| БрМЭЦМі: |
| БОЮФРДздгкЭјТчЃЌЮФжажївЊНщЩмСЫСуЪлвЕжаЕФЪ§ОнЭкОђЮЪЬтЁЃЦфжаАќРЈСуЪлвЕжаЕФЖрИіГЃМћЮЪЬтЃЌШчЯьгІНЈФЃЁЂЭЦМіЯЕЭГЁЂашЧѓдЄВтЁЂВЦЮёгАЯьЕШЁЃ |
|
СуЪлЪЧЪ§ОнПЦбЇКЭЪ§ОнЭкОђживЊЕФЩЬвЕгІгУСьгђжЎвЛЁЃСуЪлСьгђгазХЗсИЛЕФЪ§ОнКЭДѓСПЕФгХЛЏЮЪЬтЃЌШчгХЛЏМлИёЁЂелПлЁЂЭЦМіЁЂвдМАПтДцЫЎЦНЕШПЩвдгУЪ§ОнЗжЮігХЛЏЕФЮЪЬтЁЃ
ШЋЧўЕРСуЪлЃЌМДдкЫљгаЯпЩЯКЭЯпЯТЧўЕРећКЯгЊЯњЁЂПЭЛЇЙиЯЕЙмРэЃЌвдМАПтДцЙмРэЕФсШЦ№ВњЩњСЫДѓСПЕФЙиСЊЪ§ОнЃЌДѓДѓдіЧПСЫЪ§ОнЧ§ЖЏаЭОіВпЕФживЊадКЭФмСІЁЃ
ОЁЙмвбОгааэЖрЙигкЪ§ОнЭкОђдкгЊЯњКЭПЭЛЇЙиЯЕЙмРэЗНУцЕФЪщЃЌШч [BE11, AS14, PR13 etc.]ЃЌЕЋОјДѓЖрЪ§ЪщЕФНсЙЙИќЯёЪЧЪ§ОнПЦбЇМвЪжВсЃЌзЈзЂдкЫуЗЈКЭЗНЗЈТлЃЌВЂЧвМйЩшШЫЕФОіВпЪЧДІгкНЋЗжЮіНсЙћЕНвЕЮёжДааЩЯЕФжааФЮЛжУЁЃ
дкетЦЊЮФеТжаЮвУЧЪдЭМВЩгУИќМгбЯНїЕФЗНЗЈКЭЯЕЭГЛЏЕФЪгНЧРДЬНЬжЛљгкЪ§ОнЗжЮіЕФОМУбЇФЃаЭКЭФПБъКЏЪ§ШчКЮЪЙЕУОіВпИќМгздЖЏЛЏЁЃдкетЦЊЮФеТРяЃЌ
ЮвУЧНЋУшЪівЛИіМйЯыЕФЪеШыЙмРэЦНЬЈЃЌетвЛЦНЬЈЛљгкСуЪлЩЬЕФЪ§ОнВЂПижЦСуЪлВпТдЕФКмЖрЗНУцЃЌШчМлИёЁЂгЊЯњКЭВжДЂЁЃ
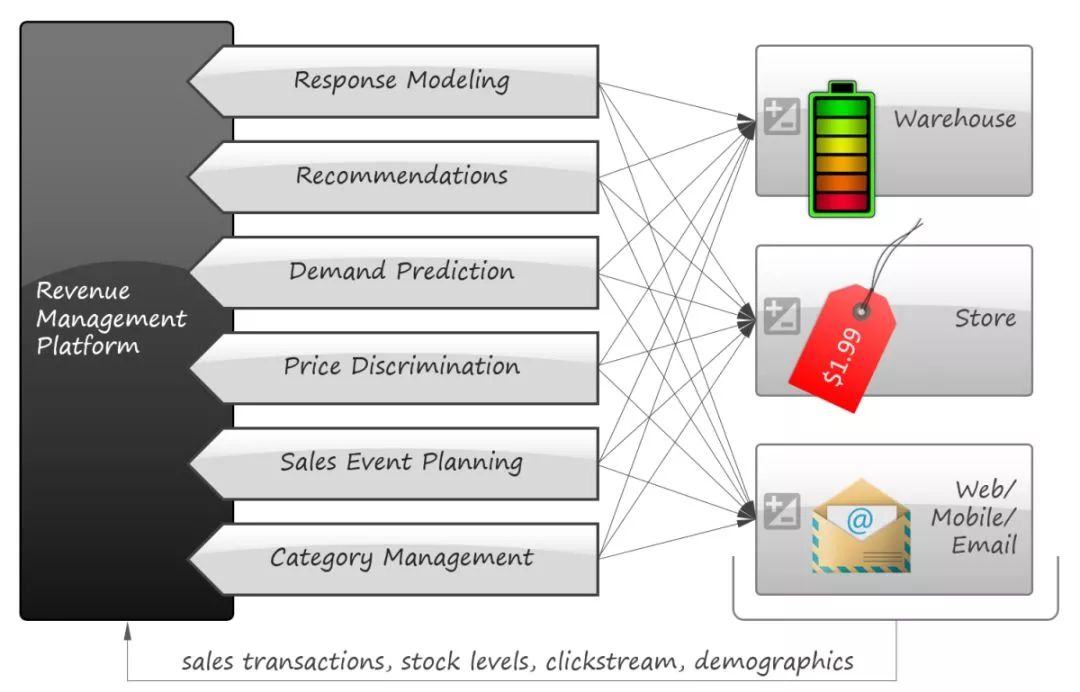
ЮвУЧзЈзЂдкНЋОМУбЇПђМмКЭЪ§ОнЭкОђЗНЗЈЕФзщКЯгавдЯТСНИіжївЊЕФдвђЃК
1.ЮвУЧПЩвдДгОМУбЇНЬПЦЪщЩЯевЕНЩЯАйИігыСуЪлгаЙиЕФОМУбЇФЃаЭЃЌвђЮЊЙигкЪаГЁЁЂелПлЁЂОКељЕШЮЪЬтдкЩЯИіЪРМЭЕУЕНСЫЩюШыЕФбаОПЁЃШЛЖјЃЌаэЖрФЃаЭЖМЪЧИпЖШВЮЪ§ЛЏЕФЃЈМДбЯИёЕФгЩДјгагаЯоВЮЪ§ЕФЙЋЪНЫљЖЈвхЃЉВЂЧвВЛФмзуЙЛСщЛюЖјОЋШЗЕиЖдЯжЪЕЪРНчЕФЮЪЬтНЈФЃЁЃЕЋЪ§ОнЭкОђЬсЙЉСЫКмЖрЗЧВЮЪ§НЈФЃММЪѕЃЌПЩвдАяжњДДНЈСщЛюЖјЪЕгУЕФФЃаЭЁЃдкзюНќЪЎФъРяЃЌвВгааэЖрГЩЙІЕФЦНКтГщЯѓФЃаЭКЭЛњЦїбЇЯАММЪѕЕФЮФеТКЭАИР§баОПвбОЗЂБэЁЃ
2.ПьЫйЕФЪ§ОнбЛЗЪЙЕУдкЯжДњСуЪлвЕжаПЩвдЪЙгУЯрЖдМђЕЅЕФФЃаЭзіГіИќМгзМШЗЕФдЄВтЃЌвђЮЊаЁЙцФЃдіСПЪНЕФдЄВтвЛАуЖјбдвЊБШДѓОіВпИќМгШнвзЁЃР§ШчЃЌвђЮЊЖдгквЛИіаТЕФЕпИВадВњЦЗдкЯћЗбепаФжаЕФИажЊМлжЕЪЧЮДжЊЕФЃЌвЊМЦЫуЫќЕФзюгХМлИёЪЧКмРЇФбЕФЁЃЕЋЪЧИљОнашЧѓКЭПтДцЫЎЦНЪЕЪБЕїећДйЯњМлИёдђЪЧЯрЖдШнвзЕФЁЃгавЛаЉГЩЙІЕФЩЬвЕНтОіЗНАИЖдМлИёгХЛЏОЭМИКѕЖЊЦњСЫОМУбЇФЃаЭЃЌМђЕЅЕФИљОнЯњЪлБеЛЗЕФЗДРЁЧщПіРДОіЖЈМлИёЕФЩЯЩ§КЭЯТНЕ
[JL11]ЁЃ
вдЩЯСНЕувтЮЖзХдкСуЪлвЕздЖЏЛЏОіВпКЭЖЏЬЌгХЛЏОпгаКмИпЕФЧБСІЃЌвђДЫЮвУЧзЈзЂгкбаОПетИіСьгђЁЃБОЮФКмДѓЦЊЗљгУгкзлЪіСуЪлвЕепКЭбаОПШЫдБЗЂБэЕФГЩЙћЃЌетаЉГЩЙћЖМЪЧЫћУЧдкзлКЯгІгУГщЯѓОМУбЇФЃаЭКЭЪ§ОнЭкОђЗНЗЈЙЙНЈЪЕМЪЕФОіВпКЭгХЛЏЯЕЭГжаВњЩњЕФЁЃ
ЬиБ№ЕФЃЌБОЮФжївЊЪмЕН 3 ИіАИР§баОПЕФЦєЗЂЃЌЗжБ№Гізд Albert Heijn [KOK07]ЃЌКЩРМзюДѓЕФСЌЫјГЌЪаЃЌZara
[CA12]ЃЌвЛМвЙњМЪЗўзАСуЪлЩЬЃЌвдМА RueLaLa [JH14]ЃЌвЛМвДДаТдкЯпЪБЩаСуЪлЩЬЁЃЮвУЧЭЌбљзлКЯСЫРДзд
AmazonЁЂNetflixЁЂLinkedIn КЭаэЖрЖРСЂбаОПепКЭЩЬвЕЯюФПЕФНсЙћЁЃЭЌЪБЃЌЮвУЧБмУтЪЙгУФЧаЉШБЗІЪЕМљжЇГжЕФбЇЪѕНсЙћЁЃ
ЮвУЧЕФбаОПжївЊзХблгкгыЪеШыЙмРэЯрЙиЕФгХЛЏЮЪЬтЃЌАќРЈгЊЯњКЭЖЈМлЕШЮЪЬтЁЃИќМгЬиЪтЕФЪ§ОнЭкОђгІгУЃЌШчЙЉгІСДгХЛЏКЭЦлеЉМьВтЃЌ
Ъ§ОнЭкОђЙ§ГЬЪЕЯжЕФЯИНкЃЈШчФЃаЭжЪСПЕФбщжЄЃЉдђВЛдкетЮвУЧбаОПЕФЗЖГыФкЁЃ
БОЮФЪЃгрВПЗжзщжЏШчЯТЃК
1.ЮвУЧЪзЯШв§ШывЛИіМђЕЅЕФПђМмНЋСуЪлЩЬЕФааЮЊЃЌРћШѓКЭЪ§ОнСЊЯЕдквЛЦ№ЁЃДЫПђМмНЋзїЮЊИќЭГвЛЕФЗНЪНРДУшЪіЗжЮіЮЪЬтЁЃ
2.БОЮФЕФжїЬхВПЗжЬНЬжСЫвЛЯЕСагыСуЪлвЕЯрЙиЕФгХЛЏЮЪЬтЁЃЮвУЧНЋдкВЛЭЌеТНкж№ИіНщЩметаЉЮЪЬтЁЃУПИіеТНкЛсМђвЊУшЪіЮЪЬтЃЌВЂЬсЙЉвЛзщвЕЮёАИР§КЭгІгУЃЌвдМАЯъЯИНщЩмШчКЮНЋЮЪЬтЗжНтГЩОМУбЇФЃаЭКЭЪ§ОнЭкОђШЮЮёЃЌЪЙЕУПЩвдЭЈЙ§Ъ§жЕгХЛЏЗНЗЈРДНтОівЕЮёЮЪЬтЁЃ
3.ШЛКѓЃЌЮвУЧЛсгавЛИіеТНкзЈУХЬжТлетаЉЗНЗЈдкЪЕМЪгІгУжаЕФПЩЦкЕФОМУЪевцЁЃ
4.зюКѓЃЌзмНсВПЗжЛсЖдетаЉЮЪЬтжЎМфЕФвРРЕЙиЯЕНјааЬжТлЃЌДгЖјВћУївЛАуЕФддђКЭЙиМќЕуЁЃ
гХЛЏПђМмЃК
БОЮФНщЩмСЫ 6 ИіжївЊгыгЊЯњКЭЖЈМлЯрЙиЕФгХЛЏЮЪЬтЃЌетаЉЮЪЬтЖМФмЙЛгІгУЪ§ОнЭкОђММЪѕРДНтОіЁЃОЁЙметаЉЮЪЬтЗЧГЃВЛЭЌЃЌЕЋЮвУЧГЂЪдНЈСЂСЫвЛАуадЕФПђМмРДАяжњЩшМЦЧѓНтЫљашЕФгХЛЏКЭЪ§ОнЭкОђШЮЮёЁЃ
ИУПђМмЕФЛљБОЫМЯыЪЧгУвЛИіОМУжИБъЃЌР§ШчУЋРћТЪзїЮЊгХЛЏФПБъЃЌВЂНЋетвЛФПБъзїЮЊСуЪлЩЬааЮЊЃЈШчгЊЯњЛюЖЏЛђепЗжРрЕїећЃЉЕФКЏЪ§ЁЃ
