| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫ
TiDB ЕФЫФИіжївЊгІгУГЁОАвдМАTiDB ВњЦЗЕФећЬхМмЙЙгУР§ШчКЮШУЪЙгУ TiDB
ЬцЛЛ MySQLЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкЦѓЖьКХ - БрГЬГСЫМТМЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ШчНёгВМўЕФадМлБШдНРДдНИпЃЌЭјТчДЋЪфЫйЖШдНРДдНПьЃЌЪ§ОнПтЗжВуЕФЧїЪЦж№НЅЯдЯжЃЌШЫУЧвбОВЛдйЧПЧѓгУвЛИіНтОіЗНАИРДНтОіЫљгаЕФДцДЂЮЪЬтЃЌЖјЪЧЭЈЙ§ЗжВуЃЌШУЛКДцгыЪ§ОнПтИКд№ИїздЩУГЄЕФвЕЮёГЁОАЁЃ
ЕБЧАЪ§ОнПтСьгђУцСйИїжжЮЪЬтЃЌШчдкЫѕЗХЁЂвЛжТадЁЂДѓЪ§ОнЗжЮіЁЂгыдЦЛљДЁМмЙЙМЏГЩЕШЗНУцОљДцдкжюЖрЮЪЬтЃЌЯжгаЕФЪ§ОнПтНтОіЗНАИКЭДѓЪ§ОнЗжЮів§ЧцНтОіЗНАИЛљБОДІгкИюСбЕФзДЬЌЃЌгЩгк
OracleЁЂMySQL Ъ§ОнПтВЂВЛЪЧУцЯђЗжВМЪНЛЗОГЖјЩшМЦЃЌвђДЫМДЪЙУуЧПЭЈЙ§ЗжПтЁЂЗжБэЛђжаМфМўЕФЗНЪНЃЌдкЪ§ОнПтВуУцзіСЫЗжЦЌЃЌДгБОжЪЩЯПДвВжЛЪЧИДжЦСЫЯрЭЌЕФЖбеЛЃЌЖјЗЧеыЖдЗжВМЪНЯЕЭГНјааДцДЂКЭМЦЫугХЛЏЃЌете§ЪЧНјааПчвЕЮёВщбЏЛђПчЮяРэЛњВщбЏКЭаДШыЪЎЗжЗБЫіЕФБОжЪдвђЁЃNoSQL
ЫфШЛНтОіСЫЪ§ОнПтЕЏадРЉеЙЕФФбЬтЃЌЕЋЪЧШДЗХЦњСЫЪ§ОнЕФЧПвЛжТадвдМАЖд ACID ЪТЮёЕФжЇГжЃЌДјРДСЫаТЕФЮЪЬтЁЃ
ЮЊСЫНтОіетвЛЮЪЬтЃЌTiDB дкМмЙЙЩЯНЋМЦЫуКЭДцДЂВуНјааИпЖШЕФГщЯѓКЭЗжРыЃЌЖдЛьКЯИКдиЕФГЁОАЭЈЙ§ IO
гХЯШМЖЖгСаЃЌжЧФмИББОЕїЖШЃЌааСаЛьКЯДцДЂЕШММЪѕЪЙЦфБфЮЊПЩФмЁЃTiDB зїЮЊПЊдДЕФЗжВМЪНЙиЯЕЪ§ОнПтЃЌЦфЬиЕуЪЧМИКѕПЩвд
100% МцШн MySQL НгПкЃЌвВМцШн MySQL ЕФгяЗЈКЭавщЃЌдкБЃжЄВЛЩЅЪЇ ACID ЪТЮёЕФЧАЬсЯТЃЌФмЙЛЕЏадЩьЫѕЃЌИпПЩгУЃЌПЩвдЭЌЪБДІРэ
OLTP КЭ OLAP ЙЄзїИКдиЃЌВЛдйашвЊ ETLЁЃ
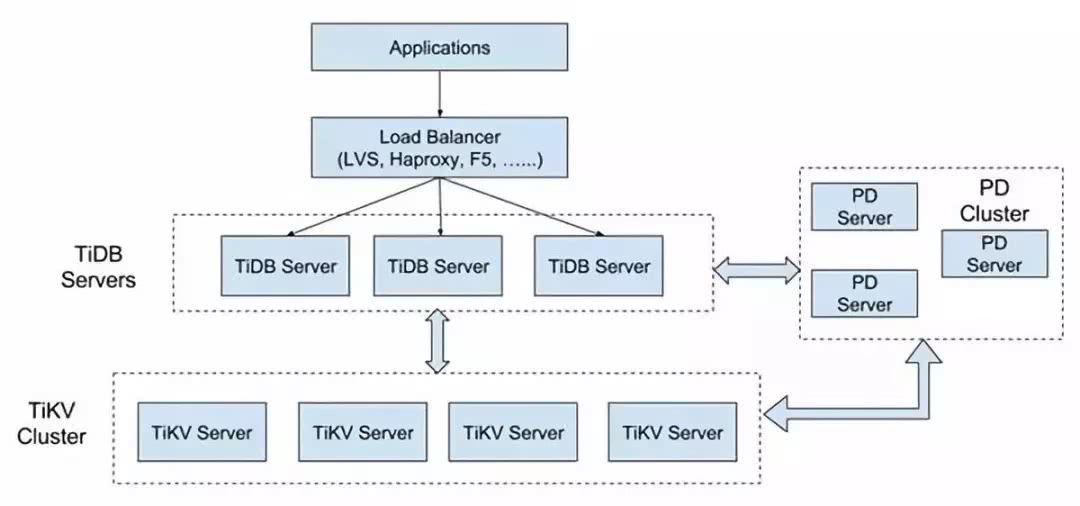
TiDBећЬхМмЙЙЭМ
TiDB ВњЦЗЕФећЬхМмЙЙЪЧИпЖШЗжВуЕФЃЌгЩЗжВМЪН SQL ВуЃЈTiDBЃЉЁЂЗжВМЪН KV ДцДЂв§ЧцЃЈTiKVЃЉвдМАЙмРэећИіМЏШКЕФ
