许多企业都面对着集成来自各种数据源的大量数据以及改善数据质量的挑战。IBM?
InfoSphere? Information Server 是针对这类任务的理想解决方案。本文将演示如何使用
Information Server 提取、查找和加载 Teradata 数据。
简介
IBM InfoSphere Information Server 是一个统一、综合的信息集成平台。它可以剖析、清理和转换来自全异数据源的数据,以交付一致准确的业务数据。IBM
Information Server 是集成和同步 Teradata 数据与其他 ERP 系统及企业应用程序的理想解决方案。
本文将演示和比较 IBM InfoSphere Information Server 提供的若干种处理
Teradata 数据的集成方法。它将通过一些示例来演示业务集成场景。这些示例将指导您解决 Teradata
数据库中的典型数据集成问题。
产品前提条件及概述
如图 1 所示,可以认为 IBM InfoSphere Information
有四个逻辑层:
1.客户机
2.引擎
3.元数据存储库
4.服务
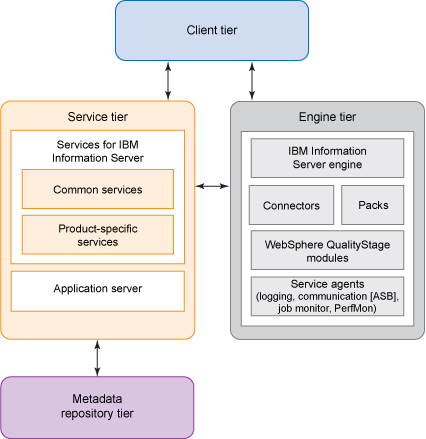
图 1. IBM InfoSphere Information
Server 逻辑层
每个逻辑层都定义了一组软件模块,它们可以映射到硬件的物理部分。这些逻辑层可以单独安装在不同的计算机上,或者一起安装在相同的计算机上。Information
Server 支持将引擎层部署在对称多处理 (SMP) 计算平台,或者部署在大规模并行处理 (MPP)
计算平台上,以实现高伸缩性和高性能。
InfoSphere Information Server 要求以下组件支持与
Teradata 数据库之间的数据集成:
DataStage Connectivity for Teradata ― 此组件包括 Teradata
Connector 和所有其他的 Teradata 早期工作台。作为一个单独的解决方案,Teradata
连接器旨在替代所有的早期工作台。Teradata 连接器安装在引擎层上。但是,Teradata 早期工作台包括客户机层的客户机安装和引擎层的服务器安装。
Teradata Tools and Utilities (TTU) ― 此组件包括许多与 Teradata
数据库协作的产品。TTU 是引擎层上所必需的,并且如果在 ETL 作业中使用了 Teradta 早期工作台,那么还必须安装在客户机层上。TTU
依赖于以下包:
Teradata Generic Security Services (TeraGSS) 客户机包