ЭЌЪБМЦСПОМУбЇФПБъвВЪЧЪ§ОнЕФвЛИіКЏЪ§ЃЌМДМЦСПОМУФЃаЭгІИУБЛСуЪлЩЬЕФЬиадВЮЪ§ЛЏЃЌДгЖјдкЦфЪфГіжаВњЩњвЛИіЪ§жЕЃЌШчУЋРћТЪЁЃ
Р§ШчЃЌФГСуЪлЩЬдкМЦЛЎвЛИігЪМўгЊЯњЛюЖЏЁЃПЩааЕФааЖЏПеМфПЩБЛЖЈвхЮЊвЛзщЖдгкУПИіПЭЛЇЗЂЫЭ/ВЛЗЂЫЭОіВпМЏКЯЃЌЖјЛюЖЏЕФУЋРћТЪдђОіЖЈгкгЊЯњЖЏзїЃЈгааЉШЫЛсНгЪмМЄРјЖјСэвЛаЉШЫВЛЛсЃЉвдМАИјЖЈПЭЛЇЕФЦкЭћЪеШыКЭгЪМўГЩБОЁЃетвЛЗНЗЈПЩвдИќаЮЪНЛЏЕФгЩШчЯТЙЋЪНБэДяЃК
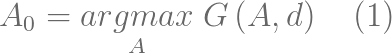
ДЫЙЋЪНРя G ЪЧПЩгУгкЗжЮіЕФЪ§ОнЃЌЪЧСуЪлвЕепааЮЊКЭОіВпПеМфЃЌ ЪЧМЦСПОМУФЃаЭКЏЪ§ЃЌЦфВЮЪ§ЪЧ d КЭ
AЃЌЖј A0 ЪЧзюгХВпТдЁЃетвЛПђМмгЩЮФЯз [JK98] ећРэЬсГіЁЃ
ФЃаЭ G ЕФЩшМЦЪЎЗжвРРЕгкЮЪЬтБОЩэЁЃдкДѓВПЗжЧщПіЯТЃЌЖдУЋРћТЪНЈФЃКЭгХЛЏЖМЪЧКЯРэЕФЁЃЕЋЪЧЃЌгааЉЧщПіЯТЦфЫћЕФФПБъвВЪЧгаПЩФмЕФЃЌОЭШчЯТвЛеТЬНЬжЕФЯьгІНЈФЃЁЃЭЌЪБашвЊзЂвтЕФЪЧгХЛЏЮЪЬтЃЈ1ЃЉвВИњЪБМфгаЙиЯЕЃЌвђЮЊЛЗОГЛсЫцзХШчаТВњЦЗЕФЩЯМмЁЂОКељЖдЪжЕФааЖЏЕШвђЫиБфЛЏЃЌСуЪлвЕепздМКЕФааЮЊвВЛсВњЩњгАЯьЁЃ
Ъ§ОнЭкОђдкетвЛгХЛЏЮЪЬтжаЕФНЧЩЋЪЧЗЧГЃживЊЕФЃЌвђЮЊМЦСПФЃаЭ G ЭЈГЃЖМБШНЯИДдгЧвБиаыЛљгкЪ§ОнЭЈЙ§ЛиЙщЕШЪ§ОнЭкОђММЪѕбЇЯАШЗЖЈЁЃ
дкФГаЉЧщПіЯТвђЮЊИДдгадЬЋИпЃЈШчгУЛЇЕФааЮЊКмФбОЋШЗдЄВтЃЉЛђепвђЮЊЮоЗЈНЋЯжгаЪ§ОнзіЭтЭЦЃЈШчЖдгкЭъШЋаТЕФЗўЮёЃЉЃЌФЃаЭЪЧЮоЗЈЭъШЋШЗЖЈЕФЁЃетЪБЃЌПЩвдгУ
A/B ВтЪдКЭЮЪОэЕїВщРДЛёЕУЖюЭтЕФЪ§ОнРДИФНјФЃаЭЕФОЋЖШЁЃ
ЮЪЬт 1ЃКЯьгІНЈФЃ
1.ЮЪЬтУшЪі
дкЙуИцЛђепЬиМлгХЛнЛюЖЏжаЃЌашвЊОіЖЈНЋвЛаЉзЪдДЭЖЗХИјвЛаЉПЭЛЇЁЃЖјетаЉзЪдДЖМЪЧгаГЩБОЕФЃЌШчгЪМФгЁжЦЩЬЦЗЕФФПТМЕФзЪН№ГЩБОЃЌЛђепвЛаЉИКУцаЇгІЃЈШчЪЙЕУгУЛЇШЁЯћгЪЭЈжЊЖЉдФЃЉЁЃ
ЭЌЪБЃЌ етаЉзЪдДНЋЛсгАЯьгУЛЇЕФОіВпЃЌШчДйЪЙЫћУЧИќЖрЕиЯћЗбЛђепЙКТђИќИпМлжЕЕФВњЦЗЁЃЦфФПБъЪЧевЕНвЛзщзюППЦзЕФКђбЁПЭЛЇЃЌЖдЫћУЧЭЖШызЪдДКѓФмЙЛЪЙЕУвЕМЈзюДѓЛЏЁЃ
ЭЖШыЕФзЪдДПЩвдЪЧЭЌжЪЕФЃЈШчЫљгаВЮМгЕФПЭЛЇЖМЕУЕНЭЌбљЕФМЄРјЃЉвВПЩвдЪЧИіадЛЏЕФЁЃдкКѓвЛжжЧщПіЯТЃЌСуЪлвЕепНЋЖдУПИіВЛЭЌЕФПЭЛЇЬсЙЉВЛЭЌЕФМЄРјШчВЛЭЌВњЦЗЕФгХЛнШЏРДзюДѓЛЏзмЬхЕФЪевцФПБъЁЃ
2.гІгУ
ЯьгІНЈФЃБЛЙуЗКЕФгІгУдкгЊЯњКЭПЭЛЇЙиЯЕЙмРэЩЯЃК
ШЗЖЈЬиЖЈЕФелПлЁЂгХЛнШЏКЭЬиМлЃЌашвЊЪЖБ№ГіПЭЛЇЖдетаЉМЄРјЕФЗДгІЁЃ
гаетЖдадЕФгЪМўДйЯњЁЂЛюЖЏКЭдљЦЗЃЈШч 4S ЕъЬсЙЉЕФУтЗбЬЋбєблОЕЃЉЭЈГЃашвЊЪЖБ№ГізюгХМлжЕЕФПЭЛЇРДНЕЕЭгЊЯњЗбгУЁЃ
ПЭЛЇЭьСєМЦЛЎашвЊЪЖБ№ГіФЧаЉПЩФмЛсРыПЊЕЋПЩвдЭЈЙ§МЄРјРДИФБфжївтЕФПЭЛЇЁЃР§ШчЃЌЕчЩЬПЩвдЯђФЧаЉЗХЦњЙКЮяГЕЛђепРыПЊЫбЫїЛсЛАЕФПЭЛЇЗЂЫЭЬиМлгХЛнЁЃ
дкЯпФПТМКЭЫбЫїНсЙћПЩвдИљОнПЭЛЇЖдФГаЉЩЬЦЗЕФЕФЯВКУРДжиаТЕїећЁЃ
ЯьгІНЈФЃАяжњгХЛЏСЫЕчгЪДйЯњРДБмУтВЛБивЊЕФРЌЛјгЪМўЃЌетаЉРЌЛјгЪМўПЩФмЛсШУПЭЛЇШЁЯћгЪМўЖЉдФЁЃ
3.ЧѓНт
ЛљгквдЩЯЕФЬжТлЃЌЮвУЧЯждкПЩвдШЯЪЖЕНетИіЮЪЬтОЭЪЧзЪдДЗжХфЕФгХЛЏЮЪЬтЃЌЖјгХЛЏЮЪЬтгЩвЛИіФПБъКЏЪ§Ч§ЖЏЁЃвЛИізюЛљБОЕФЗНЗЈЪЧЃКИљОнУПИіПЭЛЇЕФЯьгІИХТЪКЭЦкЭћОЛМлжЕРДЖдДйЯњЛюЖЏЕФећЬхРћШѓНЈФЃЁЃ
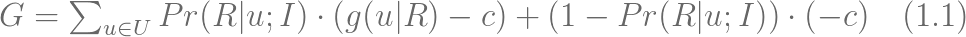
етРя Pr(RЉІu;I) ЪЧИјЖЈПЭЛЇ u ЖдМЄРј I ЕФЯьгІИХТЪЃЌg(u|R)) ЪЧетИіПЭЛЇЯьгІЕФМЄРјЕФОЛМлжЕЃЌЖј
c дђЪЧМЄРјЕФГЩБОЁЃЙЋЪНжаЕквЛЯюЪЧЯьгІДгЯьгІгУЛЇЛёЕУЕФОЛЪевцЃЌЖјЕкЖўЯюдђЪЧЖдгІдкУЛгаЯьгІЕФПЭЛЇЩЯЕФЦкЭћЫ№ЪЇЁЃФПБъЪЧЭЈЙ§евЕНвЛзщзюгаПЩФмЯьгІЛюЖЏВЂФмЙБЯзИпРћШѓЕФПЭЛЇзгМЏРДзюДѓЛЏ
GЁЃвђЮЊЙЋЪН (1.1) ПЩвддММђШчЯТЃК
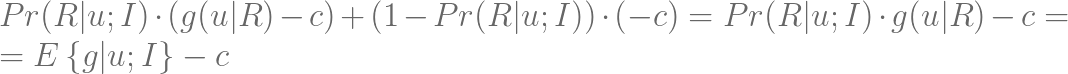
етРя E{g|u;I} БэЪОЖдИјЖЈПЭЛЇдкМйЖЈЫћЛсНгЪмМЄРјЕФЧщПіЯТЕФУЋРћТЪЕФЪ§бЇЦкЭћЃЌЖјПЭЛЇЕФбЁдёБъзМдђвЊЗћКЯвдЯТЬѕМўЃК

ЭЌЪБЃЌзюгХЕФПЭЛЇзгМЏ U ПЩвдЖЈвхЮЊзюДѓЛЏУЋРћТЪЕФзгМЏЃК
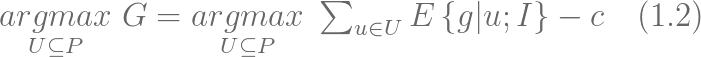
ЮвУЧвВПЩвдвдЫцЛњЗжХфМЄРјЮЊЛљзМЕФОЛжЕзюДѓЛЏЁЃЮЊДЫЃЌЮвУЧМйЩшВЮгыИУДЮгЊЯњЛюЖЏЕФПЭЛЇЪ§ЙЬЖЈЮЊ |U|ЁЃЪзЯШЃЌЮвУЧНЋЙЋЪН
(1.2) еЙПЊЃЌЯдЪОЕФАќРЈЖдгкЫцЛњбЁШЁЕФ |U| ИіПЭЛЇЕФгЊЯњЛюЖЏЕФЦкЭћУЋРћТЪЁЃ
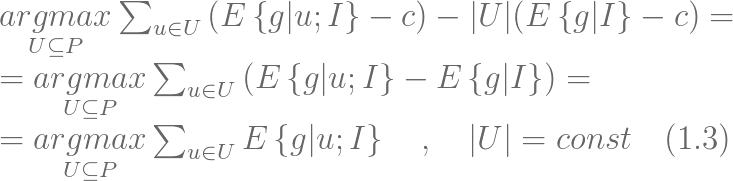
ДЫДІ E{g|I} ЪЧЫљгаПЭЛЇЩЯЕФЦНОљОЛМлжЕЁЃетвЛЦНОљОЛМлжЕЪЧГЃЪ§ЃЌвђДЫдк |U| ШЗЖЈЕФЧщПіЯТдкФПБъКЏЪ§жаПЩвдБЛТдШЅЁЃвђДЫЃЌЙЋЪНЃЈ1.2ЃЉдкЙЬЖЈ
