| БрМЭЦМі: |
|
БОЮФжївЊНщЩмСЫ ЪВУДЪЧSpring cloudЁЂSpring Cloud ЕФАцБОЁЂSpring
Cloud ЕФЗўЮёЗЂЯжПђМмЁЊЁЊEurekaЁЂИКдиОљКтжЎ RibbonЁЂЪВУДЪЧ Open
FeignЁЂБиВЛПЩЩйЕФ HystrixЁЂЮЂЗўЮёЭјЙиЁЊЁЊZuulЁЂSpring CloudХфжУЙмРэЁЊЁЊConfigЁЂв§Гі Spring Cloud BusЕШЯрЙиФкШнЁЃ
БОЮФРДздгкОђН№ЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЪзЯШЮвИјДѓМвПДвЛеХЭМЃЌШчЙћДѓМвЖдетеХЭМгааЉЕиЗНВЛЬЋРэНтЕФЛАЃЌЮвЯЃЭћФуУЧПДЭъЮветЦЊЮФеТЛсЛаШЛДѓЮђЁЃ
змЬхМмЙЙ
ЪВУДЪЧSpring cloud
ЙЙНЈЗжВМЪНЯЕЭГВЛашвЊИДдгКЭШнвзГіДэЁЃSpring Cloud ЮЊзюГЃМћЕФЗжВМЪНЯЕЭГФЃЪНЬсЙЉСЫвЛжжМђЕЅЧввзгкНгЪмЕФБрГЬФЃаЭЃЌАяжњПЊЗЂШЫдБЙЙНЈгаЕЏадЕФЁЂПЩППЕФЁЂаЕїЕФгІгУГЬађЁЃSpring
Cloud ЙЙНЈгк Spring Boot жЎЩЯЃЌЪЙЕУПЊЗЂепКмШнвзШыЪжВЂПьЫйгІгУгкЩњВњжаЁЃ
ЙйЗНЙћШЛЙйЗНЃЌНщЩмЖМетУДгаАхгаблЕФЁЃ
ЮвЫљРэНтЕФ Spring Cloud ОЭЪЧЮЂЗўЮёЯЕЭГМмЙЙЕФвЛеОЪННтОіЗНАИЃЌдкЦНЪБЮвУЧЙЙНЈЮЂЗўЮёЕФЙ§ГЬжаашвЊзіШч
ЗўЮёЗЂЯжзЂВс ЁЂХфжУжааФ ЁЂЯћЯЂзмЯп ЁЂИКдиОљКт ЁЂЖЯТЗЦї ЁЂЪ§ОнМрПи ЕШВйзїЃЌЖј Spring Cloud
ЮЊЮвУЧЬсЙЉСЫвЛЬзМђвзЕФБрГЬФЃаЭЃЌЪЙЮвУЧФмдк Spring Boot ЕФЛљДЁЩЯЧсЫЩЕиЪЕЯжЮЂЗўЮёЯюФПЕФЙЙНЈЁЃ
Spring Cloud ЕФАцБО
ЕБШЛетИіжЛЪЧИіЬтЭтЛАЁЃ
Spring Cloud ЕФАцБОКХВЂВЛЪЧЮвУЧЭЈГЃМћЕФЪ§зжАцБОКХЃЌЖјЪЧвЛаЉКмЦцЙжЕФЕЅДЪЁЃетаЉЕЅДЪОљЮЊгЂЙњТзЖиЕиЬњеОЕФеОУћЁЃЭЌЪБИљОнзжФИБэЕФЫГађРДЖдгІАцБОЪБМфЫГађЃЌБШШчЃКзюдч
ЕФ Release АцБО AngelЃЌЕкЖўИі Release АцБО BrixtonЃЈгЂЙњЕиУћЃЉЃЌШЛКѓЪЧ
CamdenЁЂ DalstonЁЂEdgwareЁЂFinchleyЁЂGreenwichЁЂHoxtonЁЃ
Spring Cloud ЕФЗўЮёЗЂЯжПђМмЁЊЁЊEureka
EurekaЪЧЛљгкRESTЃЈДњБэадзДЬЌзЊвЦЃЉЕФЗўЮёЃЌжївЊдкAWSдЦжагУгкЖЈЮЛЗўЮёЃЌвдЪЕЯжИКдиОљКтКЭжаМфВуЗўЮёЦїЕФЙЪеЯзЊвЦЁЃЮвУЧГЦДЫЗўЮёЮЊEurekaЗўЮёЦїЁЃEurekaЛЙДјгавЛИіЛљгкJavaЕФПЭЛЇЖЫзщМўEureka
ClientЃЌЫќЪЙгыЗўЮёЕФНЛЛЅБфЕУИќМгШнвзЁЃПЭЛЇЖЫЛЙОпгавЛИіФкжУЕФИКдиЦНКтЦїЃЌПЩвджДааЛљБОЕФбЛЗИКдиЦНКтЁЃдкNetflixЃЌИќИДдгЕФИКдиОљКтЦїНЋEurekaАќзАЦ№РДЃЌвдЛљгкСїСПЃЌзЪдДЪЙгУЃЌДэЮѓЬѕМўЕШЖржжвђЫиЬсЙЉМгШЈИКдиОљКтЃЌвдЬсЙЉГіЩЋЕФЕЏадЁЃ
змЕФРДЫЕЃЌEureka ОЭЪЧвЛИіЗўЮёЗЂЯжПђМмЁЃКЮЮЊЗўЮёЃЌКЮгжЮЊЗЂЯжФиЃП
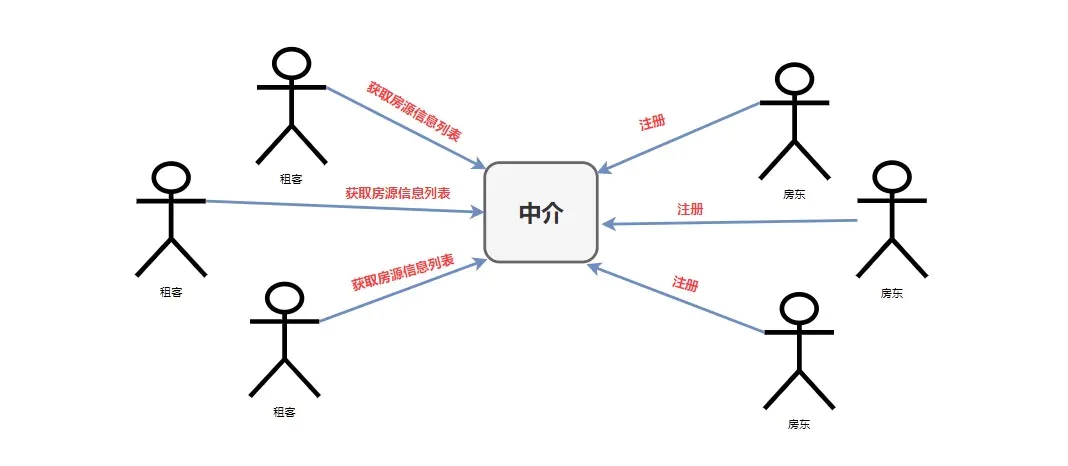
ОйвЛИіЩњЛюжаЕФР§згЃЌОЭБШШчЮвУЧЦНЪБзтЗПзгевжаНщЕФЪТЧщЁЃ
дкУЛгажаНщЕФЪБКђЮвУЧашвЊвЛИівЛИіШЅбАевЪЧЗёгаЗПЮнвЊГізтЕФЗПЖЋЃЌетЯдШЛЛсЗЧГЃЕФЗбСІЃЌвЛФуевЦОвЛИіШЫЕФФмСІЪЧевВЛЕНКмЖрЗПдДЙЉФубЁдёЃЌдйепФувВРСЕУетУДевЯТШЅ(евСЫетУДОУЃЌУЛгаКЯЪЪЕФжЛФмНЋОЭ)ЁЃетРяЕФЮвУЧОЭЯрЕБгкЮЂЗўЮёжаЕФ
Consumer ЃЌЖјФЧаЉЗПЖЋОЭЯрЕБгкЮЂЗўЮёжаЕФ Provider ЁЃЯћЗбеп Consumer ашвЊЕїгУЬсЙЉеп
Provider ЬсЙЉЕФвЛаЉЗўЮёЃЌОЭЯёЮвУЧЯждкашвЊзтЫћУЧЕФЗПзгвЛбљЁЃ
ЕЋЪЧШчЙћжЛЪЧзтПЭКЭЗПЖЋжЎМфНјаабАевЕФЛАЃЌЫћУЧЕФаЇТЪЪЧКмЕЭЕФЃЌЗПЖЋевВЛЕНзтПЭзЌВЛЕНЧЎЃЌзтПЭевВЛЕНЗПЖЋзЁВЛСЫЗПЁЃЫљвдЃЌКѓРДЗПЖЋПЯЖЈОЭЯыЕНСЫЙуВЅздМКЕФЗПдДаХЯЂ(БШШчдкНжБпЬљЬљаЁЙуИц)ЃЌетбљЖдгкЗПЖЋРДЫЕвбОЭъГЩЫћЕФШЮЮё(НЋЗПдДЙЋВМГіШЅ)ЃЌЕЋЪЧгаСНИіЮЪЬтОЭГіЯжСЫЁЃЕквЛЁЂЦфЫћВЛЪЧзтПЭЕФЖМФмЪеЕНетжжзтЗПЯћЯЂЃЌетдкЯжЪЕЪРНчУЛЪВУДЃЌЕЋЪЧдкМЦЫуЛњЕФЪРНчжаОЭЛсГіЯжзЪдДЯћКФЕФЮЪЬтСЫЁЃЕкЖўЁЂзтПЭетбљЛЙЪЧКмФбевЕНФуЃЌЪдЯывЛЯТЮвашвЊзтЗПЃЌЮвЛЙашвЊЖЋвЛИіЮївЛИіЕиШЅевНжБпаЁЙуИцЃЌТщВЛТщЗГЃП

ФЧдѕУДАьФиЃПЮвУЧЕБШЛВЛЛсФЧУДЩЕКѕКѕЕФЃЌЕквЛЪБМфОЭЪЧШЅев жаНщ бНЃЌЫќЮЊЮвУЧЬсЙЉСЫЭГвЛЗПдДЕФЕиЗНЃЌЮвУЧЯћЗбепжЛашвЊХмЕНЫќФЧРяШЅевОЭааСЫЁЃЖјЖдгкЗПЖЋРДЫЕЃЌЫћУЧвВжЛашвЊАбЗПдДдкжаНщФЧРяЗЂВМОЭааСЫЁЃ

ФЧУДЯждкЃЌЮвУЧЕФФЃЪНОЭЪЧетбљЕФСЫЁЃ
ЕЋЪЧЃЌетИіЪБКђЛЙЛсГіЯжвЛаЉЮЪЬтЁЃ
ЗПЖЋзЂВсжЎКѓШчЙћВЛЯыТєЗПзгСЫдѕУДАьЃПЮвУЧЪЧВЛЪЧашвЊШУЗПЖЋЖЈЦкајдМЃПШчЙћЗПЖЋВЛНјааајдМЪЧВЛЪЧвЊНЋЫћУЧДгжаНщФЧРяЕФзЂВсСаБэжавЦГ§ЁЃ
зтПЭЪЧВЛЪЧвВвЊНјаазЂВсФиЃПВЛШЛКЯЭЌввЗНдѕУДРДФиЃП
жаНщПЩВЛПЩвдзіСЌЫјЕъФиЃПШчЙћетвЛИіЕъвђЮЊФГаЉВЛПЩПЙСІвђЫиЖјЮоЗЈЪЙгУЃЌФЧУДЮвУЧЪЧЗёПЩвдЛЛвЛИіСЌЫјЕъФиЃП
