| 编辑推荐: |
此文主要介绍了贫血模型、领域模型、贫血模型中Facade有何用等相关内容。
本文来自于博客园,由火龙果软件Anna编辑、推荐。 |
|
领域模型
最近taowen同学连续发起了两起关于贫血模型和领域模型的讨论,引起了大家的广泛热烈的讨论,但是讨论(或者说是争论)的结果到底
怎样,我想值得商榷。问题是大家对贫血模型和领域模型都有自己的看法,如果没有对此达到概念上的共识,那么讨论的结果应该可想而知,讨论的收获也是有的,
至少知道了分歧的存在。为了使问题具有确定性,我想从一个简单例子着手,用我对贫血模型和领域模型的概念来分别实现例子。至于我的理解对与否,大家可以做
评判,至少有个可以评判的标准在这。
一个例子
我要举的是一个银行转帐的例子,又是一个被用滥了的例子。但即使这个例子也不是自己想出来的,而是剽窃的<<POJOs
in Action>>中的例子,原谅我可怜的想像力 。当钱从一个帐户转到另一个帐户时,转帐的金额不能超过第一个帐户的存款余额,余额总数不能变,钱只是从一个账户流向另一个帐户,因此它们必须在一个事务内完成,每次事务成功完成都要记录此次转帐事务,这是所有的规则。
贫血模型
我们首先用贫血模型来实现。所谓贫血模型就是模型对象之间存在完整的关联(可能存在多余的关联),但是对象除了get和set方外外几乎就没有其它的方
法,整个对象充当的就是一个数据容器,用C语言的话来说就是一个结构体,所有的业务方法都在一个无状态的Service类中实现,Service类仅仅包
含一些行为。这是Java Web程序采用的最常用开发模型,你可能采用的就是这种方法,虽然可能不知道它有个“贫血模型”的称号,这要多
亏Martin Flower(这个家伙惯会发明术语!)。
包结构
在讨论具体的实现之前,我们先来看来贫血模型的包结构,以便对此有个大概的了解。

贫血模型的实现一般包括如下包:
dao:负责持久化逻辑
model:包含数据对象,是service操纵的对象
service:放置所有的服务类,其中包含了所有的业务逻辑
facade:提供对UI层访问的入口
代码实现
先看model包的两个类,Account和TransferTransaction对象,分别代表帐户和一次转账事务。由于它们不包含业务逻辑,就是一个普通的Java
Bean,下面的代码省略了get和set方法。
public class
Account {
private String accountId;
private BigDecimal balance;
public Account() {}
public Account(String accountId, BigDecimal balance)
{
this.accountId = accountId;
this.balance = balance;
}
// getter and setter ....
} |
public class
TransferTransaction {
private Date timestamp;
private String fromAccountId;
private String toAccountId;
private BigDecimal amount;
public TransferTransaction() {}
public TransferTransaction(String fromAccountId,
String toAccountId, BigDecimal amount, Date timestamp)
{
this.fromAccountId = fromAccountId;
this.toAccountId = toAccountId;
this.amount = amount;
this.timestamp = timestamp;
}
// getter and setter ....
