�ĵ����ʣ����ɻ�������Ʒ��IBM
Cognos 8������������ע�������ܹ�
��ʹ�� Teradata ��Ϊ����Դ������ IBM Cognos 8 ʱ��һЩ���ɺͼ�����
���
����
�����ṩ��һЩ��ʹ�� Teradata ��Ϊ����Դ������ IBM Cognos
8 ʱ�ļ��ɺͼ�����
�����ṩ�ļ��ɺͼ�������Ϊ �������� ���ߣ���ˣ���Щ���ݿ���Ϊ������顣ÿ���ͻ�վ�㶼����ͬ����ˣ�������Щ��ʾ�������ܲ����á�
�����������ļ��ɺͼ����ǴӲ�ͬ�ͻ�վ������þ���Ļ��ۡ�
���Ļ�����Ϊ ���ڽ���Ŀ������ʱ�����µļ��ɺͼ������ӣ��������еļ��ɺͼ���������ʱ�����ģ�ˡ������֪ͨ��
�ĵ��Ⱦ�����
���ļٶ����߾��� Teradata��SQL�����ݿ�����ʵ�����飬����
IBM Cognos 8 �������˽⡣���Ļ��ٶ����߾�ͨ IBM Cognos 8 ʵʩ�����֪ʶ���Լ��ḻ�Ľ�ģ���顣
ǿ�ҽ����û���Ϥ�ο����ϲ��������г��������Ŀ��
�ĵ���Χ
�����ʺ����������汾��
1.IBM Cognos 8.2 BI��IBM Cognos 8.3 BI
2.Teradata EDW V2R6.2
IBM Cognos ���ڶ������� Teradata ���ɡ����ķ�Ϊ��ͬ��εļ��ɣ��Լ���Ӧ�ļ��ɺͼ�����
���Ļ��� Teradata Star/Snowflake ������ģʽ��
Teradata ����
�����ļ����ݲ�ʶ����������Primary Index��PI�� ��ѡ��
����� Teradata ������ʱ���͵Ĵ����ǽ����ϲ������� Teradata
AMPs �о��ȵطֲ����ݡ���Ȼ���ݵķֲ���������Ʊ�֮һ������ע��ҵ�������ص�����ҵ�ɵġ���������
Teradata ���ݿ��Ωһ���� �C �ڱ���������ض������������ṩ���������ơ�
������������ �C Ωһ��������UPI�����Ωһ��������NUPI����������д��ڹ��ɹ�������·�����У����磬��������в�ѯ���ӱ��м������ݣ�����ô����������Ϊ��������ѡ�ߡ��������Ωһ�ģ���ô������Ϊ
UPI �ĺ�ѡ�ߣ�����������Ϊ NUPI �ĺ�ѡ�ߡ�
�κ������������еIJ�ѯ����������������Ӧʱ�����⡣
Ϊ���������������������Ҫ������������ʱ��Ϊ���ݷ����������²�ѯ�������������ݷ���Ϊij����ѡ��һ��
PI�����粻ͬ AMP �ṩ��Ӧ���ݷֲ���
select hashamp(hashbucket(hashrow(<column that you evaluating for use as PI>))),
count(*)
from <Table Name for which the PI is being evaluated>
group by 1 |
���� Teradata ���ݿ�ͳ������
