摘要:
大部分应用程序处理某种类型或其它类型的数据,这些数据的来源大部分是数据库。但是出于多方面原因,这些数据库的数据形成与应用程序交互的模型不同。本文描述利用更适合应用的“概念模型”来处理数据库的数据
内容
应用程序模型vs.存储架构
现代的应用程序,特别是Web应用程序主要是展现或操作一个或其它类型的数据。数据可能是搜索结果,库存目录,用户配置文件,帐户信息,财政信息,个人信息,地图坐标或天气等等各种形式。但是,所有数据都是存储于某个数据库。
然而数据库存储的数据并不是最适合应用程序进行用户展现和操作的形式。数据库架构的关系数据模型被典型地(也是正确地)从存储和完整性方面考虑来进行优化,但是却不适合应用
就像Dr. Peter Chen在他的开创性文章中介绍实体关系模型时所解释的,“关系模型…可以获得更高层次的数据独立性,但是也会丧失有关真实世界的一些重要的语义信息”,他的论文继续描述了实体关系模型的替代品“接受关于真实世界所包含的实体和关系的更自然的观点”(见资源)。
简单的说,如今的面向对象的应用程序,先不考虑终端用户,试图在关系数据库的平面行和列中对数据进行推理。“真实世界”包括关于对象类型,标识及其与其它对象关系的大量的概念。
先抛开表现力的问题不管,即使所有的应用程序概念都能够通过关系模型来表达,应用程序的开发人员通常并不能控制数据库架构。更糟的是,架构随时可能改变以优化不同的使用模式,使的硬编码的访问路径,映射和隐含的假设都变的无效。
小的应用程序都是通过直接嵌入逻辑从关系架构映射到应用程序数据对象。随着应用程序规模的增长,或是应用程序建立之初就是作为大型企业框架的一部分,数据访问逻辑通常分散为单独的数据抽象层(Data
Abstraction Layer,DAL)。无论是应用程序的组成部分,还是单独的组件,关于数据库架构,关系,使用约定和访问模式的硬编码隐含假设使得维护和扩展数据访问代码越来越难,尤其是根据底层架构的更改来进行维护和扩展。
让我们详细了解一下这些问题。
数据库架构规范化
像Dr. Codd描述的那样,数据库中的数据通常展现为“规范化的”视图,独立的同构的(矩形)表包含具有单值的列。通过将没有行的特定值移到单独的表中来降低冗余,从而改进数据的完整性。基于对列中不同数据的表示含义的应用程序知识,这些单独表中的数据通过联接来组合。外键可能或不可能在相关信息的表中使用可以作为进一步加强数据完整性的方法,但是它们本身不能定义导航路径或联接条件。
“如今的面向对象的应用程序,先不考虑终端用户,试图在关系数据库的平面行和列中对数据进行推理。“真实世界”包括关于对象类型,标识及其与其它对象关系的大量的概念。”
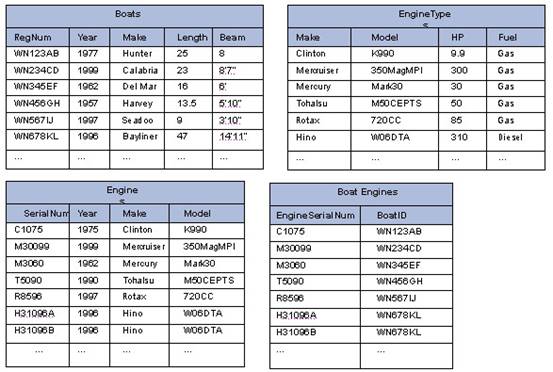
让我们举一个例子。假设您经营二手船,您想将所有库存存入数据库,可以通过Web应用展现给顾客。您必须为每艘船保存的信息为:注册,制造,年份,长度和宽度。对于有引擎的船,您想存储:制造,年份,马力,燃油类型和引擎的序列号。一个完整的规范化架构可能将引擎信息分为三个单独的表,一个包括特定马达类型的信息(制造,模型,马力,燃油类型,其中制造和模型组成组合键),一个是每个实际的引擎(序列号,年份,制造和模型)以及一个表用来连接船和引擎。建立的架构如图1所示.
