| БрМЭЦМі: |
БОЮФжївЊеыЖдInfluxDBЕФЛљБОИХФюЁЂФкКЫЪЕЯжЕШНјааЩюШыЕФЗжЮіЕШЕШЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДзд ЪБађЪ§ОнПтЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
InfluxDB Ъ§ОнФЃаЭ
InfluxDBЕФЪ§ОнФЃаЭКЭЦфЫћЪБађЪ§ОнПтгааЉаэВЛЭЌЃЌЯТЭМЪЧInfluxDBжаЕФвЛеХЪОвтБэЃК
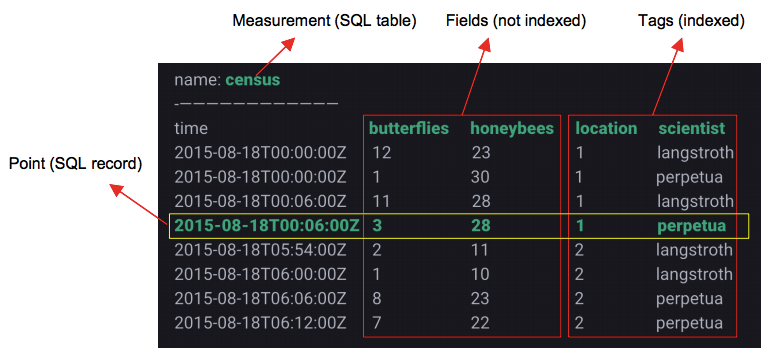
1. MeasurementЃКДгдРэЩЯНВИќЯёSQLжаБэЕФИХФюЁЃетКЭЦфЫћКмЖрЪБађЪ§ОнПтгааЉВЛЭЌЃЌЦфЫћЪБађЪ§ОнПтжаMeasurementПЩФмгыMetricЕШЭЌЃЌРрЫЦгкЯТЮФНВЕНЕФFieldЃЌетЕуашвЊзЂвтЁЃ
2. TagsЃКЮЌЖШСа
ЃЈ1ЃЉЩЯЭМжаlocationКЭscientistЗжБ№ЪЧБэжаЕФСНИіTag KeyЃЌЦфжаlocationЖдгІЕФЮЌЖШжЕTag
ValuesЮЊЃћ1, 2Ѓ§ЃЌscientistЖдгІЕФЮЌЖШжЕTag ValuesЮЊ{langstroth,
perpetual}ЃЌСНепЕФзщКЯTagSetгаЫФжжЃК
location = 1
, scientist = langstroth
location = 1 , scientist = perpetual
location = 2 , scientist = langstroth
location = 2 , scientist = perpetual |
ЃЈ2ЃЉдкInfluxDBжаЃЌБэжаTagsзщКЯЛсБЛзїЮЊМЧТМЕФжїМќЃЌвђДЫжїМќВЂВЛЮЈвЛЃЌБШШчЩЯБэжаЕквЛааКЭЕкШ§ааМЧТМЕФжїМќЖМЮЊЁЏlocation=1,scientist=langstrothЁЏЁЃЫљгаЪБађВщбЏзюжеЖМЛсЛљгкжїМќВщбЏжЎКѓдйОЙ§ЪБМфДСЙ§ТЫЭъГЩЁЃ
3. FieldsЃКЪ§жЕСаЁЃЪ§жЕСаДцЗХгУЛЇЕФЪБађЪ§ОнЁЃ
4. PointЃКРрЫЦSQLжавЛааМЧТМЃЌЖјВЂВЛЪЧвЛИіЕуЁЃ
InfluxDB КЫаФИХФю ЈC Series
ЮФеТЁЖЪБађЪ§ОнПтЬхЯЕММЪѕ ЈC ЪБађЪ§ОнДцДЂФЃаЭЩшМЦЁЗжаЬсЕНЪБМфЯпЕФИХФюЃЌЪБађЪ§ОнЕФЪБМфЯпОЭЪЧвЛИіЪ§ОндДВЩМЏЕФвЛИіжИБъЫцзХЪБМфЕФСїЪХЖјдДдДВЛЖЯЕиЭТГіЪ§ОнЃЌетбљаЮГЩЕФвЛЬѕЪ§ОнЯпГЦжЎЮЊЪБМфЯпЁЃШчЯТЭМЫљЪОЃК
