| БрМЭЦМі: |
БОЮФЪОР§ЛљгкSpring Boot 1.5.xЪЕЯжжївЊНВНтСЫЗжВМЪНЗўЮёПђМмЕФЗЂеЙЁЂSpring
Cloud МђНщЁЂЪОР§НсЙЙЫЕУїЕШФкШнЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЗжВМЪНЗўЮёПђМмЕФЗЂеЙ 1.1 ЕквЛДњЗўЮёПђМм ДњБэЃКDubbo(Java)ЁЂOrleans(.Net)ЕШ
ЬиЕуЃККЭгябдАѓЖЈНєУм
1.2 ЕкЖўДњЗўЮёПђМм ДњБэЃКSpring CloudЕШ
ЯжзДЃКЪЪКЯЛьКЯЪНПЊЗЂЃЈР§ШчНшжњSteeltoe OSSПЩвдШУASP.Net CoreгыSpring
CloudМЏГЩЃЉЃЌе§жЕЕБФъ
1.3 ЕкШ§ДњЗўЮёПђМм ДњБэЃКService MeshЃЈЗўЮёЭјИёЃЉ => Р§ШчService FabricЁЂlstioЁЂLinkerdЁЂConduitЕШ
ЯжзДЃКдкПьЫйЗЂеЙжаЃЌИќаТЕќДњБШНЯПь
1.4 ЮДРДЃЈФПВтВЛОУЃЉжїСїЕФЗўЮёМмЙЙКЭММЪѕеЛ

ЛљДЁЕФдЦЦНЬЈЮЊЮЂЗўЮёЬсЙЉСЫзЪдДФмСІЃЈМЦЫуЁЂДцДЂКЭЭјТчЕШЃЉЃЌШнЦїзїЮЊзюаЁЙЄзїЕЅдЊБЛKubernetesЕїЖШКЭБрХХЃЌService
MeshЃЈЗўЮёЭјИёЃЉЙмРэЮЂЗўЮёЕФЗўЮёЭЈаХЃЌзюКѓЭЈЙ§API GatewayЯђЭтБЉТЖЮЂЗўЮёЕФвЕЮёНгПкЁЃ
ФПЧАЃЌЮвЫљдкЕФЯюФПзщвбОдкВЩгУетжжММЪѕМмЙЙСЫЃЌЗўЮёЭјИёВЩгУЕФЪЧLinkerdЃЌШнЦїБрХХВЩгУЕФЪЧK8SЃЌSpring
CloudвбОУЛгУСЫЁЃButЃЌВЛДњБэSpring CloudУЛгабЇЯАЕФвтвхЃЌЖдгкжааЁаЭЯюФПЭХЖгЃЌSpring
CloudШдШЛЪЧПьЫйЪзбЁЁЃ
ЖўЁЂSpring Cloud МђНщ 2.1 Spring CloudМЋМђНщЩм

ЪзЯШЃЌОЁЙмSpring CloudДјгаЁАCloudЁБетИіЕЅДЪЃЌЕЋЫќВЂВЛЪЧдЦМЦЫуНтОіЗНАИЃЌЖјЪЧдкSpring
BootЛљДЁжЎЩЯЙЙНЈЕФЃЌгУгкПьЫйЙЙНЈЗжВМЪНЯЕЭГЕФЭЈгУФЃЪНЕФЙЄОпМЏЁЃ
ЦфДЮЃЌЪЙгУSpring CloudПЊЗЂЕФгІгУГЬађЗЧГЃЪЪКЯдкDockerКЭPaaSЃЈБШШчPivotal
Cloud FoundryЃЉЩЯВПЪ№ЃЌЫљвдгжНазідЦдЩњгІгУЃЈCloud Native ApplicationЃЉЁЃдЦдЩњПЩвдМђЕЅЕиРэНтЮЊУцЯђдЦЛЗОГЕФШэМўМмЙЙЁЃ
змНс ЃКSpring CloudЪЧвЛИіЛљгкSpring BootЪЕЯжЕФдЦдЩњгІгУПЊЗЂЙЄОпЃЌЫќЮЊЛљгкJVMЕФдЦдЩњгІгУПЊЗЂжаЩцМАЕФХфжУЙмРэЁЂЗўЮёЗЂЯжЁЂШлЖЯЦїЁЂжЧФмТЗгЩЁЂЮЂДњРэЁЂПижЦзмЯпЁЂЗжВМЪНЛсЛАКЭМЏШКзДЬЌЙмРэЕШВйзїЬсЙЉСЫвЛжжМђЕЅЕФПЊЗЂЗНЪНЁЃ
Spring CloudОпгаШчЯТЬиЕуЃК
дМЖЈДѓгкХфжУ ЪЪгУгкИїжжЛЗОГ вўВиСЫзщМўЕФИДдгадЃЌВЂЬсЙЉЩљУїЪНЁЂЮоXMLЪНЕФХфжУЗНЪН ПЊЯфМДгУЃЌПьЫйЦєЖЏ зщМўЗсИЛЃЌЙІФмЦыШЋ ...... Spring CloudзїЮЊЕкЖўДњЮЂЗўЮёЕФДњБэадПђМмЃЌвбОдкЙњФкжкЖрДѓжааЁаЭЕФЙЋЫОгаЪЕМЪгІгУАИР§ЁЃаэЖрЙЋЫОЕФвЕЮёЯпШЋВПгЕБЇSpring
CloudЃЌВПЗжЙЋЫОбЁдёВПЗжгЕБЇSpring CloudЁЃР§ШчЃЌХФХФДћзЪЩюМмЙЙЪІбюВЈРЯЪІОЭИљОнздМКЕФЪЕМЪОбщвдМАЖдSpring
CloudЕФЩюШыЕїбаЃЌВЂНсКЯЙњФквЛЯпЛЅСЊЭјДѓГЇЕФПЊдДЯюФПгІгУЪЕМљНсЙћЃЌШЯЮЊSpring CloudММЪѕеЛжаЕФгааЉзщМўРыЩњВњМЖПЊЗЂЩагавЛЖЈОрРыЃЌзюКѓЬсГіСЫвЛИіПЩЙЉжааЁЭХЖгВЮПМЕФЮЂЗўЮёМмЙЙММЪѕеЛЃЌгжБЛГЦЮЊЁАжаЙњЬиЩЋЕФЮЂЗўЮёМмЙЙММЪѕеЛ1.0ЁБЃК
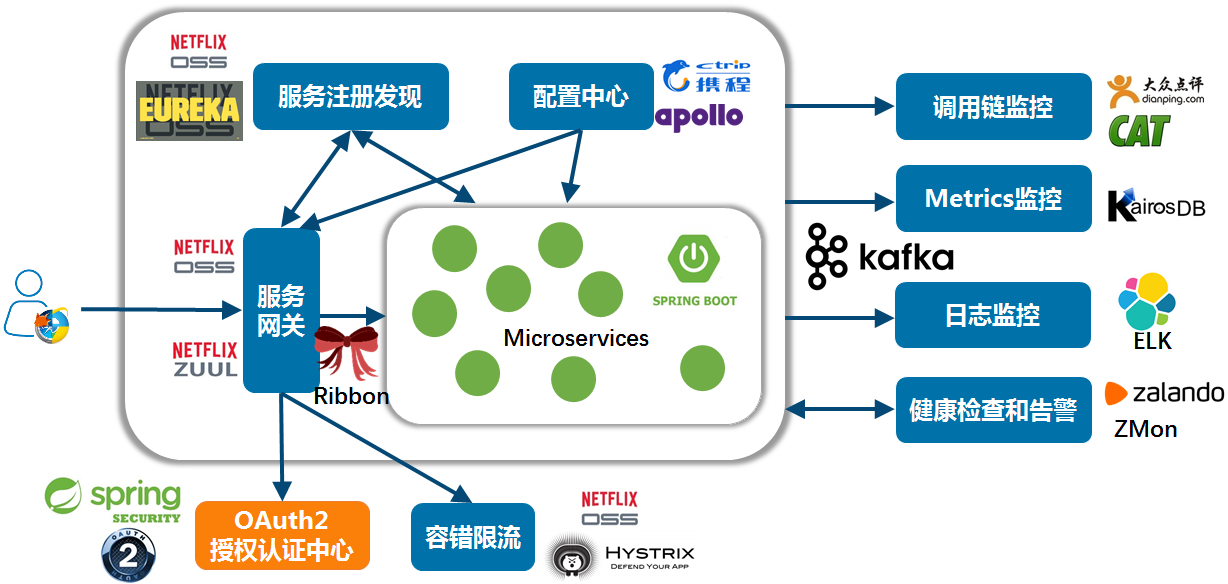
