��������ǰ�������ܵģ����ǿ��Խ��û����ݼ��е�����װ�ص�IWA��������ؼ������ݲ�ѯ��Ч�ʡ����ǣ�����ǰ�߽��ܵģ����ǽ��û������ݼ�������װ�ص�һ̨���������У�����û����ݼ��е����ݷdz���һ̨�����������ڴ���ܲ�������Ҫ����ʱ�����ǿ��Խ��û����ݼ��е�����װ�ص���Ⱥ�Ļ����������ݷֲ�����̨�����������������������������Informix
Ultimate Warehouse Edition 11.7FC4��ʼ�� IWA֧�ּ�Ⱥ���ԡ��ڼ�Ⱥ�����£�������Ҫ����$IWA_INSTALL_DIR/dwa/etc/cluster.conf�ļ���ָ����Ⱥ�������Ľڵ���Ϣ�����ļ��еĵ�һ���ڵ����ΪЭ���ڵ㣨coordinator
node��,�����ڵ����Ϊ�����߽ڵ㣨worker node�������������ǿ��Խ�IWA��Э���ڵ㼰�����ڵ�ֲ��ڲ�ͬ��������������֧�ִ������������ݼ���Ӧ�á�����ͼ��ʾ��
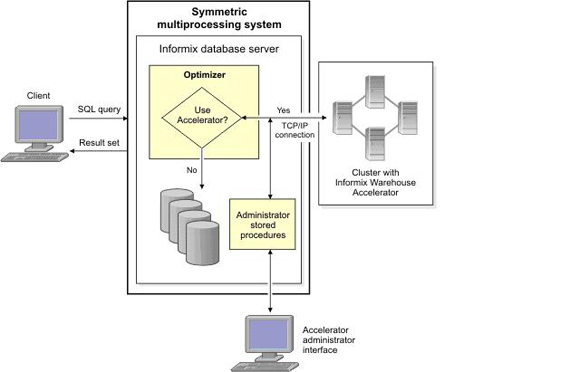
ͼ 1. IWA��װ�ڼ�Ⱥ�����£�Informix�������ͻ��˰�װ�ڲ�ͬ�Ļ�����
���ü�Ⱥ������IWA�ķ���ͬ����������IWA�����÷����������ƣ�����Щ��֮ͬ�����ڼ�Ⱥ�����£�������Ҫ����SSH,
��֤root�û������ڼ�Ⱥ�еĸ����ڵ�֮�䲻��Ҫ��������Ϳ�������Secure Shell (SSH)����Э�顣���⣬������Ҫ�ڼ�Ⱥ�����ù�����Ⱥ�ļ�ϵͳ������GPFS��GFS�ȣ����ڸü�Ⱥ�ļ�ϵͳ�ϴ����������洢Ŀ¼��accelerator
storage directory������Ⱥ�еĸ����ڵ㶼��Ҫ�ܹ�����ͬ��Ŀ¼���������ʸ�Ŀ¼����Լ�Ⱥ������IWA��������cluster.conf�����ļ���ָ����Ⱥ�еĸ����ڵ���Ϣ������dwainst.conf�����ļ���������CLUSTER_INTERFACE
���ò�����ָ����Ⱥ�ڵ��ͨ�ŵ������豸���ơ�
�±ߣ�������һ������ʾ�����������һ�¼�Ⱥ������IWA�����÷�����ϣ���ܹ��Դ������������
��Ⱥ����������IWA�Ļ��������������²��裺
1.����SSH, ��֤root�û������ڼ�Ⱥ�еĸ����ڵ�֮�䲻��Ҫ��������Ϳ�������Secure
Shell (SSH)����Э�顣
2.���ù�����Ⱥ�ļ�ϵͳ������GPFS��GFS�ȡ�
3.����Informix���ݲֿ������IWAʵ������������Informix
�����ݲֿ���������������ã��ڼ�Ⱥ�ļ�ϵͳ�ϴ���storage directory���༭dwainst.conf�����ļ�������cluster.conf�����ļ���������IWAʵ����
4.����Informix ��IWA�����������ӡ�
5.�������ݼ��С�
6.�������ݼ��С�
7.װ�����ݵ����ݼ��С�
���DZ���ʾ�������л���������������Vmware���ֱ�����Suse Linux 11�� ���У�informixva����������Informix
11.7FC4��ͬʱ��װ��IWA��IWA��Э���ڵ�Ҳ�����ڸû����ϣ�����һ̨����iwa1����װ��IWA��IWA��һ�������߽ڵ������ڸû����ϡ�
��̨�������������û�����ͬ����������eth0��eth1�����豸�����У�eth0��ΪDRDA_INTERFACE����ֵ����InformixͬIWA֮���ͨ�ţ�eth1��ΪCLUSTER_INTERFACE��������IWA��Ⱥ�ڵ���ͨ�š�Informixva��iwa1����������������Ϣ���£�
�嵥 1. Informixva��iwa1����������������Ϣ
��informixva����:
root@informixva[demo_on]:/opt/IBM/informix/dwa/etc# ifconfig -a
eth0 Link encap:Ethernet HWaddr 00:0C:29:F6:16:E6
inet addr:192.168.179.100 Bcast:192.168.179.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1132 errors:0 dropped:0 overruns:0 frame:0
TX packets:61434 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:90210 (88.0 Kb) TX bytes:82897027 (79.0 Mb)
eth1 Link encap:Ethernet HWaddr 00:0C:29:F6:16:F0
inet addr:192.168.179.101 Bcast:192.168.179.255
Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:25354 errors:0 dropped:0 overruns:0
frame:0
TX packets:20 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:4926678 (4.6 Mb) TX bytes:1547 (1.5 Kb)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:3146 errors:0 dropped:0 overruns:0
frame:0
TX packets:3146 errors:0 dropped:0 overruns:0
carrier:0
collisions:0 txqueuelen:0
RX bytes:308582 (301.3 Kb) TX bytes:308582 (301.3
Kb)
��iwa1����:
root@iwa1[demo_on]:/opt/IBM/informix/dwa/etc#
ifconfig -a
eth0 Link encap:Ethernet HWaddr 00:0C:29:72:88:ED
inet addr:192.168.179.102 Bcast:192.168.179.255
Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:336 errors:0 dropped:0 overruns:0 frame:0
TX packets:24223 errors:0 dropped:0 overruns:0
carrier:0
collisions:0 txqueuelen:1000
RX bytes:34256 (33.4 Kb) TX bytes:4818872 (4.5
Mb)
eth1 Link encap:Ethernet HWaddr 00:0C:29:72:88:E3
inet addr:192.168.179.103 Bcast:192.168.179.255
Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:60997 errors:0 dropped:0 overruns:0
frame:0