为了能够展示相对简单的库存页,包含船注册数,年份,制造,以及相关引擎信息,对于所有的马达船,您的Web应用程序可能使用以下查询:
图 1:完全规范化的架构
SELECT Boats.RegNum, Boats.Year AS
Boat_Year, Boats.Make AS Boat_Make,
BoatEngine.SerialNumber, BoatEngine.Year AS
Engine_Year, BoatEngine.Make
AS Engine_Make, BoatEngine.Model AS
Engine_Model, BoatEngine.HP
FROM Boats
INNER JOIN (
SELECT EngineType.Make, BoatEngines.BoatID,
EngineTypes.HP
FROM EngineTypes
INNER JOIN (Engines
INNER JOIN BoatEngines
ON Engines.SerialNumber = BoatEngines.EngineSerialNum)
ON EngineTypes.Model = Engines.Model
AND EngineTypes.Make = Engines.Make
) AS BoatEngine
ON Boats.RegNum = BoatEngine.BoatID
这种查询不仅复杂,而且需要对表的之间的联系事先有了解;如Engines表的Make 和 Model列与EngineTypes的Make
和 Model列相联系,而BoatEngines表的EngineSerialNum 和 BoatID列分别与Engines
和 Boats表 SerialNum 和 RegNum columns 相联系。
并且,查询只希望通过船和马达的内部联接返回马达船(而不是帆船)。当然,这种查询就会丢失没有引擎的马达船,并且也会排除小帆船和通常有马达的大船(包括我们的25-foot
Hunter sailboat)。因此,尽管基于当时的框架和数据进行应用程序开发时,假设是有效的,但是将隐含逻辑与应用程序中的查询混在一起将会比较依赖于数据和架构,从而很难跟踪和维护。
很明显,尽管从数据库的角度,该架构是非常的规范,但是并不是非常适合应用程序的形式。更糟的是,为了提取想要的数据(先不说进行更新如将引擎加到不同的船上),必须将表之间关系的隐性知识加入应用程序。对架构进行更改,如将Engines
和 BoatEngines合成(为了改善性能DBA所采取的一种很合理的反向规范化),将会引起难以预测和解决的应用程序错误。
表达继承
现在让我们考虑向框架增加更多的信息。首先您通过向表中增加“Style”列来区别帆船和不同类型的马达船。然后,您向帆船增加Keel(Fixed,
Swing, 或Dagger)以及帆数。对ski boats,您增加ski pylon 和/或 tower,对于MotorYachts,您增加它是否具有flybridge。由于每个增加的信息只是应用到Boats的行的子集中,因此这一关系数据模型非常具有挑战性。一种表达方法就是为每个派生的类型扩展数据库(“Boats”),没有应用的则用Null来表示。例如,这些信息可以在一个稀疏表格“Boats”中表示,如图2所示。
图 2:单稀疏表 “Boats” 的层次化表达
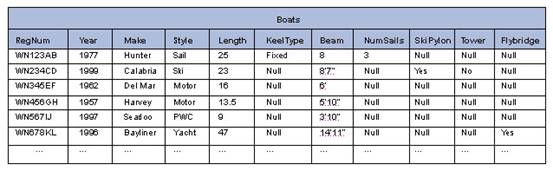
正如我们所看到的,我们为派生的类型增加的属性越多,整个表格的框架增长的就越多,从而我们为不相干的字段增加的Null值也就越多。表达同样信息的一种替代方法就是将为Sailboats,
Ski Boats和 Motor Yachts增加的信息分成单独的表,如图3所示。
图 3:在单个表中存储扩展信息
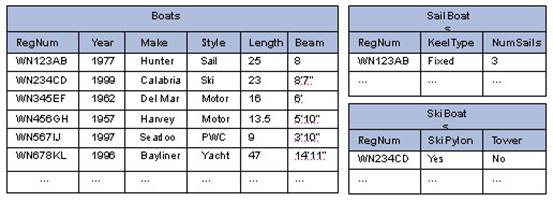
这种布局就避免了为派生类型的每个属性增加数据库表的稀疏列,但是查询却变得更加复杂,因为为了能包括每个派生类型的完整信息,每个查询都必须联接增加的表。例如,如需为没有tower
的所有船返回boat registration, year,make和相关 engine 信息,我们必须编辑以下的查询:
SELECT Boats.RegNum, Boats.Year AS
Boat_Year, Boats.Make AS Boat_Make,
BoatEngine.SerialNumber, BoatEngine.Year AS
Engine_Year, BoatEngine.Make
AS Engine_Make, BoatEngine.Model AS
Engine_Model, BoatEngine.HP
FROM (Boats
LEFT OUTER JOIN (
SELECT EngineTypes.Make, BoatEngines.BoatID,
EngineTypes.HP
FROM EngineTypes
INNER JOIN (Engines
