЕФзщРяУцЁЃетжжЩшМЦФЃЪНгажњгкИєРыЙЪеЯ(isolate
failures), ВЂдЪаэМДЪЙдкЙЪеЯЦкМфШдПЩЮЊФГаЉЪЙгУепЮЌГжЗўЮёЙІФм.
БпГЕФЃЪНЃЈSidecar PatternЃЉ
НЋгІгУГЬађЕФзщМўВПЪ№ЕНЕЅЖРЕФШнЦїжавдРДЬсЙЉИєРыКЭЗтзАЃЌетИіФЃЪНдЪаэгІгУПЩвдгЩЖржжЖрбљЕФзщМўКЭММЪѕзщКЯЖјГЩЃЌетжжФЃЪНГЦЮЊБпГЕ(Sidecar
)ЃЌ вђЮЊРрЫЦФІЭаГЕХдБпЫљИНЕФБпГЕЁЃдйетИіФЃЪНжаЃЌsidecar ИНдкИИгІгУЩЯЃЌВЂЬсЙЉгІгУЕФжЇГжЬиеїЁЃsidecar
КЭИИгІгУЙВЯэЯрЭЌЕФЩњУќжмЦкЃЌЫцзХИИгІгУДДНЈЖјДДНЈЃЌЯњЛйЖјЯњЛйЁЃБпГЕФЃЪНгаЪБГЦЮЊЁАБпЬпФЃЪН(sidekick
pattern)ЁБЁЃ
ЮЂЗўЮёЕФМЏГЩФЃЪН (Integration Patterns for Microservices)
APIЭјЙиФЃЪН (API Gateway Pattern)
ЕБАбвЛИігІгУЗжНтЮЊЖрИіаЁЕФЮЂЗўЮёЪБЃЌгавЛаЉЮЪЬташвЊЮвУЧПМТЧВЂДІРэЃК
ВЛЭЌЕФЮЂЗўЮёВЛЭЌЕФЭЈЕРЩЯгаЖрДЮЕїгУ
ашвЊДІРэВЛЭЌЕФавщРраЭ
ВЛЭЌЕФЯћЗбепПЩФмашвЊВЛЭЌИёЪНЕФЯьгІ
ОлКЯФЃЪН(Aggregator Pattern)
дкНЋвЕЮёЙІФмЗжНтЮЊМИИіНЯаЁЕФТпМДњТыЖЮЪБЃЌгаБивЊПМТЧШчКЮЖдУПИіЗўЮёЗЕЛиЕФЪ§ОнНјаааЭЌВйзїЃЌЯћЗбепВЛИКд№ДІРэетИіЪТЧщЁЃ
ОлКЯФЃЪНгажњгкНтОіДЫЮЪЬтЃЌЫќЬжТлСЫЮвУЧШчКЮОлКЯРДздВЛЭЌЗўЮёЕФЪ§ОнЃЌШЛКѓНЋзюжеЯьгІЗЂЫЭИјЯћЗбепЁЃ етПЩвдЭЈЙ§СНжжЗНЗЈРДЭъГЩ[6]ЃК
зщКЯЕФЮЂЗўЮёНЋЕїгУЫљгаБиаыЕФЮЂЗўЮёЃЌзщКЯЪ§ОнЃЌзЊЛЛЪ§ОнЃЌШЛКѓЗЕЛиИјЕїгУепЁЃ
APIЭјЙиЛЙПЩвдЗжЗЂЧыЧѓЕНЖрИіЮЂЗўЮёЩЯЃЌдйОлКЯЪ§ОнЃЌШЛКѓЗЂЫЭЯћЗбепЁЃ
ДњРэФЃЪН(Proxy Pattern)