ЩЯЭМжаЩцМАЕНЕФзщМўЃЌетРяВЛзіОпЬхНщЩм
2.2 Spring CloudКЫаФзгЯюФП Spring Cloud NetflixЃККЫаФзщМўЃЌПЩвдЖдЖрИіNetflix OSSПЊдДЬзМўНјааећКЯЃЌАќРЈвдЯТМИИізщМўЃК EurekaЃКЗўЮёжЮРэзщМўЃЌАќКЌЗўЮёзЂВсгыЗЂЯж HystrixЃКШнДэЙмРэзщМўЃЌЪЕЯжСЫШлЖЯЦї RibbonЃКПЭЛЇЖЫИКдиОљКтЕФЗўЮёЕїгУзщМў FeignЃКЛљгкRibbonКЭHystrixЕФЩљУїЪНЗўЮёЕїгУзщМў ZuulЃКЭјЙизщМўЃЌЬсЙЉжЧФмТЗгЩЁЂЗУЮЪЙ§ТЫЕШЙІФм ArchaiusЃКЭтВПЛЏХфжУзщМў Spring Cloud ConfigЃКХфжУЙмРэЙЄОпЃЌЪЕЯжгІгУХфжУЕФЭтВПЛЏДцДЂЃЌжЇГжПЭЛЇЖЫХфжУаХЯЂЫЂаТЁЂМгУм/НтУмХфжУФкШнЕШЁЃ Spring Cloud BusЃКЪТМўЁЂЯћЯЂзмЯпЃЌгУгкДЋВЅМЏШКжаЕФзДЬЌБфЛЏЛђЪТМўЃЌвдМАДЅЗЂКѓајЕФДІРэ Spring Cloud SecurityЃКЛљгкspring securityЕФАВШЋЙЄОпАќЃЌЮЊЮвУЧЕФгІгУГЬађЬэМгАВШЋПижЦ Spring Cloud Consul : ЗтзАСЫConsulВйзїЃЌConsulЪЧвЛИіЗўЮёЗЂЯжгыХфжУЙЄОпЃЈгыEurekaзїгУРрЫЦЃЉЃЌгыDockerШнЦїПЩвдЮоЗьМЏГЩ ......
Ш§ЁЂЪОР§НсЙЙЫЕУї
3.1 ЪОР§ЛЗОГАцБО
Java : JDK & JRE 1.8 8u151 Spring Boot : 1.5.15.RELEASE Spring Cloud : Edgware.SR3 ЃЈаЁЬљЪПЃКSpring CloudЕФАцБОУќУћЪЧвдТзЖиЕиЬњеОЕФУћзжРДУќУћЕФЃЉ
3.2 ЪОР§ЕижЗгыНсЙЙЫЕУї
ЪОР§
3.2.1 ЗўЮёзЂВсгыЗЂЯж - ЛљгкEureka
ДЫВПЗжЪОР§ЮЛгкЃКpart1_service-register-discovery
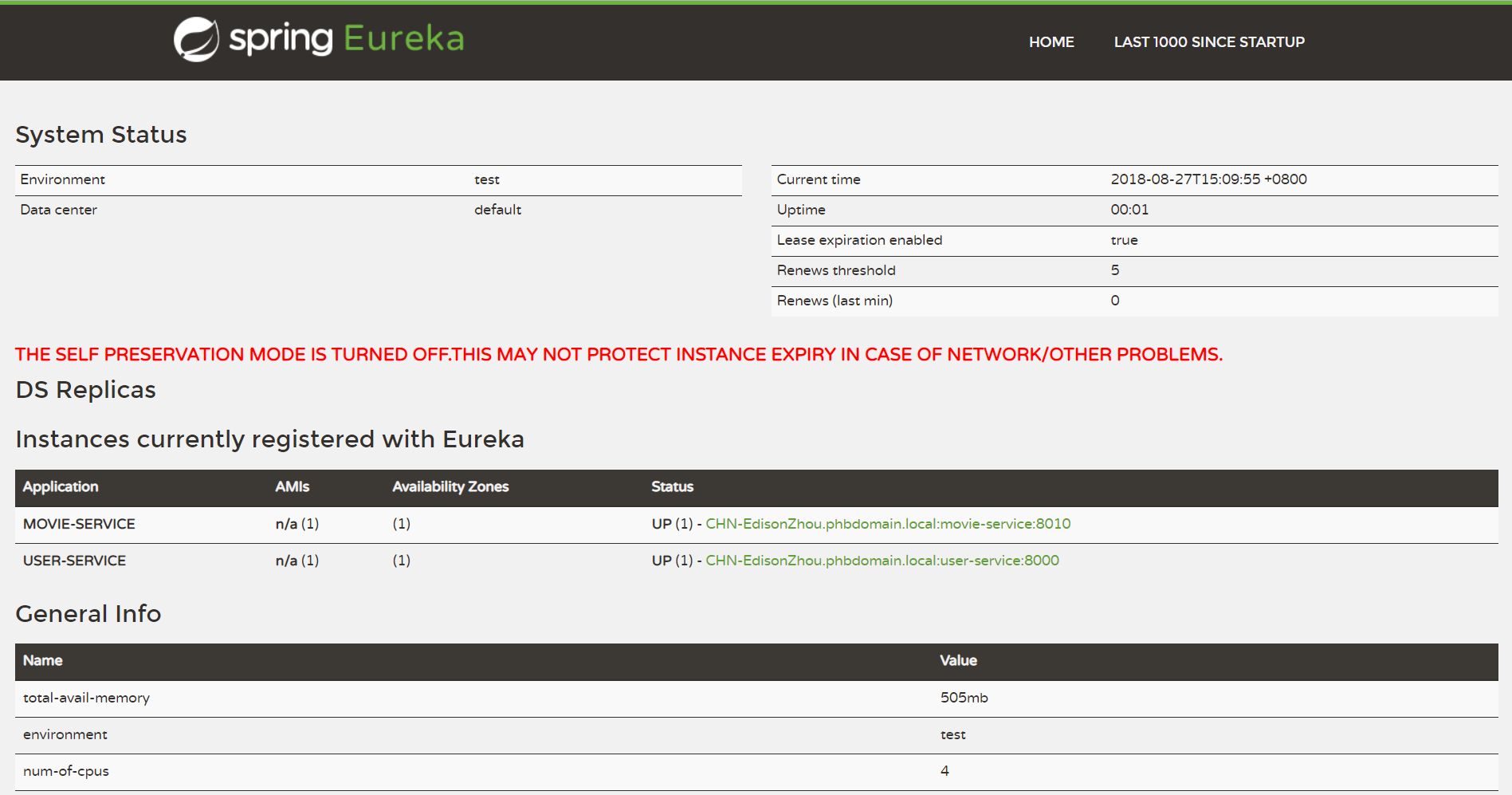
ДЫВПЗжЪОР§жївЊбнЪОСЫШчКЮЛљгкEurekaЪЕЯжЗўЮёЕФзЂВсгыЗЂЯжЃЌЦфжаАќРЈСНИіАцБОЃК
Ђй ЕЅНкЕуАцБО ЃЈПЊЗЂЛЗОГЕїЪдгУЃЉ => ЮЛгкeureka-service-sn (snДњБэsingle
node)ЯюФПФк
етРяашвЊзЂвтЕФЕиЗНЪЧЃКдкПЊЗЂЛЗОГашвЊЙиБеEurekaЕФздЮвБЃЛЄЛњжЦЃЌВЛШЛФуЮоЗЈЧсвзПДЕНЗўЮёвЦГ§ЕФаЇЙћЃЌашвЊдкapplication.ymlжаШчЯТЩшжУЃК
eureka:
server:
enableSelfPreservation: false # БОЕиЕїЪдЛЗОГЯТЙиБездЮвБЃЛЄЛњжЦ |
етЪЧвђЮЊEurekaПМТЧЕНЩњВњЛЗОГжаПЩФмДцдкЕФЭјТчЗжЧјЙЪеЯЃЌЛсЕМжТЮЂЗўЮёгыEureka
ServerжЎМфЮоЗЈе§ГЃЭЈаХЁЃЫќЕФМмЙЙембЇЪЧФўПЩЭЌЪББЃСєЫљгаЮЂЗўЮёЃЈНЁПЕЕФЮЂЗўЮёКЭВЛНЁПЕЕФЮЂЗўЮёЖМЛсБЃСєЃЉЃЌвВВЛУЄФПзЂЯњШЮКЮНЁПЕЕФЮЂЗўЮёЁЃЁЁ
Ђк HAЖрНкЕуАцБО ЃЈВПЪ№/ЩњВњЛЗОГгУЃЉ => ЮЛгкeureka-service-ha-1
& eureka-service-ha-2етСНИіЯюФПФк
ДЫАцБОашвЊзЂвтЕФЪЧСНИіНкЕуЕФapplication.ymlБЃГжвЛжТЃЌЕЋгЩгкЦфжаЪЙгУСЫpeer1КЭpeer2ЕФhostnameЃЌдкБОЕиПЊЗЂЛЗОГашвЊИјWindowsЃЈЮвМйЩшФуЪЙгУЕФЪЧWindowsЯЕЭГЃЉЩшжУhostsЮФМўШчЯТЃК
РЉеЙЃКГ§СЫEurekaжЎЭтЃЌЛЙПЩвдбЁдёЭЈгУаЭНЯЧПЕФConsulЃЌЙигкConsulЕФЛљБОИХФюгыЗўЮёЖЫЕФАВзАХфжУПЩвдПДПДЮвЕФетвЛЦЊЁЖ.Net
CoreЮЂЗўЮёжЎЛљгкConsulЪЕЯжЗўЮёзЂВсгкЗЂЯжЁЗСЫНтвЛЯТЁЃзюКѓЃЌВЛЕУВЛЫЕЃЌSpring Boot
