| 编辑推荐: |
| 本文来自于简书,文中主要介绍了为什么要用AdaBoost(为什么要用弱分类器和多个实例来构建一个强分类器)。 |
|
这一生活问题映射到计算机世界就变成了元算法(meta-algorithm)或者集成方法(ensemble
method)。这种集成可以是不同算法的集成,也可以是同一算法在不同设置下的集成,还可以是数据集不同部分分配给不同分类器之后的集成。AdaBoost就是一种最流行的元算法。
什么是AdaBoost
AdaBoost是adaptive boosting的缩写,boosting是一种与bagging很类似的技术,将原始数据集选择S次后得到S个新数据集,新数据集与原始数据集大小相等,每个数据集都是通过在原始数据集中随机选择一个样本来替换得到的,这就意味着可以多次选择同一个样本。在S个数据集建好之后,将某个学习算法分别作用于每个数据集就得到了S个分类器,当我们要对新数据分类时,就可以用这S个分类器进行分类,选择分类器投票结果最多的类别作为最后分类结果。boosting通过集中关注被已有分类器错分的数据来获得新的分类器,boosting给每个分类器的权重不相等,每个权重代表的是对应的分类器在上一轮迭代中的成功度,分类结果是基于所有分类器的加权求和得到的。
为什么要用AdaBoost(为什么要用弱分类器和多个实例来构建一个强分类器)
等待答案中。。。
Adaboost算法流程是什么
1)给数据中的每一个样本一个权重
2)训练数据中的每一个样本,得到第一个分类器
3)计算该分类器的错误率,根据错误率计算要给分类器分配的权重(注意这里是分类器的权重)
4)将第一个分类器分错误的样本权重增加,分对的样本权重减小(注意这里是样本的权重)
5)然后再用新的样本权重训练数据,得到新的分类器,到步骤3
6)直到步骤3中分类器错误率为0,或者到达迭代次数
7)将所有弱分类器加权求和,得到分类结果(注意是分类器权重)
解释:步骤3中,错误率的定义是:

错误率.png分类器的权重计算公式是:

步骤4中,错误样本权重更改公式为:

正确样本权重更改公式为:

