| БрМЭЦМі: |
ЮФеТНщЩмСЫвЛПюЗжЮіаЭЪ§ОнПтAnalyticDBЃЌАќРЈЫќЕФЖЈвхЁЂгХЪЦЁЂвдМАЯрЙиЕФгІгУГЁОАЕШЕШЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЖЈвх
ДгЙйЗНЮФЕЕСЫНтЕНЦфЕФЖЈвхЮЊЃК
АЂРядЦЗжЮіаЭЪ§ОнПтAnalyticDBЃЈМђГЦADBЃЉЃЌЪЧдЦЖЫЭаЙмЕФPBМЖИпВЂЗЂЪЕЪБЪ§ОнВжПтЃЌЪЧзЈзЂгкЗўЮёOLAPСьгђЕФЪ§ОнВжПтЁЃдкЪ§ОнДцДЂФЃаЭЩЯЃЌВЩгУЙиЯЕФЃаЭНјааЪ§ОнДцДЂЃЌПЩвдЪЙгУSQLНјааздгЩСщЛюЕФМЦЫуЗжЮіЃЌЮоашдЄЯШНЈФЃЁЃРћгУдЦЖЫЕФЮоЗьЩьЫѕФмСІЃЌAnalyticDBдкДІРэАйвкЬѕЩѕжСИќЖрСПМЖЕФЪ§ОнЪБеце§ЪЕЯжКСУыМЖМЦЫуЁЃ
AnalyticDBжЇГжЭЈЙ§SQLРДЙЙНЈЙиЯЕаЭЪ§ОнВжПтЁЃОпгаЙмРэМђЕЅЁЂНкЕуЪ§СПЩьЫѕЗНБуЁЂСщЛюЩ§НЕЪЕР§ЙцИёЕШЬиЕуЃЌЖјЧвжЇГжЗсИЛЕФПЩЪгЛЏЙЄОпвдМАETLШэМўЃЌМЋДѓЕФНЕЕЭСЫЦѓвЕНЈЩшЪ§ОнЛЏЕФУХМїЁЃ