��������ģʽ��3NF �� Star����Teradata ��ѯ�Ż���������ͳ����Ϣ����ȷ��������ݷ���·����ͳ����Ϣ���ɰ����Ż���ȷ�������ж�����������ѯ���Լ�Ԥ���ж����з��ϸ�����������
�ڳ�������ض���������ʱ����һ���ķ�������ȷ����Ҫ�ռ���Щͳ�����ݡ�
���ȣ�ʹ�� Teradata SQL Assistant ���ӵ�����Դ��
ִ�������Ϊ�Ự���ಿ�ִ���� helpstats ������� helpstats
���ڻỰ������
���������� IBM Cognos Report Studio �и��Ʊ����ԭʼ
Teradata SQL��
�� SQL ճ���� Teradata SQL Assistant's Query
�����
���� F6 ����ִ�� Explain��
��High Confidence�� ���ָ���������ռ�ͳ����Ϣ���ǽϺõĺ�ѡ�ߡ�
�ڹ���������ʾ��Ϣ�����÷�������������
��д����ʱ��Ҫ������ȷ�����þ����������С�������ݿ���������ڱ��ϴ�������������������ô��ѯӦ��������н�ϡ�������ִ��ʱ���ϲ�ѡ�е���������ʱά�ȱ��е��κ��ж���ʹ�á��Ż��������������еĺ������������ƶϹؼ�ֵѡ��
���� Report Studio �ж�����ʾ��Ϣʱ�����Բ������ֲ�ͬ���������ƣ���Use
Value�� �� ��Display Value�������磬�� Sales Org Code ָ��Ϊ ��Use
Value�� ���� Sales Org Description ָ��Ϊ ��Display Value����
��ͨ������һ���ı�ֵ����������ʵ�ַ���������
���� Teradata Soft Referential Integrity
(Soft RI)
��֮��Ĺ�ϵ�ṩ�� Teradata ���ݿ��Ż���������ֵ����Щ��ϵͨ��������֮���Լ����ϵ��ȷ�������ݲֿ��е�������ʹ�ô�ͳ����������Լ���ijɱ�̫�ߡ���ˣ�Teradata
ͨ����Լ������ ��WITH NO CHECK OPTION�� ��������� Referential Constraints��ͨ������Ϊ
��Soft RI�� �������Զ�������һ������ʵ�壨�����������ĸ�ʵ������ʵ�壬����ǿ�����ݷ��ʼƻ���Soft
RI ���ͳ������ʹ���Ż����ܹ����ɸ���Ч�ķ���·����
��������ʵʩ Soft RI ʱ��Ҫ���ǵ����⣺
ȷ����������Щ����¿��ܳ�Ϊ���������ϵ����� driving ��/ά���еĶ�����Ωһ�ġ���Ωһ�в���Ϊ��ͬ���ṩ������á�
ȷ�� driving ���е������� target ���е����������ͬ���������͡��������еĹؼ��в��ܱ�ѹ����
���� Soft RI ��������£�
ALTER TABLE <Target Table>
