随着信息量的不断增长,企业数据仓库的数据量也随着日常生产和业务处理的增长而不断增加,这随之对数据仓库的性能和存储容量提出了更高的要求。IBM
DB2 数据库以其特有的数据库分区技术和数据压缩技术,为企业数据量的不断增长提供了出众的解决方案。当前,已有很多企业客户迁移到
IBM DB2 数据库用以适应其自身不断增长的业务需要。本文将着重介绍在数据仓库迁移中的 ETL 过程和数据加载的迁移方法,并且以真实客户迁移为例,向读者介绍了如何通过与
Teradata Automation Server 的集成来完成数据仓库的 ETL 和 LOAD 迁移。
引言
随着信息量的不断增长,企业数据仓库的数据量也随着日常生产和业务处理的增长而不断增加,这随之对数据仓库的性能和存储容量提出了更高的要求。IBM
DB2 数据库以其特有的数据库分区技术和数据压缩技术,为企业数据量的不断增长提供了出众的解决方案。当前,已有很多企业客户迁移到
IBM DB2 数据库用以适应其自身不断增长的业务需要。
对于典型的数据仓库的迁移,迁移的工作量主要集中在对 ETL 的迁移,正如同数据仓库的建设,工作量集中在
ETL 过程的实现一样。下文将着重介绍由 Teradata 数据仓库迁移到 DB2 中的 ETL 和加载(LOAD)迁移部分。本文以真实客户为例,详细介绍在数据仓库迁移中的
ETL 和加载(LOAD)的迁移方法,并通过实例来进一步说明如何实现从 Teradata 到 DB2 的迁移。关于
Teradata 数据仓库迁移的概述和 Teradata 数据仓库的数据对象迁移,请参考《从 Teradata
迁移到 IBM DB2 数据仓库》文章一。
Teradata 自动化调度工具简介
对于典型的数据仓库的迁移,例如从 Teradata 到 DB2 的迁移过程,迁移的工作量主要集中在对 ETL
的迁移,正如同数据仓库的建设,工作量集中在 ETL 过程的实现一样。
数据仓库 ETL 过程(Extraction, Transformation and Load)是将原始数据从业务数据库或其他数据源进行抽取,转换并最终加载到用于分析的数据仓库模型中的过程。对于一般的数据仓库系统,通常我们需要进行
ETL 转换,因为我们需要将来自于不同数据源的原始数据进行清洗,转换和聚合,将它们转换成易于进行分析的数据仓库数据。具体来讲,ETL
的不同阶段指:
1.取(Extract)是将数据从源数据系统抽取到目标数据仓库中,通常抽取可能会涉及到从多个源数据系统中提取数据。
2.转换(Transform)是将已经抽取到数据仓库中根据一系列或者多个层次的规则进行转换,使它成为数据仓库模型能够接受的模式。
3.加载(Load)是将转换后的数据最终加载到用于分析的数据模型中。
对于 ETL 过程,其实质上是使用 SELECT,INSERT 或者 DELETE 语句将数据从最底层的原始数据表转换为数据仓库的用于分析的数据仓库模型的过程。通常,我们使用自动化工具来自动化
