| 编辑推荐: |
| 本文来自于csdn,文中讲解了一些数据挖掘的理论,概念,及相关实例。以图表,图片的形式展示,可供大家直观的感受数据挖掘。 |
|
互联网的迅猛发展,催生了数据的爆炸式增长。面对海量的数据,如何挖掘数据的价值,成为一个越来越重要的问题。本文首先介绍数据挖掘的基本内容,然后按照数据挖掘基本的处理流程,以性别预测实例来讲解一个具体的数据挖掘任务是如何实现的。
数据挖掘的基本内容
首先,对于数据挖掘的概念,目前比较广泛认可的一种解释如下:
Data mining is the use of efficient techniques for
the analysis of very large collections of data and
the extraction of useful and possibly unexpected patterns
in data.
数据挖掘是一种通过分析海量数据,从数据中提取潜在的但是非常有用的模式的技术。
主要的数据挖掘任务
数据挖掘任务可以分为预测性任务和描述性任务。预测性任务主要是预测可能出现的情况;描述性任务则是发现一些人类可以解释的模式或规律。数据挖掘中比较常见的任务包括分类、聚类、关联规则挖掘、时间序列挖掘、回归等,其中分类、回归属于预测性任务,聚类、关联规则挖掘、时间序列分析等则都是解释性任务。
按照数据挖掘的基本流程,来谈谈分类问题
在简单介绍了数据挖掘的基本内容后,我们来切入主题。以数据挖掘的流程为主线,穿插性别预测的实例,来讲解分类问题。根据经典教科书和实际工作经验来看,数据挖掘的基本流程主要包括五部分,首先是明确问题,第二是对数据进行预处理,第三是对数据进行特征工程,转化为问题所需要的特征,第四是根据问题的评价标准选择最优的模型和算法,最后将训练的模型用于实际生产,产出所需结果(如图1所示)。
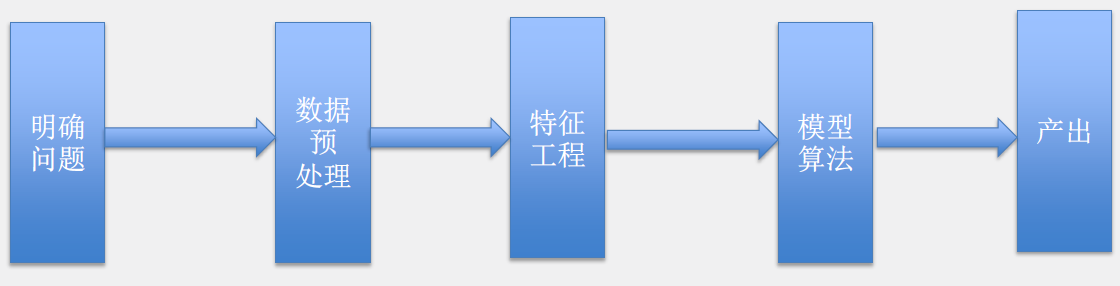
图1 数据挖掘的基本流程
下面我们分别介绍各环节涉及的主要内容:
1.明确问题和了解数据
这一环节最重要的是需求和数据的匹配。首先需要明确需求,有着怎样的需求?是需要做分类、聚类、推荐还是其他?实际数据是否支持该需求?比如,分类问题需要有或者可以构造出training
set,如果没有training set,就没有办法按照分类问题来解决。此外,数据的规模、重要feature的覆盖度等,也是需要特别考虑的问题。
2.数据预处理
1)数据集成,数据冗余,数值冲突
数据挖掘中准备数据的时候,需要尽可能地将相关数据集成在一起。如果集成的数据中,有两列或多列值一样,则不可避免地会产生数值冲突或数据冗余,可能需要根据数据的质量来决定保留冲突中的哪一列。
2)数据采样
一般来说,有效的采样方式如下:如果样本是有代表性的,则使用样本数据和使用整个数据集的效果几乎是一样的。抽样方法有很多,需要考虑是有放回的采样,还是无放回的采样,以及具体选择哪种采样方式。
3)数据清洗、缺失值处理与噪声数据
现实世界中的数据,是真实的数据,不可避免地会存在各种各样的异常情况。比如某列的值缺失,或者某列的值是异常的,所以,我们需要在数据预处理阶段进行数据清洗,来减少噪音数据对模型训练和预测结果的影响。
3.特征工程
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。下面的观点说明了特征工程的特点和重要性。
Feature engineering is another topic which doesn’t
seem to merit any review papers or books, or even
chapters in books, but it is absolutely vital to ML
success. […] Much of the success of machine learning
is actually success in engineering features that a
learner can understand.
