摘要:
本文从 MDC Load 的基本原理出发,介绍了 DB2 在 MDC 表上 Load 数据的具体实现过程,并分析了影响
MDC Load 性能的一些因素。
前言
MDC 是在 DB2 V8 中引入的,它可以将在多个维 (dimension)
上具有类似值的行聚集在一起放在连续的磁盘上。在查询性能方面,涉及表中一个或多个指定维的范围查询将从数据的聚合获得好处。这些查询只需要访问包含有指定维值的记录的页,这大大减少了磁盘
I/O,为分析性查询带来极大的性能提高。在 MDC 表中,每个维可以用一个或多个列来定义;数据块 (block)
也称作 extent,是指磁盘上一组连续的数据页,存储在同一数据块上的的数据具有相同的维值;表的维值的每一种唯一组合都形成了一个逻辑单元
(cell),逻辑单元在物理上由数据块组成。
MDC load 把输入数据流中属于同一个 cell 的数据放到磁盘上相同的
block 上。由于输入数据的无序性、数据库缓存的限制以及避免过多磁盘 I/O 的考虑,Load 内部采用了特殊的算法,使用大量缓存来保存部分数据。因此,数据缓存的大小、数据的分布、数据聚集度、cell
数量等等都会对 MDC Load 的性能带来很大的影响。其他一些因素,比如 CPU 并发、磁盘并发、临时空间等等也会对
MDC Load 有一定的影响。本文将对以上影响 MDC Load 性能的各种因素进行详细的分析。
MDC Load 原理介绍
相对于 Insert/Import 操作,Load 可以批量的处理数据,把数据直接的写入磁盘,并且不需要在操作过程中记录日志;同时
Load 仅仅对唯一键 (unique key) 进行约束检查。这些特性都极大的提高了 Load 导入数据的性能。
在最终写入磁盘以前,MDC Load 把属于同一 cell 的数据聚合起来放入内存中的数据缓存
(data buffer) 中。数据缓存由内存中一些连续的数据页组成,大小与 block 相同,并且每个数据缓存仅仅保存属于同一
cell 的数据。数据缓存数量由 Load 命令的 DATA_BUFFER 参数决定。如果用户没有指定
DATA_BUFFER,那么数据缓存将由数据库参数 UTIL_HEAP_SZ 所决定。如果一个数据缓存被写满,其所存储的数据被写入磁盘,同时该数据缓存将被释放并用来存储其他数据;如果该数据缓存没有被写满,它将被保存在内存中用来存储未来读入的数据,我们称这种处于未满状态的数据缓存为
partial extent。一次 Load 操作中,每个 cell 只能有一个 partial extent。由于内存中数据缓存的数量有限,当
MDC 表的 cell 数量过多时,DB2 将无法给新的 cell 分配数据缓存。为了解决这个问题,当数据缓存不够用时
DB2 按照一定算法从内存中的 partial extent 中挑选一个,将其存储的数据写入磁盘,然后将此数据缓存分配给新的
cell。由于 Load 要求属于同一 cell 的数据必须连续存储,所以已经写入磁盘的 partial
extent 可能会被再次从磁盘读入内存,并继续存储数据,直到被写满为止。基于以上设计,在 cell 数量特别多并且数据比较分散的情况下,同一
partial extent 可能会被反复的读写,这增加了系统的 I/O 开销,对 Load 的性能产生很大的影响。
与普通的 Load 不同,MDC Load 要求使用更多的临时空间 (tempspace)。用户在建立表的同时如果指定了索引
(index),Load 将会在数据写入磁盘后进行索引的创建。创建索引要使用大量的内存空间。当内存空间不够用时,临时空间就会被用来保存溢出的排序结果。对于普通的表,保存溢出的排序结果是临时空间的唯一用处。但对于
MDC 表,即使用户不指定索引,块索引 (block index) 和混合索引 (composite index)
也将会被建立,并在结果溢出时存储在临时空间中。MDC Load 还使用一个建立在临时空间上的临时表来保存已知的
cell 信息。当 cell 数量特别多时,临时表将变得很大,此时便要求使用更多的临时空间。
影响 MDC Load 性能的因素
影响 MDC Load 性能的因素非常多,我们这里仅仅针对 MDC 表进行讨论。其他的诸如是否指定
FASTPARSE、DPF prepetition 等等 Load 通用的方法,我们这里将不进行讨论。
数据集的维数 (Distinct Cell):数据文件中 cell 的数量,也就是表的维值的所有唯一组合的数量。
数据的聚集度 (Data Density):属于同一 cell 的数据在数据文件中的分布情况。聚集度高表示属于同一
