| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌЮФзЏжївЊНВНтСЫRattleЪЕЯжAdaBoostЫуЗЈЃЌboostingЪЧЪВУДЃЌЯрЙиЫуЗЈФкШнЃЌНсКЯЪЕР§ИјДѓМвНВНтЁЃ |
|
RattleЪЕЯжAdaBoostЫуЗЈ
BoostingЫуЗЈЪЧМђЕЅгааЇЁЂвзЪЙгУЕФНЈФЃЗНЗЈЁЃAdaBoostЃЈздЪЪгІЬсЩ§ЫуЗЈЃЉЭЈГЃБЛГЦзїЪРНчЩЯЯжГЩЕФзюКУЗжРрЦїЁЃ
BoostingЫуЗЈЪЙгУЦфЫћЕФШѕбЇЯАЫуЗЈНЈСЂЖрИіФЃаЭЃЌЖдЪ§ОнМЏжаЖдНсЙћгАЯьНЯДѓЕФЖдЯѓдіМгШЈжиЃЌвЛЯЕСаЕФФЃаЭБЛДДНЈЃЌШЛКѓЕїећФЧаЉгАЯьЗжРрЕФФЃаЭЕФЖдЯѓШЈжижЕЃЌЪЕМЪЩЯЃЌФЃаЭЕФШЈжижЕДгвЛИіФЃаЭЕНСэвЛИіФЃаЭе№ЕДЁЃзюКѓЕФФЃаЭгЩвЛЯЕСаЕФФЃаЭзщКЯЖјГЩЃЌУПИіФЃаЭЕФЪфГіЖМИљОнЯргІЕФГЩМЈБЛИГгшШЈжижЕЁЃЮвУЧзЂвтЕНЃЌШчЙћЪ§ОнЪЇаЇЛђепШѕЗжРрЦїЙ§гкИДдгЖМЛсЕМжТboostingЪЇАмЁЃ
BoostingгааЉРрЫЦгкЫцЛњЩСжЃЌНЈСЂвЛИіећЬхЕФФЃаЭЃЌзюКѓЕФФЃаЭБШШѕЗжРрЦїШЮКЮЕФзщКЯвЊКУЁЃЧјБ№гкЫцЛњЩСжЕФЃЌвЊНЈЭъвЛПУдйНЈСэвЛПУЃЌШЛКѓЛљгкжЎЧАЕФФЃаЭдйЯИЛЏЁЃФкШнЪЧНЈСЂЭъвЛИіФЃаЭжЎКѓЃЌШЮКЮДэЗжРрЕФбљБОЖМБЛЩ§ИпШЈжиЃЈboostedЃЉСЫЁЃвЛИіЬсЩ§ЕФбљБОБОжЪЩЯдкЪ§ОнМЏжаЛсИјгшЭЛГіЃЌЪЙЕУЕЅбљБОЙлВтЙ§ЖрЁЃФПЕФЪЧЪЙЯТвЛИіФЃаЭФмИќгааЇЕФеыЖдДЫбљБОе§ШЗЗжРрЃЌШчЙћЛЙУЛгае§ШЗЗжЃЌбљБОЛсдйДЮБЛЩ§ИпЁЃ