ETL 过程。其意义在于,一旦我们定义了数据的 ETL 过程,那么自动化工具会在每晚或者在指定的时间内,将原始数据自动的清理并转换为数据仓库的数据格式,并最终导入到数据仓库的表中供今后分析使用。在数据仓库环境的建立过程中,ETL
自动化工具的好坏不但在构建初期会决定数据仓库项目能否顺利进行,同时也会影响到系统的后期维护的易用性上。在
Teradata 构建的系统中,其通常使用 Teradata 自动化工具和 Perl 脚本来完成 ETL
过程。
Teradata 自动化调度工具(ETL Automation)是指在 Teradata 数据仓库中,Teradata
自动化调度工具能够让许多作业在执行条件满足时自动的去执行这些操作。这其中包括了可能需要接受一些文档来做数据加载工作的作业,或者是做一些数据整合的工作。而这些工作在执行时可能还会有一定的条件限制等等。
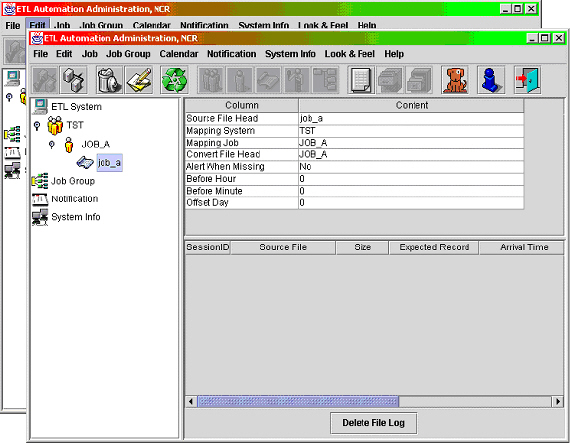
图 1. ETL Automation 工具
在 ETL Automation 机制当中提供了图形操作界面 (GUI) 的监控程序。如上图 1 所示。透过此监控程序你可以实时看到目前在
ETL Automation 中有哪些作业正在等待状态中 (Pending),以及有哪些作业正在执行中
(Running)。除此之外,你还可以透过监控程序看到 ETL Automation 机制在某些状况下所产生的例外事件
(Event) 以便你能够实时地采取对应措施。
在《从 Teradata 迁移到 IBM DB2 数据仓库》系列一中我们已经提到,在从 Teradata
到 DB2 的迁移过程中,我们可以继续沿用原 Teradata 系统中的 Teradata Automation
工具。同时,也可以使用 IBM DataStage 或 SQW 来完成相应的功能。
本文主要着重于使用继续沿用原有的 Teradata Automation 工具。因此,这就涉及到我们需要进行
DML 迁移,即 ETL 过程中 Perl 脚本的迁移,同时完成从 Teradata 到 DB2 的数据加载并驱动
Teradata 自动化工具进行 ETL 过程。下面我们将就这两个方面进行分别的讨论。
DML 迁移方案
在 Teradata 数据仓库中,其数据仓库各个层次之间的 ETL 过程是通过 Perl 脚本来进行的,如下图
2 所示。Perl 脚本主要是用于在数据仓库内部各层次之间的数据抽取、清理和转换。同时,我们使用 Teradata
自动化工具驱动 Perl 脚本进行工作。例如 Staging 区到中间层的 PDM 层,由 PDM 层到上层的
BIC 层,其都是由 Perl 脚本在自动化调度工具(Automation Server)的控制下来完成各层次之间的数据抽取和加载。由于
Perl 脚本中主要为对数据库的 INSERT,UPDATE 和 DELETE 操作,所以我们又把对 Perl
脚本的迁移称为 DML(Database Manipulation Language)迁移。