TX packets:9 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:82857485 (79.0 Mb) TX bytes:378 (378.0
b)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:2273 errors:0 dropped:0 overruns:0
frame:0
TX packets:2273 errors:0 dropped:0 overruns:0
carrier:0
collisions:0 txqueuelen:0
RX bytes:184010 (179.6 Kb) TX bytes:184010 (179.6
Kb) |
�±ߣ����Ǿ��彲��һ�¼�Ⱥ������IWA���õľ��岽�裺
1. ����SSH
�ڼ�Ⱥ����������IWA��������Ҫ����SSH, ��֤root�û������ڼ�Ⱥ�еĸ����ڵ�֮�䲻��Ҫ��������Ϳ�������Secure
Shell (SSH)����Э�顣���ǿ���ͨ����������������informixvaͬiwa1֮���SSHͨ�ţ�
��informixva�����ϣ�������root�û���¼����ִ���������
�嵥 2. ��informixva���������÷���
ssh-keygen -b 1024 -t rsa -f ~/.ssh/id_rsa
cd ~/.ssh/id_rsa
cat id_rsa.pub>>authorized_keys
scp id_rsa.pub root@iwa1:~/.ssh/pub1
cat pub2>>authorized_keys |
��iwa1�����ϣ�������root�û���¼����ִ���������
�嵥 3. ��iwa1���������÷���
ssh-keygen -b 1024 -t rsa -f ~/.ssh/id_rsa
cat id_rsa.pub>>authorized_keys
scp id_rsa.pub root@informixva:~/.ssh/pub2
cat pub1>>authorized_keys |
���ǿ���ͨ��ִ�������������SSH����ͨ�ԣ�
�嵥 4. ����SSH����ͨ��
��informixva����:
root@informixva[demo_on]:~/Desktop# ssh iwa1
Last login: Sat Nov 26 04:11:21 2011 from console
root@iwa1[demo_on]:~#
��iwa1����:
root@iwa1[demo_on]:~/Desktop# ssh informixva
Last login: Sat Nov 26 04:09:24 2011 from console
root@informixva[demo_on]:~# |
2. ���ù�����Ⱥ�ļ�ϵͳGPFS
��Ⱥ�����µ�IWA��Ҫ���ù�����Ⱥ�ļ�ϵͳ�����ڸ��ļ�ϵͳ�ϴ����洢Ŀ¼(storage directory)��IWA֧�������ļ�Ⱥ�ļ�ϵͳ������GPFS��GFS�ȡ�����ʾ�������Dz���GPFS��Ⱥ�ļ�ϵͳ��
GPFS����ʹ���߹����ֲ��ڶ���ڵ�Ͷ�������ϵ��ļ������������е�Ӧ�ó���ͬʱ��GPFS �ڵ��飨nodeset���е��κνڵ������ͬ��ͬ���ļ�(�ڵ���
nodeset ������Ϊһ��������ͬ�汾GPFS�Ľڵ�)��GPFS�ļ�ϵͳ�����Ŀ����ʹ���ݷֲ���һ����Ⱥ�е����нڵ��ϣ�����Ӧ�ó���ͨ������UNIX/Linux�ļ�ϵͳ�ӿ����������ݡ��������UNIX/Linux�ļ�ϵͳ������ڵ�һ������������ʹ�ã�����һ������,
�����ļ�������Ҳ��������ض����ļ���ȡ�����ܡ� GPFS ����Ƴ�ͨ����I/O�ֲ��ڶ��Ӳ��������ܣ�ͨ����־���Ƶķ�ʽ��߿ɿ��ԣ���ͨ�����ӽڵ�ķ�ʽ���ϵͳ�Ŀ���չ�ԡ�
����GPFS��Ⱥ�ļ�ϵͳ��Ҫ�漰���¼������裺
2.1 ��װGPFS
���ȣ�������Ҫ��Suse linux 11ϵͳ�ϰ�װGPFS������
GPFS��������Ҫ�������°�װ����
�嵥 5. GPFS������
gpfs.base-3.3.0-0.x86_64.rpm
gpfs.docs-3.3.0-0.noarch.rpm
gpfs.gpl-3.3.0-0.noarch.rpm
gpfs.gui-3.3.0-0.x86_64.rpm
gpfs.msg.en_US-3.3.0-0.noarch.rpm |
���ǿ���ͨ��ִ��������������װ������װ����
�嵥 6. ��װGPFS������
ͬʱ�����ǰ�װ�����²�������
�嵥 7. GPFS������
gpfs.base-3.3.0-3.x86_64.update.rpm
gpfs.docs-3.3.0-3.noarch.rpm
gpfs.gpl-3.3.0-3.noarch.rpm
gpfs.gui-3.3.0-3.x86_64.rpm
gpfs.msg.en_US-3.3.0-3.noarch.rpm |
����ͨ��ִ��������������װ������������
�嵥 8. ��װGPFS������
���ǻ�����ִ������������GPFS�Ƿ�װ��ȷ��
�嵥 9. ���GPFS������
root@iwa1[demo_on]:/data/fp# rpm -qa|grep gpfs
gpfs.gui-3.3.0-3
gpfs.base-3.3.0-3
gpfs.docs-3.3.0-3
gpfs.gpl-3.3.0-3
gpfs.msg.en_US-3.3.0-3 |
2.2 ��linux�ں��н���GPFS����ֲ��
���ǿ���ִ������������linux�ں��н���GPFS����ֲ�㣺
�嵥 10. ��linux�ں��н���GPFS����ֲ��
cd /usr/lpp/mmfs/src
make Autoconfig
make World
make InstallImages |
2.3 ʹ��mmcrcluster�����GPFS Cluster
����ʾ���У�������Ҫ��informixva��iwa1��̨linux�������ϴ���GPFS ��Ⱥ�����ȣ�������informixva�����ϴ���/tmp/gpfs.node�ļ�����ָ��������Ϣ��
�嵥 11. ����GPFS Cluster�ڵ�
cat /tmp/gpfs.node
informixva:quorum-manager
iwa1:quorum-manager |
gpfs.node�ļ������������ݣ�ÿ�����ݵĵ�һ��Ϊ��ʹ�û��������������ڶ���Ϊ���������quorum�ڵ��ָ����manager�ڵ��ָ����
������ִ����������������GPFS��Ⱥ��
�嵥 12. ����GPFS ��Ⱥ
#mmcrcluster -n /tmp/gpfs.node -p informixva -s iwa1 -r /usr/bin/ssh -R /usr/bin/scp
Tue Nov 8 11:42:04 EST 2011: mmcrcluster: Processing node informixva
Tue Nov 8 11:42:04 EST 2011: mmcrcluster: Processing node iwa1
mmcrcluster: Command successfully completed
mmcrcluster: Warning: Not all nodes have proper GPFS license designations.