— Scott Locklin, in “Neglected machine learning ideas”
1)特征:对所需解决问题有用的属性
特征是对你所需解决问题有用或者有意义的属性。比如,在计算机视觉领域,图片作为研究对象,可能图片中的一个线条就是一个特征;在自然语言处理领域中,研究对象是文档,文档中的一个词语的出现次数就是一个特征;在语音识别领域中,研究对象是一段话,phoneme(音位)可能就是一个特征。
2)特征的提取、选择和构造
既然特征是对我们所解决的问题最有用的属性。首先我们需要处理的是根据原始数据抽取出所需要的特征。亟需注意的是,并不是所有的特征对所解决的问题产生的影响一样大,有些特征可能对问题产生特别大的影响,但有些则可能影响甚微,和所解决的问题不相关的特征需要被剔除掉。因此,我们需要针对所解决的问题选择最有用的特征集合,一般可以通过相关系数等方式来计算特征的重要性。当然,有些模型本身会输出feature重要性,如Random
Forest等算法。而对于图片、音频等原始数据形态特别大的对象,则可能需要采用像PCA这样的自动降维技术。另外,还可能需要本人对数据和所需解决的问题有深入的理解,能够通过特征组合等方法构造出新的特征,这也正是特征工程被称之为是一门艺术的原因之一。
实例讲解(一)
接下来,我们通过一个性别预测的实例来说明数据挖掘处理流程中的“明确问题”、“数据预处理”和“特征工程”三个部分。
假设我们有如下两种数据,想根据数据训练一个预测用户性别的模型。
数据1: 用户使用App的行为数据;
数据2: 用户浏览网页的行为数据;
第一步:明确问题
首先明确该问题属于数据挖掘常见问题中的哪一类, 是分类、聚类,推荐还是其他?假设本实例数据有部分数据带有男女性别,则该问题为分类问题;
数据集是否够大?我们需要足够大的数据来训练模型,如果数据集不够大,那么所训练的模型和真实情况偏差会比较大;
数据是否满足所解决问题的假设?统计发现男人和女人使用的App不太一致,浏览网页的内容也不太一致,则说明我们通过数据可以提取出对预测性别有用的特征,来帮助解决问题。如果根据数据提取不出有用的特征,那么针对当前数据,问题是没法处理的。
第二步:数据预处理
实际工作中,在数据预处理之前需要确定整个项目的编程语言(如Python、Java、 Scala)和开发工具(如Pig、Hive、Spark)。通常而言,编程语言和开发工具的选择都依赖于所处的数据平台环境;
选取多少数据做模型训练?这是常说的数据采样问题。一般认为采样数据量越大,对所解决的任务帮助越大,但是数据量越大,计算代价也越大,因此,需要在解决问题的效果和计算代价之间折中一下;
把所有相关的数据聚合在一起,如果有相同字段则存在数据冗余的问题,需要根据数据的质量剔除掉冗余的数据;数据中可能存在异常值,则需要过滤掉;数据中可能有的值有缺失,则需要填充默认值。