ЕФЧщПіЯТЭЌбљПЩвдЕУЕНЃЈ1.3ЃЉЃК

ШЛЖјЃЌЮФЯз [VL02] ЬсГіетвЛФЃаЭДцдквЛЖЈЕФШБЯнЃЌвђЮЊИУФЃаЭЦЋЯђгквзгкНгЪмМЄРјЕФПЭЛЇЃЌЖјУЛгаПМТЧФЧаЉгаУЛгаМЄСвЖМЛсЙБЯзЭЌбљРћШѓЕФЕФПЭЛЇЁЃЮЊНтОіетвЛ
ШБЯнЃЌЮвУЧашвЊИљОнвдЯТЫФжжЧщПіРДМЦЫуПЭЛЇМЏКЯ U ЕФУЋРћТЪЃК
G1 ЈC ИљОнЙЋЪНЃЈ1.2ЃЉбЁдё U ВЂЯђжаЫљгаПЭЛЇЗЂЫЭМЄРј
G2 ЈC ЫцЛњбЁдё U ВЂЯђ U жаЫљгаПЭЛЇЗЂЫЭМЄРј
G3 ЈC ИљОнЙЋЪНЃЈ1.2ЃЉбЁдё U ЕЋЪЧВЛЗЂЫЭШЮКЮМЄРј
G4 ЈC ЫцЛњбЁдё U ЕЋЪЧВЛЗЂЫЭШЮКЮМЄРј
ЙЋЪНЃЈ1.2ЃЉЪЧзюДѓЛЏ жЎВюМДЯрНЯгкЫцЛњЭЖЗХЕФЬсЩ§ЖШЁЃ
СэвЛжжЗНЗЈЪЧгХЛЏЃЌетвЛФПБъКЏЪ§ВЛНіНіЖШСПЯрНЯгкЫцЛњЭЖЗХЕФЬсЩ§ЖШЭЌЪБЛЙПМТЧШЅГ§ЕєдкЭЌбљЕФПЭЛЇМЏКЯЩЯВЛзіШЮКЮМЄРјЕФЬсЩ§ЖШЁЃдкДЫЧщПіЯТЃЌЙЋЪНЃЈ1.2ЃЉБфЮЊШчЯТаЮЪНЃК
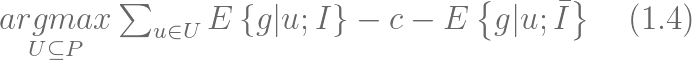
ДЫДІзюКѓвЛЯюЖдгІЕФЪЧЮДБЛМЄРјЕФПЭЛЇЕФЦкЭћОЛМлжЕЁЃетвЛЗНЗЈБЛГЦЮЊВюЗжЯьгІЗжЮіЛђепЬсЩ§ЖШНЈФЃгЩЮФЯз [BE09]
ЬсГіЁЃ
жЕЕУзЂвтЕФЪЧЃЌЙЋЪНЃЈ1.2ЃЉКЭЃЈ1.4ЃЉЖМВЛЪЧЭЈЙ§зюДѓЛЏгЊЯњЗбгУРДгХЛЏЕФЁЃПМТЧШчЯТЧщПіЃЌУПИіЯьгІЕФгУЛЇПЩвдЙБЯз
100 УРдЊЕФОЛРћШѓЃЌЖјМЄРјЗбгУЮЊ 1 УРдЊЁЃШчЙћвЛИіПЭЛЇзщга 100 ЭђПЭЛЇЃЌЦфжага 0.5% ЕФЧБдкЯьгІепЃЌдђЛЈЗбзюДѓЕФгЊЯњЛюЖЏЪЧЖдУПИіПЭЛЇЖМзіДЅДядђзюжеНЋЫ№ЪЇ
50 ЭђУРдЊЃЈзмЕФЯьгІепЙБЯзЕФ 50 ЭђУРдЊОЛМлжЕМѕШЅЛюЖЏЗбгУ 100 ЭђУРдЊЃЉЁЃ
ЙЋЪНЃЈ1.4ЃЉЖдгкИїжжРраЭЕФМлИёелПлЬиБ№живЊ(гХЛнШЏЁЂСйЪБМлИёелПлЁЂЬиМл)ЁЃПМТЧШчЯТЮЪЬтЃКЁАвЛИіСуЪлЩЬгІИУЯђУПЬьЖМТђЦЛЙћЕФШЫЬсЙЉЦЛЙћгХЛнШЏТ№ЃПЁБ
ИљОнЙЋЪНЃЈ1.2ЃЉЃЌЛиД№ЪЧПЯЖЈЕФЁЃвђЮЊетИіШЫКмгаПЩФмЛсЪЙгУгХЛнШЏЁЃ
ШЛЖјЃЌИќПЩФмЕФЪЧетИіПЭЛЇгУИќЕЭЕФМлИёЙКТђСЫЭЌбљЪ§СПЕФЦЛЙћЃЌИљБОЩЯетЛсНЕЕЭСуЪлЩЬЕФРћШѓЁЃЙЋЪНЃЈ1.4ЃЉПМТЧСЫФЌШЯЕФПЭЛЇааЮЊДгЖјЯћГ§СЫетвЛЮЪЬтЁЃЮвУЧдкЯТвЛНкНЋМЬајЬжТлМлИёЧјЗжЮЪЬтвђЮЊетвЛЪЧИіИДдгЕФЮЪЬтдЖГЌСЫЙЋЪНЃЈ1.4ЃЉЗЖГыЁЃ
ЙЋЪНЃЈ1.2ЃЉКЭЃЈ1.4ЃЉжаОЛЪеШыЕФЪ§бЇЦкЭћФмЙЛЛљгкЙ§ШЅПЭЛЇЖдМЄРјЪЧЗёНгЪмЕФРњЪЗЪ§ОнгУЗжРрЛђепЛиЙщФЃаЭРДШЗЖЈЁЃетвЛЮЪЬтПЩФмЪЧЗЧГЃгаЬєеНадЕФЃЌЬиБ№ЪЧЕБашвЊЦРЙРЕФМЄРјгыЙ§ЭљГіЯжЙ§ЕФЖМДцдкФГжжГЬЖШЩЯЕФВювьЁЃ
дкетжжЧщПіЯТЃЌШЋЙцФЃЕФЛюЖЏЩЯЯпжЎЧАашвЊдквЛИіПЭЛЇВтЪдзщЩЯНјааВтЪдЁЃСэЭтЃЌЖдгкСуЪлвЕепЖјбдУЋРћТЪВЂЗЧЮЈвЛЕФЙиМќжИБъЁЃдкЙЋЪНЃЈ1.2ЃЉКЭЃЈ1.4ЃЉжаЪЙгУЕФУЋРћТЪЖШСПЙиаФЕФЪЧЕквЛДЮИЖПюКѓМДЪБЕФЛуБЈЃЌДгПЭЛЇЙиЯЕЙмРэЕФНЧЖШПДетЪЧЗЧГЃМђЕЅЕФЪгНЧЁЃ
СуЪлвЕепЛЙЛсЙиаФЦфЫћВЛЭЌЕФЖШСПЃЌЖШСПЩЯЕФЖрдЊадЪЧШчДЫОоДѓвджСгкгавЛУХзЈУХбаОПетИіЮЪЬтЕФОМУбЇЗжжЇ
ЈC ЧуЯђадНЈФЃ[SG09, LE13] ЈC етвЛбЇПЦЗЂеЙСЫВЛЭЌЕФФЃаЭРДдЄВтгУЛЇЮДРДЕФааЮЊЁЃзюживЊЕФЧуЯђадФЃаЭАќРЈЃК
ЩњУќМлжЕдЄВтЁЃЩњУќМлжЕФЃаЭЪЧЙРМЦвЛИіПЭЛЇдкЦфЩњУќжмЦкФкПЩвдЙБЯзЕФЪеШыЛђепРћШѓзмЖюЁЃетвЛжИБъЖдгкФЧаЉФПБъЮЊЛёШЁаТПЭЕФгЊЯњЛюЖЏЖјбдЪЧКмживЊЕФЁЃ
ЧЎАќЗнЖюдЄВтЁЃЧЎАќЗнЖюФЃаЭгУРДЙРМЦгУЛЇЖдгкФГаЉРраЭЩЬЦЗЃЌШчдгЛѕЛђепЗўЪЮЃЌдкФГвЛСуЪлЩЬМАЦфдкИїОКељЖдЪжФЧЛЈЧЎЕФБШР§ЁЃетвЛЖШСПФмЙЛНвЪОФФаЉПЭЛЇОпгаЙБЯзИпЪеШыЕФЧБСІЃЌвђЮЊетвЛФЃаЭФмЙЛгУдкжвГЯМЦЛЎКЭЬсЩ§ЪЙгУЕФгЊЯњЛюЖЏжаЁЃ
РраЭРЉеЙЧуЯђЁЃИУФЃаЭЙРМЦЪзДЮЙКТђФГвЛРраЭЕФЩЬЦЗКѓЃЌДганЯаВњЦЗзЊЛЛЕНЩнГоЦЗЕФПЩФмадЁЃетвЛФЃаЭФмЙЛАяжњЩшМЦФПЕФЪЧЛёЕУЪЙгУРЉеЙЕФЛюЖЏЁЃ
СїЪЇЧуЯђЁЃетвЛФЃаЭЙРМЦПЭЛЇДгИјЖЈСуЪлЩЬСїЪЇВЂзЊЛЛЕНОКељЖдЪжЕФПЩФмадЁЃШчЙћПЭЛЇОпгаНЯИпЕФСїЪЇЧуЯђдђПЩвдЖЈЯђНјааЭьСєЛюЖЏЁЃР§ШчЃЌвЛИіСуЪлЩЬПЩвдЪЖБ№ГіФЧаЉЗХЦњСЫдкЯпЙКЮяГЕЛђепЭЫГіСЫЫбЫїЛсЛАЕЋЪЧЬсЙЉвЛЖЈелПлЛђепдљЦЗКѓЛсИФБфжївтЕФПЭЛЇЁЃ
ЙКЮяЯАЙпИФБфЧуЯђЁЃУПИіПЭЛЇЕФЙКЮяЯАЙпзюжеШЗЖЈСЫЦфЖдвЛИіСуЪлЩЬЕФМлжЕЃЌМДПЭЛЇЕФЙКТђЦЕТЪЁЂЙКТђЪВУДВњЦЗЁЂЙКТђЪВУДРраЭЕФВњЦЗЕШЕШЁЃетаЉЯАЙпЭЈГЃЪЧЮШЖЈЕФЃЌвЛЕЉСуЪлЩЬИФБфвЛИіПЭЛЇЕФЗжВуЃЌетИіЗжВуНЋЛсГжајЁЃ
вђДЫЃЌСуЪлвЕепЭЈГЃЖдевЕНФЧаЉЖдИФБфЯАЙпБШНЯПЊЗХЕФПЭЛЇИааЫШЄЃЌ ШчФЧаЉДгвЛИіГЧЪаЧЈвЦЕНСэвЛИіГЧЪаЕФШЫШКЃЌ
ДгбЇаЃБЯвЕЕФбЇЩњЃЌ ИеИеНсЛщЕФШЫШКЕШЕШЁЃвЛИіЕфаЭЕФР§згЪЧдЄВтПЭЛЇЪЧЗёдкЛГдадчЦк [DG12] вђЮЊаТЩњУќЕФЕЎЩњЛсЯджјЕФИФБфПЭЛЇЕФЙКЮяааЮЊЁЃ