Teradata Shared Component for Internationalization (tdicu)
Teradata Call-Level Interface (CLIv2)
Teradata Named Pipes Access Module
Teradata FastExport Utility
Teradata FastLoad Utility
Teradata MultiLoad Utility
Teradata TPump Utility
Teradata Parallel Transporter Interface
Teradata Connector 利用了一些全新的 Teradata 特性。它可以在立即访问模式下运行,也可以在批量模式下运行:
立即访问模式 ― 在此模式中,连接器将数据库 SQL 语句发送给 Teradata DBC/SQL 分区并立即从
Teradata 获得实时响应。Tradata DBC/SQL 分区负责处理 SQL 请求。立即模式和
DBC/SQL 分区适合支持低容量数据处理。
批量模式 ― 此模式适合大批量数据处理。在批量模式中,连接器将利用 Teradata 并行传输接口以及在
SMP 和 MPP 中定义的多个计算节点来执行并行数据加载和数据导出操作。Teradata 并行传输接口是一个支持并行的编程接口,可以使用多个计算平台上的多个进程运行批量操作。Teradata
连接器支持 Teradata 并行传输接口中指定的四个驱动程序:
1.加载驱动程序 ― 使用 FastLoad 协议对空表执行并行加载。
2.更新驱动程序 ― 使用 Multiload 协议并支持对新表或已有表执行并行插入/更新/删除/更新插入操作。
3.流驱动程序 ― 使用 TPump 协议对表执行并行实时 DML 操作。流驱动程序将使用低级锁。它允许应用程序在后台对表执行恒定数据加载操作,同时可以执行交互式读取和写入操作。
4.导出驱动程序 ― 使用 FastExport 协议执行并行数据导入。
Teradata Connector 在 IBM InfoSphere Information Server
Version 8.0.1 及更高版本上可用。它的作用是替代所有 Teradata 早期工作台。
Teradata 早期工作台包括:
Teradata Enterprise 工作台 ― 使用多个 FastLoad 和 FastExport
会话的并行批量数据加载和导出解决方案。
Teradata Multiload 工作台 ― 使用 Teradata MultiLoad、TPump
和 FastExport 实用工具的批量数据加载和导出解决方案。
Teradata API 工作台 ― 基于 SQL 语句对 Teradata 数据库提供行到行的读取和写入权限。