ЯрБШгкЫцЛњЩСжЃЌboostingЫуЗЈИќЧїгкЖрдЊЛЏЃЌШЮКЮФЃаЭЕФЗНЗЈЖМПЩвдБЛЕБзїбЇЯАЫуЗЈЃЌОіВпЪїЪЧОГЃЪЙгУЕФЫуЗЈЁЃ
1.boostingИХЪі
BoostingЫуЗЈЭЈГЃгЩвЛзщОіВпЪїзїЮЊжЊЪЖБэДяЕФЛљДЁаЮЪНЃЌжЊЪЖБэДяЙиМќЕФЕиЗНЪЧЮвУЧКЯВЂОіВпЕФЗНЗЈЁЃЖдгкboostingЃЌЪЙгУШЈжиГЩМЈЃЈscoreЃЉЃЌУПвЛИіФЃаЭЖМЖдгІвЛИіШЈжиЁЃ
2.ЫуЗЈ
зїЮЊдЊбЇЯАЃЌboostingЪЙгУвЛаЉМђЕЅЕФбЇЯАЫуЗЈзщГЩЖржиФЃаЭЃЌboostingОГЃвРРЕШѕбЇЯАЫуЗЈ--ЭЈГЃШЮКЮШѕЗжРрЦїЖМПЩвдБЛЪЙгУЁЃвЛЯЕСаЕФШѕЗжРрФЃаЭПЩвдзщГЩвЛИіЧПЗжРрЦїЁЃ
вЛИіШѕЗжРрЪЕМЪЩЯОЭБШЫцЛњВТВтЕФДэЮѓТЪЩдКУвЛЕуЁЃЕЋЪЧзщКЯЦ№РДНЋЛсгаПЩЙлЕФЗжРраЇЙћЁЃ
ЫуЗЈПЊЪМЛљгкбЕСЗЪ§ОнНЈСЂвЛИіШѕЕФГѕЪМЛЏФЃаЭЃЌШЛКѓбЕСЗЪ§ОнжаЕФДэЗжбљБОНЋЛсБЛЬсЩ§ЃЈШЈжидіМгЃЉЃЌПЊЪМЪБЫљгаЕФбљБОЖМЛсБЛИГгшвЛИіШЈжижЕЃЌБШШчШЈжЕ1ЁЃШЈжиЭЈЙ§вЛИіЙЋЪНБЛЬсЩ§ЃЌЫљвдБЛДэЗжЕФбљБОЕФШЈжЕНЋЛсБЛЬсЩ§ЃЈДѓгк1ЃЉЁЃ
ЪЙгУетаЉБЛЬсЩ§ЕФбљБОдйШЅНЈСЂаТЕФФЃаЭЃЌЮвУЧПЩвдНЋЦфзїЮЊЮЪЬтбљБОЃЌжЎКѓЕФФЃаЭНЋЛсжиЪгетаЉДэЗжбљБОЃЈШЈжЕДѓЕФбљБОЃЉЁЃ
ЮвУЧПЩвдЭЈЙ§вЛИіМђЕЅЕФР§згеЙЪОвЛЯТЙ§ГЬЁЃМйЩшга10ИібљБОЃЌУПИібљБОгаГѕЪМШЈжиЃЌ0.1ЃЌЮвУЧНЈСЂвЛИіОіВпЪїЃЌгаЫФИіДэЗжЕФбљБОЃЈбљБО7ЃЌ8ЃЌ9ЃЌ10ЃЉЃЌЮвУЧПЩвдМЦЫуДэЗжбљБОЕФШЈжижЎКЭ0.4ЃЈЭЈГЃЮвУЧгУeБэЪОЃЉЁЃетЪЧФЃаЭзМШЗТЪЕФВтСПЁЃeБЛгУзїИќаТШЈжиЕФВтСПжЕЃЌБфЛЛКѓЕФжЕa=0.5*log((1-e)/e),ДэЗжбљБОаТЕФШЈжижЕНЋЛсЪЧeaЃЌЮвУЧЕФР§згЕБжаЃЌa=0.2027ЃЌбљБО7ЃЌ8ЃЌ9ЃЌ10аТЕФШЈжижЕНЋЛсЪЧ0.1*eaЃЌЃЈ0.1225ЃЉ
аТЕФФЃаЭБШШчЛЙгаДэЗжбљБОЃЌ1КЭ8ЃЌЫќУЧЯждкЕФШЈжиЪЧ0.1КЭ0.1225ЃЌаТЕФeЪЧ0.2225ЃЌаТЕФaжЕЮЊ0.6275ЃЌЫљвдбљБО1ЕФШЈжиБфЮЊ0.1*eaЃЌЃЈ0.1869ЃЉЁЃбљБО8ЕФШЈжиЮЊ0.1225*eaЃЈ0.229ЃЉ.ЮвУЧПЩвдПДЕНЯждкбљБО8ЕФШЈжиНјвЛВНдіМгСЫЃЌГЬађМЬајжДаажБЕНЕЅвЛЪїЕФДэЮѓТЪДѓгк50%ЁЃ
3.ЪЕбщЪЕР§
ЪЙгУrattleНЈСЂФЃаЭ
дкmodelЙЄОпРИжагаBoostбЁЯюЃЌЕЅЖРЕФОіВпЪїНЈСЂЪЙгУrpart.НЈСЂвЛИіФЃаЭЕФНсЙћаХЯЂДђгЁЕНЮФБОЪгЧјЁЃЪЙгУweatherЪ§ОнМЏЃЈдкЪ§ОнРИdataЕуЛїжДааАДХЅПЩвдздЖЏМгдиЃЉЁЃ
