�����������һ���ĵ��ϣ������㲻���ܲ�֪�������ݲֿ�/����/��������(
BI )�������ڷ��ٷ�չ��������ǰ������ҵ����ʦȺ�����CIO�����ȿ��ǵ���ʱ��BI�ŵ�ʮλ ��Ȼ��������2006��Ծ�����˵ڶ�λ�����죬����Gartner
Group�����Ѿ�Ծ�ӵ�һλ�ˡ���û��ʲô���ص�ԭ���ڼ��ҵľ��þ�����������ҵ��������ҵ��Ҫ�������ڲ���������������Ҫ����ҵ���ߣ�����ս����ս�������棬�Ա�����ҵ�����ȵ�λ��
���и����⣺�ڹ�˾�齨��Ҫ��BI���Ž�Ҫ���Ѻܴ�һ���ʽ𡣺ܶ����ݲֿ��BI���̽Ϻõ�ʵ�����AMEX��̬�ȣ��Բ���IT�����������һЩ����;��ʵ�ϣ�2007����Ϣ�ܿ����鷢�֣�
39 %��IT������Թ˵���������ɷ����谭������Ҫ�ƹ�BI�ij��顣
���ǽ��뿪Դ!�������������Դ���Ѿ�����������������������Ϊ�κι�˾�����з�����ϵͳ���������ߣ��Լ����ݿ⣬�Ⱦ��о�������IT�������˷���֮�ţ���ô����ͬ��������Ҳ�����������ݲֿ����������(BI)����Ŀ����ʵ�����ݲֿ�(���MySQL��һ���ش����Ϳͻ�����)Ŀǰ��MySQL�ĵ����������Ӧ�á�
���������һ��ͳ�Ƴƣ�����TDWI �����ݲֿ�ÿ���ƽ�������ٶȵĽ���33��50 %֮�䣬Ȼ����һ���ݶ�һЩ��ҵ��˵������ԱȽϱ��صġ���������MySQL���ݲֿ������еĴ洢������MyISAM
(�ڶ�����InnoDB��) �������ݴﵽ1TB����������������Ȼ����Խ���ڴ�֮�������û����������ݲֿ�ֲ��ڶ������������������ܡ����ڣ��ӷ�����˾IDCͳ����������������������ݲֿ���6TB��(��IDC��ֻ��4
%����25TB)���������ζ�Ŵ�����˳��춼ֻ�ڹ�������GB��6TB֮������ݲֿ⡣
������㣬������ϣ����һ������MySQL�Ľ����������ô��Ӧ��Ϊ����ȥ����һ��Infobright�洢���档
Infobright��MySQL / Sun��˾�ĺ������֮һ����Ӧ��������ͻ��MyISAM�������洢�������ƣ����ṩ��һ���dz���˵ļ���(���˳Ծ�...