INNER JOIN BoatEngines
ON Engines.SerialNumber = BoatEngines.EngineSerialNum)
ON EngineTypes.Model = Engines.Model
AND EngineTypes.Make = Engines.Make
) AS BoatEngine
ON Boats.RegNum = BoatEngine.BoatID
) LEFT JOIN SkiBoats
ON Boats.RegNum = SkiBoats.RegNum
WHERE Boats.Style In (“Ski”,”Motor”,”PWC”,”Yacht”)
AND (SkiBoats.Tower=False OR SkiBoats.Tower
IS NULL)
请注意,为了获得Tower信息,我们必须将Boats 表与SkiBoats表相联接,并且我们必须在描述中考虑不属于SkiBoats的行的Null值。
随着表的增加,DBA可能决定重新建立架构以使一个特定类型的船的所有信息都包含在一个表中,如图4所示。
图4:Boat类型建立的完全独立的表
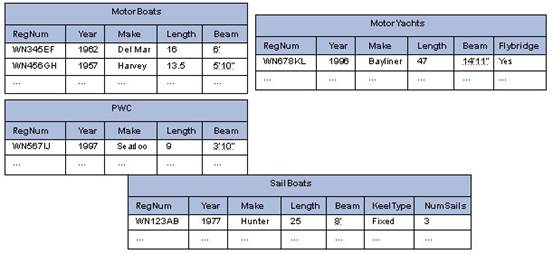
该框架针对一种单一类型的船的查询进行优化,而忽略了对所有类型船的查询。这也就意味着应用程序中的查询部分需要修改。我们对船和引擎信息的查询如下面所示:
SELECT Boats.RegNum, Boats.Year AS
Boat_Year, Boats.Make AS Boat_Make,
BoatEngine.SerialNumber, BoatEngine.Year AS
Engine_Year, BoatEngine.Make
AS Engine_Make,BoatEngine.Model AS Engine_Model,
BoatEngine.HP
FROM (
(SELECT RegNum, Year, Make, Tower
FROM SkiBoats
UNION ALL SELECT RegNum, Year,
Make, NULL As
Tower FROM MotorBoats
UNION ALL SELECT RegNum, Year,
Make, Null AS Tower FROM PWC
UNION ALL SELECT RegNum, Year,
Make, Null AS Tower FROM MotorYachts
) AS Boats
LEFT OUTER JOIN (
SELECT EngineTypes.Make, BoatEngines.BoatID,
EngineTypes.HP
FROM EngineTypes
INNER JOIN (Engines
INNER JOIN BoatEngines
ON Engines.SerialNumber = BoatEngines.EngineSerialNum)
ON EngineTypes.Model = Engines.Model
AND EngineTypes.Make = Engines.Make
) AS BoatEngine
ON Boats.RegNum = BoatEngine.BoatID
)
WHERE (Boats.Tower=False OR Boats.Tower
IS NULL)
请注意为了查询所有类型的船,包括特定于SkiBoats 的Tower列,我们必须为UNION ALL中其它表的字段显性指定Null值。
ADO.NET 实体
每个例子都说明了应用程序开发人员试图展现,操作平面关系架构和将有趣的真实世界模型在其中表达时,所遇到的挑战。事实上,此架构不能被应用程序开发人员所拥有,而是随着时间不断的变化,从而解释了从代码,开发和维护成本角度来理解,为什么说数据访问“goo”占据了应用程序和框架的较大比例。
进入ADO.NET 实体框架
ADO.NET 实体框架将作为.NET框架的扩展在2008年上半年问世,这是Microsoft Visual
Studio 代号“Orcas”的一部分,表达了面向丰富、通用实体数据模型的微软实体数据平台的首批成果。ADO.NET
实体框架是在关系数据上执行Dr. Chen的实体关系模型。取代了原先由存贮表达指挥应用程序表达得情况,编写通用概念模型允许应用程序利用真实世界的概念对数据进行建模,从而更具有表现力。这些概念可以被映射为多种多样的存储表达。(如需更多ADO.NET实体框架信息,请参见资源)。
实体框架使用客户端视图机制来扩展查询和将概念模型写入存储框架的更新。扩展的查询在数据库中进行完全的评价;没有客户端的查询处理。出于性能的考虑,这些客户端视图可以编译到您的应用程序,或是通过从XML文件产生的元数据中映射而实时产生,允许部署的应用程序面对不同的或是进化的存储结构而无需重新编译。
一个应用程序的模型