ЮвУЧжЛЪЧЭЈЙ§APIЭјЙиРДБЉТЖЮЂЗўЮёЁЃ ЮвУЧдЪаэЛёШЁAPIЕФЬиеїЃЌР§ШчАВШЋКЭGWжаAPIЕФЗжРрЁЃ етИіР§згжаЃЌAPIЭјЙиОпгаШ§ИіAPIФЃПщЃК
вЦЖЏAPI ЈC ЮЊFTGOвЦЖЏПЭЛЇЖЫЪЕЯжAPI
фЏРРЦїAPI-ЪЕЯжфЏРРЦїжадЫааЕФJavaScriptгІгУГЬађЕФAPI
ЙЋгУAPI-ЮЊЕкШ§ЗНПЊЗЂШЫдБЪЕЯжAPI
ЭјЙиТЗгЩФЃЪН (Gateway Routing Pattern)
APIЭјЙиИКд№ЧыЧѓТЗгЩЁЃ APIЭјЙиЭЈЙ§НЋЧыЧѓТЗгЩЕНЯргІЕФЗўЮёРДЪЕЯжвЛаЉAPIВйзїЁЃ ЕБAPIЭјЙиНгЪеЕНЧыЧѓЪБЃЌЫќЛсВщбЏТЗгЩгГЩфЃЌИУТЗгЩгГЩфжИЖЈНЋЧыЧѓТЗгЩЕНЕФЗўЮёЁЃ
ТЗгЩгГЩфР§ШчПЩвдНЋHTTPЗНЗЈКЭТЗОЖгГЩфЕНЗўЮёЕФHTTPЕФURLЩЯЁЃ ДЫЙІФмгыWebЗўЮёЦїЃЈШчNGINXЃЉЬсЙЉЕФЗДЯђДњРэЙІФмЯрЭЌЁЃ
ЮЂЗўЮёСДФЃЪН (Chained Microservice Pattern)
ЕЅИіЗўЮёЛђЮЂЗўЮёНЋПЩФмЛсгаЖрИівРРЕЙиЯЕЃЌ Р§ШчЃКЯњЪлЮЂЗўЮёвРРЕВњЦЗЮЂЗўЮёКЭЖЉЕЅЮЂЗўЮёЁЃЮЂЗўЮёСДФЃЪННЋИљОнФуЕФЧыЧѓЬсЙЉКЯВЂЕФНсЙћЁЃmicroservice-1
НгЪеЧыЧѓЃЌШЛКѓКЭmicroservice-2ЭЈаХЃЌВЂЧвПЩФмКЭmicroservice-3ЭЈаХЁЃ ЫљгаЕФетаЉЗўЮёЖМЪЧЭЌВНЕїгУЁЃ
ЗжжЇФЃЪНЃЈBranch PatternЃЉ
ЮЂЗўЮёПЩФмашвЊДгАќРЈЦфЫћЮЂЗўЮёдкФкЕФЖрИіРДдДЛёШЁЪ§ОнЃЌЗжжЇЮЂЗўЮёФЃЪНЪЧОлКЯЦїКЭСДЩшМЦФЃЪНЕФЛьКЯЃЌВЂдЪаэРДздСНИіЛђЖрИіЮЂЗўЮёЕФЭЌЪБЧыЧѓ/ЯьгІДІРэЁЃЕїгУЕФЮЂЗўЮёПЩвдЪЧЮЂЗўЮёСДЁЃИљОнФњЕФвЕЮёашЧѓЃЌЗжжЇФЃЪНЛЙПЩгУгкЕїгУВЛЭЌЕФЮЂЗўЮёСДЛђЕЅИіСДЁЃ
ПЭЛЇЖЫUIзщКЯФЃЪН(Client-Side UI Composition Pattern)
ЕБЭЈЙ§ЗжНтвЕЮёЙІФм/зггђРДПЊЗЂЗўЮёЪБЃЌИКд№гУЛЇЬхбщЕФЗўЮёБиаыДгЖрИіЮЂЗўЮёжаЬсШЁЪ§ОнЁЃдкЕЅЛњЪРНчжаЃЌДгUIЕНКѓЖЫЗўЮёжЛгавЛДЮЕїгУРДВщбЏЪ§ОнВЂЧвЫЂаТ/ЬсНЛUIвГУцЁЃВЛЙ§ЃЌЯждкВЛвЛбљСЫЁЃ