еыЖдЩЯУцЕФЮЪЬтЮвУЧРДжиаТЙЙНЈвЛЯТЩЯУцЕФФЃЪНЭМ
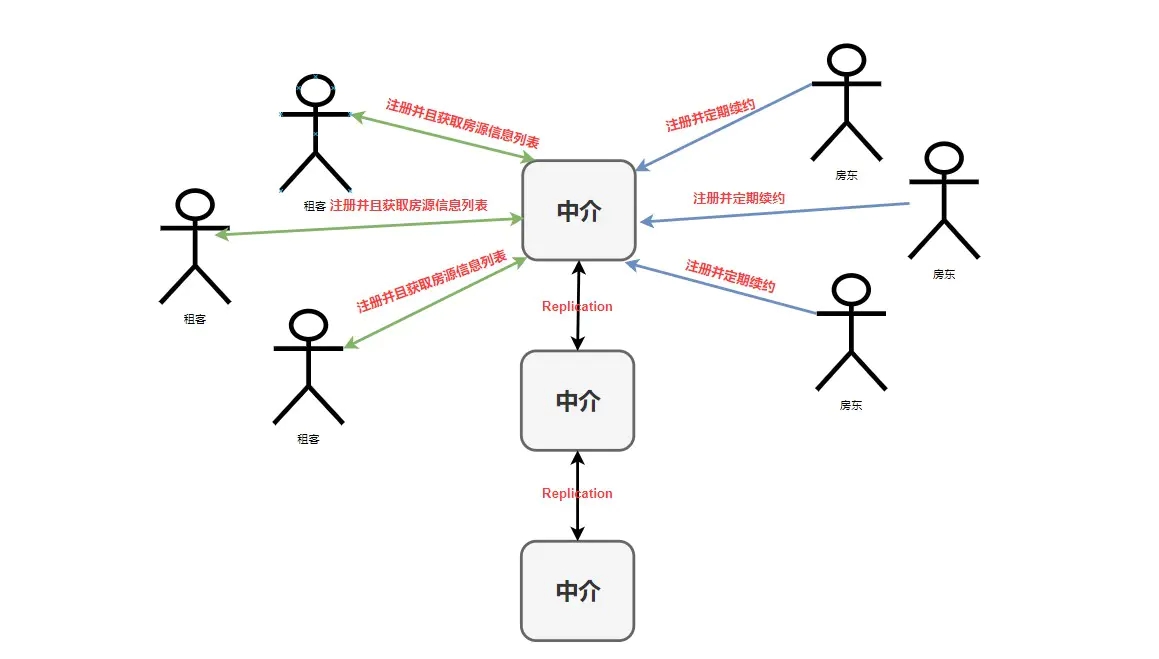
КУСЫЃЌОйЭъетИі ЮвУЧОЭПЩвдРДПДЙигк Eureka ЕФвЛаЉЛљДЁИХФюСЫЃЌФуЛсЗЂЯжетЖЋЮїРэНтЦ№РДдѕУДетУДМђЕЅЁЃ
ЗўЮёЗЂЯжЃКЦфЪЕОЭЪЧвЛИіЁАжаНщЁБЃЌећИіЙ§ГЬжагаШ§ИіНЧЩЋЃКЗўЮёЬсЙЉеп(ГізтЗПзгЕФ)ЁЂЗўЮёЯћЗбеп(зтПЭ)ЁЂЗўЮёжаНщ(ЗПЮнжаНщ)ЁЃ
ЗўЮёЬсЙЉепЃК ОЭЪЧЬсЙЉвЛаЉздМКФмЙЛжДааЕФвЛаЉЗўЮёИјЭтНчЁЃ
ЗўЮёЯћЗбепЃК ОЭЪЧашвЊЪЙгУвЛаЉЗўЮёЕФЁАгУЛЇЁБЁЃ
ЗўЮёжаНщЃК ЦфЪЕОЭЪЧЗўЮёЬсЙЉепКЭЗўЮёЯћЗбепжЎМфЕФЁАЧХСКЁБЃЌЗўЮёЬсЙЉепПЩвдАбздМКзЂВсЕНЗўЮёжаНщФЧРяЃЌЖјЗўЮёЯћЗбепШчашвЊЯћЗбвЛаЉЗўЮё(ЪЙгУвЛаЉЙІФм)ОЭПЩвддкЗўЮёжаНщжабАевзЂВсдкЗўЮёжаНщЕФЗўЮёЬсЙЉепЁЃ
ЗўЮёзЂВс RegisterЃК
ЙйЗННтЪЭЃКЕБ Eureka ПЭЛЇЖЫЯђ Eureka Server зЂВсЪБЃЌЫќЬсЙЉздЩэЕФдЊЪ§ОнЃЌБШШчIPЕижЗЁЂЖЫПкЃЌдЫаазДПіжИЪОЗћURLЃЌжївГЕШЁЃ
НсКЯжаНщРэНтЃКЗПЖЋ (ЬсЙЉеп Eureka Client Provider)дкжаНщ (ЗўЮёЦї Eureka
Server) ФЧРяЕЧМЧЗПЮнЕФаХЯЂЃЌБШШчУцЛ§ЃЌМлИёЃЌЕиЖЮЕШЕШ(дЊЪ§Он metaData)ЁЃ
ЗўЮёајдМ RenewЃК
ЙйЗННтЪЭЃКEureka ПЭЛЇЛсУПИє30Уы(ФЌШЯЧщПіЯТ)ЗЂЫЭвЛДЮаФЬјРДајдМЁЃ ЭЈЙ§ајдМРДИцжЊ Eureka
Server ИУ Eureka ПЭЛЇШдШЛДцдкЃЌУЛгаГіЯжЮЪЬтЁЃ е§ГЃЧщПіЯТЃЌШчЙћ Eureka Serverдк90УыУЛгаЪеЕН
Eureka ПЭЛЇЕФајдМЃЌЫќЛсНЋЪЕР§ДгЦфзЂВсБэжаЩОГ§ЁЃ
НсКЯжаНщРэНтЃКЗПЖЋ (ЬсЙЉеп Eureka Client Provider) ЖЈЦкИцЫпжаНщ (ЗўЮёЦї
Eureka Server) ЮвЕФЗПзгЛЙзт(ајдМ) ЃЌжаНщ (ЗўЮёЦїEureka Server) ЪеЕНжЎКѓМЬајБЃСєЗПЮнЕФаХЯЂЁЃ
ЛёШЁзЂВсСаБэаХЯЂ Fetch RegistriesЃК
ЙйЗННтЪЭЃКEureka ПЭЛЇЖЫДгЗўЮёЦїЛёШЁзЂВсБэаХЯЂЃЌВЂНЋЦфЛКДцдкБОЕиЁЃПЭЛЇЖЫЛсЪЙгУИУаХЯЂВщевЦфЫћЗўЮёЃЌДгЖјНјаадЖГЬЕїгУЁЃИУзЂВсСаБэаХЯЂЖЈЦкЃЈУП30УыжгЃЉИќаТвЛДЮЁЃУПДЮЗЕЛизЂВсСаБэаХЯЂПЩФмгы
Eureka ПЭЛЇЖЫЕФЛКДцаХЯЂВЛЭЌ, Eureka ПЭЛЇЖЫздЖЏДІРэЁЃШчЙћгЩгкФГжждвђЕМжТзЂВсСаБэаХЯЂВЛФмМАЪБЦЅХфЃЌEureka
ПЭЛЇЖЫдђЛсжиаТЛёШЁећИізЂВсБэаХЯЂЁЃ Eureka ЗўЮёЦїЛКДцзЂВсСаБэаХЯЂЃЌећИізЂВсБэвдМАУПИігІгУГЬађЕФаХЯЂНјааСЫбЙЫѕЃЌбЙЫѕФкШнКЭУЛгабЙЫѕЕФФкШнЭъШЋЯрЭЌЁЃEureka
ПЭЛЇЖЫКЭ Eureka ЗўЮёЦїПЩвдЪЙгУJSON / XMLИёЪННјааЭЈбЖЁЃдкФЌШЯЕФЧщПіЯТ Eureka
ПЭЛЇЖЫЪЙгУбЙЫѕ JSON ИёЪНРДЛёШЁзЂВсСаБэЕФаХЯЂЁЃ
НсКЯжаНщРэНтЃКзтПЭ(ЯћЗбеп Eureka Client Consumer) ШЅжаНщ (ЗўЮёЦї Eureka
Server) ФЧРяЛёШЁЫљгаЕФЗПЮнаХЯЂСаБэ (ПЭЛЇЖЫСаБэ Eureka Client List) ЃЌЖјЧвзтПЭЮЊСЫЛёШЁзюаТЕФаХЯЂЛсЖЈЦкЯђжаНщ
(ЗўЮёЦї Eureka Server) ФЧРяЛёШЁВЂИќаТБОЕиСаБэЁЃ
ЗўЮёЯТЯп CancelЃК
ЙйЗННтЪЭЃКEurekaПЭЛЇЖЫдкГЬађЙиБеЪБЯђEurekaЗўЮёЦїЗЂЫЭШЁЯћЧыЧѓЁЃ ЗЂЫЭЧыЧѓКѓЃЌИУПЭЛЇЖЫЪЕР§аХЯЂНЋДгЗўЮёЦїЕФЪЕР§зЂВсБэжаЩОГ§ЁЃИУЯТЯпЧыЧѓВЛЛсздЖЏЭъГЩЃЌЫќашвЊЕїгУвдЯТФкШнЃКDiscoveryManager.getInstance().shutdownComponent();
НсКЯжаНщРэНтЃКЗПЖЋ (ЬсЙЉеп Eureka Client Provider) ИцЫпжаНщ (ЗўЮёЦї
Eureka Server) ЮвЕФЗПзгВЛзтСЫЃЌжаНщжЎКѓОЭНЋзЂВсЕФЗПЮнаХЯЂДгСаБэжаЬоГ§ЁЃ
ЗўЮёЬоГ§ EvictionЃК
ЙйЗННтЪЭЃКдкФЌШЯЕФЧщПіЯТЃЌЕБEurekaПЭЛЇЖЫСЌај90Уы(3ИіајдМжмЦк)УЛгаЯђEurekaЗўЮёЦїЗЂЫЭЗўЮёајдМЃЌМДаФЬјЃЌEurekaЗўЮёЦїЛсНЋИУЗўЮёЪЕР§ДгЗўЮёзЂВсСаБэЩОГ§ЃЌМДЗўЮёЬоГ§ЁЃ
НсКЯжаНщРэНтЃКЗПЖЋ(ЬсЙЉеп Eureka Client Provider) ЛсЖЈЦкСЊЯЕ жаНщ (ЗўЮёЦї
Eureka Server) ИцЫпЫћЮвЕФЗПзгЛЙзт(ајдМ)ЃЌШчЙћжаНщ (ЗўЮёЦї Eureka Server)
ГЄЪБМфУЛЪеЕНЬсЙЉепЕФаХЯЂЃЌФЧУДжаНщЛсНЋЫћЕФЗПЮнаХЯЂИјЯТМм(ЗўЮёЬоГ§)ЁЃ
ЯТУцОЭЪЧ Netflix ЙйЗНИјГіЕФ Eureka МмЙЙЭМЃЌФуЛсЗЂЯжКЭЮвУЧЧАУцЛЕФжаНщЭМБ№ЮоЖўжТЁЃ
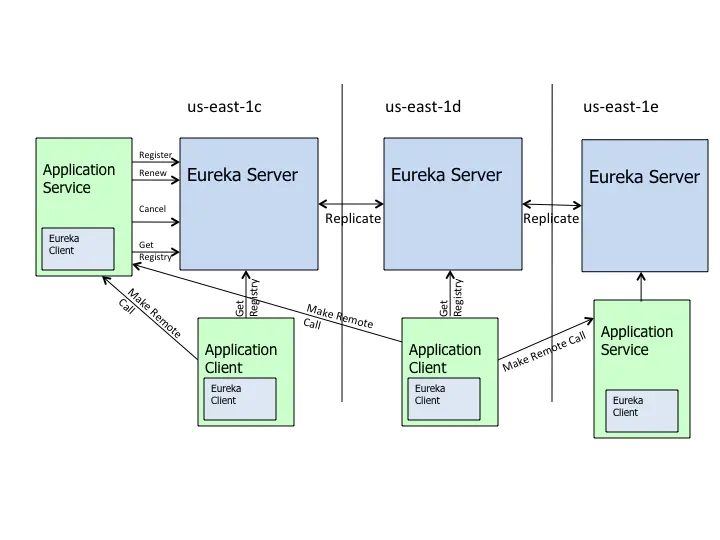
ЕБШЛЃЌПЩвдГфЕБЗўЮёЗЂЯжЕФзщМўгаКмЖрЃКZookeeper ЃЌConsul ЃЌ Eureka ЕШЁЃ
ИќЖрЙигк Eureka ЕФжЊЪЖ(здЮвБЃЛЄЃЌГѕЪМзЂВсВпТдЕШЕШ)ПЩвдздМКШЅЙйЭјВщПДЃЌЛђепВщПДетЦЊЮФеТ
ЩюШыРэНт EurekaЁЃ
ИКдиОљКтжЎ Ribbon
ЪВУДЪЧ RestTemplate?