)�������а�װ�����ú����ݿ�����Ի���������ŵĿ��ٵķ�Ӧʱ��ʱ���㲢����Ҫ���صĹ�����
����������������Infobright�ܹ�������������������Щ���飬Ȼ��������в������˽�������θ��õ�ִ�н���ʽ��ѯ��
�зdz���
������˵�� Infobright�洢������һ���е���ļܹ�����ϸ�������װ�ػ����߶ȵ�����ѹ����һ�����ģ��ⲿ�Ż����Լ�"֪ʶ����"
���ṩ����ӡ����̵����ݲֿ�ܡ���MySQL�ĽǶ������� Infobright���������κδ洢���棬��˴ӽ���ĽǶ�����û��ʲô�µĶ���Ҫ���⡣
Infobright��һ�������İ�װ��Ȼ����������MySQL��������������װ�ܼ�(�ҷ���ʵ���ٶȳ���һ����MySQL�İ�װ)
���Լ�����Ҳֻ��17MB������һ���dz��˲�������棬���Թ���10�����ֽڵ����ݡ�
����Ҫ˵�����ǣ� Infobright������һ�е������ơ��е�������ݿ�Ĵ����Ѿ���һ��ʱ��(��Sybase��˾��IQ
) �������ڲŸ�����ǿ�ҵ�ӡ�鹦�����ܺܺõ��������ݲֿ������2008��3��Infobright�о����桰What��s
Cool About Columns���������ջ�����д���� ���ڹ�ȥʮ�꣬���ڴ�ʹ���е���������Ƿdz������ġ�����...�������ţ����������߳���Ӱ����Ϊ���ݲֿ����ص��г���Ҫ������ʱ�������Ų���˵��
�����Խϵ͵ijɱ���С�ķ�װ�ṩ���õ����ܣ����������⣬Ϊʲô�κι�˾���Բ�ѯ���ܸ���Ȥ�����Ӳ����ǻ����еĽ��������
ΪʲôҪ������������?������Infobright�����е������ƣ������ݲֿ������İ������������ơ������������������ԭ�������������������������������ݲֿ�/������ѯ��ֻ����һ���������е����У����������е��С�����������£�Ϊ���ݲֿ�Ŀ�ģ������Ե��͵��и�ʽ�洢��û��Ч�ʣ�����Ӧ�ò�ȡ�е���ĸ�ʽ�洢������Infobright�����е�����Ƶ����ݿ��У�ȫ��ɨ�轫��Զ���ᱻִ��(���Dz�ѯ����һ������ȫ�������)
; ����ֻ�����ȫ��ɨ�衣���յĽ���Ǹ���I / O������������е������ݿ����Ӧʱ�䡣
Infobright�����е������Ʋ�����κ��˶�ϲ����������ƣ���ǿ�ȵ�����ѹ������Ϊ�����е���Infobrightѹ�����ݣ�����ÿһ������������ͨ���DZȱ����е����ѹ������Ч�ʣ���Ϊѹ���㷨�ɱ�ÿһ���������;��������������е����ѹ���У�������2��3��1��ѹ��;������Infobright
��10��1ѹ�����������(��ijЩ����»�ߵö�) ������1TB�����ݿ���Ա�ѹ����100GB ����Sun������һЩ��Ա�Ŀ����������ܣ����Ƕ�Inforbrightѹ�����ݵ������ܳԾ����������ܱ���������ʹ�ù����κ����ݿ�(�е�����е���)��Ҫǿ����Ȼ������ѹ���Ľ���ǣ�����������������ܣ�ͬʱҲ�����ڽ������ݲ־ݵĴ洢�ɱ����⽫�ܵ�����IT������������
Infobright��������������
��Ȼ������ͨ�����б�·�������ݵ�MySQL Infobright���� Infobright���ṩ��һ������ĸ���װ�ػ������ڼ������ݵ�һ�����ݿ�ʱ��������ȫ��һ�����㷨���ü����㷨�Ƕ��̣߳�ʹÿ�����ܲ������롣����Infobright��ҵ�棬��������100GB������ͨ����Ҫһ��Сʱ�����������һ��Сʱ����ʵ��300GB���ҵĶ������������룬�ⲻ��̫���ᡣInfobright�������ѽ��������ٶȣ���Ϊ��ֻ�ܴ�����������(�����Ƕ�����)
��������Ȼ���Կ�һ��Сʱ����40GB�������ݵ��ٶȡ�
���ǣ�Ҳ����Infobright�ܹ���Ҫ����ͻ���ļ��������ġ�֪ʶ������Ӧ���Ż����� Infobright�����ݼ��ص����ݿ���(���۳�ʼ�������)ʱ��Ϳ�ʼ����֪ʶ����֪ʶ�������������ݿ������ݺ�����ͳ�Ƶ�һ��ͳ������������ؼ�Ҫ��ס֪ʶ�����������������������ζ������Զ����Ҫ��Infobright���д������������ô�������������һ������!