PD ФЃПщзщГЩЁЃЮоЯоЫЎЦНРЉеЙЪЧ TiDB ЕФвЛДѓЬиЕуЃЌетРяЫљЫЕЕФЫЎЦНРЉеЙАќРЈСНЗНУцЃКМЦЫуФмСІКЭДцДЂФмСІЁЃ
HTAP ИјПЊЗЂепЬсЙЉСЫвЛИіЪЕЪБЪ§ОнЗжЮіЗНУцЕФаТЫМТЗЃЌВЛашвЊдйШЅЮЌЛЄСэвЛИіРыЯпЕФЪ§ОнВжПтЃЌМШМѕЧсСЫ
ETL ЕФЙЄзїЃЌгжФмНкЪЁКмДѓвЛВПЗжНЈСЂЪ§ОнВжПтЫљгУЕНЕФДцДЂКЭМЦЫуГЩБОЃЌHTAP НЋЪЧЮДРДЕФживЊЧїЪЦЁЃЛЦЖЋаёНщЩмСЫ
TiDB ЕФЫФИіжївЊгІгУГЁОАЃЌвЛЪЧ MySQL ЗжЦЌгыКЯВЂЃЛЖўЪЧжБНгЬцЛЛ MySQLЃЛШ§ЪЧгУзіЪ§ОнВжПтЃЛЫФЪЧзїЮЊЦфЫћЯЕЭГЕФвЛИіФЃПщЁЃ
гУР§1ЃКMySQLЗжЦЌгыКЯВЂ
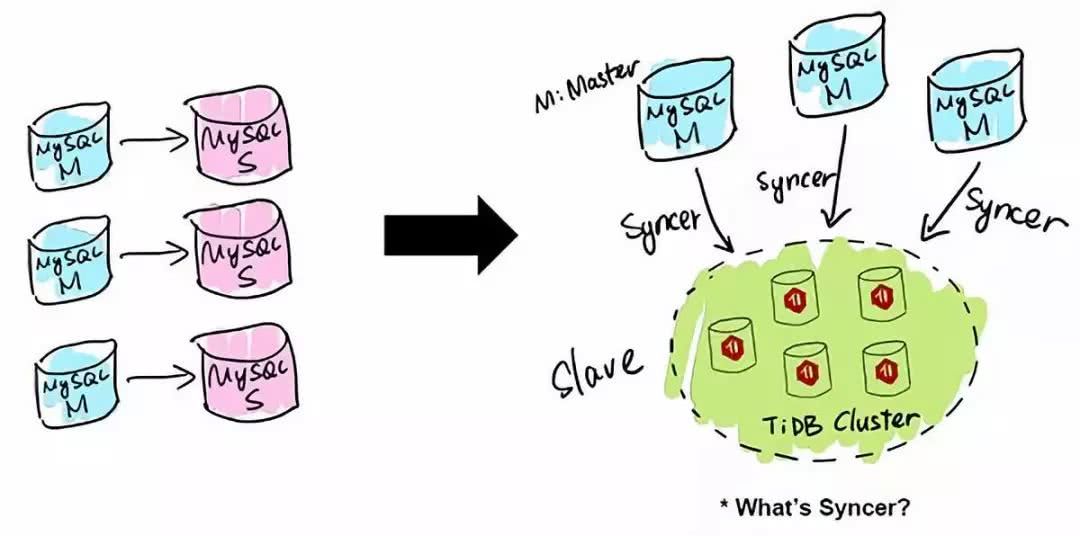
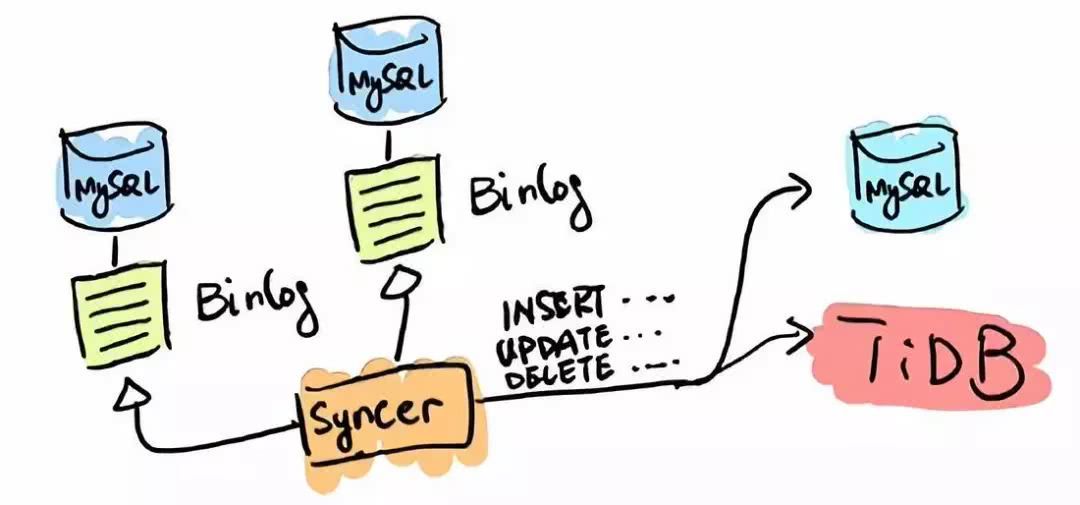
Syncer
TiDB гІгУЕФЕквЛРрГЁОАЪЧ MySQL ЕФЗжЦЌгыКЯВЂЁЃЖдгквбОдкгУ MySQL ЕФвЕЮёЃЌЗжПтЁЂЗжБэЁЂЗжЦЌЁЂжаМфМўЪЧГЃгУЪжЖЮЃЌЫцзХЗжЦЌЕФдіЖрЃЌПчЗжЦЌВщбЏЪЧвЛДѓФбЬтЁЃTiDB
дквЕЮёВуМцШн MySQL ЕФЗУЮЪавщЃЌPingCAP зіСЫвЛИіЪ§ОнЭЌВНЕФЙЄОпЁЊЁЊSyncerЃЌЫќПЩвдАб