} |
这两个类没什么可说的,它们就是一些数据容器。接下来看service包中TransferService接口和它的实现
TransferServiceImpl。TransferService定义了转账服务的接口,TransferServiceImpl则提供了转账服
务的实现。
public interface
TransferService {
TransferTransaction transfer (String fromAccountId,
String toAccountId, BigDecimal amount)
throws AccountNotExistedException, AccountUnderflowException;
} |
public class
TransferServiceImpl implements TransferService
{
private AccountDAO accountDAO;
private TransferTransactionDAO transferTransactionDAO;
public TransferServiceImpl (AccountDAO accountDAO,
TransferTransactionDAO transferTransactionDAO)
{
this.accountDAO = accountDAO;
this.transferTransactionDAO = transferTransactionDAO;
}
public TransferTransaction transfer (String fromAccountId,
String toAccountId,
BigDecimal amount) throws AccountNotExistedException,
AccountUnderflowException {
Validate.isTrue (amount.compareTo(BigDecimal.ZERO)
> 0);
Account fromAccount = accountDAO.findAccount(fromAccountId);
if (fromAccount == null) throw new AccountNotExistedException (fromAccountId);
if (fromAccount.getBalance( ).compareTo(amount)
< 0) {
throw new AccountUnderflowException (fromAccount,
amount);
}
Account toAccount = accountDAO.findAccount (toAccountId);
if (toAccount == null) throw new AccountNotExistedException (toAccountId);
fromAccount.setBalance (fromAccount.getBalance( ).subtract(amount));
toAccount.setBalance (toAccount.getBalance().add(amount));
accountDAO.updateAccount (fromAccount); // 对Hibernate来说这不是必须的
accountDAO.updateAccount (toAccount); // 对Hibernate来说这不是必须的
return transferTransactionDAO.create (fromAccountId,
toAccountId, amount);
}
} |
TransferServiceImpl类使用了AccountDAO和TranferTransactionDAO,它的transfer方法负责整个
转帐操作,它首先判断转帐的金额必须大于0,然后判断fromAccountId和toAccountId是一个存在的Account的
accountId,如果不存在抛AccountNotExsitedException。接着判断转帐的金额是否大于fromAccount的余额,如
果是则抛AccountUnderflowException。接着分别调用fromAccount和toAccount的setBalance来更新它
们的余额。最后保存到数据库并记录交易。TransferServiceImpl负责所有的业务逻辑,验证是否超额提取并更新帐户余额。一切并不复杂,对
于这个例子来说,贫血模型工作得非常好!这是因为这个例子相当简单,业务逻辑也不复杂,一旦业务逻辑变得复杂,TransferServiceImpl就
会膨胀。
优缺点
贫血模型的优点是很明显的:
被许多程序员所掌握,许多教材采用的是这种模型,对于初学者,这种模型很自然,甚至被很多人认为是java中最正统的模型。
它非常简单,对于并不复杂的业务(转帐业务),它工作得很好,开发起来非常迅速。它似乎也不需要对领域的充分了解,只要给出要实现功能的每一个步骤,就能实现它。
事务边界相当清楚,一般来说service的每个方法都可以看成一个事务,因为通常Service的每个方法对应着一个用例。(在这个例子中我使用了facade作为事务边界,后面我要讲这个是多余的)
其缺点为也是很明显的:
所有的业务都在service中处理,当业越来越复杂时,service会变得越来越庞大,最终难以理解和维护。
将所有的业务放在无状态的service中实际上是一个过程化的设计,它在组织复杂的业务存在天然的劣势,随着业务的复杂,业务会在service中多个方法间重复。
