使用
Teradata Connector 提取数据
本节将使用一个示例 ETL 作业来演示从名称为 Orders 的 Teradata 表中提取数据的步骤。图
17 展示了示例作业,它使用立即访问模式。作业使用名为 ExtractOrders 的 Teradata
连接器从 Orders 数据库读取订单。作业将转换提取的数据并将其传送到名为 SaveExtractedData
的序列文件工作台。
ExtractOrders 连接器将使用相同的表定义,如 图 12 所示, 以及相同的连接详细信息,如
图 13 所示。

图 17. 从 Teradata Orders
表提取数据
如图 18 所示,为数据提取操作指定以下参数:
通过 Teradata DBC/SQL 分区运行 SQL 的立即访问方法。此作业只能在 DataStage
指导者节点上以序列模式运行,并且它适合于小量数据提取。要支持并行提取大容量数据,需要配置指导者使用批量访问方法和
Teradata Parallel Transporter 导出驱动程序。
选择语句。 指导者可以使用如 图 13 所示的表名和列定义生成 SQL。在本例中,SQL 语句将手动输入。
记录计数。 记录计数通常与 End of Wave 特性结合使用。您可以使用 End of Wave 特性将输入/输出记录划分为许多小事务,或者工作单元。本例未使用
End of Wave 特性,并且记录计数不会影响数据提取操作。
数组大小。 数组大小主要用于为连接器缓存输入记录,以便于立即和批量加载操作。它不会对此数据提取操作造成影响。连接器将
Teradata 数据库与连接之间通信的最大包大小设置为 64k 或者 1MB(如果 Teradata
数据库服务器通过四字节替代包报头 (APH) 支持 1MB 大小的包)。
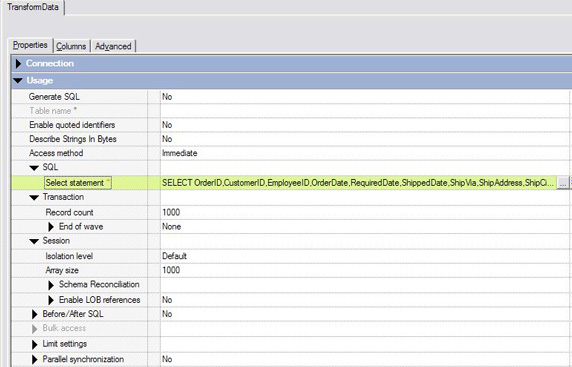
图 18. 设置数据提取操作
查找 Teradata 数据
本节将使用两个 ETL 作业演示根据输入记录查找 Teradata 数据的步骤。这些示例将根据输入订单
ID 查询订单详细信息。以下小节将讨论 DataStage 支持的两种查找方法:普通查找和稀疏查找。
普通查找
对于普通查找来说,所有引用的数据都将从目标数据库中检索一次,并缓存在缓存或磁盘中。对于各输入记录,缓存引用数据将通过交叉检查来查找结果。
图 19 展示了某示例作业的查找工作台和 Teradata 连接器,可用于执行普通查找。Teradata
连接器对 Orders 表执行完整的表查询,并将查询结果发送给名为 NormalLookup 的查找工作台。查找
工作台将缓存查询结果并根据 OrderID 输入链接中的订单 ID 对缓存的订单详细信息执行查找操作。结果将发送给输出链接
OrderDetails。此作业要求一次完整的表数据库查询。
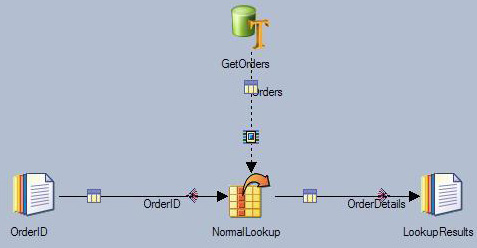
图 19. 用于执行普通查找的 DataStage
作业
执行普通查找需要两个主要步骤:
1.如图 20 所示,设置用于执行普通查找的查找工作台。