Infobright֪ʶ����û������ά����ȱ�㣬������֪��������ݿ������µ���Ӧʱ������ʱ������ƶ����ӵ�ԭ������Ϊ�Ծݿ�Խ��Խ����IJ�������һ���ŵ�Infobright�����dz�����Ԥ��IJ�ѯ����ʱ�����÷dz��ã��������������ݲֿ���Ҫ�����ġ����ֲ�ѯ�����ݿ����Ա�Ķ��Σ���Ϊ���Dz������һ����Ч��������ָ���ԣ�������ݿ����ܴ���û�е����������Infobright
���֣�������Щ���ⶼӭ�ж��⣬��Ϊ�����Զ������Щ������
Infobright��ʵ�������ǰ����д洢�ġ���Щ�б���Ϊ64K�Ĵ�С���������ݰ�����Ԫ���ݴ洢��֪ʶ����һ����ѯ�ύ��Infobrightִ��ʱ���Ż�����ѯ֪ʶ�����Ա����һ�����Ե��뷨����Щ���ݰ�������ѯ�������������ݡ������������������(
a )����Խ��ٵ����ݰ��а��������������;( b )�Ż������ܹ�ȷ��ȷ��һϵ����������ݰ�����ѯ�ٶȽ��쳣���١�
�������ݷֲ������������Զ����ݷָ�ٴΣ�����һ�����¡�����Infobright ���֣��õ�������Խ�����ݲֿ⣬�㲻����һ�����ݲֿ�����ר�ң���Ϊ������Ϊ�������������ѵĹ���-û��������ָ�ս�ԣ�����ǰ�����㹤����һ���֡�
��ijЩ����£���ѯ��������Ҫ�κ����ݰ��Ϳ���ִ��;ֻҪ��ѯ��֪ʶ�����������IJ�ѯ������ִ�С�����֪ʶ�������������ۺ���Ϣ����Ϊ�����ݲֿ��Ӧ���У��ۺ������в�ѯһ����ͬ�ĵ㣬���������ݲֿ����͵IJ�ѯִ����˵�����ٻ����û����Щ��Ҫ�����Dz�Ѱ����(���Ӻ�������)
��
Infobright�����Ӧ�ÿ��������ġ�����ʵ�ʱ��͵�ά�ȱ�������ģʽ(����������������Ʋ���Ҫ)���������ݿ��б�����ƻ������ǷǸ�ʽ���ġ��ڰ����߶ȱ����ܹ���Ӧ�ú����������ݵķֲ���ʹ������£�Infobright������ִ�С�������Ϊ��Щ���ݲ��������ݼ��е�ģʽѹ�����������ݵIJ�ѯ������鲼���ݿ⣬��˴��������ݰ���Ҫ��ɨ�衣
��˶������-���ڣ�������ͨ��һЩ�������ݲֿ��ʹ�ð���������ϰʹ��Infobright���棬����������������Ρ��������еIJ��Խ��ڴ���PowerEdge
6850�Ͻ��У�����4��Intel Xeon˫�˴�����(3.4GHz)�� 32GB���ڴ棬��5��RAID
10 ��ʽ��300GB���ڲ�Ӳ�̣�������64λ�ĺ�ñLinux 5��ҵ���Infobright��ҵ���ϡ�
Kicking the Tires
ʹ��Infobright������ʱ���������κ�����MySQL�����Ǵ�����ͬ��-������Ҫ���ľ���ָ�����������Ϊbrighthouse�����磺
mysql> create table t (c1 int) engine=brighthouse;
����Query OK, 0 rows affected (0.02 sec)
����mysql> insert into t values (1), (2), (3);
����Query OK, 3 rows affected (0.16 sec)
����Records: 3 Duplicates: 0 Warnings: 0
����mysql> select * from t;
����+------+
����| c1 |
����+------+
����| 1 |
����| 2 |
����| 3 |
����+------+
����3 rows in set (0.00 sec) |
���ԣ����ڽ���ʵ�ʲ��ԣ������������ѯ��ģ����һ���������ݲֿ�����ģ��(���������������ݿ�)
��������������ģ��������
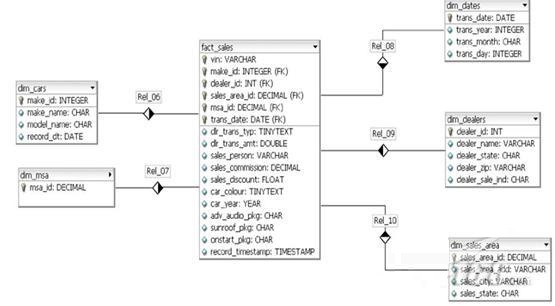
�������������ݿ�������ģ(�����INFORMATION_SCHEMA��Ϣ)���£�
&+----------------------------+-------------+------------+--------------+
����| table_name | engine | table_rows | data_length |
����+----------------------------+-------------+------------+--------------+
����| fact_sales5 | BRIGHTHOUSE | 8080000000 | 135581094511 |
����| fact_sales | BRIGHTHOUSE | 1000000000 | 16789624027 |
����| fact_sales1b | BRIGHTHOUSE | 1000000000 | 17424704919 |
����| mthly_sales_by_dealer_make | BRIGHTHOUSE | 4207788 | 43958330 |
����| dim_vins | BRIGHTHOUSE | 2800013 | 15251819 |
����| dim_sales_area | BRIGHTHOUSE | 32765 | 302326 |
����| dim_dates | BRIGHTHOUSE | 4017 | 9511 |
����| dim_dealers | BRIGHTHOUSE | 1000 | 9631 |
����| dim_dealers2 | BRIGHTHOUSE | 1000 | 10222 |
