| БрМЭЦМі: |
БОЮФжївЊЯъЯИНщЩм Nebula GraphЕФЪ§ОнФЃаЭКЭЯЕЭГМмЙЙЩшМЦ ЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкNebulaGraphЩчЧјЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
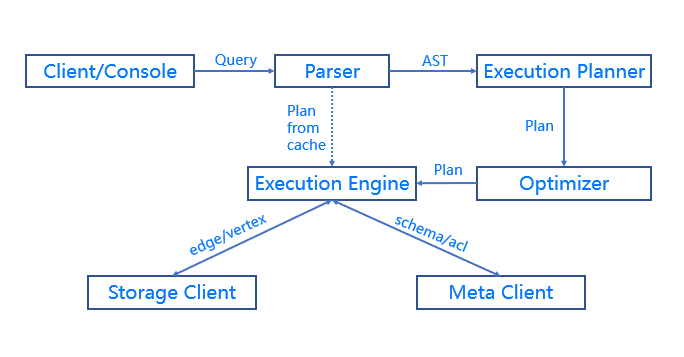
БОЦЊЕМЖС
гаЯђЪєадЭМ
ЃЈDirected Property GraphЃЉ
Nebula Graph ВЩгУЗЧГЃШнвзРэНтЕФгаЯђЪєадЭМЕФЗНЪНРДНЈФЃЁЃвВОЭЪЧЫЕЃЌдкТпМЩЯЃЌЭМгЩСНжжЭМдЊЫиЙЙГЩЃК
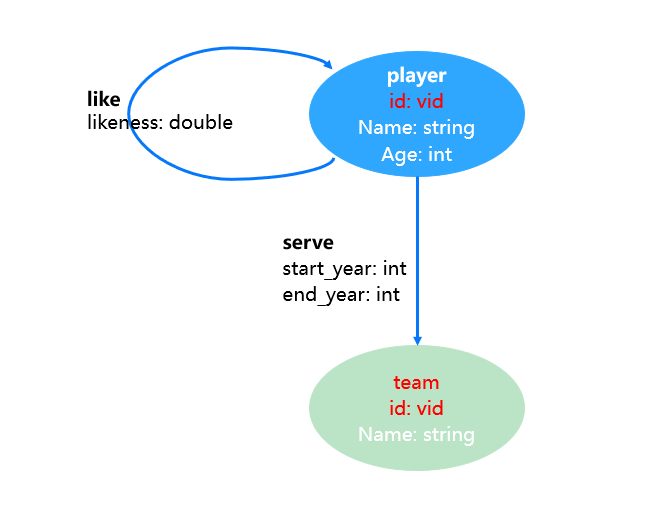
ЖЅЕуЃЈvertexЃЉЁЂЖЅЕуЕФРраЭЃЈtagЃЉКЭЖдгІЕФЖЅЕуЪєадЃКдк Nebula Graph жаЃЌЖЅЕуЕФРраЭГЦЮЊБъЧЉЃЈtagЃЉЁЃвЛИіЖЅЕуБиаыжСЩйгавЛжжРраЭЃЈБъЧЉЃЉЃЌвВПЩвдгаЖржжРраЭЃЈБъЧЉЃЉЁЃУПжжБъЧЉгавЛзщЯрЖдгІЕФЪєадЃЌГЦЮЊ
schemaЁЃ
Р§ШчЩЯЭМЪОР§жаЃЌгаСНжжРраЭЕФЖЅЕуЃКplayer КЭ teamЁЃ player ЕФ schema гаШ§жжЪєад
idЃЈvidЃЉЃЌNameЃЈstringЃЉКЭ AgeЃЈintЃЉЃЛteam ЕФ schema гаСНжжЪєад
idЃЈvidЃЉКЭ NameЃЈstringЃЉЁЃ
КЭ Mysql вЛбљЃЌNebula Graph ЪЧвЛжжЧП schema ЕФЪ§ОнПтЃЌЪєадЕФУћ-ГЦКЭЪ§ОнРраЭЖМЪЧдкЪ§ОнаДШыЧАШЗЖЈЕФЁЃ
БпЃЈedgeЃЉЁЂБпЕФРраЭЃЈedgetypeЃЉКЭБпЩЯЕФЪєадЃКNebula Graph жаЕФБпОљЪЧгаЯђБпЃЌБэУїСЫвЛИіДгЦ№ЕуЃЈsrcЃЉжИЯђжеЕуЃЈdstЃЉБпЕФЙиСЊЙиЯЕЁЃУПИіЙиЯЕЖМгавЛИі