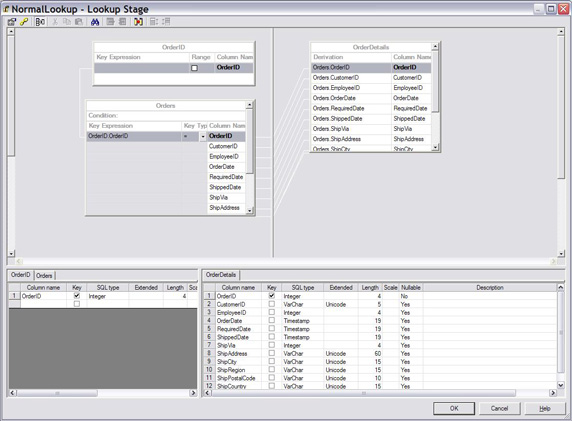
图 20. 设置用于执行普通查找的查找工作台
2.如图 21 所示,指定以下参数针对普通查找设置 Teradata
连接器:
普通查找类型。
立即访问方法。 批量访问方法也可以在普通查找中使用。
Orders 目录表和自动生成 SQL。连接器将根据目标表和列定义在运行时生成查询 SQL。
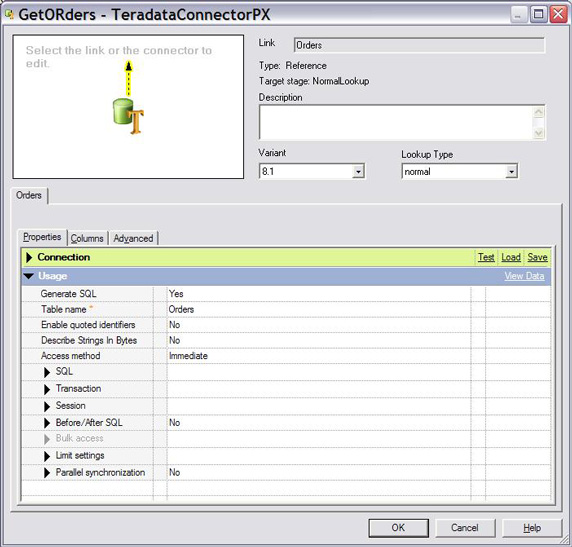
图 21. 针对普通查找设置 Teradata
连接器
稀疏查找
对于稀疏查找来说,它将根据每条输入记录来生成数据库查询,并且查询将被发送给目标数据库以获取结果。
图 22 展示的示例作业的查找工作台和 Teradata 连接器可用于执行稀疏查找。对于各订单 ID,SparseLookup
查找工作台会将订单 ID 发送给名为 GetOrderByID 的 Teradata 连接器。连接器将根据订单
ID 查询订单详细信息并将查询结果返回给查找工作台。查找工作台将查询结果转发给输出链接 OrderDetails。作业对各订单
ID 执行一次数据库查询。由于有四个订单 ID,因此作业执行了四次数据库查询。
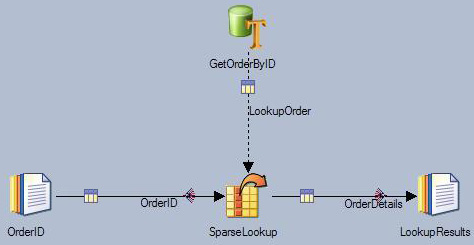
图 22. 用于执行稀疏查找的 DataStage
作业
执行稀疏查找需要两个主要步骤:
1.如图 23 所示,设置查找工作台执行稀疏查找。
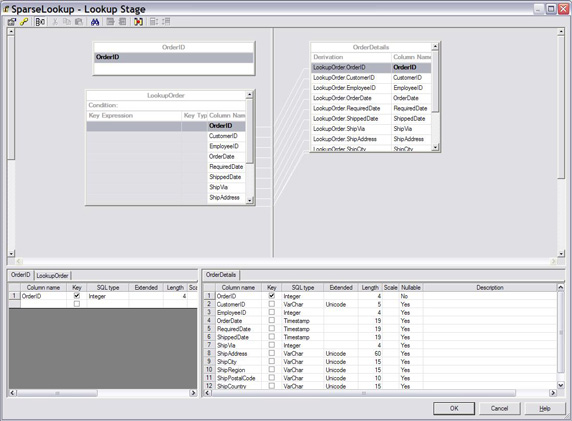
图 23. 针对稀疏查找设置查找工作台
2.如图 24 所示,指定以下参数设置用于稀疏查找的 Teradata
连接器:
稀疏查找类型。
立即访问方法。不可以在稀疏查找中使用批量访问方法。
Orders 目标表和自动生成 SQL。 连接器将根据目标表和列定义在运行时生成查询 SQL。
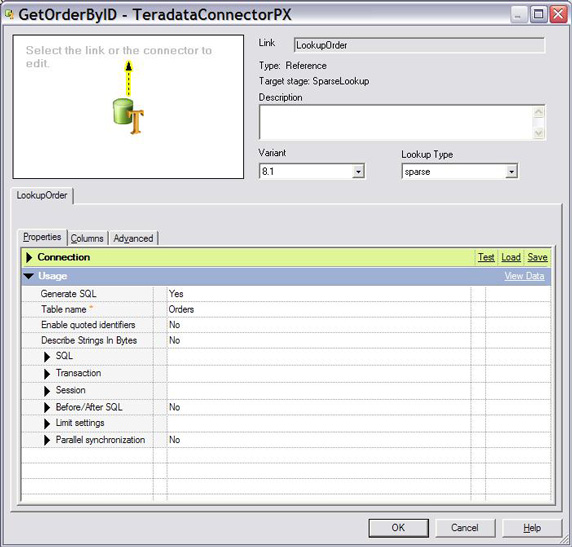
图 24. 针对稀疏查找设置查找工作台
Teradata Connector 的 Properties 选项卡设置了上述条目。
早期 Teradata Enterprise 工作台
Teradata Enterprise Stage (TDEE) 是自 DataStage Version
7.x. 之后可用的一种早期 Teradata 工作台。 TDEE 是一种本机 PX-operator,它提供了以下特性:
它是用于加载和导出大量数据的高性能解决方案。Teradata 通过批量模式选项中的加载和导出驱动程序提供等价的功能。
它使用 Teradata 调用杠接口 CLIv2 和 FastLoad/FastExport 协议。
它支持 Teradata 客户机版本 8.x、12.x 和 13.x。
它不支持更新、更改插入或稀疏查找操作。
它不支持 End of Wave 和拒绝链接特性。
图 25 所示的示例 ETL 作业演示了 TDEE 数据提取和加载特性。TDEE_Extract 将从一个
