| БрМЭЦМі: |
ЮФеТНщЩмСЫTiKV
ЕФвЛаЉЩшМЦЫМЯыКЭЛљБОИХФюЁЂдЊаХЯЂЕФДцДЂЁЂЁЂSQL ВуЕФвЛаЉЙІФмвдМАЙигк PD ЕФаХЯЂЕШЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздpingcapЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
в§бд
Ъ§ОнПтЁЂВйзїЯЕЭГКЭБрвыЦїВЂГЦЮЊШ§ДѓЯЕЭГЃЌПЩвдЫЕЪЧећИіМЦЫуЛњШэМўЕФЛљЪЏЁЃЦфжаЪ§ОнПтИќППНќгІгУВуЃЌЪЧКмЖрвЕЮёЕФжЇГХЁЃетвЛСьгђОЙ§СЫМИЪЎФъЕФЗЂеЙЃЌВЛЖЯЕФгааТЕФНјеЙЁЃ
КмЖрШЫгУЙ§Ъ§ОнПтЃЌЕЋЪЧКмЩйгаШЫЪЕЯжЙ§вЛИіЪ§ОнПтЃЌЬиБ№ЪЧЪЕЯжвЛИіЗжВМЪНЪ§ОнПтЁЃСЫНтЪ§ОнПтЕФЪЕЯждРэКЭЯИНкЃЌвЛЗНУцПЩвдЬсИпИіШЫММЪѕЃЌЖдЙЙНЈЦфЫћЯЕЭГгаАяжњЃЌСэвЛЗНУцвВгаРћгкгУКУЪ§ОнПтЁЃ
баОПвЛУХММЪѕзюКУЕФЗНЗЈЪЧбаОПЦфжавЛИіПЊдДЯюФПЃЌЪ§ОнПтвВВЛР§ЭтЁЃЕЅЛњЪ§ОнПтСьгђгаКмЖрКмКУЕФПЊдДЯюФПЃЌЦфжа
MySQL КЭ PostgreSQL ЪЧЦфжажЊУћЖШзюИпЕФСНИіЃЌВЛЩйЭЌбЇЖМПДЙ§етСНИіЯюФПЕФДњТыЁЃЕЋЪЧЗжВМЪНЪ§ОнПтЗНУцЃЌКУЕФПЊдДЯюФПВЂВЛЖрЁЃ
TiDB ФПЧАЛёЕУСЫЙуЗКЕФЙизЂЃЌЬиБ№ЪЧвЛаЉММЪѕАЎКУепЃЌЯЃЭћФмЙЛВЮгыетИіЯюФПЁЃгЩгкЗжВМЪНЪ§ОнПтздЩэЕФИДдгадЃЌКмЖрШЫВЂВЛФмКмКУЕФРэНтећИіЯюФПЃЌЫљвдЮвЯЃЭћФмаДвЛаЉЮФеТЃЌздЖЅЯђЯТЃЌгЩЧГШыЩюЃЌНВЪі
TiDB ЕФвЛаЉММЪѕдРэЃЌАќРЈгУЛЇПЩМћЕФММЪѕвдМАДѓСПвўВидк SQL НчУцКѓгУЛЇВЛПЩМћЕФММЪѕЕуЁЃ
БЃДцЪ§Он

Ъ§ОнПтзюИљБОЕФЙІФмЪЧФмАбЪ§ОнДцЯТРДЃЌЫљвдЮвУЧДгетРяПЊЪМЁЃ
БЃДцЪ§ОнЕФЗНЗЈКмЖрЃЌзюМђЕЅЕФЗНЗЈЪЧжБНгдкФкДцжаНЈвЛИіЪ§ОнНсЙЙЃЌБЃДцгУЛЇЗЂРДЕФЪ§ОнЁЃБШШчгУвЛИіЪ§зщЃЌУПЕБЪеЕНвЛЬѕЪ§ОнОЭЯђЪ§зщжазЗМгвЛЬѕМЧТМЁЃетИіЗНАИЪЎЗжМђЕЅЃЌФмТњзузюЛљБОЃЌВЂЧвадФмПЯЖЈЛсКмКУЃЌЕЋЪЧГ§ДЫжЎЭтШДЪЧТЉЖДАйГіЃЌЦфжазюДѓЕФЮЪЬтЪЧЪ§ОнЭъШЋдкФкДцжаЃЌвЛЕЉЭЃЛњЛђепЪЧЗўЮёжиЦєЃЌЪ§ОнОЭЛсгРОУЖЊЪЇЁЃ
ЮЊСЫНтОіЪ§ОнЖЊЪЇЮЪЬтЃЌЮвУЧПЩвдАбЪ§ОнЗХдкЗЧвзЪЇДцДЂНщжЪЃЈБШШчгВХЬЃЉжаЁЃИФНјЕФЗНАИЪЧдкДХХЬЩЯДДНЈвЛИіЮФМўЃЌЪеЕНвЛЬѕЪ§ОнЃЌОЭдкЮФМўжа
Append вЛааЁЃOKЃЌЮвУЧЯждкгаСЫвЛИіФмГжОУЛЏДцДЂЪ§ОнЕФЗНАИЁЃЕЋЪЧЛЙВЛЙЛКУЃЌМйЩшетПщДХХЬГіЯжСЫЛЕЕРФиЃПЮвУЧПЩвдзі
RAID ЃЈRedundant Array of Independent DisksЃЉЃЌЬсЙЉЕЅЛњШпгрДцДЂЁЃШчЙћећЬЈЛњЦїЖМЙвСЫФиЃПБШШчГіЯжСЫЛ№джЃЌRAID