Use the mmchlicense command to designate licenses as needed.
mmcrcluster: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
root@informixva[demo_on]:/usr/lpp/mmfs/src# |
mmcrcluster����ĸ�ѡ�����壺-Nָ��gpfs.node�ļ���-Cָ����Ⱥ���ƣ�-pָ����NSD��������-sָ����NSD��������-rָ����̨����֮������ӷ�ʽ��-Rָ����̨����֮���ļ�����ķ�ʽ��
���ǿ���ʹ��mmlscluster����鿴����cluster�������Ϣ��
�嵥 13. �鿴GPFS ��Ⱥ
./mmlscluster
GPFS cluster information
========================
GPFS cluster name: informixva
GPFS cluster id: 13882543094768425948
GPFS UID domain: informixva
Remote shell command: /usr/bin/ssh
Remote file copy command: /usr/bin/scp
GPFS cluster configuration servers:
-----------------------------------
Primary server: informixva
Secondary server: iwa1
Node Daemon node name IP address Admin node name
Designation
------------------------------------------------------------------------
1 informixva 192.168.179.100 informixva quorum-manager
2 iwa1 192.168.179.102 iwa1 quorum-manager
root@informixva[demo_on]:/var/mmfs/gen# |
����֮ǰû�н���license������������Ҫִ����������������license��
�嵥 14. ����GPFS license
root@informixva[demo_on]:/usr/lpp/mmfs# mmchlicense server --accept -N informixva
The following nodes will be designated as possessing GPFS server licenses:
informixva
mmchlicense: Command successfully completed
mmchlicense: Warning: Not all nodes have proper GPFS license designations.
Use the mmchlicense command to designate licenses as needed.
mmchlicense: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
root@informixva[demo_on]:/usr/lpp/mmfs#mmchlicense server --accept -N iwa1
The following nodes will be designated as possessing GPFS server licenses:
iwa1
mmchlicense: Command successfully completed
mmchlicense: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process. |
2.4 ����GPFS ��Ⱥ
���ǿ���ִ��������������GPFS��Ⱥ��
�嵥 15. ����GPFS��Ⱥ
ͬʱ�����ǿ���ͨ��ִ����������۲�GPFS��Ⱥ���:
�嵥 16. �鿴GPFS��Ⱥ���
root@informixva[demo_on]:/data# mmgetstate -Lsa
Node number Node name Quorum Nodes up Total nodes
GPFS state Remarks
-------------------------------------------------------------------------------
1 informixva 2 2 2 active quorum node
2 iwa1 2 2 2 active quorum node
Summary information
---------------------
Number of nodes defined in the cluster: 2
Number of local nodes active in the cluster: 2
Number of remote nodes joined in this cluster:
0
Number of quorum nodes defined in the cluster:
2
Number of quorum nodes active in the cluster:
2
Quorum = 2, Quorum achieved
root@informixva[demo_on]:/var/mmfs/gen# |
����Ҳ����ͨ�����/var/adm/ras/mmfs.log.latest��־�ļ��鿴GPFS��Ⱥִ��״̬��Ϣ��
�嵥 17. �鿴��־��Ϣ
root@informixva[demo_on]:/data# cat /var/adm/ras/mmfs.log.latest
Tue Nov 8 12:03:32 EST 2011: runmmfs starting
Removing old /var/adm/ras/mmfs.log.* files:
/bin/mv: cannot stat `/var/adm/ras/mmfs.log.previous': No such file or directory
Unloading modules from /lib/modules/2.6.27.39-0.3-default/extra
Loading modules from /lib/modules/2.6.27.39-0.3-default/extra
Module Size Used by
mmfs26 1499720 0
mmfslinux 300776 1 mmfs26
tracedev 32560 2 mmfs26,mmfslinux
Tue Nov 8 12:03:36.839 2011: mmfsd initializing.
{Version: 3.3.0.3 Built: Dec 3 2009 14:45:03} ...
Tue Nov 8 12:03:40.082 2011: Connecting to 192.168.179.101 iwa1
Tue Nov 8 12:03:41.017 2011: Accepted and connected to 192.168.179.101 iwa1
Tue Nov 8 12:03:45.602 2011: This node (192.168.179.100 (informixva))
is now Cluster Manager for informixva.
Tue Nov 8 12:03:45.792 2011: mmfsd ready
Tue Nov 8 12:03:45 EST 2011: mmcommon mmfsup invoked. Parameters:
192.168.179.100 192.168.179.100 all
root@informixva[demo_on]:/data# |
2.5 ʹ��mmcrnsd�����nsd��
������������̨������ÿ̨�����϶��Ѿ���װ��GPFS��������������̨������ֻ��ϵͳ�̣���GPFS��Ҫ����������֧���ļ�ϵͳ���������ǽ�����Ҫ������̨������ʹ��dd��������������Ĵ��̣����ļ�ģ����̣���
�嵥 18. ʹ��dd�����������������
��informixva�����ϴ���/data/disk1
dd if=/dev/zero of=/data/disk1 bs=1M count=1000 # 1G
��iwa1�����ϴ���/data/disk2
dd if=/dev/zero of=/data/disk2 bs=1M count=1000 # 1G |
��������������informixva�����ϴ���/tmp/disk1.node�ļ�������������Ϣ��
�嵥 19. /tmp/disk1.node�ļ�
/data/disk1:informixva::dataAndMetadata:1:nsd1: |
��ִ�������������NSD1��
�嵥 20. ����NSD1
mmcrnsd -F /tmp/disk1.node -v no
mmcrnsd: Processing disk /data/disk1
mmcrnsd: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
root@informixva[demo_on]:/data# |
ͬ����������iwa1�����ϴ���/tmp/disk2.node�ļ�������������Ϣ��
�嵥 21. /tmp/disk2.node�ļ�
/data/disk2:iwa1::dataAndMetadata:1:nsd2: |
��ִ�������������NSD2��
�嵥 22. ����NSD2
mmcrnsd -F /tmp/disk2.node -v no
mmcrnsd: Processing disk /data/disk2
mmcrnsd: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
root@informixva[demo_on]:/data# |
���ǿ���ͨ��ִ����������鿴NSD�����Ϣ��
�嵥 23. �鿴NSD��Ϣ
root@informixva[demo_on]:/data# mmlsnsd -m
Disk name NSD volume ID Device Node name Remarks
----------------------------------------------------------------------------------
nsd1 C0A8B3644EB95F78 /data/disk1 informixva server
node
nsd2 C0A8B3644EB95FBF /data/disk2 iwa1 server
node |
2.6 ʹ��mmcrfs�����GPFS�ļ�ϵͳ
���ȣ�������informixva�����ϴ������ص㣺mkdir /gpfs1,������/tmp/nsdfile�ļ����������ǸղŴ�����NSD������Ϣ��
�嵥 24. /tmp/nsdfile�ļ�
cat /tmp/nsdfile
nsd1
nds2 |
�����������ǿ���ִ����������������GPFS�ļ�ϵͳ��
�嵥 25. ����GPFS�ļ�ϵͳ
# mmcrfs /gpfs1 /dev/gpfs1 -F /tmp/nsdfile -A yes -B 512k -m 1 -M 2 -r 1 -R 2
The following disks of gpfs will be formatted
on node informixva:
nsd1: size 1024000 KB
nsd2: size 1024000 KB
Formatting file system ...