ЖўЁЂВњЦЗгХЪЦ
Пь
аТвЛДњГЌДѓЙцФЃЕФMPP+DAGШкКЯв§Чц
ВЩгУааСаЛьДцММЪѕЁЂздЖЏЫїв§ЁЂжЧФмгХЛЏЦїЃЌдкЫВМфМДПЩЖдЧЇвкМЖБ№ЕФЪ§ОнНјааМДЪБЕФЖрЮЌЖШЗжЮіЭИЪгЃЌПьЫйЗЂЯжЪ§ОнМлжЕ
ПЩвдПьЫйРЉШнжСЪ§ЧЇНкЕуЕФГЌДѓЙцФЃ
СщЛю
МЋЖШСщЛюЕФДцДЂКЭМЦЫуЗжРыМмЙЙЃЌПЩвдЫцЪБЕїећНкЕуЪ§СПКЭЖЏЬЌЩ§НЕХфЪЕР§ЙцИё
ЭЌЪБжЇГждкДѓДцДЂSATAНкЕуКЭИпадФмЕФSSDНкЕуСщЛюЧаЛЛ
взгУ
зїЮЊдЦЖЫЭаЙмЕФPBМЖSQLЪ§ОнВжПтЃЌШЋУцМцШнMySQLавщКЭSQLЃК2003
ЭЈЙ§БъзМЕФSQLКЭГЃгУЕФBIЙЄОпЁЂвдМАETLЙЄОпЦНЬЈМДПЩЧсЫЩЪЙгУAnalyticDB
ГЌДѓЙцФЃ
ШЋЗжВМЪННсЙЙЃЌЮоШЮКЮЕЅЕуЩшМЦЃЌЪЙЕУЪ§ОнПтЪЕР§жЇГжECUНкЕуЖЏЬЌЯпадРЉШнжСЪ§ЧЇНкЕу
ЭЈЙ§КсЯђРЉШнРДДѓЗљЖШЬсЩ§ВщбЏSQLЯьгІЫйЖШЁЂвдМАдіМгSQLДІРэВЂЗЂ