КЭ Spring CloudжаКЫаФзщМўЗтзАЕФзЂНтецЕФЪЧЬЋЧПДѓСЫЃЌКмЖрВйзївЛИізЂНтжБНгИуЖЈЃЌЮоаыЙ§ЖрЕФcodingЁЃЁЁЁЁ
3.2.2 ПЭЛЇЖЫИКдиОљКт - ЛљгкRibbon
ДЫВПЗжЪОР§ЮЛгкЃКpart2_
client-load-balance
ДЫВПЗжЪОР§жївЊбнЪОСЫШчКЮЛљгкRibbonЪЕЯжПЭЛЇЖЫЕФИКдиОљКтЃЌНЈвщЦєЖЏЗНЪНЃКЯШЦєЖЏEurekaЃЌдйЦєЖЏUserServiceКЭMovieServiceЁЃЭЈЙ§ЗУЮЪMovieServiceЕФAPIНгПк
/log-instance НјааШежОВщПДЃЌВтЪдНсЙћШчЯТЭМЫљЪОЃК
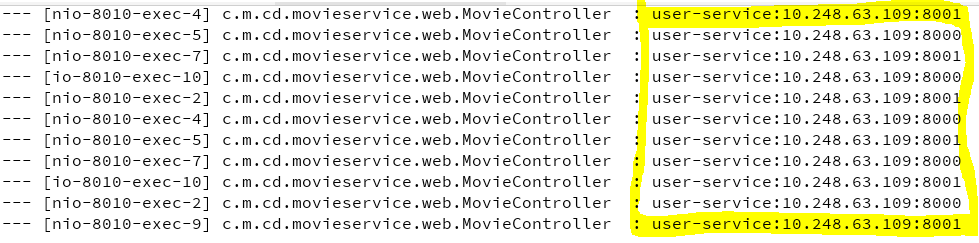
ДгЩЯЭМПЩвдПДГіЃЌЭЈЙ§ПЭЛЇЖЫЕФИКдиОљКтЫуЗЈЃЌвРДЮЗУЮЪСЫВЛЭЌЕФЗўЮёНкЕуЁЃ
3.2.3 ЩљУїЪНRESTЕїгУ - ЛљгкFeign
ДЫВПЗжЪОР§ЮЛгкЃКpart3_feign
ДЫВПЗжЪОР§жївЊбнЪОСЫЛљгкFeignШчКЮЪЕЯжЩљУїЪНЕїгУЃЌАќРЈвдЯТФкШнЃК
ЃЈ1ЃЉЛљБОећКЯFeignНјааЕЅВЮЪ§гыЖрВЮЪ§ЕФЧыЧѓЃКЮЛгкmovie-serviceетИіЯюФПФк
ашвЊзЂвтЕФОЭЪЧБ№ЭќСЫдкЦєЖЏРрМгЩЯ@EnableFeignClientsзЂНт
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients // вЊЪЙгУFeignЃЌашвЊМгЩЯДЫзЂНт
public class MovieServiceApplication {
public static void main(String[] args) {
SpringApplication.run (MovieServiceApplication.class,
args);
}
} |
ЃЈ2ЃЉздЖЈвхFeignХфжУЕФЪЙгУЃКЮЛгкmovie-service -feign-customizingетИіЯюФПФк
ЯТУцЕФFeignНгПкОЭЪЙгУСЫздЖЈвхЕФХфжУРрFeignConfigurationЁЃ
@FeignClient(name
= "user-service", configuration = FeignConfiguration.class)
public interface UserFeignClient {
/**
* ЪЙгУfeignздДјЕФзЂНт@RequestLine
* @see https://github.com/OpenFeign/feign
* @param id гУЛЇid
* @return гУЛЇаХЯЂ
*/
@RequestLine("GET /{id}")
User findById(@Param("id") Long id);
} |
ЃЈ3ЃЉFeignЕФШежОЕФЪЙгУЃКЮЛгкmovie-service-feign-loggingетИіЯюФПФк
ашвЊзЂвтЕФЪЧЃКFeignЫфШЛЬсЙЉСЫloggerЃЌЕЋЪЧЦфШежОДђгЁжЛЛсЖдDEBUGМЖБ№зіГіЯьгІЁЃШежОМЖБ№вЛЙВга4жжРраЭЃЌШчЯТЫљЪОЃК
Logger.Level ПЩбЁжЕЃК * NONE: ВЛМЧТМШЮКЮШежОЃЈФЌШЯжЕЃЉ * BASIC: НіМЧТМЧыЧѓЗНЗЈЁЂURLЁЂЯьгІзДЬЌТывдМАжДааЪБМф * HEADERS: МЧТМBASICМЖБ№ЕФЛљДЁжЎЩЯЃЌМЧТМЧыЧѓКЭЯьгІЕФheader * FULL: МЧТМЧыЧѓКЭЯьгІЕФheaderЃЌbodyКЭдЊЪ§Он
вЊЪфГіШежОДђгЁЃЌapplication.ymlФквЊЩшжУDEBUGМЖБ№ЃК
logging:
level:
# НЋFeignНгПкЕФШежОМЖБ№ЩшжУЮЊDEBUGЃЌвђЮЊFeignЕФLogger.LevelжЛеыЖдDEBUGзіГіЯьгІ
com.mbps.cd.movieservice .feign.UserFeignClient:
DEBUG |
зюКѓЃЌеыЖдFULLМЖБ№ЕФШежОДђгЁаЇЙћШчЯТЭМЫљЪОЃК

3.2.4 ШнДэДІРэ - ЛљгкHystrix
ДЫВПЗжЪОР§ЮЛгкЃКpart4_hystrix
ДЫВПЗжЪОР§жївЊбнЪОШчКЮЛљгкHystrixЪЕЯжШнДэДІРэЃЌжївЊАќРЈвдЯТФкШнЃК
ЃЈ1ЃЉЭЈгУЗНЪНећКЯHystrixЃКДЫЪОР§ЮЛгкmovie-serviceЯюФПжа