Disks up to size 29 GB can be added to storage
pool 'system'.
Creating Inode File
Creating Allocation Maps
Clearing Inode Allocation Map
Clearing Block Allocation Map
Formatting Allocation Map for storage pool 'system'
Completed creation of file system /dev/gpfs.
mmcrfs: Propagating the cluster configuration
data to all
affected nodes. This is an asynchronous process. |
���У�mmcrfs ����IJ����������£�
1./gpfs1���ļ�ϵͳ mount ������
2./dev/gpfs1: ָ���ļ�ϵͳ lv ����
3.-F ָ�� NSD ���ļ���
4.-A �Զ� mount ѡ��Ϊ yes
5.-B ���СΪ512K
��ʱ��������informixva������ʹ��cat /etc/fstab����鿴��ǰ����ϵͳ�ڵ��ļ��豸��
�嵥 26. informixva������/etc/fstab�ļ�
cat /etc/fstab
/dev/sda1 swap swap defaults 0 0
/dev/sda2 / ext3 acl,user_xattr 1 0
/dev/sdb1 /data ext3 acl,user_xattr 1 0
proc /proc proc defaults 0 0
sysfs /sys sysfs noauto 0 0
debugfs /sys/kernel/debug debugfs noauto 0 0
usbfs /proc/bus/usb usbfs noauto 0 0
devpts /dev/pts devpts mode=0620,gid=5 0 0
# Beginning of the block added by the VMware software
.host:/ /mnt/hgfs vmhgfs defaults,ttl=5 0 0
# End of the block added by the VMware software
/dev/gpfs1 /gpfs1 gpfs rw,mtime,atime,dev=gpfs1,autostart 0 0
|
ͬ����������iwa1������ʹ��cat /etc/fstab����鿴��ǰ����ϵͳ�ڵ��ļ��豸��
�嵥 27. iwa1������/etc/fstab�ļ�
cat /etc/fstab
/dev/sda1 swap swap defaults 0 0
/dev/sda2 / ext3 acl,user_xattr 1 0
/dev/sdb1 /data ext3 acl,user_xattr 1 0
proc /proc proc defaults 0 0
sysfs /sys sysfs noauto 0 0
debugfs /sys/kernel/debug debugfs noauto 0 0
usbfs /proc/bus/usb usbfs noauto 0 0
devpts /dev/pts devpts mode=0620,gid=5 0 0
# Beginning of the block added by the VMware software
.host:/ /mnt/hgfs vmhgfs defaults,ttl=5 0 0
# End of the block added by the VMware software
/dev/gpfs1 /gpfs1 gpfs rw,mtime,atime,dev=gpfs1,autostart
0 0 |
2.7 �����ļ�ϵͳ
��informixva�����ϣ�ͨ�������������gpfs1�ļ�ϵͳ��
�嵥 28. ��informixva�����Ϲ���gpfs1�ļ�ϵͳ
���ǿ�����informixva��iwa1������ִ����������鿴GPFS��Ⱥ��״̬��Ϣ��
�嵥 29. �鿴GPFS��Ⱥ��״̬��Ϣ
root@informixva[demo_on]:/# mmlsconfig
Configuration data for cluster informixva:
------------------------------------------
clusterName informixva
clusterId 13882543094768425948
autoload no
minReleaseLevel 3.3.0.2
dmapiFileHandleSize 32
adminMode central
File systems in cluster informixva:
----------------------------------
/dev/gpfs1 |
3. ����Informix���ݲֿ������IWAʵ��
���ȣ�������Ҫ��������Informix �����ݲֿ���������������á������ϱ������ܵģ�����ʾ���е�informixva��iwa1��̨�������������û�����ͬ����������eth0��eth1�����豸�����У�eth0��ΪDRDA_INTERFACE����ֵ����InformixͬIWA֮���ͨ�ţ�eth1��ΪCLUSTER_INTERFACE��������IWA��Ⱥ�ڵ���ͨ�š�
��������������Ҫ�ڹ�����Ⱥ�ļ�ϵͳ��ΪIWA�����洢Ŀ¼���������洢Ŀ¼��Ҫ�����洢������Ԫ������Ϣ�����ݼ����ڴ����ݵĴ��̾�����־��Ϣ�Լ�������Ϣ�ȡ��������ݼ������ݵĴ��̾���Ҫ�����ڸ�Ŀ¼�У�����������������ӣ���ˣ���Ŀ¼Ҫ���㹻�Ŀռ䣬Ҳ�����齫��Ŀ¼������IWA��װĿ¼�¡�ͬʱ����Ⱥ�еĸ����ڵ㶼��Ҫ�ܹ�����ͬ��Ŀ¼���������ʸ�Ŀ¼��
���ǿ���ʹ��dwainst.conf�����ļ��е�DWADIR���ò�����ָ���洢·����λ�á����±���ʾ���ڱ���ʾ���У�������/gpfs1/demoĿ¼�´����˼������洢Ŀ¼��
�嵥 30. ��/gpfs1/demoĿ¼�´����������洢Ŀ¼
root@informixva[demo_on]:/gpfs1# mkdir demo
root@informixva[demo_on]:/gpfs1# cd demo |
�ڴ�����������洢Ŀ¼������Ҫ����dwainst.conf �����������ļ���cluster.conf��Ⱥ�����ļ���dwainst.conf
�����������ļ����ڶ�IWA�������ã�cluster.conf��Ⱥ�����ļ��������ü�Ⱥ�ڵ���Ϣ������Ҫ������ondwa
setup����֮ǰ���������ļ��������á�
dwainst.conf�����������ļ�Ĭ�ϰ�װ��$IWA_INSTALL_DIR/dwa/etcĿ¼�¡����ļ����ò����͵���������IWA������ͬ����Ⱥ������IWA������������£�
�� 1. dwainst.conf ��Ⱥ���ò�����

���±���ʾ���ڱ���ʾ���У����Ƕ�dwainst.conf�����ļ��������������ã�
�嵥 31. dwainst.conf�����ļ�
# DWA storage directory
# Stores the catalog, marts, logs, traces etc.
DWADIR=/gpfs1/demo
# Starting port number
# Grows to START_PORT-1+DEFAULT_NUMBER_ENTITLED_NODES*4
.
