| 编辑推荐: |
| 本文来自于个人微信公众号,本文通过JMS实战,演示了如何通过Java代码来扩展Kettle的功能,希望对您的学习有所帮助。 |
|
一、问题背景
在使用Kettle的过程中,有可能遇到现有步骤无法满足需求的情况。解决此类问题,有诸如购买第三方插件、开发插件、自定义Java类等办法。最后一种办法因其代价小且门槛较低而成为最为常用的定制方法。本文将解释Java代码步骤的原理,并通过一个实际案例,快速掌握相关入门知识。
二、原理剖析
Java代码步骤,位于Kettle转换的核心对象/脚本类别中,属于典型的需要编程基础才能掌控的步骤类型。而Java代码步骤,适用于熟悉Java语言的开发人员,用好这个步骤,需要对类、接口、多线程等语言相关知识有所掌握,并且需要对Kettle的基础框架有所理解。Java语言的基础知识不在本文讨论范围,下面将着重对Kettle框架的核心部分进行解释。
Kettle转换的执行,有以下三个核心的生命周期节点:
1、初始化
Kettle转换在执行前,会有一个各步骤的初始化动作,为步骤执行前的准备工作创造机会。为提高初始化的性能,Kettle为每个步骤启用一个初始化线程,从而并行完成所有步骤的初始化。初始化的主要内容就是调用一次步骤的以下方法:
public boolean init( StepMetaInterface meta, StepDataInterfacedata)
此方法包含两个参数。其中,meta为元数据,data为数据。如果返回true,那么代表初始化成功,否则代表初始化失败。任何一个步骤初始化失败,都会导致整个转换停止执行(在停止前,会调用每一个转换的资源释放方法dispose)。
2、执行
执行阶段是每一个步骤实现特定价值的时候。为提高效率,Kettle为每一个步骤单独启动一个工作线程来执行任务。Java程序员都了解,线程的核心代码是覆盖run方法。为简化起见,我将不重要的代码删除,得到工作线程run方法核心代码:
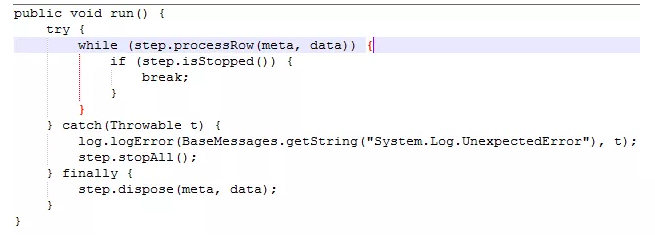
可以看出,线程一直在执行步骤的processRow方法,直到出现以下情况之一:
· processRow方法返回false
· isStopped方法返回true
· processRow方法执行过程中出现异常,
其中,第一种情况代表工作已经正常完成;第二种情况,代表步骤被强制停止;第三种情况,代表执行过程中出现错误,Kettle将调用stopAll方法,从而导致整个转换的所有工作线程停止执行。
执行方法的声明如下:
public boolean processRow( StepMetaInterface meta,StepDataInterfacedata
) throws KettleException;
每一个步骤,都会在processRow方法中各显神通。一般的过程是,从输入行集中拿出一行,进行特定处理,然后将新的行放入输出行集中。从输入行集中取数据可以调用getRow方法。如果getRow方法返回值不为null,则步骤应将该行数据进行处理,并调用putRow方法将处理结果存入输出行集,然后返回true,以继续为下一行输入数据处理提供机会。如果getRow方法返回null,代表输入行集已经处理完毕,这时可以调用setOutputDone,标识本步骤执行完毕,并返回false,以结束本工作线程的执行。
3、资源释放
从上述工作线程的核心代码可以看出,不管工作线程是正常执行完毕还是异常执行完毕,最终会调用dispose方法。该方法声明如下:
public void dispose( StepMetaInterface meta, StepDataInterfacedata);