Teradata Load 工作台 ― 提供了一个使用 Teradata FastLoad 实用工具的批量数据加载解决方案。
Teradata 早期工作台在 Information Server Version 及更新版本中可用。
本文并不会详细讨论存储过程 (STP) 和 Open Database Connectivity (ODBC)
工作台。IBM InfoSphere Information Server 使用以下工作台提供对多种数据库类型的支持:
STP 工作台允许从 DataStage 作业调用 DB2、Oracle、Teradata、Sybase
和 SQL 服务器中的存储过程。它支持带输入和/或输出参数的存储过程。STP 工作台是用于调用 Teradata
宏、存储过程、纯量函数和表函数的建议解决方案。
ODBC 工作台允许使用 ODBC 驱动程序访问各种数据库系统,包括 Teradata。
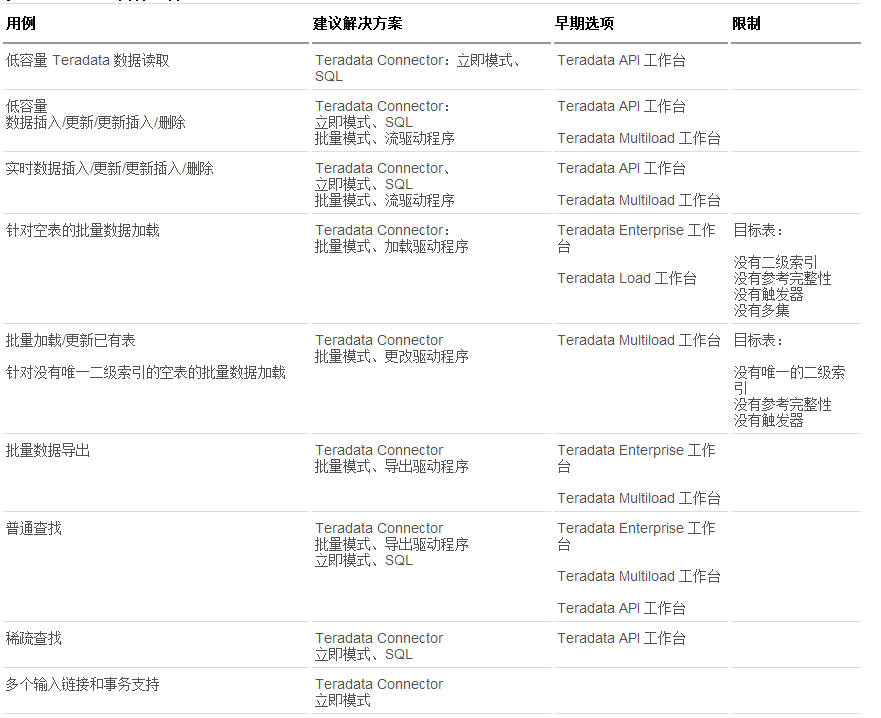
表 1 显示了根据用例进行选择的建议选项。稀疏和普通查找的概念请阅读 查找 Teradata 数据小节。
表 1. Teradata 集成选项
使用 Teradata Connector 加载数据
本文将使用一个示例 ETL 作业来演示通过 Teradata 连接器将数据加载到空 Teradata 表中的步骤。图
2 展示了示例作业。作业将从一个平面文件中读取订单。它转换源数据并将其传递给 Teradata 连接器
LoadDataUsingBulkLoad。连接器使用 Teradata 并行传输加载驱动程序将数据加载到一个空的
Orders 表中。违反数据库约束的数据记录将被连接器拒绝并被转发到一个平面文件中。

图 2. 将数据加载到 Teradata
Orders 表中
上述文本描述的加载数据作业的范例图。
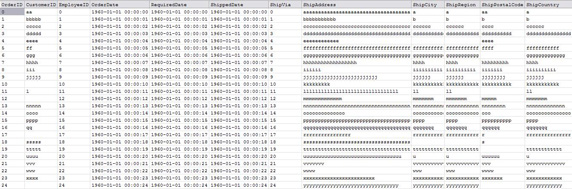
图 3 显示了示例源数据。
清单 1 显示了用于创建 Teradata 数据库 Orders 表的 SQL。
清单 1. 用于创建 Orders 表的 SQL
CREATE SET TABLE Orders ,NO FALLBACK ,
NO BEFORE JOURNAL,
NO AFTER JOURNAL,
CHECKSUM = DEFAULT
(
OrderID INTEGER NOT NULL,
CustomerID VARCHAR(5) CHARACTER SET LATIN CASESPECIFIC,
EmployeeID INTEGER,
OrderDate TIMESTAMP(0),