дкЮЂЗўЮёжаЃЌUIБиаыЩшМЦЮЊЦСФЛ/вГУцЩЯОпгаЖрИіВПЗж/ЧјгђЕФПђМмЁЃУПИіВПЗжЖМНЋЕїгУЕЅЖРЕФКѓЖЫЮЂЗўЮёвдЬсШЁЪ§ОнЁЃжюШчAngularJSКЭReactJS
жЎРрЕФПђМмПЩвдЧсЫЩЕизіЕНетвЛЕуЃЌетаЉЦСФЛГЦЮЊЕЅвГгІгУГЬађЃЈSPAЃЉЁЃУПИіЭХЖгЖМПЊЗЂвЛИіПЭЛЇЖЫUIзщМўЃЌР§ШчAngularJSжИСюЃЌИУзщМўЪЕЯжеыЖдИУвГУц/ЦСФЛЧјгђЕФЮЂЗўЮёЕїгУЁЃвЛИіUIЭХЖгИКд№ЪЕЯжвГУцЕФПђМмЃЌетИіПђМмЭЈЙ§зщКЯЖрИіЬиЖЈЗўЮёUI
(service-specific UI) зщМўРДЙЙНЈвГУц/ЦСФЛЁЃ
Ъ§ОнПтФЃЪН(Database Patterns)
ЮЊЮЂЗўЮёЖЈвхЪ§ОнПтМмЙЙЪБЃЌЮвУЧашвЊПМТЧвдЯТМИЕуЃК
ЗўЮёжЎМфБиаыЪЧЫЩЩЂёюКЯЕФ, ЫќУЧПЩвдЖРСЂПЊЗЂЃЌВПЪ№КЭРЉеЙЁЃ
вЕЮёЪТЮёдкПчдНЖрИіЮЂЗўЮёЕФЪБКђБЃжЄВЛБф
вЛаЉвЕЮёЪТЮёПчдНЖрИіЮЂЗўЮёРДВщбЏЪ§Он
гаЪБЪ§ОнПтБиаыПЩвдИДжЦЃЌВЂЧвПЩвдЕЏадЙВЯэ
ВЛЭЌЕФЗўЮёгаВЛЭЌЕФЪ§ОнДцДЂвЊЧѓ
УПвЛИіЗўЮёЖдгІвЛИіЪ§ОнПт(Database per Service)
ЮЊСЫНтОіЩЯЪіЮЪЬт,БиаыЮЊУПИіЮЂЗўЮёЩшМЦвЛИіЪ§ОнПт. ИУЪ§ОнПтжЛФмЪЧИУЗўЮёЫНгаЕФЃЌВЂЧвжЛФмЭЈЙ§ЮЂЗўЮёЕФAPIЗУЮЪЃЌВЛФмБЛЦфЫћЕФЮЂЗўЮёжБНгЗУЮЪЁЃР§ШчЃЌЖдЙиЯЕаЭЪ§ОнПтЃЌЮвУЧПЩвдЪЙгУ
УПИіЗўЮёгаЫНгаЛЏЕФБэ(private-tables-per-service), УПИіЗўЮёгаздМКЕФschema
(schema-per-service), ЛђепУПИіЗўЮёгаЫНгаЕФЪ§ОнПтЗўЮёЦї ЃЈdatabase-server-per-serviceЃЉ
УПвЛИіЗўЮёЙВЯэЪ§ОнПт (Shared Database per Service)