edgetypeЃЌУПжж edgetype ЖЈвхСЫЙиЯЕЕФЪєадЁЃ
Р§ШчЃЌЩЯЭМжагаСНжжРраЭЕФБпЃЌвЛжжЮЊ player жИЯђ player ЕФ like ЙиЯЕЃЌЪєадЮЊ
likeness (double)ЃЛСэвЛжжЮЊ player жИЯђ team ЕФ serve ЙиЯЕЃЌСНИіЪєадЗжБ№ЮЊ
start_year(int) КЭ end_year(int)ЁЃ
ашвЊЫЕУїЕФЪЧЃЌЦ№ЕуКЭжеЕужЎМфЃЌПЩвдЭЌЪБДцдкЖрЬѕЯрЭЌЛђепВЛЭЌРраЭЕФБпЁЃ
ЭМЗжИю
ЃЈGraph PartitionЃЉ
гЩгкГЌДѓЙцФЃЙиЯЕЭјТчЕФНкЕуЪ§СПИпДяАйвкЕНЧЇвкЃЌЖјБпЕФЪ§СПИќЛсИпДяЭђвкЃЌМДЪЙНіДцДЂЕуКЭБпСНепвВдЖДѓгквЛАуЗўЮёЦїЕФШнСПЁЃвђДЫашвЊгаЗНЗЈНЋЭМдЊЫиЧаИюЃЌВЂДцДЂдкВЛЭЌТпМЗжЦЌЃЈPartitionЃЉЩЯЁЃNebula
Graph ВЩгУБпЗжИюЕФЗНЪНЃЌФЌШЯЕФЗжЦЌВпТдЮЊЙўЯЃЩЂСаЃЌpartition Ъ§СПЮЊОВЬЌЩшжУВЂВЛПЩИќИФЁЃ
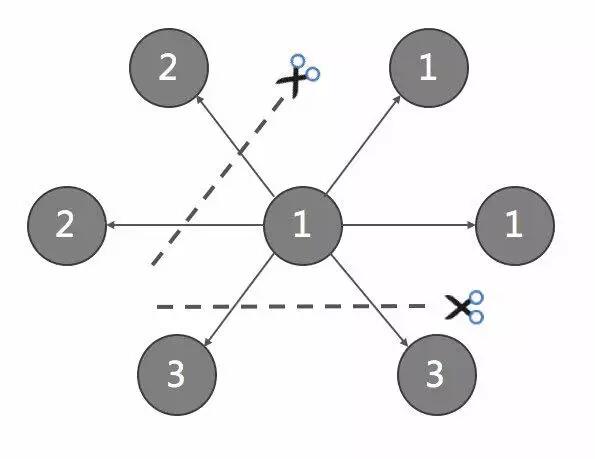
Ъ§ОнФЃаЭ
ЃЈData ModelЃЉ
дк Nebula Graph жаЃЌУПИіЖЅЕуБЛНЈФЃЮЊ key-valueЃЌИљОнЦф vertexIDЃЈЛђМђГЦ
vidЃЉЙўЯЃЩЂСаКѓЃЌДцДЂЕНЖдгІЕФ partition ЩЯЁЃ

вЛЬѕТпМвтвхЩЯЕФБпЃЌдк Nebula Graph жаНЈФЃЮЊСНИіЖРСЂЕФ key-valueЃЌЗжБ№ГЦЮЊ
out-key КЭ in-keyЁЃout-key гыетЬѕБпЫљЖдгІЕФЦ№ЕуДцДЂдкЭЌвЛИі partition