FOREIGN KEY (<The column which references a Primary Key Column in a Driving Table>)
REFERENCES WITH NO CHECK OPTION <Driving Table> (<Primary Key Column>); |
���� Soft RI ��ȷ���õ���Լ���������е��ʵ�ͳ�����ݡ�
�� Teradata Database Administration �ֲ���
��Using Referential Integrity�� ���֡�
Teradata ��ģ
����������ģ���б��� �ⲿ����
�ⲿ���ӿ��ܻ�Բ�ѯ���ܲ�������Ӱ�졣��һ���黹���������ӳ������ 3NF
�� Star �ܹ��������� Teradata ר�á�
��ͨ������������Ĭ��ֵ����� fact ���������ⲿ����ת��Ϊ�ڲ����ӡ���������ǿ�������Ҫ������������ģ�;Ϳ���ʵ�֡�
ODBC ����
Teradata ���� ODBC ��������Ϊ��ѡ��ϵ�����������������ṩ�˸�
ODBC �������ļ���ѡ�
�洢�û�ƾ��
����û���Ҫ������һ�� TD �û��˻���Ϊ�����û�����ô�û�ƾ�ݽ��洢��
ODBC ���������𣬶����� IBM Cognos 8 Connection ����
�� Windows �У���д ��Username�� �� ��Password��
�ֶΣ�

�� UNIX �У���д�� ��.odbc.ini�� �ļ��е� ��Username=��
�� ��Password=�� �ֶΡ����磺
[ODBC]
InstallDir=/usr/odbc
Trace=0
TraceDll=/usr/odbc/lib/odbctrac.so
TraceFile=/usr/odbcusr/joe/trace.log
TraceAutoStop=1
[ODBC Data Sources]
financial=tdata.so
[financial]
Driver=/usr/odbc/drivers/tdata.so
Description=NCR 3600 running Teradata V2R5.1
DBCName=123.45.67.10
DBCName2=123.45.67.11
DBCName3=123.45.67.12
Username=odbcadm
Password=password
Database=
DefaultDatabase=sales |
�����øü���ʱ�������� IBM Cognos Administration
�д�������Դʱ��Ҫѡ�� ��User ID�� ѡ�

use X Views
TD ODBC �������ṩ����ѡ�
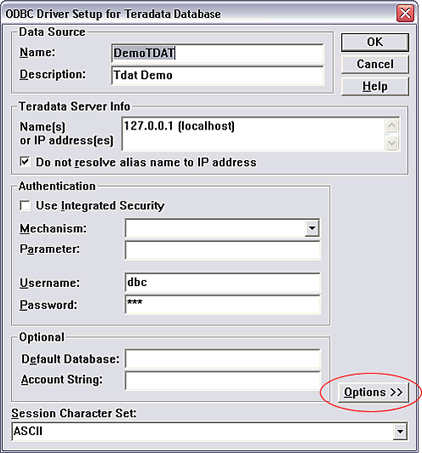
ǿ�ҽ���ȡ��ѡ�� ��Use X Views�� ѡ���ѡ����ӳ� IBM
Cognos Ӧ�ó����õģ��ڶ����ϵ� Metadata ���õ�ʱ�䡣
�� Windows �У��� Teradata ODBC ����ѡ����ȡ��ѡ����ѡ�
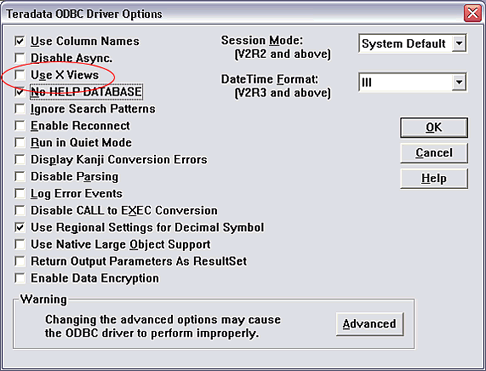
�� UNIX �У�ȷ���� ��.odbc.ini�� �ļ��в����� ��UseXViews=��
ѡ�����ļ����и�ѡ���ôҪȷ������Ϊ ��No�������磺
[ODBC]
InstallDir=/usr/odbc
Trace=0
TraceDll=/usr/odbc/lib/odbctrac.so
TraceFile=/usr/odbcusr/joe/trace.log
TraceAutoStop=1
[ODBC Data Sources]
financial=tdata.so
[financial]
Driver=/usr/odbc/drivers/tdata.so
Description=NCR 3600 running Teradata V2R5.1
DBCName=123.45.67.10
DBCName2=123.45.67.11
DBCName3=123.45.67.12
Username=odbcadm
Password=password
Database=
DefaultDatabase=sales
UseXViews=No |
No HELP DATABASE
������ ��No HELP DATABASE�� ѡ�������������ݿ��ѯ����
Teradata ʱ��������á��� IBM Cognos 8 ǿ��ִ���м���е����Ӳ�ͬ��Teradata
����������еĴ������̡�
�� Windows �У�ѡ�� ��No HELP DATABASE�� ѡ�

�� UNIX �У�ȷ�� ��.odbc.ini�� �ļ��е� ��DontUseHelpDatabase=��
����Ϊ ��Yes�������磺
[ODBC]
InstallDir=/usr/odbc
Trace=0
TraceDll=/usr/odbc/lib/odbctrac.so
TraceFile=/usr/odbcusr/joe/trace.log
TraceAutoStop=1
[ODBC Data Sources]
financial=tdata.so
[financial]
Driver=/usr/odbc/drivers/tdata.so
Description=NCR 3600 running Teradata V2R5.1
DBCName=123.45.67.10
DBCName2=123.45.67.11
DBCName3=123.45.67.12
Username=odbcadm
Password=password
Database=
DefaultDatabase=sales
DontUseHelpDatabase=Yes |
ODBC ��ѡ��
TD ODBC ���ṩ��ѡ�
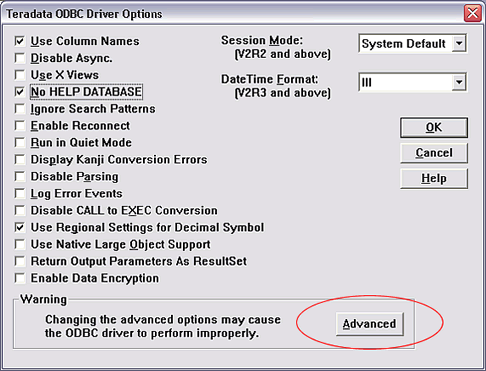
�ڸ�ѡ���У��ɶ� ��Maximum Response Buffer Size��
���е�����Ĭ��ֵ�� 8192�����������ֵ�� 1048575�����Ƽ��ض���ֵ��ÿ���ͻ�վ����Ҫ��ͬ��ֵ�������ֵ̫���ǽ���Ӱ��Ԫ���ݵ��á����ý�С��ֵʱ������������á�
�����������в��ø�ѡ��֮ǰӦ���������ȫ����ԡ�
�� Windows �У�����ֵ���� ��Maximum Response
Buffer Size:�� ѡ���С�
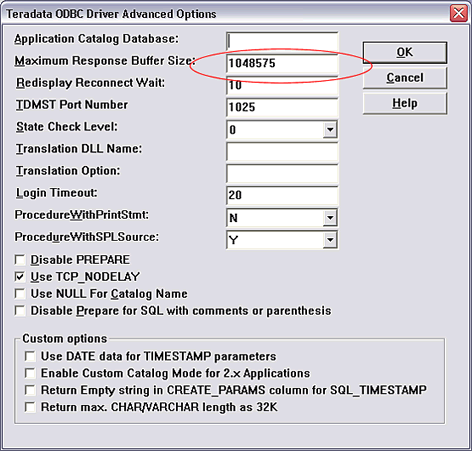
�� UNIX �У��� ��MaxRespSize=�� ѡ���в��������ֵ�����磺
[ODBC]
InstallDir=/usr/odbc