cell 的数据连续的分布在数据集中;聚集度低表示属于同一 cell 的数据分散在文件的各个位置。数据聚集度在内存比较小的情况下会对
MDC Load 产生很大的影响。
数据缓存 (DATA BUFFER):Load 传送数据所使用的内存数(以
page 为单位的数量)。内存大小对 MDC Load 有较大影响。
排序列表堆 (Sort Heap) 和临时空间 (Temporary Space):索引和临时表所使用的空间。
CPU 并发数 (CPU Parallelism):load 用来处理解析,转换和格式化数据行的线程或者进程数。
磁盘 I/O 并发数 (Disk Parallelism):Load 写数据的线程、进程数。
预排序 (Presort):是指在 Load 数据之前根据 MDC 表的维度对数据进行排序,使数据的聚集度最高。预排序后的数据可以更快的写入磁盘。
本章我们分析一下数据维度和聚集度对 MDC Load 的影响,在下一章将对其它的因素进行分析。
数据维度及聚集度对 MDC Load 性能的影响
因为物理内存的限制,提高 MDC Load 性能采用的主要措施就是尽量减少
I/O。也就是在一次 MDC Load 操作中,尽量避免多次读、写同一数据。下面我们来分析一下具有不同数据维度和聚集度的数据集对
MDC Load 性能的影响。
数据量比较少,可以完全缓存在内存中。当数据量比较少的时候,所有的 partial
extent 都可以存放在内存中,避免了额外的磁盘 I/O。所以这种情况下 MDC Load 的设计已经实现了最优的
I/O。
数据比较多,不能够完全放入内存中;但是数据维数比较少。在这种情况下,虽然用户数据量比较大,但是因为维数少,所产生的
partial extent 也就比较少,能够全部保存在内存里,不需要进行额外的磁盘 I/O,这样也自然实现了
I/O 的最优化。
用户数据比较多,不能够完全放入内存,且维数比较大;但是属于同一维的数据聚集度比较高。数据聚集度高可以实现最优的磁盘
I/O。这是因为即使所有的 partial extent 不能够完全保存在内存中,但是由于属于同一维的数据聚集度比较高,即便某个
partial extent 已经被写入磁盘,我们重新把它读入内存的几率非常小,所以同样也避免了重复读写同一数据的情况发生。
用户数据比较多,不能够完全放入内存,且维数比较大;数据聚集度很低,数据分散。这种极为分散的数据集会对
MDC Load 性能带来很大影响。因为属于同一 cell 的数据会出现在数据集的任何位置,所以随时可能对该
cell 的 partial extent 进行反复读写。一旦 partial extent 被写入磁盘,被重新读回内存的概率极高。数据越分散,Load
在磁盘 I/O 上花费的开销越大,对性能的影响也就越大。我们将在后面的章节对此种情况做重点分析。
MDC Load 性能调优
由于 MDC Load 的特殊性,采用优化的配置和策略可以使性能得到极大的提高。下面我们通过原理分析,并结合具体实例和测试结果来对
MDC Load 进行调优。
准备工作
本文中所有操作都是在 LinuxAMD64 平台上的 DB2 9.7 进行,在其他的平台上也可以得到相似的结果,但不能保证完全一致。首先我们创建一个自动存储类型的数据库,名字叫做
test。然后建立一个简单的 MDC 表 load,这个表有 5 列,我们将在 COL2, COL3,
COL4 上进行聚合。
清单 1. 建立数据库和 MDC 表
db2 create db TEST AUTOMATIC STORAGE YES
DB20000I The CREATE DATABASE command completed successfully.
db2 connect to test
Database Connection Information
Database server = DB2/LINUXX8664 9.7.0
SQL authorization ID = ZHOULI
Local database alias = TEST
db2 drop table load
DB20000I The SQL command completed successfully.
db2 create table load ( COL1 VARCHAR(64), COL2 INTEGER, COL3 VARCHAR(64), COL4 INTEGER,
COL5 VARCHAR(256) )ORGANIZE BY DIMENSIONS (COL2, COL3, COL4)
DB20000I The SQL command completed successfully.