ИпВЂЗЂаДШы
ЭЈЙ§КсЯђРЉШнНкЕуЬсЩ§аДШыФмСІ
ЪЕЪБаДШыЪ§ОнКѓЃЌдМ1УызѓгвМДПЩВщбЏЗжЮіЁЃЕЅИіБэзюДѓжЇГж2PBЪ§ОнЃЌЪЎЭђвкМЧТМ
Ш§ЁЂгІгУГЁОА
ОЕфЪЕЪБЪ§ВжГЁОА
ФњПЩвдЭЈЙ§Ъ§ОнДЋЪфDTSНЋЙиЯЕаЭЪ§ОнПтЕФвЕЮёБэЪЕЪБОЕЯёвЛЗнЕНAnalyticDBЃЌЭЈЙ§Quick BIЃЈМђГЦQBIЃЉЭЯзЇЪНЧсЫЩЩњГЩБЈБэЃЌЛђепЭЈЙ§DataVПьЫйЖЈжЦФњЕФЦѓвЕЪЕЪБЪ§ОнДѓЦС
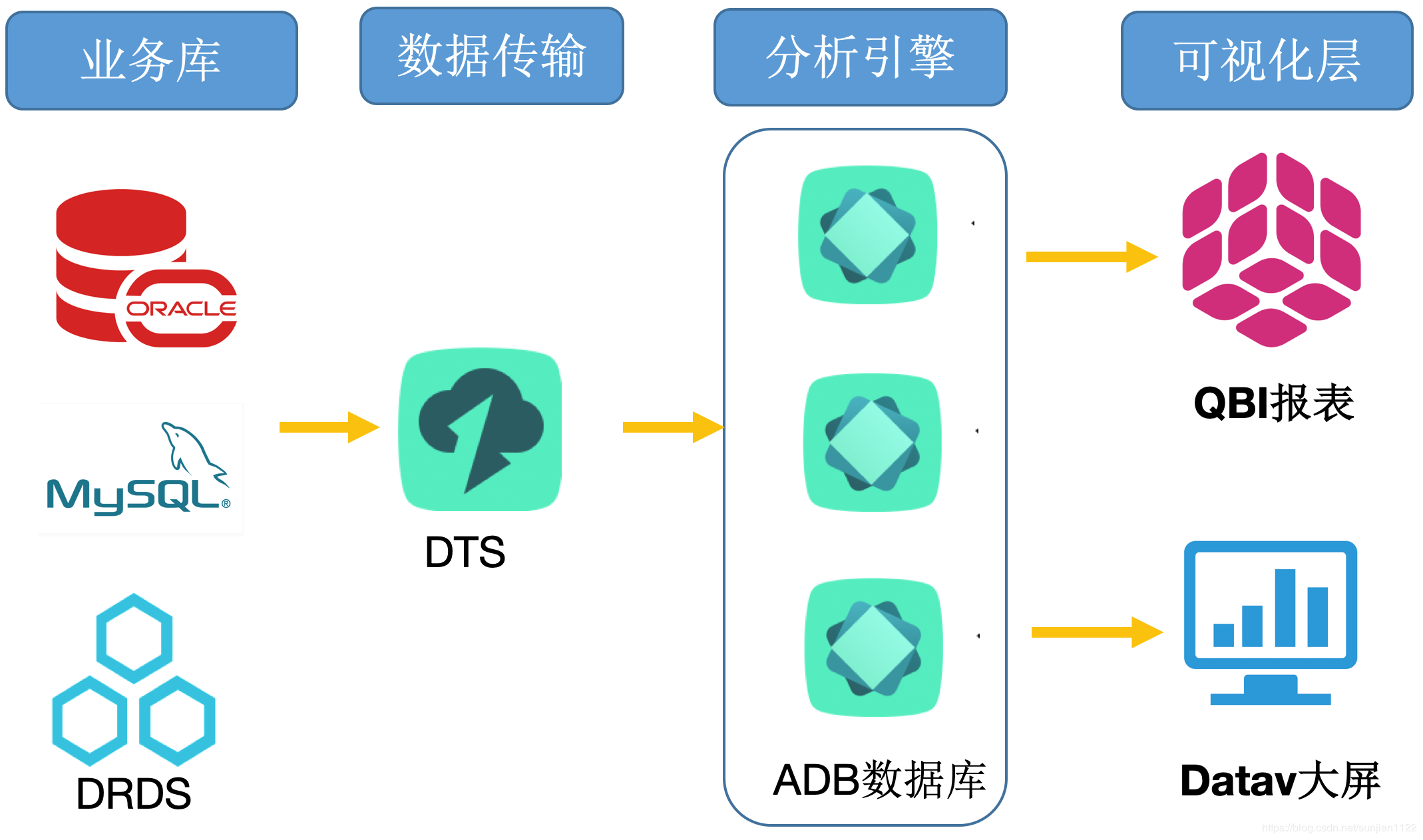
ЪЕЪБМЦЫуЧхЯДЛиСїГЁОА
ЭЈЙ§НЋСїМЦЫуЧхЯДНсЙћЪ§ОнЛиСїжСAnalyticDBРДДњЬцДЋЭГЕФMySQLЕШЕЅЛњЪ§ОнПтЃЌзїЮЊБЈБэПтРДВщбЏЪЙгУЁЃгЩгкЙиЯЕаЭЪ§ОнПтЗжВМЪНЕФВщбЏадФмгХЪЦЃЌВЛашвЊЗжПтЗжБэОЭФмНтОіPBМЖБ№ЕФВщбЏадФмЮЪЬтЁЃ
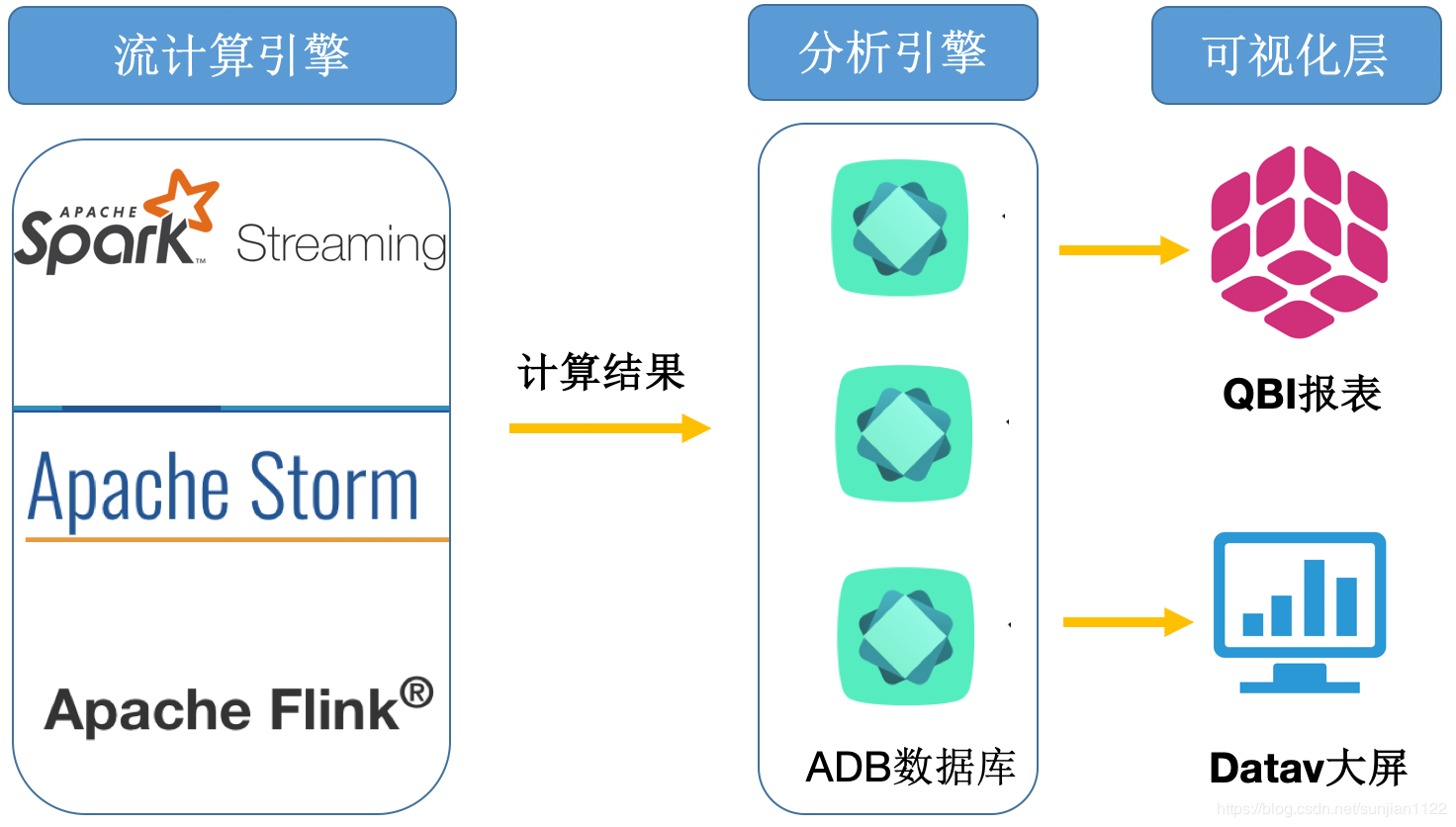
ETLЧхЯДЛиСїГЁОА