RequiredDate TIMESTAMP(0),
ShippedDate TIMESTAMP(0),
ShipVia INTEGER,
ShipAddress VARCHAR(60) CHARACTER SET LATIN CASESPECIFIC,
ShipCity VARCHAR(15) CHARACTER SET LATIN CASESPECIFIC,
ShipRegion VARCHAR(15) CHARACTER SET LATIN CASESPECIFIC,
ShipPostalCode VARCHAR(10) CHARACTER SET LATIN CASESPECIFIC,
ShipCountry VARCHAR(15) CHARACTER SET LATIN CASESPECIFIC)
UNIQUE PRIMARY INDEX ( OrderID ); |
为批量数据加载操作设置 LoadDataUsingBulkLoad Teradata 连接器需要两个主要步骤:
1.启动连接器导入向导,如图所示,并导入 Orders 表的定义。

图 4. 启动 Connector Import
Wizard
2.打开连接器的 Properties 选项卡,如图 5 所示,并设置
Teradata 数据操作。
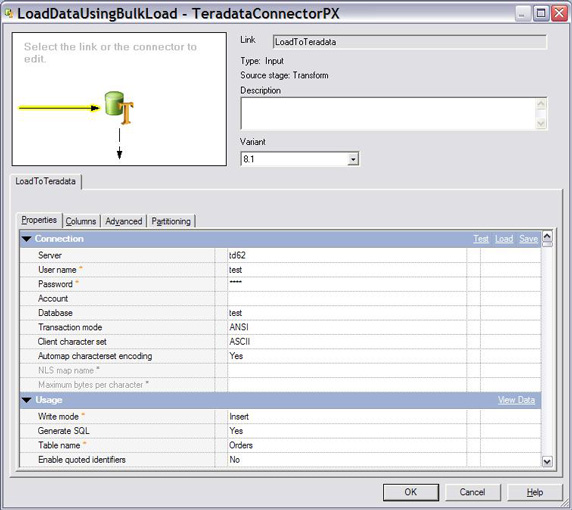
图 5. Teradata Connector
属性编辑器
导入 Teradata 表定义
本节中的屏幕快照将演示导入 Orders 数据库表定义的步骤。
1.如图 6 所示,选择 Teradata Connector 导入
Teradata 表模式。Teradata connector variant 8.1 支持 Teradata
TTU 8.1 和 8.2。variant 12 支持 Teradata TTU 12 和 13。本示例将使用
TTU 8.2。如图 5 和图 6 所示,这些示例作业将选择 Teradata connector variant
8.1。
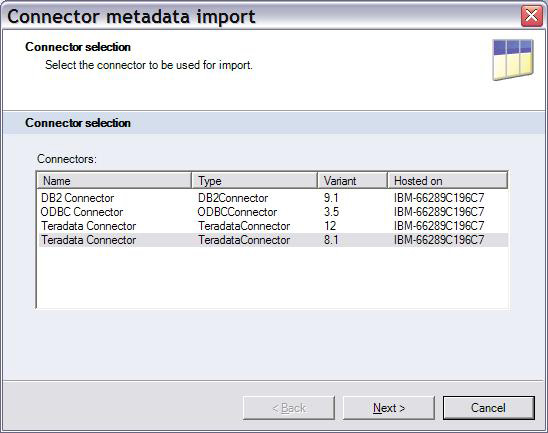
图 6. 选择 Teradata 连接器进行
Metadata 导入
2.如图 7 所示,指定 Teradata Director Program
ID (TDPID)、用户名和密码,以便导入向导可以连接到 Teradata 数据库。Teradata
客户机应用程序将使用 TDPID 别名连接到 Teradata 数据库。TDPID 参数定义在机器主机文件中(在
UNIX? 中为 /etc/hosts,在 Windows? 中为 \windows\system32\drivers\etc\hosts)。
