| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФЯъЯИНщЩмСЫЪ§ОнВжПтШ§жжНЈФЃЗНЗЈвдМАЮЌЖШНЈФЃЗЈЪ§ОнФЃаЭЕФЧјБ№ЕШЯрЙижЊЪЖЁЃ |
|
НЈЩшЪ§ОнФЃаЭМШШЛЪЧећИіЪ§ОнВжПтНЈЩшжавЛИіЗЧГЃживЊЕФЙиМќВПЗжЃЌФЧУДЃЌдѕУДНЈЩшЮвУЧЕФЪ§ОнВжПтФЃаЭОЭЪЧЮвУЧашвЊНтОіЕФвЛИіЮЪЬтЁЃетРяЮвУЧНЋвЊЯъЯИНщЩмШчКЮДДНЈЪЪКЯздМКЕФЪ§ОнФЃаЭЁЃ
Ъ§ОнВжПтНЈФЃЗНЗЈ
ДѓЧЇЪРНчЃЌБэУцПДЮхВЪчЭЗзЃЌЪЕжЪЩЯЃЌЭђЮяЖМзёбЦфздгаЕФЗЈдђЁЃ
Ъ§ОнВжПтЕФНЈФЃЗНЗЈЭЌбљвВгаКмЖржжЃЌУПвЛжжНЈФЃЗНЗЈЦфЪЕДњБэСЫембЇЩЯЕФвЛИіЙлЕуЃЌДњБэСЫвЛжжЙщФЩЃЌИХРЈЪРНчЕФвЛжжЗНЗЈЁЃ
ФПЧАвЕНчНЯЮЊСїааЕФЪ§ОнВжПтЕФНЈФЃЗНЗЈЗЧГЃЖрЃЌетРяжївЊНщЩмЗЖЪННЈФЃЗЈЃЌЮЌЖШНЈФЃЗЈЃЌЪЕЬхНЈФЃЗЈЕШМИжжЗНЗЈЃЌУПжжЗНЗЈЦфЪЕДгБОжЪЩЯНВОЭЪЧДгВЛЭЌЕФНЧЖШПДЮвУЧвЕЮёжаЕФЮЪЬтЃЌВЛЙмДгММЪѕВуУцЛЙЪЧвЕЮёВуУцЃЌЦфЪЕДњБэЕФЪЧембЇЩЯЕФвЛжжЪРНчЙлЁЃ
ЮвУЧЯТУцИјДѓМвЯъЯИНщЩмвЛЯТетаЉНЈФЃЗНЗЈЁЃ
ЗЖЪННЈФЃЗЈЃЈThird Normal FormЃЌ3NFЃЉ
ЗЖЪННЈФЃЗЈЦфЪЕЪЧЮвУЧдкЙЙНЈЪ§ОнФЃаЭГЃгУЕФвЛИіЗНЗЈЃЌИУЗНЗЈЕФжївЊгЩ Inmon ЫљЬсГЋЃЌжївЊНтОіЙиЯЕаЭЪ§ОнПтЕУЪ§ОнДцДЂЃЌРћгУЕФвЛжжММЪѕВуУцЩЯЕФЗНЗЈЁЃ
ФПЧАЃЌЮвУЧдкЙиЯЕаЭЪ§ОнПтжаЕФНЈФЃЗНЗЈЃЌДѓВПЗжВЩгУЕФЪЧШ§ЗЖЪННЈФЃЗЈЁЃ
ЗЖЪНЪЧЪ§ОнПтТпМФЃаЭЩшМЦЕФЛљБОРэТлЃЌвЛИіЙиЯЕФЃаЭПЩвдДгЕквЛЗЖЪНЕНЕкЮхЗЖЪННјааЮоЫ№ЗжНтЃЌетИіЙ§ГЬвВПЩГЦЮЊЙцЗЖЛЏЁЃ
дкЪ§ОнВжПтЕФФЃаЭЩшМЦжаФПЧАвЛАуВЩгУЕкШ§ЗЖЪНЃЌЫќгазХбЯИёЕФЪ§бЇЖЈвхЁЃДгЦфБэДяЕФКЌвхРДПДЃЌвЛИіЗћКЯЕкШ§ЗЖЪНЕФЙиЯЕБиаыОпгавдЯТШ§ИіЬѕМў
:
УПИіЪєаджЕЮЈвЛЃЌВЛОпгаЖрвхад ;
УПИіЗЧжїЪєадБиаыЭъШЋвРРЕгкећИіжїМќЃЌЖјЗЧжїМќЕФвЛВПЗж ;