Teradata 数据库中导出数据。 TDEE 支持从表导出数据或者使用用户定义的 SQL。 TDEE_Load
可将数据加载到 Teradata 表中。 TDEE 只支持将数据加载到表中。用户定义的 SQL 不可用于数据加载操作。

图 25. 使用 TDEE 加载和提取数据
图 26 演示了如何设置 TDEE_LOAD 工作台。 TDEE 可以根据写入模式选择执行以下预加载操作:
创建 ― 创建新表
替换 ― 放弃已有表并创建一个新表
截去 ― 删除已有表中的记录
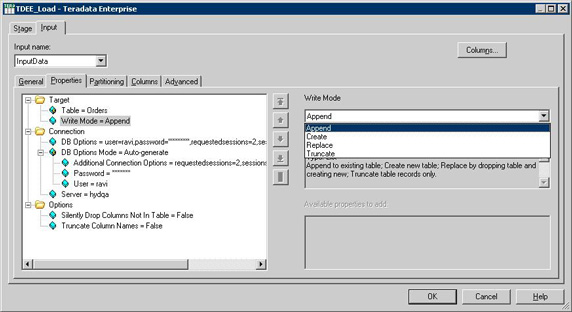
图 26. 设置 TDEE 数据加载操作
Teradata Enterprise 工作台使用 FastLoad
协议将数据加载到表中。FastLoad 协议仅支持加入空表。选择 Append 写模式后,工作台将使用
FastLoad 协议将数据插入到临时工作表中。完成数据加载操作之后,工作台将使用以下 SQL 将数据插入到目标表:
insert into <target table> select * from <temporary work table> |
Teradata Enterprise 工作台将在并发模式下运行。它支持为创建加载或导出操作创建多个在多个计算机节点上运行的进程。
如果定义了 requestedsessions/sessionsperplayer 属性,则它们将控制为数据操作生成的播放器进程的数量。否则,为数据操作生成的播放器进程的数量的默认值将设置为
Teradata Access Module 处理器数量的一半。
需要在数据操作的各时间点同步多个加载进程。同步需要创建并使用一个 terasync 数据库表。对于运行中的各个作业,表中都会插入一个相应行。各播放器进程将更新表中的行以指示其当前状态。如果不能在超时时间内(默认为
20 秒)同步所有播放器进程,则作业将中断。您可以更改默认值,方法是在数据加载定义中指定 synctimeout=<specified_value>
作为一个 Additional Connection Option 选项(参见图 26)。
早期 Teradata Multiload 工作台
Teradata MultiLoad (TDMLoad) 工作台最初是针对 DataStage 服务器设计的。TDMLoad
工作台支持数据加载和导出。它在内部使用 Teradata FastExport 实用工具进行导出。它使用
Teradata MultiLoad 或 TPump 实用工具进行加载。TDMLoad 工作台还可以在
DataStage PX 上运行。但是,与 Teradata 连接器不同,它只在序列模式下运行。以并行模式运行
TDMLoad 不受支持。
在 Teradata 连接器可用之前,主要推荐使用 TDMLoad 工作台来支持数据库更新和更新插入操作。Teradata
连接器的批量模式中的更新和流驱动程序提供了与之等价的特性。
图 27 所示的示例 ETL 作业演示了 TDMLOAD 数据导出和加载特性。 TDMLOAD_Export
