ǰ���ص������Hadoop������ϵ�ṹ�ͼ���ģ��MapReduce�����ڿ�ʼ����Hadoop�����ݹ�������Ҫ����Hadoop�ķֲ�ʽ�ļ�ϵͳHDFS���ֲ�ʽ���ݿ�HBase�����ݲֿ��Hive�����ݹ�����
1 HDFS�����ݹ���
HDFS�Ƿֲ�ʽ����Ĵ洢��ʯ��Hadoop�ֲ�ʽ�ļ�ϵͳ�������ֲ�ʽ�ļ�ϵͳ�кܶ����Ƶ����ʣ�
1.����������Ⱥ�е�һ�������ռ䣻
2.��������һ���ԡ��ʺ�һ��д���ζ�ȡ��ģ�ͣ��ͻ������ļ�û�б��ɹ�����֮ǰ���������ļ����ڵģ�
3.�ļ��ᱻ�ָ�ɶ���ļ��飬ÿ���ļ��鱻����洢�����ݽڵ��ϣ����һ���������ɸ����ļ�������֤���ݵİ�ȫ�ԡ�
��ǰ��Ľ��ܺ�ͼ���Կ�����HDFSͨ��������Ҫ�Ľ�ɫ�������ļ�ϵͳ�Ĺ�����NameNode��DataNode��Client
NameNode���Կ����Ƿֲ�ʽ�ļ�ϵͳ�еĹ����ߣ���Ҫ��������ļ�ϵͳ�������ռ䡢��Ⱥ������Ϣ�ʹ洢��ĸ��Ƶȡ�NameNode�Ὣ�ļ�ϵͳ��Metadata�洢���ڴ��У���Щ��Ϣ��Ҫ�����ļ���Ϣ��ÿһ���ļ���Ӧ���ļ������Ϣ��ÿһ���ļ�����DataNode�е���Ϣ�ȡ�DataNode���ļ��洢�Ļ�����Ԫ�������ļ��飨Block���洢�ڱ����ļ�ϵͳ�У�����������Block��Metadata��ͬʱ�����Եؽ����д��ڵ�Block��Ϣ����NameNode��Client������Ҫ��ȡ�ֲ�ʽ�ļ�ϵͳ�ļ���Ӧ�ó�������ͨ����������IJ�����˵��HDFS�����ݵĹ�����
(һ) �ļ�д��
1) Client��NameNode�����ļ�д�������
2) NameNode�����ļ���С���ļ����������������ظ�Client����������DataNode����Ϣ��
3) Client���ļ�����Ϊ���Block������DataNode�ĵ�ַ��Ϣ����˳����д��ÿһ��DataNode���С�
(��) �ļ���ȡ
1) Client��NameNode�����ȡ�ļ�������
2) NameNode�����ļ��洢��DataNode��Ϣ��
3) Client��ȡ�ļ���Ϣ��
(��) �ļ��飨Block������
1) NameNode���ֲ����ļ���Block��������С��������һҪ���DataNodeʧЧ��
2) ֪ͨDataNode�����Block��
3) DataNode��ʼֱ������ơ�
HDFS��Ϊ�ֲ�ʽ�ļ�ϵͳ�����ݹ������滹�м���ֵ�ý���Ĺ��ܣ�
1.�ļ��飨Block���ķ��ã�һ��Block�������ݱ��ݣ�һ�ݷ���NameNodeָ����DataNode�ϣ���һ�ݷ�����ָ����DataNode����ͬһ̨�����ϵ�DataNode�ϣ����һ�ݷ�����ָ����DataNode��ͬһRack�ϵ�DataNode�ϡ����ݵ�Ŀ����Ϊ�����ݰ�ȫ�������������÷�ʽ��Ҫ�ǿ���ͬһRackʧ�ܵ�������Լ���ͬRack֮������ݿ�����������������⡣
2.������⣺���������DataNode�Ľ���״���������������Ͳ�ȡ���ݱ��ݵķ�ʽ����֤���ݵİ�ȫ�ԡ�
3.���ݸ��ƣ�����ΪDataNodeʧ�ܡ���Ҫƽ��DataNode�Ĵ洢�����ʺ�ƽ��DataNode���ݽ���ѹ�����������ʹ��Hadoopʱ������HDFS��balancer��������Threshold��ƽ��ÿһ��DataNode�Ĵ��������ʡ�����������ThresholdΪ10%����ôִ��balancer�����ʱ�����Ȼ�ͳ������DataNode�Ĵ��������ʵ�ƽ��ֵ��Ȼ���ж����ijһ��DataNode�Ĵ��������ʳ��������ֵ����ô��������DataNode��blockת�Ƶ����������ʵ͵�DataNode�ϣ�������½ڵ�ļ�����˵ʮ�����á�
4.����У�飺����CRC32������У�顣��д���ļ�Block��ʱ����д���������д��У����Ϣ���ڶ�ȡ��ʱ������ҪУ����ٶ��롣
5.����NameNode�����ʧ�ܣ���������Ϣ�����¼�ڱ����ļ�ϵͳ��Զ�˵��ļ�ϵͳ�С�
6.���ݹܵ��Ե�д�룺���ͻ���Ҫд���ļ���DataNode��ʱ���ͻ������Ȼ��ȡһ��Block��Ȼ��д����һ��DataNode�ϣ������ɵ�һ��DataNode���䴫�ݵ����ݵ�DataNode�ϣ�ֱ��������Ҫд�����Block��DataNode���ɹ�д��ͻ��˲ŻῪʼд��һ��
Block��
7.��ȫģʽ���ֲ�ʽ�ļ�ϵͳ������ʱ����а�ȫģʽ��ϵͳ�����ڼ�Ҳ����ͨ��������밲ȫģʽ�������ֲ�ʽ�ļ�ϵͳ���ڰ�ȫģʽʱ���ļ�ϵͳ�е����ݲ�������Ҳ������ɾ����ֱ����ȫģʽ��������ȫģʽ��Ҫ��Ϊ����ϵͳ������ʱ�������DataNode�ϵ����ݿ����Ч�ԣ�ͬʱ���ݲ��Խ��б�Ҫ�ĸ��ƻ�ɾ���������ݿ顣��ʵ�ʲ��������У�����ϵͳ����ʱ�ĺ�ɾ���ļ�����ְ�ȫģʽ�������ĵĴ�����ʾ��ֻ��Ҫ�ȴ�һ������ɡ�
2 HBase�����ݹ���
HBase��һ������Bigtable�ķֲ�ʽ���ݿ⣬���Ĵ����Ժ�Bigtableһ������һ��ϡ��ġ����ڴ洢�ģ�����Ӳ���ϣ�����ά�ȵ�����ӳ��������ű����������йؼ��֡��йؼ��ֺ�ʱ�����ÿ��ֵ��һ�������͵��ַ����飬���ݶ����ַ�����û�����͡��û��ڱ����д洢���ݣ�ÿһ�ж���һ����������������������С�������ϡ��洢�ģ�����ͬһ�ű������ÿһ�����ݶ������н�Ȼ��ͬ���С������ֵĸ�ʽ�ǡ�<family>:<label>�����������ַ�����ɵģ�ÿһ�ű���һ��family���ϣ���������ǹ̶�����ģ��൱�ڱ��Ľṹ��ֻ��ͨ���ı���ṹ���ı����family���ϣ�����labelֵ�����ÿһ����˵���ǿ��Ըı�ġ�
HBase��ͬһ��family�е����ݴ洢��ͬһ��Ŀ¼�£���HBase��д���������еģ�ÿһ�ж���һ��ԭ��Ԫ�أ������Լ������������ݿ�ĸ��¶���һ��ʱ�����ǣ�ÿ�θ��¶�������һ���µİ汾����HBase�ᱣ��һ�������İ汾�����ֵ�ǿ����趨�ġ��ͻ��˿���ѡ���ȡ����ij��ʱ�������İ汾������һ�λ�ȡ���а汾��
���ϴ����Ͻ�����HBase��һЩ���ݹ�����ʩ����ôHBase��Ϊ�ֲ�ʽ���ݿ��������ϴӼ�Ⱥ����������ι������ݵ��أ�
HBase�ڷֲ�ʽ��Ⱥ����Ҫ������HRegion��HMaster��HClient��ɵ���ϵ�ṹ�������Ϲ������ݡ�
HBase��ϵ�ṹ��������Ҫ��ɲ����ǣ�
1.HBaseMaster��HBase������������Bigtable�������������ơ�
2.HRegionServer��HBase�����������Bigtable��Tablet���������ơ�
3.HBaseClient��HBase�ͻ�������org.apache.hadoop.HBase.client.HTable����ġ�
���潫�����������������ϸ�Ľ��ܡ�
(һ) HBaseMaster
һ��HBaseֻ����һ̨������������ͨ���쵼ѡ���㷨��Leader Election
Algorithm��ȷ��ֻ��Ψһ�����������ǻ�Ծ�ģ�ZooKeeper�������������ķ�������ַ��Ϣ�������������̱��������ͨ���쵼ѡ���㷨�ӱ��÷�������ѡ���µ�����������
����������ʼ����Ⱥ��������������һ������ʱ������ͼ��HDFS��ȡ�������Ŀ¼������ȡʧ�����������Ŀ¼���Լ���һ��Ԫ��Ŀ¼���´�����ʱ�����������Ϳ��Ի�ȡ��Ⱥ�ͼ�Ⱥ�����������Ϣ�ˡ�
��������������ķ��乤�������ȣ������������������洢ָ������������������ַ��ָ�롣��Σ������������������ѯԪ������Ԫ����������С�ÿ��Ԫ���а��������е��û����û����д洢�˶���û�����������е�Ԫ�������ϣ�����������������û�����Ӧ������������Ա������������ĸ���ƽ�⡣
��������ʱ�̼������������������״̬��һ������������ijһ����������ɴ�ʱ�������������������ϵ�ÿ�����Ԥд��־��write-ahead
log���ļ���֮�����������Ὣ�����·��䵽������������ϣ�������֮�����������������һ������������������У����ȡ����رո����������һЩ������Щ����䵽�������ص���������ϡ�
�����������������Ĺ��������磬�������������/����״̬�ı�����ģʽ�����ӻ�ɾ�����壩�ȡ����⣬�ͻ��˻�����������ֱ�Ӵ���������϶�ȡ���ݡ�
��Bigtable�У�������������������������ӶϿ�ʱ�����������Ȼ���Լ���������ΪBigtable�ṩ��һ�ֶ�������������ƣ����ֻ����е�����������Chubby����֤�������������Ŀ����ԡ�����HBase�У�����û���ṩ���������ƣ���������������ʱ��������Ⱥϵͳ��Ҫ������������Ϊ����������������������Ĺ������ġ�
�������Ԫ�������ĸ��
Ԫ����Meta Table�������������û���Ļ�����Ϣ������Ϣ������ʼ�ؼ��֡������ؼ��֡����Ƿ����ߡ������ڵ����������ַ�ȡ�Ԫ���������û����������������
������Root Table��������Ϊ�洢��һ�����Ϣ����ָ��Ԫ���е���������Ԫ��һ��������Ҳ����ÿ��Ԫ�����Ϣ��Ԫ�����ڵ����������ַ��
������Ԫ���е�ÿ�д�ԼΪ1KB����Ĭ�ϴ�СΪ256MB���������ӳ��2.6��105��Ԫ��ͬ����Ԫ�����ӳ����Ӧ�������û�����ˣ��������ӳ��6.9��1010���û���Լ���Դ洢1.9��1019�ֽڵ����ݡ�
(��) HRegionServer