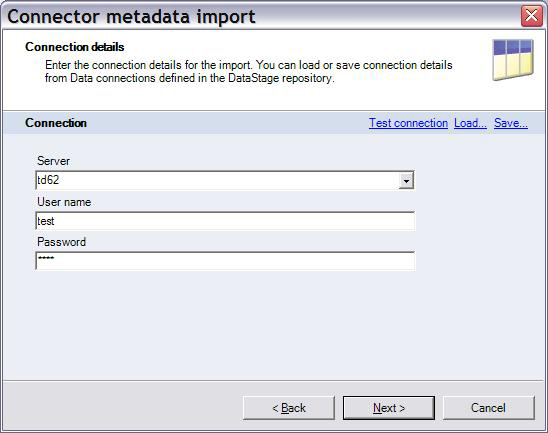
图 7. 输入连接详细信息
3.如图 8 所示,指定从何处导入表。此信息主要供 DataStage
用于跟踪表定义的原始源。
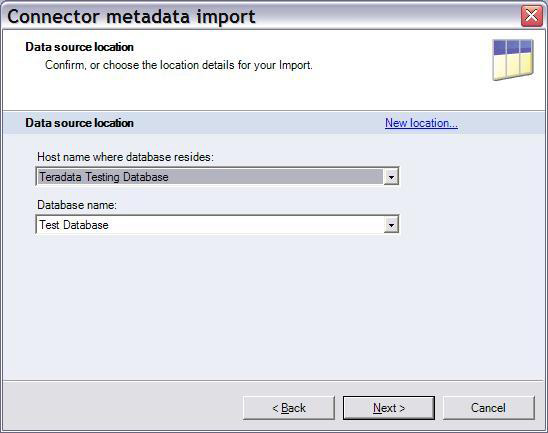
图 8. 输入位置详细信息
4.如图 9 所示,提供筛选器缩小表搜索结果范围。
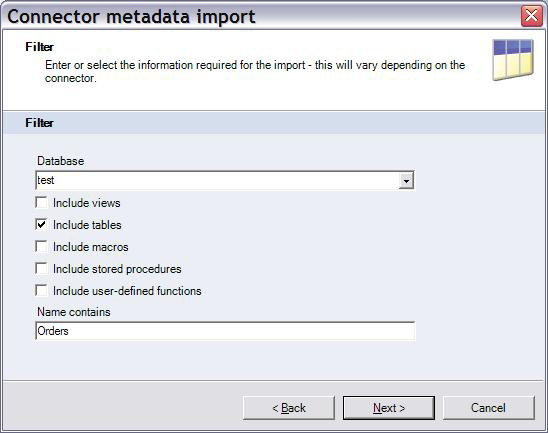
图 9. 按数据库和表名筛选表列表
5.如图 10 所示,与图 9 中设定的筛选条件匹配的所有表都将返回。选择要进行导入操作的
Orders 表。
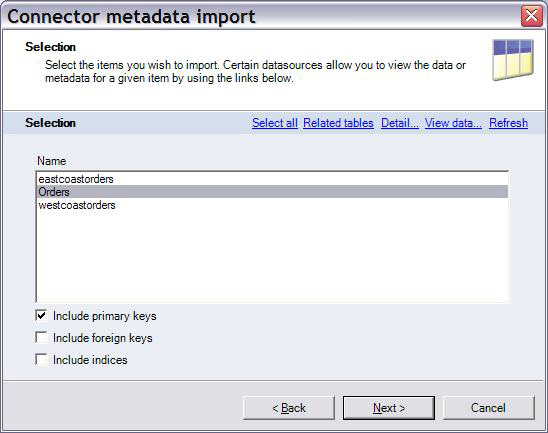
图 10. 选择一个 Teradata 表
6.图 11 显示了导入操作的确认屏幕。单击 Import 按钮开始导入操作。在本例中,根据
Orders 表的数据库表模式在 DataStage 存储库中创建一个名称为 test.Orders 的
DataStage 表定义。
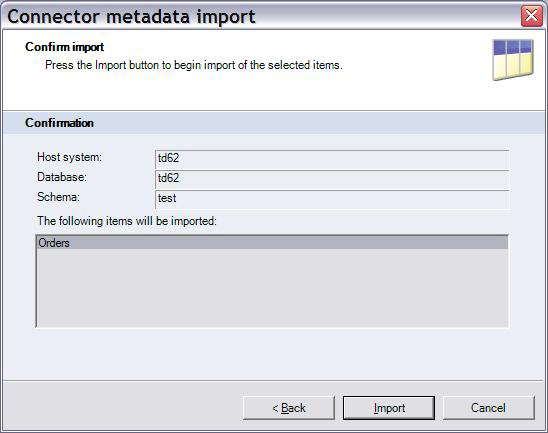
图 11. 确认导入操作
在 Property Editor 上设置批量加载操作
本节中的屏幕快照将演示使用 Teradata Parallel Transport 加载驱动程序定义批量加载操作的步骤。
1.如图 12 所示,打开连接器的 Columns 选项卡,选择 OrderID
列作为键并单击 Load 按钮将 test.Orders 表定义从 DataStage 存储库加载到 LoadDataUsingBulkLoad
连接器。
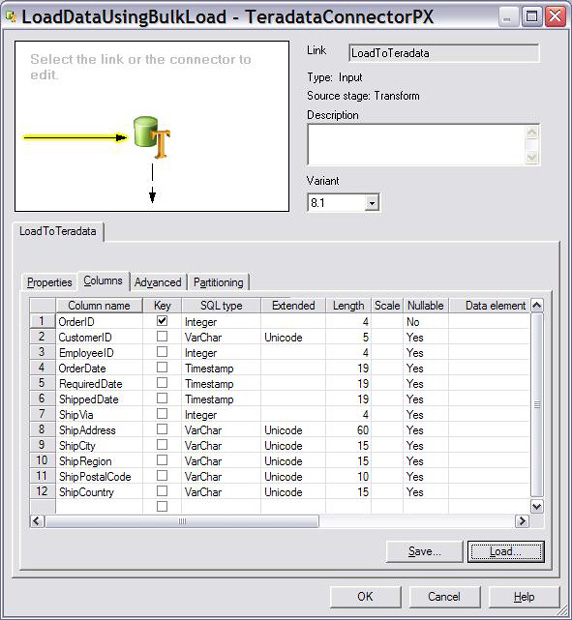
图 12. 加载 Columns 定义
2.如图 13 所示,返回连接器的 Properties 选项卡并为
Terdata 加载操作指定以下参数:
连接详细信息:Teradata Program Director ID (TPDID)、用户名、密码和数据库。
用于与 Teradata 服务器通信的 Teradata 客户机字符集。
目标数据库表名、自动生成 SQL 和表操作。连接器将根据 Orders 的目标表名以及图 12 中所选择的列定义创建插入
SQL 语句。在数据加载操作开始之前,选择 Truncate 表操作删除 Orders 表中的所有已有行。
批量访问方法和驱动程序。选择加载驱动程序将数据加载到空 Orders 表中。
睡眠和韧度设置。 Teradata 数据库将限制可并发运行的 FastLoad、MultiLoad