Trace=0
TraceDll=/usr/odbc/lib/odbctrac.so
TraceFile=/usr/odbcusr/joe/trace.log
TraceAutoStop=1
[ODBC Data Sources]
financial=tdata.so
[financial]
Driver=/usr/odbc/drivers/tdata.so
Description=NCR 3600 running Teradata V2R5.1
DBCName=123.45.67.10
DBCName2=123.45.67.11
DBCName3=123.45.67.12
Username=odbcadm
Password=password
Database=
DefaultDatabase=sales
MaxRespSize=65477 |
����ı��˸�ѡ�����ģ���е������ʱ��FM ����������Ϣ����ô��Ҫ����
��Maximum Response Buffer Size�� ֵ������Ҫ�Ա�������н��ж�β��ԡ��ڿ�ʼ��һ������֮ǰ��Ҫ�Ե�ǰ������ж�β��ԡ�
Custom Catalog Mode
��Ҫע�⣬������ ��Enable Custom Catalog Mode
for 2.x Applications�� ����������һЩ��ߡ�
��Ӧ�õ���������֮ǰ��Ҫ�������ȫ����ԡ�
�� Windows ������ ��Enable Custom Catalog
Mode for 2.x application�� ѡ�
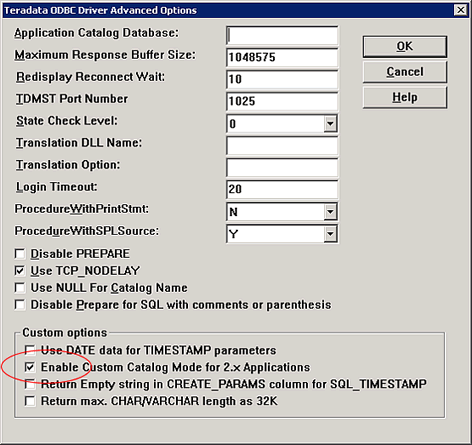
�� UNIX ������ ��USE2XAPPCUSTOMCATALOGMODE=��
ѡ����磺
[ODBC]
InstallDir=/usr/odbc
Trace=0
TraceDll=/usr/odbc/lib/odbctrac.so
TraceFile=/usr/odbcusr/joe/trace.log
TraceAutoStop=1
[ODBC Data Sources]
financial=tdata.so
[financial]
Driver=/usr/odbc/drivers/tdata.so
Description=NCR 3600 running Teradata V2R5.1
DBCName=123.45.67.10
DBCName2=123.45.67.11
DBCName3=123.45.67.12
Username=odbcadm
Password=password
Database=
DefaultDatabase=sales
USE2XAPPCUSTOMCATALOGMODE=Yes |
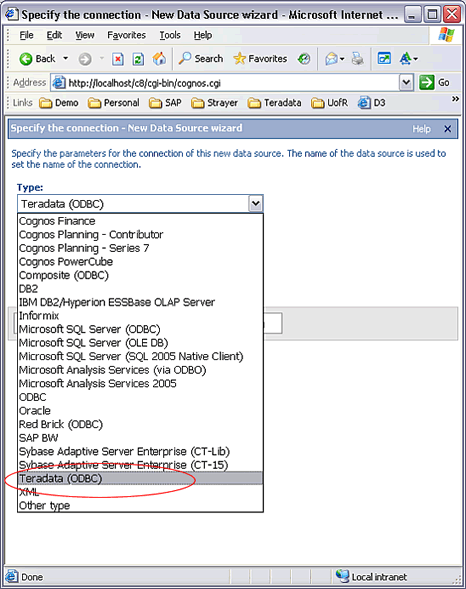
IBM Cognos ����
������ IBM Cognos 8 ����Դ����ʱ��ʹ�� ��Teradata
(ODBC)�� ������ ��ODBC�� ѡ�
IBM Cognos ��ģ
��� Teradata �� IBM Cognos 8 Ԫ���ݽ�ģ�� IBM
Cognos 8 ʵʩ��������Ҫ������
��Ҫ����һЩ�� Framework Manager �н�ģ��ؼ�������ѵ�����ܳɹ���ʵʩ������Ҫ�������
IBM developerWorks վ���� IBM Cognos Modeling Proven Practices