HBase���������Ҫ�з�����������������������ͻ��˵Ķ�д����������д��ѹ���ͷָ���ȹ��ܡ�
ÿ����ֻ����һ̨�����������������ʼ������ij��ʱ�������HDFS�ļ�ϵͳ�ж�ȡ�������־�����д洢�ļ���ͬʱ�������������HDFS�ļ��ij־��Դ洢������
�ͻ���ͨ������������ͨ�Ż�ȡ�������������������б���Ϣ�Ϳ���ֱ������������������д�����ˡ���������յ�д����ʱ�����Ƚ�д������Ϣд��һ��Ԥд��־�ļ��У����ļ�ȡ��ΪHLog��ͬһ���������д������¼��ͬһ��HLog�ļ��С�һ��д����¼��HLog��֮�������������ڴ洢��������MemCache���С�ÿ��HStore��Ӧһ���洢�����������ڶ��������������Ҫ������������ڴ洢���������Ƿ����У����û�����У����������ȥ������ص�ӳ���ļ���
���洢�������Ĵ�С�ﵽһ����ֵ����Ҫ���洢�������е����ݻ�д�������ϣ��γ�ӳ���ļ�������HLog��־�ļ��б�ǡ���˵��ٴ�ִ��ʱ��������Ծ�����һ�λ�д֮ǰ�IJ����ϡ���дҲ��������������洢��ѹ������������
��ӳ���ļ��������ﵽһ����ֵʱ����������Ὣ�����д���ӳ���ļ�������ȵĺϲ�ѹ�������⣬����������������Եض����е�ӳ���ļ�����ѹ����ʹ���Ϊ��һ��ӳ���ļ���֮���������Ե�ѹ�����е�ӳ���ļ�������Ϊ�����ӳ���ļ�ͨ�����Ƚϴ������ӳ���ļ���ҪС�ܶ࣬ѹ��Ҫ���ĺܶ��ʱ�䣬�������ĵ�ʱ����Ҫȡ���ڶ�ȡ���ϲ���д�����ӳ���ļ�����Ҫ��I/O����������ѹ���ʹ�����д������ͬʱ���еġ���һ���µ�ӳ���ļ�����֮ǰ����д������������ֱ��ӳ���ļ�������HStore�Ļ�Ծӳ���ļ��б��У����Ѻϲ��ľ�ӳ���ļ���ɾ���Ż��ͷŶ�д������
��HStore��ӳ���ļ��Ĵ�С�ﵽһ������ֵʱ��ĿǰĬ�ϵ���ֵΪ256MB�������������Ҫ������зָ��ˡ�����Ϊ�������ָ����ִ���ٶȺܿ죬��Ϊ������ֱ�ӴӸ����ж�ȡ���ݵġ�֮����������״̬�����������Ԫ���м�¼�µ�����֪ͨ�����������Խ���������������������������ָ���Ϣ�����紫���ж�ʧ����������������������ɨ��Ԫ����δ�����������Ϣʱ���ַָ������һ�����رգ����жԸ���Ķ�д�����������𡣿ͻ������̽����ķָ���Ϣ�����µ���������ʱ���ͻ����ٷ�����д��������ѹ������ʱ����������ݽ����Ƶ������С������������������ѹ������ʱ�����ա�
(��) HBaseClient
HBase�ͻ��˸�������û������ڵ����������ַ��HBase�ͻ��˻���HBase����������Ϣ�Բ��Ҹ����λ�ã���������֮��Ψһ�Ľ�����
��λ����ͻ������Ӹ������ڵ������������ɨ������ȡԪ����Ϣ��Ԫ����������û�������������ַ���ͻ���������Ԫ�����ڵ����������ɨ��Ԫ������ȡ�����û������ڵ����������ַ����λ�û���ͻ��������û������ڵ����������������д�����û���ĵ�ַ���ڿͻ����б����棬���������������ظ��������̡�
������������������Ϊ�˸��ؾ�������·���������������������ͻ��˶�������ɨ��Ԫ������λ�µ��û����ַ�����Ԫ�����·��䣬�ͻ��˽�ɨ���������λ�µ�Ԫ���ַ���������Ҳ�����·��䣬�ͻ��˽�������������λ�µĸ����ַ����ͨ���ظ�������������λ�û����ַ��
������������HBase����ϵ�ṹ�У�HBase��Ҫ��������������������Ϳͻ�����������ɡ�����������ΪHBase�����ģ�������������Ⱥ�е��������ÿ�������������������ȣ���������������Է������ķ��������ͻ��˵����д����дӳ���ļ��ȣ��ͻ�����Ҫ���������û������ڵ����������ַ��Ϣ��
3 Hive�����ݹ���
Hive�ǽ����� Hadoop �ϵ����ݲֿ�������ܡ����ṩ��һϵ�еĹ��ߣ���������������ȡ��ת�������أ�����һ�ֿ��Դ洢����ѯ�ͷ����洢��
Hadoop �еĴ��ģ���ݵĻ��ơ�Hive�����˼��� SQL ��ѯ���ԣ���Ϊ QL����������Ϥ SQL
���û���ѯ���ݡ���Ϊһ�����ݲֿ⣬Hive�����ݹ�������ʹ�ò�ο��Դ�Ԫ���ݴ洢�����ݴ洢�����ݽ����������������ܡ�
(һ) Ԫ���ݴ洢
Hive ��Ԫ���ݴ洢��RDBMS �У�������ģʽ�������ӵ����ݿ⣺
Single User Mode����ģʽ���ӵ�һ�� In-memory
�����ݿ� Derby��һ������ Unit Test��
Multi User Mode��ͨ���������ӵ�һ�����ݿ��У�������õ�ģʽ��
Remote Server Mode�����ڷ� Java �ͻ��˷���Ԫ���ݿ⣬�ڷ�����������һ��
MetaStoreServer���ͻ��������� Thrift Э��ͨ��MetaStoreServer������Ԫ���ݿ⡣
(��) ���ݴ洢
���ȣ�Hive û��ר�ŵ����ݴ洢��ʽ��Ҳû��Ϊ���ݽ����������û����Էdz����ɵ���֯
Hive �еı���ֻ��Ҫ�ڴ�������ʱ����� Hive �����е��зָ������зָ��������Ϳ��Խ��������ˡ�
��Σ�Hive �����е����ݶ��洢�� HDFS �У�Hive �а���4������ģ�ͣ�Table��External
Table��Partition��Bucket��
Hive �е� Table �����ݿ��е� Table �ڸ����������Ƶģ�ÿһ��Table
�� Hive �ж���һ����Ӧ��Ŀ¼���洢���ݡ����磬һ���� pvs������ HDFS �е�·��Ϊ��/wh/pvs�����У�wh
���� hive-site.xml ���� ${hive.metastore.warehouse.dir}
ָ�������ݲֿ��Ŀ¼�����е� Table ���ݣ�������External Table�������������Ŀ¼�С�
Partition ��Ӧ�����ݿ���Partition �е��ܼ�����������
Hive �� Partition ����֯��ʽ�����ݿ��еĺܲ���ͬ���� Hive �У����е�һ�� Partition
��Ӧ�ڱ��µ�һ��Ŀ¼�����е�Partition ���ݶ��洢�ڶ�Ӧ��Ŀ¼�С����磺pvs ���а��� ds