START_PORT=21020
# Number of DWA_CM processes
NUM_NODES=2
# Worker shared memory
# SHM (in Megabyte) for all worker nodes.
# Minimum value is 1 percent of physical memory.
WORKER_SHM=520
# Coordinator shared memory
# SHM (in Megabyte) for all coordinator nodes.
# Minimum value is 1 percent of physical memory.
COORDINATOR_SHM=250
# DRDA network interface
# For running the accelerator on a separate computer
ask the system
# administrator for the network interface (e.g.
eth0) that the Informix
# database server should connect to or run the
ifconfig command to find the
# network interface.
DRDA_INTERFACE=eth0
CLUSTER_INTERFACE=eth1
CORES_FOR_LOAD_THREADS_PERCENTAGE=100
CORES_FOR_REORG_THREADS_PERCENTAGE=25
CORES_FOR_SCAN_THREADS_PERCENTAGE=100 |
ͬʱ��������Ҫ��$IWA_INSTALL_DIR/dwa/etcĿ¼�´���cluster.conf �ļ������漯Ⱥ�ڵ���������IP��ַ����cluster.conf
�ļ��У�ÿһ����Ⱥ�ڵ�ռ��һ�У����ļ��еĵ�һ���ڵ����ΪIWAЭ���ڵ㣨coordinator node��,�����ڵ����ΪIWA�����߽ڵ㣨worker
node�����ļ��м�Ⱥ�ڵ��˳�����ondwa start ��ondwa stop����������ֹͣ�ڵ��˳���ڱ���ʾ���У����Ƕ�cluster.conf�����ļ��������������ã�
�嵥 32. cluster.conf�����ļ�
������������Ҫ���С�ondwa setup������������Informix���ݲֿ������IWAʵ������ʱ����Ҫ���ļ�����Ŀ¼�����ǿ����ڼ�Ⱥ�е�����һ���ڵ�������ondwa���������û�����IWAʵ����ondwa�������cluster.conf
�ļ�������ļ�Ⱥ�ڵ������и����
���±���ʾ��������root�û�ִ�С�ondwa setup������������ȡdwainst.conf��cluster.conf�����ļ�����IWAʵ���������ã�
���ڼ������洢Ŀ¼�´������½ṹ��
1.IWA�ڵ�乲��Ŀ¼(shared)
2.�����ڵ�˽��·����Ŀ¼(local)
3.����ÿһ���ڵ�:
1)�ڵ�˽��Ŀ¼: local/#node#
2)�ڵ������ļ�: #node#.conf
3)�C ָ��DWA_CM ��ִ���ļ�������: DWA_CM_#node#
�ڱ���ʾ���У�����ΪIWAʵ��ָ����2���ڵ㣬��ˣ�IWA������1��Э���߽ڵ�node0��1�������߽ڵ�node1������localĿ¼�´�����node0��node1�ڵ�˽��Ŀ¼����Ӧ��node0.conf��node1.conf
2���ڵ������ļ���������DWA_CM_node0��DWA_CM_node1ָ��IWA��ִ���ļ������ӡ�
�嵥 33. ִ��ondwa setup����
root@informixva[demo_on]:/gpfs1/demo # ondwa setup
root@informixva[demo_on]:/gpfs1/demo# ls -l
total 64
DWA_CM_node0 -> /opt/IBM/informix/dwa/bin/dwa/DWA_CM
DWA_CM_node1 -> /opt/IBM/informix/dwa/bin/dwa/DWA_CM
drwxr-xr-x 4 informix informix 16384 2011-11-13 11:22 local
-r--r--r-- 1 informix informix 916 2011-11-13 11:22 node0.conf
-r--r--r-- 1 informix informix 916 2011-11-13 11:22 node1.conf
drwxr-xr-x 2 informix informix 16384 2011-11-13 11:22 shared |
���ǾͿ���ͨ��ִ�С�ondwa start������������IWAʵ������������ʾ��������informixva��������root�û����С�ondwa
start��������IWAʵ�������������IWA���еĽڵ㣬�����ڵ�������Ϣ��¼��ÿ���ڵ����־�ļ��У���node0.log,
node1.log������ondwa start������ִ�гɹ���IWAʵ���Ϳ���ʹ���ˡ�
�嵥 34. ����IWAʵ��
root@informixva[demo_on]:/gpfs1/demo# ondwa start
Starting DWA_CM_node0 on informixva: started
Starting DWA_CM_node1 on iwa1: started |
���ǿ���������������鿴IWAʵ������״����
�嵥 35. �鿴IWAʵ������״��
root@informixva[demo_on]:/gpfs1/demo# ondwa status
ID | Role | Cat-Status | HB-Status | Hostname | System ID
-----+-------------+-------------+--------------
0 | COORDINATOR | ACTIVE | Healthy | informixva | 1
1 | WORKER | ACTIVE | Healthy | iwa1 | 2
Cluster is in state : Fully Operational
Expected node count : 1 coordinator and 1 worker
nodes
root@informixva[demo_on]:/gpfs1/demo# |
ͬʱ�����ǻ�������informixva��iwa1������������������鿴IWA������Ϣ��
�嵥 36. �鿴IWA����
��informixva������:
root@informixva[demo_on]:/gpfs1/demo# ps -ef|grep DWA
informix 19294 1 0 11:23 ? 00:00:00 ./DWA_CM_node0 --no-console
root 19322 1 0 11:23 ? /bin/bash /opt/IBM/informix/dwa/etc/DWA_watchdog -daemon 0
root@informixva[demo_on]:/gpfs1/demo#
��iwa1������:
root@iwa1[demo_on]:/opt/IBM/informix/dwa/etc# ps -ef|grep DWA