从 Teradata 数据库导出数据。 TDMLOAD_Load_Update 将数据加载到 Teradata
表中。

图 27. 使用 TDMLOAD 提取和加载数据
图 28 展示了如何设置 TDMLOAD 数据导出操作。以下内容将描述 TDMLoad 工作台如何实现数据导出操作:
工作台通过特定的 SQL 语句调用 Teradata FastExport 实用工具。
FastExport 实用工具从 Teradata 读取 Teradata 格式的数据,并将数据写入到管道或数据文件。
工作台将从管道或数据文件读取数据,并将数据写入到输出链接。
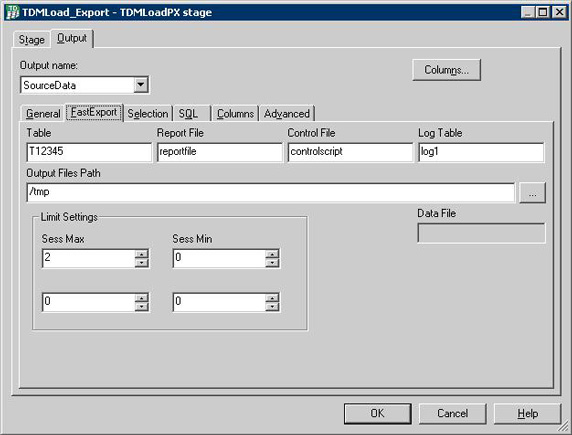
图 28. 设置 TDMLOAD 数据导出
图 29 展示了如何设置 TDMLOAD 数据加载操作。以下内容描述了 TDMLoad 工作台如何实现数据加载操作:
工作台从 DataStage 输入链接读取数据。
工作台将数据转换为 Teradata 格式并将数据写入到数据文件或管道。
工作台将生成一个 Teradata 加载实用工具脚本,然后根据用户选择调用 Teradata MultiLoad
或者 TPump 实用工具。
所选 Teradata 实用工具将使用生成的脚本作为输入,并将输出写入到报表文件。
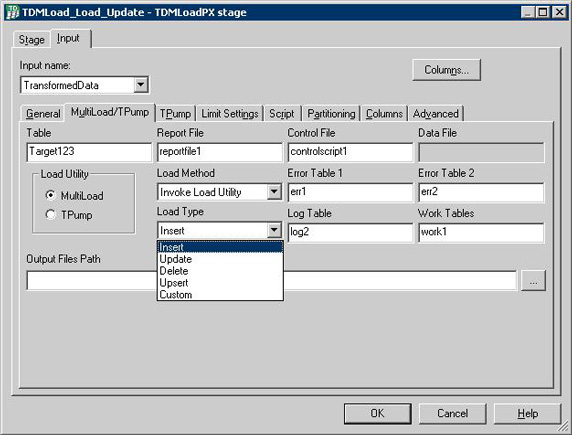
图 29. 设置 TDMLOAD 数据加载
TDMLoad 工作台提供了使用 Teradata FastLoad 或 VarText 格式将 DataStage
数据写入到数据文件中选项。您随后可以使用 Teradata 加载实用工具加载 the DataStage
外部的数据文件。Teradata 连接器不支持此特性。
其他早期 Teradata 工作台
Teradata API (TDAPI) 工作台专为 DataStage 服务器设计。 它提供了通过 Teradata
DBC/SQL 分区执行 SQL select/insert/update/upsert/delete
语句的功能。它支持以序列模式在 DataStage PX 上运行。以并行模式运行工作台不受支持。
Teradata API 工作台一次处理一个数据记录。它没有利用 Teradata DML 数组操作特性。数组操作一次会向服务器发送许多行数据。建议使用该工作台处理少量记录。
Teradata 连接器的立即访问模式支持通过 DBC/SQL 分区执行 SQL。连接器还允许用户指定数组大小使用
Teradata 数组操作特性。
图 30 展示了用于插入或更新数据库表的 Teradata API 的工作台定义。
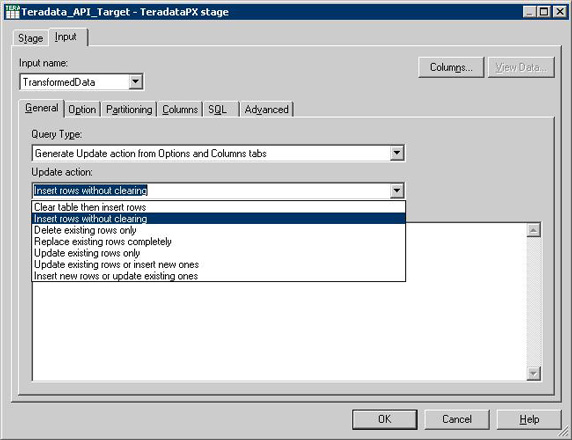
图 30. Teradata API 工作台定义
Teradata Load (terabulk) 工作台也是专为 DataStage 服务器设计的。它使用
FastLoad 实用工具并提供了将批量数据加载到空数据库表中的功能。它支持以序列模式在 DataStage