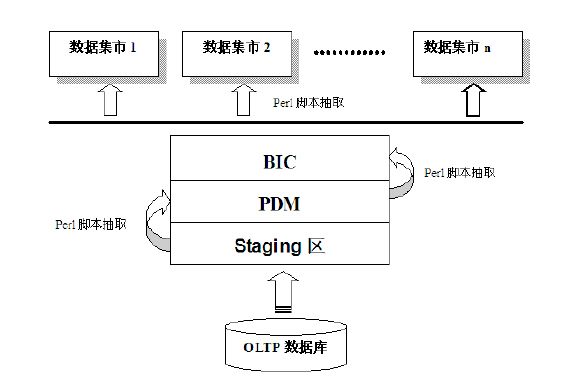
图 2. 典型数据仓库中的 ETL 过程
对于企业在进行 DML 迁移时,遇到的主要问题是:
1. 我们需要找到 Teradata DML 语言与 DB2 DML 语言的映射关系。对于不同的数据库厂商,其
DML 语言在符合标准 SQL 语法的同时,总会有其细微的差别。因此,我们需要找到 Teradata 与
DB2 数据库之间的映射关系。
2. 对典型的 Teradata 数据仓库系统来说,其包含大量的 DML 脚本,即 Perl 脚本。
3. 如何保证当前 Teradata 数据仓库下的 DML 脚本能够在 DB2 平台下正常使用,并且保证迁移后的脚本能够保持其原有功能。
DML(Data Manipulation Language)脚本迁移方案
为了保证转换后 DML 脚本转换后的可用性和一致性,我们使用如下原则进行转换:
1.保证原有功能的正确运行
2.DML 脚本和其他程序流程尽少改变
3.DML 脚本或其他文件尽量少进行修改
4.转换过程可以模式化
原有 Teradata 系统使用 Perl 脚本的 ETL 过程根据不同的应用有以下 2 种典型方式。第一种方式是使用在
ETL 的 Perl 脚本中嵌入 SQL 语句的方式来完成各层之间的 ETL 过程。如下图 3 所示。
图 3. Perl 脚本中嵌入 SQL 的方式
第二种方式是将调用底层数据库的接口进行封装,上层的 ETL 脚本通过调用底层的 Perl 程序来执行 SQL
语句。如下图 4 所示。
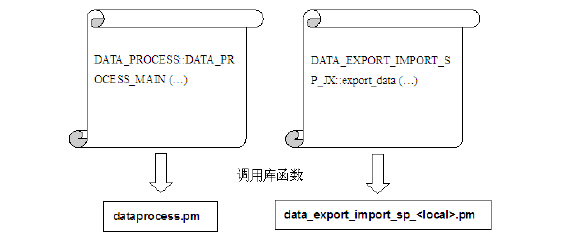
图 4. Perl 脚本调用底层函数执行
SQL 语句
实际上,无论是采用嵌入式的 SQL 的 Perl 脚本,还是在底层进行了函数封装。对于 DB2 的迁移来说,我们本质上还是要将
ETL 的 Perl 脚本中和 Teradata 相关的命令和 SQL 语句, 转换为 DB2 支持的语句。
迁移方案实现细节
对于原 TD 系统不同调用方式,它们的程序流程也有所不同。在确定转换策略前,我们需要了解原 TD 系统中不同
Perl 脚本和 Teradata SQL 的调用方式。
1. 底层数据库接口进行封装
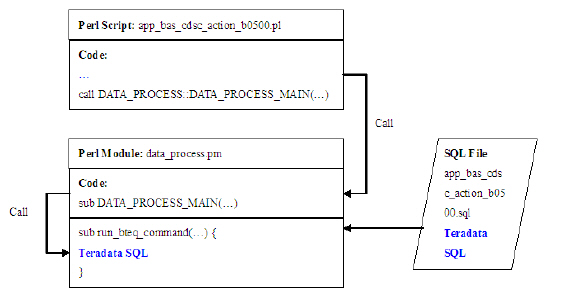
图 5. Perl 脚本调用底层函数方式
每一个 Perl 脚本会去调用 data_process.pm 中的 run_bteq_command()
函数,如上图 5 所示。此函数会被调用用来执行外部的一个 SQL 文件。对于此种方式执行的 perl SQL,
我们需要对 run_bteq_command 函数和相关的 SQL 文件进行修改,将 Teradata
SQL 转为 DB2 支持的 SQL。
2. 读取自身 Perl 脚本中的嵌入 SQL

图 6. Perl 脚本调用嵌入 SQL
的方式
由上图 6 可见,Perl 脚本会调用脚本中的 run_bteq_command 去执行嵌入在此函数中的