еыЖдЦеЭЈЕФЗНЗЈЃЌжЛашМгЩЯHystrixCommandзЂНтМАЖЈвхЛиЭЫЗНЗЈМДПЩЃЌР§ШчЃК
@HystrixCommand
(fallbackMethod = "findByIdFallback")
@GetMapping(value = "/user/{id}")
public User findById (@PathVariable Long id) {
return restTemplate.getForObject ("http://user-service/"
+ id, User.class);
}
public User findByIdFallback(Long id){
User user = new User();
user.setId(-1L);
user.setUsername("Default User");
return user;
} |
ЃЈ2ЃЉFeignЪЙгУHystrixЃКДЫЪОР§ЮЛгкmovie-service-feign-hystrixЯюФПжа
еыЖдFeignЃЌЫќЪЧвдНгПкаЮЪНЙЄзїЕФЃЌКУдкSpring CloudвбФЌШЯЮЊFeignећКЯСЫHystrixЃЌВЛЙ§ФЌШЯЪЧЙиБеЕФЃЌашвЊЪжЖЏдкХфжУЮФМўжаПЊЦєЃК
feign:
hystrix:
enabled: true |
дкжЎЧАЕФАцБОЃЈDalstonжЎЧАЕФАцБОЃЉжаЪЧФЌШЯПЊЦєЕФЃЌжСгкЮЊКЮвЊИФЮЊФЌШЯНћгУЃЌПЩвдПДПДетРяЃК
ШЛКѓжБНгдкFeignClientзЂНтжаМгШыfallbackЪєадМДПЩЃЌР§ШчЯТУцЫљЪОЃК
@FeignClient
(name = "user-service", fallback = FeignClientFallback.class)
public interface UserFeignClient {
@GetMapping(value = "/{id}")
User findById(@PathVariable("id") Long
id);
}
@Component
class FeignClientFallback implements UserFeignClient{
@Override
public User findById(Long id) {
User user = new User();
user.setId(-1L);
user.setUsername("Default User");
return user;
}
} |
ШчЙћЯывЊдкFeignЗЂЩњЛиЭЫЪБФмЙЛСєЯТШежОЙЉВщПДЛиЭЫдвђЃЌФЧУДПЩвдЪЙгУFallbackFactoryЃЌЪОР§ЯюФПЃКmovie-service
-feign-fallback-factory.
@FeignClient(name
= "user-service", fallbackFactory =
FeignClientFallbackFactory.class)
public interface UserFeignClient {
@GetMapping(value = "/{id}")
User findById (@PathVariable("id") Long
id);
}
@Component
class FeignClientFallbackFactory implements
FallbackFactory<UserFeignClient> {
private static final Logger LOGGER =
LoggerFactory.getLogger (FeignClientFallbackFactory.class);
@Override
public UserFeignClient create(Throwable cause)
{
return new UserFeignClient() {
@Override
public User findById(Long id) {
/*
* ШежОзюКУЗХдкИїИіfallbackжаЃЌЖјВЛвЊжБНгЗХдкcreateЗНЗЈжа
* Зёдђдкв§гУЦєЖЏЪБЃЌОЭЛсДђгЁИУШежО
*/
FeignClientFallbackFactory.LOGGER.info ("sorry,
fallback. reason was: ", cause);
User user = new User();
user.setId(-1L);
user.setUsername("Default Username");
return user;
}
};
}
} |
ЕБЗЂЩњЛиЭЫЪБЃЌШежОЪфГіаХЯЂШчЯТЃК