当添加一个新的UI时,很多业务逻辑得重新写。例如,当要提供Web Service的接口时,原先为Web界面提供的service就很难重用,导致重复的业务逻辑(在贫血模型的分层图中可以看得更清楚),如何保持业务逻辑一致是很大的挑战。
领域模型
接下来看看领域驱动模型,与贫血模型相反,领域模型要承担关键业务逻辑,业务逻辑在多个领域对象之间分配,而Service只是完成一些不适合放在模型中的业务逻辑,它是非常薄的一层,它指挥多个模型对象来完成业务功能。
包结构
领域模型的实现一般包含如下包:
infrastructure: 代表基础设施层,一般负责对象的持久化。
domain:代表领域层。domain包中包括两个子包,分别是model和service。model中包含模型对
象,Repository(DAO)接口。它负责关键业务逻辑。service包为一系列的领域服务,之所以需要service,按照DDD的观点,是因为领域中的某些概念本质是一些行为,并且不便放入某个模型对象中。比如转帐操作,它是一个行为,并且它涉及三个对
象,fromAccount,toAccount和TransferTransaction,将它放入任一个对象中都不好。
application: 代表应用层,它的主要提供对UI层的统一访问接口,并作为事务界限。
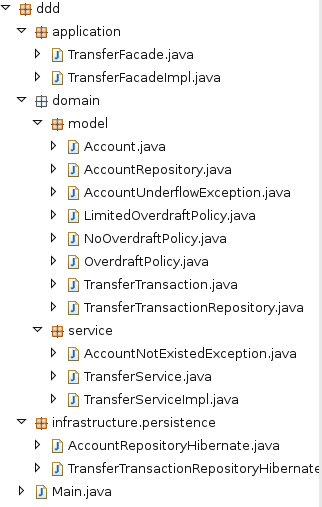
代码实现
现在来看实现,照例先看model中的对象:
public class
Account {
private String accountId;
private BigDecimal balance;
private OverdraftPolicy overdraftPolicy = NoOverdraftPolicy.INSTANCE;
public Account() {}
public Account(String accountId, BigDecimal balance)
{
Validate.notEmpty(accountId);
Validate.isTrue(balance == null || balance.compareTo(BigDecimal.ZERO)
>= 0);
this.accountId = accountId;
this.balance = balance == null ? BigDecimal.ZERO
: balance;
}
public String getAccountId() {
return accountId;
}
public BigDecimal getBalance() {
return balance;
}
public void debit (BigDecimal amount) throws AccountUnderflowException
{
Validate.isTrue (amount.compareTo(BigDecimal.ZERO)
> 0);
if (!overdraftPolicy.isAllowed (this, amount))
{
throw new AccountUnderflowException (this, amount);
}
balance = balance.subtract(amount);
}
public void credit (BigDecimal amount) {
Validate.isTrue (amount.compareTo(BigDecimal.ZERO)
> 0);
balance = balance.add(amount);
}
} |
与贫血模型的区别在于Account类中包含业务方法(credit,debit),注意没有set方法,对Account的更新是通过业务方法来更新
的。由于“不允许从帐户取出大于存款余额的资金”是一条重要规则,将它放在一个单独的接口OverdraftPolicy中,也提供了灵活性,当业务规则
变化时,只需要改变这个实现就可以了。
TransferServiceImpl类:
public class
TransferServiceImpl implements TransferService
{
private AccountRepository accountRepository;
private TransferTransactionRepository transferTransactionRepository;
public TransferServiceImpl (AccountRepository accountRepository,
TransferTransactionRepository transferTransactionRepository)
{
this.accountRepository = accountRepository;
this.transferTransactionRepository = transferTransactionRepository;
}
public TransferTransaction transfer(String fromAccountId,
String toAccountId,
BigDecimal amount) throws AccountNotExistedException,
AccountUnderflowException {
Account fromAccount = accountRepository.findAccount (fromAccountId);
if (fromAccount == null) throw new AccountNotExistedException (fromAccountId);
Account toAccount = accountRepository.findAccount (toAccountId);