вдЩЯФЃаЭЖМФмЙЛЧЖШыРрЫЦЙЋЪНЃЈ1.4ЃЉЕФЙЋЪНРДДњЬцУЋРћТЪФПБъЃЌЮвУЧдкКѓУцЕФаЁНкжаНЋеыЖдЬжМлИёВювьЛЏЕФЧщПіЯТЖделПлЕФЯьгІЧуЯђНЈФЃЕФЧщПізаЯИЬНЬжЧуЯђадНЈФЃЁЃЙигкЧуЯђадНЈФЃЕФИќЖрЯИНкПЩвдВЮПМ
[FX06] КЭ [SG09] СНБОЪщЁЃ
етвЛПђМмвВФмЙЛРЉеЙЕНдкЖрИіПЩФмЕФМЄРјЗНАИжабЁдёзюгХЕФЗНАИЁЃР§ШчЃЌвЛИіСуЪлЩЬПЩвдЙРМЦЖдгкСНИіМЄСвЗНАИ
A КЭ BЃЈР§ШчЧЩПЫСІБљМЄСмКЭЯуВнБљМЄСмЃЉЕФЦкЭћБэЯжШЛКѓЖдгкИјЖЈЕФгУЛЇПЩвдИљОнвдЯТБъзМ[WE07]РДбЁдёзюгХЕФбЁЯюЃК
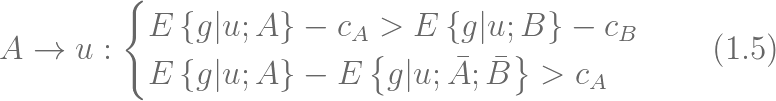
зюКѓЃЌжЕЕУзЂвтЕФЪЧЯьгІНЈФЃЪЧгыПЭЛЇЗжШКНєУмёюКЯЕФЃК
ЯьгІНЈФЃФмЙЛгУРДМьбщЭЈЙ§ОлРрааГЬЕФПЭЛЇЗжШКЕФПЩааадЁЃвЛИіЗжШКгІИУЖдЬиЖЈЕФгЊЯњМЦЛЎгаГжајЕФЯьгІЁЃ
ЧуЯђадФЃаЭЪЧЛљгкПЭЛЇЪ§ОнбЕСЗЕУЕНЕФЛиЙщКЭЗжРрФЃаЭЁЃПЭЛЇЗжШКПЩвдВЮПМЖдгкжївЊЛиЙщСПЕФЗжЮіНсЙћЁЃСэвЛЗНУцЃЌДгОлРрНсЙћжавВПЩвдЗЂЯжКЯРэЕФЧуЯђадФЃаЭЁЃ
ЮЪЬт 2ЃКЭЦМі
1.ЮЪЬтЫЕУї
вЛзщМЄРјжаЕФУПвЛЯюМЄРјЖдгІзХвЛИіВњЦЗЛђепЦфЫћФПТМЯюФПЁЃеЙЪОетаЉМЄРјВЂВЛжБНггыЗбгУГЩБОЯрЙиЃЌЕЋЪЧжЛгагаЯоЪ§СПЕФМЄРјФмЙЛеЙЪОИјгУЛЇЁЃ
ДгетИіНЧЖШРДЫЕЃЌУПИіМЄРјЕФеЙЪОЖМЛсеМгУвЛЖЈЕФЦСФЛПеМфЛђепПЭЛЇЕФзЂвтСІЃЌЫљвдИјПЭЛЇЬсЙЉЕФФГИіМЄРјЕФИКУцМЄРјФмЙЛБЛЛњЛсГЩБОЕФЫ№ЪЇРДЖШСПЁЃ
дкетбљЕФФПБъЯТОЭашвЊНЋМЄРјЕФзгМЏЖдгкУПИіПЭЛЇЖјбдЖМЪЧИіадЛЏЕФЃЈШчЭјеОЩЯЕФЭЦМіЃЉДгЖјзюДѓЛЏШКЬхЕФЙКТђБэЯжЁЃ
2.гІгУ
ИУЮЪЬтзюЕфаЭЕФгІгУгаЭЦМіЯЕЭГЃЌ ИіадЛЏЫбЫїНсЙћЃЌ КЭЖЈЯђЙуИцЁЃ ДЫЭтЛЙгавЛаЉЦфЫћживЊЕФгІгУЃК
ГЇЩЬдожњелПлПЩвдЙщЮЊетРрЮЪЬтЃЌвђЮЊСуЪлЩЬЖдМЄРјЕФГЩБОВЛЙиаФЃЈгЩГЇЩЬИВИЧетВПЗжГЩБОЃЉ, ЫћУЧНіЙиаФгааЇЕФЖЈЯђЁЃГЇЩЬдожњЕФЛюЖЏБЛЙуЗКЕФгІгУдкКмЖрСуЪлЯИЗжСьгђЃЌШчдгЛѕЕъЛђепАйЛѕЩЬЕъЃЌвђЮЊетаЉГЇЩЬЪаГЁЗнЖюЕФЬсЩ§гаКмжиЕФвРРЕЁЃ
НЛВцЯњЪлЕФгЊЯњФмвВЙЛДгЭЦМіФЃаЭжаЛёвцЃЌвђЮЊвЛаЉЭЦМіММЪѕФмЙЛНвЪОГіПЭЛЇЛЯёжаЕФвўКЌЮЌЖШЃЌШчЩњЛюЗНЪНЁЃетаЉФмСІЖдгкПчРржЎМфЕФЭЦМіЪЧЬиБ№гагУЕФЃЌПЩвдЛљгкПЭЛЇЗўЪЮЗНУцЕФЯћЗбааЮЊЯђПЭЛЇЭЦМіМвОгЛђепГјОпЁЃ
ЭЦМіЯЕЭГПЩвдНЋгУЛЇЕФЙКТђКЭфЏРРРњЪЗИХРЈЮЊаФаФРэбЇЛЯёЃЌвђДЫЗІЮЖЕФзХзАЦЗЮЖЛђепдЫЖЏаЭЕФЩњЛюЗНЪНФмЙЛСПЛЏВтСПЁЃЭЌбљЕФММЪѕвВПЩвдИљОнОКељепЯњЪлВњЦЗЕФРДЖдОКељепЛЯёЃЌОЭЯёИљОнПЭЛЇЙКТђРДЖдПЭЛЇЛЯёЁЃ
вЛаЉЭЦМіЫуЗЈФмЙЛЛљгкЮФБОУшЪіРДЧјЗжВњЦЗЕФаФРэЮЌЖШЃЌШчЩњЛюЗНЪНЕШЁЃЫљвдЩЬМвПЩвдРћгУЫќУЧРДЦРЙРВњЦЗУшЪіЃЌвВПЩвдгУРДЛёЕУЙигкВњЦЗЖЈЮЛЕФЪЪЕБДыДЧЕФНЈвщЁЃ
ЬиБ№ашвЊзЂвтЕФЪЧОЁЙмЭЦМіЭЈГЃБЛШЯЮЊЪЧЯпЩЯЗўЮёЬигаЕФЃЌЕЋЦфЫљВњЩњЕФЛљБОддђКЭММЪѕЖдгкСуЪлвЕЕФаэЖрЗНУцвВЪЧЗЧГЃживЊЕФЁЃвђЮЊетаЉММЪѕжТСІгкНвЪОПЭЛЇЖдВњЦЗаЫШЄЕФвўКЌЙиЯЕЃЌЖјетЪЧСуЪлЩЬзюЛљБОЕФШЮЮёЁЃ
3.НтОіЗНАИ
ЭЦМіЯЕЭГдкЙ§ШЅ20ФъЪЧЗЧГЃЪмЙизЂЕФбаОПСьгђЃЌ[JZ10, RR10] СНБОЪщЬсЙЉСЫЖдМИЪЎжждкИїжжТлЮФЃЌбнНВКЭАзЦЄЪщжаЬсГіЕФЭЦМіЫуЗЈКЭММЪѕЕФЯЕЭГЛЏЪгНЧЁЃ
ФГжжГЬЖШЩЯЃЌЭЦМіММЪѕЕФИпЖШЖрбљаддкгквЛаЉЪЕЯжЭЦМіЪБгіЕНЕФЬєеНЃЌШчПЭЛЇЦРЗжЕФЯЁЪшадЃЌМЦЫуЕФПЩРЉеЙадЃЌвдМАШБЗІаТЮяЦЗКЭПЭЛЇЕФаХЯЂЁЃ
ЯдШЛЃЌЮвУЧЮоЗЈдкБОНкжазлЪіФФХТвЛЯТВПЗжЗНЗЈКЭЫуЗЈЃЌЖјЧвдкДЫДІЬНЬжетаЉвВУЛгаЬЋЖрЕФвтвхЃЌвђЮЊетбљЕФзлЪіИЉЪАНдЪЧЁЃЯрЗДЮвУЧНЋЙизЂгкЧ§ЖЏЩшМЦЭЦМіЯЕЭГЕФФПБъКЭаЇгУКЏЪ§ЃЌЖјЛљБОЩЯКіТдетвЛЮЪЬтЕФЫуЗЈКЭММЪѕВрЕФЯИНкЁЃ
ДгМЦСПОМУбЇЕФЙлЕуРДПДЃЌЭЦМіЯЕЭГЮЪЬтгыЕчЩЬКЭШЋЧўЕРЩЬвЕдкКмЖрСуЪлСьгђЕФаЫЦ№ДјРДЯњЪлЦЗРрЕФПьЫйРЉеХЪЧНєУмЯрЙиЁЃДѓЕФЦНРрдіМгСЫКмЖрЗЧГЉЯњВњЦЗЃЌУПвЛИіВњЦЗЕФЯњЪлСПКЭЙБЯзЕФЪеШыЖМЪЧКмЩйЕФЃЌЕЋЪЧетИіЁАГЄЮВЁБЕФзмЬхЙБЯзЪЧЗЧГЃЯджјЕФЁЃ
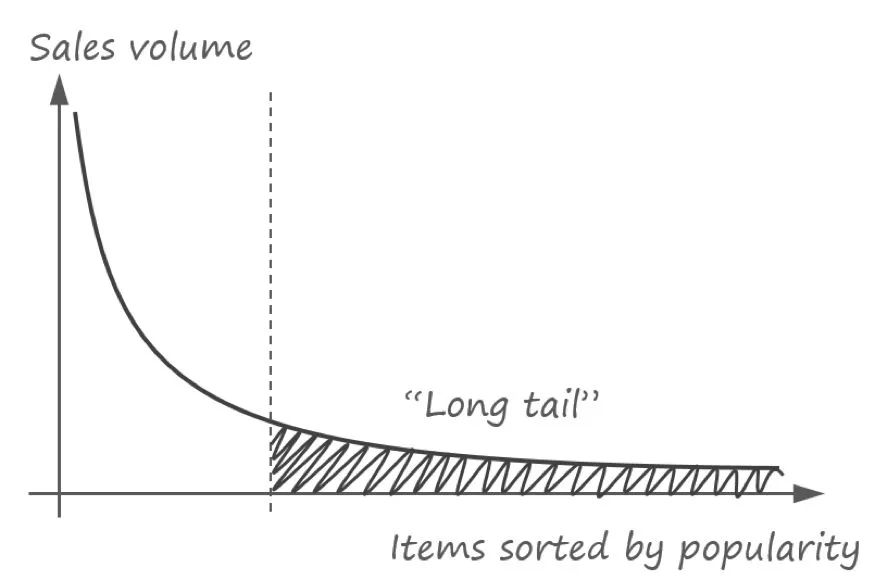
ДЋЭГЭЦМіММЪѕШчЭЦЙузюГЉЯњЕФЩЬЦЗВЛФмгааЇРћгУЗЧГЉЯњЩЬЦЗЕФЧБСІЃЌетОЭашвЊИќЧЩУюЕФЭЦМіЗНЗЈдкЪ§АйЭђЫћЛђепЫ§ДгЮДЬНЫїЙ§ЕФВњЦЗжаЖдЦфНјаав§ЕМЁЃ
вђЮЊЮвУЧжївЊЙизЂФЃаЭЖдПЭЛЇдкВњЦЗЩЯЕФЦЋКУЕФУшЪіЃЌЮвУЧНЋДгИљОнаЇгУКЏЪ§ЕФИДдгадДгМђЕЅЕНИКд№РДНщЩмЪЙгУзюЙуЕФЭЦМіММЪѕЃЌ
ЮвУЧНЋвРОнШчЯТЭМЫљЪОЕФЭЦМіММЪѕВуДЮЗжРрЭМЁЃетИіВуДЮЗжРрзлКЯСЫЭЦМіЯЕЭГЕФГЃгУЗжРрЃЌЕЋвВВЛЪЧЭъШЋвЛжТЃК
4.ЕЅвЛФПБъ