�ĵ���
Teradata ���ʵ������ֱ�����ӵ� Teradata Business
Views Layer��Ҳ��Ϊ Semantic Views Layer���������� Teradata Physical
Tables��IBM Cognos 8 ���ܹ����ӵ��κ�һ�㣬����������ѭ Teradata ���ʵ����
Teradata Business Views Ӧ��������ϵ� READ
Locks��
Create/Replace view {view name} as Locking
Row for Access Select * From {table name}
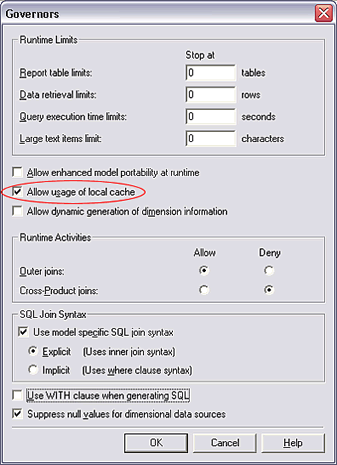
���ػ���
IBM Cognos Framework Manager ���ṩ����Ϣ���ػ���������ã�������Ҫÿ�ζ�����
Teradata���������ø�ѡ���������� Teradata Active Data Warehouse��Ϊ�ˣ���
Project �˵��£�ѡ�� Edit Governors��Ȼ��ѡ�� Allow usage of local
cache��
SQL �����
SQL ��������ܻ�����ܲ���Ӱ�졣Ҫע�⣬��ʹ�� Explicit
Joins vs. Implicit Joins ��ø������ܡ�
Ҫȷ������������� SQL ������������� project Governors
�Ի����е�ѡ�

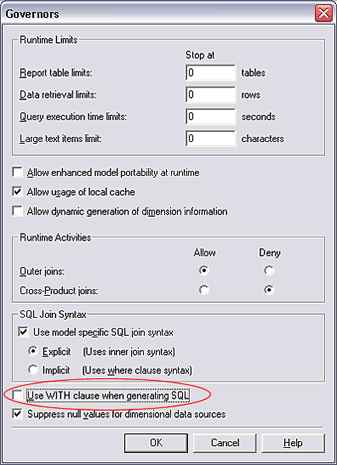
WITH �Ӿ�
���ر� ��Use WITH clause when generating
SQL�� ѡ������ܻ���һЩ��ߡ�
Like Data Types �ϵ�����
ͨ���ڽ� fact ���е������ dimension ���е�������������ʱ����
like �������ͣ����� INT32 to INT32��������߲�ѯ���ܡ�ͨ���� DDL ��ȷ����������һ�£��ڲ�ѯ���е���������ת����صĿ�����Ƚ�С��
���� Durable Models
��Ҫ��С����������Դ�����Ӱ�죬IBM Cognos �������÷ֲ㷽������
IBM Cognos Framework Manager �н���ģ����ơ�������ζ������ʵʩ����Ϣ����μ���Ϊ
��IBM Cognos 8 Framework Manager - Durable Models�� ��
IBM Cognos Proven Practice �ĵ���
���⸽��Ԫ���ݵ���
ǿ�ҽ�����С���� Teradata ��Ԫ���ݵ��á�Ҫ�ﵽ��һĿ�ģ���Ҫ�����������ݿ�/������ļ�ࡣ�Ըò�ı�����ᵼ�¸���Ԫ���ݵ��ã�������Ԫ���ݲ�ѯ������
SQL ѡ�����ʾ�� select ��䣬�Լ����Ӽ����������������Щ���͵Ļ������ڸ��߲�Ľ�ģ�У�������ģ�Ͳ�ѯ��������ɵ�Ԫ����
Business View �У�����������Դ��ѯ����
Ҫȷ�����ݿ�/������ѯ�����Ƿ�������Ԫ���ݵ��ã��ɲ鿴 Query Test