和 FastExport 任务的数量。这将由 MaxLoadTasks 和 MaxLoadAWT DBS
控件字段控制。通常,其限制是从 5 到 15。睡眠和韧度设置将影响超过限制时连接器重新尝试连接到数据库的方式。睡眠值将指定重试之间的时间间隔(分钟)。韧度值将指定登录重试的超时时间(小时)。
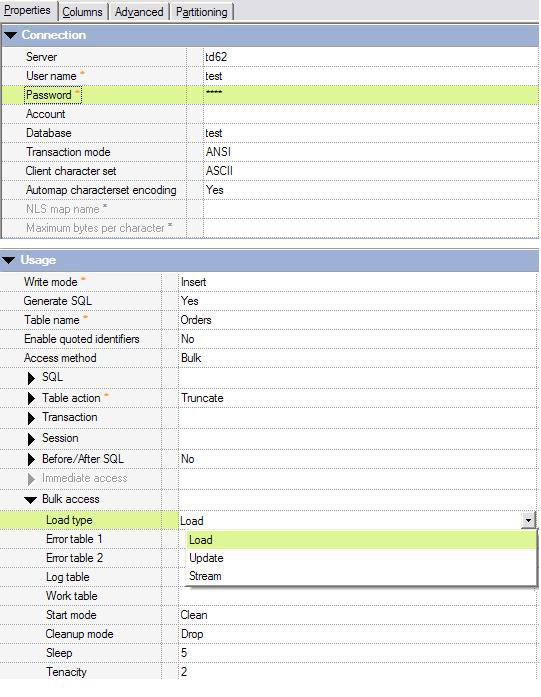
图 13. 输入连接详细信息并设置批量加载操作
3.如图 14 所示,在连接器的 Properties 中继续为 Teradata
加载操作定义参数值:
Record Count 用于设置检查点。连接器支持 Teradata
并行传输中的检查点和重启特性。检查点定义数据库在加载流程中成功处理指定数量的记录时的时间点。如果在检查点后出现了任何错误,则可以从检查点后的行重新启动加载流程。本示例每隔
1,000 行设定一个检查点。
Sync 表和操作。 连接器支持使用在多个计算节点中运行的多个进程来执行数据加载操作。连接器依赖于
Teradata 并行传输接口,它要求在加载流程的各点同步多个进程。本例指定连接器将创建并使用 jli_sync_table
表进行进程同步。
最多会话和最多分区会话。 这两个参数指定用于数据加载操作的最大会话数量,以及各加载进程所使用的最大会话数量。本例运行于两个计算节点之上,并且目标
Teradata 数据库有两个 AMP。图 14 中的值指定两个进程使用两个会话将数据加载到数据库表中。
数组大小。 此参数指定在将数据发送给加载驱动程序之前应该缓存多少行。加载驱动程序将使用连接器中的数据并构建
64k 缓冲以便发送给 Teradata 数据库。
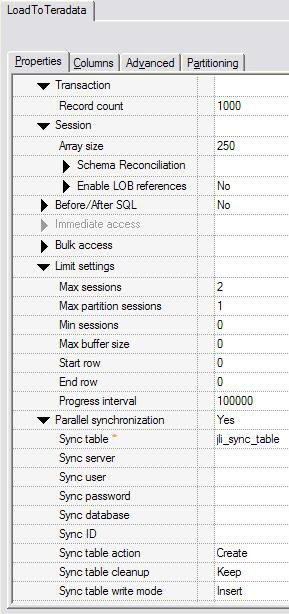
图 14. 重新启动、并行加载和同步等
4.打开 Rejects 选项卡,指定如何处理错误情况。如图 15 所示,指定以下项目:
选择 Duplicate key 和 SQL errors,将导致这些错误的记录发送给拒绝链接。
选择 ERRORCODE 和 ERRORTEXT 将这些列添加到各个被拒绝的数据记录,表明记录被拒绝的原因。其他选择不适用于加载驱动程序。
本例中未使用的一种特殊的筛选条件是 Success 条件。Success
筛选器的作用是将成功处理的记录转发给下一个工作台进行处理。
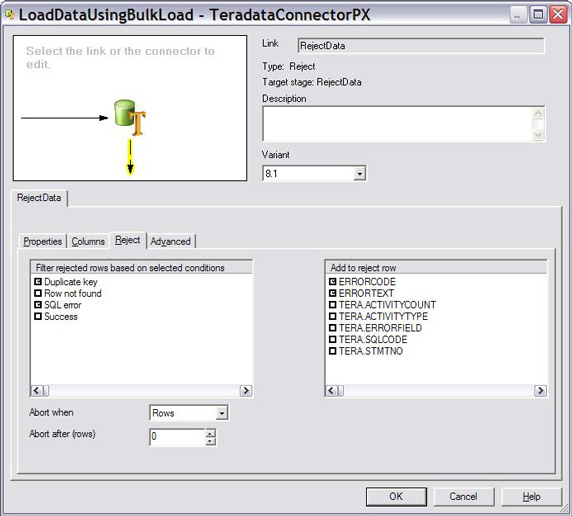
图 15. 设置拒绝链接
Teradata Connector 的 Reject 选项卡中设置了上述条目。
5.如图 16 所示,两个示例记录中的批量加载操作结果被发送给拒绝链接,因为它们违反唯一的主键约束。

图 16. 被拒绝的记录
|