ЮвУЧвбОЬжТлСЫУПИіЗўЮёвЛИіЪ§ОнПтЪЧЮЂЗўЮёЕФРэЯыбЁдёЃЌЕЋЫќЪЧЮЂЗўЮёЕФЗДФЃЪН(anti-pattern)ЁЃШчЙћвЛИіЕЅвЛЖјгжХгДѓЕФгІгУЃЌВЂЪдЭМАбЫќВ№ЗжЮЊЮЂЗўЮёЃЌФЧУДЪ§ОнПтЕФЗДЗЖЪНЛЏ(denormalization
)ОЭВЛФЧУДШнвзЁЃНЋУПИіЮЂЗўЮёЙВЯэЪ§ОнПтВЛЪЧРэЯыЕФЧщПіЃЌЕЋЪЧЪЧПЩааЕФНтОіЗНАИЁЃДѓЖрЪ§ШЫШЯЮЊетЪЧЮЂЗўЮёЕФЗДФЃЪНЃЌЕЋЖдгкbrownfield
гІгУЃЌетЪЧНЋгІгУГЬађЗжНтГЩНЯаЁТпМВПЗжЕФвЛИіКмКУЕФПЊЪМЁЃЕЋЪЧЖдгкgreenfield гІгУВЛЬЋЪЪгУЁЃ
УќСюВщбЏЕФд№ШЮЗжРы (Command Query Responsibility SegregationЃЌCQRS)
вЛЕЉЮвУЧЪЕЯжСЫУПИіЗўЮёЖдгІвЛИіЪ§ОнПтЃЌОЭашвЊНЋДгЖрИіЮЂЗўЮёВщбЏЗЕЛиЕФЪ§ОнСЌНгЦ№РДЁЃЯдШЛетЪЧВЛПЩФмЕФЁЃCQRSНЈвщНЋгІгУЗжЮЊСНИіВПЗж
ЁЊ УќСюЖЫ (command side)КЭВщбЏЖЫ (query side):
УќСюЖЫДІРэДДНЈЃЌИќаТКЭЩОГ§ЧыЧѓ
ВщбЏЖЫЭЈЙ§ЪЙгУЮяЛЏЪгЭМРДДІРэВщбЏВПЗж
ЭЈГЃ ЪТМўЫндДФЃЪН(event sourcing pattern)КЭЫќвЛЦ№гУРДЮЊШЮКЮЪ§ОнИќИФДДНЈЪТМўЁЃЭЈЙ§ЖЉдФЪТМўСїЃЌПЩвдЪЙЮяЛЏЪгЭМБЃГжВЛЖЯЕФИќаТ
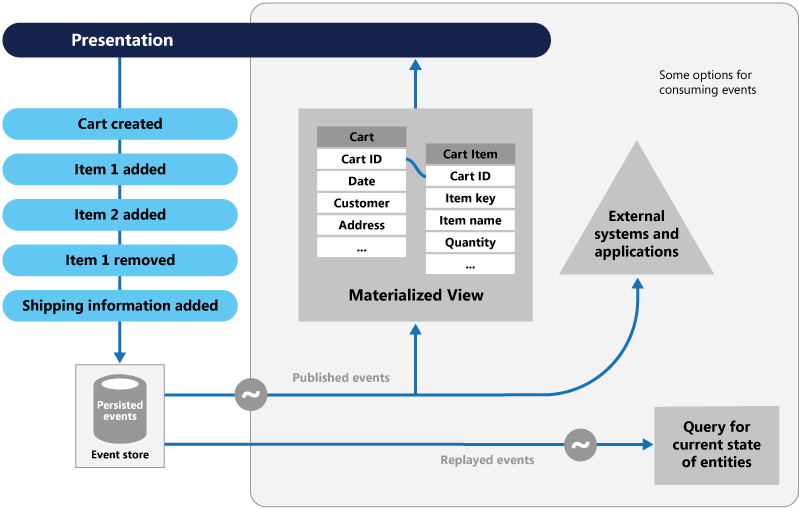
ЪТМўЫндДФЃЪН(event sourcing pattern)
ДѓЖрЪ§гІгУГЬађЖМЪЙгУЪ§ОнЃЌвЛИіЕфаЭЕФЭООЖОЭЪЧгІгУБЃГжЕБЧАЕФзДЬЌЁЃР§ШчЃЌДЋЭГЕФДДНЈЃЌЖСШЁЃЌИќаТКЭЩОГ§ЃЈCRUDЃЉжаЃЌЕфаЭЕФЪ§ОнДІРэЪЧДгДцДЂжаЖСШЁЪ§ОнЃЌЫќАќКЌОГЃЪЙгУЪТЮёЫјЖЈЪ§ОнЕФЯожЦЁЃ
ЪТМўЫндДФЃЪНЖЈвхСЫвЛЯЕСаЪТМўЧ§ЖЏЕФЪ§ОнЕФДІРэВйзїЃЌУПвЛИіЪТМўДІРэВйзїЖМЛсМЧТМдкНізЗМгДцДЂжа(append-only
store)ЁЃгІгУГЬађДњТыЗЂЫЭвЛЯЕСа УќСюЪНЕФУшЪіСЫЪ§ОнЩЯЗЂЩњЕФЖЏзїЕФЪТМўЕНЪТМўГжОУЛЏДцДЂЕФЕиЗНЁЃУПИіЪТМўДњБэвЛзщЪ§ОнИќИФЃЈР§ШчЃЌAddedItemToOrderЃЉ