ЩЯЃЌin-key гыетЬѕБпЫљЖдгІЕФжеЕуДцДЂдкЭЌвЛИі partition ЩЯЁЃ

ЙигкЪ§ОнФЃаЭЕФЯъЯИЩшМЦЛсдкКѓајЕФЯЕСаЮФеТжаНщЩмЁЃ
ЯЕЭГМмЙЙ
ЃЈArchitectureЃЉ
Nebula Graph АќРЈЫФИіжївЊЕФЙІФмФЃПщЃЌЗжБ№ЪЧДцДЂВуЁЂдЊЪ§ОнЗўЮёЁЂМЦЫуВуКЭПЭЛЇЖЫЁЃ
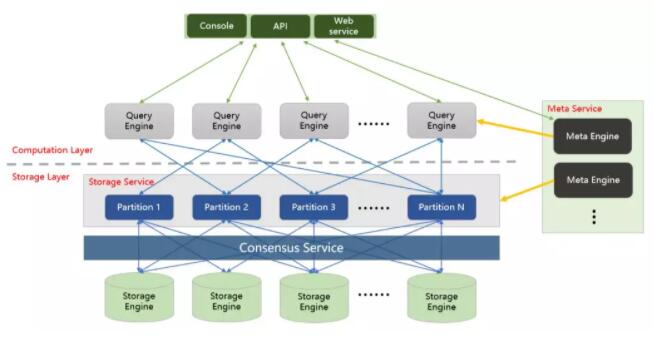
ДцДЂВу
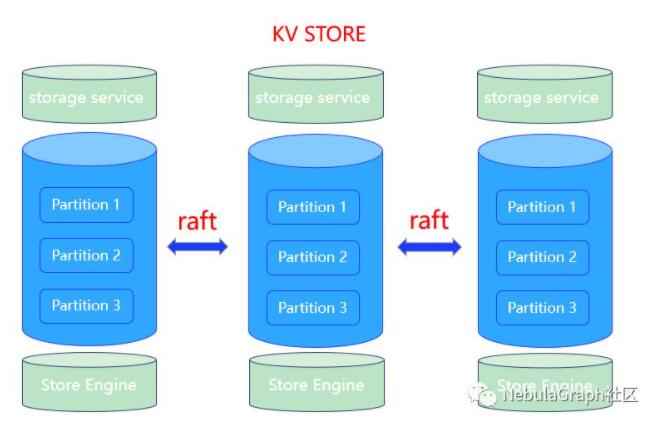
ДцДЂВуЖдгІНјГЬЪЧ nebula-storagedЁЃЦфКЫаФЮЊЛљгк RAFT авщЕФЗжВМЪН Key-value
StorageЁЃФПЧАжЇГжЕФжївЊДцДЂв§ЧцЮЊ Rocksdb КЭ HBaseЁЃ
Raft авщЭЈЙ§ leader/follower ЕФЗНЪНЃЌРДБЃГжЪ§ОнжЎМфЕФвЛжТадЁЃNebula
Storage жївЊдіМгСЫвдЯТЙІФмКЭгХЛЏЃК
1.Parallel Raft. ЖрЬЈЛњЦїЩЯЕФЯрЭЌ partiton-id
зщГЩвЛИі Raft groupЁЃЭЈЙ§Жрзщ Raft group ЪЕЯжВЂЗЂВйзїЁЃ
2.Write Path & batchЃКRaft авщЕФЖрЛњЦїМфЭЌВНвРРЕгкШежО
id ЫГађадЃЌетбљЕФ throughput НЯЕЭЁЃЭЈЙ§ХњСПКЭТвађЬсНЛЕФЗНЪНЃЌРДЪЕЯжИќИпЕФЭЬЭТСПЁЃ
3.ЛљгквьВНИДжЦЕФ learnerЃКЕБМЏШКжадіМгаТЕФЛњЦїЪБЃЌПЩвдНЋЦфЯШБъМЧЮЊ
learnerЃЌВЂвьВНДг leader/follower РШЁЪ§ОнЁЃЕБИУ learner зЗЩЯ leader
КѓЃЌдйБъМЧЮЊ followerЃЌВЮгы raft авщЁЃ