ВЛЪЧНВ Ribbon УДЃПдѕУДГЖЕНСЫ RestTemplate СЫЃПФуЯШБ№МБЃЌЬ§ЮвТ§Т§ЕРРДЁЃ
ЮвВЛЬ§ЮвВЛЬ§ЮвВЛЬ§ ЁЃ
ЮвОЭЫЕвЛОфЃЁRestTemplateЪЧSpringЬсЙЉЕФвЛИіЗУЮЪHttpЗўЮёЕФПЭЛЇЖЫРрЃЌдѕУДЫЕФиЃПОЭЪЧЮЂЗўЮёжЎМфЕФЕїгУЪЧЪЙгУЕФ
RestTemplate ЁЃБШШчетИіЪБКђЮвУЧ ЯћЗбепB ашвЊЕїгУ ЬсЙЉепA ЫљЬсЙЉЕФЗўЮёЮвУЧОЭашвЊетУДаДЁЃШчЮвЯТУцЕФЮБДњТыЁЃ
@Autowired
private RestTemplate restTemplate;
// етРяЪЧЬсЙЉепAЕФipЕижЗЃЌЕЋЪЧШчЙћЪЙгУСЫ Eureka ФЧУДОЭгІИУЪЧЬсЙЉепAЕФУћГЦ
private static final String SERVICE_PROVIDER_A
= "http://localhost:8081";
@PostMapping("/judge")
public boolean judge (@RequestBody Request request)
{
String url = SERVICE_PROVIDER_A + "/service1";
return restTemplate.postForObject (url, request,
Boolean.class);
} |
ШчЙћФуЖддДТыИааЫШЄЕФЛАЃЌФуЛсЗЂЯжЩЯУцЮвУЧЫљНВЕФ Eureka ПђМмжаЕФ зЂВсЁЂајдМ ЕШЃЌЕзВуЖМЪЧЪЙгУЕФ
RestTemplate ЁЃ
ЮЊЪВУДашвЊ RibbonЃП
Ribbon ЪЧ Netflix ЙЋЫОЕФвЛИіПЊдДЕФИКдиОљКт ЯюФПЃЌЪЧвЛИіПЭЛЇЖЫ/НјГЬФкИКдиОљКтЦїЃЌдЫаадкЯћЗбепЖЫЁЃ
ЮвУЧдйОйИі ЃЌБШШчЮвУЧЩшМЦСЫвЛИіУыЩБЯЕЭГЃЌЕЋЪЧЮЊСЫећИіЯЕЭГЕФ ИпПЩгУ ЃЌЮвУЧашвЊНЋетИіЯЕЭГзівЛИіМЏШКЃЌЖјетИіЪБКђЮвУЧЯћЗбепОЭПЩвдгЕгаЖрИіУыЩБЯЕЭГЕФЕїгУЭООЖСЫЃЌШчЯТЭМЁЃ
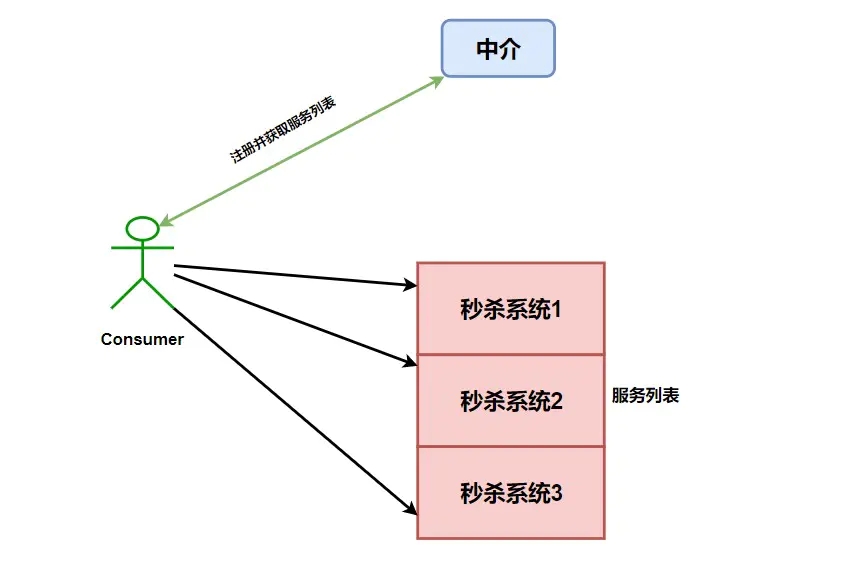
ШчЙћетИіЪБКђЮвУЧУЛгаНјаавЛаЉ ОљКтВйзї ЃЌШчЙћЮвУЧЖд УыЩБЯЕЭГ1 НјааДѓСПЕФЕїгУЃЌЖјСэЭтСНИіЛљБОВЛЧыЧѓЃЌОЭЛсЕМжТ
УыЩБЯЕЭГ1 БРРЃЃЌЖјСэЭтСНИіОЭБфГЩСЫПўРмЃЌФЧУДЮвУЧЮЊЪВУДЛЙвЊзіМЏШКЃЌЮвУЧИпПЩгУЬхЯжЕФвтвхгждкФФФиЃП
Ыљвд Ribbon ГіЯжСЫЃЌзЂвтЮвУЧЩЯУцМгДжЕФМИИізжЁЊЁЊдЫаадкЯћЗбепЖЫЁЃжИЕФЪЧЃЌRibbon ЪЧдЫаадкЯћЗбепЖЫЕФИКдиОљКтЦїЃЌШчЯТЭМЁЃ
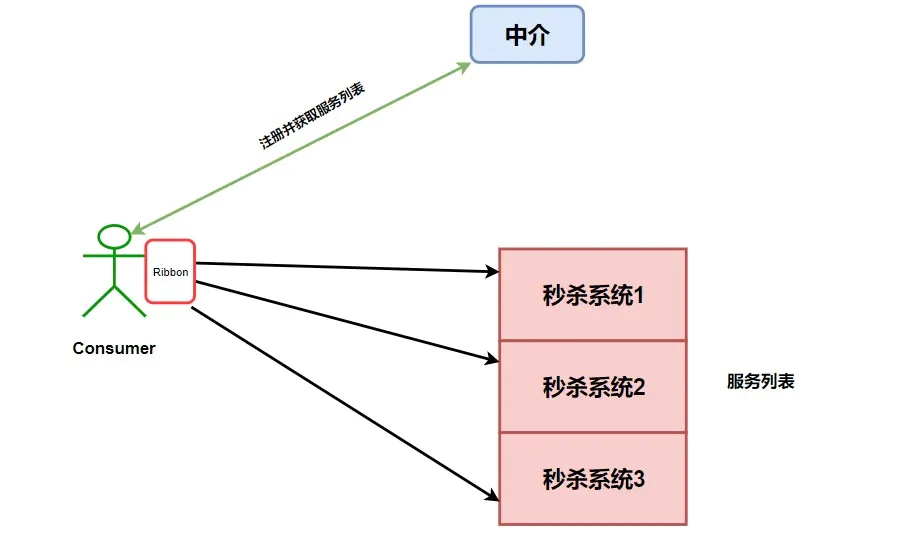
ЦфЙЄзїдРэОЭЪЧ Consumer ЖЫЛёШЁЕНСЫЫљгаЕФЗўЮёСаБэжЎКѓЃЌдкЦфФкВПЪЙгУИКдиОљКтЫуЗЈЃЌНјааЖдЖрИіЯЕЭГЕФЕїгУЁЃ
Nginx КЭ Ribbon ЕФЖдБШ
ЬсЕН ИКдиОљКт ОЭВЛЕУВЛЬсЕНДѓУћЖІЖІЕФ Nignx СЫЃЌЖјКЭ Ribbon ВЛЭЌЕФЪЧЃЌЫќЪЧвЛжжМЏжаЪНЕФИКдиОљКтЦїЁЃ
КЮЮЊМЏжаЪНФиЃПМђЕЅРэНтОЭЪЧ НЋЫљгаЧыЧѓЖММЏжаЦ№РДЃЌШЛКѓдйНјааИКдиОљКтЁЃШчЯТЭМЁЃ
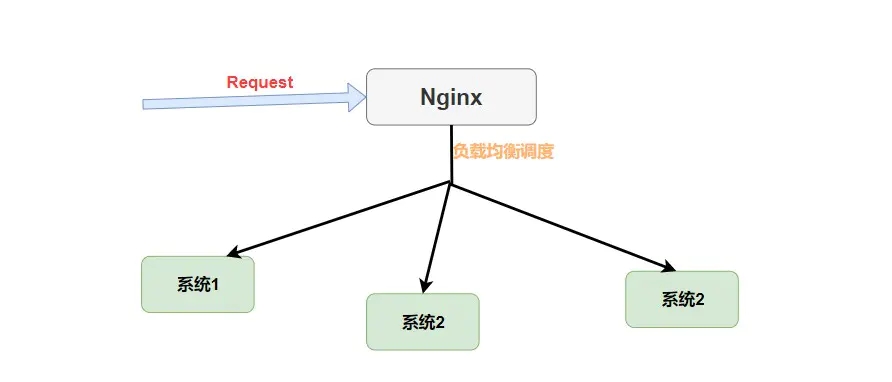
ЮвУЧПЩвдПДЕН Nginx ЪЧНгЪеСЫЫљгаЕФЧыЧѓНјааИКдиОљКтЕФЃЌЖјЖдгк Ribbon РДЫЕЫќЪЧдкЯћЗбепЖЫНјааЕФИКдиОљКтЁЃШчЯТЭМЁЃ
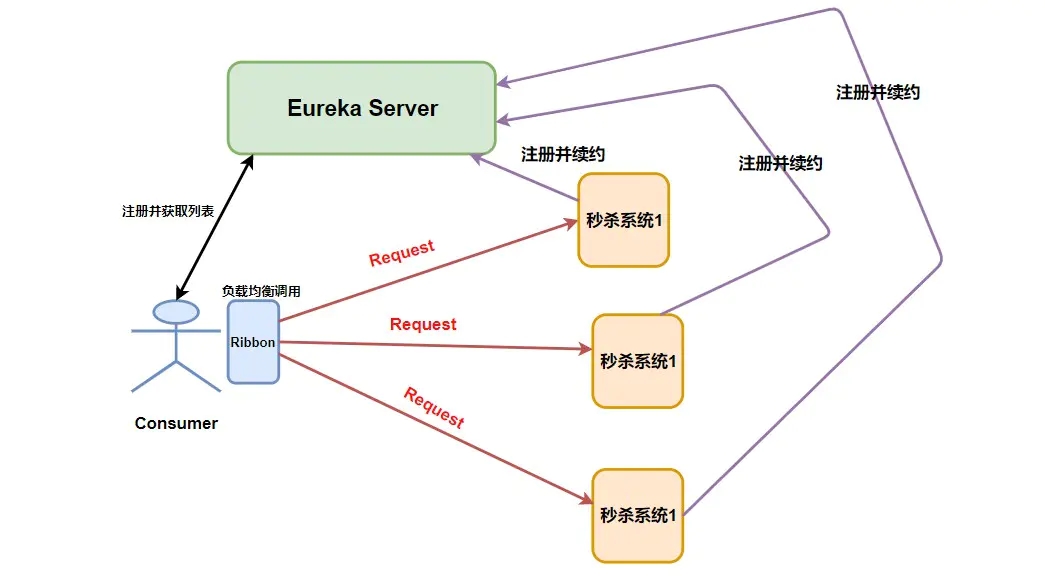
ЧызЂвт Request ЕФЮЛжУЃЌдк Nginx жаЧыЧѓЪЧЯШНјШыИКдиОљКтЦїЃЌЖјдк Ribbon жаЪЧЯШдкПЭЛЇЖЫНјааИКдиОљКтВХНјааЧыЧѓЕФЁЃ
Ribbon ЕФМИжжИКдиОљКтЫуЗЈ
ИКдиОљКтЃЌВЛЙм Nginx ЛЙЪЧ Ribbon ЖМашвЊЦфЫуЗЈЕФжЇГжЃЌШчЙћЮвУЛМЧДэЕФЛА Nginx ЪЙгУЕФЪЧ
ТжбЏКЭМгШЈТжбЏЫуЗЈЁЃЖјдк Ribbon жагаИќЖрЕФИКдиОљКтЕїЖШЫуЗЈЃЌЦфФЌШЯЪЧЪЙгУЕФ RoundRobinRule
ТжбЏВпТдЁЃ
RoundRobinRuleЃКТжбЏВпТдЁЃRibbon ФЌШЯВЩгУЕФВпТдЁЃШєОЙ§вЛТжТжбЏУЛгаевЕНПЩгУЕФ
providerЃЌЦфзюЖрТжбЏ 10 ТжЁЃШєзюжеЛЙУЛгаевЕНЃЌдђЗЕЛи nullЁЃ
RandomRule: ЫцЛњВпТдЃЌДгЫљгаПЩгУЕФ provider жаЫцЛњбЁдёвЛИіЁЃ
RetryRule: жиЪдВпТдЁЃЯШАДее RoundRobinRule ВпТдЛёШЁ providerЃЌШєЛёШЁЪЇАмЃЌдђдкжИЖЈЕФЪБЯоФкжиЪдЁЃФЌШЯЕФЪБЯоЮЊ
500 КСУыЁЃ
ЛЙгаКмЖрЃЌетРяВЛвЛвЛОй СЫЃЌФузюашвЊжЊЕРЕФЪЧФЌШЯТжбЏЫуЗЈЃЌВЂЧвПЩвдИќЛЛФЌШЯЕФИКдиОљКтЫуЗЈЃЌжЛашвЊдкХфжУЮФМўжазіГіаоИФОЭааЁЃ
providerName:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule |
ЕБШЛЃЌдк Ribbon жаФуЛЙПЩвдздЖЈвхИКдиОљКтЫуЗЈЃЌФужЛашвЊЪЕЯж IRule НгПкЃЌШЛКѓаоИФХфжУЮФМўЛђепздЖЈвх
Java Config РрЁЃ
ЪВУДЪЧ Open Feign
гаСЫ EurekaЃЌRestTemplateЃЌRibbon ЮвУЧОЭПЩвд