ЮФБОЪгЧјПЊЪМЪфГіЕФЪЧНЈСЂФЃаЭЕФвЛаЉКЏЪ§ЃК
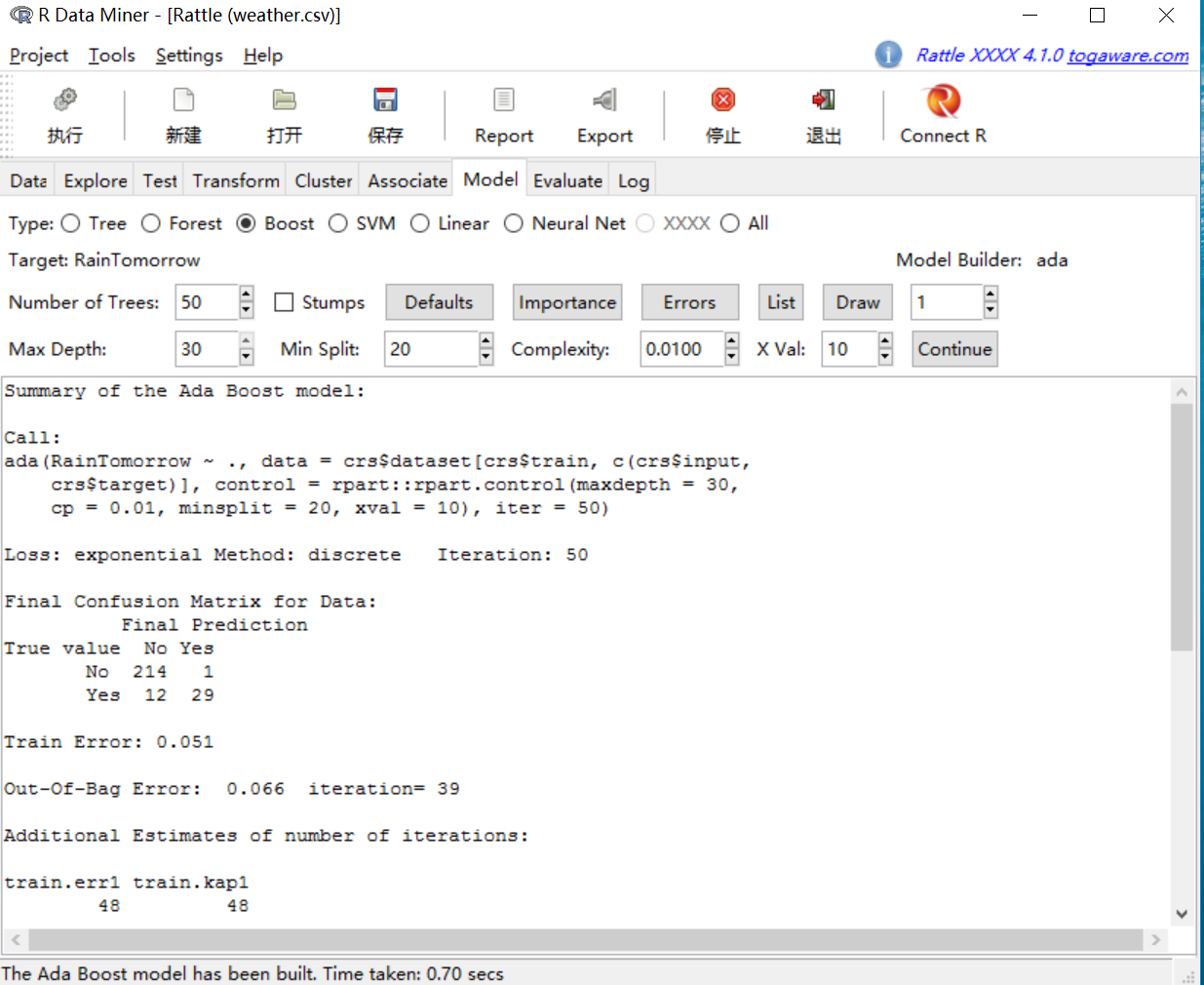
ЮФБОЪгЧјЕФCallЛљБОаХЯЂжаЃК
ФЃаЭдЄВтБфСПЪЧRainTomorrowЃЌdataБэЪОЪЧЛљБОЪ§ОнаХЯЂЃЌcontol=ВЮЪ§жБНгДЋВЮИјrpart(),iter=ЪЧНЈСЂЪїЕФЪ§СПЁЃlossЪЧжИЪ§Ы№ЪЇКЏЪ§ЃЌIterationЪЧвЊЧѓНЈСЂЕФЪїЕФЪ§ФПЁЃ
адФмЦРЙРЃК
ЛьЯ§ОиеѓЯдЪОСЫФЃаЭЕФадФмЃЌСаГіСЫбЕСЗЪ§ОнЕФдЄВте§ШЗЧщПіЁЃ
train error ЪЧФЃаЭбЕСЗЕФДэЮѓТЪ=1-ЃЈ214+29ЃЉ/ЃЈ214+1+12+29ЃЉ дЄВте§ШЗЕФбљБО/змбљБО
out-of-bag ЗНЗЈЕФДэЮѓТЪКЭЯргІЕФЕќДњДЮЪ§ЁЃ
train.err1 train.kap1
48 48
Variables actually used in tree construction:
[1] "Cloud3pm" "Cloud9am"
"Evaporation" "Humidity3pm"
[5] "Humidity9am" "MaxTemp"
"MinTemp" "Pressure3pm"
[9] "Pressure9am" "Rainfall"
"Sunshine" "Temp3pm"
[13] "Temp9am" "WindDir3pm"
"WindDir9am" "WindGustDir"
[17] "WindGustSpeed" "WindSpeed3pm"
"WindSpeed9am"