数据预处理后可能的结果(如表1、表2所示):
表1 数据1预处理后结果
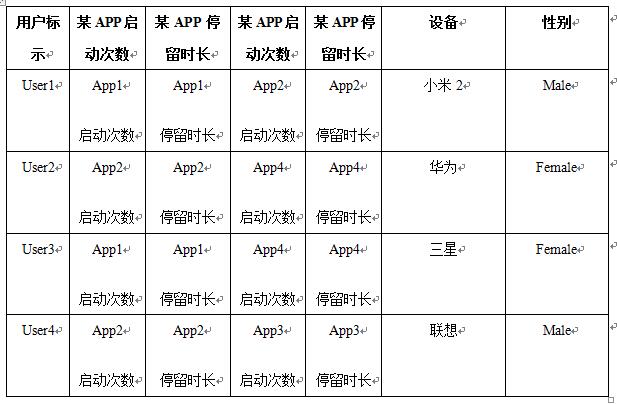
表2 数据2预处理后结果

第三步:特征工程
由于数据1和数据2的类型不太一样,所以进行特征工程时,所采用的方法也不太一样,下面分别介绍一下:
数据1的特征工程
数据1的单个特征的分析主要包括以下内容:
数值型特征的处理,比如App的启动次数是个连续值,可以按照低、中、高三个档次将启动次数分段成离散值;
类别型特征的处理,比如用户使用的设备是三星或者联想,这是一个类别特征,可以采用0-1编码来处理;
需要考虑特征是否需要归一化。
数据1的多个特征的分析主要包括以下内容:
使用的设备类型是否决定了性别?需要做相关性分析,通常计算相关系数;
App的启动次数和停留时长是否完全正相关,结果表明特别相关,则说明App的停留时长是无用特征,将App的停留时长这个特征过滤掉;
如果特征太多,可能需要做降维处理。
2.数据2的特征工程
数据2是典型的文本数据,文本数据常用的处理步骤包含以下几个部分:
网页 → 分词 → 去停用词 → 向量化
分词。可以采用Jieba分词(Python库)或张华平老师的ICTCLAS;
去除停用词。停用词表除了加入常规的停用词外,还可以将DF(Document Frequency)比较高的词加入停用词表,作为领域停用词;
向量化。一般是将文本转化为TF或TF-IDF向量。
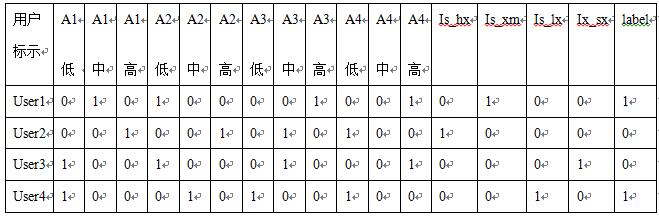
特征工程后数据1的结果(如表3所示,A1低表示启动App1的次数比较低,以此类推,is_hx表示设备是否是华为,Label为1表示Male)。
表3 数据1特征工程后结果
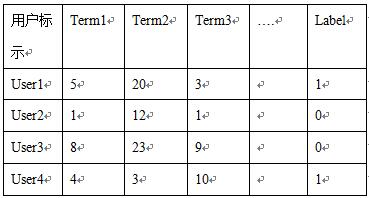
特征工程后数据2的结果(如表4所示,term1=5表示user1浏览的网页中出现词1的频率,以此类推)。
表4 数据2特征工程后结果
第四步:算法和模型
做完特征工程后,下一步就是选择合适的模型和算法。算法和模型的选择主要考虑一下几个方面:
训练集的大小;
特征的维度大小;
所解决问题是否是线性可分的;
所有的特征是独立的吗?
需要不需要考虑过拟合的问题;
对性能有哪些要求?
上面中提到的很多问题没法直接回答,可能我们还是不知道该选择哪种模型和算法,但是奥卡姆剃刀原理给出了模型和算法的选择方法:
Occam’s Razor principle: use the least complicated
algorithm that can address your needs and only go
for something more complicated if strictly necessary.
