| БрМЭЦМі: |
БОЮФНЋЯъЯИНщЩмЪ§ОнВжПтЮЌЖШНЈФЃММЪѕЃЌВЂжиЕуЬжТлШ§жжЛљгкERНЈФЃ/ЙиЯЕНЈФЃ/ЮЌЖШНЈФЃЕФЪ§ОнВжПтзмЬхНЈФЃЬхЯЕЃКЙцЗЖЛЏЪ§ОнВжПтЃЌЮЌЖШНЈФЃЪ§ОнВжПтЃЌвдМАЖРСЂЪ§ОнМЏЪаЁЃЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздcnblogsЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
ЧАбд
Ъ§ОнВжПтНЈФЃАќКЌСЫМИжжЪ§ОнНЈФЃММЪѕЃЌГ§СЫжЎЧАдкЪ§ОнПтЯЕСажаНщЩмЙ§ЕФERНЈФЃКЭЙиЯЕНЈФЃЃЌЛЙАќРЈзЈУХеыЖдЪ§ОнВжПтЕФЮЌЖШНЈФЃММЪѕЁЃ
ЮЌЖШНЈФЃЕФЛљБОИХФю
ЮЌЖШНЈФЃ(dimensional modeling)ЪЧзЈУХгУгкЗжЮіаЭЪ§ОнПтЁЂЪ§ОнВжПтЁЂЪ§ОнМЏЪаНЈФЃЕФЗНЗЈЁЃ
ЫќБОЩэЪєгквЛжжЙиЯЕНЈФЃЗНЗЈЃЌЕЋКЭжЎЧАдкВйзїаЭЪ§ОнПтжаНщЩмЕФЙиЯЕНЈФЃЗНЗЈЯрБШдіМгСЫСНИіИХФюЃК
1. ЮЌЖШБэ(dimension)
БэЪОЖдЗжЮіжїЬтЫљЪєРраЭЕФУшЪіЁЃБШШч"зђЬьдчЩЯеХШ§дкОЉЖЋЛЈЗб200дЊЙКТђСЫвЛИіЦЄАќ"ЁЃФЧУДвдЙКТђЮЊжїЬтНјааЗжЮіЃЌПЩДгетЖЮаХЯЂжаЬсШЁШ§ИіЮЌЖШЃКЪБМфЮЌЖШ(зђЬьдчЩЯ)ЃЌЕиЕуЮЌЖШ(ОЉЖЋ), ЩЬЦЗЮЌЖШ(ЦЄАќ)ЁЃЭЈГЃРДЫЕЮЌЖШБэаХЯЂБШНЯЙЬЖЈЃЌЧвЪ§ОнСПаЁЁЃ
2. ЪТЪЕБэ(fact table)
БэЪОЖдЗжЮіжїЬтЕФЖШСПЁЃБШШчЩЯУцФЧИіР§згжаЃЌ200дЊОЭЪЧЪТЪЕаХЯЂЁЃЪТЪЕБэАќКЌСЫгыИїЮЌЖШБэЯрЙиСЊЕФЭтТыЃЌВЂЭЈЙ§JOINЗНЪНгыЮЌЖШБэЙиСЊЁЃЪТЪЕБэЕФЖШСПЭЈГЃЪЧЪ§жЕРраЭЃЌЧвМЧТМЪ§ЛсВЛЖЯдіМгЃЌБэЙцФЃбИЫйдіГЄЁЃ
зЂЃКдкЪ§ОнВжПтжаВЛашвЊбЯИёзёЪиЙцЗЖЛЏЩшМЦддђ(ОпЬхдвђЧыПДЩЯЦЊ)ЁЃБОЮФЪОР§жаЕФжїТыЃЌЭтТыОљжЛБэЪОвЛжжЖдгІЙиЯЕЃЌДЫДІЬиБ№ЫЕУїЁЃ