if (toAccount == null) throw new AccountNotExistedException(toAccountId);
fromAccount.debit(amount);
toAccount.credit(amount);
accountRepository.updateAccount (fromAccount);
// 对Hibernate来说这不是必须的
accountRepository.updateAccount (toAccount); //
对Hibernate来说这不是必须的
return transferTransactionRepository.create (fromAccountId,
toAccountId, amount);
}
} |
与贫血模型中的TransferServiceImpl相比,最主要的改变在于业务逻辑被移走了,由Account类来实现。对于这样一个简单的例子,领域模型没有太多优势,但是仍然可以看到代码的实现要简单一些。当业务变得复杂之后,领域模型的优势就体现出来了。
优缺点
其优点是:
领域模型采用OO设计,通过将职责分配到相应的模型对象或Service,可以很好的组织业务逻辑,当业务变得复杂时,领域模型显出巨大的优势。
当需要多个UI接口时,领域模型可以重用,并且业务逻辑只在领域层中出现,这使得很容易对多个UI接口保持业务逻辑的一致(从领域模型的分层图可以看得更清楚)。
其缺点是:
对程序员的要求较高,初学者对这种将职责分配到多个协作对象中的方式感到极不适应。
领域驱动建模要求对领域模型完整而透彻的了解,只给出一个用例的实现步骤是无法得到领域模型的,这需要和领域专家的充分讨论。错误的领域模型对项目的危害非常之大,而实现一个好的领域模型非常困难。
对于简单的软件,使用领域模型,显得有些杀鸡用牛刀了。
我的看法
这部分我将提出一些可能存在争议的问题并提出自己的看法。
软件分层
理解软件分层、明晰每层的职责对于理解领域模型以及代码实现是有好处的。软件一般分为四层,分别为表示层,应用层,领域层和基础设施层。软件领域中另外一个著名的分层是TCP/IP分层,分为应用层,运输层,网际层和网络接口层。我发现它们之间存在对应关系,见下表:
| TCP/IP分层
|
软件分层
|
|
| |
|
表示层
|
负责向用户显示信息。
|
| 应用层 |
负责处理特定的应用程序细节。如FTP,SMTP等协议。 |
应用层 |
定义软件可以完成的工作,指挥领域层的对象来解决问题。它不负责业务逻辑,是很薄的一层。 |
| 运输层 |
两台主机上的应用程序提供端到端的通信。主要包括TCP,UDP协议。 |
领域层 |
负责业务逻辑,是业务软件的核心。 |
| 网际层 |
处理分组在网络中的活动,例如分组的选路。主要包括IP协议。 |
|
| 网络接口层 |
操作系统中的设备驱动程序和计算机中对应的网络接口卡。它们一起处理与电缆(或其他任何传输媒介)的物理接口细节。 |
基础设施层 |
为上层提供通用技术能力,如消息发送,数据持久化等。 |
对于TCP/IP来说,运输层和网际层是最核心的,这也是TCP/IP名字的由来,就像领域层也是软件最核心的一层。可以看出领域模型的包结构与软
件分层是一致的。在软件分层中,表示层、领域层和基础设施层都容易理解,难理解的是应用层,很容易和领域层中Service混淆。领域Service属于
领域层,它需要承担部分业务概念,并且这个业务概念不易放入模型对象中。应用层服务不承担任何业务逻辑和业务概念,它只是调用领域层中的对象(服务和模
型)来完成自己的功能。应用层为表示层提供接口,当UI接口改变一般也会导致应用层接口改变,也可能当UI接口很相似时应用层接口不用改变,但是领域层
(包括领域服务)不能变动。例如一个应用同时提供Web接口和Web Service接口时,两者的应用层接口一般不同,这是因为Web
Service的接口一般要粗一些。可以和TCP/IP的层模型进行类比,开发一个FTP程序和MSN聊天程序,它们的应用层不同,但是可以同样利用
TCP/IP协议,TCP/IP协议不用变。与软件分层不同的是,当同样开发一个FTP程序时,如果只是UI接口不同,一个是命令行程序,一个是图形界
面,应用层不用变(利用的都是FTP服务)。下图给出领域模型中的分层:
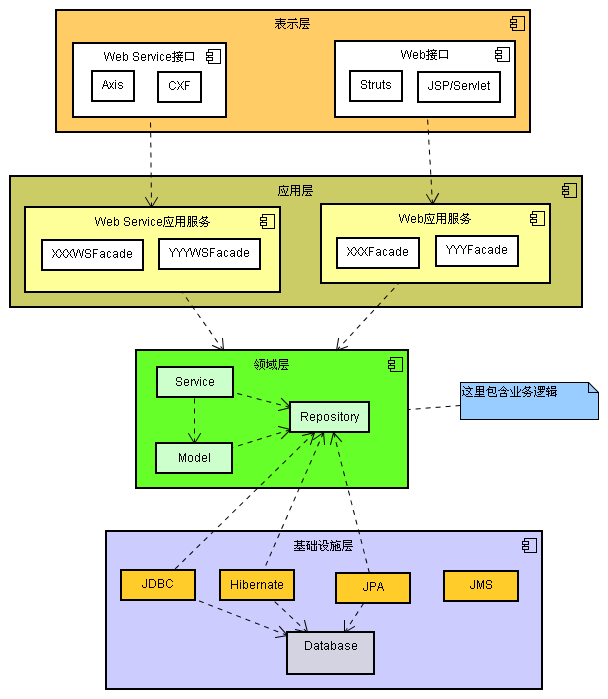
Repository接口属于领域层
可能有人会将Repository接口,相当于贫血模型中的DAO接口,归于基础设施层,毕竟在贫血模型中DAO是和它的实现放在一起。这就涉及
Repository 接口到底和谁比较密切?应该和domain层比较密切,因为Repository接口是由domain层来定义的。用TCP/IP来类比,网际层支持标准
以太网、令牌环等网络接口,支持接口是在网际层中定义的,没有在网际层定义的网络接口是不能被网际层访问的。那么为什么在贫血模型中DAO的接口没有放在
model包中,这是因为贫血模型中DAO的接口是由service来定义的,但是为什么DAO接口也没有放在service包中,我无法解释,按照我的
观点DAO接口放在service包中要更好一些,将DAO接口放在dao包或许有名称上对应的考虑。对于领域模型,将Repository接口放入
infrastructure包中会引入包的循环依赖,Repository依赖Domain,Domain依赖Repository。然而对于贫血模
型,将DAO接口放入dao包中则不会引入包循环依赖,只有service对DAO和model的依赖,而没有反方向的依赖,这也导致service包很
不稳定,service又正是放置业务逻辑的地方。JDepend这个工具可以检测包的依赖关系。
贫血模型中Facade有何用?