业界比较通用的算法选择一般是这样的规律:如果LR可以,则使用LR;如果LR不适合,则选择Ensemble的方式;如果Ensemble方式不适合,则考虑是否尝试Deep
Learning。下面主要介绍一下LR算法和Ensemble方法的相关内容。
LR算法(Logistic Regression,逻辑回归算法)
只要认为问题是线性可分的,就可采用LR,通过特征工程将一些非线性特征转化为线性特征。 模型比较抗噪,而且可以通过L1、L2范数来做参数选择。LR可以应用于数据特别大的场景,因为它的算法效率特别高,且很容易分布式实现。
区别于其他大多数模型,LR比较特别的一点是结果可以解释为概率,能将问题转为排序问题而不是分类问题。
Ensemble方法(组合方法)
组合方法的原理主要是根据training set训练多个分类器,然后综合多个分类器的结果,做出预测(如图2所示)。
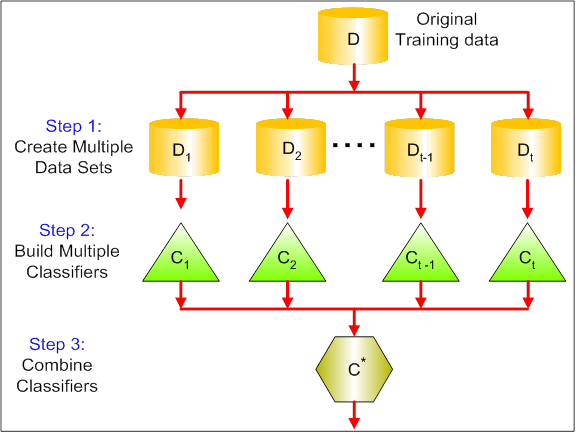
图2 组合方法的基本流程
组合方式主要分为Bagging和Boosting。Bagging是Bootstrap Aggregating的缩写,基本原理是让学习算法训练多轮,每轮的训练集由从初始的训练集中随机取出的n个训练样本组成(有放回的随机抽样),训练之后可得到一个预测函数集合,通过投票方式决定预测结果。
而Boosting中主要的是AdaBoost(Adaptive Boosting)。基本原理是初始化时对每一个训练样本赋相等的权重1/n,然后用学习算法对训练集训练多轮,每轮结束后,对训练失败的训练样本赋以较大的权重。也就是让学习算法在后续的学习中集中对比较难的训练样本进行学习,从而得到一个预测函数集合。每个预测函数都有一定的权重,预测效果好的预测函数权重较大,反之较小,最终通过有权重的投票方式来决定预测结果。
Bagging和Boosting的主要区别如下:
取样方式不同。Bagging采用均匀取样,而Boosting根据错误率来取样,因此理论上来讲Boosting的分类精度要优于Bagging;
训练集的选择方式不同。Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boostng的各轮训练集的选择与前面的学习结果有关;