ЮЌЖШНЈФЃЕФШ§жжФЃЪН
1. аЧаЮФЃЪН
аЧаЮФЃЪН(Star Schema)ЪЧзюГЃгУЕФЮЌЖШНЈФЃЗНЪНЃЌЯТЭМеЙЪОСЫЪЙгУаЧаЮФЃЪННјааЮЌЖШНЈФЃЕФЙиЯЕНсЙЙЃК
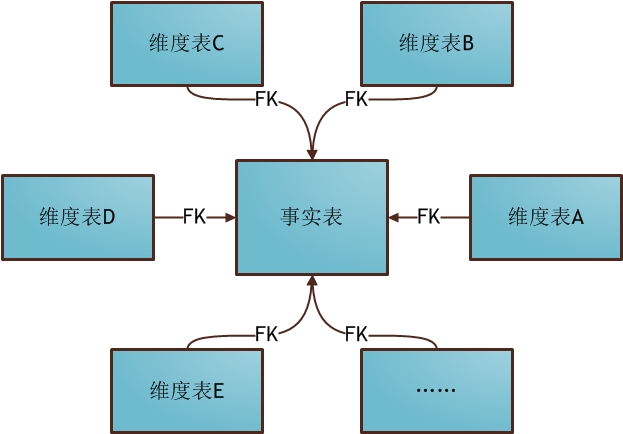
ПЩвдПДГіЃЌаЧаЮФЃЪНЕФЮЌЖШНЈФЃгЩвЛИіЪТЪЕБэКЭвЛзщЮЌБэГЩЃЌЧвОпгавдЯТЬиЕуЃК
a. ЮЌБэжЛКЭЪТЪЕБэЙиСЊЃЌЮЌБэжЎМфУЛгаЙиСЊЃЛ
b. УПИіЮЌБэЕФжїТыЮЊЕЅСаЃЌЧвИУжїТыЗХжУдкЪТЪЕБэжаЃЌзїЮЊСНБпСЌНгЕФЭтТыЃЛ
c. вдЪТЪЕБэЮЊКЫаФЃЌЮЌБэЮЇШЦКЫаФГЪаЧаЮЗжВМЃЛ
2. бЉЛЈФЃЪН
бЉЛЈФЃЪН(Snowflake Schema)ЪЧЖдаЧаЮФЃЪНЕФРЉеЙЃЌУПИіЮЌБэПЩМЬајЯђЭтСЌНгЖрИізгЮЌБэЁЃЯТЭМЮЊЪЙгУбЉЛЈФЃЪННјааЮЌЖШНЈФЃЕФЙиЯЕНсЙЙЃК
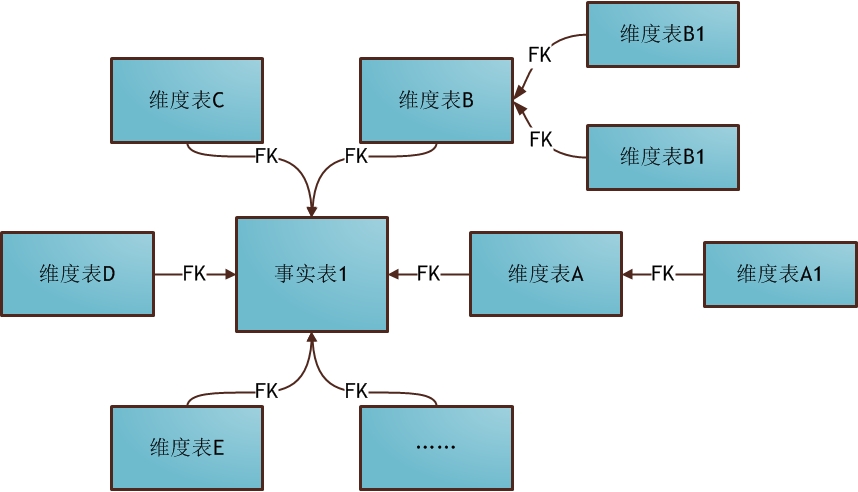
аЧаЮФЃЪНжаЕФЮЌБэЯрЖдбЉЛЈФЃЪНРДЫЕвЊДѓЃЌЖјЧвВЛТњзуЙцЗЖЛЏЩшМЦЁЃбЉЛЈФЃаЭЯрЕБгкНЋаЧаЮФЃЪНЕФДѓЮЌБэВ№ЗжГЩаЁЮЌБэЃЌТњзуСЫЙцЗЖЛЏЩшМЦЁЃШЛЖјетжжФЃЪНдкЪЕМЪгІгУжаКмЩйМћЃЌвђЮЊетбљзіЛсЕМжТПЊЗЂФбЖШдіДѓЃЌЖјЪ§ОнШпгрЮЪЬтдкЪ§ОнВжПтРяВЂВЛбЯжи?/p>?
3. аЧзљФЃЪН
аЧзљФЃЪН(Fact Constellations Schema)вВЪЧаЧаЭФЃЪНЕФРЉеЙЁЃЛљгкетжжЫМЯыОЭгаСЫаЧзљФЃЪНЃК
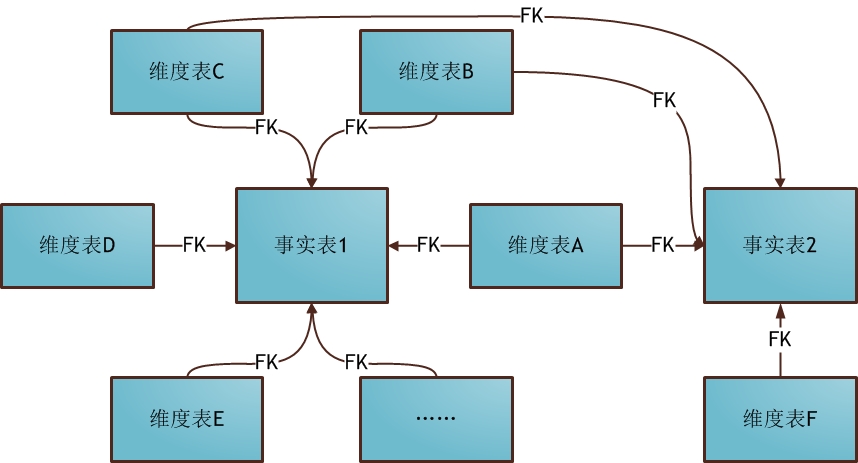
ЧАУцНщЩмЕФСНжжЮЌЖШНЈФЃЗНЗЈЖМЪЧЖрЮЌБэЖдгІЕЅЪТЪЕБэЃЌЕЋдкКмЖрЪБКђЮЌЖШПеМфФкЕФЪТЪЕБэВЛжЙвЛИіЃЌЖјвЛИіЮЌБэвВПЩФмБЛЖрИіЪТЪЕБэгУЕНЁЃдквЕЮёЗЂеЙКѓЦкЃЌОјДѓВПЗжЮЌЖШНЈФЃЖМВЩгУЕФЪЧаЧзљФЃЪНЁЃ
4. Ш§жжФЃЪНЖдБШ
ЙщФЩвЛЯТЃЌаЧаЮФЃЪН/бЉЛЈФЃЪН/аЧзљФЃЪНЕФЙиЯЕШчЯТЭМЫљЪОЃК
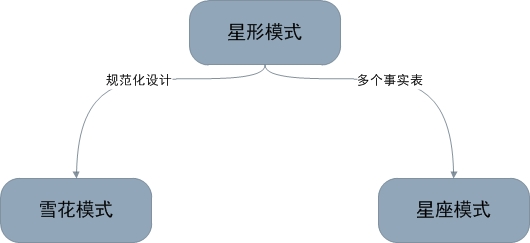