гфПьЕиНјааЗўЮёМфЕФЕїгУСЫЃЌЕЋЪЧЪЙгУ RestTemplate ЛЙЪЧВЛЗНБуЃЌЮвУЧУПДЮЖМвЊНјааетбљЕФЕїгУЁЃ
@Autowired
private RestTemplate restTemplate;
// етРяЪЧЬсЙЉепAЕФipЕижЗЃЌЕЋЪЧШчЙћЪЙгУСЫ Eureka ФЧУДОЭгІИУЪЧЬсЙЉепAЕФУћГЦ
private static final String SERVICE_PROVIDER_A
= "http://localhost:8081";
@PostMapping("/judge")
public boolean judge (@RequestBody Request request)
{
String url = SERVICE_PROVIDER_A + "/service1";
// ЪЧВЛЪЧЬЋТщЗГСЫЃПЃПЃПУПДЮЖМвЊ urlЁЂЧыЧѓЁЂЗЕЛиРраЭЕФ
return restTemplate.postForObject (url, request,
Boolean.class);
} |
етбљУПДЮЖМЕїгУ RestRemplate ЕФ API ЪЧЗёЬЋТщЗГЃЌЮвФмВЛФмЯёЕїгУдРДДњТывЛбљНјааИїИіЗўЮёМфЕФЕїгУФиЃП
ДЯУїЕФаЁХѓгбПЯЖЈЯыЕНСЫЃЌФЧОЭгУ гГЩф бНЃЌОЭЯёгђУћКЭIPЕижЗЕФгГЩфЁЃЮвУЧПЩвдНЋБЛЕїгУЕФЗўЮёДњТыгГЩфЕНЯћЗбепЖЫЃЌетбљЮвУЧОЭПЩвд
ЁАЮоЗьПЊЗЂЁБРВЁЃ
OpenFeign вВЪЧдЫаадкЯћЗбепЖЫЕФЃЌЪЙгУ Ribbon НјааИКдиОљКтЃЌЫљвд OpenFeign
жБНгФкжУСЫ RibbonЁЃ
дкЕМШыСЫ Open Feign жЎКѓЮвУЧОЭПЩвдНјаагфПьБраД Consumer
ЖЫДњТыСЫЁЃ
// ЪЙгУ @FeignClient
зЂНтРДжИЖЈЬсЙЉепЕФУћзж
@FeignClient(value = "eureka-client-provider")
public interface TestClient {
// етРявЛЖЈвЊзЂвташвЊЪЙгУЕФЪЧЬсЙЉепФЧЖЫЕФЧыЧѓЯрЖдТЗОЖЃЌетРяОЭЯрЕБгкгГЩфСЫ
@RequestMapping(value = "/provider/xxx",
method = RequestMethod.POST)
CommonResponse<List<Plan>> getPlans(@RequestBody
planGetRequest request);
} |
ШЛКѓЮвУЧдк Controller ОЭПЩвдЯёдРДЕїгУ Service
ВуДњТывЛбљЕїгУЫќСЫЁЃ
@RestController
public class TestController {
// етРяОЭЯрЕБгкдРДздЖЏзЂШыЕФ Service
@Autowired
private TestClient testClient;
// controller ЕїгУ service ВуДњТы
@RequestMapping(value = "/test", method
= RequestMethod.POST)
public CommonResponse<List<Plan>>
get(@RequestBody planGetRequest request) {
return testClient.getPlans(request);
}
} |
БиВЛПЩЩйЕФ Hystrix
ЪВУДЪЧ HystrixжЎШлЖЯКЭНЕМЖ

дкЗжВМЪНЛЗОГжаЃЌВЛПЩБмУтЕиЛсгааэЖрЗўЮёвРРЕЯюжаЕФФГаЉЪЇАмЁЃHystrixЪЧвЛИіПтЃЌПЩЭЈЙ§ЬэМгЕШД§ЪБМфШнЯоКЭШнДэТпМРДАяжњФњПижЦетаЉЗжВМЪНЗўЮёжЎМфЕФНЛЛЅЁЃHystrixЭЈЙ§ИєРыЗўЮёжЎМфЕФЗУЮЪЕуЃЌЭЃжЙЗўЮёжЎМфЕФМЖСЊЙЪеЯВЂЬсЙЉКѓБИбЁЯюРДЪЕЯжДЫФПЕФЃЌЫљгаетаЉЖМПЩвдЬсИпЯЕЭГЕФећЬхЕЏадЁЃ
змЬхРДЫЕ Hystrix ОЭЪЧвЛИіФмНјаа ШлЖЯ КЭ НЕМЖ ЕФПтЃЌЭЈЙ§ЪЙгУЫќФмЬсИпећИіЯЕЭГЕФЕЏадЁЃ
ФЧУДЪВУДЪЧ ШлЖЯКЭНЕМЖ ФиЃПдйОйИі ЃЌДЫЪБЮвУЧећИіЮЂЗўЮёЯЕЭГЪЧетбљЕФЁЃЗўЮёAЕїгУСЫЗўЮёBЃЌЗўЮёBдйЕїгУСЫЗўЮёCЃЌЕЋЪЧвђЮЊФГаЉдвђЃЌЗўЮёCЖЅВЛзЁСЫЃЌетИіЪБКђДѓСПЧыЧѓЛсдкЗўЮёCзшШћЁЃ
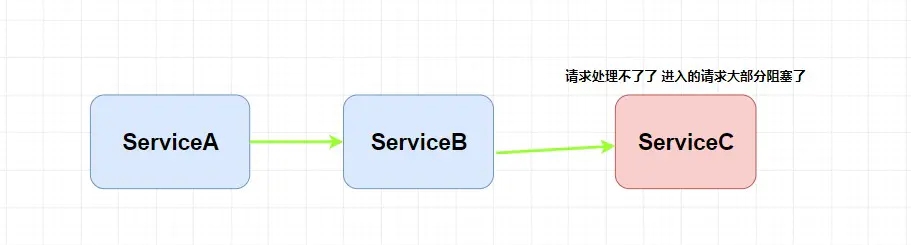
ЗўЮёCзшШћСЫЛЙКУЃЌБЯОЙжЛЪЧвЛИіЯЕЭГБРРЃСЫЁЃЕЋЪЧЧызЂвтетИіЪБКђвђЮЊЗўЮёCВЛФмЗЕЛиЯьгІЃЌФЧУДЗўЮёBЕїгУЗўЮёCЕФЕФЧыЧѓОЭЛсзшШћЃЌЭЌРэЗўЮёBзшШћСЫЃЌФЧУДЗўЮёAвВЛсзшШћБРРЃЁЃ
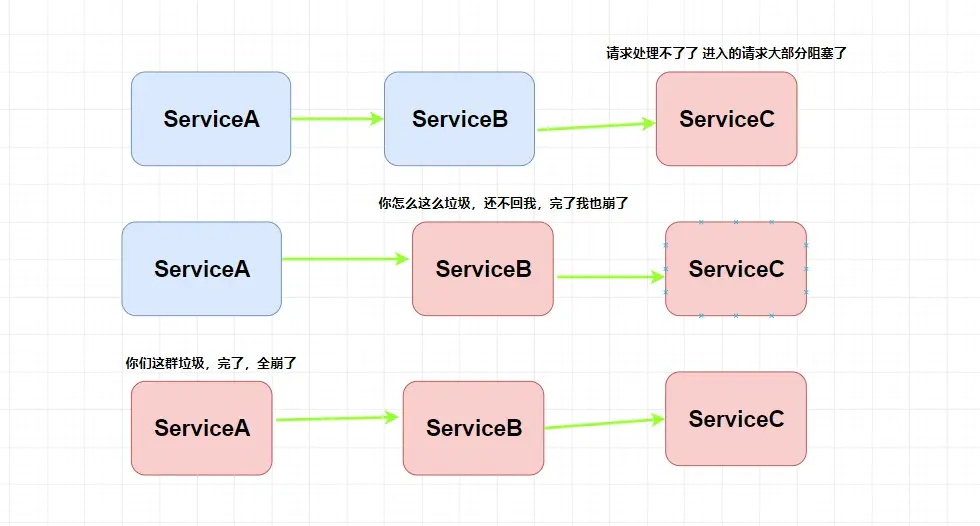
ЧызЂвтЃЌЮЊЪВУДзшШћЛсБРРЃЁЃвђЮЊетаЉЧыЧѓЛсЯћКФеМгУЯЕЭГЕФЯпГЬЁЂIO ЕШзЪдДЃЌЯћКФЭъФуетИіЯЕЭГЗўЮёЦїВЛОЭБРСЫУДЁЃ
етОЭНа ЗўЮёбЉБРЁЃТшвЎЃЌЩЯУцСНИі ШлЖЯ КЭ НЕМЖ ФуЖМУЛИјЮвНтЪЭЧхГўЃЌФуЯждкгжИјЮвГЖЪВУД
ЗўЮёбЉБР ЃП
Б№МБЃЌЬ§ЮвТ§Т§ЕРРДЁЃ

ВЛЬ§ЮввВЕУНВЯТШЅЃЁ
ЫљЮН ШлЖЯ ОЭЪЧЗўЮёбЉБРЕФвЛжжгааЇНтОіЗНАИЁЃЕБжИЖЈЪБМфДАФкЕФЧыЧѓЪЇАмТЪДяЕНЩшЖЈуажЕЪБЃЌЯЕЭГНЋЭЈЙ§
ЖЯТЗЦї жБНгНЋДЫЧыЧѓСДТЗЖЯПЊЁЃ
вВОЭЪЧЮвУЧЩЯУцЗўЮёBЕїгУЗўЮёCдкжИЖЈЪБМфДАФкЃЌЕїгУЕФЪЇАмТЪЕНДяСЫвЛЖЈЕФжЕЃЌФЧУД Hystrix дђЛсздЖЏНЋ