Г§ДЫжЎЭтЃЌЙигкHystrixВПЗжЃЌЛЙгаМрПиЕФжїЬтЃЌетРягЩгкЮвЫљдкЕФЯюФПзщЕФММЪѕМмЙЙжаВЛЛсЩцМАЕНЃЌвВОЭУЛгаХЊЃЌгааЫШЄЕФЭЏаЌПЩвдЙизЂвЛЯТHystrixздДјЕФМрПивдМАЛљгкTurbineЕФОлКЯМрПиЁЃВЮПМЮФеТЃКЁЖHystrixМрПиУцАхЃЈDalstonАцЃЉЁЗгыЁЖHystrixМрПиЪ§ОнОлКЯЁЗЁЃ
3.2.5 APIЭјЙи - ЛљгкZuul
ДЫВПЗжЪОР§ЮЛгкЃКpart5_zuul
ДЫВПЗжЪОР§жївЊбнЪОШчКЮЛљгкZuulЪЕЯжAPIЭјЙиЃЌжївЊАќРЈвдЯТФкШнЃК
ЃЈ1ЃЉећКЯZuulБраДAPIЭјЙиЃКЮЛгкzuul-serviceЯюФПжа
ПЩвдВтЪдбщжЄЕФФкШнЃК
ТЗгЩЙцдђЃКвРДЮЦєЖЏeurekaЃЌuser-serviceЃЌmovie-serviceЃЌzuul-serviceЃЌШЛКѓЭЈЙ§zuulЗУЮЪuser-serviceНгПк ИКдиОљКтЃКвРДЮЦєЖЏeurekaЃЌЖрИіuser-serviceЃЌzuul-serviceЃЌШЛКѓЖрДЮЗУЮЪuser-serviceЃЌзюКѓВщПДШежОаХЯЂЃЈСНИіuser-serviceЖМЛсДђгЁhibernateШежОаХЯЂЃЉЃЌбщжЄЪЧЗёДяЕНИКдиОљКтЕФаЇЙћЁЃPSЃКZuulФкжУСЫRibbonРДЪЕЯжИКдиОљКтЁЃЁЁЁЁ ТЗгЩЖЫЕуЃКвРДЮЦєЖЏeurekaЃЌuser-serviceЃЌmovie-serviceЃЌzuul-serviceЃЌШЛКѓфЏРРЦїЗУЮЪzuul-serviceЃЈhttp://localhost:5000/routesЃЉПЩвдЕУЕНТЗгЩЖЫЕуаХЯЂ
ЖдгкТЗгЩЖЫЕуЃЌашвЊИФвЛЯТвдЯТХфжУЃЌВХФме§ГЃЯдЪОТЗгЩЖЫЕуаХЯЂЃЌЗёдђЛсБЈ401ЕФДэЮѓЃК
management:
security:
enabled: false # ФЌШЯЮЊtrueЃЌИФЮЊfalseвдБуПЩвдПДЕНroutes |
ТЗгЩХфжУЃКЪОР§жївЊбнЪОСЫТЗгЩЧАзКЁЂШЋОжУєИаЩшжУвдМАТЗгЩЙцдђЩшжУ
ДѓЮФМўЩЯДЋЩшжУЃКеыЖдГЌДѓЮФМўЩЯДЋЃЈБШШч500MЃЉЃЌашвЊдкZuulжаЬсЩ§ГЌЪБЩшжУ
# ЯТУцЕФЩшжУеыЖдГЌДѓЮФМўЩЯДЋЃЈБШШч500MЃЉЃЌЬсЩ§СЫГЌЪБЩшжУ
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMillseconds: 60000
ribbon:
ConnectionTimeout: 3000
ReadTimeout: 60000 |
ЃЈ2ЃЉZuulЕФЙ§ТЫЦїЃКжївЊЮЛгкzuul-service-filterетИіЯюФПжа
ЖдгкZuulЕФЧыЧѓЩљУїжмЦкРДЫЕЃЌвЛЙВга4жжБъзМЙ§ТЫЦїРраЭЃК
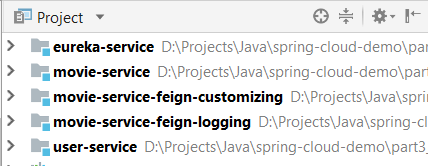
PREЃКдкЧыЧѓБЛТЗгЩжЎЧАЕїгУЃЌПЩРћгУетжжЙ§ТЫЦїЪЕЯжЩэЗнбщжЄЁЂМЧТМЕїЪдаХЯЂЕШВйзїЃЛ ROUTINGЃКНЋЧыЧѓТЗгЩЕНЮЂЗўЮёЃЌПЩРћгУетжжЙ§ТЫЦїгУгкЙЙНЈЗЂЫЭИјЮЂЗўЮёЕФЧыЧѓЃЛ POSTЃКдкТЗгЩЕНЮЂЗўЮёвдКѓжДааЃЌПЩгУРДЮЊЯьгІЬэМгБъзМЕФHTTP HeaderЁЂЪеМЏЭГМЦаХЯЂКЭжИБъЁЂНЋЯьгІДгЮЂЗўЮёЗЂЫЭИјПЭЛЇЖЫЕШЃЛ ERRORЃКдкЦфЫћНзЖЮЗЂЩњДэЮѓЪБжДааИУЙ§ТЫЦїЃЛЁЁЁЁ
ДЫЪОР§жабнЪОСЫPREРраЭЕФЙ§ТЫЦїЃЌВПЗжГЁОАЯТЃЌЯывЊНћгУВПЗжЙ§ТЫЦїЃЌжЛашвЊдкХфжУЮФМўжаЩшжУМДПЩЃЌР§ШчетРяНћгУPreRequestLogFilterЙ§ТЫЦїЃК
zuul:
# НћгУжИЖЈЙ§ТЫЦїЩшжУ
PreRequestLogFilter:
pre:
disable: true # НћгУЮвУЧДДНЈЕФPreRequestLogFilterЙ§ТЫЦї |
ЃЈ3ЃЉZuulЕФШнДэгыЛиЭЫЃКжївЊЮЛгкzuul-service-fallbackетИіЯюФПжа