ШУЮвУЧДгЕЅвЛФПБъЭЦМіШЮЮёЕФЛљБОЖЈвхПЊЪМЃЌетвЛЖЈвхБЛЙуЗКЕФгІгУдкЭЦМіЯЕЭГЕФЮФЯзжЎжаЁЃСуЪлЩЬЯђгУЛЇШКЬх
U={u_1,Ё,u_m } ЯњЪлЮяЦЗ J={j_1,Ё,j_n }ЁЃЦРЗжКЏЪ§ R:JЁСU БэЪОвЛИігУЛЇЖдвЛИіЮяЦЗЕФЙлЕуДгИКУцЃЈЁАВЛЯВЛЖЁБЃЉЕНе§УцЃЈЁАЯВЛЖЁБЃЉЃЌЭЈГЃЪЙгУЪ§зжРДБэЪОЁЃ
вЛаЉгУЛЇКЭЮяЦЗЖдЕФЦРЗжжЕПЩвдЛљгкгУЛЇЕФЦРЗжЛђепЭЈЙ§ЗжЮіЙКТђРњЪЗЃЌЭјеОЗУЮЪМЧТМРДЙРМЦЃЌЭЦМіШЮЮёдђПЩвдБЛЖЈвхЮЊЖдИјЖЈгУЛЇ-ЮяЦЗЖд
(u,j) ЦРЗжжЕ ?r_(u,j) ЕФдЄВтЁЃ
гаСНжжЗНЗЈПЩвдНтОіЦРМЖдЄВтЮЪЬтЃК
ЭЈЙ§ВщевгыЬиЖЈгУЛЇЙ§ШЅЯВЛЖЕФЯюФПЯрЫЦЕФЯюФПРДЖРСЂЙРМЦУПИігУЛЇЕФЦРЗжЃЛ
вВПЩвдЭЈЙ§ЖдРДздгыИјЖЈгУЛЇРрЫЦЕФгУЛЇЕФЦРЗжНјааЦНОљРДЙРМЦЦРЗжЁЃетСНжжЗНЗЈЗжБ№БЛГЦЮЊФкШнЙ§ТЫКЭазїЙ§ТЫЁЃ
5.ФкШнЙ§ТЫ
ФкШнЙ§ТЫЕФжївЊЫМЯыЪЧЛљгкЖдгУЛЇЙ§ЭљЖдгкВњЦЗЕФЦЋКУЁЂааЮЊКЭЙКТђЁЃОЁЙмВЛПЩвдЖдФкШнЙ§ТЫзіВЛЭЌЕФНтЪЭЃЌ
ЮвУЧбЁдёНЋЦфзїЮЊЗжРрЮЪЬт [PZ07] РДЧПЕїЪ§ОнЭкОђЕФгІгУЃК
УПИігУЛЇПЩвдБЛЪгзївЛИіЖдЮяЦЗдЄВтЦРЗжЕФЛиЙщФЃаЭЁЃвЛИіЬиЪтЕФР§згЪЧПЩвдгУЖўЗжРрНЋЮяЦЗЗжЮЊСНИіРрБ№ ЈC
ЁАЯВЛЖЁБКЭЁАВЛЯВЛЖЁБЁЃ
вЛИігУЛЇЕФЛЯёОЭЪЧЩЯУцНщЩмЕФЛиЙщФЃаЭЕФвЛИіЪЕР§ЁЃетвЛФЃаЭЪЙгУИУгУЛЇЕФвбжЊЦРЗжЃЈЯдЪОЦРЗжЃЌЙКТђРњЪЗЕШЕШЃЉРДбЕСЗЁЃ
ИјжИЖЈгУЛЇЕФЭЦМіЮяЦЗСаБэЪЧЭЈЙ§ЖдЫљгаФПТМЮяЦЗВЩгУИУгУЛЇЖдгІЕФЛиЙщФЃаЭдЄВтЦРЗжШЛКѓбЁдёФЧаЉЙРМЦЦРЗжзюИпЕФЮяЦЗзгМЏРДЛёЕУЕФЁЃ
ОЁЙмвдЩЯЕФЙ§ГЬЫЦКѕЪЧЪЧБШНЯжБНгЕФЃЌЕЋЪЧЪЕМЪЩЯШЗЪЕЗЧГЃЬєеНЕФЁЃвђЮЊгУЛЇКЭЮяЦЗЪЧИљБОВЛЭЌЕФЪЕЬхЃЌЖјЧввЊевЕНвЛжжПЩвджБНгНЋЮяЦЗзЊЛЛГЩЛиЙщФЃаЭПЩвдЪЙгУЕФгУЛЇЦЋКУетжжЮЂУюЕФЖЋЮїЁЃ
зюжївЊЕФЮЪЬтЪЧДцЛѕЪєаджюШчЦЗХЦЁЂЮяЦЗУћЃЌЛђепМлИёЖдгкКтСПЮяЦЗЖдгУЛЇЕФаЇгУЪЧИљБОВЛЙЛЕФЁЃОЁЙмвЛаЉПЭЛЇФмЙЛБЛТњзужвгкФГЦЗХЦЛђМлИёШЁМўЕФЬиеїЃЌЕЋЪЧашвЊИќЖрЮЂУюЖјгааХЯЂЕФЮЌЖШШчЩњЛюЗНЪНЛђепЦЗЮЖРДУшЪіЙлВьЕНЕФФЃЪНКЭЙВадЁЃ
етаЉвўЪНЕФЮЌЖШЖдгкШчЕчгАЁЂЪщМЎЁЂвєРжЃЌЩѕжСЪЧШчЗўЪЮетбљЕФгааЮЮяЦЗЖМЪЧЗЧГЃживЊЕФЁЃСуЪлЩЬПЩвдгУШчЯТЕФЗНЗЈЛљгкБъзМЕФЗжРрММЪѕРДЖдДјгавўКЌЮЌЖШЕФЮяЦЗДђБъЧЉ
[GH02]ЃК
Р§ШчЃЌЗўзАПЩвдгУжюШчЪБїжЁЂБЃЪиЁЂдЫЖЏЕШБъЧЉРДБъЪЖЁЃ
БъзМВњЦЗЪєадЃЈШчЮФБОУшЪіЃЉжМдкЯђПЭЛЇЬсЙЉЬиЖЈЕФгЊЯњаХЯЂЃЌвђДЫЫќУЧвўКЌЕиАќКЌСЫвЛаЉЮоаЮЕФЪєадЁЃвђДЫЃЌШЫЙЄЦРЗжЯюФПЕФЮяЦЗзгМЏПЩвдгУгкЙЙНЈНЋДгВњЦЗЪєадгГЩфЕНвўКЌЮЌЖШЕФЗжРрФЃаЭЁЃР§ШчЃЌПЩвдЪЙгУБДвЖЫЙЗжРрЗНЗЈРДЙРМЦУшЪідквўКЌЪєаджЕГіЯжЪБДЪГіЯжЕФЬѕМўИХТЪ
PrЃЈДЪЯюУшЪі | вўКЌЪєаджЕЃЉЁЃ
ЮяЦЗШЛКѓПЩвдЭЈЙ§МЦЫуКѓбщИХТЪ PrЃЈвўЪНЪєаджЕ | ЯюФПУшЪіЃЉРДздЖЏЗжРрУЛгаШЫЙЄЦРЗжЕФЩЬЦЗЁЃ
вЛАуЛЏЕФРДПДЃЌФкШнЙ§ТЫКЭЮяЦЗНЈФЃЪЕМЪЪЧаХЯЂМьЫїШЮЮёЃЌЫљвдаэЖрЕФЮЊЖїБОЭкОђКЭЫбЫїММЪѕЃЈР§ШчЃЌ[MA08]
ЕФзлЪіЫљЬсЕНЕФЃЉПЩвдБЛгУРДЙЙНЈЭЦМіЯЕЭГЁЃЮвУЧдкДЫТдЙ§етаЉЯИНкЃЌвђЮЊДгМЦСПОМУЕФНЧЖШРДПДетаЉЖМВЛЪЧзюживЊЕФВПЗжЁЃ
аЭЌЙ§ТЫЃК ЧАУцВПЗжЬсЕНЕФвўКЌЮЌЖШЕФЮЪЬтОпгаживЊвтвхЃЌДЫЮЪЬтПЩвдв§ЕМЮвУЧСЫНтЭЦМіММЪѕЕФЕкЖўИіЯЕСаЁЃетИіЮЪЬтдДгкИљБОЮоЗЈбЯИёЕФЖдШЫЕФПкЮЖКЭЧуЯђНЈФЃЁЃ
аЭЌЙ§ТЫЪЧвЛжжздШЛЕФЃЌвВаэЪЧЮЈвЛВЛашвЊЖдЯЕЭГНјааКмЖрШЫЙЄЙЄзїЕФНтОіЗНАИ ЈC ЭЦМіОіВпжаЖдЁБШЫЕФвђЫиЁБЕФашЧѓЭЈЙ§ЦфЫћгУЛЇЕФЗДРЁРДТњзуЁЃ
зюЛљБОЕФаЭЌЙ§ТЫФЃаЭ [RE04, BR98] жБНггЩгУЛЇжЎМфЕФЯрЫЦЖШЖШСПРДЖЈвхЃК
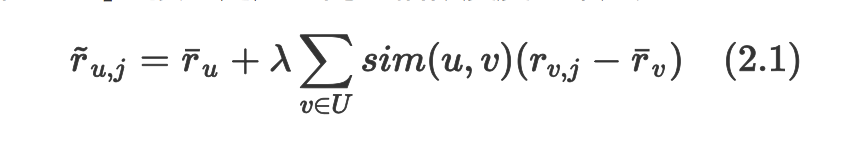
ДЫДІ r_u,j ЮЊгУЛЇ u Жд j ЮяЦЗЕФЦРЗжЃЌU ЪЧЫљгагУЛЇЕФМЏКЯЛђепЦєЗЂЪНбЁШЁЕФИјЖЈгУЛЇЕФСкНќгУЛЇЃЌІЫ
ЪЧЙцЗЖЛЏЯЕЪ§ЃЌsim(u,v) ЪЧСНИігУЛЇжЎМфЕФЯрЫЦЖШЖШСПЃЌ Жј ЁЅr_u ЪЧИъЖЁгУЛЇЕФЦНОљЦРЗжЃК
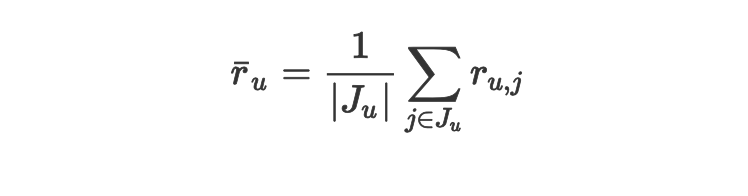
МйЩш J_u ЪЧвЛзщгУЛЇЦРЗжЙ§ЕФЮяЦЗЃЌЙЋЪН (2.1) ЪЙгУЕФЦНОљгУЛЇЦРЗжИХФюРДНЈФЃгУЛЇБШЦфЫћгУЛЇдкДђЗжЧуЯђЩЯЪЧЦЋИпЛЙЪЧЦЋЕЭЃЌвђЮЊЫћУЧгаЕФвЊЧѓИпгаЕФвЊЧѓЕЭЁЃЫфШЛВЛЪЧОјЖдБивЊЃЌетвЛаое§дкЪЕМљЪЧЩЯЗЧГЃживЊВЂдкзюПЊЪМЪЕЯжаЭЌЙ§ТЫЪБОЭБЛЙуЗКгІгУСЫЁЃ
вЛАугУгрЯвОрРыЛђепЦЄЖћЩЯрЙиЯЕЪ§РДМЦЫуЦРЗжЯђСП J_u КЭ J_v жЎМфЕФЯрЫЦЖШЁЃДЫЭтЃЌЮФЯз [ER98,
SU09] НщЩмСЫКмЖрЖдгкДЫЛљБОЯрЫЦЖШЖШСПНјааЕїећЕФЖржжЗНЗЈРДИФНјЪЙгУжаЕФадФмЁЃ