ЗўЮёBгыC жЎМфЕФЧыЧѓЖМЖЯСЫЃЌвдУтЕМжТЗўЮёбЉБРЯжЯѓЁЃ
ЦфЪЕетРяЫљНВЕФ ШлЖЯ ОЭЪЧжИЕФ Hystrix жаЕФ ЖЯТЗЦїФЃЪН ЃЌФуПЩвдЪЙгУМђЕЅЕФ @HystrixCommand
зЂНтРДБъзЂФГИіЗНЗЈЃЌетбљ Hystrix ОЭЛсЪЙгУ ЖЯТЗЦї РДЁААќзАЁБетИіЗНЗЈЃЌУПЕБЕїгУЪБМфГЌЙ§жИЖЈЪБМфЪБ(ФЌШЯЮЊ1000ms)ЃЌЖЯТЗЦїНЋЛсжаЖЯЖдетИіЗНЗЈЕФЕїгУЁЃ
ЕБШЛФуПЩвдЖдетИізЂНтЕФКмЖрЪєадНјааЩшжУЃЌБШШчЩшжУГЌЪБЪБМфЃЌЯёетбљЁЃ
@HystrixCommand(
commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value
= "1200")}
)
public List<Xxx> getXxxx() {
// ...ЪЁТдДњТыТпМ
} |
ЕЋЪЧЃЌЮвВщдФСЫвЛаЉВЉПЭЃЌЗЂЯжЫћУЧЖМНЋ ШлЖЯ КЭ НЕМЖ ЕФИХФюЛьЯ§СЫЃЌвдЮвЕФРэНтЃЌНЕМЖЪЧЮЊСЫИќКУЕФгУЛЇЬхбщЃЌЕБвЛИіЗНЗЈЕїгУвьГЃЪБЃЌЭЈЙ§жДааСэвЛжжДњТыТпМРДИјгУЛЇгбКУЕФЛиИДЁЃетвВОЭЖдгІзХ
Hystrix ЕФ КѓБИДІРэ ФЃЪНЁЃФуПЩвдЭЈЙ§ЩшжУ fallbackMethod РДИјвЛИіЗНЗЈЩшжУБИгУЕФДњТыТпМЁЃБШШчетИіЪБКђгавЛИіШШЕуаТЮХГіЯжСЫЃЌЮвУЧЛсЭЦМіИјгУЛЇВщПДЯъЧщЃЌШЛКѓгУЛЇЛсЭЈЙ§idШЅВщбЏаТЮХЕФЯъЧщЃЌЕЋЪЧвђЮЊетЬѕаТЮХЬЋЛ№СЫ(БШШчзюНќЪВУД*взЖдАЩ)ЃЌДѓСПгУЛЇЭЌЪБЗУЮЪПЩФмЛсЕМжТЯЕЭГБРРЃЃЌФЧУДЮвУЧОЭНјаа
ЗўЮёНЕМЖ ЃЌвЛаЉЧыЧѓЛсзівЛаЉНЕМЖДІРэБШШчЕБЧАШЫЪ§ЬЋЖрЧыЩдКѓВщПДЕШЕШЁЃ
// жИЖЈСЫКѓБИЗНЗЈЕїгУ
@HystrixCommand(fallbackMethod = "getHystrixNews")
@GetMapping("/get/news")
public News getNews(@PathVariable("id")
int id) {
// ЕїгУаТЮХЯЕЭГЕФЛёШЁаТЮХapi ДњТыТпМЪЁТд
}
//
public News getHystrixNews(@PathVariable("id")
int id) {
// зіЗўЮёНЕМЖ
// ЗЕЛиЕБЧАШЫЪ§ЬЋЖрЃЌЧыЩдКѓВщПД
} |
ЪВУДЪЧHystrixжЎЦфЫћ
ЮвдкдФЖС ЁЖSpringЮЂЗўЮёЪЕеНЁЗетБОЪщЕФЪБКђЛЙНгДЅЕНСЫвЛИіВеБкФЃЪНЕФИХФюЁЃдкВЛЪЙгУВеБкФЃЪНЕФЧщПіЯТЃЌЗўЮёAЕїгУЗўЮёBЃЌетжжЕїгУФЌШЯЕФЪЧЪЙгУЭЌвЛХњЯпГЬРДжДааЕФЃЌЖјдквЛИіЗўЮёГіЯжадФмЮЪЬтЕФЪБКђЃЌОЭЛсГіЯжЫљгаЯпГЬБЛЫЂБЌВЂЕШД§ДІРэЙЄзїЃЌЭЌЪБзшШћаТЧыЧѓЃЌзюжеЕМжТГЬађБРРЃЁЃЖјВеБкФЃЪНЛсНЋдЖГЬзЪдДЕїгУИєРыдкЫћУЧздМКЕФЯпГЬГижаЃЌвдБуПЩвдПижЦЕЅИіБэЯжВЛМбЕФЗўЮёЃЌЖјВЛЛсЪЙИУГЬађБРРЃЁЃ
ОпЬхЦфдРэЮвЭЦМіДѓМвздМКШЅСЫНтвЛЯТЃЌБОЦЊЮФеТжаЖдВеБкФЃЪНВЛзіЙ§ЖрНтЪЭЁЃЕБШЛЛЙга Hystrix вЧБэХЬЃЌЫќЪЧгУРДЪЕЪБМрПи
Hystrix ЕФИїЯюжИБъаХЯЂЕФЃЌетРяЮвНЋетИіЮЪЬтвВХзГіШЅЃЌЯЃЭћгаВЛСЫНтЕФПЩвдздМКШЅЫбЫївЛЯТЁЃ
ЮЂЗўЮёЭјЙиЁЊЁЊZuul

ZUUL ЪЧДгЩшБИКЭ web еОЕуЕН Netflix СїгІгУКѓЖЫЕФЫљгаЧыЧѓЕФЧАУХЁЃзїЮЊБпНчЗўЮёгІгУЃЌZUUL
ЪЧЮЊСЫЪЕЯжЖЏЬЌТЗгЩЁЂМрЪгЁЂЕЏадКЭАВШЋадЖјЙЙНЈЕФЁЃЫќЛЙОпгаИљОнЧщПіНЋЧыЧѓТЗгЩЕНЖрИі Amazon Auto
Scaling GroupsЃЈбЧТэбЗздЖЏЫѕЗХзщЃЌбЧТэбЗЕФвЛжждЦМЦЫуЗНЪНЃЉ ЕФФмСІ
дкЩЯУцЮвУЧбЇЯАСЫ Eureka жЎКѓЮвУЧжЊЕРСЫ ЗўЮёЬсЙЉеп ЪЧ ЯћЗбеп ЭЈЙ§ Eureka Server
НјааЗУЮЪЕФЃЌМД Eureka Server ЪЧ ЗўЮёЬсЙЉеп ЕФЭГвЛШыПкЁЃФЧУДећИігІгУжаДцдкФЧУДЖр ЯћЗбепашвЊгУЛЇНјааЕїгУЃЌетИіЪБКђгУЛЇИУдѕбљЗУЮЪетаЉ
ЯћЗбепЙЄГЬ ФиЃПЕБШЛПЩвдЯёжЎЧАФЧбљжБНгЗУЮЪетаЉЙЄГЬЁЃЕЋетжжЗНЪНУЛгаЭГвЛЕФЯћЗбепЙЄГЬЕїгУШыПкЃЌВЛБугкЗУЮЪгыЙмРэЃЌЖј
Zuul ОЭЪЧетбљЕФвЛИіЖдгк ЯћЗбеп ЕФЭГвЛШыПкЁЃ
ШчЙћбЇЙ§ЧАЖЫЕФПЯЖЈЖМжЊЕР Router АЩЃЌБШШч Flutter жаЕФТЗгЩЃЌVueЃЌReactжаЕФТЗгЩЃЌгУСЫ
Zuul ФуЛсЗЂЯждкТЗгЩЙІФмЗНУцКЭЧАЖЫХфжУТЗгЩЛљБОЪЧвЛИіРэЁЃ ЮвХМЖћпЃпЃ FlutterЁЃ
ДѓМвЖдЭјЙигІИУКмЪьАЩЃЌМђЕЅРДНВЭјЙиЪЧЯЕЭГЮЈвЛЖдЭтЕФШыПкЃЌНщгкПЭЛЇЖЫгыЗўЮёЦїЖЫжЎМфЃЌгУгкЖдЧыЧѓНјааМјШЈЁЂЯоСїЁЂ
ТЗгЩЁЂМрПиЕШЙІФмЁЃ
УЛДэЃЌЭјЙигаЕФЙІФмЃЌZuul ЛљБОЖМгаЁЃЖј Zuul жазюЙиМќЕФОЭЪЧ ТЗгЩКЭЙ§ТЫЦї СЫЃЌдкЙйЗНЮФЕЕжа
Zuul ЕФБъЬтОЭЪЧ
Router and Filter : Zuul
Zuul ЕФТЗгЩЙІФм
МђЕЅХфжУ