бЉЛЈФЃЪНЪЧНЋаЧаЭФЃЪНЕФЮЌБэНјвЛВНЛЎЗжЃЌЪЙИїЮЌБэОљТњзуЙцЗЖЛЏЩшМЦЁЃЖјаЧзљФЃЪНдђЪЧдЪаэаЧаЮФЃЪНжаГіЯжЖрИіЪТЪЕБэЁЃБОЮФКѓУцВПЗжНЋОпЬхНВЕНетМИжжФЃЪНЕФЪЙгУЃЌЧыЖСепНсКЯЪЕР§ЬхЛсЁЃ
ЪЕР§ЃКСуЪлЙЋЫОЯњЪлжїЬтЕФЮЌЖШНЈФЃ
дкНјааЮЌЖШНЈФЃЧАЃЌЪзЯШвЊСЫНтгУЛЇашЧѓЁЃЖјБЪепдкЪ§ОнПтЯЕСаЕФЕквЛЦЊОЭНВЙ§ЃЌERНЈФЃЪЧЕБЧАЪеМЏКЭПЩЪгЛЏашЧѓЕФзюМбММЪѕЁЃвђДЫМйЖЈКЭФГСуЪлЙЋЫОНјааЖрДЮашЧѓPKКѓЃЌЕУЕНвдЯТERЭМЃК
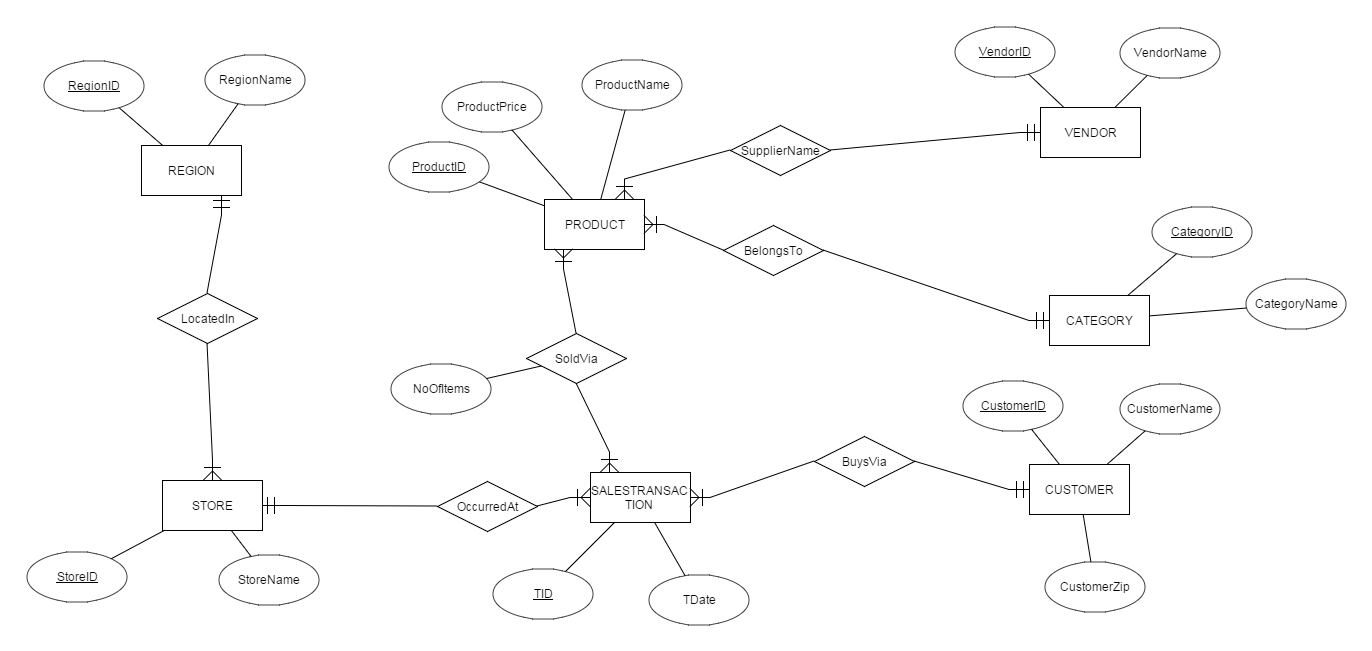
ЫцКѓПЩРћгУНЈФЃЙЄОпНЋERЭМжБНггГЩфЕНЙиЯЕЭМЃК
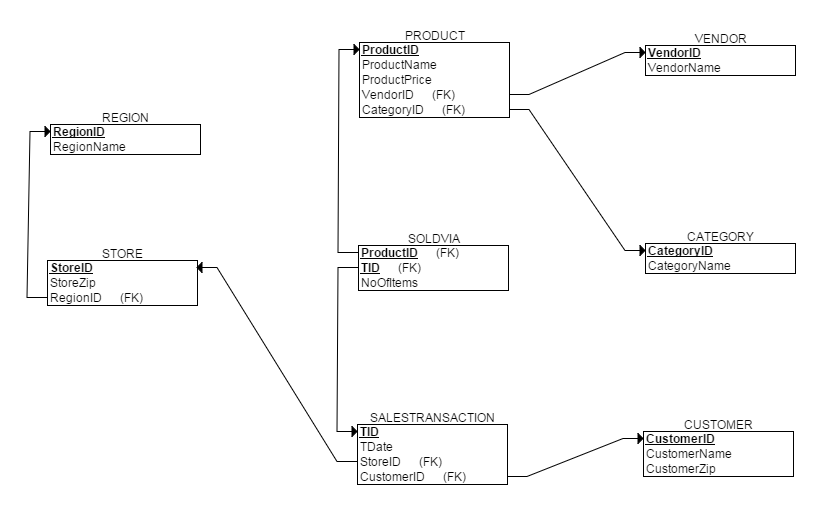
ашЧѓЫбМЏЭъБЯКѓЃЌБуПЩНјааЮЌЖШНЈФЃСЫЁЃБОР§ВЩгУаЧаЮФЃаЭЮЌЖШНЈФЃЁЃЕЋВЛТлВЩШЁКЮжжФЃЪНЃЌЮЌЖШНЈФЃЕФЙиМќдкгкУїШЗЯТУцЫФИіЮЪЬтЃК
1. ФФаЉЮЌЖШЖджїЬтЗжЮігагУЃП
БОР§жаЃЌИљОнВњЦЗ(PRODUCT)ЁЂЙЫПЭ(CUSTOMER)ЁЂЩЬЕъ(STORE)ЁЂШеЦк(DATE)ЖдЯњЪлЖюНјааЗжЮіЪЧЗЧГЃгаАяжњЕФЃЛ
2. ШчКЮЪЙгУЯжгаЪ§ОнЩњГЩЮЌБэЃП
a. ЮЌЖШPRODUCTПЩгЩЙиЯЕPRODUCTЃЌЙиЯЕVENDORЃЌЙиЯЕCATEGORYСЌНгЕУЕНЃЛ
b. ЮЌЖШCUSTOMERКЭЙиЯЕCUSTOMERЯрЭЌЃЛ
c. ЮЌЖШSTOREПЩгЩЙиЯЕSTROEКЭЙиЯЕREGIONСЌНгЕУЕНЃЛ
d. ЮЌЖШCALENDARгЩЙиЯЕSALESTRANSACTIONжаЕФTDateСаЗжРыЕУЕНЃЛ
3. гУЪВУДжИБъРД"ЖШСП"жїЬтЃП
БОР§ЕФжїЬтЪЧЯњЪлЃЌЖјЯњСПКЭЯњЪлЖюетСНИіжИБъзюФмжБЙлЗДгГЯњЪлЧщПіЃЛ
4. ШчКЮЪЙгУЯжгаЪ§ОнЩњГЩЪТЪЕБэЃП
ЯњСПКЭЯњЪлЖюаХЯЂПЩвдгЩЙиЯЕSALESTRANSACTIONКЭЙиЯЕSOLDVIAЃЌЙиЯЕPRODUCTСЌНгЕУЕНЃЛ