我以前的做一个项目使用的就是贫血模型,使用了service和facade,当我们讨论service和facade有什么区别时,很少有人清
楚,最终结果facade就是一个空壳,它除了将方法实现委托给相应的service方法,不做任何事,它们的接口中的方法都一样。Facade应该是主
要充当远程访问的门面,这在EJB时代相当普遍,自从Rod Johson叫嚷without EJB之后,大家对EJB的热情降了很多,对许多使用贫血模型的应用程序来说,facade是没有必要的。贫血模型中的service在本质上属于应用层
的东西。当然如果确实需要提供远程访问,那么远程Facade(或许叫做Remote Service更好)也是很有用的,但是它仍然属于应用层,只不过在技术层面上将它的实现委托给对应的Service。下图是贫血模型的分层:
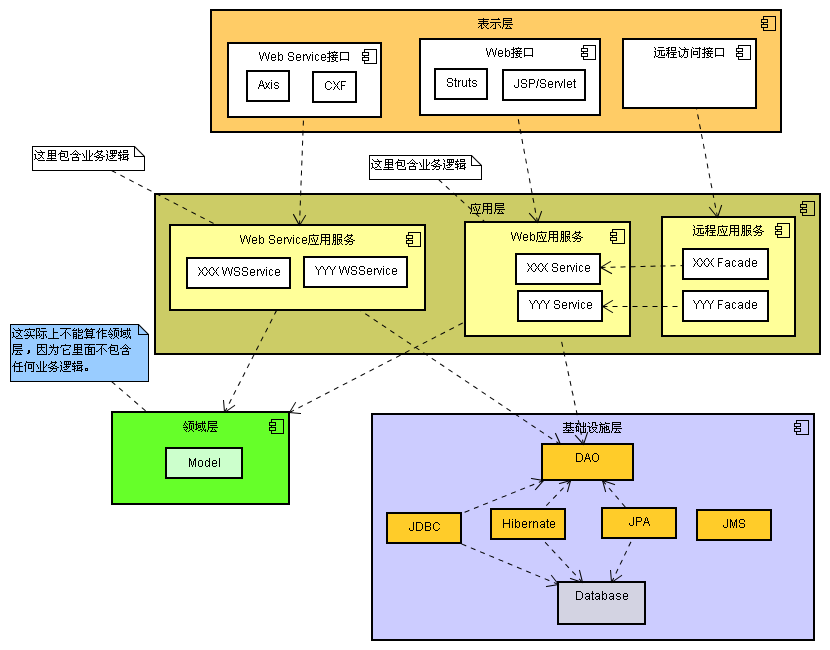
贫血模型分层
从上面的分层可以看出贫血模型实际上相当于取消掉了领域层,因为领域层并没有包含业务逻辑。
DAO到底有没有必要?
贫血模型中的DAO或领域模型中的Repository到底有没有必要?有人认为DAO或者说Repository是充血模型的大敌,对此我无论如
何也不赞同。DAO或Repository是负责持久化逻辑的,如果取消掉DAO或Repository,将持久化逻辑直接写入到model对象中,势必
造成model对象承担不必要的职责。虽然现在的ORM框架已经做得很好了,持久化逻辑还是需要大量的代码,持久化逻辑的掺入会使model中的业务逻辑
变得模糊。允许去掉DAO的一个必要条件就是Java的的持久化框架必须足够先进,持久化逻辑的引入不会干扰业务逻辑,我认为这在很长一段时间内将无法做
到。在rails中能够将DAO去掉的原因就是rail中实现持久化逻辑的代码很简洁直观,这也与ruby的表达能力强有关系。DAO的另外一个好处隔离
数据库,这可以支持多个数据库,甚至可以支持文件存储。基于DAO的这些优点,我认为,即使将来Java的持久化框架做得足够优秀,使用DAO将持久化逻
辑从业务逻辑中分离开来还是十分必要的,况且它们本身就应该分离。
结束语
在这篇文章里,我使用了一个转帐例子来描述领域模型和贫血模型的不同,实现代码可以从附件中下载,我推荐你看下附件代码,这会对领域模型和贫血模型
有个更清楚的认识。我谈到了软件的分层,以及贫血模型和领域模型的实现又是怎样对应到这些层上去的,最后是对DAO(或Repository)的讨论。以
上只是我个人观点,如有不同意见欢迎指出。 |