ФЃаЭЃЈ2.1ЃЉДцдквЛаЉЯджјЕФШБЯнЃКЪзЯШетвЛФЃаЭЕФМЦЫуИДдгадЃЈгыЮяЦЗКЭгУЛЇЪ§СПГЩе§БШЃЉКмИпЃЌЦфДЮгУЛЇЕФЦРЗжЪЧЗЧГЃЯЁЪшЕФЁЃЦРЗжЕФЯЁЪшадЪЧжИУПИігУЛЇЖМжЛЛсЖдКмаЁвЛВПЗжЮяЦЗНјааЦРЗжЃЌЫљвддкМЦЫуЯђСП
J_u КЭЯђСП J_v ЕФЯрЫЦЖШЪБОГЃЛсГіЯжУЛгажиКЯЕФдЊЫиЃЌетЛсНЕЕЭЭЦМіЕФжЪСПЁЃ
Р§ШчЃЌжкЫљжмжЊ Amazon[SA01] КЭ Netflix[YK08] ЕФЦРЗжОиеѓжаЕФЦРЗжШБЪЇТЪДяЕН
99%ЁЃЮЊСЫПЫЗўетвЛЯожЦЃЌЛљгкгУЛЇЕФФЃаЭЃЈ2.1ЃЉдкЭЈГЃБЛИХФюЩЯЗЧГЃЯрЫЦЕФЛљгкЮяЦЗЕФФЃаЭ [SA01,
YK08] ЫљШЁДњЃК
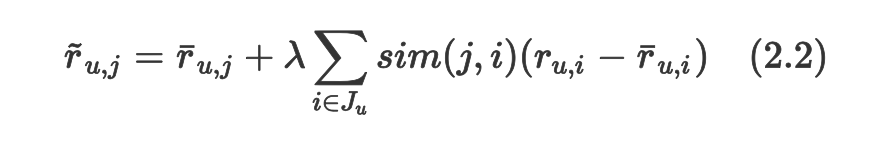
ЦфжаЮяЦЗжЎМфЕФЯрЫЦЖШЖШСПЪЧЛљгкФЧаЉдкСНИіЮяЦЗЩЯЖМгаЦРЗжЕФгУЛЇЕФЛљзМЦРЗж ЁЅr_(u,j) РДМЦЫуЕФЁЃЛљзМЦРЗжЭЌЪБПМТЧСЫгУЛЇЦЋВюЃЈгУЛЇЕФЦНОљЦРЗжжЕЯрНЯгкећЬхЦРЗжЕФЦЋВюЃЉвдМАЮяЦЗЦЋВюЃЈЮяЦЗЕФЦНОљЦРЗжЯрНЯгкећЬхЦРЗжЕФЦЋВюЃЉЁЃ
жЕЕУзЂвтЕФЪЧЃЌгавЛМђЕЅЕФЗНЗЈРДЪЕЯжЙЋЪНЃЈ2.2ЃЉЃЌДЫЗНЗЈЭЈЙ§бАевЦЕЗБЯюМЏЃЈБЛЦЕЗБвЛЦ№ЙКТђЕФЮяЦЗЃЉВЂЛљгкдкЦЕЗБЯюМЏЕФЭЌЯжРДМЦЫуЯрЫЦЖШЁЃетвЛЗНЗЈвђЦфМђЕЅБЛЪгЮЊЁАЧюШЫЕФЭЦМів§ЧцЁБ[RE03]ЁЃ
ФЃаЭЃЈ2.1ЃЉКЭЃЈ2.2ЃЉЪєгкЫљЮНзюНќСкФЃаЭЃЌетаЉФЃаЭЭЈЙ§ЗжЮіЯрЫЦЕФгУЛЇЛђепЮяЦЗЕФСкОгРДЙРМЦЫћУЧЕФЦРЗжЁЃетвЛЯЕСаЕФЫуЗЈвВАќРЈКмЖрБфжжЕФММЪѕ
[SU09] ЭЈЙ§ЪЙгУИњНєДеЕФИХТЪФЃаЭЛђепЦфЫћНќЫЦЗНЗЈРДШЁДњМЦЫуПЊЯњАКЙѓЕФМьВщСкОгЕФЗНЗЈЁЃ
ОЁЙмзюНќСкФЃаЭЪЧвЛжжБЛжюШчбЧТэбЗЕШСьЯШЕФСуЪлЩЬбщжЄЙ§ЕФЭЦМіММЪѕЃЌЕЋдкИљБОЩЯетаЉММЪѕЛЙЪЧдкИљБОЩЯОпгадкФкШнЙ§ТЫжаОЭгаЕФвўКЌЮЌЖШЫљДјРДЕФЮЪЬтЁЃЧАУцПМТЧЕФгУЛЇжЎМфКЭЮяЦЗжЎМфЕФЯрЫЦЖШЖШСПЖдгкНвЪОгУЛЇКЭЮоЦЋжЎМфЕФИДдгЙиЯЕЃЌЦфФмСІЪЧгаЯоЕФЁЃ
етгыаХЯЂМьЫїРяУцЕФЭЌвхЫбЫїКЭЖрвхЫбЫїУоУцСйЕФЮЪЬтЪЧРрЫЦЕФЃЌвЊНвЪОЫбЫїепЕФЪЕМЪвтЭМЃЌВЂНЋЦфвтЭМЗвыГЩЮФБОКЭВщбЏжЎМфЕФЯрЫЦЖШЪЧЗЧГЃЬєеНЕФЪТЧщЁЃ
ЮЊСЫНтОіетвЛЮЪЬтЃЌвЛжжБЛГЦЮЊвўКЌгявхЗжЮіЕФЕФММЪѕБЛЬсГіРД [DR90]ЁЃИУЗНЗЈБЛЬсГіРД 10 ФъКѓБЛгУРДЩшМЦЭЦМіЯЕЭГ
[SA00]ЃЌВЂПЊДДСЫвЛРраТвўКЌвђзгФЃаЭЁЃ
вўКЌвђзгФЃаЭжївЊЕФЫМЯыФмЙЛБЛУшЪіШчЯТЃКЦРЗжКЏЪ§ R ФмЙЛБЛБэДяГЩ mЁСn Оиеѓ(m ЪЧгУЛЇЪ§ЃЌn
ЪЧВњЦЗЪ§)ЃЌ ЦфжаЕФдЊЫиЪЧЦРЗжжЕЁЃетПЩвдБЛЕБзївЛИіЯпадПеМфЮЪЬтЁЃ
ЭЦМіШЮЮёдђПЩвдБЛжиаТЖЈвхЮЊгУЦфЫћЦРЗжЯђСПЕФзщКЯРДМЦЫугУЛЇЦРЗжЯђСПЁЃЪЕМЪЩЯЃЌЙЋЪНЃЈ2.1ЃЉздШЛЕФОЭЪЧвЛжжШЈжигЩЯрЫЦЖШКЏЪ§ЖЈвхЕФЦРЗжжЦЕФЯпадзщКЯЁЃ
ШЛЖјЃЌЮЪЬтЪЧЦРЗжОиеѓШБЪЇЦРЗжЖјЯЁЪшЃЌвђЦЋМћКЭЫцЛњвђЫиЭЈГЃДјгадывєЃЌЖјЧвЛљгкЮяЦЗЮЌЖШдђЯожЦСЫНвЪОгУЛЇЦЗЮЖЕФФмСІЃЌЖјЦЗЮЖЭЈГЃЪЧгывЛзщЮяЦЗЯрЙиЖјВЛЪЧгыЕЅИіЮяЦЗЯрЙиЁЃ
ЛЛОфЛАЫЕЃЌ БЛЩЂТфдкОоДѓЕФЕЭУмЖШОиеѓжаВЂЛьгавЛЖЈГЬЖШдывєЕФаХКХжЧФмЭЈЙ§баОПвўКЌФЃЪНВХФмЯдЪОГіРДЁЃвўКЌвђзгФЃаЭЕФЫМЯыЪЧгУЕЭЮЌЖШЕФЛљРДНќЫЦвЛИіИпЮЌЯпадПеМфЃЌетгажњгкДяГЩвдЯТФПБъЃК
НЯЩйЕФЮЌЖШФмЙЛАяжњАбаХКХЕФФмСПМЏжаЃЌдђУПИіЛљЯђСПЖдЦРЗжЙРМЦЕФЙБЯзЖМЪЧЯджјЕФЁЃЫќЭЈЙ§ЖЊЦњМђЕЅЕФВЛЪЪгІетаЉНЯаЁЕФЛљАЁЕФВЈЖЏРДМѕЩйдыЩљЁЃ
ЛљБОЕФМЦЫуЙ§ГЬПЩвдБЛЩшМЦРДВњЩњгазХзюЩйвРРЕЕФЛљЯђСПЃЌДгЖјгааЇЕФНвЪОгУЛЇЦЗЮЖЕФжївЊЧуЯђЃЌетаЉЧуЯђУПИіЖдгІвЛИіЛљЯђСПЁЃР§ШчЃЌNetflix
гУетвЛЗНЗЈРДдЄВтЕчгАЦРЗж [YK08, YK09] ЪБ, ЯЕЭГВњЩњЕФЮЌЖШЧхЮњЕФЖдгІзХжюШчЯВОчЃЌФаХЎЕШзјБъжсЁЃ
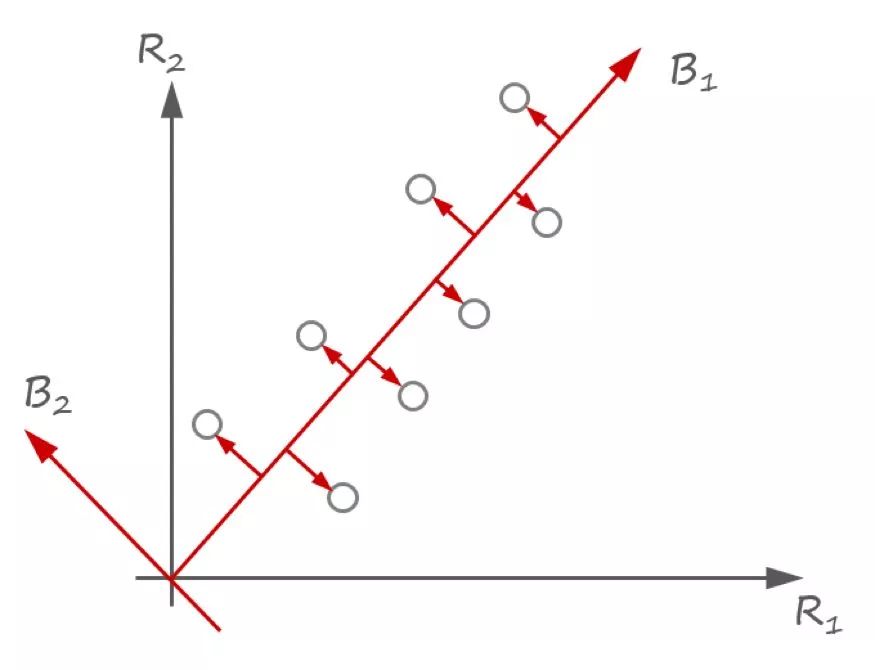
МЏКЯжаЕФУПИіЕубизХ R_1 КЭ R_2 ЮЌЖШЖМгазХКмДѓЕФзјБъжЕВЂЯдЪОГіЪ§ОнЕФИДдгЖјВЛЙцдђЕФНсЙЙЁЃШЛЖјЃЌдкСэвЛИізјБъЯЕ
B жадђНвЪОСЫЪ§ОнПЩвдБЛЮЌЖШ B_1 гааЇУшЪіЃЌЖјЮЌЖШ B_2 дђВЂВЛживЊЃЌетАЕЪОСЫетЪЧвЛИівЛЮЌЕФвўКЌвђзгФЃаЭЁЃ
ФГжжГЬЖШЩЯЃЌвўКЌвђзгФЃаЭФмЙЛгыРыЩЂгрЯвБфЛЛ (DCT) ЯрБШНЯЃЌРыЩЂгрЯвБфЛЛБЛгУдкЭМЯёбЙЫѕЫуЗЈжюШч
JPEG жаРДгУЩйСПЕФаГВЈРДНќЫЦЭМЦЌЁЃ
вдЩЯЕФЫМПМСДв§ЕМЮвУЧЕНШчЯТЕФвўКЌвђзгЕФаЮЪНЛЏФЃаЭЃЌЪзЯШбЁдёЮЌЪ§ b?n,m ВЂНЋУПИігУЛЇКЭЮяЦЗЖМЕБзїИУЮЌЖШПеМфжаЕФвЛИіЯђСПЁЃЮвУЧНЋгУЛЇ
u ЕФЯђСПБъЪЖЮЊ p_uЁЪR^b, ЮяЦЗ j ЕФЯђСПБъЪЖЮЊ q_jЁЪR^bЃЌетаЉЯђСПЪЧЛљгкЦРЗжОйжЄМЦЫу
R ЕУЕНЕФЃЌМЦЫуЙ§ГЬжаЭЈЙ§ФГжжАьЗЈШУЯђСП b ЕФИіЗжСПЖМЖдгІЕНЩЯУцЫљЪіЕФвЛИівўКЌЮЌЖШЁЃ