4.Load-balanceЃКЖдгкВПЗжЗУЮЪбЙСІНЯДѓЕФЛњЦїЃЌНЋЦфЫљЗўЮёЕФ
partition ЧЈвЦЕННЯРфЕФЛњЦїЩЯЃЌвдЪЕЯжИќКУЕФИКдиОљКтЁЃ
дЊЪ§ОнЗўЮёВу
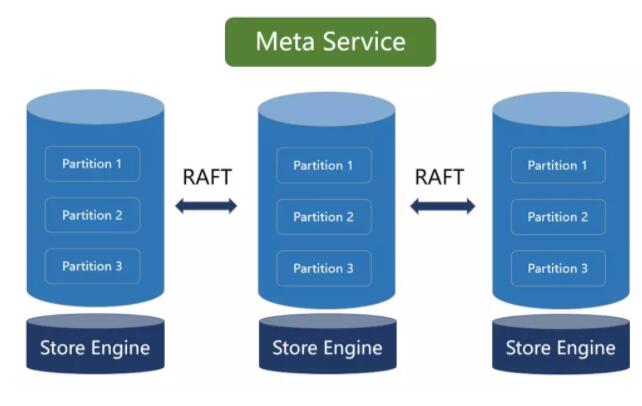
Meta service ЖдгІЕФНјГЬЪЧ nebula-metadЃЌЦфжївЊЕФЙІФмгаЃК
1.гУЛЇЙмРэЃКNebula Graph ЕФгУЛЇЬхЯЕАќРЈ God userЃЌAdminЃЌUserЃЌGuest
ЫФжжЁЃУПжжгУЛЇЕФВйзїШЈЯоВЛвЛЁЃ
2.МЏШКХфжУЙмРэЃКжЇГжЩЯЯпЁЂЯТЯпаТЕФЗўЮёЦїЁЃ
3.ЭМПеМфЙмРэЃКдіМгЁЂЩОГ§ЭМПеМфЃЌаоИФЭМПеМфХфжУЃЈRaft ИББОЪ§ЃЉЁЃ
4.Schema ЙмРэЃКNebula Graph ЮЊЧП schema
ЩшМЦЁЃ
1ЃЉЭЈЙ§ Meta service МЧТМ Tag КЭ Edge ЕФЪєадЕФИїзжЖЮЕФРраЭЁЃжЇГжЕФРраЭгаЃКint,
double, timestamp, list ЕШЃЛ
2ЃЉЖрАцБОЙмРэЃЌжЇГждіМгЁЂаоИФКЭЩОГ§ schemaЃЌВЂМЧТМЦфАцБОКХЃЛ
3ЃЉTTL ЙмРэЃЌЭЈЙ§БъЪЖЕНЦкЛиЪеЃЈtime-to-liveЃЉзжЖЮЃЌжЇГжЪ§ОнЕФздЖЏЩОГ§КЭПеМфЛиЪеЁЃ
Meta Service ВуЮЊгазДЬЌЕФЗўЮёЃЌЦфзДЬЌГжОУЛЏЗНЗЈгы Storage ВувЛбљЭЈЙ§ KV
Store ЗНЪНДцДЂЁЃ
Query Engine &
Query Language (nGQL)
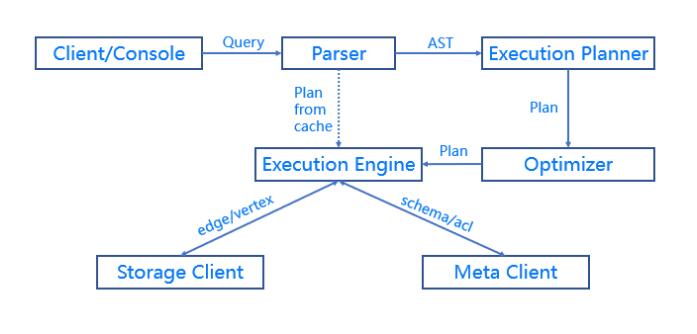
МЦЫуВуЖдгІЕФНјГЬЪЧ nebula-graphdЃЌЫќгЩЭъШЋЖдЕШЮозДЬЌЮоЙиСЊЕФМЦЫуНкЕузщГЩЃЌМЦЫуНкЕужЎМфЯрЛЅЮоЭЈаХЁЃ