УПИіЗЧжїЪєадВЛФмвРРЕгкЦфЫћЙиЯЕжаЕФЪєадЃЌвђЮЊетбљЕФЛАЃЌетжжЪєадгІИУЙщЕНЦфЫћЙиЯЕжаШЅЁЃ
гЩгкЗЖЪНЪЧЛљгкећИіЙиЯЕаЭЪ§ОнПтЕФРэТлЛљДЁжЎЩЯЗЂеЙЖјРДЕФЃЌвђДЫЃЌБОШЫдкетРяВЛЖрзіНщЩмЃЌгааЫШЄЕФЖСепПЩвдЭЈЙ§дФЖСЯргІЕФВФСЯРДЛёЕУетЗНУцЕФжЊЪЖЁЃ
ИљОн Inmon ЕФЙлЕуЃЌЪ§ОнВжПтФЃаЭЕУНЈЩшЗНЗЈКЭвЕЮёЯЕЭГЕФЦѓвЕЪ§ОнФЃаЭРрЫЦЁЃдквЕЮёЯЕЭГжаЃЌЦѓвЕЪ§ОнФЃаЭОіЖЈСЫЪ§ОнЕФРДдДЃЌЖјЦѓвЕЪ§ОнФЃаЭвВЗжЮЊСНИіВуДЮЃЌМДжїЬтгђФЃаЭКЭТпМФЃаЭЁЃЭЌбљЃЌжїЬтгђФЃаЭПЩвдПДГЩЪЧвЕЮёФЃаЭЕФИХФюФЃаЭЃЌЖјТпМФЃаЭдђЪЧгђФЃаЭдкЙиЯЕаЭЪ§ОнПтЩЯЕФЪЕР§ЁЃ
ДгвЕЮёЪ§ОнФЃаЭзЊЯђЪ§ОнВжПтФЃаЭЪБЃЌЭЌбљвВашвЊгаЪ§ОнВжПтЕФгђФЃаЭЃЌМДИХФюФЃаЭЃЌЭЌЪБвВДцдкгђФЃаЭЕФТпМФЃаЭЁЃ
етРяЃЌвЕЮёФЃаЭжаЕФЪ§ОнФЃаЭКЭЪ§ОнВжПтЕФФЃаЭЩдЮЂгавЛаЉВЛЭЌЁЃжївЊЧјБ№дкгкЃК
Ъ§ОнВжПтЕФгђФЃаЭгІИУАќКЌЦѓвЕЪ§ОнФЃаЭЕФгђФЃаЭжЎМфЕФЙиЯЕЃЌвдМАИїжїЬтгђЖЈвхЁЃ
Ъ§ОнВжПтЕФгђФЃаЭЕФИХФюгІИУБШвЕЮёЯЕЭГЕФжїЬтгђФЃаЭЗЖЮЇИќМгЙуЁЃ
дкЪ§ОнВжПтЕФТпМФЃаЭашвЊДгвЕЮёЯЕЭГЕФЪ§ОнФЃаЭжаЕФТпМФЃаЭжаГщЯѓЪЕЬхЃЌЪЕЬхЕФЪєадЃЌЪЕЬхЕФзгРрЃЌвдМАЪЕЬхЕФЙиЯЕЕШЁЃ
вдБЪепЕФЙлЕуРДПДЃЌInmon ЕФЗЖЪННЈФЃЗЈЕФзюДѓгХЕуОЭЪЧДгЙиЯЕаЭЪ§ОнПтЕФНЧЖШГіЗЂЃЌНсКЯСЫвЕЮёЯЕЭГЕФЪ§ОнФЃаЭЃЌФмЙЛБШНЯЗНБуЕФЪЕЯжЪ§ОнВжПтЕФНЈФЃЁЃ
ЕЋЦфШБЕувВЪЧУїЯдЕФЃЌгЩгкНЈФЃЗНЗЈЯоЖЈдкЙиЯЕаЭЪ§ОнПтжЎЩЯЃЌдкФГаЉЪБКђЗДЖјЯожЦСЫећИіЪ§ОнВжПтФЃаЭЕФСщЛюадЃЌадФмЕШЃЌЬиБ№ЪЧПМТЧЕНЪ§ОнВжПтЕФЕзВуЪ§ОнЯђЪ§ОнМЏЪаЕФЪ§ОнНјааЛузмЪБЃЌашвЊНјаавЛЖЈЕФБфЭЈВХФмТњзуЯргІЕФашЧѓЁЃ
ЮЌЖШНЈФЃЗЈ