SQL 语句。因此我们需要对其中的嵌入的 SQL 进行改写,将相关的 Teradata SQL 转换成
DB2 SQL。
由于 Teradata 的 SQL 在某些细节上和 DB2 的 SQL 应用有细微的区别,因此我们需要对这些有变化的
SQL 进行改写,下表给出了常用的 SQL 语句在 Teradata 和 DB2 上的对应表。由于篇幅有限,
这里仅列出那些典型的转换语句,表中的蓝色字体为 Teradata 与 DB2 所不同的 SQL 语法。
表 1. SELECT / INSERT / UPDATE 语句对应表
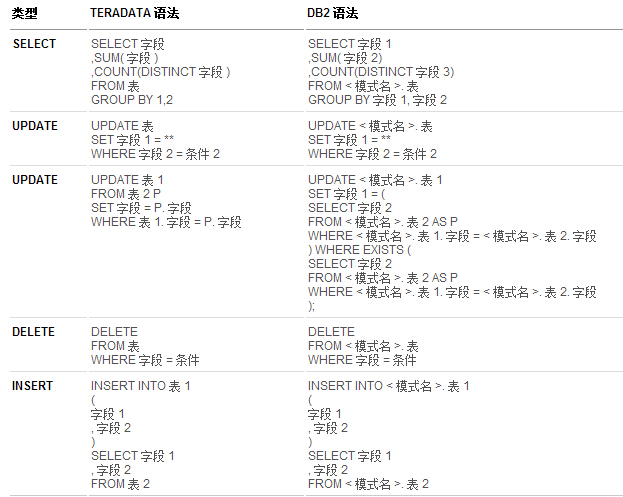
表 2. CREATE TABLE 语句对应表

表 3. 常用函数对应表
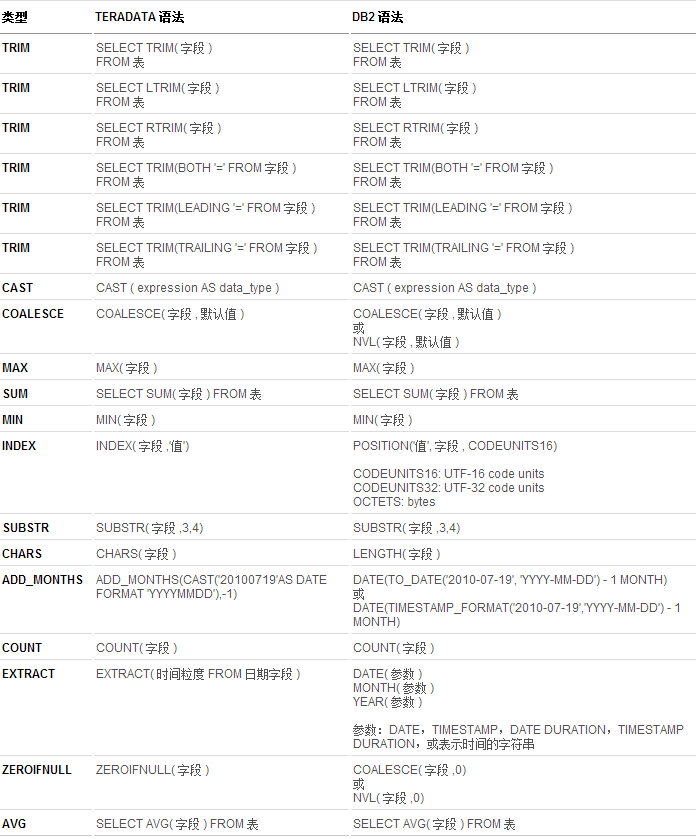
值得一提的是,对于在实际项目中的具体转换策略来说,即如何由 Teradata
SQL 转换为 DB2 支持的 SQL,我们有更加具体的文档指导客户进行转换。同时, 我们也提供了针对不同调用方式的
DB2 下的 perl SQL 模板。这里由于篇幅限制就不一一列举了。
数据扫描加载方案介绍
如在《从 Teradata 迁移到 IBM DB2 数据仓库》系列文章一中所提到的,数据迁移是整个数据库迁移中非常重要的一环。我们需要保证原
Teradata 中的数据被无损的,快速的装载到 数据仓库。因此我们提供了数据扫描和加载的通用程序,来完成
Teradata 数据库到 DB2 的数据迁移工作。本节会做详细的介绍。
数据扫描加载的目的不同于 DML 脚本,即在上文提到的 Perl 脚本迁移。与 DML 用在处理数据仓库内部的转换和加载不同,数据扫描和加载是用于将外部数据源中的数据,
如将业务数据库中的数据(Teradata,Oracle 中的数据)加载到数据仓库的表中,即在 ETL 过程中我们提到的数据抽取过程。如图
2 中由 OLTP 加载到 Staging 区。同时, 我们使用扫描程序定时扫描由业务数据库中卸载的文件,并且扫描程序会根据预先设定的时间,每晚、每月或者在指定的时间驱动
Teradata 自动化测试工具完成由业务数据库 到数据仓库的数据加载。
实际上,对于外部数据的扫描和加载,我们也是使用的 Perl 脚本来完成外部数据的加载过程。所不同的是,在这里我们并不像
DML 脚本那样对过去已有的 Perl 脚本进行迁移, 而是使用通用的加载(Load)和扫描(Scan)工具来进行外部数据的加载。此工具是由
IBM 中国 Avalanche 团队开发,其用于将外部数据抽取到数据仓库内部的表中(如 Staging
区或 PSA 区), 同时此工具可以驱动 Teradata 自动化工具进行自动的数据加载。其具有很高的模块化和可定制性,可针对不同的需求和加载方式进行快速的定制,使此加载和扫描程序能适应当前的需要。
此工具目前已经在某电信行业的项目实践得到应用,并取得了非常好的迁移成果。
方案介绍