етаЉЪТМўГжОУЛЏДцДЂдкГфЕБЯЕЭГМЧТМЯЕЭГЕФЪТМўДцДЂжаЁЃЪТМўДцДЂЯЕЭГжаЪТМўЗЂВМЕФЕфаЭгІгУГЁОАЪЧЃКдкгІгУжаБЃГжЪЕЬхЕФЮяЛЏЪгЭМКЭЪТМўЕФЖЏзївЛбљРДИФБфЫћУЧЃЌвдМАМЏГЩЕФЭтВПЯЕЭГЁЃР§ШчЯЕЭГПЩвдЮЌЛЄвЛИіеыЖдЫљгагУЛЇЕФЮяЛЏЪгЭМЃЌгУРДЬюГфUIВПЗжЕФЪ§ОнЁЃЕБгІгУГЬађЬэМгаТЖЉЕЅЃЌЬэМгЛђЩОГ§ЖЉЕЅЩЯЕФЯюФПвдМАЬэМгдЫЪфаХЯЂЪБЃЌетаЉЪТМўУшЪіСЫетаЉЪ§ОнБфЛЏПЩвдБЛДІРэВЂЧвПЩвдИќаТЕНЮяЛЏЪгЭМЩЯЁЃЯТУцЪЧетИіФЃЪНЕФзнРРЃК
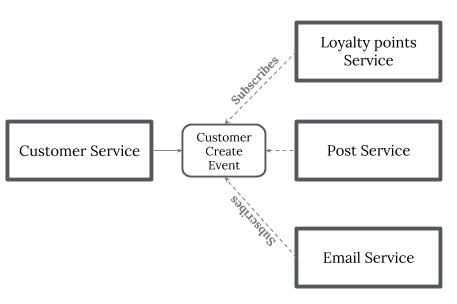
ЪТМўТФРњФЃЪН(Saga Pattern)
ЕБУПвЛИіЮЂЗўЮёЖМгаздМКЕФЪ§ОнПтЃЌВЂЧввЛИівЕЮёЪТЮёПчдНЖрИіЮЂЗўЮёЕФЪБКђЃЌЮвУЧЪЧШчКЮШЗБЃИїИіЗўЮёжЎМфЕФЪ§ОнвЛжТадЃПУПИіЧыЧѓЖМгавЛИіВЙГЅЧыЧѓЃЌИУЧыЧѓНЋдкЧыЧѓЪЇАмЪБжДааЁЃ
ЫќПЩвдЭЈЙ§СНжжЗНЪНЪЕЯжЃК
Choreography? ЁЊ ШчЙћУЛгажабыаЕїЃЌдђУПИіЗўЮёЖМЛсВњЩњВЂеьЬ§СэвЛИіЗўЮёЕФЪТМўЃЌВЂОіЖЈЪЧЗёгІВЩШЁДыЪЉЁЃChoreography?
ЪЧжИЖЈСНИіЛђСНИівдЩЯВЮгыепЕФЗНЪНЁЃ УПвЛИіВЮгыепЖМЮоЗЈПижЦЖдЗНЕФСїГЬЃЌЛђепШЮвтПЩМћЕФСїГЬЃЌетаЉПЩМћЕФСїГЬПЩвдаЕїЫћУЧЕФЛюЖЏКЭСїГЬвдЙВЯэаХЯЂКЭЪ§жЕЁЃЕБашвЊПчПижЦ/ПЩМћадгђНјаааЕїЪБЃЌЧыЪЙгУchoreography
ЁЃФуПЩвддкМђЕЅЕФЧщПіЯТНЋБрХХЪгЮЊЭјТчавщЃЌЫќЙцЖЈСЫИїВЮгыепжЎМфПЩНгЪмЕФЧыЧѓКЭЯьгІФЃЪНЁЃ
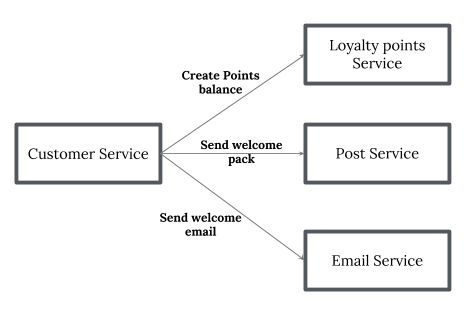