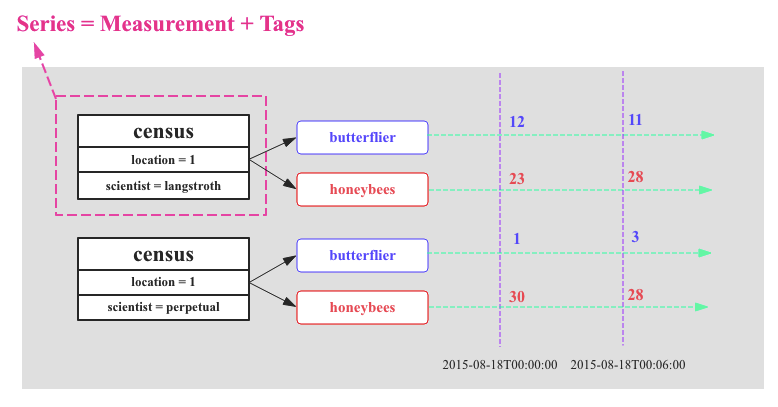
ЩЯЭМжагаСНИіЪ§ОндДЃЌУПИіЪ§ОндДЛсВЩМЏСНжжжИБъЃКbutterflierКЭhoneybeesЁЃInfluxDBжаЪЙгУSeriesБэЪОЪ§ОндДЃЌSeriesгЩMeasurementКЭTagsзщКЯЖјГЩЃЌTagsзщКЯгУРДЮЈвЛБъЪЖMeasurementЁЃSeriesЪЧInfluxDBжазюживЊЕФИХФюЃЌдкНгЯТРДЕФФкКЫЗжЮіжаЛсОГЃгУЕНЁЃ
InfluxDB ЯЕЭГМмЙЙ
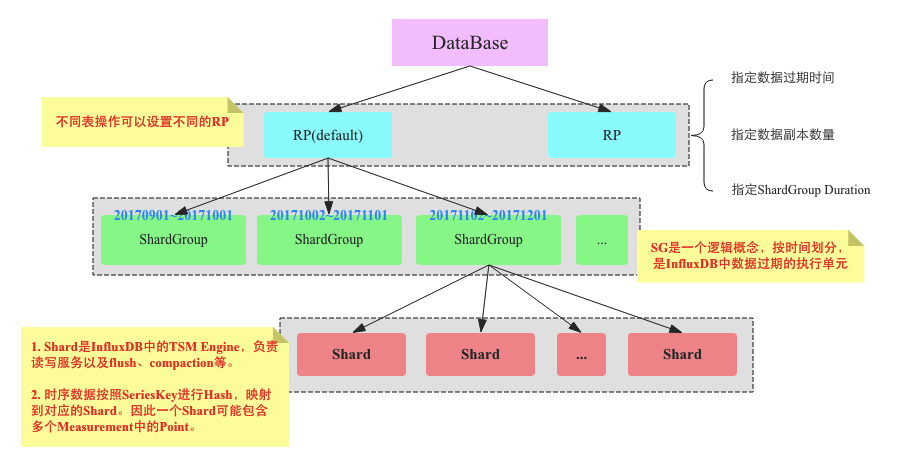
InfluxDBЖдЪ§ОнЕФзщжЏКЭЦфЫћЪ§ОнПтЯрБШгаКмДѓЕФВЛЭЌЃЌЮЊСЫИќМгЧхЮњЕФЫЕУїЃЌБЪепАДеездМКЕФРэНтЛСЫвЛеХInfluxDBТпММмЙЙЭМЃК
DataBase
InfluxDBжагаDatabaseЕФИХФюЃЌгУЛЇПЩвдЭЈЙ§create
database xxxРДДДНЈвЛИіЪ§ОнПтЁЃ
Retention PolicyЃЈRPЃЉ
Ъ§ОнБЃСєВпТдЁЃКмГЄвЛЖЮЪБМфБЪепЖдRPЕФРэНтЖМВЛзуЙЛГфЗжЃЌвдЮЊRPжЛЙцЖЈСЫЪ§ОнЕФЙ§ЦкЪБМфЁЃЦфЪЕВЛШЛЃЌRPдкInfluxDBжаЪЧвЛИіЗЧГЃживЊЕФИХФюЃЌКЫаФзїгУга3ИіЃКжИЖЈЪ§ОнЕФЙ§ЦкЪБМфЃЌжИЖЈЪ§ОнИББОЪ§СПвдМАжИЖЈShardGroup
DurationЁЃRPДДНЈгяОфШчЯТЃК
| CREATE RETENTION
POLICY ON <retention_policy_name> ON <database_name>
DURATION <duration> REPLICATION <n>
[SHARD DURATION <duration> ] [DEFAULT] |
Цфжаretention_policy_nameБэЪОRPЕФУћГЦЃЌdatabase_nameБэЪОЪ§ОнПтУћГЦЃЌdurationБэЪОTTLЃЌnБэЪОЪ§ОнИББОЪ§ЁЃSHARD
DURATIONЯТЮФдйНВЁЃОйИіМђЕЅЕФРѕзгЃК
| CREATE RETENTION
POLICY "one_day_only" ON "water_database"
DURATION 1d REPLICATION 1 SHARD DURATION 1h DEFAULT
|
InfluxDBжаRetention PolicyгаетУДМИИіаджЪКЭгУЗЈЃК
1. RPЪЧЪ§ОнПтМЖБ№ЖјВЛЪЧБэМЖБ№ЕФЪєадЁЃетКЭКмЖрЪ§ОнПтЖМВЛЭЌЁЃ
2. УПИіЪ§ОнПтПЩвдгаЖрИіЪ§ОнБЃСєВпТдЃЌЕЋжЛФмгавЛИіФЌШЯВпТдЁЃ