步骤应该在需要时覆盖此方法,并释放相关资源。
了解上述原理后,撰写Java类步骤中的代码时将胸有成竹。综上所述,一般情况下重写processRow方法即可满足需求,如果用到了一些重量级的资源,最好在init方法中初始化,并在dispose方法中释放。
由于Kettle使用Janino框架为自定义Java转换步骤类动态定义了类名,并指定父类为TransformClassBase,所以在撰写代码时,只需要提供类的内容即可,无需class声明。
既然自动建立了父类,那么父类的成员、方法都可以在代码中重用。父类常用的成员包括以下三个实例:
parent:代表容器对象
meta:代表容器元数据对象
data:代表容器数据对象
常用的方法包括:
getRow:从输入行集中取一行数据
putRow:存银行数据到输出行集
stopAll:停止所有工作线程
setOutputDone:标记本步骤工作完成
logBasic:输出基本日志
logError:输出错误日志
getInputRowMeta:得到输入行的元数据
createOutputRow:创建一个输出行数据
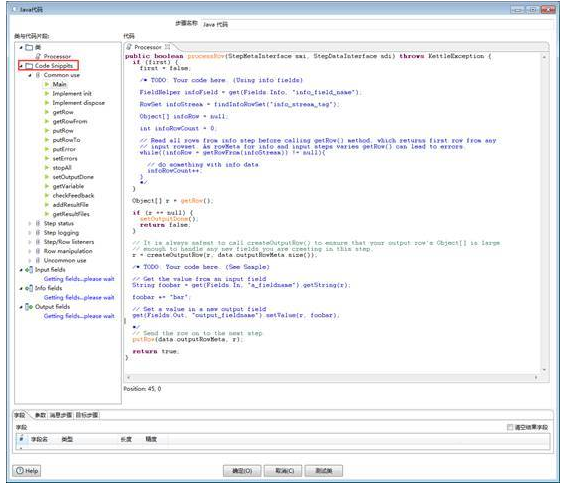
其实,常用的方法(如下图1所示),基本上都在步骤属性对话框左侧Code Snippits中。一般情况下,可以双击其中的Main节点,从processRow方法的重写开始,需要其他代码时,在左侧找到对应代码块,双击即可加入。
三、案例分享
本文使用一个Kettle集成JMS的案例来进行实战演练。假设需要两个转换:一个转换名为Send,实现从文本文件输入流读取数据,并发送到ActiveMQ的队列;另外一个转换名为Receive,实现从队列读取数据,并发送到文本文件输出流。两个转换截图如下:
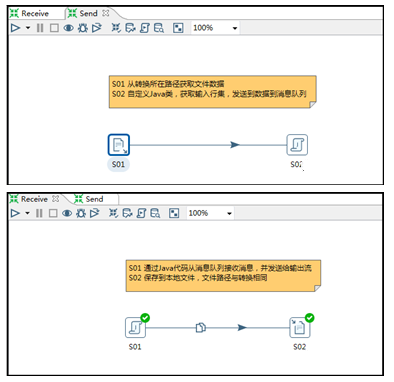
由于两个转换中用到的文本文件输入、输出都非常简单,这里只做简单描述。Send转换中,S01读取本地文本文件,包含两个String类型的字段ID、MENU_NAME。Receive转换中,S02输出文件到转换所在目录,仅包含一个名为MENU_NAME的String类型字段。
下文着重描述两个Java代码步骤。第一个步骤是Send转换中的S02,其主要代码注释如下:

第二个步骤是Receive转换中的S01步骤。主要代码注释如下:

注意,由于本文使用了ActiveMQ作为JMS服务器,所以为保证实例能够正常运行,需要自行下载服务器安装程序,并将对应jar文件拷贝到Kettle的lib目录下(本例使用activemq-all-5.8.0.jar)。代码中,需要的import指令如下:
import java.util.
* ;
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.DeliveryMode;
import javax.jms.Destination;
import javax.jms.MapMessage;
import javax.jms.MessageProducer;
import javax.jms.Session;
import org.apache.activemq.ActiveMQConnection;
import org.apache.activemq.ActiveMQConnectionFactory; |
四、总结
本文在具备程序员背景知识的数据工程师在运用Kettle进行定制开发时,可以参考。 |