其中t指当前分类器,i指第i个样本。
构建基于单层决策树的AdaBoost分类器
用一个很简单的散点分类问题来实现AdaBoost分类器。
准备数据集
import numpy
as np
def loadSimpData():
datMat = np.matrix([[1. , 2.1],
[1.5 , 1.6],
[1.3, 1. ],
[1. , 1. ],
[2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat, classLabels
datMat, classLabels = loadSimpData()
showScatter(datMat, classLabels) |
showScatter方法用来绘制散点图,代码如下:
import matplotlib.pyplot
as plt
def showScatter(matrix, labels):
plt.figure(figsize=(8,6))
x1 = []; y1 = []; x2 = []; y2 = []
for i in range(len(labels)):
if labels[i] == 1.0:
x1.append(matrix[i, 0])
y1.append(matrix[i, 1])
else:
x2.append(matrix[i, 0])
y2.append(matrix[i, 1])
plt.scatter(x1, y1, marker='o',
color='green', alpha=0.7, label='1.0')
plt.scatter(x2, y2, marker='^',
color='red', alpha=0.7, label='-1.0')
plt.title('dataset')
plt.ylabel('variable Y')
plt.xlabel('Variable X')
plt.legend(loc='upper right')
plt.show() |
所以要进行的分类如下图所示:
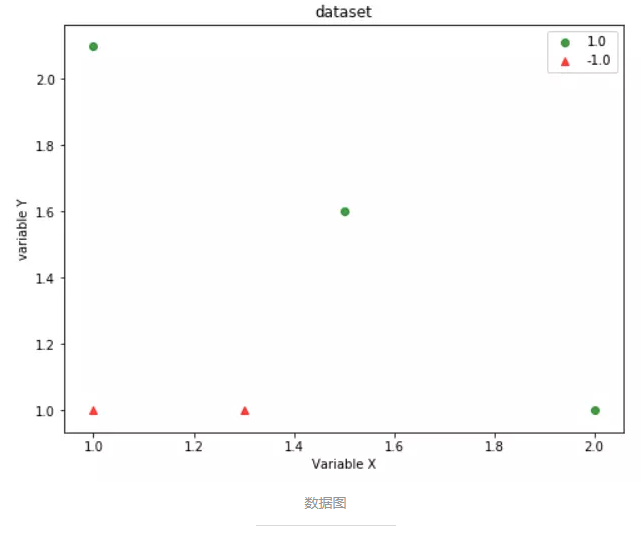
结果调用方法(期望实现效果)
把它放在第二步,倒着写程序,是借用了TDD的思路,这样会更好理解,测试就不粘出来了,从结果出发,一步一步驱动出算法代码。
对于这个demo,我们希望输入一个或多个点,告诉我们是1.0类(绿色原点)还是-1.0类(红色三角)。
为了让代码更灵活,我们把弱分类器也作为参数传入,则最后的调用为:
# [[5, 5], [0,
0]]是要分类的点
# classifierArr是弱分器数组
adaClassify ([[5, 5], [0, 0]], classifierArr)
|
期望的输出是:
[[1.], [-1.]]
写AdaBoost分类函数
从上一步让我们驱动出adaClassify函数,我们希望每一个弱分类器是一个字典,有最好的维度、所用的阈值、是大于阈值还是小于阈值为1类这些属性,通过这些属性能得到一个分类结果,再用分类结果乘以分类器的权重,进行累加,返回分类结果,下面写它的实现
# datToClass:要分类的数据
# classifierArr:弱分类器数组
def adaClassify(datToClass, classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m, 1))) # 为了满足输出期望,先用0列向量初始化输出结果
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'],
classifierArr[i]['thresh'], classifierArr[i]['ineq'])
# 得到一个弱分类器分类结果
aggClassEst += classifierArr[i]['alpha'] * classEst
# 对应算法流程的步骤7,将弱分类器结果加权求和
# print(aggClassEst)
return np.sign(aggClassEst) #由于是二类问题,所以可以根据加权求和结果的正负情况得到期望的分类输出
|
写基于单层决策树的AdaBoost函数
上一步可以驱动出stumpClassify函数,需要传入的参数为要分类的数据、维度、阈值、大于阈值是1类还是小于阈值是1类,希望它能给出一个分类结果,结果长这样:[[1.],[1.],[-1.],...]。实现如下:
# dataMatirx:要分类的数据
# dimen:维度
# threshVal:阈值
# threshIneq:有两种,‘lt’=lower than,‘gt’=greater
than
def stumpClassify(dataMatrix, dimen, threshVal,
threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0], 1))
if threshIneq == 'gt':
retArray[dataMatrix[:, dimen] <= threshVal]
= -1.0 # 如果希望大于阈值的是1,则小于阈值的部分置为-1
else:
retArray[dataMatrix[:, dimen] > threshVal]
= -1.0
return retArray |
训练分类器
接下来的工作就是训练分类器,得到classifierArr弱分类器数组,作为参数,穿给我们的最中调用函数。
回想AdaBoost分类器的步骤2-6,即每个分类器都是在上一次的基础上更新权重,训练数据,权重更新方法是增加分类错误的样本权重,减小分类正确的样本权重。
我们希望告诉这个函数数据集,还有对应的标签,我们设置的最多迭代次数后,能返回一个弱分类器数组。所以函数长下面这样:
def adaBoostTrainDS(dataArr,
classLabels, numIt=40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m,1)) / m) # 初始化权重向量,给每个样本相同的权重,[[1/m],[1/m],[1/m],...]