УїШЗетЫФИіЮЪЬтКѓЃЌБуФмЧсЫЩЭъГЩЮЌЖШНЈФЃЃК
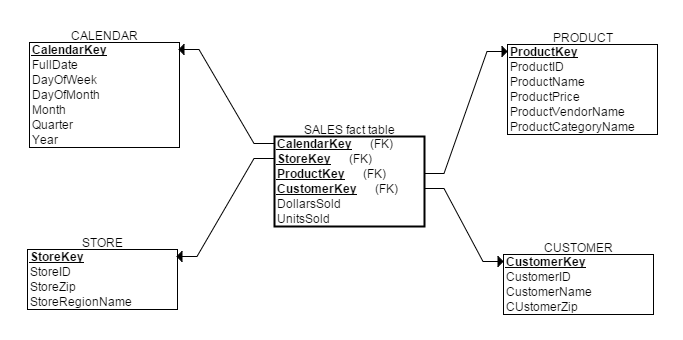
ЯИаФЕФЖСепЛсЗЂЯжШ§ИіЮЪЬтЃК1. ЮЌБэВЛТњзуЙцЗЖЛЏЩшМЦ(ВЛТњзу3NF)ЃЛ2. ЪТЪЕБэвВВЛТњзуЙцЗЖЛЏЩшМЦ(1NFЖМВЛТњзу)ЃЛ 3. ЮЌЖШНЈФЃжаИїЮЌЖШЕФжїТыгЩ***IDБфГЩ***KeyЃЛ
ЖдгкЧАСНИіЮЪЬтЃЌгЩгкЕБЧАНЈФЃЛЗОГЪЧЪ§ОнВжПтЃЌЖјУЛгаИќаТВйзїЃЌЫљвдВЛашвЊбЯИёзіЙцЗЖЛЏЩшМЦРДЯћГ§ШпгрБмУтИќаТвьГЃЁЃ
вђДЫЫфШЛПЩвдвдбЉЛЈФЃаЭНјааЮЌЖШНЈФЃЃЌШчЯТЫљЪОЃК
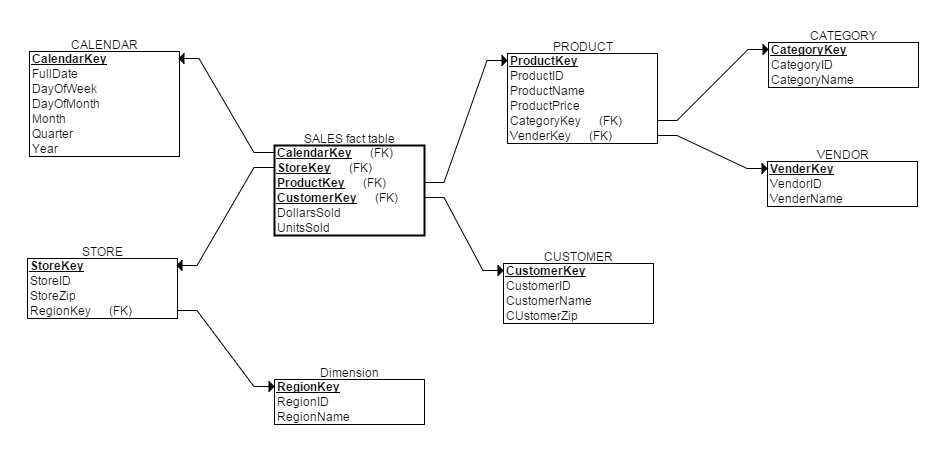
ЕЋетбљЛсМгДѓВщбЏШЫдБИКЕЃЃКУПДЮВщбЏЖМЩцМАЕНЬЋЖрБэСЫЁЃвђДЫдкЪЕМЪгІгУжаЃЌбЉЛЈФЃаЭНіЪЧвЛжжРэТлЩЯЕФФЃаЭЁЃаЧзљФЃаЭдђГіЯждк"ЮЌЖШНЈФЃЪ§ОнВжПт"жаЃЌБОЮФКѓУцНЋЛсНВЕНЁЃ
ЖдгкЕкШ§ИіЮЪЬтЃЌ***KeyетбљЕФзжЖЮБЛГЦЮЊДњРэТы(surrogate key)ЃЌЫќЪЧвЛИіЭЈЙ§здЖЏЗжХфећЪ§ЩњГЩЕФжїТыЃЌУЛгаШЮКЮЦфЫћвтвхЁЃЪЙгУЫќжївЊЪЧЮЊСЫФмЙЛДІРэ"ЛКТ§БфЛЏЕФЮЌЖШ"ЃЌБОЮФКѓУцЛсзаЯИЗжЮіетИіЮЪЬтЃЌетРяВЛОРНсЁЃ
ИќЖрПЩФмЕФЪТЪЕЪєад
Г§СЫЖдгІЕНЮЌЖШЕФЭтТыКЭЖШСПЪєадЃЌЪТЪЕБэжаЛЙГЃГЃПМТЧСэЭтСНИіЪєадЃКЪТЮёБъЪЖТы(transaction identifier)КЭЪТЮёЪБМф(transaction time)ЁЃ
ЪТЮёБъЪЖТыЭЈГЃБЛУќУћЮЊTIDЃЌЦфвтвхОЭЪЧИїжжЖЉЕЅКХЃЌЪТЮёБрКХ...... ЮЊЪВУДНЋетИіЪєадЗХЕНЪТЪЕБэЖјВЛЪЧЮЌБэжаФиЃПвЛИіжївЊдвђЪЧЫќЕФЪ§СПМЖЬЋДѓСЫЃЌетбљУПДЮВщбЏЖМЛсКФЗбКмЖрзЪдДРДJoinЁЃетжжНЋФГаЉТпМвтвхЩЯЕФЮЌЖШЗХЕНЪТЪЕБэРяЕФзіЗЈБЛГЦЮЊЭЫЛЏЮЌЖШ(degenerate dimension)ЁЃ