вђДЫЃЌгУЛЇКЭЮяЦЗЖМПЩвддкЭЌбљЕФжїЬтЯТНјааБрТыЃЌЭЌЪБЦРЗжПЩвдЭЈЙ§МЦЫуСНИіЯђСПЕФФкЛ§ЃЌМДНЋЯђСПЕФЮЌЖШСНСНЖдгІЯрГЫШЛКѓЧѓКЭЕУЕНЃК
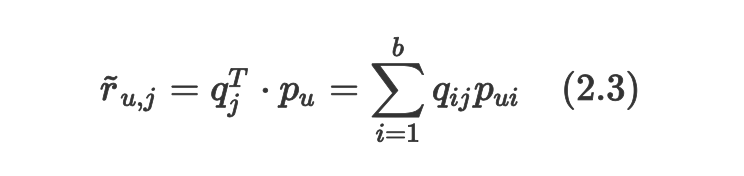
гааэЖрВЛЭЌЕФЗНЗЈРДМЦЫугУЛЇКЭЮяЦЗЕФвўКЌвђзгЯђСП p_u КЭ q_jЃЌзюжБНгЕФЗНЗЈОЭЪЧгУЦцвьжЕЗжНт
(SVD) ЖдЦРЗжОиеѓ R НјааЗжНтЁЃШЛЖјЃЌЛљгкМЦЫуЮШЖЈадКЭИДдгадЕФПМТЧЃЌдкЪЕМљжавЛАуЪЙгУЕќДњЕФЬнЖШЯЙНВгХЛЏЗНЗЈ
[YK09]ЁЃ
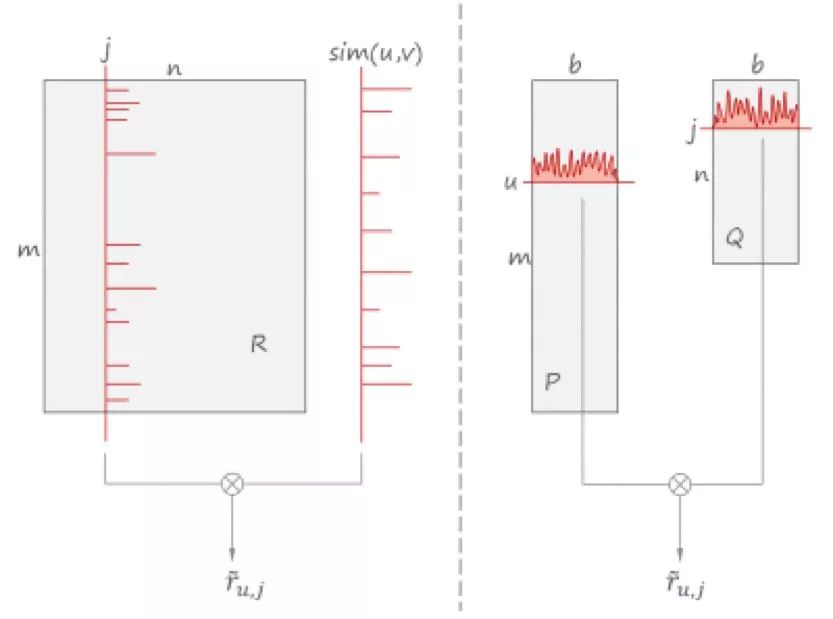
ЯТЭМеЙЪОСЫОэЛ§ЃЈ2.1ЃЉКЭЃЈ2.3ЃЉжЎМфЕФЧјБ№ЁЃзѓБпЖдгкИјЖЈЮяЦЗЕФЯЁЪшЕФЦРЗжЯђСПгыЯЁЪшЖШЯрЫЦЕФИјЖЈгУЛЇзіОэЛ§ЕУЕНЦРЗжЙРМЦЃЛЖјдкгвБпЃЌЦРЗжЪЧЭЈЙ§МЦЫуСНИіНЕЮЌКѓЧвФмСПУмЖШКмКУЕФЯђСПЕФОэЛ§ЕУЕНЕФЁЃ
6.ЖрФПБъ
вдЩЯЬжТлЕФЭЦМіЗНЗЈБОжЪЩЯЖМЪЧгЩвЛИіЕЅвЛФПБъЧ§ЖЏЃЌетвЛФПБъЪЧЬсЙЉзюКУЕФгявхЦЅХфЛђепдЄВтЦЋКУЦРЗжЁЃШЛЖјЃЌЭЦМіОЋЖШВЂВЛЪЧЭЦМіЯЕЭГЩшМЦЕФЮЈвЛПМТЧЃЌСуЪлЩЬПЩФмгааЫШЄЖдзлКЯЖрИігаГхЭЛЕФФПБъдквЛЦ№ИјгУЛЇЬсЙЉЭЦМіЁЃ
Р§ШчЃЌЪГЦЗдгЛѕЩЬПЩФмгааЫШЄЬсЩ§ОпгаНЯЖЬЛѕМмЦкЕФвзИЏЪГЮяЕФЯњСПЃЌЪБЩаЩЬЕъПЩФмЯЃЭћЭЦЙудожњЦЗХЦЛђЕБМОПюЃЌИќЖрЕФСуЪлЩЬПЩвдДгЭЦМіНЯИпРћШѓТЪЕФВњЦЗЛђПМТЧВњЦЗПтДцЫЎЦНБмУтвдБмУтШБЛѕРДЛёЕУИќКУЪевцЁЃ
ЮФЯз [JW10] ЬсГіСЫЖрФПБъЭЦМіЯЕЭГВЂдк LinkedIn[RP12] жазіСЫДѓЙцФЃбщжЄЁЃдк
LinkedIn ЕФР§згжаЃЌ ЦфжївЊЕФФПБъЪЧИјКђбЁШЫЭЦМігявхЩЯЦЅХфЕФЙЄзїЛњЛсЃЌЦфДЮЪЧЯдЪОевЙЄзїЕФааЮЊЁЃ[RP12]
УшЪіСЫИУЗНЗЈЃЌНЋЭЦМіШЮЮёЖЈвхЮЊШчЯТЕФгХЛЏЮЪЬтЃК
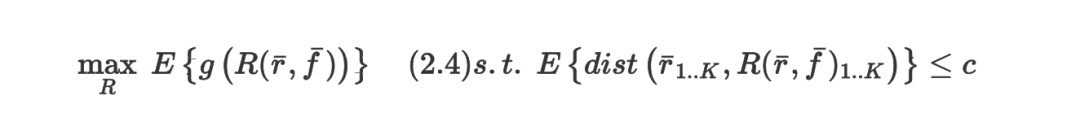
ДЫДІЃК
ЁЅr ЪЧгЩЕзВуЭЦМіЯЕЭГЛљгкгявхЦЅХфКЭЯрЙиадВњЩњЕФдЩњЭЦМіЯђСПЃЌЁЅr жаЕФЕк j ИідЊЫиБэЪОЕФЪЧЕк
j ИіВњЦЗЕФЯрЙиадЗжжЕЃЈЛђХХађЃЉЁЃ
ЁЅf ЪЧЖўМЖЬиеїжЕЯђСПЃЌЁЅf жаЕФЕкИідЊЫиЖдгІЕФЪЧЕк j ИіВњЦЗдкДЮвЊФПБъЩЯЖдгІЕФЗжжЕЁЃР§ШчЃЌетвЛЯђСППЩвдВњЦЗЕФУЋРћТЪЁЃ
R(ЁЄ) ЪЧзщКЯХХађКЏЪ§ЦфзлКЯСЫ ЁЅr КЭ ЁЅf аЮГЩвЛИіаТЕФЮяЦЗХХађЦНКтСЫСНИіФПБъЁЃ
g(ЁЄ) БэЪОЖШСПЭЦМіЯЕЭГадФмЕФећЬхаЇгУКЏЪ§ЁЃ
E{?} ЖдЫљгаЭЦМіаЇЙћЕФЦНОљЁЃ
(ЁЄ)_(1ЁK) БэЪОЕФЪЧЧА K ИіОпгазюИпЗжЪ§ЕФдЊЫиЃЌетРя K ЪЧИјгУЛЇЭЦМіЕФЮяЦЗЪ§ЁЃР§ШчЃЌШчЙћ
ЁЅr жаАќРЈдкВсЕФЫљга n ИіВњЦЗЕФЭЦМіЗжЃЌдђ ЁЅr_(1..K) ЖдгІЕФЪЧ K ИізюжЕЕУЭЦМіЕФВњЦЗЁЃ
dist(ЁЄ) ЪЧЖШСПСНИіЭЦМіЯђСПжЎМфЕФВювьЕФОрРыКЏЪ§ЃЌЖј c ЪЧетвЛВювьЕФЯожЦуажЕЁЃИљОн [RP12]ЃЌ
вЛИіКЯРэЖјЪЕМЪЕФОрРыЖШСПЪЧСНИіЗжжЕЯђСПжБЗНЭМЕФЦНЗНЮѓВюКЭЁЃ
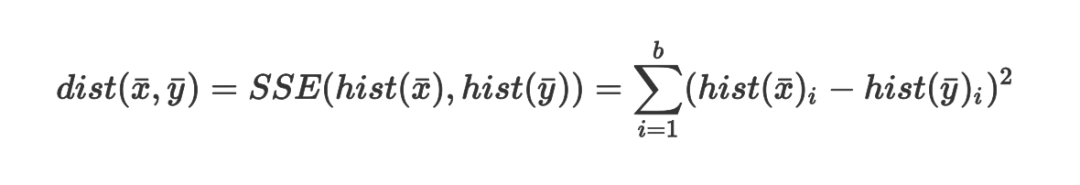
ЩЯЪігХЛЏЮЪЬтЕФжївЊЪТЯюЪЧЪЧдіМгЛьКЯСЫДЮвЊФПБъЕФЯрЙиЖШЗжжЕЕФзлКЯЭЦМіЕФаЇгУЃЌЕЋЪЧЖддЩљЕФЯрЙиадЭЦМіНсЙћКЭзлКЯЭЦМіНсЙћЕФВювьзіГЭЗЃРДБЃжЄВЛЛсЮЊСЫзюЧѓДЮвЊФПБъЖјЭъШЋЮўЩќЯрЙиадЁЃ
КЏЪ§ R(ЁЄ) ЕФЩшМЦашвЊАќРЈПЩЕїећЕФВЮЪ§РДЕїНкСНИіФПБъЕФШЈжиВЂОіЖЈФФИіЪЧжївЊЕФгХЛЏФПБъЃЌетвЛЗНЗЈПЩвджБНгЕФРЉеЙЕНЖргкСНИіФПБъЕФЧщПіЁЃ
ЮвУЧФмЙЛЪЙгУДѓСПЕФР§згРДеЙЪОЩЯЪігХЛЏФЃаЭЪЧПЩвдЪЪХфЕНЪЕМЪЕФЮЪЬтжаШЅЕФЁЃЪзЯШЃЌПМТЧСуЪлЩЬвЊНЋЪеШыФПБъећКЯЕНЭЦМіЗжжЕРяЕФЧщПіЁЃ
ећЬхЕФаЇгУКЏЪ§ПЩвдБЛЦкЭћУЋРћТЪЖЈвхЃЌЩш m(p)ЁЪ[0,1] ЮЊЮяЦЗ p ЕФЙцЗЖЛЏУЋРћТЪЃЌЖјБЛЙКТђЕФИХТЪдђгЩХХађЮЛжУЕФЕЙЪ§БэЪО(МДдкЭЦМіСаБэРяХХађдНЕЭЕФЕФЮяЦЗЃЌЦфзЊЛЏИХТЪдНЕЭЃЉЁЃ
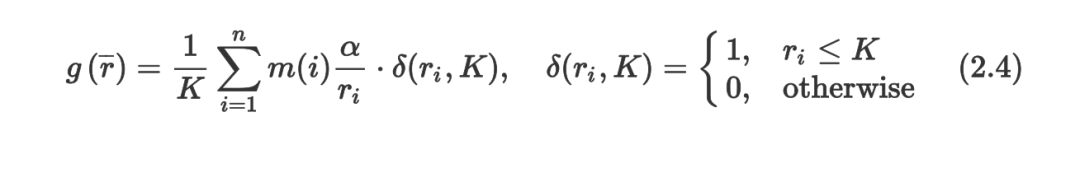
ДЫДІЪЧИХТЪЙцЗЖЛЏГЃЪ§ЁЃзлКЯХХађКЏЪ§ПЩвдБЛЖЈвхЮЊШчЯТЃК
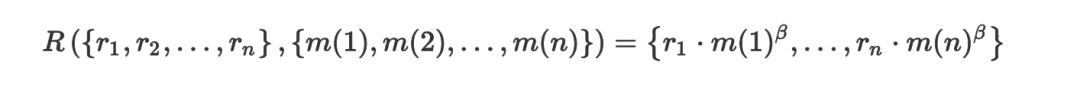
Цфжа ІТ ЪЧвЛИіПижЦЯрЙиадКЭбЁШЁИпУЋРћТЪВњЦЗжЎМфЕФШЈКтЕФВЮЪ§ЃЌетвЛВЮЪ§ОіЖЈСЫгХЛЏЮЪЬтЃЈ2.4ЃЉЕФжївЊФПБъЁЃ
ИљОнДЮвЊФПБъжиаТХХађЕФСэвЛИіР§згЪЧДйЯњЬиЩЋЩЬЦЗЃЌШчДђелВњЦЗЛђвзИЏЛѕЮяЁЃаЇгУКЏЪ§ПЩвджИЖЈЮЊЬибЁВњЦЗдкга
K ИіЭЦМіЯюЕФЭЦМіСаБэжаЕФЦНОљИіЪ§ЁЃ
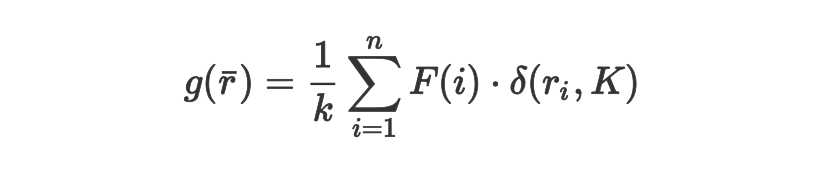
ДЫДІ F(ЁЄ) ЪЧЬибЁБъжОЕБЮяЦЗЪЧЬибЁЪБЮЊ 1ЃЌВЛЪЧдђЮЊ 0ЁЃзлКЯХХађКЏЪ§зщКЯСЫЯрЙиадЗжжЕКЭЬибЁБъжОЃЌЭЈЙ§ВЮЪ§
ІТ РДШЈКтФФИіЪЧжївЊЕФгХЛЏФПБъЁЃ
вдЩЯЕФХХађКЏЪ§ФмЙЛжБНгРЉеЙЕНећКЯЖрИіЗжРыЕФЬиеїЃЌУПИіЬиеїЖдзюжеХХађЗжжЕЕФЙБЯзгШЦфЖдгІЕФШЈКтВЮЪ§ЃЈЫљгаВЮЪ§ашвЊСЊКЯЦ№РДгХЛЏЃЉЃК
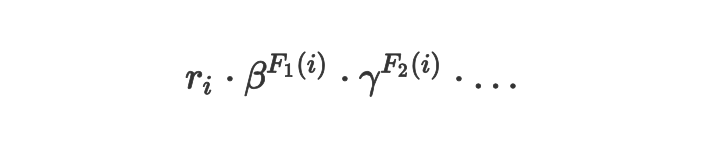