ЮЌЖШНЈФЃЗЈЃЌKimball зюЯШЬсГіетвЛИХФюЁЃЦфзюМђЕЅЕФУшЪіОЭЪЧЃЌАДееЪТЪЕБэЃЌЮЌБэРДЙЙНЈЪ§ОнВжПтЃЌЪ§ОнМЏЪаЁЃ
ЪТЪЕБэЪЧгУРДМЧТМОпЬхЪТМўЕФЃЌАќКЌСЫУПИіЪТМўЕФОпЬхвЊЫиЃЌвдМАОпЬхЗЂЩњЕФЪТЧщЃЛЮЌБэдђЪЧЖдЪТЪЕБэжаЪТМўЕФвЊЫиЕФУшЪіаХЯЂЁЃ
БШШчвЛИіЪТМўЛсАќКЌЪБМфЁЂЕиЕуЁЂШЫЮяЁЂЪТМўЃЌЪТЪЕБэМЧТМСЫећИіЪТМўЕФаХЯЂЃЌЕЋЖдЪБМфЁЂЕиЕуКЭШЫЮяЕШвЊЫижЛМЧТМСЫвЛаЉЙиМќБъМЧЃЌБШШчЪТМўЕФжїНЧНаЁАMichaelЁБЃЌФЧУДMichaelЕНЕзЁАГЄЪВУДбљЁБЃЌОЭашвЊЕНЯргІЕФЮЌБэРяУцШЅВщбЏЁАMichaelЁБЕФОпЬхУшЪіаХЯЂСЫЁЃ
ЛљгкЪТЪЕБэКЭЮЌБэОЭПЩвдЙЙНЈГіЖржжЖрЮЌФЃаЭЃЌАќРЈаЧаЮФЃаЭЁЂбЉЛЈФЃаЭКЭаЧзљФЃаЭЁЃ
ЮЌЖШНЈФЃЗЈзюБЛШЫЙуЗКжЊЯўЕФУћзжОЭЪЧаЧаЭФЃЪНЃЈStar-schemaЃЉЁЃ
ЩЯЭМЕФетИіМмЙЙжаЪЧЕфаЭЕФаЧаЭМмЙЙЁЃаЧаЭФЃЪНжЎЫљвдЙуЗКБЛЪЙгУЃЌдкгкеыЖдИїИіЮЌзїСЫДѓСПЕФдЄДІРэЃЌШчАДееЮЌНјаадЄЯШЕФЭГМЦЁЂЗжРрЁЂХХађЕШЁЃ
ЭЈЙ§етаЉдЄДІРэЃЌФмЙЛМЋДѓЕФЬсЩ§Ъ§ОнВжПтЕФДІРэФмСІЁЃ
ЬиБ№ЪЧеыЖд 3NF ЕФНЈФЃЗНЗЈЃЌаЧаЭФЃЪНдкадФмЩЯеМОнУїЯдЕФгХЪЦЁЃ
ЭЌЪБЃЌЮЌЖШНЈФЃЗЈЕФСэЭтвЛИігХЕуЪЧЃЌЮЌЖШНЈФЃЗЧГЃжБЙлЃЌНєНєЮЇШЦзХвЕЮёФЃаЭЃЌПЩвджБЙлЕФЗДгГГівЕЮёФЃаЭжаЕФвЕЮёЮЪЬтЁЃ
ВЛашвЊОЙ§ЬиБ№ЕФГщЯѓДІРэЃЌМДПЩвдЭъГЩЮЌЖШНЈФЃЁЃетвЛЕувВЪЧЮЌЖШНЈФЃЕФгХЪЦЁЃ
ЕЋЪЧЃЌЮЌЖШНЈФЃЗЈЕФШБЕувВЪЧЗЧГЃУїЯдЕФЃЌгЩгкдкЙЙНЈаЧаЭФЃЪНжЎЧАашвЊНјааДѓСПЕФЪ§ОндЄДІРэЃЌвђДЫЛсЕМжТДѓСПЕФЪ§ОнДІРэЙЄзїЁЃ
ЖјЧвЃЌЕБвЕЮёЗЂЩњБфЛЏЃЌашвЊжиаТНјааЮЌЖШЕФЖЈвхЪБЃЌЭљЭљашвЊжиаТНјааЮЌЖШЪ§ОнЕФдЄДІРэЁЃ
ЖјдкетаЉгыДІРэЙ§ГЬжаЃЌЭљЭљЛсЕМжТДѓСПЕФЪ§ОнШпгрЁЃ
СэЭтвЛИіЮЌЖШНЈФЃЗЈЕФШБЕуОЭЪЧЃЌШчЙћжЛЪЧвРППЕЅДПЕФЮЌЖШНЈФЃЃЌВЛФмБЃжЄЪ§ОнРДдДЕФвЛжТадКЭзМШЗадЃЌЖјЧвдкЪ§ОнВжПтЕФЕзВуЃЌВЛЪЧЬиБ№ЪЪгУгкЮЌЖШНЈФЃЕФЗНЗЈЁЃ