Query Engine ВуЕФжївЊЙІФмЃЌЪЧНтЮіПЭЛЇЖЫЗЂЫЭ nGQL ЮФБОЃЌЭЈЙ§ДЪЗЈНтЮіЃЈLexerЃЉКЭгяЗЈНтЮіЃЈParserЃЉЩњГЩжДааМЦЛЎЁЃВЂЭЈЙ§гХЛЏКѓНЋжДааМЦЛЎНЛгЩжДаав§ЧцЁЃжДаав§ЧцЭЈЙ§
Meta Service ЛёШЁЭМЕуКЭБпЕФ schemaЃЌВЂЭЈЙ§ДцДЂв§ЧцВуЛёШЁЕуКЭБпЕФЪ§ОнЁЃ
Query EngineВуЕФжївЊгХЛЏгаЃК
вьВНКЭВЂЗЂжДааЃКгЩгк IO КЭЭјТчОљЮЊГЄЪБбгВйзїЃЌашВЩгУвьВНМАВЂЗЂВйзїЁЃДЫЭтЃЌЮЊБмУтЕЅИіГЄ
query гАЯьКѓај queryЃЌвВЮЊУПИі query ЩшжУЕЅЖРЕФзЪдДГивдБЃжЄЗўЮёжЪСП QoSЁЃ
МЦЫуЯТГСЃКЮЊБмУтДцДЂВуНЋЙ§ЖрЪ§ОнЛиДЋЕНМЦЫуВуЃЌеМгУБІЙѓДјПэЃЌЬѕМўЙ§ТЫЃЈwhereЃЉЕШЫузгЛсЫцВщбЏЬѕМўвЛЭЌЯТЗЂЕНДцДЂВуНкЕуЁЃ
жДааМЦЛЎгХЛЏЃКЙиЯЕЪ§ОнПт SQL жаЕФжДааМЦЛЎгХЛЏвбООРњСЫГЄЪБМфЕФЗЂеЙЃЌЕЋвЕНчЖдгкЭМВщбЏгябдЕФгХЛЏбаОПНЯЩйЁЃNebula
Graph ЖдЭМВщбЏЕФжДааМЦЛЎгХЛЏвВНјааСЫвЛЖЈЕФЬНЫїЃЌАќРЈжДааМЦЛЎЛКДцКЭЩЯЯТЮФЮоЙигяОфЕФВЂЗЂжДааЁЃ
API КЭ console
Nebula Graph ЬсЙЉC++, java, Golang Ш§жжгябдЕФПЭЛЇЖЫЃЌгыЗўЮёЦїжЎМфЕФЭЈаХЗНЪНЮЊ
RPCЃЌВЩгУЕФЭЈаХавщЮЊ Facebook-ThriftЁЃгУЛЇвВПЩЭЈЙ§ linux ЩЯ console
ЪЕЯжЖд Nebula Graph ВйзїЁЃWeb ЗУЮЪЗНЪНвВвбдкПЊЗЂЙ§ГЬжаЁЃ |