ЙигкЮЪЬтЃЈ2.4ЃЉЕФЪ§жЕгХЛЏЫуЗЈЕФЯИНкПЩвддк [RP12] жаевЕНЁЃ
ЮЪЬт 3ЃК ашЧѓдЄВт
1.ЮЪЬтЖЈвх
СуЪлЩЬЮЊПЭЛЇЬсЙЉвЛзщВњЦЗЃЌЖдИјЖЈВњЦЗЕФашЧѓвРРЕгкаэЖрвђЫиЃЌАќРЈВњЦЗБОЩэЕФЬиадШчМлИёЛђЦЗХЦЃЌЭЌРрВњЦЗОКељЖдЪжЕФМлИёЁЂ
ДйЯњЛюЖЏЃЌЩѕжСЪЧЬьЦјЁЃ
ИУЮЪЬтЕФФПБъЪЧећКЯетаЉвђЫиРДЙЙНЈашЧѓФЃаЭВЂЧвдЪаэНјааМйЩшЗжЮівддЄВтЖдМлИёБфЛЏЕФЯьгІЃЌЦЗРрЕФРЉГфКЭМѕЩйЃЌМЦЫузюМбПтДцЫЎЦНЃЌВЂЗжХфЛѕМмПеМфЕЅЮЛЁЃ
2.гІгУ
дкБОНкжаЮвУЧНЋЬжТлашЧѓдЄВтКЫаФЮЪЬтЁЃетвЛЮЪЬтПЩвдБЛПМТЧЮЊвЛИіНЈдьФЃПщЃЌИУФЃПщвЊЧѓЖдгАЯьашЧѓЕФааЮЊЛђепПтДцЫЎЦНЕФЯожЦНЈФЃЃК
МлИёгХЛЏЃЌДйЯњЛюЖЏМЦЛЎЃЌ вдМАЖЈЯђелПлЁЃ
ЦЗРрЙмРэКЭМЦЛЎЁЃ
ПтДцЫЎЦНгХЛЏЁЃ
ашЧѓдЄВтФЃаЭЭЈГЃгІгУдкЪаГЁгЊЯњЛюЖЏЩшМЦжаЃЌвђЮЊетаЉФЃаЭФмЙЛНтЪЭашЧѓЛиЙщСПЕФгАЯьЁЃР§ШчЃЌвЛИіашЧѓдЄВтФЃаЭПЩвдНвЪОФГвЛВњЦЗЕФМлИёУєИаад(ЕБМлИёБфЛЏЪБашЧѓгаЖрЩйБфЛЏ)гыАќзАДѓаЁКЭКЭЯњЪлЧјгђЕФШЫПкЬиадНєУмЯрЙиЃЌетОЭАЕЪОСЫПЩвддкВЛЭЌЕФЩЬЕъЪЙгУВЛЭЌЕФМлИёВЂЖдВЛЭЌАќзАЕФВњЦЗЩшЖЈВЛЭЌЕФЕЅЮЛУЋРћТЪЁЃ
ЮвУЧНЋдкКѓУцЕФеТНкжаАбашЧѓдЄВтФЃаЭгУдкМлИёгХЛЏКЭЦЗРрМЦЛЎЮЪЬтЩЯЁЃ
3.НтОіЗНАИ
ашЧѓдЄВтПЩвдБЛШЯЮЊЪЧвЛИіЯрЖдМђЕЅЕФЪ§ОнЭкОђЮЪЬтЃЌжЛашвЊНЈСЂвЛИіЛиЙщФЃаЭВЂгУРњЪЗЪ§ОнНјааЦРЙРЁЃШЛЖјЃЌЩшМЦЛиЙщФЃаЭдђВЛЪЧФЧУДМђЕЅЕФЪТЧщЃЌвђЮЊашЧѓЪмЕНКмЖргазХИДдгвРРЕЙиЯЕЕФвђЫиЕФгАЯьЁЃ
дкБОНкжаЃЌЮвУЧНЋбаОПЮФЯз [KOK07] ЮЊ Albert HeijnЃЈвЛМвКЩРМЕФСЌЫјГЌЪаЃЉЙЙНЈВЂбщжЄЕФЛиЙщФЃаЭЁЃетвЛФЃаЭЛљгкдчЦкЕФгЊЯњбаОПШч
[BG92]ЃЌвдМАЪБЩаСуЪлЩЬШч RueLaLa[JH14] КЭ Zara[CA12] ЕФЪЕМљЃЌетаЉЪЕМљжагІгУСЫЯрЫЦЕФФЃаЭЁЃ
ШЛЖјЃЌживЊЕФЪЧвЊРэНтВЛЭЌЕФгХЛЏЮЪЬташвЊВЛЭЌЕФашЧѓдЄВтФЃаЭВЂЧвМИКѕВЛПЩФмЙЙНЈЭЈгУЕФашЧѓФЃаЭРДећКЯИїжжВЛЭЌЕФашЧѓгАЯьвђзгЁЃ
ЮвУЧДгвдЯТЖдвЛИјЖЈВњЦЗЕФашЧѓФЃаЭПЊЪМЃК
ДЫДІЃК
V ЪЧдкИјЖЈЪБМфДАПкФкЙЫПЭЕНЗУЩЬЕъЕФЪ§СПЃЌР§ШчвЛЬьЁЃ
Pr(purchase | visit) ЪЧПЭЛЇдкЙфЩЬЕъЦкМфЙКТђШЮвтЩЬЦЗЕФИХТЪЁЃ
Pr(j | purchase) ЪЧЕБПЭЛЇЗЂЩњЙКТђЪБдкЫљгаПЩбЁЯюжабЁдёВњЦЗЕФИХТЪЁЃ
E{Q | jЃЛpurchase} ЪЧЕБПЭЛЇбЁдёСЫВњЦЗВЂЙКТђЪБЙКТђЪ§СП(ЕЅЮЛЪ§СП)ЕФЪ§бЇЦкЭћЁЃ
ЙЋЪНЃЈ3.1ЃЉжаЕФЫљгавђЫиЖМПЩвдгУЕъЦЬЕФРњЪЗНЛвзЪ§ОнРДЙРМЦЁЃашЧѓЭЈГЃгыШеЦкЃЈжмМИЁЂНкМйШеЕШЃЉКЭЕъЦЬЃЈДѓаЁЁЂСкНќЧјгђЕФШЫПкЭГМЦЧщПіЕШЕШЃЉЯрЙиЃЌЫљвдЮвУЧв§ШыЯТБъ
t КЭ h РДЗжБ№БэЪОШеЦкКЭЕъЦЬЃЌЖјЙРМЦЕФашЧѓОЭЪЧетаЉВЮЪ§ЕФКЏЪ§ЁЃ
СэЭтЃЌЩЬЕъЪєадЃЌШчДѓаЁЁЂЮЛжУКЭЦНОљЯћЗбепЕФЪеШыПЩвдФЩШыФЃаЭзїЮЊЛиЙщЁЃИљОн [KOK07]ЃЌЩЬЕъЗУПЭЕФЪ§СППЩвдНЈФЃШчЯТЃК
ДЫДІ Tt ЪЧЬьЦјЮТЖШЃЌWt ЪЧЬьЦјЪцЪЪЖШжИЪ§(ЪЊЖШЁЂвѕЧчЕШ)ЃЌBti КЭ Eti ЗжБ№ЪЧБэЪОвЛЬьЪЧаЧЦкМИКЭЙЋЙВМйЦкЕФ
0/1 бЦБфСПЃЌH ЪЧЙЋЙВМйЦкЕФЬьЪ§ЃЌЖј ІС ЪЧЛиЙщЯЕЪ§ЁЃ
ЙКТђЪТМўЪЧвЛИіЖўжЕБфСПЃЈЙКТђ/УЛгаЙКТђЃЉЃЌЫљвдЮвУЧПЩвдгУвЛИіБъзМЕФНЈФЃЗНЗЈ ЈC НЋЙКТђИХТЪгУвЛИі
Sigmoid КЏЪ§РДБэДяВЂДгЪ§ОнЙРМЦжИЪ§ВЮЪ§ЃК
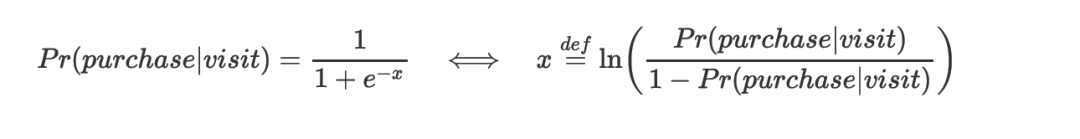
дђ x ЕФЛиЙщФЃЪЧЃК

ДЫДІ Ajht ЪЧбЦБфСПЃЌВњЦЗ j дкДйЯњЪБжЕЮЊ 1 ЗёдђЮЊ 0ЃЌNh ЪЧЫљгаВњЦЗЕФЪ§СПЃЌЖј ІТ4
ЖдгІЕФЪЧДйЯњВњЦЗеМећЬхЯњЪлВњЦЗжаЕФАйЗжБШЁЃ
Pr(j | purchase) ЕФЙРМЦдђИќЮЊМЌЪжвЛаЉЁЃПЭЛЇбЁдёНЈФЃдкБОжЪЩЯЪЧМЦСПОМУЮЪЬтЃЌЪЧвЛИіЬиБ№ЕФОМУбЇбаОПЗжжЇЁЊЁЊбЁдёНЈФЃРэТлЁЃбЁдёНЈФЃРэТлжЄУїСЫЖрЯю
logit ФЃаЭЃЈMNLЃЉЪЧгааЇЕФЗНЗЈРДЖдЖрИібЁЯюжабЁдёЕФИХТЪНјааНЈФЃЁЃ
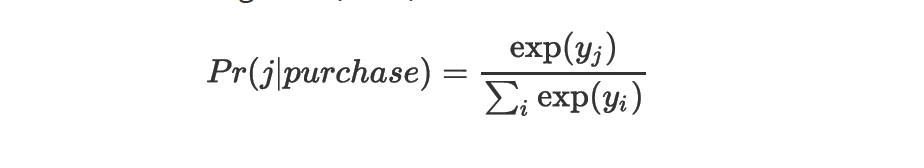
ДЫДІЛс i ЕќДњБщРњЫљгаВњЦЗЃЌyj ЪЧвЛИіВЮЪ§БфСПЁЃРрЫЦгкЙКТђЪТМўЕФИХТЪЃЌЮвУЧЖдВЮЪ§ yj НЈСЂСЫвЛИіЛиЙщФЃаЭЃК
ДЫДІЯЕЪ§ ІЃn+1 КЭ Ъ§ ІЃn+2 гЩЫљгаВњЦЗЙВЯэЃЌRjht КЭ R ЗжБ№ЪЧЕЅИіВњЦЗЕФМлИёКЭВњЦЗЕФЦНОљМлИёЃЌЖј
Ajht КЭ A ЪЧДйЯњбЦБфСПКЭЦНОљДйЯњТЪЃЌШчЩЯУцЖдЙКТђПЩФмадЛиЙщФЃаЭУшЪіЕФФЧбљЁЃ
зюКѓЃЌЕЅЮЛВњЦЗЕФЦНОљЯњЪлЪ§СППЩвдНЈФЃШчЯТЃК
ЭЈЙ§НЋЩЯЪіФЃаЭДњШыИљБэДяЪНЃЈ3.1ЃЉЃЌПЩвдЕУЕНЭъШЋЬиБ№ЕФашЧѓдЄВтФЃаЭЁЃ етвЛФЃаЭПЩвдИљОнСуЪлЩЬЕФвЕЮёгУР§РДЕїећЃЌетаЉЬјжЁИіПЩвдЭЈЙ§діМгИќЖрЕФНтЪЭадБфСПШчгЊЯњЪТМўРДЭъГЩЁЃ
|