PX 中运行。以并行模式运行 Teradata 加载工作台是不受支持的。Teradata 连接器通过批量模式选项中的加载驱动程序提供了等价的加载功能。
Teradata Load 工作台提供了使用 Teradata FastLoad 或 VarTex 格式将
DataStage 数据写入到数据文件中的选项。Teradata 连接器不支持此特性。
图 31 展示了 Teradata Load 工作台用于将数据加载到数据库表中时的工作台定义。
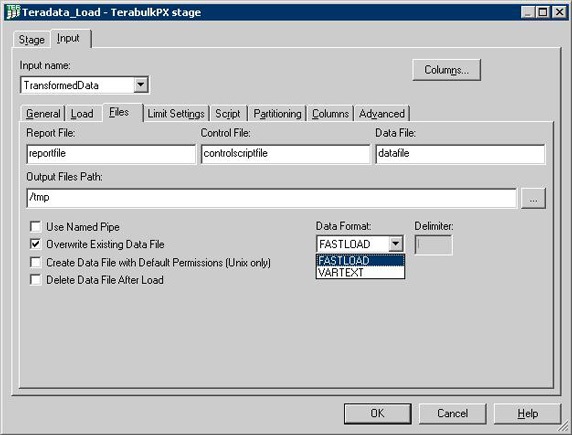
图 31. Teradata Load 工作台定义
早期元数据导入服务
如图 32 所示,您可以通过以下菜单项调用早期元数据导入服务:
Orchestrate Schema Definitions
Plug-in Meta Data Definitions
图 32. 早期元数据导入选项
选择 Orchestrate Schema Definitions 菜单项将开始使用 PX 运算符导入文件定义或数据库表模式。选择
Teradata 数据库类型之后,流程将调用 Teradata enterprise stage (TDEE)
导入所选 Teradata 表模式。
选择e Plug-in Meta Data Definitions 菜单项半开始使用 DataStage
插件工作台导入数据库表模式。选择 Teradata 数据库类型之后,流程将调用 Teradata API
工作台导入所选 Teradata 表模式。
结束语
本文演示了如何在 IBM InfoSphere Information Server 中使用 Teradata
连接解决方案集成 Teradata 数据与其他数据源。它介绍了 Teradata 连接器的数据加载、数据提取和查找特性。此处,还讨论了
Teradata 早期工作台的主要特性。Teradata 连接器提供了一个可替换所有早期工作台的解决方案。文章通过许多示例演示了详细的设计流程。
IBM InfoSphere Information Server 提供了许多领先的技术和集成解决方案,旨在触发许多关键集成问题,包括:
数据质量。构建数据仓库的数据通常来自各种数据源。早期数据的结构经常没有任何记录,并且数据质量也较差。InfoSphere
Information Analyzer 将分析您的数据并确保数据结构和质量。它将帮助您理解您的数据。InfoSphere
QualityStage 解决方案将标准化并匹配任意类型的信息以创建高质量的数据。
数据量。数据仓库环境通常要定期处理大量数据。有时,数据量的增长会超过预期。这一问题通过借助可伸缩的 ETL
架构来解决。IBM InfoSphere Information Server 将利用管道和分区技术来支持高数据吞吐量。可以将它部署在对称多处理(Symmetric
Multiprocessing,SMP)和大规模并行处理(Massively Parallel Processing,MMP)计算机系统中来最大限度提高可伸缩性。
|