НЋЪТЮёЪБМфЮЌЖШЗХЕНЪТЪЕБэжаЕФПМТЧвВЪЧГігкЯрЭЌПМТЧЁЃШЛЖјетУДЩшМЦгжвЛДЮ"ФцЙцЗЖЛЏ"СЫЃКЪТЮёБъЪЖТыЗЧжїТыШДОіЖЈЪТЮёБъЪЖЪБМфЃЌЯдШЛЮЅБГСЫ3NFЁЃЕЋЯждкЮвУЧЪЧЮЊЪ§ОнВжПтНЈФЃЃЌЫљвдетбљзіЪЧOKЕФЁЃСэЭтдкЗжВМЪНЕФЪ§ОнВжПтжаЃЌетИізжЖЮЪЎЗжживЊЁЃвђЮЊЪТЪЕБэЕФЪ§СПМЖЗЧГЃДѓЃЌHiveЛђепSpark SQLетРрЗжВМЪНЪ§ОнВжПтЙЄОпЖМЛсЖдетаЉЪ§ОнНјааЗжЧјЁЃШЮКЮГЩЪьЕФЗжВМЪНМЦЫуЦНЬЈжаЖМгІНћжЙПЊЗЂШЫдБНЈСЂЗЧЗжЧјЪТЪЕБэЃЌВЂФЌШЯЗжЧјзжЖЮЮЊ(ЕБЬь)ШеЦкЁЃ
ОЕфаЧзљФЃаЭ
ЧАЮФвбОНВЙ§ЃЌгаЖрИіЪТЪЕБэЕФЮЌЖШФЃаЭБЛГЦЮЊаЧзљФЃаЭЁЃаЧзљФЃаЭжївЊгавдЯТСНДѓзїгУЃКЙВЯэЮЌЖШКЭЩшжУЯИНк/ОлМЏЪТЪЕБэЁЃЯТУцЗжБ№ЖдетСНжжЧщПіНјааЗжЮіЃК
1. ЙВЯэЮЌЖШ
вдЧАЮФЬсЕНЕФСуЪлЙЋЫОЮЊР§ЃЌМйШчИУЙЋЫОжЪСПМрЙмВПУХЯЃЭћгУЗжЮіЯњЪлжїЬтЭЌбљЕФЗНЗЈЗжЮіСгжЪВњЦЗЃЌФЧУДДЫЪБВЛашвЊжиаТЮЌЖШНЈФЃЃЌжЛашЭљФЃаЭРяМгШывЛИіаТЕФСгжЪВњЦЗЪТЪЕБэЁЃжЎКѓаТЕФЪ§ОнВжПтЮЌЖШНЈФЃНсЙћШчЯТЃК
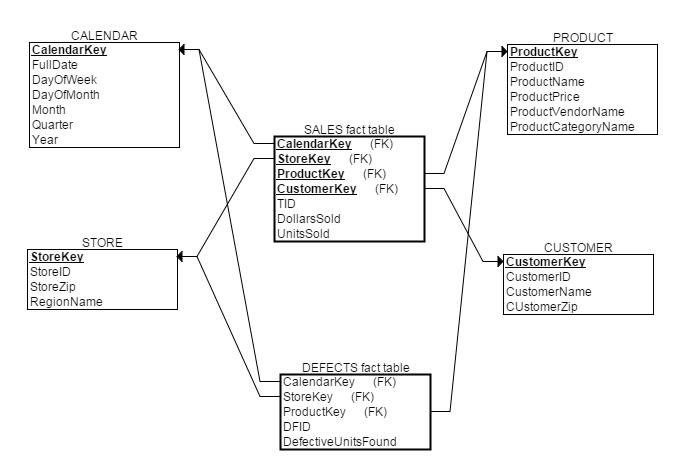
2. ЯИНк/ОлМЏЪТЪЕБэ
ЯИНкЪТЪЕБэ(detailed fact tables)жаУПЬѕМЧТМБэЪОЕЅвЛЪТЪЕЃЌЖјОлМЏЪТЪЕБэ(aggregated fact tables)жаУПЬѕМЧТМдђОлКЯСЫЖрЬѕЪТЪЕЁЃДгБэЕФзжЖЮЩЯПДЃЌЯИНкЪТЪЕБэЭЈГЃгаЩшжУTIDЪєадЃЌЖјОлМЏЪТЪЕБэдђЮоЁЃ
СНжжЪТЪЕБэИїгагХШБЕуЃЌЯИНкЪТЪЕБэВщбЏСщЛюЕЋЪЧЯьгІЫйЖШЯрЖдТ§ЃЌЖјОлМЏЪТЪЕБэЫфШЛЬсИпСЫВщбЏЫйЖШЃЌЕЋЪЙВщбЏЙІФмЪмЕНвЛЖЈЯожЦЁЃвЛИіГЃМћЕФзіЗЈЪЧЪЙгУаЧзљФЃаЭЭЌЪБЩшжУСНжжЪТЪЕБэ(ПЩКЌЖрИіОлМЏЪТЪЕБэ)ЁЃетжжЩшМЦЗНЗЈжаЃЌОлМЏЪТЪЕБэЪЙгУКЭЯИНкЪТЪЕБэЯИНкЪТЪЕБэЕФЮЌЖШЁЃШчЯТЮЌЖШНЈФЃЗНЗЈВЩгУаЧзљФЃаЭзлКЯСЫЯИНкЪТЪЕБэКЭСНжжОлМЏЪТЪЕБэЃК