БОРДЯыИјФуУЧИДжЦвЛаЉДњТыЃЌЕЋЪЧЯыСЫЯыЃЌвђЮЊИїИіДњТыХфжУБШНЯСуЩЂЃЌПДЦ№РДвВБШНЯСуЩЂЃЌЮвОіЖЈЛЙЪЧИјФуУЧЛИіЭМРДНтЪЭАЩЁЃ
ЧыВЛвЊвђЮЊЮветУДКУОЭИјЮвЕудо ЁЃ ЗшПёАЕЪОЁЃ
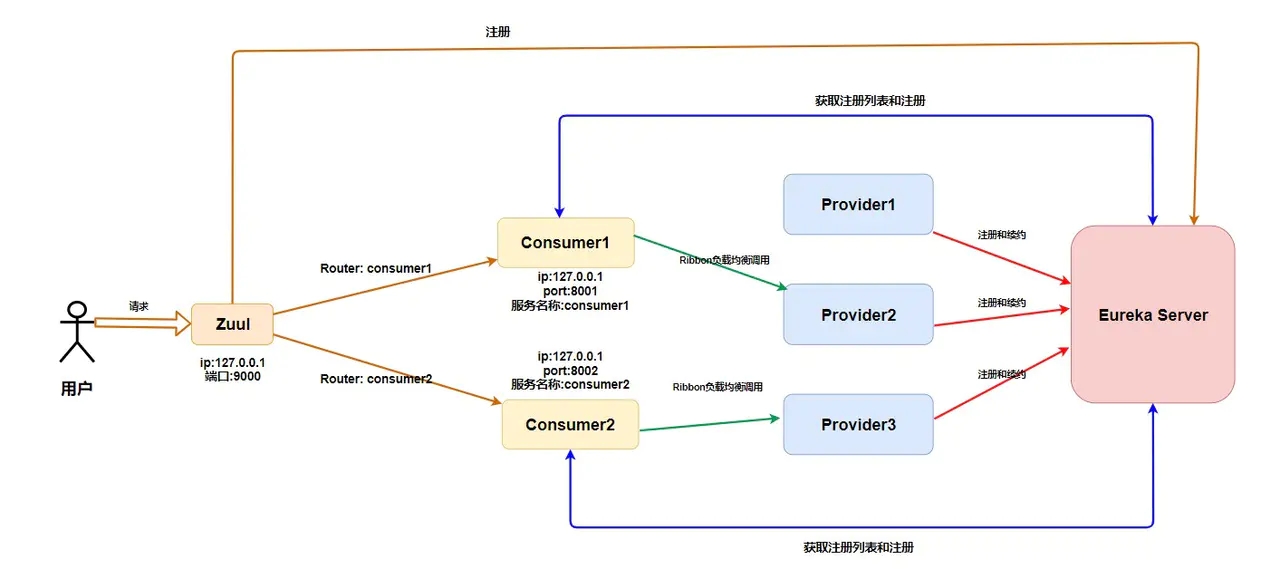
БШШчетИіЪБКђЮвУЧвбОЯђ Eureka Server зЂВсСЫСНИі Consumer ЁЂШ§Иі Provicer
ЃЌетИіЪБКђЮвУЧдйМгИі Zuul ЭјЙигІИУБфГЩетбљзгСЫЁЃ
emmmЃЌаХЯЂСПгаЕуДѓЃЌЮвРДНтЪЭвЛЯТЁЃЙигкЧАУцЕФжЊЪЖЮвОЭВЛНтЪЭСЫ ЁЃ
ЪзЯШЃЌZuul ашвЊЯђ Eureka НјаазЂВсЃЌзЂВсгаЩЖКУДІФиЃП
ФуЩЕбНЃЌConsumer ЖМЯђ Eureka Server НјаазЂВсСЫЃЌЮвЭјЙиЪЧВЛЪЧжЛвЊзЂВсОЭФмФУЕНЫљга
Consumer ЕФаХЯЂСЫЃП
ФУЕНаХЯЂгаЪВУДКУДІФиЃП
ЮвФУЕНаХЯЂЮвЪЧВЛЪЧПЩвдЛёШЁЫљгаЕФ Consumer ЕФдЊЪ§Он(УћГЦЃЌipЃЌЖЫПк)ЃП
ФУЕНетаЉдЊЪ§ОнгаЪВУДКУДІФиЃПФУЕНСЫЮвУЧЪЧВЛЪЧжБНгПЩвдзіТЗгЩгГЩфЃПБШШчдРДгУЛЇЕїгУ Consumer1
ЕФНгПк localhost:8001/studentInfo/update етИіЧыЧѓЃЌЮвУЧЪЧВЛЪЧПЩвдетбљНјааЕїгУСЫФиЃПlocalhost:9000/consumer1/studentInfo/update
ФиЃПФуетбљЪЧВЛЪЧЛаШЛДѓЮђСЫЃП
етРяЕФurlЮЊСЫШУИќЖрШЫПДЖЎЫљвдУЛгаЪЙгУ restful ЗчИёЁЃ
ЩЯУцЕФФуРэНтСЫЃЌФЧУДОЭФмРэНтЙигк Zuul зюЛљБОЕФХфжУСЫЃЌПДЯТУцЁЃ
server:
port: 9000
eureka:
client:
service-url:
# етРяжЛвЊзЂВс Eureka ОЭааСЫ
defaultZone: http://localhost:9997/eureka |
ШЛКѓдкЦєЖЏРрЩЯМгШы @EnableZuulProxy зЂНтОЭааСЫЁЃУЛДэЃЌОЭЪЧФЧУДМђЕЅ ЁЃ
ЭГвЛЧАзК
етИіКмМђЕЅЃЌОЭЪЧЮвУЧПЩвддкЧАУцМгвЛИіЭГвЛЕФЧАзКЃЌБШШчЮвУЧИеИеЕїгУЕФЪЧ
localhost: 9000/consumer1/ studentInfo/updateЃЌетИіЪБКђЮвУЧдк
yaml ХфжУЮФМўжаЬэМгШчЯТЁЃ
етбљЮвУЧОЭашвЊЭЈЙ§ localhost: 9000/zuul/consumer1/
studentInfo/update РДНјааЗУЮЪСЫЁЃ
ТЗгЩВпТдХфжУ
ФуЛсЗЂЯжЧАУцЕФЗУЮЪЗНЪН(жБНгЪЙгУЗўЮёУћ)ЃЌашвЊНЋЮЂЗўЮёУћГЦБЉТЖИјгУЛЇЃЌЛсДцдкАВШЋадЮЪЬтЁЃЫљвдЃЌПЩвдздЖЈвхТЗОЖРДЬцДњЮЂЗўЮёУћГЦЃЌМДздЖЈвхТЗгЩВпТдЁЃ
zuul:
routes:
consumer1: /FrancisQ1/**
consumer2: /FrancisQ2/** |
етИіЪБКђФуОЭПЩвдЪЙгУ localhost: 9000/zuul/FrancisQ1/
studentInfo/update НјааЗУЮЪСЫЁЃ
ЗўЮёУћЦСБЮ
етИіЪБКђФуБ№вдЮЊФуКУСЫЃЌФуПЩвдЪдЪдЃЌдкФуХфжУЭъТЗгЩВпТджЎКѓЪЙгУЮЂЗўЮёУћГЦЛЙЪЧПЩвдЗУЮЪЕФЃЌетИіЪБКђФуашвЊНЋЗўЮёУћЦСБЮЁЃ
zuul:
ignore-services: "*" |
ТЗОЖЦСБЮ
Zuul ЛЙПЩвджИЖЈЦСБЮЕєЕФТЗОЖ URIЃЌМДжЛвЊгУЛЇЧыЧѓжаАќКЌжИЖЈЕФ
URI ТЗОЖЃЌФЧУДИУЧыЧѓНЋЮоЗЈЗУЮЪЕНжИЖЈЕФЗўЮёЁЃЭЈЙ§ИУЗНЪНПЩвдЯожЦгУЛЇЕФШЈЯоЁЃ
zuul:
ignore-patterns: **/auto/** |
етбљЙигк auto ЕФЧыЧѓЮвУЧОЭПЩвдЙ§ТЫЕєСЫЁЃ
** ДњБэЦЅХфЖрМЖШЮвтТЗОЖ
*ДњБэЦЅХфвЛМЖШЮвтТЗОЖ
УєИаЧыЧѓЭЗЦСБЮ
ФЌШЯЧщПіЯТЃЌЯё CookieЁЂSet-Cookie ЕШУєИаЧыЧѓЭЗаХЯЂЛсБЛ zuul ЦСБЮЕєЃЌЮвУЧПЩвдНЋетаЉФЌШЯЦСБЮШЅЕєЃЌЕБШЛЃЌвВПЩвдЬэМгвЊЦСБЮЕФЧыЧѓЭЗЁЃ
Zuul ЕФЙ§ТЫЙІФм
ШчЙћЫЕЃЌТЗгЩЙІФмЪЧ Zuul ЕФЛљВйЕФЛАЃЌФЧУДЙ§ТЫЦїОЭЪЧ ZuulЕФРћЦїСЫЁЃБЯОЙЫљгаЧыЧѓЖМОЙ§ЭјЙи(Zuul)ЃЌФЧУДЮвУЧПЩвдНјааИїжжЙ§ТЫЃЌетбљЮвУЧОЭФмЪЕЯж
ЯоСїЃЌЛвЖШЗЂВМЃЌШЈЯоПижЦЕШЕШЁЃ
МђЕЅЪЕЯжвЛИіЧыЧѓЪБМфШежОДђгЁ
вЊЪЕЯжздМКЖЈвхЕФ Filter ЮвУЧжЛашвЊМЬГа ZuulFilter ШЛКѓНЋетИіЙ§ТЫЦїРрвд @ComponentзЂНтМгШы
Spring ШнЦїжаОЭааСЫЁЃ
дкИјФуУЧПДДњТыжЎЧАЮвЯШИјФуУЧНтЪЭвЛЯТЙигкЙ§ТЫЦїЕФвЛаЉзЂвтЕуЁЃ
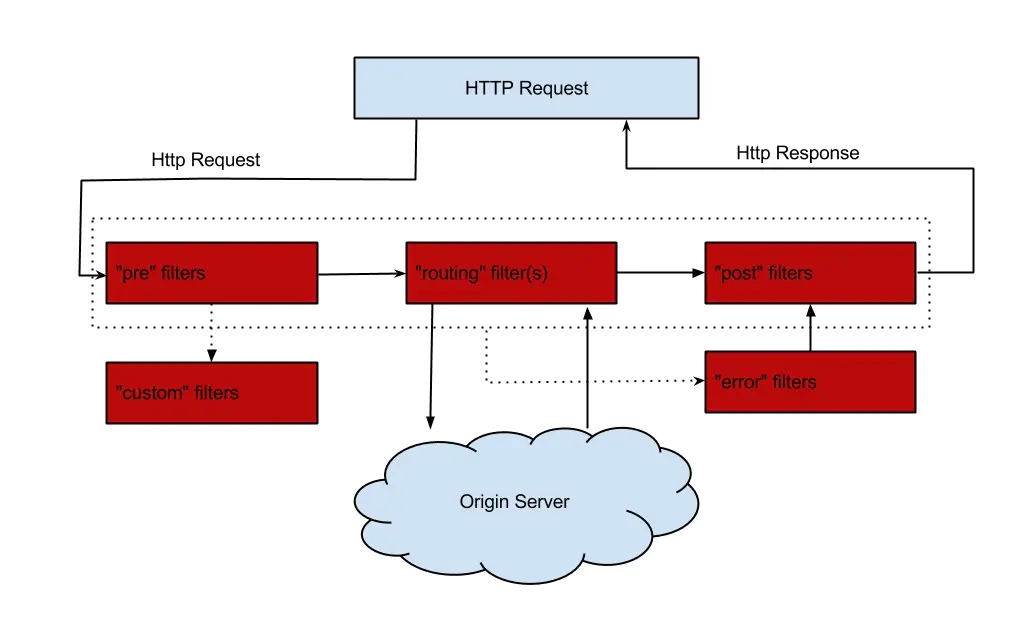
Й§ТЫЦїРраЭЃКPreЁЂRoutingЁЂPostЁЃЧАжУPreОЭЪЧдкЧыЧѓжЎЧАНјааЙ§ТЫЃЌRoutingТЗгЩЙ§ТЫЦїОЭЪЧЮвУЧЩЯУцЫљНВЕФТЗгЩВпТдЃЌЖјPostКѓжУЙ§ТЫЦїОЭЪЧдк
Response жЎЧАНјааЙ§ТЫЕФЙ§ТЫЦїЁЃФуПЩвдЙлВьЩЯЭМНсКЯзХРэНтЃЌВЂЧвЯТУцЮвЛсИјГіЯргІЕФзЂЪЭЁЃ
// МгШыSpringШнЦї
@Component