图5展现了更适合于Web应用程序的面向应用的数据模型。值得注意的是,尽管我使用类图来表达模型,但是对象仅是在实体框架中将此概念模型向应用程序展现的方法之一。同一概念模型可以直接使用扩展的SQL语法,也可以以多形的,层次化的记录返回。
图 5: 一个面向应用的概念模型

首先我们对此模型所要关注的是它和以前的任何一个存储架构都不同。例如:
1 Engine类包括来自EngineTypes 表 (Make, Horsepower和
Fuel)和Engines表(Year and SerialNumber)的信息。
2 没有包括BoatID 属性,Engine类包含了对Boat的引用。
3 Boats包含0个或更多引擎的集合。
4 不展现Boat的属性Style,也不为每个增加的属性都建立不同的表,我们使用更自然的继承概念来区分不同类型的船。
实体框架允许您将概念模型展现给应用程序,对以前描述的任何数据库架构使用应用概念如强类型,集成和关系等。事实是映射在应用程序之外声明,这也就意味着如果数据库架构随着时间的推移为了不同的访问模式而进行优化,仅需要更改映射;应用程序可以继续使用同一查询,并且在同一概念模型中提取同一结论。
让我们看一下此概念模型是如何简化我们的应用程序模式的。
查询概念模型
有了这个概念模型,查询一个单独的船的多形集合变的更简单了。例如,以下是利用该概念框架查询所有没有tower的motorboat的registration
year,make和engine信息的代码。
SELECT boat.RegNum, boat.Year, boat.Make,
boat.Engines
FROM Boats AS boat
WHERE boat IS OF (Motorboat)
AND (Boat IS NOT OF (SkiBoat)
OR TREAT(boat AS SkiBoat).Tower
= False)
请注意此查询中不需要联接;实体是强类型定义的,关系通过属性来遍历,可以根据层次内的类型来过滤集合。
嵌套结果
前面三个查询都是针对数据库架构的,查询结果如图6所示。请注意最后一只船(the 1996 BayLiner)出现了两次。从数据中我们可以看出the
1996 BayLiner是一种有两个Hino 310 引擎的MotorYacht。因为关系数据是平面的,所有没有更好的方法在一行上表达多个引擎;因此,对同一艘船,返回了两行结果-一个引擎对应一行。
图 6:以矩形表形式返回的嵌套结果

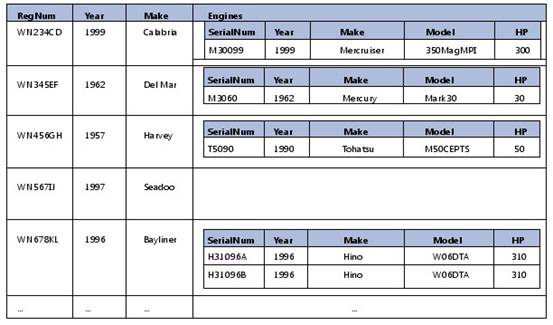
而使用概念模型的查询返回的“Engines”列,一艘船只对应一行,但是包含引擎的集合,如图7所示。
图 7:以嵌套表的形式返回结果
如果每个引擎只有一个自己的数据(例如Make和HP),就可以选择将信息表达如下:
SELECT boat.RegNum, boat.Year,
boat.Make,
SELECT engine.Make, engine.HP FROM boat.Engines
AS engine
FROM Boats AS boat
WHERE boat IS OF (Motorboat)
AND (Boat IS NOT OF (SkiBoat)
OR TREAT(boat AS SkiBoat).Tower
= False)
请注意此查询仍然不需要开发人员编写任何联接;引擎的相关字段利用boat.Engines作为子查询源而投影为嵌套的列。
不同应用程序的不同视图
Web应用程序框架经常需要将同一数据通过不同的Web应用程序展现为不同的视图。例如,您向没有授权的Web客户端展现的内容往往是信任客户端展现内容的子集,同时也与展现给内部的管理和报表的应用程序的数据不同。同样的,您在应用程序框架内部处理的数据架构也与您在进行商业事务交换的数据架构大不相同。ADO.NET实体框架将不同的概念模型映射到同一数据库架构,从而满足了这些类型场景的需求。
将结论建模为对象
前面的例子将返回结论表达为记录。在ADO.NET实体框架中,这意味着将结论作为DataReader返回,可以对其进行扩展从而支持类型信息,多形现象,嵌套和复杂值。有了实体,就可以对同一个概念模型编写查询,返回强类型的业务对象结论。当把结论建模为业务对象时,关系就可以通过对象的类型属性进行导航和更新,而不需要操作大量的外键值。对业务对象也可以选择身份解析和更改追踪。
以下代码说明了通过业务对象使用概念模型的例子。这个例子表现了通过查询概念模型而将boats返回为对象,通过engine集合的属性导航,并去除与船不是同一个年份的引擎。对数据库的更改通过对SaveChanges()的调用进行保存。
// Specify query as an eSQL
string string eSql =
“SELECT VALUE boat FROM Boats
AS boat “ +
“WHERE EXISTS(“ +
“SELECT engine from boat.Engines
AS engine “ +
“WHERE engine.Year != boat.Year)”;