预测函数不同。Bagging的各预测函数没有权重,而Boosting是有权重的。Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成。
对于像神经网络这样极其耗时的学习方法,Bagging可通过并行训练节省大量时间开销。Bagging和Boosting都可以有效地提高分类的准确性。在大多数数据集中,Boosting的准确性比Bagging要高。
分类算法的评价
上一部分介绍了常用的模型和算法,不同的算法在不同的数据集上会产生不同的效果,我们需要量化算法的好坏,这就是分类算法的评价。在本文中,笔者将主要介绍一下混淆矩阵和主要的评价指标。
1.混淆矩阵(如图3所示)
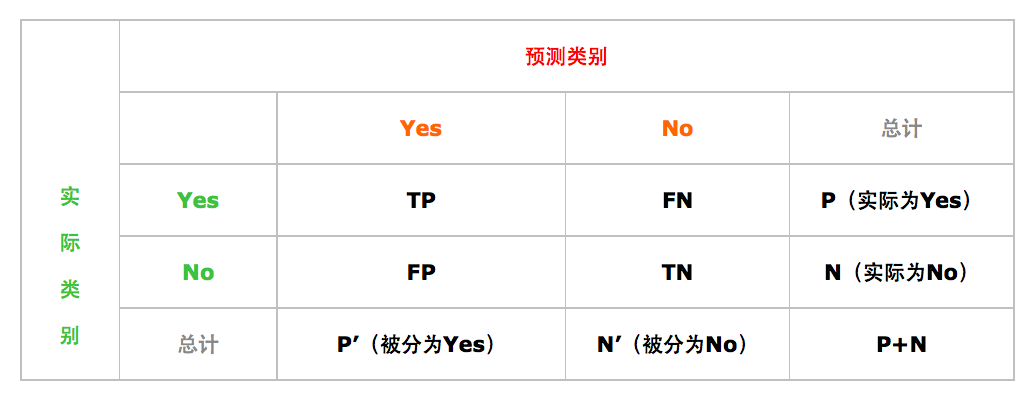
图3 混淆矩阵
1)True positives(TP):即实际为正例且被分类器划分为正例的样本数;
2)False positives(FP):即实际为负例但被分类器划分为正例的样本数;
3)False negatives(FN):即实际为正例但被分类器划分为负例的样本数;
4)True negatives(TN):即实际为负例且被分类器划分为负例的样本数。
2.主要的评价指标
1)准确率accuracy=(TP+TN)/(P+N)。这个很容易理解,就是被分对的样本数除以所有的样本数。通常来说,准确率越高,分类器越好;
2)召回率recall=TP/(TP+FN)。召回率是覆盖面的度量,度量有多少个正例被分为正例。
3)ROC和AUC。
实例讲解(二)
实例(一)产出的特征数据,经过“模型和算法”以及“算法的评价”两部分所涉及的代码实例如图4所示。
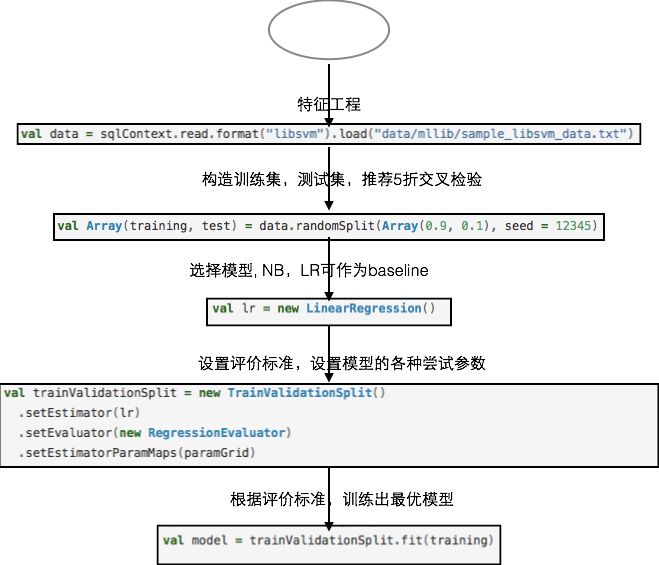
图4 模型训练示例代码
总结
本文以数据挖掘的基本处理流程为主线,以性别预测为具体实例,介绍了处理一个数据挖掘的分类问题所涉及的方方面面。对于一个数据挖掘问题,首先要明确问题,确定已有的数据是否能够解决所需要解决的问题,然后就是数据预处理和特征工程阶段,这往往是在实际工程中最耗时、最麻烦的阶段。经过特征工程后,需要选择合适的模型进行训练,并且根据评价标准选择最优模型和最优参数,
最后根据最优模型对未知数据进行预测,产出结果。希望本文的内容对大家有所帮助。 |