public class PreRequestFilter extends ZuulFilter
{
// ЗЕЛиЙ§ТЫЦїРраЭ етРяЪЧЧАжУЙ§ТЫЦї
@Override
public String filterType() {
return FilterConstants.PRE_TYPE;
}
// жИЖЈЙ§ТЫЫГађ дНаЁдНЯШжДааЃЌетРяЕквЛИіжДаа
// ЕБШЛВЛЪЧжЛеце§ЕквЛИі дкZuulФкжУжагаЦфЫћЙ§ТЫЦїЛсЯШжДаа
// ФЧЪЧаДЫРЕФ БШШч SERVLET_DETECTION_FILTER_ORDER = -3
@Override
public int filterOrder() {
return 0;
}
// ЪВУДЪБКђИУНјааЙ§ТЫ
// етРяЮвУЧПЩвдНјаавЛаЉХаЖЯЃЌетбљЮвУЧОЭПЩвдЙ§ТЫЕєвЛаЉВЛЗћКЯЙцЖЈЕФЧыЧѓЕШЕШ
@Override
public boolean shouldFilter() {
return true;
}
// ШчЙћЙ§ТЫЦїдЪаэЭЈЙ§дђдѕУДНјааДІРэ
@Override
public Object run() throws ZuulException {
// етРяЮвЩшжУСЫШЋОжЕФRequestContextВЂМЧТМСЫЧыЧѓПЊЪМЪБМф
RequestContext ctx = RequestContext.getCurrentContext();
ctx.set("startTime", System.currentTimeMillis());
return null;
}
} |
// lombokЕФШежО
@Slf4j
// МгШы Spring ШнЦї
@Component
public class AccessLogFilter extends ZuulFilter
{
// жИЖЈИУЙ§ТЫЦїЕФЙ§ТЫРраЭ
// ДЫЪБЪЧКѓжУЙ§ТЫЦї
@Override
public String filterType() {
return FilterConstants.POST_TYPE;
}
// SEND_RESPONSE_FILTER_ORDER ЪЧзюКѓвЛИіЙ§ТЫЦї
// ЮвУЧДЫЙ§ТЫЦїдкЫќжЎЧАжДаа
@Override
public int filterOrder() {
return FilterConstants.SEND_RESPONSE_FILTER_ORDER
- 1;
}
@Override
public boolean shouldFilter() {
return true;
}
// Й§ТЫЪБжДааЕФВпТд
@Override
public Object run() throws ZuulException {
RequestContext context = RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
// ДгRequestContextЛёШЁдЯШЕФПЊЪМЪБМф ВЂЭЈЙ§ЫќМЦЫуећИіЪБМфМфИє
Long startTime = (Long) context.get ("startTime");
// етРяЮвПЩвдЛёШЁHttpServletRequestРДЛёШЁURIВЂЧвДђгЁГіРД
String uri = request.getRequestURI();
long duration = System.currentTimeMillis() - startTime;
log.info(" uri: " + uri + ", duration:
" + duration / 100 + "ms");
return null;
}
} |
ЩЯУцОЭМђЕЅЪЕЯжСЫЧыЧѓЪБМфШежОДђгЁЙІФмЃЌФугаУЛгаИаЪмЕН Zuul Й§ТЫЙІФмЕФЧПДѓСЫФиЃП
УЛгаЃПКУЕФЁЂФЧЮвУЧдйРДЁЃ
СюХЦЭАЯоСї
ЕБШЛВЛНіНіЪЧСюХЦЭАЯоСїЗНЪНЃЌZuul жЛвЊЪЧЯоСїЕФЛюЫќЖМФмИЩЃЌетРяЮвжЛЪЧМђЕЅОйИі ЁЃ
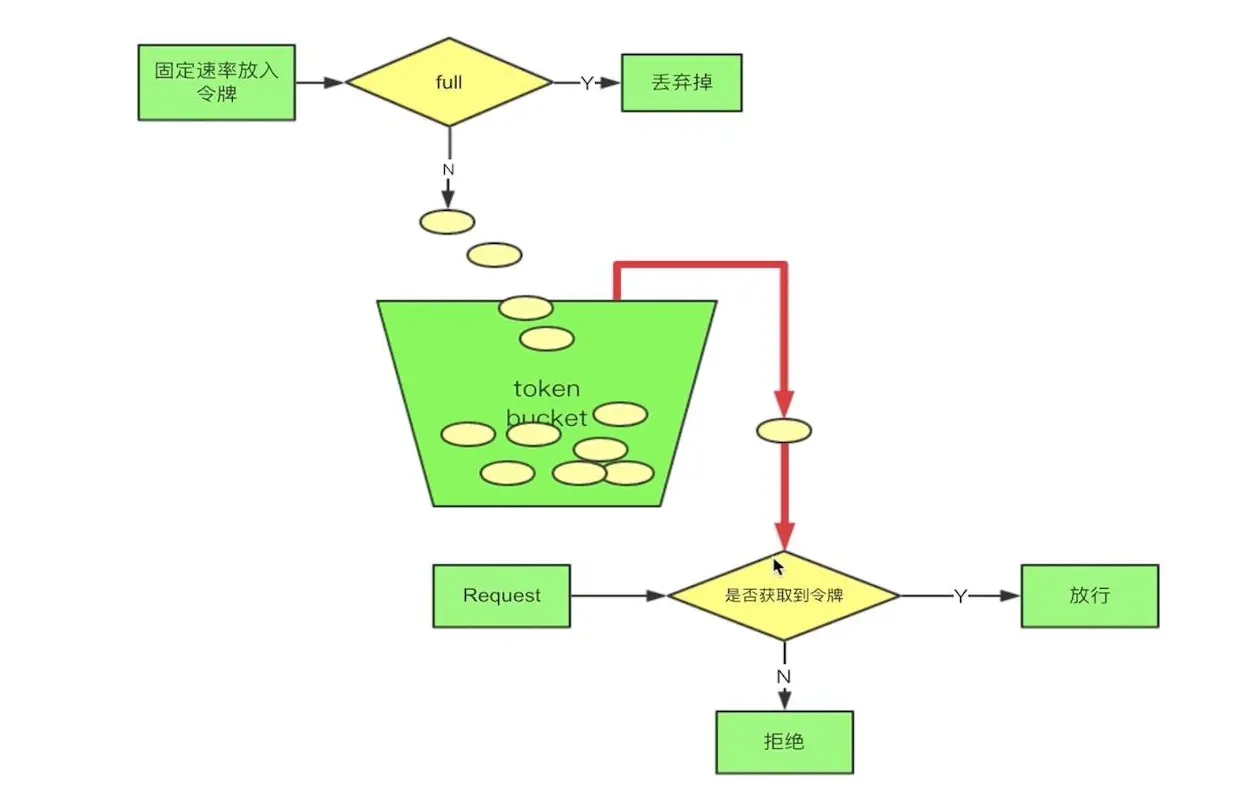
ЮвЯШРДНтЪЭвЛЯТЪВУДЪЧ СюХЦЭАЯоСї АЩЁЃ
ЪзЯШЮвУЧЛсгаИіЭАЃЌШчЙћРяУцУЛгаТњФЧУДОЭЛсвдвЛЖЈ ЙЬЖЈЕФЫйТЪ ЛсЭљРяУцЗХСюХЦЃЌвЛИіЧыЧѓЙ§РДЪзЯШвЊДгЭАжаЛёШЁСюХЦЃЌШчЙћУЛгаЛёШЁЕНЃЌФЧУДетИіЧыЧѓОЭОмОјЃЌШчЙћЛёШЁЕНФЧУДОЭЗХааЁЃКмМђЕЅАЩЃЌАЁЙўЙўЁЂ
ЯТУцЮвУЧОЭЭЈЙ§ Zuul ЕФЧАжУЙ§ТЫЦїРДЪЕЯжвЛЯТСюХЦЭАЯоСїЁЃ
@Component
@Slf4j
public class RouteFilter extends ZuulFilter {
// ЖЈвхвЛИіСюХЦЭАЃЌУПУыВњЩњ2ИіСюХЦЃЌМДУПУызюЖрДІРэ2ИіЧыЧѓ
private static final RateLimiter RATE_LIMITER
= RateLimiter.create(2);
@Override
public String filterType() {
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
return -5;
}
@Override
public Object run() throws ZuulException {
log.info("ЗХаа");
return null;
}
@Override
public boolean shouldFilter() {
RequestContext context = RequestContext.getCurrentContext();
if(!RATE_LIMITER.tryAcquire()) {
log.warn("ЗУЮЪСПГЌди");
// жИЖЈЕБЧАЧыЧѓЮДЭЈЙ§Й§ТЫ
context.setSendZuulResponse(false);
// ЯђПЭЛЇЖЫЗЕЛиЯьгІТы429ЃЌЧыЧѓЪ§СПЙ§Жр
context.setResponseStatusCode(429);
return false;
}
return true;
}
} |