����| dim_cars | BRIGHTHOUSE | 400 | 4672 |
����| dim_msa | BRIGHTHOUSE | 371 | 3527 |
����| tt | BRIGHTHOUSE | 1 | 193 |
����+----------------------------+-------------+------------+--------------+
����12 rows in set (0.00 sec)
����+------------------+
����| sum(data_length) |
����+------------------+
����| 169854973688 |
����+------------------+
����1 row in set (0.01 sec)
|
���������˼����൱���ʵ����ÿ������10���У�һ���������ʷʵ������80���У�һ�����ͻ��ܱ�(
400����) ���Լ�һ��������ά���������С���൱С��(��280����dim_vins��) �����ݿ����������С������170GB
����ʵ��ԭʼ���ݵĴ�С��1TB����������Կ�����Infobrightѹ�������У���������������ŵ�ġ�
���һЩ����֤���������ݣ�
mysql> select count(*) from fact_sales5;
����+------------+
����| count(*) |
����+------------+
����| 8080000000 |
����+------------+
����1 row in set (0.00 sec)
����mysql> select count(*) from fact_sales;
����+------------+
����| count(*) |
����+------------+
����| 1000000000 |
����+------------+
����1 row in set (0.00 sec)
|
��ע�⣬ Infobright��Ӧʱ�����MyISAMȫ����COUNT(*)��ѯ��ʱ��;֪ʶ����֪��ÿ�����ж����У�����㲻���˷�ʱ��ȴ����ֲ�ѯ�Ĵ�
���ڣ������ǽ��м���������ѯ���������ǻ��ʲô�����ȣ���������һ������������������һ���ض���ʱ�����ܹ����۶���������
mysql> select sum(dlr_trans_amt)
����-> from fact_sales a, dim_cars b
����-> where a.make_id = b.make_id and
����-> b.make_name = "ACURA" and
����-> b.model_name = "MDX" and
����-> trans_date between "2007-01-01" and "2007-01-31";
����+--------------------+
����| sum(dlr_trans_amt) |
����+--------------------+
����| 11264027726 |
����+--------------------+
����1 row in set (24.98 sec)
|
Not too bad at all. But now let��s put
the knowledge grid / data packs to the test and see
how big a dent in our response time we get by adding
eight times more data to the mix:
�����̫��⡣���ǣ����������ǰ�֪ʶ����/���ݰ����в��ԣ�����ͨ�����Ӱ˱����ϵ�������ϣ�Ȼ�����ǵ���Ӧʱ���ܵ����Ӱ�졣
mysql> select sum(dlr_trans_amt)
����-> from fact_sales5 a, dim_cars b
����-> where a.make_id = b.make_id and
����-> b.make_name = "ACURA" and
����-> b.model_name = "MDX" and
����-> trans_date between "2007-01-01" and "2007-01-31";
����+--------------------+
����| sum(dlr_trans_amt) |
����+--------------------+
����| 11264027726 |
����+--------------------+
����1 row in set (27.20 sec)
|
�dz���! Infobright��-�ٴ�-ֻ�����������ݰ������ų������������ݣ���Щ��������Ҫ�������������ǵIJ�ѯ�����������Ӧʱ�䲢û������ʵ�ʵ�Ӱ��(������ͬ�IJ�ѯ��ʵ�����ñȵ�һ�β�ѯ��С�ı�)
��
���ڣ������Dz��ԣ���ijЩ�������ʹ��ͨMySQL������̱���IJ�ѯ�� -Ƕ���Ӳ�ѯ��
mysql> select avg(dlr_trans_amt)
����-> from fact_sales
����-> where trans_date between "2007-01-01" and "2007-12-31" and
����-> dlr_trans_type = "SALE" and make_id =
����-> (select make_id
����-> from dim_cars
����-> where make_name = "ASTON MARTIN" and
����-> model_name = "DB7") and
����-> sales_area_id in
����-> (select sales_area_id
����-> from dim_sales_area
����-> where sales_state =
����-> (select dealer_state
����-> from dim_dealers