Orchestration?ЁЊ? вЛИіOrchestration?ЃЈЖдЯѓЃЉИКд№SagaЕФОіВпКЭвЕЮёТпМЫГађЁЃЕБФувбОПижЦСїГЬжаЕФЫљгаВЮгыепЪБЃЌЕБЫќУЧШЋВПДІгквЛИіПижЦЗЖЮЇФкЪБЃЌФуПЩвдПижЦЛюЖЏЕФСїГЬЁЃЕБШЛЃЌЭЈГЃЧщПіЯТЃЌЕБФужЦЖЈвЛИізщжЏФкЕФвЕЮёСїГЬЪБЃЌФувбОПижЦСЫЫќЁЃ
ЙлВьепФЃЪН(Observability Patterns)
ШежООлКЯ
ПМТЧетбљвЛжжЧщПіЃКвЛИігІгУАќКЌЖрИіЮЂЗўЮёЪЕР§ЃЌУПИіЧыЧѓОГЃдкКсПчЖрИіЮЂЗўЮёЪЕР§ЃЌФЧУДУПвЛИіЮЂЗўЮёЪЕР§ЖМВњЩњвЛИіБэзЊЛЏИёЪНЕФШежОЮФМўЁЃ
вђДЫЮвУЧашвЊвЛИіжааФЛЏЕФШежОЗўЮёРДНЋУПИіЗўЮёЪЕР§ЕФШежОЪеМЏЦ№РДЁЃгУЛЇПЩвдЫбЫїЗжЮіВЂЗжЮіШежОЃЌВЂЧвХфжУвЛаЉЕБШежОжаГіЯжЬиЖЈаХЯЂЕФБЈОЏЙцдђЁЃР§ШчЃКPCFШЗЪЕгавЛИіШежООлКЯЦї(Log
aggregator), гУРДЪеМЏPCFЦНЬЈЩЯИїИігІгУЕФИїИізщМў(router, controller,
Diego, ЕШЕШЁ)ЕФШежОЁЃAWS Cloud WatchвВетбљзіЁЃ
адФмжИБъ
вђЮЊЮЂЗўЮёМмЙЙЕМжТЗўЮёЕФЪ§СПдіМгЪБЃЌУмЧазЂвтЪТЮёБфЕУЪЎЗжЙиМќЃЌвдБуМрПиЮЂЗўЮёФЃЪНВЂЧвдкЮЪЬтЗЂЩњЕФЪБКђЗЂГіОЏИцЁЃ
вЛИіжИБъЗўЮёгУРДЪеМЏУПИіЕЅЖРВйзїЕФЭГМЦаХЯЂЁЃЫќгІИУОлКЯвЛИігІгУЗўЮёЕФЫљгажИБъЃЌвдБуЬсЙЉБЈИцКЭОЏБЈЁЃ
ОлКЯжИБъгІИУАќКЌСНИіФЃПщЃК
ЭЦЫЭ ЁЊ ЗўЮёЭЦЫЭжИБъИјжИБъЗўЮё Р§ШчЃКNewRelic, AppDynamics
РШЁ ЁЊ жИБъЗўЮёПЩвдДгУПИіЗўЮёжаРШЁжИБъ Р§ШчЃКPrometheus
ЗжВМЪНИњзй
дкЮЂЗўЮёМмЙЙжаЃЌЧыЧѓЭЈГЃПчдНЖрИіЮЂЗўЮёЁЃ УПИіЗўЮёЭЈЙ§ПчЖрИіЗўЮёжДаавЛИіЛђЖрИіВйзїРДДІРэвЛИіЧыЧѓЁЃ
дкНјааЙЪеЯХХГ§ЪБЃЌгавЛИіИњзйIDЪЧЗЧГЃжЕЕУЕФЃЌетбљЮвУЧПЩвдЖЫЖдЖЫЕФИњзйЧыЧѓ
НтОіЗНАИЪЧв§ШывЛИіЪТЮёIDЃЌПЩвдЪЙгУвдЯТЗНЗЈЃК
ЮЊУПИіЭтВПЧыЧѓЗжХфЮЈвЛЕФЭтВПЧыЧѓID