ZuulздЩэОЭДјгаHystrixЃЌЕЋЪЧЫќМрПиЕФСЃЖШЪЧЮЂЗўЮёМЖБ№ЃЌЖјВЛЪЧФГИіAPIЃЌЕБФГИіAPIВЛПЩгУЪБЃЌЛсЭГвЛХз500ДэЮѓТыЕФвьГЃвГЁЃЮвУЧПЩвдЮЊZuulЬэМгЛиЭЫЃЌвдЪЕЯжИќгбКУЕФЗЕЛиаХЯЂЁЃЪЕЯжвВКмМђЕЅЃЌжЛашвЊЪЕЯжFallbackProviderНгПкМДПЩЁЃетРявЊзЂвтЕФЪЧЃЌЖдгкEdgwareжЎЧАЕФАцБОЃЈМДDalstonМАИќЕЭАцБОЃЉашвЊЪЕЯжЕФЪЧZuulFallbackProviderНгПкЃЌЖјEdgwareМАжЎКѓЕФАцБОвЊЪЕЯжЕФЪЧFallbackProviderНгПкЁЃвђЮЊFallbackProviderЪЧZuulFallbackProviderЕФзгНгПкЃЌЖјЫќЕФКУДІОЭЪЧЖрСЫвЛИіНгПкПЩвдЛёШЁПЩФмдьГЩЛиЭЫЕФдвђЃЌОпЬхПЩвдВЮПМетвЛЦЊЮФеТЃКЁЖSpring
Cloud EdgwareаТЬиаджЎАЫЃКZuulЛиЭЫЕФИФНјЁЗЁЃЯТУцЪЧБОЪОР§жаЗУЮЪuser-serviceНгПкЃЈuser-serviceБЛЮвЪжЖЏЙиБеЃЉКѓЕФЗЕЛиНсЙћЃК

ЃЈ4ЃЉZuulЕФИпПЩгУМмЙЙ
ЩњВњЛЗОГжавЛАуЖМашвЊВПЪ№ИпПЩгУЕФZuulвдБмУтЕЅЕуЙЪеЯЃЌЪЕМЪПЊЗЂжагаСНжжЧщПіЃК
Ђй ZuulЕФПЭЛЇЖЫвВзЂВсЕНСЫEureka ServerЩЯЃЈБШШчЃКMVC App, SPA ЕШЃЉ
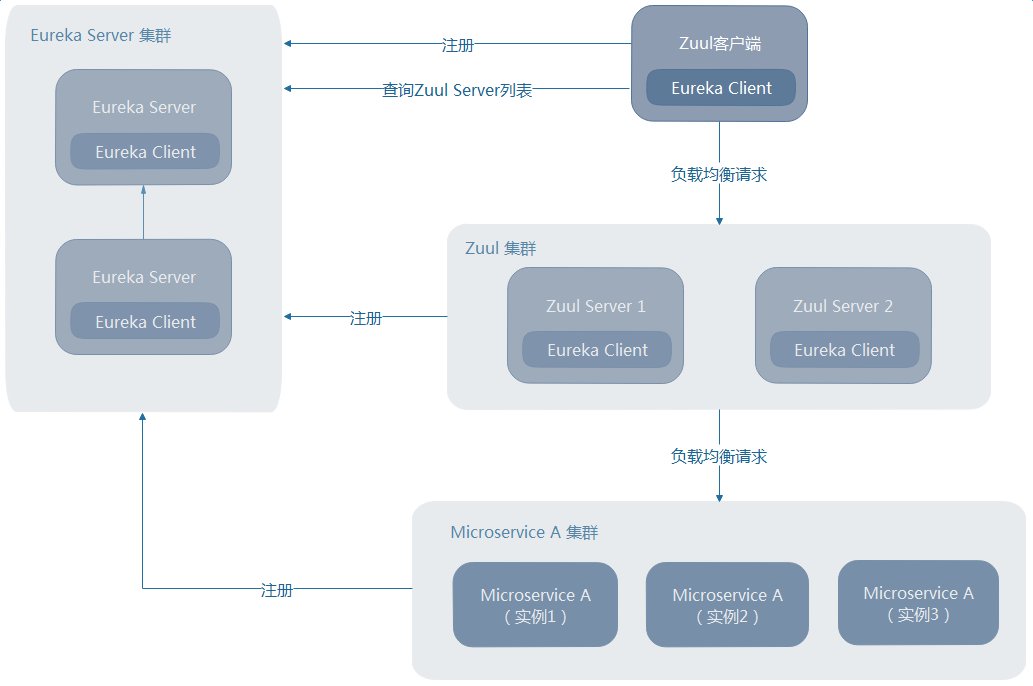
ДЫЪБZuulЕФИпПЩгУКЭЦфЫћЮЂЗўЮёУЛЧјБ№ЃЌЖМЪЧНшжњEurekaКЭRibbonРДЪЕЯжИКдиОљКтЁЃ
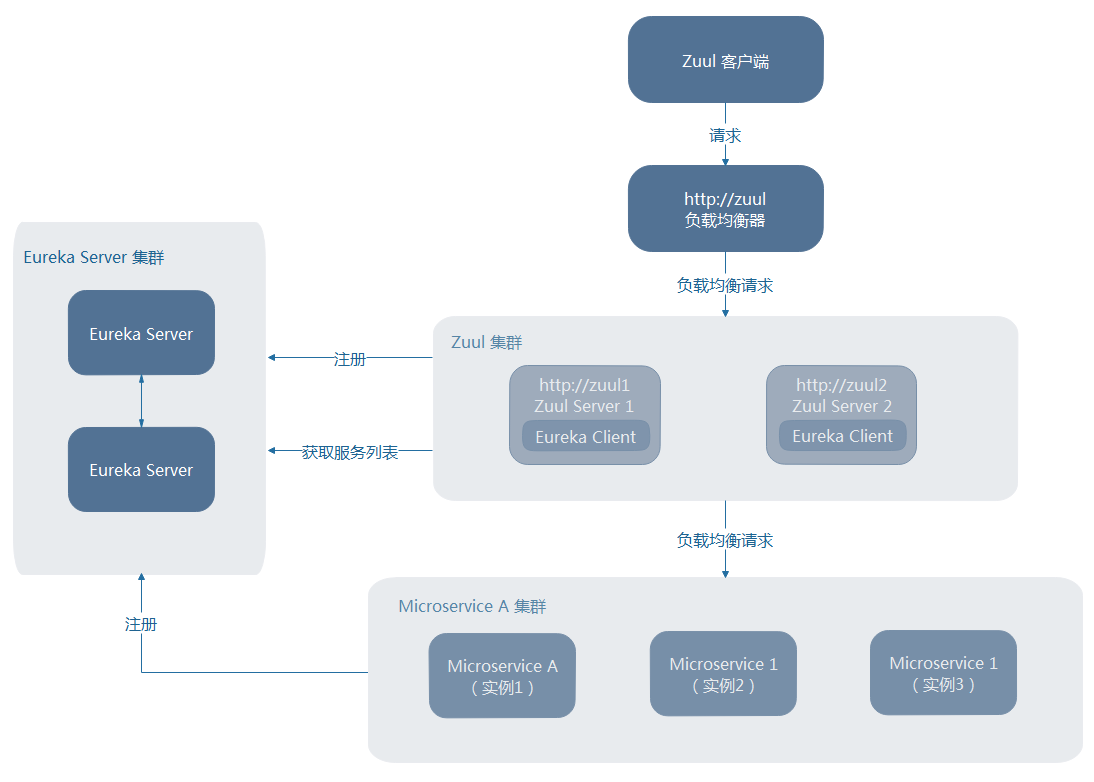
Ђк ZuulЕФПЭЛЇЖЫЮДзЂВсЕНEureka ServerЩЯЃЈБШШчЪжЛњAppЖЫЕШЃЉ
ЯжЪЕжаетжжГЁОАЛђаэИќГЃМћЃЌДЫЪБашвЊНшжњвЛИіЖюЭтЕФИКдиОљКтЦїРДЪЕЯжZuulЕФИпПЩгУЃЌБШШчЃКNginxЁЂHAProxyвдМАF5ЕШЁЃ
ЃЈ5ЃЉЪЙгУZuulОлКЯЮЂЗўЮёЃКДЫЪОР§ЮЛгкzuul-service-aggregationЯюФПжа
аэЖрГЁОАЯТПЩФмвЛИіЭтВПЧыЧѓвЊВщбЏZuulКѓЖЫЕФЖрИіЗўЮёЃЌетЪБПЩвдЪЙгУZuulРДОлКЯЗўЮёЧыЧѓЃЌМДжЛашЧыЧѓвЛДЮЃЌгЩZuulРДЧыЧѓИїИіЗўЮёЃЌШЛКѓзщжЏКУЪ§ОнЗЂЫЭИјПЭЛЇЖЫЃЈБШШчAppПЭЛЇЖЫЃЉЁЃЪОР§жажївЊЛљгкRxJavaгыZuulРДНсКЯЪЕЯжЕФЮЂЗўЮёЧыЧѓЕФОлКЯЁЃ
3.2.6 ЭГвЛХфжУЙмРэ - ЛљгкSpring Cloud Config
Spring Cloud ConfigЮЊЗжВМЪНЯЕЭГЭтВПЛЏХфжУЬсЙЉСЫЗўЮёЖЫКЭПЭЛЇЖЫЕФжЇГжЃЌАќРЈConfig
ServerКЭConfig ClientСНВПЗжЃЌЦфМмЙЙЭМШчЯТЭМЫљЪОЃК
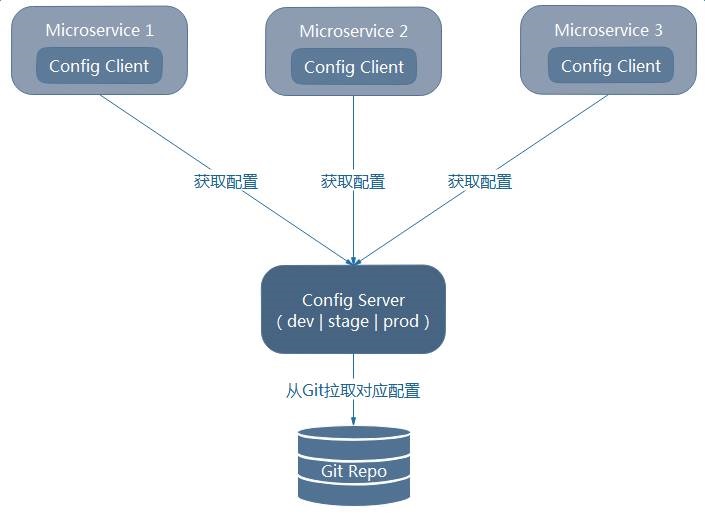
ЦфжаЃЌИїИіЮЂЗўЮёдкЦєЖЏЪБЛсЧыЧѓConfig ServerвдЛёШЁЫљашвЊЕФХфжУЪєадЃЌШЛКѓЛКДцетаЉЪєадвдЬсИпадФмЃЌШчЯТЭМЫљЪОЃК

ДЫВПЗжЪОР§ЮЛгкЃКpart6_config
ДЫВПЗжЪОР§жївЊбнЪОШчКЮЛљгкSpring Cloud ConfigЪЕЯжЭГвЛХфжУжааФЃЌжївЊАќРЈвдЯТФкШнЃК
ЃЈ1ЃЉЛљБОЕФConfig ServerгыConfig ClientБраДЃКДЫЪОР§ЮЛгкconfig-serviceгыconfig-clientжа
ДЫЪОР§ашвЊгУЕНвЛаЉвбЗХЕНgitЕФХфжУЮФМўЃЌетРяЮввбНЋЦфЗХЕНСЫgithubЗНБуДѓМвПЩвджБНгФУРДВтЪдгУЃЌВжПтЕижЗ
ЖЫЕугыХфжУЮФМўЕФгГЩфЙцдђШчЯТЃК
/{application}/{profile}[/{label}]
/{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application} -{profile}.properties
ЦфжаЃЌapplication: БэЪОЮЂЗўЮёЕФащФтжїЛњУћЃЌМДХфжУЕФspring.application.name
profile: БэЪОЕБЧАЕФЛЗОГЃЌdev, test or production?