ДѓЪ§ОнРыЯпМЦЫуЦНЬЈ MaxComputeЁЂSparkSQLЁЂHadoopЁЂE-MapReduceЕШЦНЬЈВњЦЗдкЧхЯДЭъЪ§ОнКѓЃЌгЩгкБЈБэВщбЏЬѕМўвРШЛКмИДдгЃЌдЫгЊБЈБэашвЊзъШЁЃЌЕМжТЕЅЛњЪ§ОнПтЮоЗЈжЇГХадФмЃЌДЫЪБашвЊвЛИіЯёAnalyticDBетбљЗЧГЃЧПДѓЕФБЈБэВщбЏв§ЧцЭъГЩЪ§ОнВщбЏЙЄзїЁЃГЃМћЕФЛиСїЪ§ОнЙЄОпгаЪ§ОнМЏГЩ
КЭвЕФкПЊдДВњЦЗDataxЁЃ
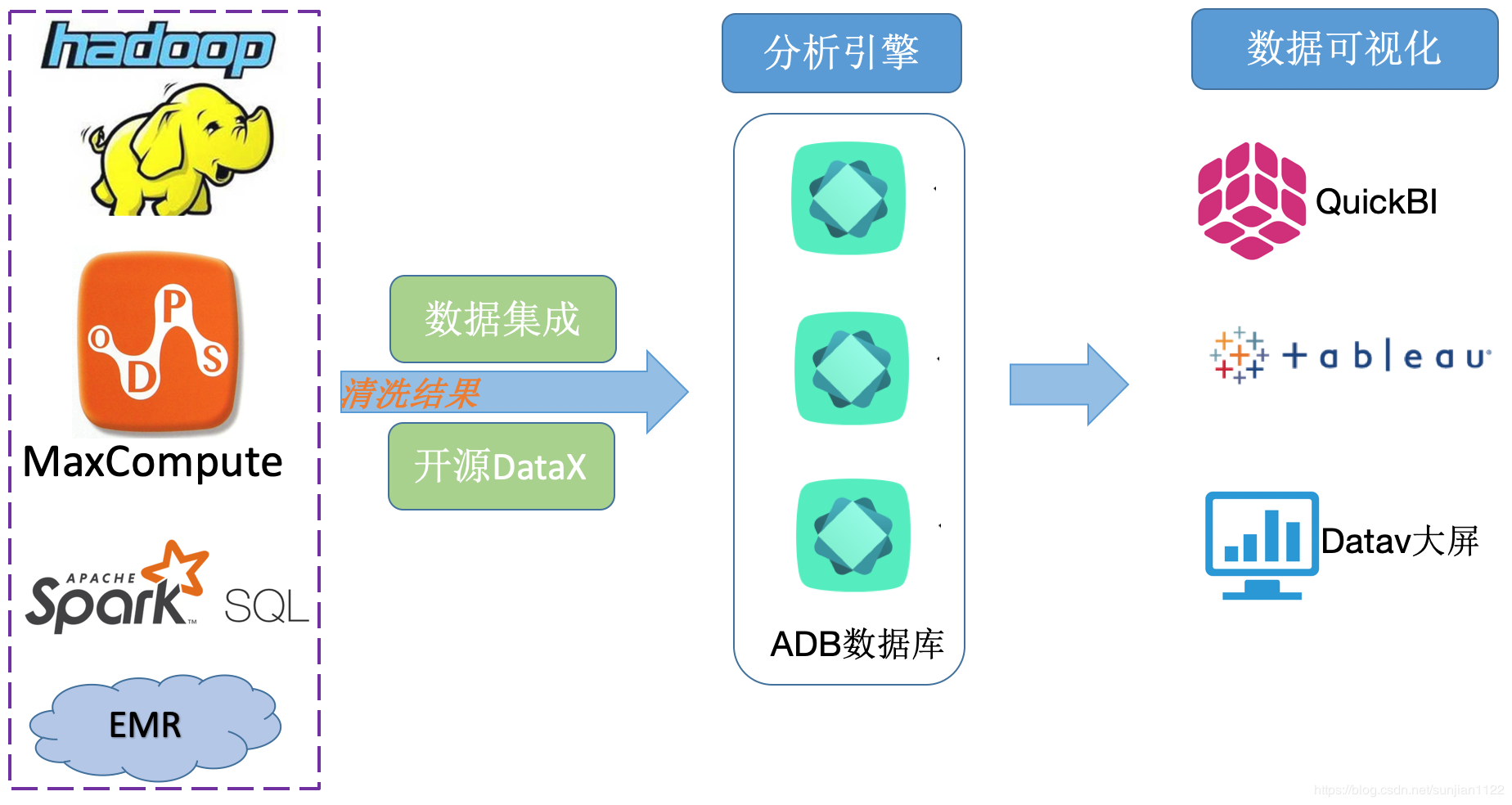
ЫФЁЂУћДЪНтЪЭ
Ъ§ОнПт
Ъ§ОнПтЪЧAnalyticDBзюИпВуЕФЖдЯѓЃЌАДЪ§ОнПтНјаазЪдДЕФЗжХфКЭЙмРэЁЃУПИіЪ§ОнПтЖРЯэвЛИіЗўЮёНјГЬЃЌЪЕЯжгУЛЇМфзЪдДЕФИєРыЁЃAnalyticDBжаЪ§ОнПтЕФИХФюгжГЦжЎЮЊЪЕР§ЃЌЭЈГЃЫЕЕФвЛИіAnalyticDBЪ§ОнПтОЭЪЧвЛИіЪЕР§ЃЌвЛИіЪЕР§гЩШєИЩИіECUНкЕузщГЩЁЃ
ECU