�� ��Response����
ʾ����ѯ�������ڽ���Ԫ���ݵ��ã�
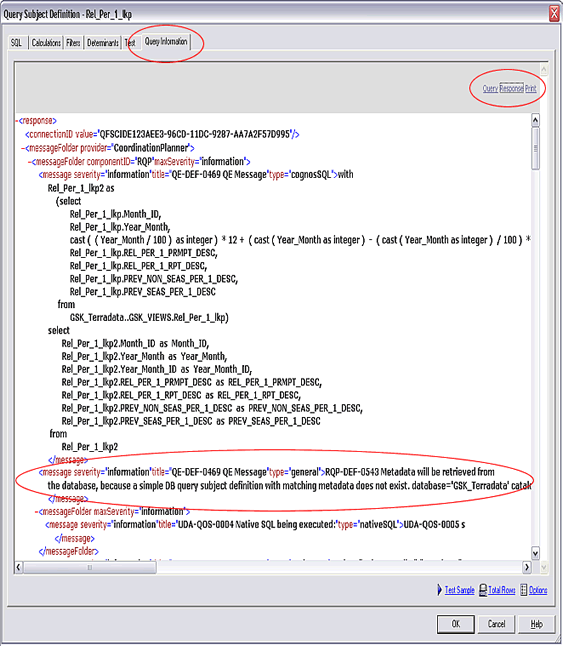
δ����Ԫ���ݵ��õ� Query Test ʾ����
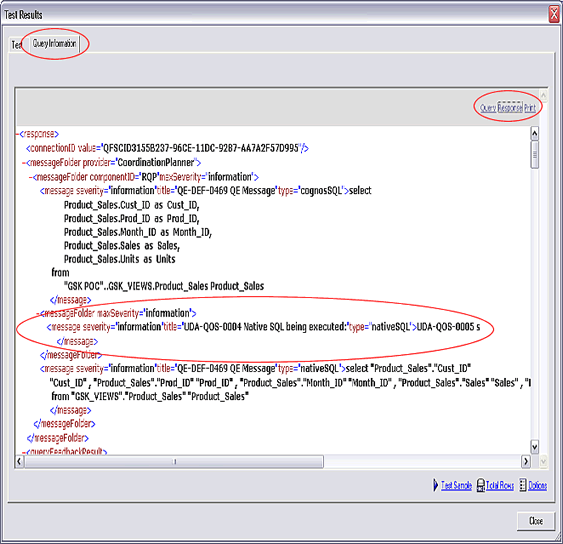
��Ҫ����Եײ�����Դ��Ԫ���ݻص����Ƽ��ķ����Ǵ���һ��ר�ò�ѯ�����������Ԫ���ݡ�Ϊ�ˣ���Ҫ����
Framework Manager ���ƿռ䣬���е�������б�����ͼ�����ֲ��䡣��Щ���ֲ��������Դ��ѯ����ɱ�ģ���е�������ѯ�����������Լ������������á�
Report Studio ��ʹ��
������ Report Studio �������߶ȸ�ʽ���ı���ʱ���ɿ��Dz��ü�����ѡ�
Processing
Processing Ӧ����������Ϊ ��Database only������������
��Limited Local���������Ҫ���� ��Limited Local������ô��Ҫ���·��� Framework
Manager ģ�ͣ����鿴�Ƿ���ڽ� processing ���ݸ� Teradata �ķ�����
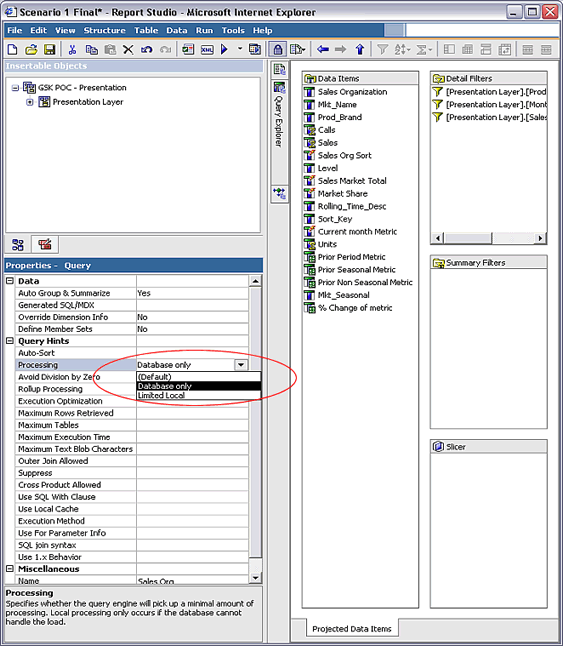
Query Joins��Unions��Intersections ��
Excepts
IBM Cognos 8 Ϊ���濪����Ա�ṩ�˽�������ϲ��������ѯ�еĹ��ܡ���dz����ã�Ȼ��������������������ȫ����������Ҫ�����ڱ��漶�����ӵIJ�ѯʱ���������·���
Teradata �е����ݿ�ܹ��������õ����� Teradata ���ݿ�Ĵ���������
ִ�з���
IBM Cognos 8 �ܹ������ػ�˳������ж�����档Ĭ������£�IBM
Cognos 8 ��������˳���ѯ�����濪����Ա�ܹ����ִ�з��������в�����ѯ��
ע�⣺��ѡ��ת��Ϊ Concurrent ������ζ�ű��潫�����еø��졣���������ţ���˳������ʱ�����潫���ṩ���õ����ܡ��ڽ��䲿������������֮ǰ������������ȫ����ԡ�
���������ѽ��
�����ڲ��Ժ�/�����ѽ���У����÷� IBM Cognos ���ݡ����磬���
Query Subject ���ִ�����ô������Щ�����ж� SQL �����и�����ճ��������֤ SQL
��䡣
���õĹ��߰�����
�� Windows ��Teradata SQL Assistant
�� UNIX �У�Adhoc.c ʾ��Ӧ�ó���
�������߶���ͨ�� ODBC ���ӵ� Teradata�������� ODBC
���������ٴ���֤ SQL ��䡣
������
IBM Cognos �� Teradata Ϊ�ͻ��ṩ�˷dz���Ч�� BI/EDW
����������������г��ļ��ɺͼ����ǶԲ�ͬ�ͻ�վ���ۺϿ���Ľ����ǿ�ҽ�����������е�ÿ�����ɺͼ�������ȫ��IJ��ԣ�ȷ��ʵ�����ض�վ����������ܡ�
|