label: БэЪОgitВжПтЗжжЇЃЌmaster or relase or others repository
name? ФЌШЯЪЧmaster
ЯюФПжаЃЌconfig-serviceЕФХфжУЮФМўШчЯТЃК
server:
port: 8080
spring:
application:
name: sampleservice-config-server
cloud:
config:
server:
git:
# ХфжУGitВжПтЕижЗ
uri: https://github.com/EdisonChou/ EDC.SpringCloud.Samples.Config
# GitВжПтеЫКХЃЈШчЙћашвЊШЯжЄЃЉ
username:
# GitВжПтУмТыЃЈШчЙћашвЊШЯжЄЃЉ
password: |
ЦєЖЏЫГађЃКЯШЦєЖЏconfig-serverЃЌдйЦєЖЏconfig-clientЃЌвђЮЊconfig-clientдкЦєЖЏЪБОЭЛиШЅconfig-serverЛёШЁХфжУЃЌШчЙћетЪБconfig-serverЮДЦєЖЏдђЛсБЈДэЁЃ
етРяашвЊзЂвтЕФОЭЪЧдкconfig-clientжаЃЌЖдгкspring
cloud configЕФХфжУгІИУЗХдкbootstrap.ymlжаЖјВЛЪЧapplication.ymlжаЃЌЗёдђЛсВЛЦ№зїгУЁЃетРяЩцМАЕНвЛИіspring
cloudЕФЁАв§ЕМЩЯЯТЮФЁБЕФИХФюЁЃ
ЃЈ2ЃЉЪЙгУ/refreshЖЫЕуЪжЖЏЫЂаТХфжУЃКШдШЛЮЛгкconfig-clientЯюФПжа
вЊЯыдкдЫааЦкМфЫЂаТХфжУЃЌашвЊСНЕуИФдьЃКМгЩЯ@RefreshScopeзЂНт
@RestController
@RefreshScope // @RefreshScopeзЂНтВЛФмЩйЃЌЗёдђМДЪЙЕїгУ/refreshЃЌХфжУвВВЛЛсЫЂаТ
public class ConfigClientController {
@Value("${profile}")
private String profile;
@GetMapping("/profile")
public String hello(){
return this.profile;
}
} |
ДЫЭтЃЌеыЖдSpring Boot 1.5.xЃЌЛЙашвЊИјconfig-clientЖЫЙиБеАВШЋШЯжЄЃЌЗёдђЮоЗЈе§ГЃrefreshЃК
management:
security:
enabled: false |
жЎКѓЃЌОЭПЩвдЭЈЙ§Ждconfig-clientЗЂЦ№POSTЧыЧѓЫЂаТХфжУСЫЃК

ВЛЙ§ЃЌШчЙћЫљгаЮЂЗўЮёЖМашвЊЪжЖЏЫЂаТХфжУЃЌЙЄзїСПЛсКмДѓЁЃЫљвдЃЌдкЪЕМЪЛЗОГжаЃЌвЛАуЛсЪЕЯжХфжУЕФздЖЏЫЂаТЁЃ
ЃЈ3ЃЉЪЙгУSpring Cloud BusздЖЏЫЂаТХфжУЃКДЫЪОР§ЮЛгкconfig-server-cloud-busгыconfig-client-cloud-busЯюФПжа
ДЫЪОР§ЪЙгУЕНЕФМмЙЙШчЯТЭМЫљЪОЃЌЫќНЋConfig ServerМгШыЯћЯЂзмЯпжЎжаЃЌВЂЪЙгУConfig
ServerЕФ/bus/refershЖЫЕуРДЪЕЯжХфжУЕФЫЂаТЁЃетбљЃЌИїИіЮЂЗўЮёжЛашвЊЙизЂздЩэЕФвЕЮёТпМЃЌЖјЮоашдйздМКЪжЖЏЫЂаТХфжУЁЃ

TipЃКSpring Cloud BusЛљгкЧсСПМЖЕиЯћЯЂДњРэЃЈР§ШчRabbitMQЁЂKafkaЕШЃЉСЌНгЗжВМЪНЯЕЭГЕФНкЕуЃЌОЭПЩвдЭЈЙ§ЙуВЅЕФЗНЪНРДДЋВЅзДЬЌЕФИќИФЃЈР§ШчХфжУЕФИќаТЃЉЛђепЦфЫћЕФЙмРэжИСюЁЃЮвУЧПЩвдНЋSpring
Cloud BusЯыЯѓГЩвЛИіЗжВМЪНЕФSpring Boot ActuatorЁЃЁЁЁЁ
дЫааЫГађЃКЯШЦєЖЏconfig-service-cloud-busЃЌдйЦєЖЏСНИіconfig-client-cloud-busЃЈЕквЛИіФЌШЯЖЫПк8081ЃЌЕкЖўИіЖЫПкИФЮЊ8082ЃЉЃЌаоИФgithubжаsampleservice-foo-dev.propertiesжаЕФprofileжЕКѓcommit
& pushЃЌШЛКѓPOSTЧыЧѓconfig-service-cloud-busЕФ/bus/refershЖЫЕуЃЌзюКѓдйДЮЗУЮЪСНИіclientЕФ/profileЖЫЕуНјаабщжЄЁЃ
ШчЙћВПЗжГЁОАЯывЊжЊЕРSpring Cloud BusЪТМўДЋВЅЕФЯИНкЃЌПЩвдЭЈЙ§вдЯТЩшжУРДИњзйЪТМўзмЯпЃК
spring:
cloud:
bus:
trace:
enabled: true # ПЊЦєcloud busИњзй |
ЃЈ4ЃЉгыEurekaЕФХфКЯЪЙгУЃКДЫЪОР§ЮЛгкconfig-service-eurekaгыconfig-client-eurekaСНИіЯюФПжа
ЃЈ5ЃЉConfig ServerЕФИпПЩгУЃКЩцМАЕНGitВжПтЕФИпПЩгУЁЂRabbitMQЕФИпПЩгУвдМАConfig
ServerздЩэЕФИпПЩгУЁЃ
ЖдгкGitВжПтЕФИпПЩгУЃЌЕкШ§ЗНGitВжПтРрЫЦгкGitHubЕШБОЩэвбОЪЕЯжСЫИпПЩгУЃЌЖјеыЖдздНЈGitВжПтШчGitLabЃЌПЩвдВЮПМGitLabЙйЗНЮФЕЕДюНЈИпПЩгУ
ЖдгкConfig ServerздЩэЕФИпПЩгУЃЌвВПЩвдЗжЮЊЮДзЂВсЕНEurekaКЭзЂВсЕНEurekaСНжжЧщаЮ
ДЫЭтЃЌЖдгкХфжУФкШнЕФМгУмЃЌДЫЪОР§УЛгаЩцМАЃЌЫќвРРЕгкJCEЃЈJava
Cryptography ExtensionЃЉ
РЉеЙЃКЙигкЭГвЛХфжУжааФЃЌЛЙПЩвдбЁдёИќКУгУЕФApolloЃЈаЏГЬЕФПЊдДЯюФПЃЉЃЌ
3.2.7 ЮЂЗўЮёИњзй - ЛљгкSpring Cloud Sleuth
ЪзЯШЃЌжЕЕУвЛЬсЕФЪЧSpring Cloud SleuthДѓСПНшгУСЫGoogle
DapperЃЌTwitter ZipkinКЭApache HTraceЕФЩшМЦЃЌЮвУЧЕУСЫНтвЛаЉЪѕгяЃЌР§ШчЃКspanЁЂtraceЁЂannotationЕШ.