ЕЏадМЦЫуЕЅдЊЃЈElastic compute units МђаДECUЃЉЪЧAnalyticDBгУРДКтСПЪЕР§МЦЫуФмСІЕФдЊЕЅЮЛЁЃвЛИіЪ§ОнПтгЩШєИЩИіЭЌвЛРраЭЕФECUНкЕузщГЩЃЌР§ШчЪ§ОнПтAЃЌПЩФмгЩ4ИіC8зщГЩЃЌЛђеп6ИіS2NзщГЩЃЌУПИіECUНкЕуХфБИгаЙЬЖЈЕФДХХЬКЭФкДцзЪдДЁЃ
Бэзщ
БэзщЪЧвЛЯЕСаПЩЗЂЩњЙиСЊЕФЪ§ОнБэЕФМЏКЯЃЌAnalyticDBЮЊСЫЙмРэЯрЙиСЊЕФЪ§ОнБэЃЌв§ШыСЫБэзщЕФИХФюЁЃБэзщРрЫЦгкДЋЭГЪ§ОнПтschemaЕФИХФюЃЌAnalyticDBБэзщЗжЮЊСНРрЃК
ЮЌЖШБэзщЃЈЯЕЭГздДјЃЉ
здДјЮЌЖШИХФюЕФБэЃЈР§ШчЪЁЗнБэЁЂвјааБэЕШЃЉЃЌПЩвдЗХЕНЮЌЖШБэзщЯТЁЃ
ЦеЭЈБэзщ
вЛАуЛсАбашвЊЙиСЊЕФЦеЭЈБэЗХдкЯрЭЌЦеЭЈБэзщжаЃЌНЈвщетИіБэзщжаЕФЫљгаЦеЭЈБэЕФвЛМЖЗжЧјЪ§вЛжТЃЌjoinадФмЛсгаКмДѓЬсЩ§ЁЃ
Бэ
дкБэзщжЎЯТЪЧБэЕФИХФюЃЌAnalyticDBЬсЙЉСНжжРраЭЕФБэЃК
ЮЌЖШБэ