3. ВЛЭЌБэПЩвдИљОнБЃСєВпТдЙцЛЎдкаДШыЪ§ОнЕФЪБКђжИЖЈRPНјаааДШыЃЌЯТУцгяОфОЭжИЖЈsix_mouth_rollupЕФrpНјаааДШыЃК
| curl -X POST
'http://localhost:8086/write?db=mydb&rp=six_month_rollup'
--data-binary 'disk_free,hostname=server01 value=442221834240i
1435362189575692182' |
ШчЙћУЛгажИЖЈШЮКЮRPЃЌдђЪЙгУФЌШЯЕФRPЁЃ
Shard Group
Shard GroupЪЧInfluxDBжавЛИіживЊЕФТпМИХФюЃЌДгзжУцвтЫМРДПДShard GroupЛсАќКЌЖрИіShardЃЌУПИіShard
GroupжЛДцДЂжИЖЈЪБМфЖЮЕФЪ§ОнЃЌВЛЭЌShard GroupЖдгІЕФЪБМфЖЮВЛЛсжиКЯЁЃБШШч2017Фъ9дТЗнЕФЪ§ОнТфдкShard
Group0ЩЯЃЌ2017Фъ10дТЗнЕФЪ§ОнТфдкShard Group1ЩЯЁЃ
УПИіShard GroupЖдгІЖрГЄЪБМфЪЧЭЈЙ§Retention PolicyжазжЖЮЁБSHARD DURATIONЁБжИЖЈЕФЃЌШчЙћУЛгажИЖЈЃЌвВПЩвдЭЈЙ§Retention
DurationЃЈЪ§ОнЙ§ЦкЪБМфЃЉМЦЫуГіРДЃЌСНепЕФЖдгІЙиЯЕЮЊЃК

ЮЪЬтРДСЫЃЌЮЊЪВУДашвЊНЋЪ§ОнАДееЪБМфЗжГЩвЛИівЛИіShard GroupЃПИіШЫШЯЮЊгаСНИідвђЃК
1. НЋЪ§ОнАДееЪБМфЗжИюГЩаЁЕФСЃЖШЛсЪЙЕУЪ§ОнЙ§ЦкЪЕЯжЗЧГЃМђЕЅЃЌInfluxDBжаЪ§ОнЙ§ЦкЩОГ§ЕФжДааСЃЖШОЭЪЧShard
GroupЃЌЯЕЭГЛсЖдУПвЛИіShard GroupХаЖЯЪЧЗёЙ§ЦкЃЌЖјВЛЪЧвЛЬѕвЛЬѕМЧТМХаЖЯЁЃ
2. ЪЕЯжСЫНЋЪ§ОнАДееЪБМфЗжЧјЕФЬиадЁЃНЋЪБађЪ§ОнАДееЪБМфЗжЧјЪЧЪБађЪ§ОнПтвЛИіЗЧГЃживЊЕФЬиадЃЌЛљБОЩЯЫљгаЪБађЪ§ОнВщбЏВйзїЖМЛсДјгаЪБМфЕФЙ§ТЫЬѕМўЃЌБШШчВщбЏзюНќвЛаЁЪБЛђзюНќвЛЬьЃЌЪ§ОнЗжЧјПЩвдгааЇИљОнЪБМфЮЌЖШбЁдёВПЗжФПБъЗжЧјЃЌЬдЬВПЗжЗжЧјЁЃ
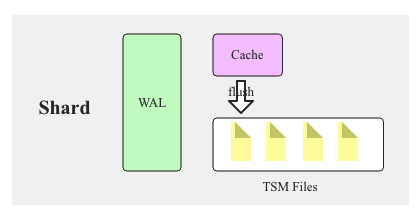
Shard
Shard GroupЪЕЯжСЫЪ§ОнЗжЧјЃЌЕЋЪЧShard GroupжЛЪЧвЛИіТпМИХФюЃЌдкЫќРяУцАќКЌСЫДѓСПShardЃЌShardВХЪЧInfluxDBжаеце§ДцДЂЪ§ОнвдМАЬсЙЉЖСаДЗўЮёЕФИХФюЃЌРрЫЦгкHBaseжаRegionЃЌKuduжаTabletЕФИХФюЁЃЙигкShardЃЌашвЊХЊЧхГўСНИіЗНУцЃК