вђДЫвдБЪепЕФЙлЕуПДЃЌЮЌЖШНЈФЃЕФСьгђжївЊЪЪгУгыЪ§ОнМЏЪаВуЃЌЫќЕФзюДѓЕФзїгУЦфЪЕЪЧЮЊСЫНтОіЪ§ОнВжПтНЈФЃжаЕФадФмЮЪЬтЁЃ
ЮЌЖШНЈФЃКмФбФмЙЛЬсЙЉвЛИіЭъећЕиУшЪіецЪЕвЕЮёЪЕЬхжЎМфЕФИДдгЙиЯЕЕФГщЯѓЗНЗЈЁЃ
ЪЕЬхНЈФЃЗЈ
ЪЕЬхНЈФЃЗЈВЂВЛЪЧЪ§ОнВжПтНЈФЃжаГЃМћЕФвЛИіЗНЗЈЃЌЫќРДдДгкембЇЕФвЛИіСїХЩЁЃ
ДгембЇЕФвтвхЩЯЫЕЃЌПЭЙлЪРНчгІИУЪЧПЩвдЯИЗжЕФЃЌПЭЙлЪРНчгІИУПЩвдЗжГЩгЩвЛИіИіЪЕЬхЃЌвдМАЪЕЬхгыЪЕЬхжЎМфЕФЙиЯЕзщГЩЁЃ
ФЧУДЮвУЧдкЪ§ОнВжПтЕФНЈФЃЙ§ГЬжаЭъШЋПЩвдв§ШыетИіГщЯѓЕФЗНЗЈЃЌНЋећИівЕЮёвВПЩвдЛЎЗжГЩвЛИіИіЕФЪЕЬхЃЌЖјУПИіЪЕЬхжЎМфЕФЙиЯЕЃЌвдМАеыЖдетаЉЙиЯЕЕФЫЕУїОЭЪЧЮвУЧЪ§ОнНЈФЃашвЊзіЕФЙЄзїЁЃ
ЫфШЛЪЕЬхЗЈДжПДЦ№РДКУЯёгавЛаЉГщЯѓЃЌЦфЪЕРэНтЦ№РДКмШнвзЁЃ
МДЮвУЧПЩвдНЋШЮКЮвЛИівЕЮёЙ§ГЬЛЎЗжГЩ 3 ИіВПЗжЃЌЪЕЬхЃЌЪТМўКЭЫЕУїЁЃ
Р§ШчЮвУЧУшЪівЛИіМђЕЅЕФЪТЪЕЃКЁАаЁУїПЊГЕШЅбЇаЃЩЯбЇЁБЁЃвдетИівЕЮёЪТЪЕЮЊР§ЃЌЮвУЧПЩвдАбЁАаЁУїЁБЃЌЁАбЇаЃЁБПДГЩЪЧвЛИіЪЕЬхЃЌЁАЩЯбЇЁБУшЪіЕФЪЧвЛИівЕЮёЙ§ГЬЃЌЮвУЧдкетРяПЩвдГщЯѓЮЊвЛИіОпЬхЁАЪТМўЁБЃЌЖјЁАПЊГЕШЅЁБдђПЩвдПДГЩЪЧЪТМўЁАЩЯбЇЁБЕФвЛИіЫЕУїЁЃ
ДгЩЯУцЕФОйР§ЮвУЧПЩвдСЫНтЃЌЮвУЧЪЙгУЕФГщЯѓЙщФЩЗНЗЈЦфЪЕКмМђЕЅЃЌШЮКЮвЕЮёПЩвдПДГЩ 3 ИіВПЗжЃК
ЪЕЬхЃЌжївЊжИСьгђФЃаЭжаЬиЖЈЕФИХФюжїЬхЃЌжИЗЂЩњвЕЮёЙиЯЕЕФЖдЯѓЁЃ
ЪТМўЃЌжївЊжИИХФюжїЬхжЎМфЭъГЩвЛДЮвЕЮёСїГЬЕФЙ§ГЬЃЌЬижИЬиЖЈЕФвЕЮёЙ§ГЬЁЃ
ЫЕУїЃЌжївЊЪЧеыЖдЪЕЬхКЭЪТМўЕФЬиЪтЫЕУїЁЃ