TiDB зїЮЊвЛИі MySQL SlaveЃЌНЋ TiDB зїЮЊЯжгаЪ§ОнПтЕФДгПтНгдкжї MySQL ПтЕФКѓЗНЃЌдкетвЛВуНЋЪ§ОнДђЭЈЃЌПЩвджБНгНјааИДдгЕФПчПтЁЂПчБэЁЂПчвЕЮёЕФЪЕЪБ
SQL ВщбЏЁЃЛЦЖЋаёЬсЕНЃЌЁАЙ§ШЅЕФЪ§ОнПтЖМЪЧвЛжїЖрДгЃЌгаСЫ TiDB вдКѓЃЌПЩвдЗДЙ§РДзіЕНЖржївЛДгЁЃЁБ
гУР§2ЃКжБНгЬцЛЛMySQL
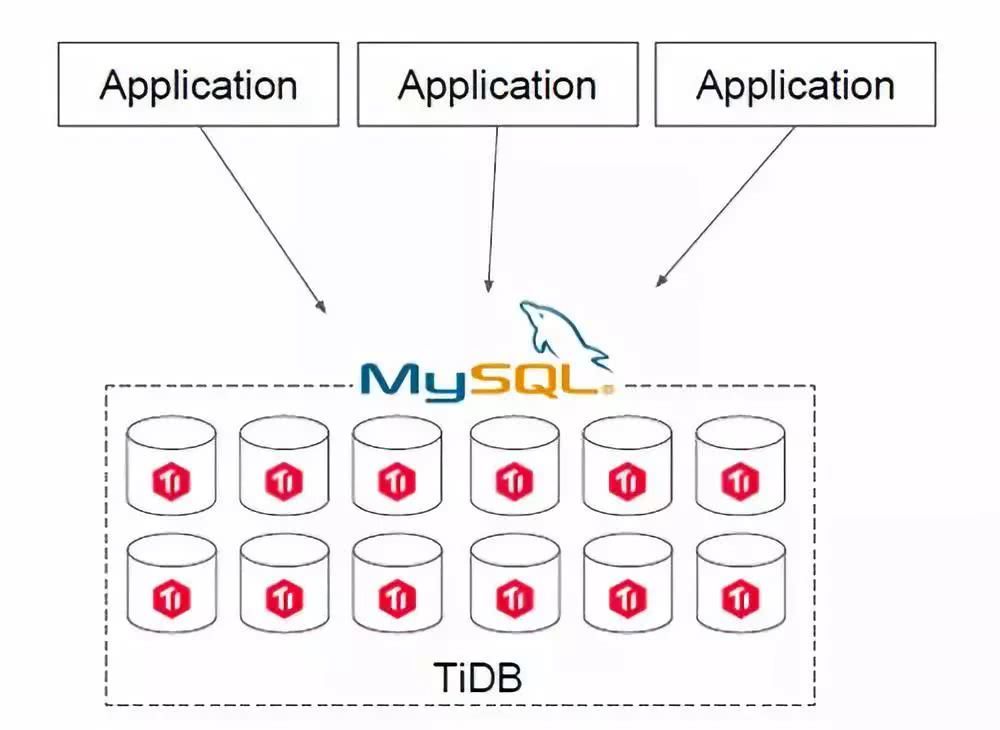
ЕкЖўРрГЁОАЪЧгУ TiDB жБНгШЅЬцЛЛ MySQLЁЃШчЙћФуЕФITМмЙЙдкДюНЈжЎГѕВЂЮДПМТЧЗжПтЗжБэЕФЮЪЬтЃЌШЋВПгУСЫ
MySQLЃЌЫцзХвЕЮёЕФПьЫйдіГЄЃЌКЃСПИпВЂЗЂЕФ OLTP ГЁОАдНРДдНЖрЃЌШчКЮНтОіМмЙЙЩЯЕФБзЖЫФи?
дквЛИі TiDB ЕФЪ§ОнПтЩЯЃЌЫљгавЕЮёГЁОАВЛашвЊзіЗжПтЗжБэЃЌЫљгаЕФЗжВМЪНЙЄзїЖМгЩЪ§ОнПтВуЭъГЩЁЃTiDB
МцШн MySQL авщЃЌЫљвдПЩвджБНгЬцЛЛ MySQLЃЌЖјЧвЛљБОзіЕНСЫПЊЯфМДгУЃЌЭъШЋВЛгУЕЃаФДЋЭГЗжПтЗжБэЗНАИДјРДЗБжиЕФЙЄзїИКЕЃКЭИДдгЕФЮЌЛЄГЩБОЃЌгбКУЕФгУЛЇНчУцШУГЃЙцЕФММЪѕШЫдБПЩвдИпаЇЕиНјааЮЌЛЄКЭЙмРэЁЃСэЭтЃЌTiDB