1. ShardЪЧInfluxDBЕФДцДЂв§ЧцЪЕЯжЃЌОпЬхГЦжЎЮЊTSM(Time Sort Merge
Tree) EngineЃЌИКд№Ъ§ОнЕФБрТыДцДЂЁЂЖСаДЗўЮёЕШЁЃTSMРрЫЦгкLSMЃЌвђДЫShardКЭHBase
RegionвЛбљАќКЌCacheЁЂWALвдМАData FileЕШИїИізщМўЃЌвВЛсгаflushЁЂcompactionЕШетРрЪ§ОнВйзїЁЃ
2. Shard GroupЖдЪ§ОнАДЪБМфНјааСЫЗжЧјЃЌФЧТфдквЛИіShard GroupжаЕФЪ§ОнгжЪЧШчКЮгГЩфЕНФФИіShardЩЯФиЃП
InfluxDBВЩгУСЫHashЗжЧјЕФЗНЗЈНЋТфЕНЭЌвЛИіShard GroupжаЕФЪ§ОндйДЮНјааСЫвЛДЮЗжЧјЁЃетРяЬиБ№ашвЊзЂвтЕФЪЧЃЌInfluxDBЪЧИљОнhash(Series)НЋЪБађЪ§ОнгГЩфЕНВЛЭЌЕФShardЃЌЖјВЛЪЧИљОнMeasurementНјааhashгГЩфЃЌетбљЛсЪЙЕУЯрЭЌSeriesЕФЪ§ОнПЯЖЈЛсДцдкЭЌвЛИіShardжаЃЌЕЋетбљЕФгГЩфВпТдЛсЪЙЕУвЛИіShardжаАќКЌЖрИіMeasurementЕФЪ§ОнЃЌВЛЯёHBaseжавЛИіRegionЕФЪ§ОнПЯЖЈЖМЪєгкЭЌвЛеХБэЁЃ
InfluxDB ShardingВпТд
ЩЯЮФвбОЖдInfluxDBЕФShardingВпТдНјааСЫНщЩмЃЌетРяМђЕЅЕизіЯТзмНсЁЃЮвУЧжЊЕРЭЈГЃЗжВМЪНЪ§ОнПтвЛАугаСНжжShardingВпТдЃКRange
ShardingКЭHash ShardingЃЌЧАепЖдгкЛљгкжїМќЕФЗЖЮЇЩЈУшБШНЯИпаЇЃЌHBaseвдМАTiDBЖМВЩгУЕФетжжShardingВпТдЃЛКѓепЖдгкРыЩЂДѓЙцФЃаДШывдМАЫцМДЖСШЁЯрЖдБШНЯгбКУЃЌЭЈГЃзюМђЕЅЕФHashВпТдЪЧВЩгУШЁФЃЗЈЃЌЕЋШЁФЃЗЈгаИіКмДѓЕФБзВЁОЭЪЧШЁФЃЛљДЁашвЊЙЬЖЈЃЌвЛЕЉБфЛЏОЭашвЊЪ§ОнжиЗжВМЃЌЕБШЛПЩвдВЩгУИќМгИДдгЕФвЛжТадHashВпТдРДЛКНтЪ§ОнжиЗжВМгАЯьЁЃ
InfluxDBЕФShardingВпТдЪЧЕфаЭЕФСНВуShardingЃЌЩЯВуЪЙгУRange ShardingЃЌЯТВуЪЙгУHash
ShardingЁЃЖдгкЪБађЪ§ОнПтРДЫЕЃЌЛљгкЪБМфЕФRange ShardingЪЧзюКЯРэЕФПМТЧЃЌЕЋШчЙћНіНіЪЙгУTime