гЩгкЪЕЬхНЈФЃЗЈЃЌФмЙЛКмЧсЫЩЕФЪЕЯжвЕЮёФЃаЭЕФЛЎЗжЃЌвђДЫЃЌдквЕЮёНЈФЃНзЖЮКЭСьгђИХФюНЈФЃНзЖЮЃЌЪЕЬхНЈФЃЗЈгазХЙуЗКЕФгІгУЁЃДгБЪепЕФОбщРДПДЃЌдйУЛгаЯжГЩЕФаавЕФЃаЭЕФЧщПіЯТЃЌЮвУЧПЩвдВЩгУЪЕЬхНЈФЃЕФЗНЗЈЃЌКЭПЭЛЇвЛЦ№РэЧхећИівЕЮёЕФФЃаЭЃЌНјааСьгђИХФюФЃаЭЕФЛЎЗжЃЌГщЯѓГіОпЬхЕФвЕЮёИХФюЃЌНсКЯПЭЛЇЕФЪЙгУЬиЕуЃЌЭъШЋПЩвдДДНЈГівЛИіЗћКЯздМКашвЊЕФЪ§ОнВжПтФЃаЭРДЁЃ
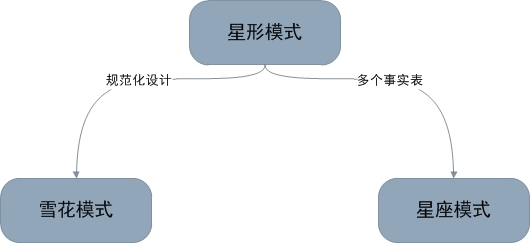
ЕЋЪЧЃЌЪЕЬхНЈФЃЗЈвВгазХздМКЯШЬьЕФШБЯнЃЌгЩгкЪЕЬхЫЕУїЗЈжЛЪЧвЛжжГщЯѓПЭЙлЪРНчЕФЗНЗЈЃЌвђДЫЃЌзЂЖЈСЫИУНЈФЃЗНЗЈжЛФмОжЯодквЕЮёНЈФЃКЭСьгђИХФюНЈФЃНзЖЮЁЃвђДЫЃЌЕНСЫТпМНЈФЃНзЖЮКЭЮяРэНЈФЃНзЖЮЃЌдђЪЧЗЖЪННЈФЃКЭЮЌЖШНЈФЃЗЂЛгГЄДІЕФНзЖЮЁЃ
вђДЫЃЌБЪепНЈвщЖСепдкДДНЈздМКЕФЪ§ОнВжПтФЃаЭЕФЪБКђЃЌПЩвдВЮПМЪЙгУЩЯЪіЕФШ§жжЪ§ОнВжПтЕУНЈФЃЗНЗЈЃЌдкИїИіВЛЭЌНзЖЮВЩгУВЛЭЌЕФЗНЗЈЃЌДгЖјФмЙЛБЃжЄећИіЪ§ОнВжПтНЈФЃЕФжЪСПЁЃ
ЮЌЖШНЈФЃЗЈЪ§ОнФЃаЭЕФЧјБ№
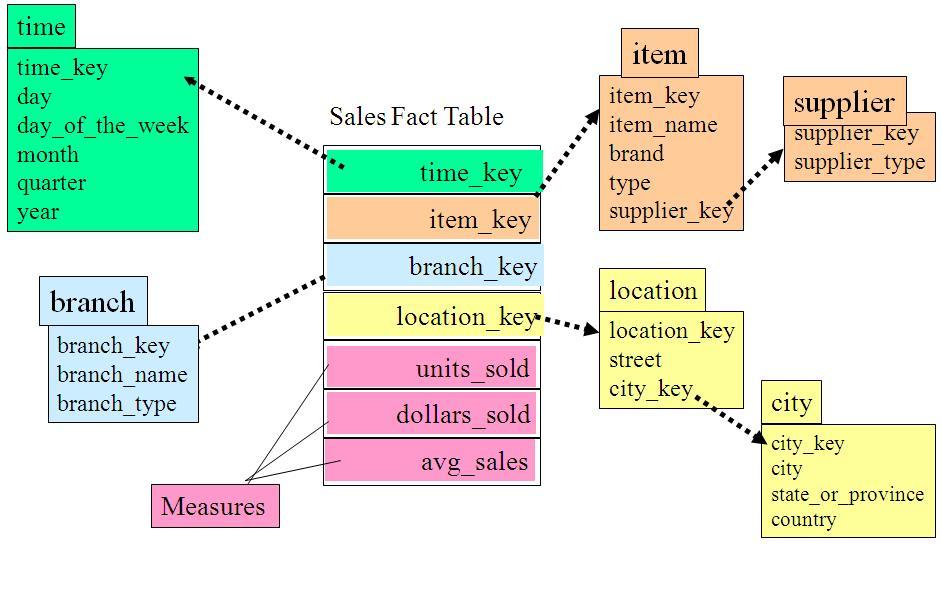
ЖрЮЌЪ§ОнФЃаЭЪЧзюСїааЕФЪ§ОнВжПтЕФЪ§ОнФЃаЭЃЌЖрЮЌЪ§ОнФЃаЭзюЕфаЭЕФЪ§ОнФЃЪНАќРЈаЧаЭФЃЪНЁЂбЉЛЈФЃЪНКЭЪТЪЕаЧзљФЃЪНЃЌБОЮФвдЪЕР§ЗНЪНеЙЪОШ§епЕФФЃЪНКЭЧјБ№ЁЃ
аЧаЭФЃЪНЃЈstar schemaЃЉ
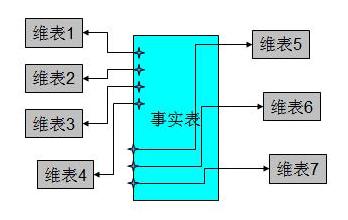
аЧаЭФЃЪНЕФКЫаФЪЧвЛИіДѓЕФжааФБэЃЈЪТЪЕБэЃЉЃЌвЛзщаЁЕФИНЪєБэЃЈЮЌБэЃЉЁЃаЧаЭФЃЪНЪОР§ШчЯТЫљЪОЃК
ПЩвдПДГіЃЌаЧаЮФЃЪНЕФЮЌЖШНЈФЃгЩвЛИіЪТЪЕБэКЭвЛзщЮЌБэГЩЃЌЧвОпгавдЯТЬиЕуЃК
a. ЮЌБэжЛКЭЪТЪЕБэЙиСЊЃЌЮЌБэжЎМфУЛгаЙиСЊЃЛ
b. УПИіЮЌБэЕФжїТыЮЊЕЅСаЃЌЧвИУжїТыЗХжУдкЪТЪЕБэжаЃЌзїЮЊСНБпСЌНгЕФЭтТыЃЛ
c. вдЪТЪЕБэЮЊКЫаФЃЌЮЌБэЮЇШЦКЫаФГЪаЧаЮЗжВМЃЛ
бЉЛЈФЃЪНЃЈsnowflake schemaЃЉ
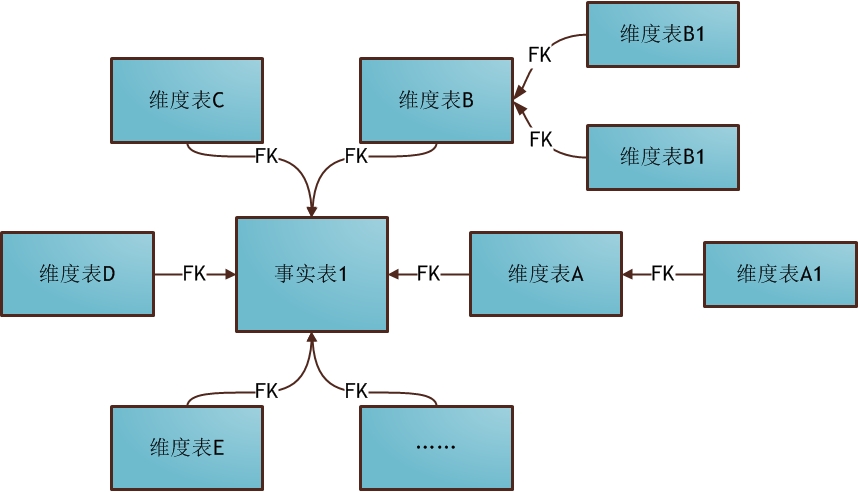