НЋЭтВПЧыЧѓIDДЋЕнИјЫљгаЗўЮё
дкЫљгаШежОЯћЯЂжаАќРЈЭтВПЧыЧѓID
НЁПЕМьВщ
ЪЕЪЉЮЂЗўЮёМмЙЙКѓЃЌгавЛжжПЩФмЪЧЃКЗўЮёПЩФмЛсЦєЖЏЕЋЮоЗЈДІРэЪТЮёЁЃУПИіЗўЮёЖМашвЊОпгавЛИіЖЫЕугУРДМьВщгІгУЕФНЁПЕГЬЖШЃЌР§ШчhealthЁЃетИіAPIгІИУМьВщжїЛњЕФзДЬЌ,
гыЦфЫћЗўЮё/ЛљДЁНсЙЙЕФСЌНгвдМАЦфЫћШЮвтЬиЖЈЕФТпМЁЃ
НЛВцЙизЂФЃЪН(Cross-Cutting Concern Patterns)
ЭтВПХфжУ(External Configuration)
вЛИіЕфаЭЕФЗўЮёЭЈГЃЛЙЛсЕїгУЦфЫћЗўЮёКЭЪ§ОнПтЃЌЖдгкУПвЛИіЛЗОГЃЌР§Шчdev, QA, UAT, prodЃЌетаЉЛЗОГЕФЖЫЕуURLЛђФГаЉХфжУЪєадПЩФмВЛЭЌЃЌетаЉЪєаджаЕФШЮКЮвЛЯюИќИФЖМПЩФмашвЊжиаТЙЙНЈЛђжиаТВПЪ№ЗўЮёЁЃ
ЮЊСЫБмУтДњТыаоИФЃЌЮвУЧПЩвдЪЙгУХфжУЃЌНЋЫљгаЕФХфжУаХЯЂЖМЭтВПЛЏЃЌАќРЈЖЫЕуURLКЭШЯжЄаХЯЂЁЃгІгУГЬађгІИУдкЦєЖЏЪБЛђдЫааЪБМгдиетаЉХфжУЁЃетаЉХфжУПЩвддкгІгУЦєЖЏЕФЪБКђЗУЮЪЕНЃЌЛђепетаЉХфжУдкВЛашвЊжиЦєЗўЮёЕФЧщПіЯТПЩвдИќаТЁЃ
ЗўЮёЗЂЯжФЃЪН
ЕБгіМћШчЭМЫљЪОЕФЮЂЗўЮёМмЙЙЪБЃЌдкЮЂЗўЮёЕїгУЗНУцЮвУЧашвЊЙизЂвЛаЉЮЪЬтЁЃ
ЪЙгУШнЦїММЪѕЃЌIPЕижЗПЩвдЖЏЬЌЗжХфИјУПИіЮЂЗўЮёЪЕР§ЃЌ УПДЮЕижЗИќИФЪБЃЌЯћЗбепЗўЮёЕФЕїгУЖМЛсжаЖЯЃЌашвЊЪжЖЏИќИФВХФмЛжИДЁЃ
ЯћЗбепБиаыМЧзЁУПИіЗўЮёURLЃЌВЂЪЙЦфНєУмёюКЯЁЃ
вђДЫашвЊДДНЈЗўЮёзЂВсЃЌИУЗўЮёзЂВсНЋБЃДцУПИіЩњВњаЭЗўЮёЕФдЊЪ§ОнКЭУПИіЗўЮёЕФЫЕУїЙцЗЖЁЃЗўЮёЪЕР§дкЦєЖЏЪБгІзЂВсЕНзЂВсжааФЃЌЖјдкЪЕР§ЙиБеЪБгІзЂЯњЁЃЗўЮёЗЂЯжгаСНжжРраЭЃК
ПЭЛЇЖЫЃЌР§ШчЃКNetflix Eureka
ЗўЮёЖЫЃКР§ШчЃК AWS ALB
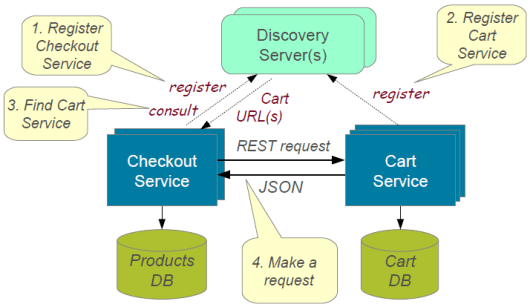