Frequency of variables actually used:
WindDir9am WindGustDir Sunshine WindDir3pm Pressure3pm
36 26 25 25 23
Cloud3pm MaxTemp MinTemp Temp9am WindSpeed3pm
12 8 6 6 6
Evaporation WindGustSpeed Cloud9am Humidity3pm
Humidity9am
5 5 3 3 2
Pressure9am Rainfall Temp3pm WindSpeed9am
2 2 2 1
Time taken: 0.70 secs |
Variables actually used in tree construction ЪЧФЃаЭЕФОіВпЪїЙЙдьЪЕМЪЪЙгУЕФЪєадЁЃ
Frequency of variables actually usedЪЧФЃаЭЪєадЪЙгУЕНЕФЦЕДЮЃЌДгДѓЕНаЁСаГіЁЃ
зюКѓЪЧЛЈЗбЕФЪБМф0.7УыЃЌвђЮЊЪ§ОнСПНЯаЁЃЌЫљвдЛЈЗбЕФЪБМфЪЧКмЩйЕФЁЃ
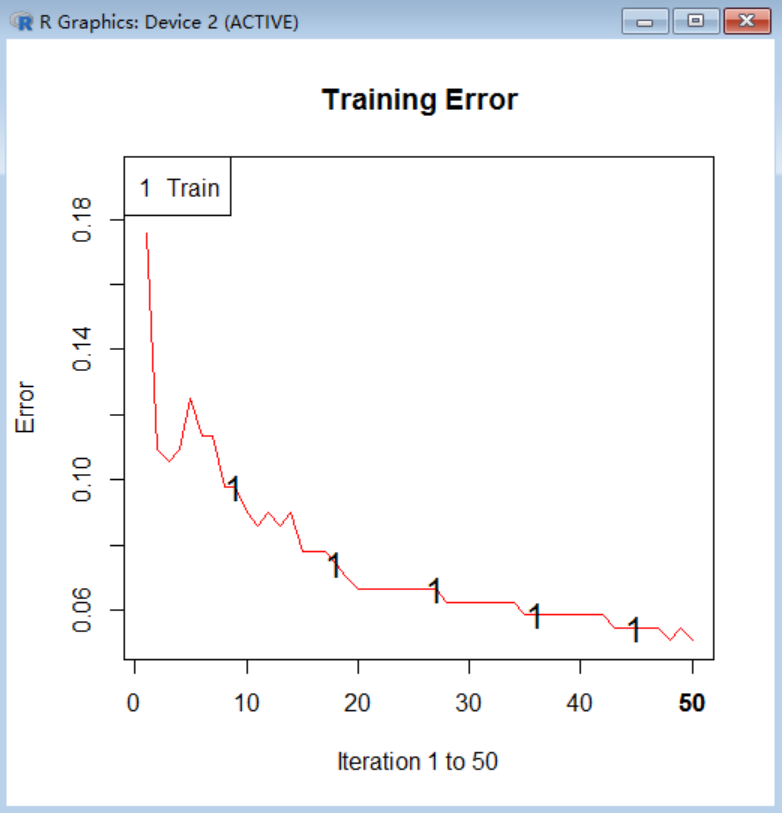
вЛЕЉФЃаЭНЈСЂЭъГЩЃЌЙЄОпРИЕФerrorАДХЅНЋЛсЛцжЦШчЯТЭМЫљЪОЕФДэЮѓТЪЭМЃЌЫцзХИќЖрЕФЪїМгШыФЃаЭЃЌДэЮѓТЪВЛЖЯНЕЕЭЃЌПЊЪМЯТНЕБШНЯбИЫйЃЌКѓРДТ§Т§ЧїгкЦНЬЙЁЃ
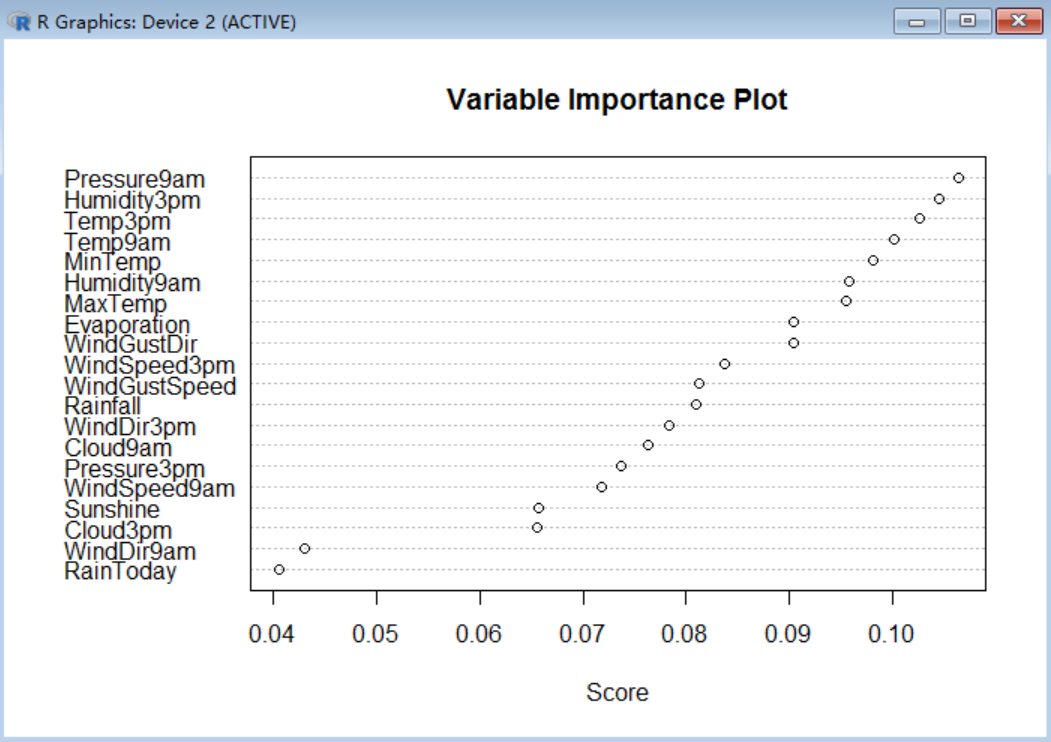
importanceАДХЅЛцжЦСЫФЃаЭживЊЕФЪєадЃК
гвЯТНЧЕФcontinueАДХЅПЩвдМЬајдіМгЪїЕФЪ§ФПНјаабЕСЗФЃаЭЁЃ
|