����-> where dealer_name like "BHUTANI%"));
����+--------------------+
����| avg(dlr_trans_amt) |
����+--------------------+
����| 45531.444471505 |
����+--------------------+
����1 row in set (50.78 sec)
|
Infobright plows through the data just
fine. What about UNION statements �C oftentimes these
can cause response issues with MySQL. Let��s try both
fact tables this time:
Infobright���������Ƿdz��ĺá�������������-��Щ���������������MySQL��Ӧ��ͻ����ô����������dz�������ʵ�ʱ���
mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
����-> from fact_sales
����-> where trans_date between "2007-01-01" and "2007-01-31")
����-> union all
����-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
����-> from fact_sales
����-> where trans_date between "2007-02-01" and "2007-02-28");
����+--------------------+-----------------------+---------------------+
����| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
����+--------------------+-----------------------+---------------------+
����| 45550.1568209903 | 5.39966 | 349.50289769532 |
����| 45549.5774942714 | 5.39976 | 349.498835301098 |
����+--------------------+-----------------------+---------------------+
����2 rows in set (0.49 sec)
����mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
����-> from fact_sales5
����-> where trans_date between "2007-01-01" and "2007-01-31")
����-> union all
����-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
����-> from fact_sales5
����-> where trans_date between "2007-02-01" and "2007-02-28");
����+--------------------+-----------------------+---------------------+
����| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
����+--------------------+-----------------------+---------------------+
����| 45550.1568209903 | 5.39966 | 349.50289769532 |
����| 45549.5774942714 | 5.39976 | 349.498835301098 |
����+--------------------+-----------------------+---------------------+
����2 rows in set (0.75 sec)
����It appears the UNION��s were satisfied via knowledge grid access alone. Next,
let��s try a few joins coupled with a having clause and ask for the average
Ashton Martin dealer transaction amounts over one year for dealers in the state of Indiana:
��������˫���Խ�ͨ��֪ʶ�����������Ľ�����Ƚ����⡣
�������������dz���һЩ�й�����ļ��ˣ�
����ѯ��ʲ�����������̹�ȥһ���ӡ�ڰ����ݽ����̵�ƽ��������
����mysql> select fact.dealer_id,
����-> avg(fact.dlr_trans_amt)
����-> from fact_sales fact
����-> inner join dim_cars cars on (fact.make_id = cars.make_id)
����-> inner join dim_sales_area sales on
����-> (fact.sales_area_id = sales.sales_area_id)
����-> where fact.trans_date between "2007-01-01" and "2007-12-31" and
����-> fact.dlr_trans_type = "SALE" and
����-> cars.make_name = "ASTON MARTIN" and
����-> cars.model_name = "DB7" and
����-> sales.sales_state = "IN"
����-> group by fact.dealer_id
����-> having avg(fact.dlr_trans_amt) > 50000
����-> order by fact.dealer_id desc;
����.