етбљЮвУЧОЭФмНЋЧыЧѓЪ§СППижЦдквЛУыСНИіЃЌгаУЛгаОѕЕУКмПсЃП
Йигк Zuul ЕФЦфЫћ
Zuul ЕФЙ§ТЫЦїЕФЙІФмПЯЖЈВЛжЙЩЯУцЮвЫљЪЕЯжЕФСНжжЃЌЫќЛЙПЩвдЪЕЯж ШЈЯоаЃбщЃЌАќРЈЮвЩЯУцЬсЕНЕФ ЛвЖШЗЂВМ
ЕШЕШЁЃ
ЕБШЛЃЌZuul зїЮЊЭјЙиПЯЖЈвВДцдк ЕЅЕуЮЪЬт ЃЌШчЙћЮвУЧвЊБЃжЄ Zuul ЕФИпПЩгУЃЌЮвУЧОЭашвЊНјаа
Zuul ЕФМЏШКХфжУЃЌетИіЪБКђПЩвдНшжњЖюЭтЕФвЛаЉИКдиОљКтЦїБШШч Nginx ЁЃ
Spring CloudХфжУЙмРэЁЊЁЊConfig
ЮЊЪВУДвЊЪЙгУНјааХфжУЙмРэЃП
ЕБЮвУЧЕФЮЂЗўЮёЯЕЭГПЊЪМТ§Т§ЕиХгДѓЦ№РДЃЌФЧУДЖр Consumer ЁЂProvider ЁЂEureka
ServerЁЂZuul ЯЕЭГЖМЛсГжгаздМКЕФХфжУЃЌетИіЪБКђЮвУЧдкЯюФПдЫааЕФЪБКђПЩФмашвЊИќИФФГаЉгІгУЕФХфжУЃЌШчЙћЮвУЧВЛНјааХфжУЕФЭГвЛЙмРэЃЌЮвУЧжЛФмШЅУПИігІгУЯТвЛИівЛИібАевХфжУЮФМўШЛКѓаоИФХфжУЮФМўдйжиЦєгІгУЁЃ
ЪзЯШЖдгкЗжВМЪНЯЕЭГЖјбдЮвУЧОЭВЛгІИУШЅУПИігІгУЯТШЅЗжБ№аоИФХфжУЮФМўЃЌдйепЖдгкжиЦєгІгУРДЫЕЃЌЗўЮёЮоЗЈЗУЮЪЫљвджБНгХзЦњСЫПЩгУадЃЌетЪЧЮвУЧИќВЛдИМћЕНЕФЁЃ
ФЧУДгаУЛгавЛжжЗНЗЈМШФмЖдХфжУЮФМўЭГвЛЕиНјааЙмРэЃЌгжФмдкЯюФПдЫааЪБЖЏЬЌаоИФХфжУЮФМўФиЃП
ФЧОЭЪЧЮвНёЬьЫљвЊНщЩмЕФ Spring Cloud Config ЁЃ
ФмНјааХфжУЙмРэЕФПђМмВЛжЙ Spring Cloud Config вЛжжЃЌДѓМвПЩвдИљОнашЧѓздМКбЁдёЃЈdisconfЃЌАЂВЈТоЕШЕШЃЉЁЃЖјЧвЖдгк
Config РДЫЕгааЉЕиЗНЪЕЯжЕФВЛЪЧФЧУДОЁШЫвтЁЃ
Config ЪЧЪВУД
Spring Cloud Config ЮЊЗжВМЪНЯЕЭГжаЕФЭтВПЛЏХфжУЬсЙЉЗўЮёЦїКЭПЭЛЇЖЫжЇГжЁЃЪЙгУ Config
ЗўЮёЦїЃЌПЩвддкжааФЮЛжУЙмРэЫљгаЛЗОГжагІгУГЬађЕФЭтВПЪєадЁЃ
МђЕЅРДЫЕЃЌSpring Cloud Config ОЭЪЧФмНЋИїИі гІгУ/ЯЕЭГ/ФЃПщ ЕФХфжУЮФМўДцЗХЕН
ЭГвЛЕФЕиЗНШЛКѓНјааЙмРэ(Git Лђеп SVN)ЁЃ
ФуЯывЛЯТЃЌЮвУЧЕФгІгУЪЧВЛЪЧжЛгаЦєЖЏЕФЪБКђВХЛсНјааХфжУЮФМўЕФМгдиЃЌФЧУДЮвУЧЕФ Spring Cloud
Config ОЭБЉТЖГівЛИіНгПкИјЦєЖЏгІгУРДЛёШЁЫќЫљЯывЊЕФХфжУЮФМўЃЌгІгУЛёШЁЕНХфжУЮФМўШЛКѓдйНјааЫќЕФГѕЪМЛЏЙЄзїЁЃОЭШчЯТЭМЁЃ
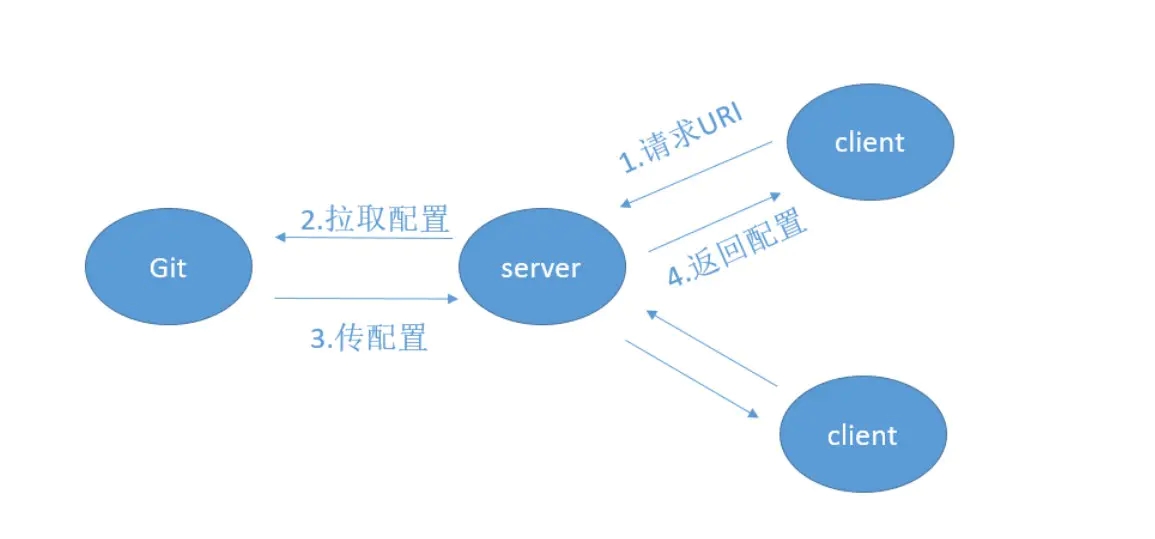
ЕБШЛетРяФуПЯЖЈЛЙЛсгавЛИівЩЮЪЃЌШчЙћЮвдкгІгУдЫааЪБШЅИќИФдЖГЬХфжУВжПт(Git)жаЕФЖдгІХфжУЮФМўЃЌФЧУДвРРЕгкетИіХфжУЮФМўЕФвбЦєЖЏЕФгІгУЛсВЛЛсНјааЦфЯргІХфжУЕФИќИФФиЃП
Д№АИЪЧВЛЛсЕФЁЃ
ЪВУДЃПФЧдѕУДНјааЖЏЬЌаоИФХфжУЮФМўФиЃПетВЛЪЧГіЯжСЫ ХфжУЦЏвЦ Т№ЃПФуИідќФа ЃЌФугжЦЮвЃЁ
Б№МБТяЃЌФуПЩвдЪЙгУ Webhooks ЃЌетЪЧ github ЬсЙЉЕФЙІФмЃЌЫќФмШЗБЃдЖГЬПтЕФХфжУЮФМўИќаТКѓПЭЛЇЖЫжаЕФХфжУаХЯЂвВЕУЕНИќаТЁЃ
ророЃЌетЛЙВюВЛЖрЁЃЮвШЅВщВщдѕУДгУЁЃ
Т§зХЃЌЬ§ЮвЫЕЭъЃЌWebhooks ЫфШЛФмНтОіЃЌЕЋЪЧФуСЫНтвЛЯТЛсЗЂЯжЫќИљБОВЛЪЪКЯгУгкЩњВњЛЗОГЃЌЫљвдЛљБОВЛЛсЪЙгУЫќЕФЁЃ

ЖјвЛАуЮвУЧЛсЪЙгУ Bus ЯћЯЂзмЯп + Spring Cloud Config НјааХфжУЕФЖЏЬЌЫЂаТЁЃ
в§Гі Spring Cloud Bus
гУгкНЋЗўЮёКЭЗўЮёЪЕР§гыЗжВМЪНЯћЯЂЯЕЭГСДНгдквЛЦ№ЕФЪТМўзмЯпЁЃдкМЏШКжаДЋВЅзДЬЌИќИФКмгагУЃЈР§ШчХфжУИќИФЪТМўЃЉЁЃ
ФуПЩвдМђЕЅРэНтЮЊ Spring Cloud Bus ЕФзїгУОЭЪЧЙмРэКЭЙуВЅЗжВМЪНЯЕЭГжаЕФЯћЯЂЃЌвВОЭЪЧЯћЯЂв§ЧцЯЕЭГжаЕФЙуВЅФЃЪНЁЃЕБШЛзїЮЊ
ЯћЯЂзмЯп ЕФ Spring Cloud Bus ПЩвдзіКмЖрЪТЖјВЛНіНіЪЧПЭЛЇЖЫЕФХфжУЫЂаТЙІФмЁЃ
ЖјгЕгаСЫ Spring Cloud Bus жЎКѓЃЌЮвУЧжЛашвЊДДНЈвЛИіМђЕЅЕФЧыЧѓЃЌВЂЧвМгЩЯ @ResfreshScope
зЂНтОЭФмНјааХфжУЕФЖЏЬЌаоИФСЫЃЌЯТУцЮвЛСЫеХЭМЙЉФуРэНтЁЃ
.jpg)
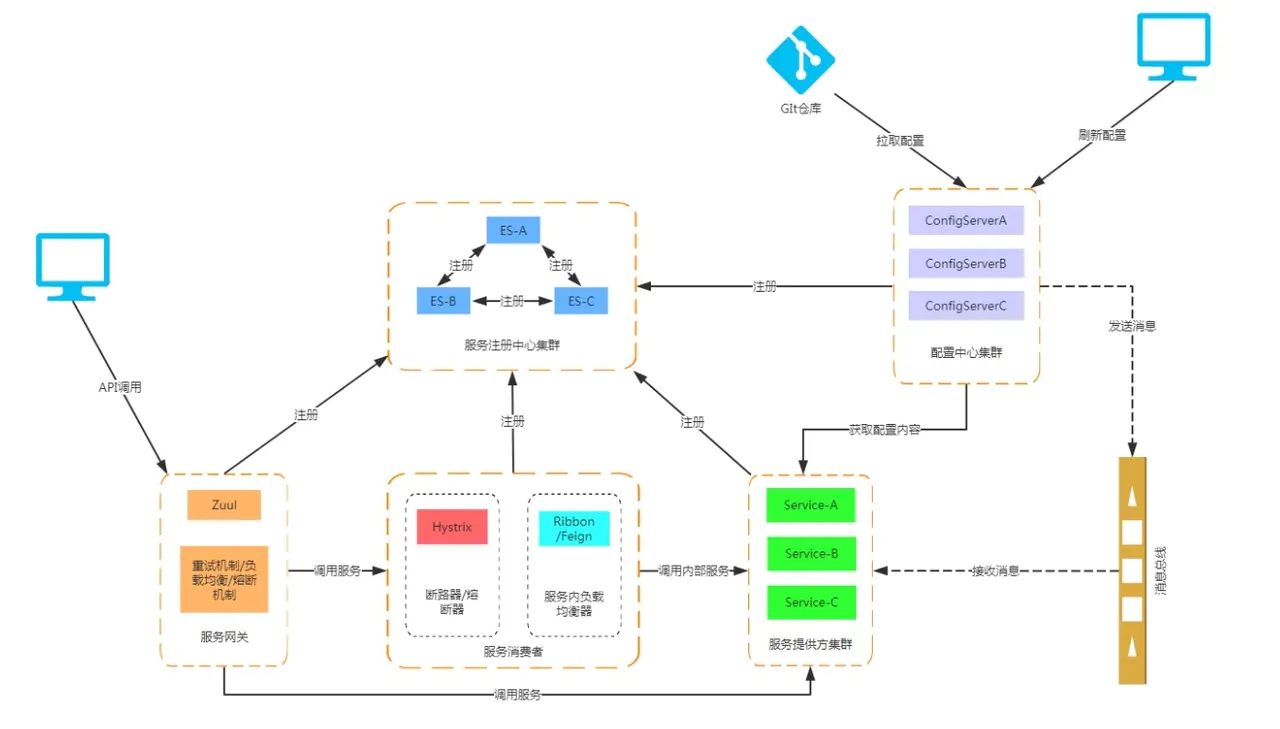
змНс
етЦЊЮФеТжаЮвДјДѓМвГѕВНСЫНтСЫ Spring Cloud ЕФИїИізщМўЃЌЫћУЧга
Eureka ЗўЮёЗЂЯжПђМм
Ribbon НјГЬФкИКдиОљКтЦї
Open Feign ЗўЮёЕїгУгГЩф
Hystrix ЗўЮёНЕМЖШлЖЯЦї
Zuul ЮЂЗўЮёЭјЙи
Config ЮЂЗўЮёЭГвЛХфжУжааФ
Bus ЯћЯЂзмЯп
ШчЙћФуФметИіЪБКђФмПДЖЎЯТУцФЧеХЭМЃЌвВОЭЫЕУїСЫФувбОЖд Spring Cloud ЮЂЗўЮёгаСЫвЛЖЈЕФМмЙЙШЯЪЖЁЃ
.jpg)
|