在数据仓库的某一数据层上,Teradata 将这个层面上所有的表按照指定(固定)的时间卸成文本文件传递到
DB2 所在的系统上。对于 DB2 数据仓库系统,就等于得到了这些数据文件, 并把它们装载到结构相同的
DB2 数据库表中。在这个层面以上的部分,则通过迁移到 DB2 环境下的 ETL 脚本,根据相互的依赖关系,经过层层处理,最后使得整个数据仓库的数据得
到更新,支持了分析应用的运行。
通常,对于数据仓库系统,其需要从业务系统中抽取某日或某月的业务数据,并将其以全量或者增量的方式加载到数据仓库中。简单的流程如下图
7 所示。
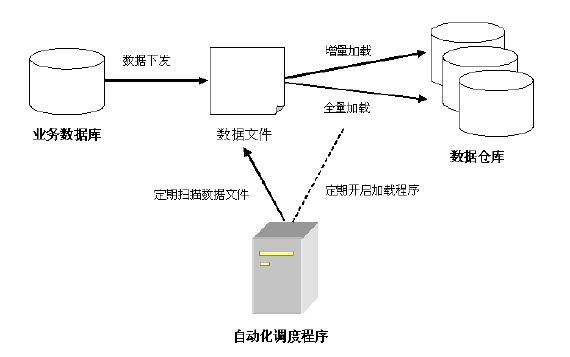
图 7. 数据扫描加载方案
其中,业务数据库即可以是 DB2 数据库,也可以是 Teradata 数据库。其数据定期的(每天或者每月)下发到服务器上的指定目录。每天,在自动调度程序(Automation
Server) 的调度下,通过我们的通用加载程序,将数据以增量、全量或者其他自定义的方式加载到数据仓库中。之后数据经过
ETL 处理,最终可以通过数据仓库的展现程序对外展现信息。
加载实现模式
如《从 Teradata 迁移到 IBM DB2 数据仓库》系列文章一中提到的,在 ETL 工具和 Perl
脚本迁移过程中,我们可以选择 2 种方式:
方式一,继续沿用 Teradata Automation 工具,工作重点是迁移大量的 Perl 脚本。
方式二,放弃 Teradata Automation 工具,使用 IBM DataStage 或 SQW,工作重点是编写新的
ETL 脚本来实现业务逻辑。
根据客户的具体需求和系统的实际情况,我们可以选择使用第一种方式或者第二种方式。在本节中,我们着重介绍采用第一种方式,即还延续使用
Teradata Automation 工具的方式来做后期的加载和 ETL 过程,这样我们可以保证对原有系统进行较小的变化,即可完成从
Teradata 到 DB2 的迁移。
因此,对于我们的加载程序来说,它包括两个部分。
扫描程序:它用来定期扫描从业务数据库下载的数据文件,并通知 Teradata Automation 工具何时进行加载。
加载程序:加载程序提供了最基本的增量,全量等加载模式,可以根据需要在 Teradata Automation
工具中进行任意配置。同时,其还提供给了客户可以自定义加载模式的方法。
扫描程序
根据需求,我们进行扫描程序的设计,这个程序是我们数据仓库的入口控制程序。则扫描程序会:
1 .扫描程序会定期的去扫描数据下发后生成的标识文件。当某天或者某月的数据完成下发后,则此表示文件会生成在该下发文件的文件夹中。扫描程序会通过
ftp 的方式去扫描各个远程服务器上的标识文件。
2 .当扫描程序启动后,扫描程序会每天启动一次,由操作系统自动在凌晨启动。当然,此扫描程序的启动频率我们可以自行进行设置。该程序启动的时候可以将业务日期作为参数,使得该扫描程序只负责扫描当天需要装载的数据标识文件。为了安全起见,该程序在启动时会检查是否还有前一天的扫描程序在运行。如果有前一天的扫描程序在运行,则报错并退出。