Range ShardingЃЌЛсДцдквЛИіКмбЯжиЕФЮЪЬтЃЌМДаДШыЛсДцдкШШЕуЃЌЛљгкTime Range ShardingЕФЪБађЪ§ОнПтаДШыБиШЛЛсТфЕНзюаТЕФShardЩЯЃЌЦфЫћРЯShardВЛЛсНгЪеаДШыЧыЧѓЁЃЖдаДШыадФмвЊЧѓКмИпЕФЪБађЪ§ОнПтРДЫЕЃЌШШЕуаДШыПЯЖЈВЛЪЧзюгХЕФЗНАИЁЃНтОіетИіЮЪЬтзюздШЛЕФЫМТЗОЭЪЧдйЪЙгУHashНјаавЛДЮЗжЧјЃЌЮвУЧжЊЕРЛљгкKeyЕФHashЗжЧјЗНАИПЩвдЭЈЙ§ЩЂСаКмКУЕиНтОіШШЕуаДШыЕФЮЪЬтЃЌЕЋЭЌЪБЛсв§ШыСНИіаТЮЪЬтЃК
1. ЕМжТKey Range ScanадФмБШНЯВюЁЃInfluxDBКмгХбХЕФНтОіСЫетИіЮЪЬтЃЌЩЯЮФБЪепЬсЕНЪБађЪ§ОнПтЛљБОЩЯЫљгаВщбЏЖМЪЧЛљгкSeriesЃЈЪ§ОндДЃЉРДЭъГЩЕФЃЌвђДЫжЛвЊHashЗжЧјЪЧАДееSeriesНјааHashОЭПЩвдНЋЯрЭЌSeriesЕФЪБађЪ§ОнЗХдквЛЦ№ЃЌетбљRange
ScanадФмОЭПЩвдЕУЕНБЃжЄЁЃЪТЪЕЩЯInfluxDBе§ЪЧетбљЪЕЯжЕФЁЃ
2. HashЗжЧјЕФИіЪ§БиаыЙЬЖЈЃЌШчЙћвЊИФБфHashЗжЧјЪ§ЛсЕМжТДѓСПЪ§ОнжиЗжВМЁЃГ§ЗЧЪЙгУвЛжТадHashЫуЗЈЁЃБЪепПДЕНInfluxDBдДТыжаHashЗжЧјЕФИіЪ§ЙЬЖЈЪЧ1ЃЌЖдДЫЛЙВЛЪЧКмРэНтЃЌШчЙћФФЮЛПДЙйЖдДЫБШНЯЪьЯЄПЩвджИЕМвЛЖўЁЃ
змНс
БОЦЊЮФеТжиЕуНщЩмInfluxDBжавЛаЉЛљБОИХФюЃЌЮЊКѓУцЗжЮіInfluxDBФкКЫЪЕЯжЕьЖЈвЛИіЛљДЁЁЃЮФеТжївЊНщЩмСЫШ§ИіживЊФЃПщЃК
1. ЪзЯШНщЩмСЫInfluxDBжавЛаЉЛљБОИХФюЃЌАќРЈMeasurementЁЂTagsЁЂFieldsвдМАPointЁЃ
2. НгзХНщЩмСЫSeriesетИіЗЧГЃЗЧГЃживЊЕФИХФюЁЃ
3. зюКѓжиЕуНщЩмСЫInfluxDBжаЪ§ОнЕФзщжЏаЮЪНЃЌзмНсЦ№РДОЭЪЧЃКЯШАДееRPЛЎЗжЃЌВЛЭЌЙ§ЦкЪБМфЕФЪ§ОнЛЎЗжЕНВЛЭЌЕФRPЃЌЭЌвЛИіRPЯТЕФЪ§ОндйАДееЪБМфRangeЗжЧјаЮГЩShardGroupЃЌЭЌвЛИіShardGroupжаЕФЪ§ОндйАДееSeriesНјааHashЗжЧјЃЌНЋЪ§ОнЛЎЗжГЩИќаЁСЃЖШЕФЙмРэЕЅдЊЁЃShardЪЧInfluxDBжаЪЕМЪЙЄзїепЃЌЪЧInfluxDBЕФДцДЂв§ЧцЁЃ
| 