aggClassEst = np.mat(np.zeros((m,1))) # 初始化每个样本的预估值为0
for i in range(numIt): # 遍历迭代次数
bestStump, error, classEst = buildStump(dataArr,
classLabels, D) # 构建一棵单层决策树,返回最好的树,错误率和分类结果
alpha = float(0.5 * np.log((1.0 - error)/error))
#计算分类器权重
bestStump['alpha'] = alpha #将alpha值也加入最佳树字典
weakClassArr.append(bestStump) # 将弱分类器加入数组
# print("classEst:", classEst.T)
# 更新权重向量D
expon = np.multiply(-1*alpha*np.mat(classLabels).T,
classEst)
D = np.multiply(D, np.exp(expon))
D = D / D.sum()
# 累加错误率,直到错误率为0或者到达迭代次数
aggClassEst += alpha * classEst
print("aggClassEst:", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) !=
np.mat(classLabels).T, np.ones((m, 1)))
errorRate = aggErrors.sum() / m
print("total error:", errorRate, "\n")
if errorRate == 0.0:
break;
return weakClassArr |
构建单层决策树分类器
通过上一步可以驱动出buildStump函数。我们希望输入数据集和标签以及由每个样本的权重构成的权重矩阵D,能得到最好的分类器的属性,包含维度、阈值、大于阈值还是小于阈值是1.0类,还有分类器错误率,最好的分类器的长相。
# dataArr: 数据集
# classLabels:标签
# D:由每个样本的权重构成的矩阵
def buildStump(dataArr, classLabels, D):
dataMatrix = np.mat(dataArr)
labelMat = np.mat(classLabels).T # 标签转成列向量
m, n = np.shape(dataMatrix) #m为数据个数,n为每条数据含有的样本数(也就是特征)
numSteps = 10.0
bestStump = {}
bestClasEst = np.mat(np.zeros((m, 1))) # 初始化最好的分类器为[[0],[0],[0],...]
minError = np.inf #最小错误率,不停更新最小错误率
for i in range(n): #遍历特征
rangeMin = dataMatrix[:, i].min(); # 找这一列特征的最小值
rangeMax = dataMatrix[:, i].max(); # 找这一列特征的最大值
stepSize = (rangeMax - rangeMin) / numSteps #每次移动的步长
for j in range(-1, int(numSteps) + 1): #对每个步长
for inequal in ['lt', 'gt']: # 每个条件,大于阈值是1还是小于阈值是1
threshVal = (rangeMin + float(j) * stepSize) #
阈值设为最小值+第j个步长
print('i=%d, threshVal=%f, inequal=%s'%(i,threshVal,inequal))
predictedVals = stumpClassify(dataMatrix, i ,
threshVal, inequal) # 将dataMatrix的第i个特征inequal阈值的置为1,否则为-1
print(predictedVals)
errArr = np.mat(np.ones((m, 1)))
errArr[predictedVals == labelMat] = 0 # 预测对的置0
print(errArr)
weightedError = D.T * errArr
print("split: dim %d, threshold %.2f, threshold
inequal: %s, the weighted error is %.3f"
% (i, threshVal, inequal, weightedError))
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst |
上述过程就是,遍历每个特征,在每个特征上找合理的分界点,每次移动一个步长,对每个步长,根据它的大于阈值是1.0还是小于阈值是1.0类得到分类情况,计算错误率,找错误率最小的一种情况返回。bestStump是一个字典,找到一个好的分类器,当然要包含所选择的维度(映射到这个题目就是x轴还是y轴),分类的阈值是多少,大于还是小于阈值的是1.0类,所以把这些属性放入了bestStump字典。
进行测试
到这里,就实现了,可以用一个或一组点进行测试,用第一步设想的调用方法:
# 分类(0,0)点
adaClassify([0,0], classifierArray) |
输出结果为:

可见,(0,0)点分类为-1类。
总结
AdaBoost简单来讲,就是多个弱分类器,可能基于单层决策树,也可能基于其他算法,每一个弱分类器得到一个分类结果,根据它的错误率给这个分类器一个权重,还要更新样本的权重,基于这个权重矩阵,再去训练出一个弱分类器,依次循环,直到错误率为0,就得到了一系列弱分类器,组成一个抢分类器,将这些弱分类器的结果加权求和,能得到一个较为准确的分类。
|