3 .当扫描程序扫描到某个数据文件标识存在,即表明此数据文件已经下发成功,则扫描程序就会通过 SOCKET
消息通知 Teradata Automation 程序开始此数据的加载工作。这时,Teradata Automation
会根据自身配置的加载方式,去调用加载程序将相应的数据加载到生产表中。
加载程序
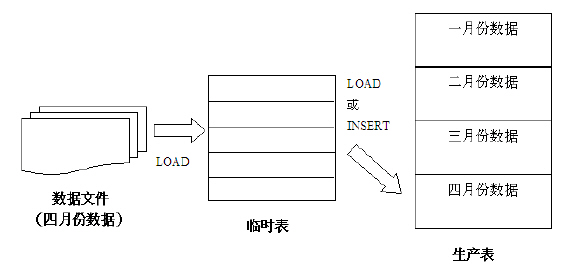
图 8. 数据加载示例
数据加载过程如上图 8 所示。在加载程序中,我们使用如下的一些原则进行设计。
1.易扩展的数据加载模式
在加载程序中,所有的数据加载,和数据库相关的 LOAD,INSERT,DELETE 等操作,创建临时表的操作等均进行了封装。所有通用的操作都被封装为可以被单独调用的程序。如程序
1 所示。
清单 1. 示例代码 Base_Load.pm
# 加载模式可以使用的通用函数 sub Create_Temp_Table (...) sub Load_Temp_Data (...); sub Transfer (...); ... |
我们只需在外部定义的不同的加载模式中,如增量加载,全量加载等实现中,调用这些最基本的函数就可以实现不同的加载模式,因此达到了加载模式的可扩展性。
2.外部调用方式和加载控制表
加载程序对外提供统一的调用接口 Table_Load.pl <Table_ID>,如 Automation
Server 可以通过此接口命令调用不同的 Load 程序进行数据加载。对于不同的表,采用何种加载控制方式等信息,
我们都通过维护加载控制表来进行控制和调整。
3.出错处理和数据一致性
加载程序可以提供出错处理和数据一致性维护。针对不同的加载方式,在加载时,首先进行数据一致性维护。当读取数据文件到临时表失败,程序会退出。加载数据到生产表中失败,
数据一致性恢复,程序退出。
4.源代码组织结构
源代码组织结构如下图 9 所示。其中,table_load.pl 提供了上面我们提到的统一调用接口,table_load.pl
会根据加载控制表中的信息来进一步的调用不同的加载模式,如在本例中, Load_w.pl 对应全量加载,Load_a.pl
对应增量加载,以及 Load_m.pl,Load_x.pl 以及 Load_x.pl 等加载脚本,它们分别对应着拉链加载,详单加载和订单加载。这
3 种加载方式是根据项目 的实际情况以 base_load.pm 为基础而根据客户需求定义出的特定加载方式。实际上,所有不同的加载脚本均是可以通过
base_load.pm 中的通用函数组合调用而成。
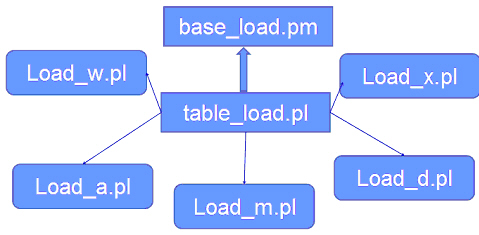
图 9. 源代码组织结构
5.源代码示例如下所示
清单 2. 示例代码 Table_Load.pl
# ----- 读取控制表信息 -------
sub Get_Table_Ctl {
...