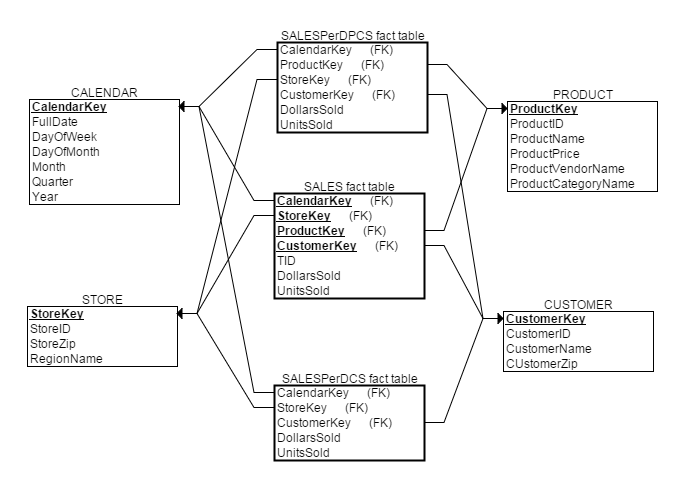
ЛКТ§БфЛЏЮЌЖШЮЪЬт
ЫфШЛЃЌЮЌБэЕФЪ§ОнБШЪТЪЕБэИќЮШЖЈЁЃЕЋВЛТлШчКЮЮЌЖШдкФГаЉЪБКђзмЛсЗЂЩњвЛаЉБфЛЏЁЃдкжЎЧАдјХзГівЛИіЮЪЬтЃКЮЊЪВУДЮЌЖШНЈФЃКѓЕФЙиЯЕВЛЪЧ***IDЃЌЖјЪЧ***KeyСЫЁЃетбљзіЕФФПЕФЦфЪЕОЭЪЧЮЊСЫНтОівЛжжБЛГЦЮЊЛКТ§ЮЌЖШБфЛЏ(slowly changing dimension)ЕФЮЪЬтЁЃдкЮЌЖШБфЛЏКѓЃЌвЛВПЗжРњЪЗаХЯЂОЭБЛЖЊЕєСЫЁЃБШШчеХШ§ЪЧФГЙЋЫОЛсдБЁЃ
ЕЋНіНіетУДзіЛЙЪЧВЛЙЛЕФЃЌДњРэТыашвЊХфКЯЪБМфДСЃЌвдМАааБъЪЖЗћЪЙгУВХФмНтОіЛКТ§ЮЌЖШБфЛЏЕФЮЪЬтЁЃШчЯТCUSTOMERБэЪЙгУИУЗНЗЈБмУтЛКТ§ЮЌЖШБфЛЏЃК
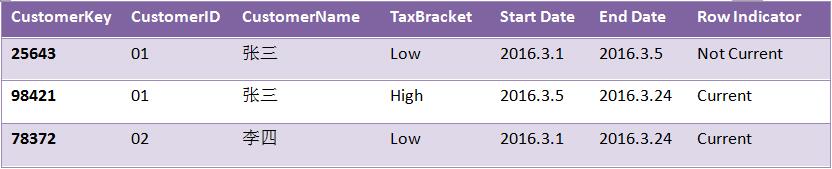
ПЩвдПДЕНгУЛЇеХШ§ЖдгІаТЮЌЖШЕФTaxBracketзДЬЌгЩLowБфГЩСЫHighЁЃШчЙћашвЊЭГМЦеХШ§ЕФЯрЙиааЮЊЃЌФЧУДПЩвдШУЫљгаМЧТМгУCustomerIDзжЖЮJoinЪТЪЕБэЃЛШчЙћвЊЭГМЦЕБЧАTaxBracketЮЊLowЕФгУЛЇзДЬЌЃЌдђПЩНЋRow IndicatorзжЖЮЮЊCurrentЕФМЧТМгУCustomerKeyзжЖЮJoinЪТЪЕБэЃЛШчЙћвЊЭГМЦРњЪЗTaxBracketзДЬЌЮЊLowЕФгУЛЇЧщПіЃЌдђжЛашвЊНЋTaxBracketЪєадЮЊLowЕФгУЛЇМЧТМЕФCustomerKeyЪєадгыЪТЪЕБэЙиСЊЁЃ
Ъ§ОнВжПтНЈФЃЬхЯЕжЎЙцЗЖЛЏЪ§ОнВжПт
ЫљЮН"Ъ§ОнВжПтНЈФЃЬхЯЕ"ЃЌжИЕФЪЧЪ§ОнВжПтДгЮоЕНгаЕФвЛећЬзНЈФЃЗНЗЈЁЃзюГЃМћЕФШ§жжЪ§ОнВжПтНЈФЃЬхЯЕЗжБ№ЮЊЃКЙцЗЖЛЏЪ§ОнВжПтЃЌЮЌЖШНЈФЃЪ§ОнВжПтЃЌЖРСЂЪ§ОнМЏЪаЁЃКмЖрЪщНЋЫќУЧГЦЮЊ"Ъ§ОнВжПтНЈФЃЗНЗЈ"ЃЌЕЋБЪепШЯЮЊЪ§ОнВжПтНЈФЃЬхЯЕИќФмзМШЗБэДявтЫМЃЌЧыдЪаэЮвздзїжїеХвЛДЮАЩЃКЃЉЁЃЯТУцЪзЯШРДНщЩмЙцЗЖЛЏЪ§ОнВжПтЁЃ