�� city ���� Partition�����Ӧ�� ds = 20090801, city = US ��
HDFS ��Ŀ¼Ϊ:/wh/pvs/ds=20090801/city=US����Ӧ�� ds = 20090801,
city = CA �� HDFS ��Ŀ¼Ϊ:/wh/pvs/ds=20090801/city=CA��
Buckets ��ָ���м��� hash������ hash ֵ�з����ݣ�Ŀ����Ϊ�˱��ڲ��У�ÿһ��
Buckets��Ӧһ���ļ�����user �з�ɢ�� 32 ��Bucket�ϣ����ȶ� user �е�ֵ����
hash�����磬��Ӧ hash ֵΪ 0 �� HDFS Ŀ¼Ϊ��/wh/pvs/ds=20090801/city=US/part-00000����Ӧhash
ֵΪ 20 �� HDFS Ŀ¼Ϊ��/wh/pvs/ds=20090801/city=US/part-00020��
External Table ָ���Ѿ��� HDFS �д��ڵ����ݣ����Դ���
Partition������ Table ��Ԫ���ݵ���֯�ṹ������ͬ�ģ�����ʵ�����ݵĴ洢�����нϴ�IJ��졣
��Table �Ĵ������̺����ݼ��ع��̣����������̿�����ͬһ���������ɣ��У�ʵ�����ݻᱻ�ƶ������ݲֿ�Ŀ¼�С�֮������ݵķ��ʽ���ֱ�������ݲֿ��Ŀ¼����ɡ�ɾ����ʱ�����е����ݺ�Ԫ���ݽ��ᱻͬʱɾ����
External Table ֻ��һ�����̣���Ϊ�������ݺʹ�������ͬʱ��ɵġ�ʵ�������Ǵ洢��
Location ����ָ���� HDFS ·���еģ����������ƶ������ݲֿ�Ŀ¼�С�
(��) ���ݽ���
���ݽ�����Ҫ��Ϊ���¼������֣���ͼ��ʾ����
1.�û��ӿڣ������ͻ��ˡ�Web��������ݿ�ӿڡ�
2.Ԫ���ݴ洢��ͨ���Ǵ洢�ڹ�ϵ���ݿ��еģ���MySQL��Derby�ȡ�
3.�����������������Ż�����ִ������
4.Hadoop���� HDFS���д洢������ MapReduce ���м��㡣
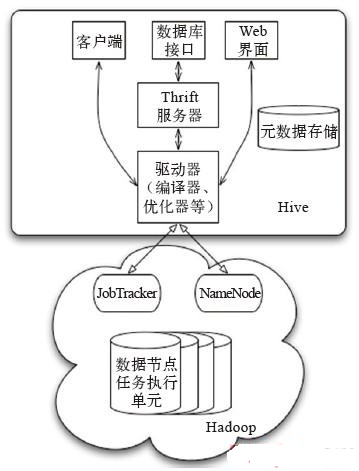
�û��ӿ���Ҫ���������ͻ��ˡ����ݿ�ӿں�Web���棬������õ��ǿͻ��ˡ�Client
�� Hive �Ŀͻ��ˣ������� Client ģʽʱ���û�����Ҫ����Hive Server����ʱ��Ҫָ��
Hive Server ���ڵĽڵ㣬�����ڸýڵ�����Hive Server��Web������ͨ�����������Hive�ġ�
Hive ��Ԫ���ݴ洢�����ݿ��У���MySQL��Derby�С�Hive
�е�Ԫ���ݰ����������֡������кͷ����������ԡ��������ԣ��Ƿ�Ϊ�ⲿ���ȣ������������ڵ�Ŀ¼�ȡ�
�����������������Ż������ HQL ��ѯ���Ӵʷ�����������������롢�Ż�����ѯ�ƻ������ɡ����ɵIJ�ѯ�ƻ��洢��
HDFS �У����������MapReduce����ִ�С�
Hive �����ݴ洢�� HDFS �У��ֵIJ�ѯ�� MapReduce
��ɣ����� * �IJ�ѯ�������� MapRedcue ������select * from tbl����
���ϴ�Hadoop�ķֲ�ʽ�ļ�ϵͳHDFS���ֲ�ʽ���ݿ�HBase�����ݲֿ��Hive���ֽ�����Hadoop�����ݹ��������Ƕ�ͨ���Լ������ݶ��塢��ϵ�ṹʵ�������ݴӺ�۵��۵����廯�����������Hadoopƽ̨�ϴ��ģ�����ݴ洢����������
|