|
为了更好的分析不同因素对性能影响的效果,我们所使用的数据集包含 5000 个不同的 cell,总共 100000
条数据。第 2 列 (COL2) 有 10 个不同的值;第 3 列 (COL3) 有 100 个不同的值,第
4 列 (COL4) 有 5 个不同的值。
清单 2. 数据准备
head -2 loaddata.del
litfvfmqbhqajnjrvpheuoiabgeukeppacoyduihbosjgblkpetpojcrieg,27,hthw,0,
abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz
eetnipchtfdiymllnpegwcpcwpwtlwbcfsuxithanmkypypaeopfqlicqbb,27,uqrd,9,
abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz
awk -F "," '{print $2}' loaddata.del |sort|uniq|wc -l
10
awk -F "," '{print $3}' loaddata.del |sort|uniq|wc -l
100
awk -F "," '{print $4}' loaddata.del |sort|uniq|wc -l
5
|
数据缓存 (DATA BUFFER)
从 MDC Load 的基本原理我们知道增大数据缓存可以使更多的 partial extent 保存在内存中,从而避免额外的磁盘
I/O,提高 Load 的性能。但值得注意的是并不是无限增大 DATA BUFFER 就会使性能得到不断的提升。当所有的
partial extent 都已经能够保存在内存中,增大数据缓存不会使 MDC Load 的性能再得到提高。
下面我们执行清单 3 的 DB2 命令。
清单 3. Load 数据到 MDC 表以验证 DATA BUFFER 对性能的影响
connect to test;
load from loaddata.del of del replace into load DATA BUFFER 5000;
load from loaddata.del of del replace into load DATA BUFFER 10000;
load from loaddata.del of del replace into load DATA BUFFER 20000;
load from loaddata.del of del replace into load DATA BUFFER 30000;
load from loaddata.del of del replace into load DATA BUFFER 40000;
load from loaddata.del of del replace into load DATA BUFFER 50000;
load from loaddata.del of del replace into load DATA BUFFER 60000;
load from loaddata.del of del replace into load DATA BUFFER 70000;
load from loaddata.del of del replace into load DATA BUFFER 80000;
load from loaddata.del of del replace into load DATA BUFFER 90000;
load from loaddata.del of del replace into load DATA BUFFER 100000;
load from loaddata.del of del replace into load DATA BUFFER 120000;
load from loaddata.del of del replace into load DATA BUFFER 150000;
|
表 1. 设置不同 DATA BUFFER,Load 的执行时间

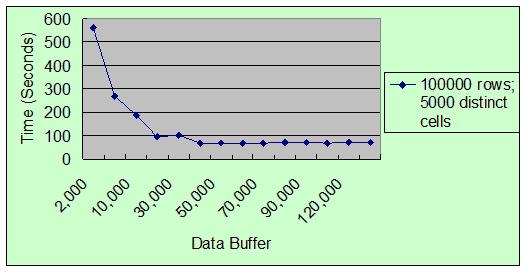
图 1. 设置不同 DATA BUFFER,Load 的执行时间
从表 1 的结果可以看出当 DATA BUFFER 从 2k 增加到 5k 再到 10k,20k,load
执行速度都有将近一倍的提高;但当 DATA BUFFER 达到 40k 以后,MDC Load 的性能基本保持平稳,没有再显著的提高。所以适当的增大
DATA BUFFER 的大小会使 MDC Load 性能得到提高。
排序列表堆 (Sort Heap) 和临时空间 (Temporary
Space)
Sort Heap 和 Temporary Space 主要用在索引的建立上,包括用户指定的索引和 MDC
表的内部索引。对于 MDC 内部索引来说,所需要的内存数量由数据集的 cell 数量决定:如果 cell
数比较少,那么增加或者减少 Sort Heap 对性能几乎没有影响;如果 cell 数比较多,那么就需要更多的内存来创建索引。一旦
Sort Heap 不能提供足够的内存,部分数据将被写到临时空间中;当临时空间也不足以保存数据,数据将会被写到磁盘上。