Опга NoSQL РрЫЦЕФРЉШнФмСІЃЌдкЪ§ОнСПКЭЗУЮЪСїСПГжајдіГЄЕФЧщПіЯТФмЙЛЭЈЙ§ЫЎЦНРЉШнЬсИпЯЕЭГЕФвЕЮёжЇГХФмСІЃЌВЂЧвЯьгІбгГйЮШЖЈЁЃ
ЛЦЖЋаёдкбнНВжаЬсЕНСЫФІАнЕЅГЕЕФАИР§ЃЌФІАндчЦкЕФЪ§ОнПтШЋВПгУ MySQLЃЌЫцзХвЕЮёЕФПьЫйдіГЄЃЌMySQL
ЕФБзЖЫж№НЅЯдЯжЃЌФІАнЕЅГЕгк 2017 ФъГѕПЊЪМЪЙгУ TiDB ЬцЛЛ MySQLЁЃШчНёЃЌФІАнЕФ IT
ЯЕЭГжавбВПЪ№СЫЪ§Ьз TiDB МЏШКЃЌНќАйИіНкЕуЃЌГадизХЪ§ЪЎ TB ЕФИїРрЪ§ОнЁЃ
гУР§3ЃКЪ§ОнВжПт
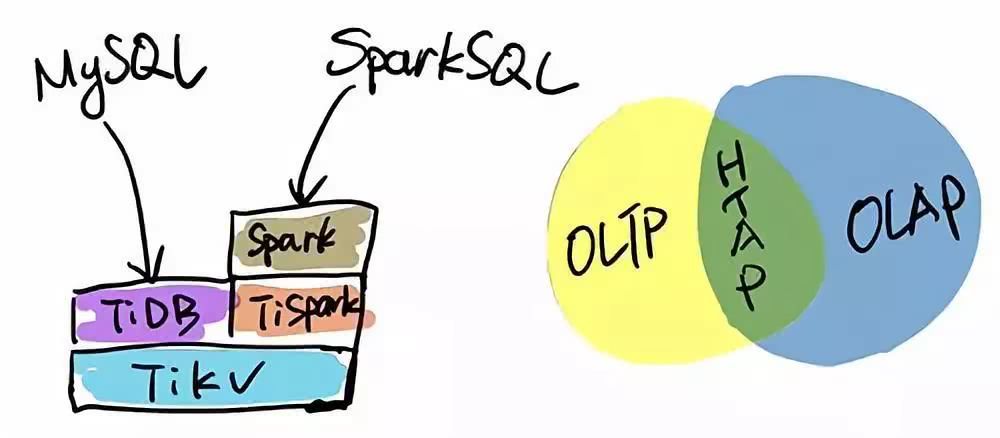
TiDB БОЩэЪЧвЛИіЗжВМЪНЯЕЭГЃЌЕкШ§жжЪЙгУГЁОАЪЧНЋ TiDB ЕБзїЪ§ОнВжПтЪЙгУЁЃTPC-H ЪЧЪ§ОнЗжЮіСьгђЕФвЛИіВтЪдМЏЃЌTiDB
2.0 дк OLAP ГЁОАЯТЕФадФмгаСЫДѓЗљЬсЩ§ЃЌдРДжЛФмдкЪ§ОнВжПтРяУцХмЕФвЛаЉИДдгЕФ QueryЃЌдк
TiDB 2.0 РяУцХмЃЌЪБМфЛљБОЖМФмПижЦдк 10 УывдФкЁЃЕБШЛЃЌвђЮЊ OLAP ЕФЗЖГыЗЧГЃДѓЃЌTiDB