бЉЛЈФЃЪНЪЧаЧаЭФЃЪНЕФРЉеЙЃЌЦфжаФГаЉЮЌБэБЛЙцЗЖЛЏЃЌНјвЛВНЗжНтЕНИНМгБэЃЈЮЌБэЃЉжаЁЃбЉЛЈФЃЪНЪОР§ШчЯТЭМЫљЪОЃК
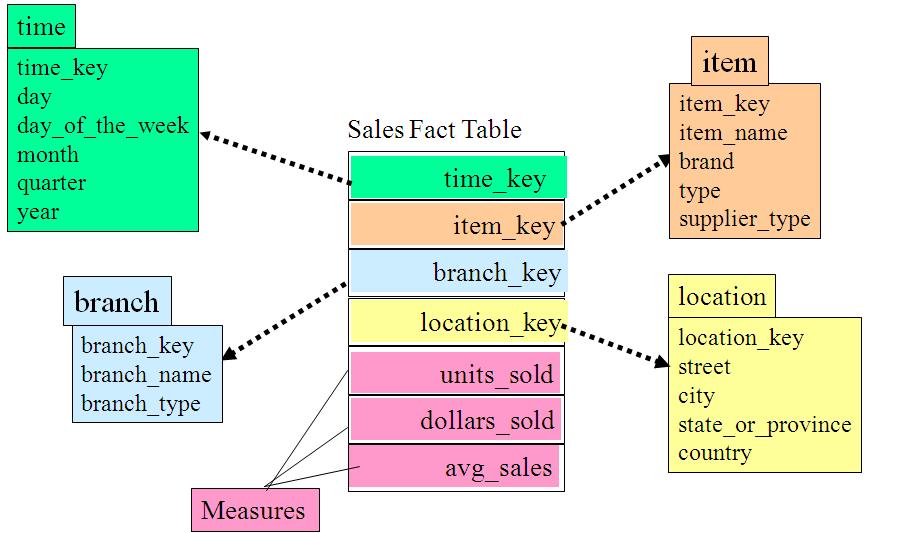
ДгЭМжаЮвУЧПЩвдПДЕНЕижЗБэБЛНјвЛВНЯИЗжГіСЫГЧЪаЃЈcityЃЉЮЌЁЃsupplier_typeБэБЛНјвЛВНЯИЗжГіРДsupplierЮЌЁЃ
аЧаЮФЃЪНжаЕФЮЌБэЯрЖдбЉЛЈФЃЪНРДЫЕвЊДѓЃЌЖјЧвВЛТњзуЙцЗЖЛЏЩшМЦЁЃбЉЛЈФЃаЭЯрЕБгкНЋаЧаЮФЃЪНЕФДѓЮЌБэВ№ЗжГЩаЁЮЌБэЃЌТњзуСЫЙцЗЖЛЏЩшМЦЁЃШЛЖјетжжФЃЪНдкЪЕМЪгІгУжаКмЩйМћЃЌвђЮЊетбљзіЛсЕМжТПЊЗЂФбЖШдіДѓЃЌЖјЪ§ОнШпгрЮЪЬтдкЪ§ОнВжПтРяВЂВЛбЯжиЁЃ
ЪТЪЕаЧзљФЃЪНЃЈFact ConstellationЃЉЛђаЧЯЕФЃЪНЃЈgalaxy schemaЃЉ
Ъ§ОнВжПтгЩЖрИіжїЬтЙЙГЩЃЌАќКЌЖрИіЪТЪЕБэЃЌЖјЮЌБэЪЧЙЋЙВЕФЃЌПЩвдЙВЯэЃЌетжжФЃЪНПЩвдПДзіаЧаЭФЃЪНЕФЛуМЏЃЌвђЖјГЦзїаЧЯЕФЃЪНЛђепЪТЪЕаЧзљФЃЪНЁЃБОФЃЪНЪОР§ШчЯТЭМЫљЪОЃК
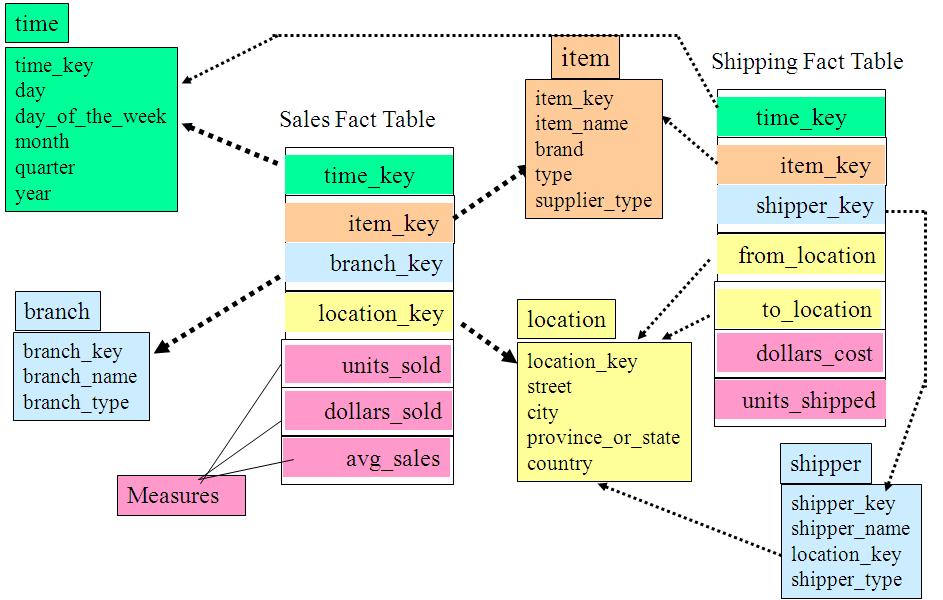
ШчЩЯЭМЫљЪОЃЌЪТЪЕаЧзљФЃЪНАќКЌСНИіЪТЪЕБэЃКsalesКЭshippingЃЌЖўепЙВЯэЮЌБэЁЃ
ЪТЪЕаЧзљФЃЪНЪЧЪ§ОнВжПтзюГЃЪЙгУЕФЪ§ОнФЃЪНЃЌгШЦфЪЧЦѓвЕМЖЪ§ОнВжПтЃЈEDWЃЉЁЃ
ЧАУцНщЩмЕФСНжжЮЌЖШНЈФЃЗНЗЈЖМЪЧЖрЮЌБэЖдгІЕЅЪТЪЕБэЃЌЕЋдкКмЖрЪБКђЮЌЖШПеМфФкЕФЪТЪЕБэВЛжЙвЛИіЃЌЖјвЛИіЮЌБэвВПЩФмБЛЖрИіЪТЪЕБэгУЕНЁЃдквЕЮёЗЂеЙКѓЦкЃЌОјДѓВПЗжЮЌЖШНЈФЃЖМВЩгУЕФЪЧаЧзљФЃЪНЁЃ
етвВЪЧЪ§ОнВжПтЧјБ№гкЪ§ОнМЏЪаЕФвЛИіЕфаЭЕФЬиеїЃЌДгИљБОЩЯЖјбдЃЌЪ§ОнВжПтЪ§ОнФЃаЭЕФФЃЪНИќЖрЪЧЮЊСЫБмУтШпгрКЭЪ§ОнИДгУЃЌЬзгУЯжГЩЕФФЃЪНЃЌЪЧЩшМЦЪ§ОнВжПтзюКЯРэЕФбЁдёЁЃ
Ш§жжФЃЪНЖдБШ
ЙщФЩвЛЯТЃЌаЧаЮФЃЪН/бЉЛЈФЃЪН/аЧзљФЃЪНЕФЙиЯЕШчЯТЭМЫљЪОЃК
ЪЕР§