ЙцЗЖЛЏЪ§ОнВжПт(normalized data warehouse)ЙЫУћЫМвхЃЌЦфжаЪЧЙцЗЖЛЏЩшМЦЕФЗжЮіаЭЪ§ОнПтЃЌШЛКѓЛљгкетИіЪ§ОнПтЮЊИїВПУХНЈСЂЪ§ОнМЏЪаЁЃзмЬхМмЙЙШчЯТЭМЫљЪОЃК
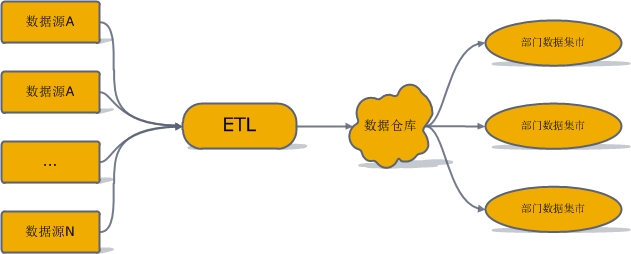
ИУНЈФЃЬхЯЕЪзЯШЖдETLЕУЕНЕФЪ§ОнНјааERНЈФЃЃЌЙиЯЕНЈФЃЃЌЕУЕНвЛИіЙцЗЖЛЏЕФЪ§ОнПтФЃЪНЁЃШЛКѓгУетИіжааФЪ§ОнПтЮЊЙЋЫОИїВПУХНЈСЂЛљгкЮЌЖШНЈФЃЕФЪ§ОнМЏЪаЁЃИїВПУХПЊЗЂШЫдБДѓЖМДгетаЉЪ§ОнМЏЪаЬсЪ§ЃЌЭЈГЃРДЫЕВЛдЪаэжБНгЗУЮЪжааФЪ§ОнПтЁЃ
Ъ§ОнВжПтНЈФЃЬхЯЕжЎЮЌЖШНЈФЃЪ§ОнВжПт
ЗЧЮЌЖШНЈФЃЪ§ОнВжПт(dimensionally modeled data warehouse)ЪЧвЛжжЪЙгУНЛДэЮЌЖШНјааНЈФЃЕФЪ§ОнВжПтЃЌЦфзмЬхМмЙЙШчЯТЭМЫљЪОЃК
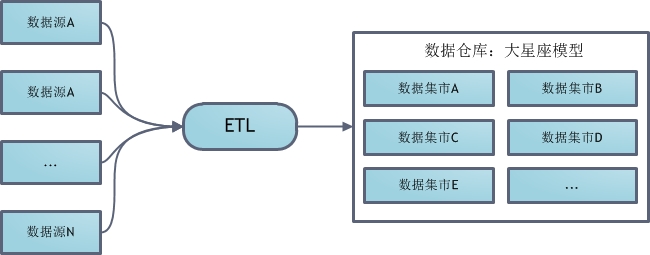
ИУНЈФЃЬхЯЕЪзЯШЩшМЦвЛзщГЃгУЕФЖШМЏКЯ(conformed dimension)ЃЌШЛКѓДДНЈвЛИіДѓаЧзљФЃаЭБэЪОЫљгаЗжЮіаЭЪ§ОнЁЃШчЙћетжжвЛжТЮЌЖШВЛТњзуФГаЉЪ§ОнЗжЮівЊЧѓЃЌздШЛвВПЩдкЪ§ОнВжПтжЎЩЯМЬајЙЙНЈаТЕФЪ§ОнМЏЪаЁЃ
Ъ§ОнВжПтНЈФЃЬхЯЕжЎЖРСЂЪ§ОнМЏЪа
ЖРСЂЪ§ОнМЏЪаЕФНЈФЃЬхЯЕЪЧШУЙЋЫОЕФИїИізщжЏздМКДДНЈВЂЭъГЩETLЃЌздМКЮЌЛЄздМКЕФЪ§ОнМЏЪаЁЃЦфзмЬхМмЙЙШчЯТЭМЫљЪОЃК
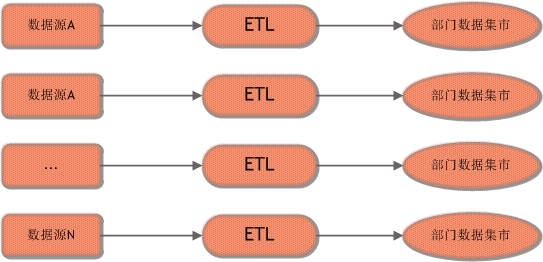
ДгММЪѕЩЯРДНВетЪЧвЛжжКмВЛжЕЕУЭЦГчЕФЗНЪНЃЌвђЮЊНЋЪЙаХЯЂЗжЩЂЃЌгАЯьСЫЦѓвЕШЋОжЗЖЮЇФкЪ§ОнЗжЮіЕФаЇТЪЁЃДЫЭтЃЌИїзщжЏжЎМфЕФETLМмЙЙЯрЛЅЖРСЂЮоЗЈИДгУЃЌвВРЫЗбСЫЦѓвЕЕФПЊЗЂзЪдДЁЃШЛЖјГігкФГаЉЙЋЫОжЦЖШМАдЄЫуЗНУцЕФПМТЧЃЌгаЪБвВЛсЪЙгУЕНетжжНЈФЃЬхЯЕЁЃ