}
#---- 根据不同加载模式,从 DAT 文件中 LOAD 信息 -----
sub Table_Load {
# 1. 全覆盖模式
if ($load_type eq "W") {
print "### Calling load_W.pl ###\n";
$rc = system("perl load_W.pl $Target_DB_Name $Target_Usr ...");
}
# 2. 纯附加模式
elsif ($load_type eq "A") {
print "### Calling load_A.pl ###\n";
$rc = system("perl load_A.pl $Target_DB_Name $Target_Usr ...");
}
# 3. 拉链模式
elsif ($load_type eq "M") {
print "### Calling load_M.pl ###\n";
$rc = system("perl load_M.pl $Target_DB_Name $Target_Usr ...");
}
# 4. 话费详单模式
elsif ($load_type eq "X") {
print "### Calling load_X.pl ###\n";
print "$Target_DB_Name $Target_Usr ..." );
}
# 5. 话费订单模式
elsif ($load_type eq "D") {
print "### Calling load_D.pl ###\n";
$rc = system("perl load_D.pl $Target_DB_Name $Target_Usr ...");
} |
清单 3. 示例代码 Table_A.pl
#----------- 开始进行增量加载 --------------
print "### START TO LOAD TABLE ${SCHEMA}.${TABNAME} AT ".&getNow()." ###\n";
# 1. 进行加载前的数据一致性维护
&Recover_Transfer_Load_A();
# 2. 删除临时加载表
&Drop_Temp_Table($DBNAME_TARGET, $USER_TARGET, ...);
# 3. 创建临时加载表,如果失败,则记录到 Log 文件并退出
$rc = &Create_Temp_Table($DBNAME_TARGET, $USER_TARGET, ...);
if ($rc eq 2 || $rc eq 4 || $rc eq 8) {
print "Failure on create temporary table ${SCHEMA_TMP}.${TABNAME_TMP}\n";
print "Waiting for re-run current job\n";
exit 1;
}
#4. 将数据文件中的数据加载到临时表中,如果失败,清理临时表并退出
$rc = &Load_Temp_Data($DBNAME_TARGET, $USER_TARGET, ...);
if ($rc eq 2 || $rc eq 4 || $rc eq 8) {
&Drop_Temp_Table($DBNAME_TARGET, $USER_TARGET, ...);
print "Failure on loading into temporary table ${SCHEMA_TMP}.${TABNAME_TMP}\n";
print "Waiting for re-run current job\n";
exit 1;
}
#5. 将临时表中的数据加载到正式的生产表中,如果失败,则对生产表数据进行一致性维护
$rc = &Transfer($DBNAME_TARGET, $USER_TARGET, ...");
if ($rc eq 2 || $rc eq 4 || $rc eq 8) {
&Recover_Transfer_Load_A();
&Drop_Temp_Table($DBNAME_TARGET, $USER_TARGET, ...);
print "Failure on transfer data into table ${SCHEMA}.${TABNAME}\n";
print "Waiting for re-run current job\n";
exit 1;
}
#6. 对生产表执行 RUNSTATS 操作
&Runstats($DBNAME_TARGET, $USER_TARGET, ...);
#7. 删除临时表
&Drop_Temp_Table($DBNAME_TARGET, $USER_TARGET, ...);
#-------- 结束进行增量加载 ---------
print "### FINISH TO LOAD TABLE ${SCHEMA}.${TABNAME} AT ".&getNow()." ###\n";
exit 0; |
结束语
本文是《从 Teradata 迁移到 IBM DB2 数据仓库》系列中的第二篇文章,本文介绍了从 Teradata
迁移到 DB2 数据库时所需要进行的 DML 迁移方法和数据加载实现。在本文中提到的方法已经在真实的迁移项目中得到验证,并被证明是行之有效的。限于本文篇幅,本文不能对
DML 迁移方法和数据加载进行详细的介绍,这里只能就其整体方法进行讨论,具体的细节问题留待读者进一步思考。
|