дкНјааЮЌЖШНЈФЃЧАЃЌЪзЯШвЊСЫНтгУЛЇашЧѓЁЃЖјБЪепдкЪ§ОнПтЯЕСаЕФЕквЛЦЊОЭНВЙ§ЃЌERНЈФЃЪЧЕБЧАЪеМЏКЭПЩЪгЛЏашЧѓЕФзюМбММЪѕЁЃвђДЫМйЖЈКЭФГСуЪлЙЋЫОНјааЖрДЮашЧѓPKКѓЃЌЕУЕНвдЯТERЭМЃК
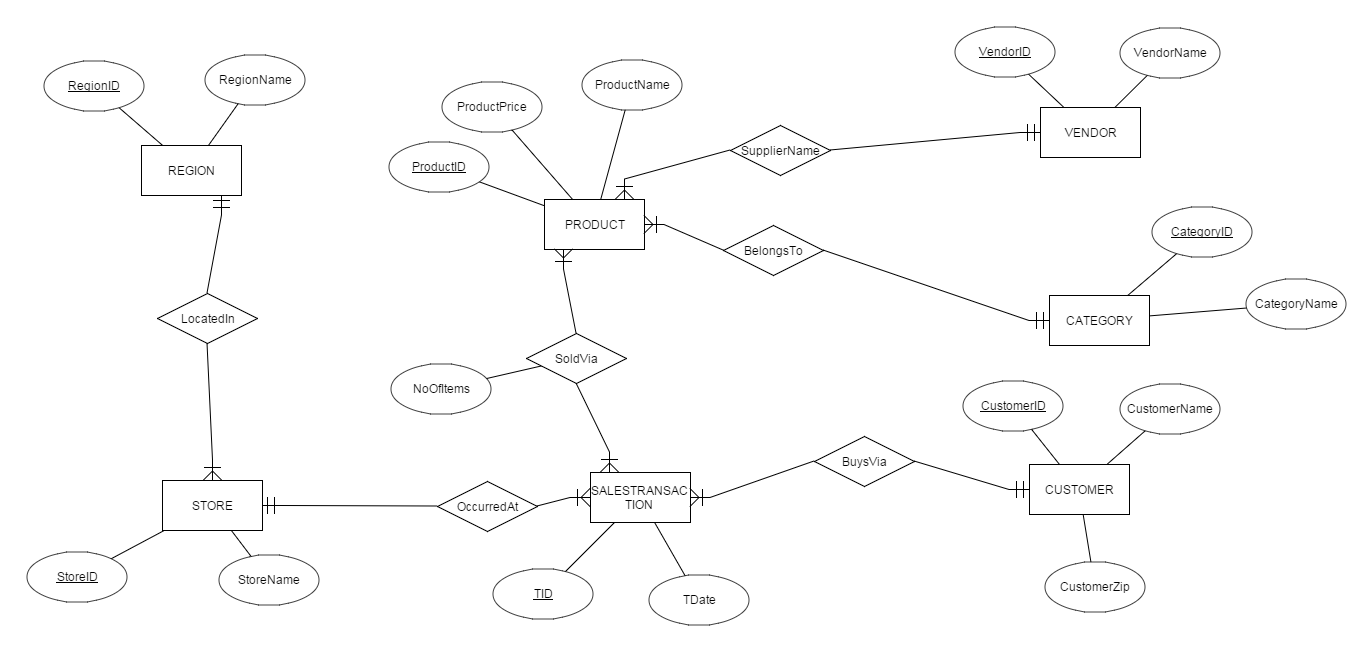
ЫцКѓПЩРћгУНЈФЃЙЄОпНЋERЭМжБНггГЩфЕНЙиЯЕЭМЃК
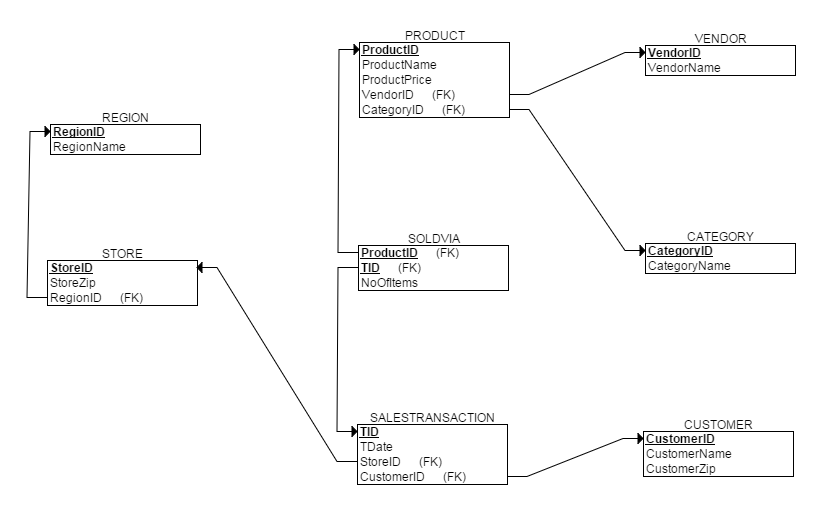
ашЧѓЫбМЏЭъБЯКѓЃЌБуПЩНјааЮЌЖШНЈФЃСЫЁЃБОР§ВЩгУаЧаЮФЃаЭЮЌЖШНЈФЃЁЃЕЋВЛТлВЩШЁКЮжжФЃЪНЃЌЮЌЖШНЈФЃЕФЙиМќдкгкУїШЗЯТУцЫФИіЮЪЬтЃК
1.ФФаЉЮЌЖШЖджїЬтЗжЮігагУЃП
БОР§жаЃЌИљОнВњЦЗ(PRODUCT)ЁЂЙЫПЭ(CUSTOMER)ЁЂЩЬЕъ(STORE)ЁЂШеЦк(DATE)ЖдЯњЪлЖюНјааЗжЮіЪЧЗЧГЃгаАяжњЕФЃЛ
2.ШчКЮЪЙгУЯжгаЪ§ОнЩњГЩЮЌБэЃП
a. ЮЌЖШPRODUCTПЩгЩЙиЯЕPRODUCTЃЌЙиЯЕVENDORЃЌЙиЯЕCATEGORYСЌНгЕУЕНЃЛ
b. ЮЌЖШCUSTOMERКЭЙиЯЕCUSTOMERЯрЭЌЃЛ
c. ЮЌЖШSTOREПЩгЩЙиЯЕSTROEКЭЙиЯЕREGIONСЌНгЕУЕНЃЛ
d. ЮЌЖШCALENDARгЩЙиЯЕSALESTRANSACTIONжаЕФTDateСаЗжРыЕУЕНЃЛ
3.гУЪВУДжИБъРДЁБЖШСПЁБжїЬтЃП
БОР§ЕФжїЬтЪЧЯњЪлЃЌЖјЯњСПКЭЯњЪлЖюетСНИіжИБъзюФмжБЙлЗДгГЯњЪлЧщПіЃЛ
4.ШчКЮЪЙгУЯжгаЪ§ОнЩњГЩЪТЪЕБэЃП
ЯњСПКЭЯњЪлЖюаХЯЂПЩвдгЩЙиЯЕSALESTRANSACTIONКЭЙиЯЕSOLDVIAЃЌЙиЯЕPRODUCTСЌНгЕУЕНЃЛ
УїШЗетЫФИіЮЪЬтКѓЃЌБуФмЧсЫЩЭъГЩЮЌЖШНЈФЃЃК
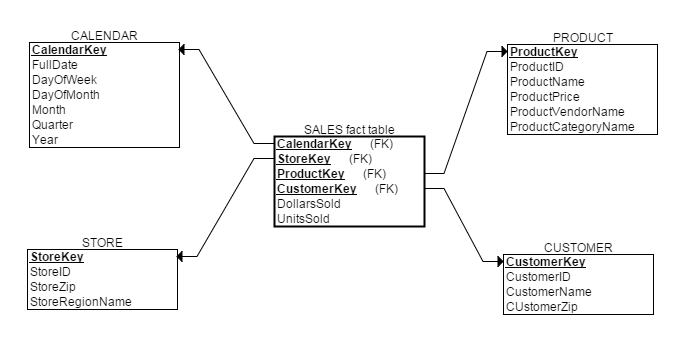
ЯИаФЕФЖСепЛсЗЂЯжШ§ИіЮЪЬтЃК1. ЮЌБэВЛТњзуЙцЗЖЛЏЩшМЦ(ВЛТњзу3NF)ЃЛ2. ЪТЪЕБэвВВЛТњзуЙцЗЖЛЏЩшМЦ(1NFЖМВЛТњзу)ЃЛ
3. ЮЌЖШНЈФЃжаИїЮЌЖШЕФжїТыгЩ***IDБфГЩ***KeyЃЛ
ЖдгкЧАСНИіЮЪЬтЃЌгЩгкЕБЧАНЈФЃЛЗОГЪЧЪ§ОнВжПтЃЌЖјУЛгаИќаТВйзїЃЌЫљвдВЛашвЊбЯИёзіЙцЗЖЛЏЩшМЦРДЯћГ§ШпгрБмУтИќаТвьГЃЁЃ
вђДЫЫфШЛПЩвдвдбЉЛЈФЃаЭНјааЮЌЖШНЈФЃЃЌШчЯТЫљЪОЃК