informix 17787 1 0 11:23 ? 00:00:00 ./DWA_CM_node1 --no-console
root 17815 1 0 11:23 ? /bin/bash /opt/IBM/informix/dwa/etc/DWA_watchdog -daemon 1
root 18049 5389 0 11:25 pts/0 00:00:00 grep DWA
root@iwa1[demo_on]:/opt/IBM/informix/dwa/etc# |
ͨ�����ڼ�Ⱥ�����µ�IWA�����ǽ�����ÿһ����Ⱥ�ڵ�������һ��IWAЭ���ڵ�����߽ڵ㣬ͬ��������Ҳ������һ����Ⱥ�ڵ������ж�������߽ڵ㡣���磬���ǿ���ָ����informixva����������һ��Э���߽ڵ㼰һ�������߽ڵ㣬��iwa1����������һ�������߽ڵ㣬������������Ҫ��dwainst.conf�����ļ���ָ����
�嵥 37. dwainst.conf�ļ�
# Number of DWA_CM processes
NUM_NODES=3 |
��cluster.conf�����ļ��н����������ã�
�嵥 38. cluster.conf�ļ�
informixva
informixva
iwa1 |
����������������IWAʵ������informixva�����ϣ�������һ��Э���߽ڵ㼰һ�������߽ڵ㣬��iwa1�����Ͻ�����һ�������߽ڵ㣬���±���ʾ��
�嵥 39. IWAʵ��״̬��Ϣ
root@informixva[demo_on]:/opt/IBM/informix/dwa/etc# ondwa status
ID | Role | Cat-Status | HB-Status | Hostname | System ID
-----+-------------+-------------+--------------+-------
0 | COORDINATOR | ACTIVE | Healthy | informixva | 1
1 | WORKER | ACTIVE | Healthy | informixva | 2
2 | WORKER | ACTIVE | Healthy | iwa1 | 3
Cluster is in state : Fully Operational
Expected node count : 1 coordinator and 2 worker
nodes |
ͬʱ������Ҳ������informixva��iwa1�����ϲ鿴IWA������Ϣ��
�嵥 40. IWAʵ��������Ϣ
��informixva������:
root@informixva[demo_on]:/opt/IBM/informix/dwa/etc# ps -ef|grep DWA
informix 27803 1 0 11:04 ? 00:00:00 ./DWA_CM_node0 --no-console
root 27828 1 0 11:04 ? /bin/bash /opt/IBM/informix/dwa/etc/DWA_watchdog -daemon 0
informix 28141 1 0 11:04 ? 00:00:00 ./DWA_CM_node1 --no-console
root 28160 1 0 11:04 ? /bin/bash /opt/IBM/informix/dwa/etc/DWA_watchdog -daemon 1
root 28395 25297 0 11:04 pts/1 00:00:00 grep DWA
��iwa1������:
root@iwa1[demo_on]:/opt/IBM/informix/dwa/etc#
ps -ef|grep DWA
informix 26905 1 0 11:04 ? 00:00:00 ./DWA_CM_node2
--no-console
root 26929 1 0 11:04 /bin/bash /opt/IBM/in
formix/dwa/etc/DWA_watchdog -daemon 2 root 27100 6819 99 11:04 pts/0 00:00:00 grep DWA
|
4. ����Informix��������������
���ȣ�������Ҫ���С�ondwa getpin����������ȡ���ݲֿ��������IP��ַ,
�˿ںż�PIN���롣��������ʾ��������root�û����� ��ondwa getpin�������ȡ��IWA��ǰ��IP��ַ,
�˿ںż�PIN����Ϊ��192.168.179.100 21022 4028��
�嵥 41. ��ȡ���ݲֿ������IP��ַ, �˿ںż�PIN����
root@informixva[demo_on]:~/Desktop# ondwa getpin
192.168.179.100 21022 4028
root@informixva[demo_on]:~/Desktop# |
��������������Ҫ��Informix���ݲֿ��������������IBM Smart Analytics Optimizer
Studio �д���ͬInformix���ݿ������ds2,��Ϊds2���ݿⴴ��һ���µļ�����������ͼ��ʾ������Ϊds2���ݿⴴ����IWADEMO��������
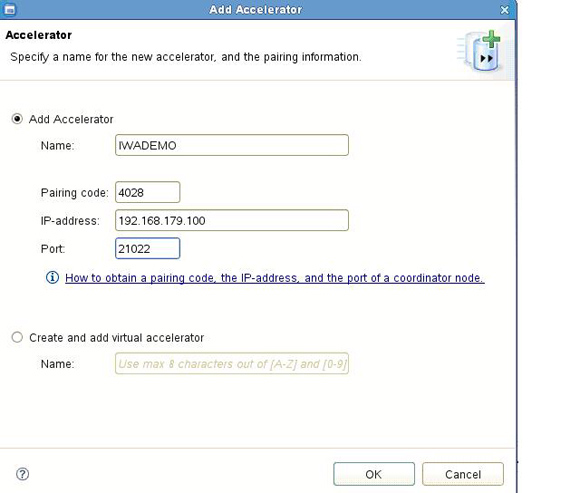
ͼ 2. Ϊds2���ݿⴴ��IWADEMO������
��������������Ϣ��
Name: IWADEMO
Paring code: 4028
IP-address: 192.168.179.100
Port: 21022 |
5. �������ݼ���
���ȣ�������Ҫ���һ����Ч�����ݼ��С��ڱ���ʾ���У����������IWAMart���ݼ��У���������salecost��ʵ����shop��goodsά����
��ƺ����ݼ���֮��������Ҫ��Informix���ݲֿ��������������IBM
Smart Analytics Optimizer Studio �д������ݼ��еĶ��塣���ݼ��ж�����Ϣ������XML�ļ��У������������ݼ����ж���ı����ֶ��Լ����ͱ�֮��Ĺ�ϵ��XML�ļ�ֻ�������ݼ��еĶ�����Ϣ�����������û�ʵ�����ݡ�
���������ݼ���ʱ�����ݼ��ж�����Ϣ������IWA�����ݼ��гɹ������IWA�Ὣ���ݼ��ж�����Ϣ��SQL�����ʽ���ظ�Informix���ݿⲢ��Informix���ݿ�ϵͳ���д���accelerated
query table or AQT�����û�������ѯ�����Informix�Ż����Ὣ�û���ѯ���ͬAQT����ƥ�䣬���������IJ�ѯ���ᱻ��·�ɵ�IWA�����ӿ��ѯ�ٶȡ�
���ȣ�����Ҫ��IBM Smart Analytics Optimizer
Studio�д���һ��accelerator ���̡�����ͼ��ʾ���ڱ���ʾ���У����Ǵ�����IWADEMO���̡�
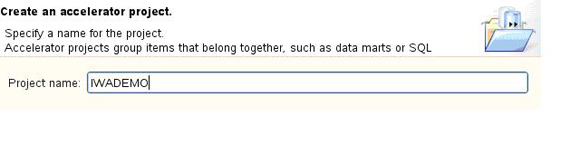
ͼ 3. ����IWADEMO����
��������������IWADEMO������ʹ��New Data Mart wizard
����IWAMart���ݼ��У�����ͼ��ʾ��
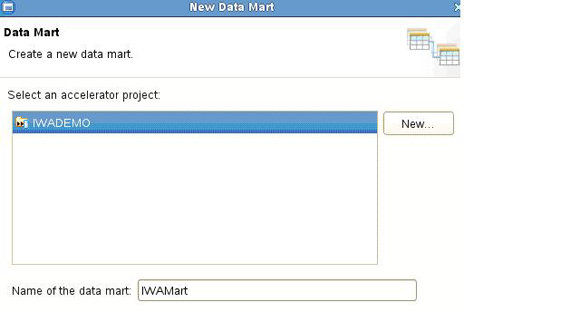