ДЫЪОР§ЮЛгкЃКpart7_sleuth
ДЫВПЗжЪОР§жївЊбнЪОШчКЮЛљгкSpring Cloud SleuthЪЕЯжЗжВМЪНСДТЗМрПиЃЌжївЊАќРЈвдЯТФкШнЃК
ЃЈ1ЃЉЛљДЁећКЯSpring Cloud SleuthЃКЮЛгкuser-service-traceгыm
ovie-service-traceЯюФПжаЃЌжївЊВщПДПижЦЬЈЪфГіШежО
ЃЈ2ЃЉSpring Cloud SleuthгыZipkinЕФХфКЯЪЙгУЃКЮЛгкzipkin-service-serverЁЂ
user-service-trace-zipkinгыmovie-service-trace-zipkinШ§ИіЯюФПжа
ZipkinЪЧTwitterПЊдДЕФЗжВМЪНИњзйЯЕЭГЃЌЛљгкDapperТлЮФЩшМЦЖјРДЃЌжївЊЙІФмЪЧЪеМЏЯЕЭГЕФЪБађЪ§ОнЃЌДгЖјзЗзйЮЂЗўЮёМмЙЙЕФЯЕЭГбгЪБЮЪЬтЃЌДЫЭтЛЙЬсЙЉСЫвЛИіЗЧГЃгбКУЕФНчУцРДАяжњзЗзйЗжЮіЪ§ОнЁЃ
ЯТЭМЪЧвЛИіНгШыZipkinжЎКѓЕФЗўЮёЕїгУМђвзСїГЬЭМЃК
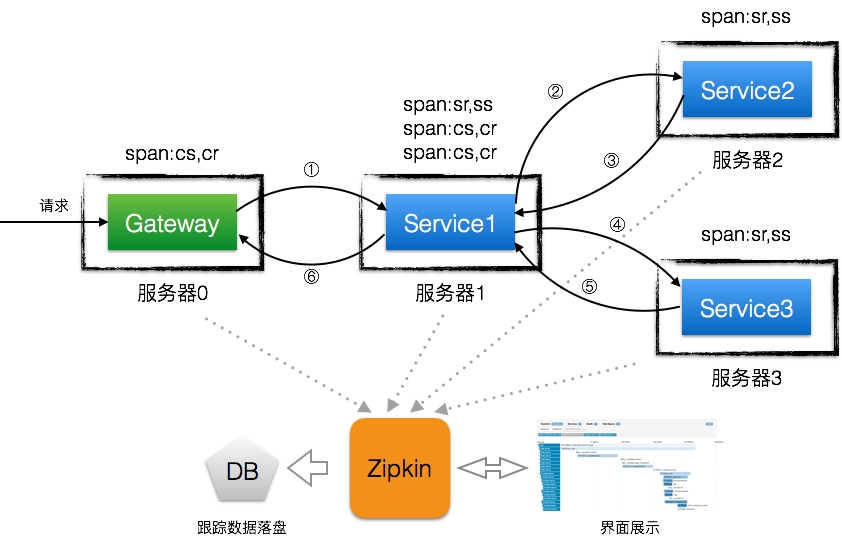
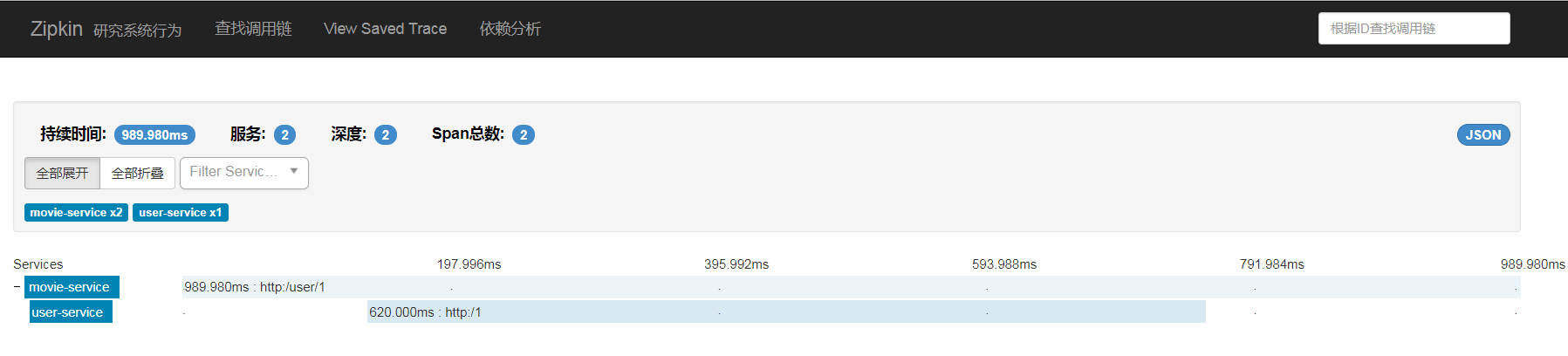
дЫааЫГађЃКЪзЯШдЫааzipkin-service-serverЃЌЦфДЮдЫааuser-service-zipkinгыmovie-service-zipkinЃЌШЛКѓЗУЮЪhttp://localhost:8010/user/1ЕУЕНЪ§ОнНсЙћЃЌзюКѓЗУЮЪzipkin
serverЪзвГЃЌЬюШыЦ№ЪМЪБМфЁЂНсЪјЪБМфЕШЩИбЁЬѕМўКѓЃЌЕуЛїFind a traceАДХЅЃЌПЩвдПДЕНtraceСаБэЃЌШчЯТЭМЫљЪОЃК
ЕуЛїЁАвРРЕЗжЮіЁБЃЌПЩвдЕУЕНЯТЭМЃЌгажњгкЮвУЧЗжЮівРРЕЙиЯЕЃК
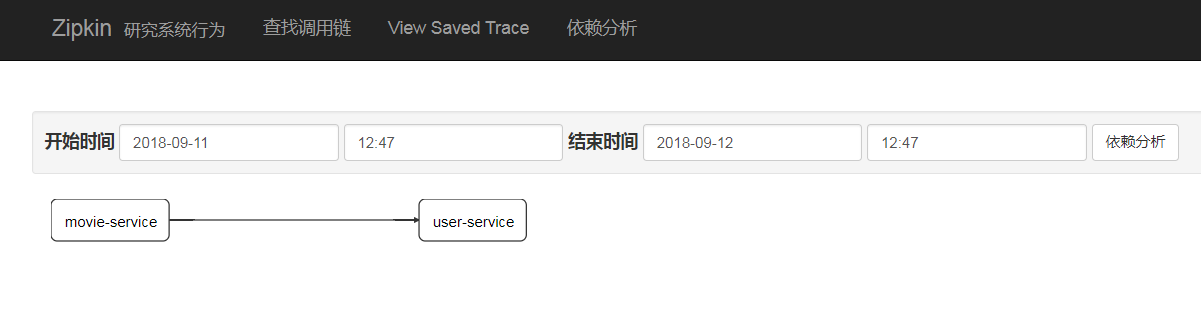
ашвЊзЂвтЕФЪЧЃЌдкПЊЗЂЕїЪдЪБЃЌвђЮЊФЌШЯЕФВЩбљАйЗжБШЪЧ10%ЃЌSleuthЛсКіТдДѓСПspanЃЌвђДЫЮвУЧПЩвддкПЊЗЂЛЗОГНЋЦфЩшжУЮЊ100%ЃК
spring:
sleuth:
sampler:
# жИЖЈашВЩбљЕФЧыЧѓЕФАйЗжБШЃЌФЌШЯЪЧ0.1ЃЈМД10%ЃЉЃЌетРяЗНБуВщПДЩшЮЊ100%ЃЈЪЕМЪЛЗОГВЛвЊетбљЩшжУЃЉ
percentage: 1.0 |
ЃЈ3ЃЉЪЙгУRabbitMQЪеМЏЪ§ОнЃКДЫЪОР§ЮЛгкzipkin-service-server-stream
гы user-service-trace-zipkin-streamСНИіЯюФПжа

ДЫЭтЃЌSpring Cloud SleuthЛЙПЩвдгыELKХфКЯЪЙгУЃЌВЛЙ§ДЫЪОР§УЛгаЩцМА.ЕБШЛЃЌЪОР§жаЕФИњзйЪ§ОнЖМЪЧДцЗХЕНФкДцжаЃЌЕЋЪЧИњзйЪ§ОнЛЙЪЧНЈвщДцЗХЕНElasticSearchжаЃЌЩњВњЛЗОГЧаФЊжЛДцДЂЕНФкДцжаЁЃ
|