����.
����.
����| 2 | 51739.181818182 |
����| 1 | 57964.8 |
����+-----------+-------------------------+
����317 rows in set (50.66 sec)
|
��Ȼ���������������IJ�ѯ���ɱ����ԣ�������������Infobright���ִ��һЩ���͵Ľ���ʽ��ѯ�ĸ��ܡ��ٴΣ�һ��ΰ����������㲻�ػ�ʱ������������ƶ��ָ�ƻ����Ի������չʾ�����ܽ������Ϊ������Щ��Infobright������ȫû�б�Ҫ�ġ���ʵ�ϣ�����ֻ���������ҵ����������������Ƕ����ڴ���ء�
Infobright�ľ�����
�˿̣�Infobright��ijЩ���������֪�����������еIJ�ѯ����ͨ��Infobright�Ż��������Ż�;��Щ�������ձ����͵�MySQL�Ż�������������������������IJ�ѯִ�к�����յ����棬ָ�����������鷢����
1.���ڣ�Infobright�ɴ������8-10�����û������ڼ��������İ汾�мƻ�������30�����ҡ�
2.��ѯĿǰ��������һ��CPU /���ġ�
3.֧������Ӳ�ѯ����ͨ��������Ч�����С�
4.DML(���룬���£�ɾ��;����������ҵ��)ֻ֧�ֱ������������Լ��ٲ����ԣ����DML������һ��Infobright�ֿ⡣
5.��������˵��һ��Infobright������������147�����У���ʵ���ϣ�500�������ڵ�����-��������������������еĹ�ģ��ʹ�õ���������(�������ƿ��ܻ��ȡ�����й�ģ)
6.���ڣ�ȱ������֧�֣��ƻ�2009���ϰ�����UTF8֧�֡�
7.���ڣ�û�õ�Windows��Solaris֧��;Ԥ�Ƶ�2009�����á�
8.û��ALTER TABLE�йص�֧�֡������ܴ�������ת����Infobright
����֮��Ȼ��
9.֪ʶ������������Infobright������ˣ������IJ�ѯ��һ����ϴ洢���棬�漰Infobright������ô������ܽ�����ۿۡ�
��������ѯ�������һ�����һ��С��������10���еı�ȡ����80���еı���ʱ�������ѯ���ܴ���½�����Ȼ������֪�������㷨�������漰��Դ���ݣ�����ֻ�ڴ���д��ڡ�
Infobright������ͼ���������⡣
��Ŀǰ���ԣ��ڲ���ϵͳ��Ӳ����֧���£� Infobright�洢����������32λ(������)��64λ(���������ҵ��)Ӣ�ض���AMD�������Լ���ñLinux��ҵ�棬
CentOS �� Fedora(������)��Debian�Լ�������ƷӲ��������������Ҫ��BI����( Business
Objects���� Cognos�� Pentaho ��JasperSoft��) ����֧��MySQL��Infobright����ϡ�
����
�������ܸ߿Ƽ�����ҵ����ᵽ���ݲֿ��BI֧�ֵľ��Ա����ԣ��⽫��һ��ΰ���ʱ��������MySQL
- Infobright�Ľ����������������www.infobright.org���ز������������Infobright�洢���档���⣬
MySQL�����ݲֿ���������̳�ǣ�http://forums.mysql.com/list.php?32����MySQL��Infobright��վ(
Infobright��˾����վ��www.infobright.org)�и�������ϺͰ�Ƥ��(�����Ƽ�����������)��
���ԣ��볢��Infobright����������֪������뷨��������һ������л���MySQL��Sun��˾��֧�֡�
|