Ш§жжЪ§ОнВжПтНЈФЃЬхЯЕЖдБШ
ЙцЗЖЛЏЪ§ОнВжПтКЭЮЌЖШНЈФЃЪ§ОнВжПтЗжБ№ЪЧBill InmonКЭRalph KimballЬсГіЕФЗНЗЈЁЃЙигкФФжжЗНЗЈИќКУЃЌФФжжЗНЗЈИќгХауЕФељТлвбОгЩРДвбОУЁЃЕЋЫцзХетСНжжЪ§ОнВжПтгІгУдНРДдНЖрЃЌШЫУЧвВж№НЅСЫНтЕНСНжжЪ§ОнВжПтЕФгХСгжЎДІЃЌШчЯТБэЫљЪОЃК
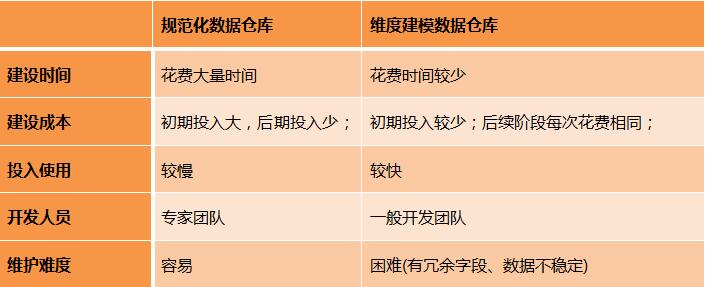
ВњЩњетаЉЧјБ№ЕФИљБОжЎДІдкгкЙцЗЖЛЏЪ§ОнВжПташвЊЖдЦѓвЕШЋОжНјааЙцЗЖЛЏНЈФЃЃЌетНЋЕМжТНЯДѓЕФЙЄзїСПЁЃЕЋетвЛВНБиаыЭъГЩКУЃЌВХФмМЬајЭљЩЯНЈЩшЪ§ОнМЏЪаЁЃвђДЫвВОЭЕМжТЙцЗЖЛЏЪ§ОнВжПташвЊвЛЖЈЪБМфВХФмЭЖШыЪЙгУЃЌУєНнадЯрЖдКѓепРДЫЕТдВюЁЃЕЋЪЧЙцЗЖЛЏЪ§ОнВжПтвЛЕЉНЈСЂКУСЫЃЌдђвдКѓЪ§ОнОЭИќвзгкЙмРэЁЃЖјЧвгЩгкПЊЗЂШЫдБВЛФмжБНгЪЙгУЦфжааФЪ§ОнПтЃЌИќМгШЗБЃСЫЪ§ОнжЪСПЁЃЛЙгагЩгкжааФЪ§ОнПтЪЧВЩгУЙцЗЖЛЏЩшМЦЕФЃЌШпгрЧщПівВЛсИќЩйЁЃ
ШЛЖјСэвЛЗНУцЮЌЖШНЈФЃЪ§ОнВжПтГ§СЫУєНнадИќЧПЃЌЖјЧвЪЪгУгквЕЮёБфЛЏБШНЯЦЕЗБЕФЧщПіЃЌЖдПЊЗЂШЫдБЕФвЊЧѓвВУЛгаЙцЗЖЛЏЪ§ОнВжПтФЧУДИпЁЃзмжЎИїгаРћБзЃЌОпЬхЪЕЪЉЪБашвЊзаЯИЕФШЈКтЁЃ
аЁНс
Ъ§ОнВжПтНЈФЃЪЧвЛИізлКЯадММЪѕЃЌашвЊЪЙгУЕНERНЈФЃЁЂЙиЯЕНЈФЃЁЂЮЌЖШНЈФЃЕШММЪѕЁЃЖјЧвЕБЦѓвЕвЕЮёИДдгЕФЪБКђЃЌетВПЗжЙЄзїИќЪЧашвЊзЈУХЭХЖггывЕЮёЗНЙВЭЌКЯзїРДЭъГЩЁЃвђДЫвЛИігХауЕФЪ§ОнВжПтНЈФЃЭХЖгМШвЊгаМсЪЕЕФЪ§ОнВжПтНЈФЃММЪѕЃЌЛЙвЊгаЖдЯжЪЕвЕЮёЧхЮњЁЂЭИГЙЕФРэНтЁЃ
|