ЖЯТЗЦїФЃЪН
вЛИіЗўЮёЭЈГЃЛсЕїгУЦфЫћЗўЮёРДВщбЏЪ§ОнЃЌгавЛжжПЩФмадЪЧЯТгЮЕФЗўЮёЛсЙиБеЃЌетНЋЛсДјРДСНИіЮЪЬтЃКЕквЛИіЪЧЃКЩЯгЮЗўЮёМЬајЧыЧѓЙиБеЕФЭјТчЗўЮёЃЌжБЕНКФОЁЭјТчзЪдДЃЌВЂЧвНЕЕЭЯЕЭГадФмЁЃЕкЖўИіЪЧЃКгУЛЇЬхбщНЋЪЧдуИтЕФЧвВЛПЩдЄВтЕФЁЃ
ЯћЗбепгІЭЈЙ§ДњРэРДЕїгУдЖГЬЗўЮёЃЌИУДњРэЕФааЮЊРрЫЦгкЕчТЗжаЕФЖЯТЗЦїЁЃЕБСЌајЕФЧыЧѓЪЇАмЕФДЮЪ§ГЌЙ§уажЕЪБЃЌЖЯТЗЦїНЋЬјеЂвЛЖЮЪБМфЃЌВЂЧвдкЬјеЂЕФетЖЮЪБМфФкЃЌЫљгаЕФЕїгУдЖГЬЗўЮёЕФГЂЪдЖМНЋСЂМДЪЇАмЁЃЕБГЌЙ§СЫЖЯТЗЦїЬјеЂЪБМфжЎКѓЃЌЖЯТЗЦїНЋдЪаэгаЯоЪ§СПЕФВтЪдЧыЧѓЭЈЙ§ЁЃШчЙћетаЉЧыЧѓГЩЙІЃЌдђЖЯТЗЦїНЋЛжИДе§ГЃВйзїЁЃЗёдђЃЌШчЙћгавЛИіЧыЧѓЪЇАмЃЌдђЖЯТЗЦїдйДЮЬјеЂЁЃЖдгк
вЛИігІгУЪдЭМГЂЪдЕїгУвЛИідЖГЬЗўЮёЛђепЛёШЁЙВЯэзЪдДЃЌВЂЧвИУВйзїКмШнвзЕФЪЇАмЕФЧщПіРДЫЕЃЌ етИіФЃЪНЗЧГЃЪЪгУ
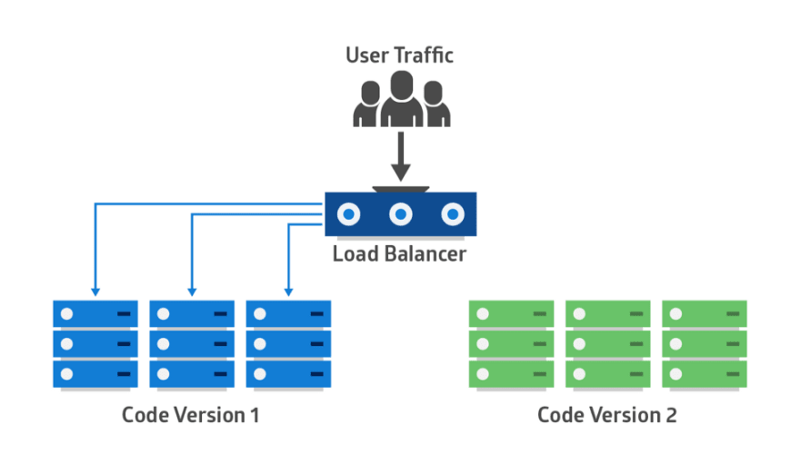
РЖТЬЗЂВМФЃЪН
дкЮЂЗўЮёМмЙЙжаЃЌвЛИігІгУГЬађПЩвдОпгааэЖрЮЂЗўЮёЁЃ ШчЙћЮвУЧдкЭЃжЙЫљгаЗўЮёжЎКѓШЛКѓВПЪ№діЧПАцБОЃЌдђЭЃЛњЪБМфНЋЪЧОоДѓЕФЃЌВЂЧвПЩФмгАЯьвЕЮёЁЃЭЌбљЃЌЛиЙіНЋЪЧвЛГЁиЌУЮЁЃРЖТЬЗЂВМФЃЪНПЩвдБмУтетжжЧщПіЁЃ
ЪЕЪЉРЖТЬЗЂВМФЃЪНПЩвдМѕЩйЛђЯћГ§ЭЃЛњЪБМфЃЌЫќЭЈЙ§дЫааСНИіЯрЭЌЕФЩњВњЛЗОГЃКBlueКЭGreenЃЌРДЪЕЯжетвЛФПБъЁЃетРяЮвУЧМйЩшТЬЩЋЪЧвбДцдкЕФЙЄзїЪЕР§ЃЌРЖЩЋЪЧИУгІгУГЬађЕФаТАцБОЁЃдкШЮКЮЪБКђЃЌжЛгавЛИіЛЗОГДІгкЛюЖЏзДЬЌЃЌИУЛюЖЏЛЗОГЮЊЫљгаЩњВњСїСПЬсЙЉЗўЮёЁЃ
ЫљгадЦЦНЬЈОљЬсЙЉгУгкЪЕЪЉРЖТЬЩЋВПЪ№ЕФбЁЯюЁЃ
|