ͼ 4. ����IWAMart���ݼ���
������salecost��ʵ����shop��goodsά����IWAMart���ݼ��У�����ͼ��ʾ������ѡ��salecost��Ϊ��ʵ�������Լ��������ݼ�������ʵ���Լ�ά��֮������ӡ�
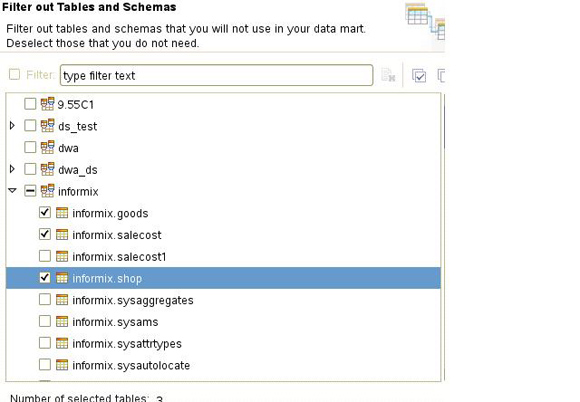
ͼ 5. ������ʵ�������ά����IWAMart���ݼ���
�ڶ�������ݼ��к�������Ҫ�Դ��������ݼ��ж��������������֤��������IWAMart���ݼ����ϵ���Ҽ�ѡ��Validate��IWAMart���ݼ��н�����������֤��
6. ����װ�����ݼ���
���������ɺ�XML��ʽ�����ݼ��ж�����Ϣ��������Ҫ���䲿��IWA�С����������ݼ���ʱ�����ݼ��ж�����Ϣ������IWA�����ݼ��гɹ������IWA�Ὣ���ݼ��ж�����Ϣ��SQL�����ʽ���ظ�Informix���ݿⲢ��Informix���ݿ�ϵͳ���д���accelerated
query table or AQT��ƥ���û��IJ�ѯ��䡣���ǿ��Բ���IBM Smart Analytics
Optimizer Studio����java CLI���������ݼ��С�
�����ݼ��гɹ���������ݼ��д���LOAD PENDING״̬�����Ҳ����ã�ֱ������װ����ɺ����ݼ��вſ���ʹ�á�
����ͼ��ʾ��������IBM Smart Analytics Optimizer
Studio�����е�Data Source Exploerѡ��IWADEMO������ʵ���������������У�ѡ��Data
Marts�������Deploy��ť������װ�����ݼ��У�
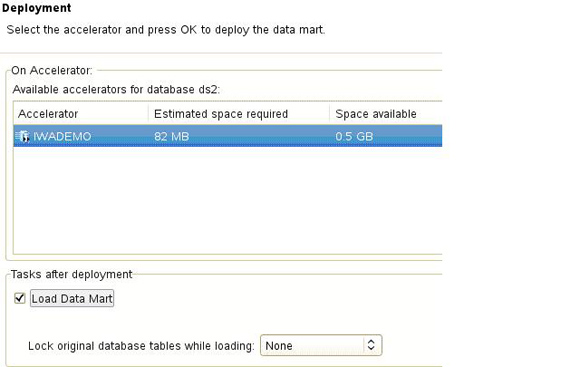
ͼ 6. ����װ�����ݼ���
7. SQL��ѯ������
�����ݼ���װ�سɹ������ǾͿ����������ݼ������������ݲ�ѯ��Informix���ݿ��Ż�������ݸ�ͳ����Ϣ�������û���ѯ������ʵ���Ƿ��AQT�е���ʵ����ͬ���������ͬ���ò�ѯ���Ͳ����ض���IWA��ȥ���С���������������Ҫ����PDQPRIORITY������������Informix�Ż������ῼ��star
join plan�����ҿ�����ȷѡ����ʵ�������ǻ���Ҫ����use_dwa���������ǿ���ͨ������use_dwa����������Inforix�Ż����Ƿ�ʹ��IWA���������ݲ�ѯ��������ǽ�use_dwa������Ϊ0�����߲��������ã��û��IJ�ѯ��佫�����ض���IWA�����١������use_dwa��������Ϊ1���û��IJ�ѯ��佫���ض���IWA�����١�
���±���ʾ���ڱ���ʾ���У�����ͨ��set environment use_dwa
'1'�������øñ�������������ѯ��䱻�ض���IWA�����ٲ�ѯ��Ϊ���ܹ����õز鿴�û���ѯ����Ƿ��ض���IWA����ʾ���У����Ƕ�ִ�е�SQL����ռ���ִ�мƻ������������ǿ���ͨ���鿴SQL����ִ�мƻ������SQL����Ƿ��ض���IWA�����ٲ�ѯ��
�嵥 42. query1_iwa.sql��ѯ���
informix@informixva[demo_on]: cat query1_iwa.sql
set explain file to '/tmp/query1_iwa.out';
set explain on;
set environment use_dwa '1';
set PDQPRIORITY 100;
select a.ShopID,b.Name ShopName,a.DeptID,sum(a.Qty) Qty,sum(a.SaleValue) SaleValue,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue) RealValue,
sum((a.SaleValue-a.DiscountValue+a.ExDiscValue)/(1+a.saletaxrate/100)) NTRealValue,
sum(a.Qty*a.Cost) CostValue,sum(a.Qty*a.Cost/(1+a.saletaxrate/100)) NTCostValue,
sum(a.DiscountValue) DiscountValue,sum(a.ExDiscValue) ExDiscValue,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost) MarginValue,
sum((a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)/
(1+a.saletaxrate/100)) NTMarginValue,
case sum(a.SaleValue-a.DiscountValue+a.ExDiscValue) when 0 then 0 else
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)*100/decode(
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue),0,NULL,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue)) end MarginRate,
sum(case a.MarginRate when 100 then 0 else (a.Qty*a.Cost/
decode (1-a.MarginRate, 0, NULL, 1-a.MarginRate )/100) end) PlanSaleValue,
sum(case a.MarginRate when 100 then 0 else (a.Qty*a.Cost/decode
(1-a.MarginRate, 0, NULL, 1-a.MarginRate )/100)/
(1+a.saletaxrate/100) end) NTPlanSaleValue
from SaleCost a,Shop b,Goods c
where a.ShopID=b.ID and a.VgNo=c.VgNo and a.SDate
between '2010-01-01' and '2010-12-31' and c.ZYFlag=0
group by ShopID,ShopName,a.DeptID��
set explain off; |
ͨ���鿴�ò�ѯ����ִ�мƻ������±���ʾ�����ǿ��Կ�����QUERY: DWA executed:(OPTIMIZATION
TIMESTAMP: 11-20-2011 10:45:15)��Ҳ����ζ�Ÿò�ѯ��䱻�ض���IWA�����ٲ�ѯ��
�嵥 43. query1_iwa.sqlִ�мƻ�
informix@informixva[demo_on]:/tmp$ cat query1_iwa.out
QUERY: DWA executed:(OPTIMIZATION TIMESTAMP:
11-20-2011 10:45:15)
------
select a.ShopID,b.Name ShopName,a.DeptID,sum(a.Qty)