Temporary Space 还可以用来存放临时表,该临时表记录已知的 cell 信息。同样临时表所需要的临时空间也取决于数据集的
cell 数:当 cell 数比较小,所有的 cell 信息都可以保存在临时空间;当 cell 数量非常大,用户需要增大临时空间以避免部分数据写入磁盘,增加额外的
I/O 开销。
由于在实际场景下多数用户仍然会建立自己的索引以方便快速查找,所以我们在考虑这两个变量的时候也需要将对用户索引排序所使用的内存考虑在内。
清单 4. Load 数据到 MDC 表以验证 Sort Heap 对性能的影响
connect to test;
load from loaddata.del of del replace into load SORT BUFFER 100;
load from loaddata.del of del replace into load SORT BUFFER 500;
load from loaddata.del of del replace into load SORT BUFFER 1500;
load from loaddata.del of del replace into load SORT BUFFER 2000;
load from loaddata.del of del replace into load SORT BUFFER 2500;
load from loaddata.del of del replace into load SORT BUFFER 3000;
load from loaddata.del of del replace into load SORT BUFFER 3500;
load from loaddata.del of del replace into load SORT BUFFER 4000;
load from loaddata.del of del replace into load SORT BUFFER 4500; |
表 2. 设置不同 Sort Heap,Load 的执行时间

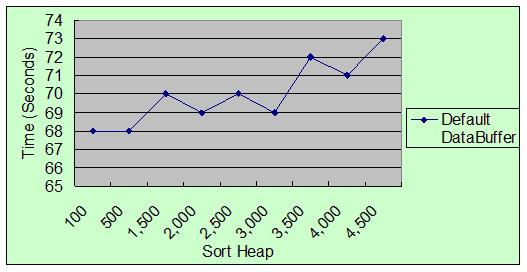
图 1. 设置不同 Sort Heap,Load 的执行时间
从上面的测试结果我们可以看出,Sort Heap 和 Temporary Space 对性能影响很小(小于
10%;在实际应用场景中,小于 5%)。所以在对 MDC Load 来说,使用系统默认值就可以达到理想的效果。
CPU 并发数 (CPU Parallelism)
DB2 Load 可以从多种数据源中读取数据,并且需要将用户数据转变为 DB2 的内部存储格式。Load
使用单独的线程来完成此工作,CPU Parallelism 可以指定 Load 完成格式化工作所使用的线程数。
当系统处于 CPU bound 的时候,表明进行格式化工作的线程已经非常繁忙,格式化的速度远远小于将数据写入磁盘的速度。所以此时增加线程数可以使用户数据更快的被格式化,在相同的时间内有更多的数据被写入磁盘,提高
Load 的性能。
而当系统处于 I/O bound 的时候,增加线程数不会带来性能的提高。有时反而会因为新的线程占用了更多的内存而使其他线程所能使用的内存变少,从而使性能下降。
清单 5. Load 数据到 MDC 表以验证 CPU Parallelism 对性能的影响
connect to test;
load from loaddata2.del of del replace into load CPU_PARALLELISM 1;
load from loaddata2.del of del replace into load CPU_PARALLELISM 2;
load from loaddata2.del of del replace into load CPU_PARALLELISM 3;
load from loaddata2.del of del replace into load CPU_PARALLELISM 4;
load from loaddata2.del of del replace into load CPU_PARALLELISM 5;
load from loaddata2.del of del replace into load CPU_PARALLELISM 6; |
表 3. CPU Parallelism 对性能的影响


图 3. CPU Parallelism 对性能的影响
从上面的结果可以看出,我们把线程数从 1 增加到 2,性能得到一倍以上的提升;再增加到 2,3,4
以后,性能提升不是很明显。同 Sort Heap 一样,我们完全可以使用系统的默认值来取得不错的效果。(由于测试此参数需要使系统处于
CPU bound 下,我们采用了特殊的操作方法和数据,所以结果可能与其它测试有一定差异。)
磁盘 I/O 并发数(Disk Parallelism)
Disk Parallelism 用来指定进行磁盘 I/O 的线程数。增加磁盘 I/O 的并发数并不能带来显著的性能提高;反而由于过度的增大该参数容易使其他线程所用的内存数变小,对性能带来负面影响。总体来说,可以使用
DB2 配置的默认值,用户不必修改此参数。