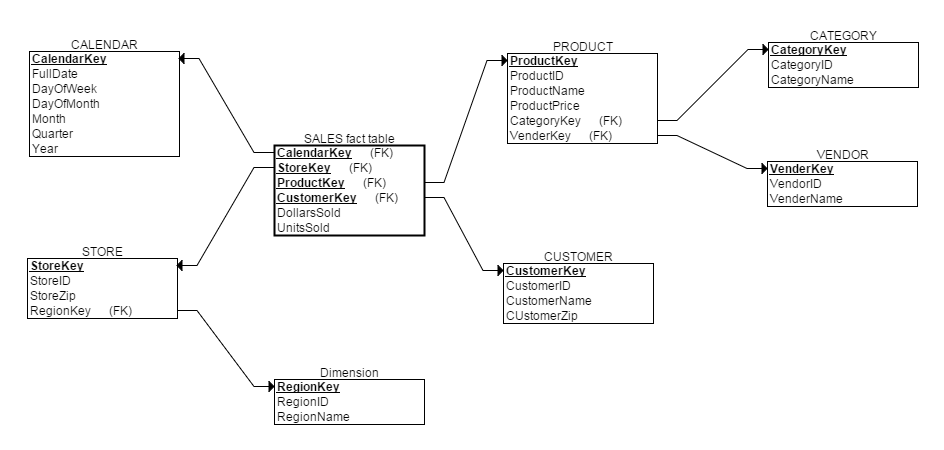
ЕЋетбљЛсМгДѓВщбЏШЫдБИКЕЃЃКУПДЮВщбЏЖМЩцМАЕНЬЋЖрБэСЫЁЃвђДЫдкЪЕМЪгІгУжаЃЌбЉЛЈФЃаЭНіЪЧвЛжжРэТлЩЯЕФФЃаЭЁЃаЧзљФЃаЭдђГіЯждкЁБЮЌЖШНЈФЃЪ§ОнВжПтЁБжаЃЌБОЮФКѓУцНЋЛсНВЕНЁЃ
ЖдгкЕкШ§ИіЮЪЬтЃЌ***KeyетбљЕФзжЖЮБЛГЦЮЊДњРэТы(surrogate key)ЃЌЫќЪЧвЛИіЭЈЙ§здЖЏЗжХфећЪ§ЩњГЩЕФжїТыЃЌУЛгаШЮКЮЦфЫћвтвхЁЃЪЙгУЫќжївЊЪЧЮЊСЫФмЙЛДІРэЁБЛКТ§БфЛЏЕФЮЌЖШЁБЁЃ
ОЕфаЧзљФЃаЭ
ЧАЮФвбОНВЙ§ЃЌгаЖрИіЪТЪЕБэЕФЮЌЖШФЃаЭБЛГЦЮЊаЧзљФЃаЭЁЃаЧзљФЃаЭжївЊгавдЯТСНДѓзїгУЃКЙВЯэЮЌЖШКЭЩшжУЯИНк/ОлМЏЪТЪЕБэЁЃЯТУцЗжБ№ЖдетСНжжЧщПіНјааЗжЮіЃК
1.ЙВЯэЮЌЖШ
вдЧАЮФЬсЕНЕФСуЪлЙЋЫОЮЊР§ЃЌМйШчИУЙЋЫОжЪСПМрЙмВПУХЯЃЭћгУЗжЮіЯњЪлжїЬтЭЌбљЕФЗНЗЈЗжЮіСгжЪВњЦЗЃЌФЧУДДЫЪБВЛашвЊжиаТЮЌЖШНЈФЃЃЌжЛашЭљФЃаЭРяМгШывЛИіаТЕФСгжЪВњЦЗЪТЪЕБэЁЃжЎКѓаТЕФЪ§ОнВжПтЮЌЖШНЈФЃНсЙћШчЯТЃК
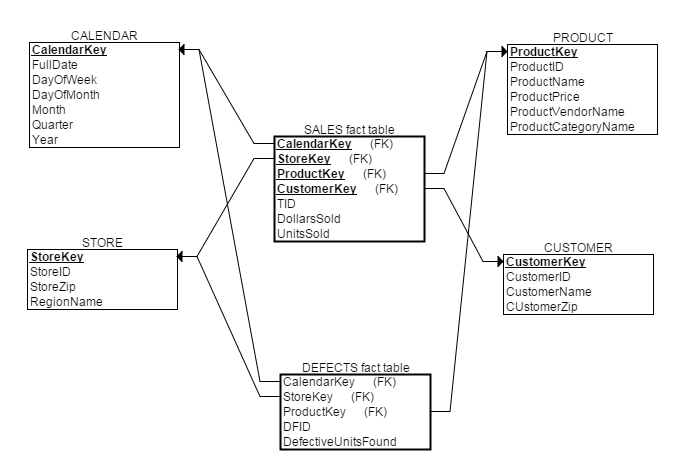
2.ЯИНк/ОлМЏЪТЪЕБэ
ЯИНкЪТЪЕБэ(detailed fact tables)жаУПЬѕМЧТМБэЪОЕЅвЛЪТЪЕЃЌЖјОлМЏЪТЪЕБэ(aggregated
fact tables)жаУПЬѕМЧТМдђОлКЯСЫЖрЬѕЪТЪЕЁЃДгБэЕФзжЖЮЩЯПДЃЌЯИНкЪТЪЕБэЭЈГЃгаЩшжУTIDЪєадЃЌЖјОлМЏЪТЪЕБэдђЮоЁЃ
СНжжЪТЪЕБэИїгагХШБЕуЃЌЯИНкЪТЪЕБэВщбЏСщЛюЕЋЪЧЯьгІЫйЖШЯрЖдТ§ЃЌЖјОлМЏЪТЪЕБэЫфШЛЬсИпСЫВщбЏЫйЖШЃЌЕЋЪЙВщбЏЙІФмЪмЕНвЛЖЈЯожЦЁЃвЛИіГЃМћЕФзіЗЈЪЧЪЙгУаЧзљФЃаЭЭЌЪБЩшжУСНжжЪТЪЕБэ(ПЩКЌЖрИіОлМЏЪТЪЕБэ)ЁЃетжжЩшМЦЗНЗЈжаЃЌОлМЏЪТЪЕБэЪЙгУКЭЯИНкЪТЪЕБэЯИНкЪТЪЕБэЕФЮЌЖШЁЃШчЯТЮЌЖШНЈФЃЗНЗЈВЩгУаЧзљФЃаЭзлКЯСЫЯИНкЪТЪЕБэКЭСНжжОлМЏЪТЪЕБэЃК
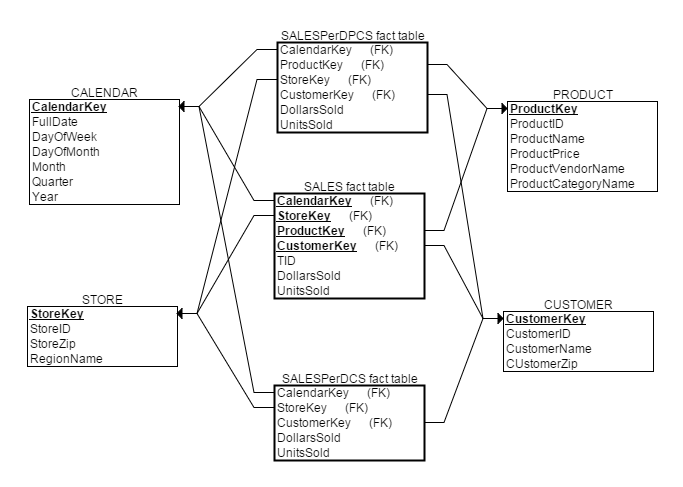
|