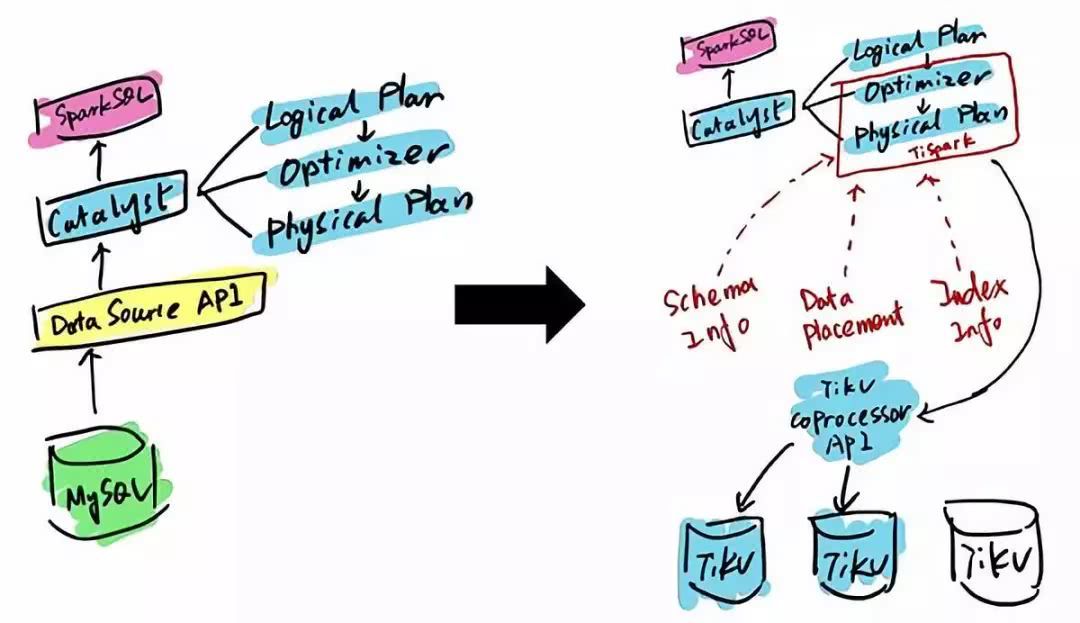
ЕФ SQL вВгаИуВЛЖЈЕФЧщПіЃЌЮЊДЫ PingCAP ПЊдДСЫ TiSparkЃЌTiSpark ЪЧвЛИі
Spark ВхМўЃЌгУЛЇПЩвджБНггУ Spark SQL ЪЕЪБЕидк TiKV ЩЯзіДѓЪ§ОнЗжЮіЁЃ
гУР§4ЃКзїЮЊЦфЫћЯЕЭГЕФФЃПщ
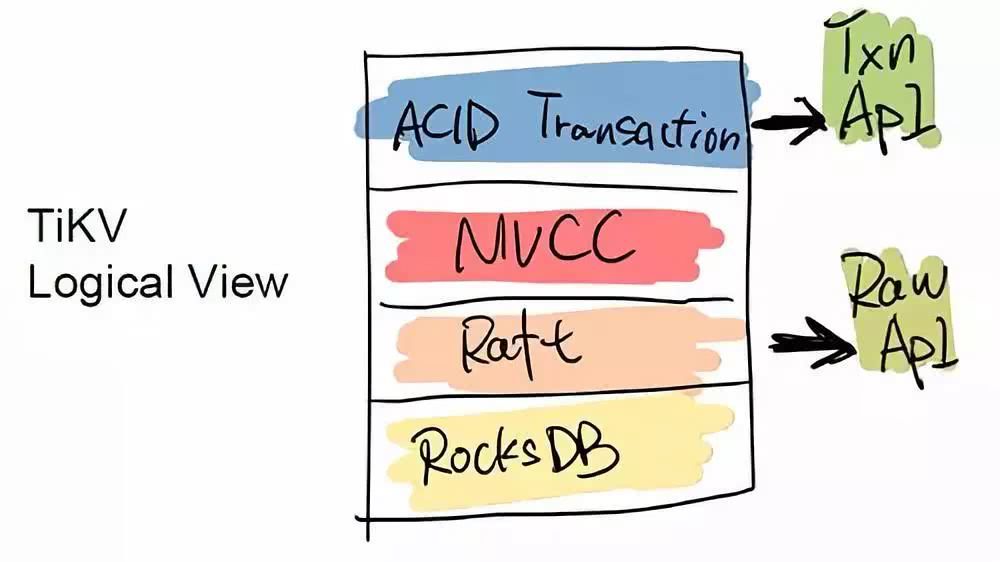
TiDB ЪЧвЛИіДЋЭГЕФДцДЂИњМЦЫуЗжРыЕФЯюФПЃЌЦфЕзВуЕФ Key-Value
ВуЃЌПЩвдЕЅЖРзїЮЊвЛИі HBase ЕФ Replacement РДгУЃЌЫќЭЌЪБжЇГжПчааЪТЮёЁЃTiDB ЖдЭтЬсЙЉСНИі
API НгПкЃЌвЛИіЪЧ ACID Transaction ЕФ APIЃЌгУгкжЇГжПчааЪТЮёЃЛСэвЛИіЪЧ Raw
APIЃЌЫќПЩвдзіЕЅааЕФЪТЮёЃЌЛЛРДЕФЪЧећИіадФмЕФЬсЩ§ЃЌЕЋВЛЬсЙЉПчааЪТЮёЕФ ACID жЇГжЁЃгУЛЇПЩвдИљОнздЩэЕФашЧѓдкСНИі
API жЎМфздаабЁдёЁЃР§ШчгавЛаЉгУЛЇжБНгдк TiKV жЎЩЯЪЕЯжСЫ Redis авщЃЌНЋ TiKV ЬцЛЛвЛаЉДѓШнСПЃЌЖдбгГйвЊЧѓВЛИпЕФ
Redis ГЁОАЁЃ
| 