Qty,sum(a.SaleValue) SaleValue,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue)
RealValue,
sum((a.SaleValue-a.DiscountValue+a.ExDiscValue)/(1+a.saletaxrate/100))
NTRealValue,
sum(a.Qty*a.Cost) CostValue,sum(a.Qty*a.Cost/(1+a.saletaxrate/100))
NTCostValue,
sum(a.DiscountValue) DiscountValue,sum(a.ExDiscValue)
ExDiscValue,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)
MarginValue,
sum((a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)/
(1+a.saletaxrate/100)) NTMarginValue,
case sum(a.SaleValue-a.DiscountValue+a.ExDiscValue)
when 0 then 0 else
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)*100/decode(
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue),0,NULL,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue))
end MarginRate,
sum(case a.MarginRate when 100 then 0 else (a.Qty*a.Cost/
decode (1-a.MarginRate, 0, NULL, 1-a.MarginRate
)/100) end) PlanSaleValue,
sum(case a.MarginRate when 100 then 0 else (a.Qty*a.Cost/decode
(1-a.MarginRate, 0, NULL, 1-a.MarginRate )/100)/
(1+a.saletaxrate/100) end) NTPlanSaleValue
from SaleCost a,Shop b,Goods c
where a.ShopID=b.ID and a.VgNo=c.VgNo and a.SDate
between '2010-01-01' and '2010-12-31' and c.ZYFlag=0
group by ShopID,ShopName,a.DeptID��
Estimated Cost: 94109
Estimated # of Rows Returned: 7304
Maximum Threads: 0
ds2@IWADEMO:dwa.aqt6c910b46-edc4-440c-addc-d2202154dc42:
REMOTE PATH
Remote SQL Request:
{QUERY {FROM dwa.aqt6c910b46-edc4-440c-addc-d2202154dc42}
... ...
QUERY: IDS FYI:(OPTIMIZATION TIMESTAMP: 11-20-2011
10:45:15)
------
select a.ShopID,b.Name ShopName,a.DeptID,sum(a.Qty)
Qty,sum(a.SaleValue) SaleValue,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue)
RealValue,
sum((a.SaleValue-a.DiscountValue+a.ExDiscValue)/(1+a.saletaxrate/100))
NTRealValue,
sum(a.Qty*a.Cost) CostValue,sum(a.Qty*a.Cost/(1+a.saletaxrate/100))
NTCostValue,
sum(a.DiscountValue) DiscountValue,sum(a.ExDiscValue)
ExDiscValue,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)
MarginValue,
sum((a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)/
(1+a.saletaxrate/100)) NTMarginValue,
case sum(a.SaleValue-a.DiscountValue+a.ExDiscValue)
when 0 then 0 else
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue-a.Qty*a.Cost)*100/decode(
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue),0,NULL,
sum(a.SaleValue-a.DiscountValue+a.ExDiscValue))
end MarginRate,
sum(case a.MarginRate when 100 then 0 else (a.Qty*a.Cost/
decode (1-a.MarginRate, 0, NULL, 1-a.MarginRate
)/100) end) PlanSaleValue,
sum(case a.MarginRate when 100 then 0 else (a.Qty*a.Cost/decode
(1-a.MarginRate, 0, NULL, 1-a.MarginRate )/100)/
(1+a.saletaxrate/100) end) NTPlanSaleValue
from SaleCost a,Shop b,Goods c
where a.ShopID=b.ID and a.VgNo=c.VgNo and a.SDate
between '2010-01-01' and '2010-12-31' and c.ZYFlag=0
group by ShopID,ShopName,a.DeptID��
Estimated Cost: 94109
Estimated # of Rows Returned: 7304
Maximum Threads: 0
Temporary Files Required For: Group By
1) informix.a: SEQUENTIAL SCAN
... ...
2) informix.c: INDEX PATH
Filters: informix.c.zyflag = 0
(1) Index Name: informix. 154_493
Index Keys: vgno (Parallel, fragments: ALL)
Lower Index Filter: informix.a.vgno = informix.c.vgno
NESTED LOOP JOIN
3) informix.b: INDEX PATH
(1) Index Name: informix. 155_535
Index Keys: id (Parallel, fragments: ALL)
Lower Index Filter: informix.a.shopid = informix.b.id
NESTED LOOP JOIN |
�ܽ�
ͨ���������ܣ����ǶԼ�Ⱥ���������á�ʹ��IWA�Ļ�����������������һ���Ƚ���̵��˽⡣ͨ��ʹ��IWA���ر��Ǽ�Ⱥ�����µ�IWA�����Լ��ټӿ�����������ݼ��еIJ�ѯ����Ϊ��ҵҵ���Ż������������ṩ���õİ�����
|