ДјгаЮЌЖШИХФюЕФБэЃЈР§ШчвјааБэЃЉЃЌгжГЦЮЊИДжЦБэЁЃФЌШЯУПИіECUНкЕуЗХжУвЛЗнШЋСПЕФЮЌЖШБэЪ§ОнЃЌЫљвдЮЌЖШБэПЩвдКЭШЮКЮЦеЭЈБэНјааЙиСЊЁЃгЩгкЮЌЖШБэЛсЯћКФИќЖрЕФДцДЂзЪдДЃЌЫљвдЮЌЖШБэЕФЪ§ОнСПДѓаЁгаЯожЦЃЌвЛАувЊЧѓЮЌЖШБэЕЅБэВЛГЌЙ§5000ЭђааЁЃ
ЦеЭЈБэ
ЦеЭЈБэОЭЪЧЗжЧјБэЃЌЮЊГфЗжРћгУЗжВМЪНЯЕЭГЕФВщбЏФмСІЖјЩшМЦЕФвЛжжБэЁЃЦеЭЈБэФЌШЯЪЧжИвЛМЖЗжЧјБэЃЌШчЙћгадіСПЪ§ОнЕМШыашЧѓЃЌПЩвдДДНЈЖўМЖЗжЧјБэЁЃ
ЗжЧј
ЦеЭЈБэВХгаЗжЧјЕФИХФюЃЌAnalyticDBжЇГжСНМЖЗжЧјВпТдЃКвЛМЖЗжЧјВЩгУhashЫуЗЈЃЌЕЅБэЪ§ОнСПдк60вквдФкЃЌЮвУЧЭЦМіФњЪЙгУвЛМЖЗжЧјЃЌЭЈГЃвЛМЖЗжЧјвбзуЙЛЁЃЖўМЖЗжЧјВЩгУlistЫуЗЈЃЌЖўМЖЗжЧјВПЗжМћзюМбЪЕМљеТНкЁЃ
жїМќ