BoatInventory inventory = new BoatInventory();
ObjectQuery<Boat> motorizedBoats =
inventory.CreateQuery<Boat>(eSql);
// Include Engines in results
motorizedBoats.Span.Include(“Engines”);
// Loop through Engines for
each Boat foreach(Boat boat in
motorizedBoats) {
foreach(Engine engine in boat.Engines)
{
if(engine.Year!= boat.Year)
boat.Engines.Remove(engine);
// alternatively
// engine.Boat = null;
}
}
inventory.SaveChanges();
“事实上,此架构不能被应用程序开发人员所拥有,而是随着时间不断的变化,从而解释了从代码,开发和维护成本角度来理解,为什么说数据访问“goo”占据了应用程序和框架的较大比例。
请注意,与前面的概念查询例子一样,这里的查询中也不需要联接。对象结论是强类型和可更新的,对两个不同类型关系的导航和修改通过属性和方法来完成,而不需更新大量键值。
同样的查询可以采用Microsoft Visual Studio和.NET Framework 的下一代版本(代码为“Orcas”)的新的Language
Integrated Query (“LINQ”)扩展来实现,如下所示:
BoatInventory inventory = new BoatInventory();
// Include Engines in queries
for Boats inventory.Boats.Span.Include(“Engines”);
// Specify query through LINQ
var motorizedBoats =
from boat in inventory.Boats
where boat.Engines.Any(e => e.Year
!= boat.Year)
select boat;
// Loop through Engines for
each Boat foreach(Boat boat in
motorizedBoats) {
foreach(Engine engine in boat.Engines)
{
if(engine.Year != boat.Year)
boat.Engines.Remove(engine);
// alternatively
// engine.Boat = null;
}
}
inventory.SaveChanges();
结论
总之,至少有六个原因说明直接向数据库存储框架编写应用程序存在很多问题:
1 您既不能控制应用程序对象模型也不能控制存储架构。
2 数据库的规范化程度使其很难直接从应用程序中使用。
3 特定的真实世界建模概念无法直接在关系架构中表达。
4 应用程序被迫需要了解数据库架构中字段是如何使用的,从而很难跟踪和维护。
5) 不同的应用程序需要对同一数据展现不同的视图。
6 数据库架构会随着时间发生变化,从而导致直接面向架构的应用程序不可用。
ADO.NET实体框架允许您的应用程序使用应用程序概念(如强类型,继承和关系)来建立概念模型。该概念模型可以映射到各种存储架构。由于映射是应用程序外声明的,那么如果数据库架构随着时间的推移为了不同的访问模式而进行优化,仅需要更改映射;应用程序可以继续使用同一查询,并且在同一概念模型提取同一结论。
资源
Next-Generation Data Access: Making the Conceptual Level
Real,J. Blakeley, D. Campbell, J. Gray, S. Muralidhar和A.
Nori (MSDN, 2006年6月)
The ADO.NET Entity Framework Overview,(MSDN, 2006年6月)
The LINQ Project, (MSDN, 2007年1月)
Visual Studio Future Versions (MSDN, 2007年1月)
Dr. Peter Chen: Entity Relationship Model - Past, Present
and Future,2007年4月
The Entity-Relationship Model ― Toward a Unified
View of Data, P.P.S. Chen. ACM Transactions on Database
Systems (TODS), 1976.
A Relational Model of Data for Large Shared Data
Banks, E. Codd. Communications of the ACM, 1970. | 