清单 6. Load 数据到 MDC 表以验证 Disk Parallelism 对性能的影响
connect to test;
load from loaddata.del of del replace into load DISK_PARALLELISM 10;
load from loaddata.del of del replace into load DISK_PARALLELISM 15;
load from loaddata.del of del replace into load DISK_PARALLELISM 20;
load from loaddata.del of del replace into load DISK_PARALLELISM 25;
load from loaddata.del of del replace into load DISK_PARALLELISM 30;
load from loaddata.del of del replace into load DISK_PARALLELISM 35;
load from loaddata.del of del replace into load DISK_PARALLELISM 40;
load from loaddata.del of del replace into load DISK_PARALLELISM 45; |
表 4. Disk Parallelism 对性能的影响

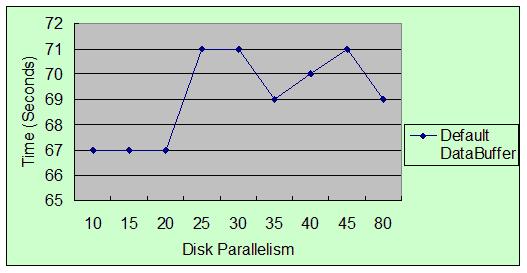
图 4. Disk Parallelism 对性能的影响
数据预排序(Presort)
Load 预排序的数据集到 MDC 表会比没有预排序的数据集要快,这是因为后者可能会导致同一 partial
extent 反复的被写入磁盘,加大了磁盘的 I/O 开销。但是如果把对数据集进行排序的时间也算在内的话,只有当数据集具有以下特点时,预排序才会带来显著的性能提升:
数据集的 cell 数量非常多,仅仅有一小部分可以保存在内存中。
数据的聚合度非常低,也就是说数据极为分散。
如果数据集具有以上特点,那么会使 Load 内部的数据处理过程变得复杂、I/O 显著增大。而通过预排序则可以使
Load 达到近似于非 MDC 表的效果,有效地提高性能。
在实际应用中,预排序适用于数据集可以提前准备好,并且 Load 时间窗口比较短的情况下。例如银行或者移动的某些汇总操作需要在夜间进行,并且要在限定的时间内完成。如果我们能够在
Load 数据以前对数据进行预排序,那么汇总时 Load 的效率将会得到大大的提升。
下面来看一下对我们的实验数据进行测试的结果。
清单 7. 验证 Presort 对性能的影响
sort -t , -k 2,4 loaddata.del > loaddata.sort
connect to test;
load from loaddata.sort of del replace into load DATA BUFFER 2000;
load from loaddata.sort of del replace into load DATA BUFFER 10000;
load from loaddata.sort of del replace into load DATA BUFFER 30000;
load from loaddata.sort of del replace into load DATA BUFFER 40000;
load from loaddata.sort of del replace into load DATA BUFFER 50000; |
表 5. PreSort 对性能的影响

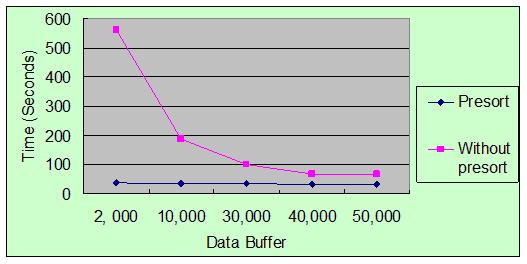
图 5. PreSort 对性能的影响
虽然我们的实验数据量不是特别多,但是由于 cell 数很大,数据很分散,所以在 Data Buffer
比较小的情况下,没有预排序的数据集对性能影响很大。但随着 Data Buffer 数量的增大,更多的 partial
extent 被保存在内存中,磁盘 I/O 减少,预排序对性能的影响变得有限。
结论
综上所述,用户数据集中的 cell 数量、数据分布以及 Load 可使用的内存大小对
MDC Load 的性能起到了决定性因素:当数据量比较小、cell 数较少或者数据聚集度比较高的情况下,MDC
Load 已经自动实现了最优的效果,不需要进行过多的调优操作;当数据量和 cell 数比较多,数据比较分散的情况下,我们可以考虑采用以下的方法进行优化,来提高
MDC Load 的性能:
增大 DATA BUFFER 可以有效地提高 MDC Load 的性能。
增加 sort heap 和 Temporary space 可以提高 MDC Load 的性能,但效果比较有限。
在 CPU bound 的环境下,增加 CPU Parallelism 可以提高 MDC Load 的性能。
增大 Disk Parallelism 参数对性能提升有限;过度增大此参数会带来性能下降。
预排序数据会给性能带来巨大的提高,但仅局限于数据量比较大、cell 数比较多、数据比较分散的情况下。
|