AnalyticDBЕФЕФБэБиаыАќКЌжїМќзжЖЮЃЌЭЈЙ§жїМќНјааМЧТМЕФЮЈвЛадХаЖЯЁЃжїМќгЩвЕЮёidЁЂвЛМЖЗжЧјМќзщГЩЃЌгааЉЧщПівЕЮёidгывЛМЖЗжЧјЯрЭЌЁЃЖдгкМЧТМСПЬиБ№ДѓЕФБэЃЌДгДцДЂПеМфКЭinsertадФмПМТЧЃЌвЛЖЈвЊМѕЩйжїМќЕФзжЖЮЪ§ЁЃ
ЪОР§
вдвЛИіЕчЩЬЙЋЫОЙКТђСЫвЛИіAnalyticDB TradeЮЊР§ЃЌАяжњФњРэНтЩЯЪіИХФюЁЃ
1.ПЭЛЇдкАЂРядЦЙКТђ1ИіУћЮЊTradeЕФAnalyticDBЃЈвВГЦжЎЮЊ1ИіADSЪЕР§ЃЉЃЌШчЭМЫљЪОЃЌTradeгЩ4ИіC4НкЕуЙЙГЩЁЃ
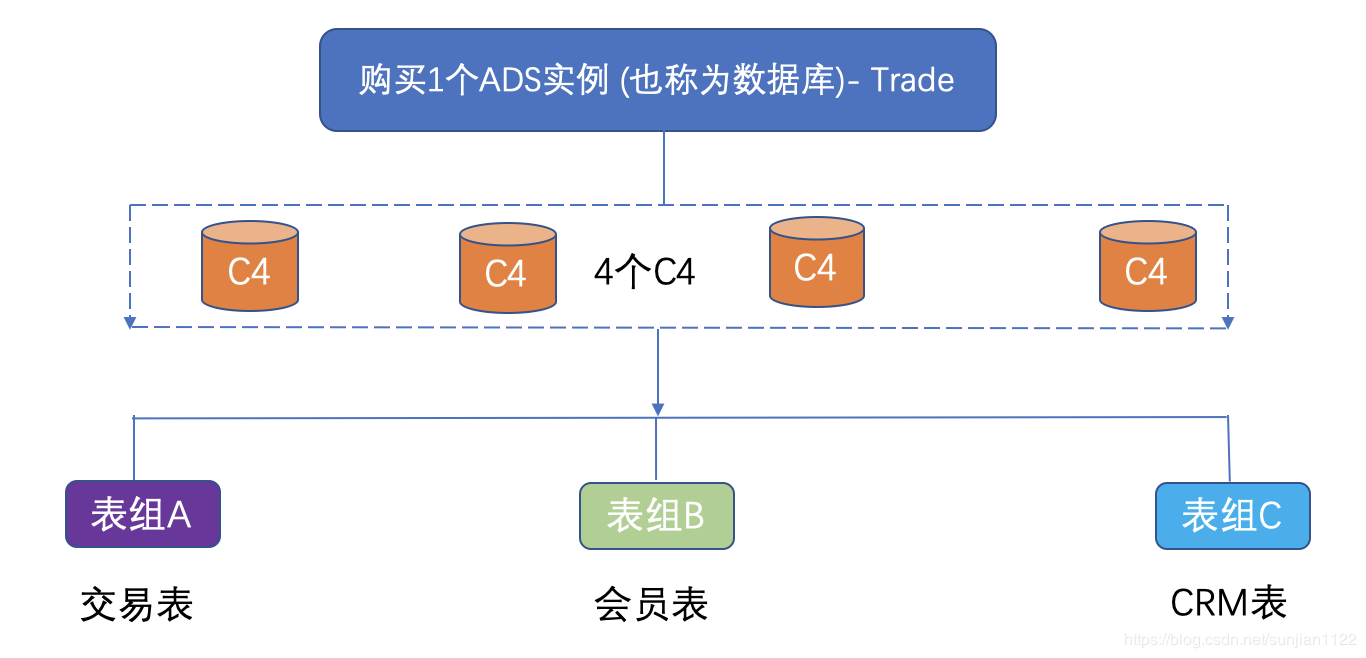
2.C4ЪЧвЛжжECUЙцИёЃЌЮвУЧЛЙЬсЙЉC8ЃЌS2NЃЌS8NШ§жжВЛЭЌЙцИёЕФECUЁЃ
3.Ъ§ОнПтTradeЯТУцПЩвдЙцЛЎЖрИіБэзщЃЈРрЫЦSchemaИХФюЃЉЃЌВЛЭЌБэзщгУгкДцЗХВЛЭЌЕФвЕЮёБэЁЃ
4.TradeЪ§ОнПтДДНЈЭъБЯКѓЃЌЯЕЭГЛсФЌШЯДДНЈвЛИіЮЌЖШБэзщЃЌЫљгаЮЌЖШЯрЙиЕФБэЃЌПЩвдЗХЕНЮЌЖШБэзщЯТЁЃЦеЭЈБэАДееЩЯЪіЕк3ЕуЕФЙцдђРДЙмРэЁЃ
| 