вВБЃВЛзЁетаЉЪ§ОнЁЃЮвУЧЛЙПЩвдНЋДцДЂИФгУЭјТчДцДЂЃЌЛђепЪЧЭЈЙ§гВМўЛђепШэМўНјааДцДЂИДжЦЁЃЕНетРяЫЦКѕЮвУЧвбОНтОіСЫЪ§ОнАВШЋЮЪЬтЃЌПЩвдЫЩвЛПкЦјСЫЁЃButЃЌзіИДжЦЙ§ГЬжаЪЧЗёФмБЃжЄИББОжЎМфЕФвЛжТадЃПвВОЭЪЧдкБЃжЄЪ§ОнВЛЖЊЕФЧАЬсЯТЃЌЛЙвЊБЃжЄЪ§ОнВЛДэЁЃБЃжЄЪ§ОнВЛЖЊВЛДэжЛЪЧвЛЯюзюЛљБОЕФвЊЧѓЃЌЛЙгаИќЖрСюШЫЭЗЬлЕФЮЪЬтЕШД§НтОіЃК
ФмЗёжЇГжПчЪ§ОнжааФЕФШнджЃП
аДШыЫйЖШЪЧЗёЙЛПьЃП
Ъ§ОнБЃДцЯТРДКѓЃЌЪЧЗёЗНБуЖСШЁЃП
БЃДцЕФЪ§ОнШчКЮаоИФЃПШчКЮжЇГжВЂЗЂЕФаоИФЃП
ШчКЮдзгЕиаоИФЖрЬѕМЧТМЃП
етаЉЮЪЬтУПвЛЯюЖМЗЧГЃФбЃЌЕЋЪЧвЊзівЛИігХауЕФЪ§ОнДцДЂЯЕЭГЃЌБиаывЊНтОіЩЯЪіЕФУПвЛИіФбЬтЁЃ ЮЊСЫНтОіЪ§ОнДцДЂЮЪЬтЃЌЮвУЧПЊЗЂСЫ
TiKV етИіЯюФПЁЃНгЯТРДЮвЯђДѓМвНщЩмвЛЯТ TiKV ЕФвЛаЉЩшМЦЫМЯыКЭЛљБОИХФюЁЃ
Key-Value
зїЮЊБЃДцЪ§ОнЕФЯЕЭГЃЌЪзЯШвЊОіЖЈЕФЪЧЪ§ОнЕФДцДЂФЃаЭЃЌвВОЭЪЧЪ§ОнвдЪВУДбљЕФаЮЪНБЃДцЯТРДЁЃTiKV ЕФбЁдёЪЧ
Key-Value ФЃаЭЃЌВЂЧвЬсЙЉгаађБщРњЗНЗЈЁЃМђЕЅРДНВЃЌПЩвдНЋ TiKV ПДзівЛИіОоДѓЕФ MapЃЌЦфжа
Key КЭ Value ЖМЪЧдЪМЕФ Byte Ъ§зщЃЌдкетИі Map жаЃЌKey АДее Byte Ъ§зщзмЕФдЪМЖўНјжЦБШЬиЮЛБШНЯЫГађХХСаЁЃ
ДѓМветРяашвЊЖд TiKV МЧзЁСНЕуЃК
етЪЧвЛИіОоДѓЕФ MapЃЌвВОЭЪЧДцДЂЕФЪЧ Key-Value pair
етИі Map жаЕФ Key-Value pair АДее Key ЕФЖўНјжЦЫГађгаађЃЌвВОЭЪЧЮвУЧПЩвд Seek
ЕНФГвЛИі Key ЕФЮЛжУЃЌШЛКѓВЛЖЯЕФЕїгУ Next ЗНЗЈвдЕндіЕФЫГађЛёШЁБШетИі Key ДѓЕФ Key-Value
НВСЫетУДЖрЃЌгаШЫПЩФмЛсЮЪСЫЃЌетРяНВЕФДцДЂФЃаЭКЭ SQL жаБэЪЧЪВУДЙиЯЕЃПдкетРягавЛМўживЊЕФЪТЧщвЊЫЕЫФБщЃК
етРяЕФДцДЂФЃаЭКЭ SQL жаЕФ Table ЮоЙиЃЁ етРяЕФДцДЂФЃаЭКЭ SQL жаЕФ Table ЮоЙиЃЁ
етРяЕФДцДЂФЃаЭКЭ SQL жаЕФ Table ЮоЙиЃЁ етРяЕФДцДЂФЃаЭКЭ SQL жаЕФ Table ЮоЙиЃЁ
ЯждкШУЮвУЧЭќМЧ SQL жаЕФШЮКЮИХФюЃЌзЈзЂгкЬжТлШчКЮЪЕЯж TiKV етбљвЛИіИпадФмИпПЩППадЕФОоДѓЕФЃЈЗжВМЪНЕФЃЉ
MapЁЃ
RocksDB
ШЮКЮГжОУЛЏЕФДцДЂв§ЧцЃЌЪ§ОнжеЙщвЊБЃДцдкДХХЬЩЯЃЌTiKV вВВЛР§ЭтЁЃЕЋЪЧ TiKV УЛгабЁдёжБНгЯђДХХЬЩЯаДЪ§ОнЃЌЖјЪЧАбЪ§ОнБЃДцдк
RocksDB жаЃЌОпЬхЕФЪ§ОнТфЕигЩ RocksDB ИКд№ЁЃетИібЁдёЕФдвђЪЧПЊЗЂвЛИіЕЅЛњДцДЂв§ЧцЙЄзїСПКмДѓЃЌЬиБ№ЪЧвЊзівЛИіИпадФмЕФЕЅЛњв§ЧцЃЌашвЊзіИїжжЯИжТЕФгХЛЏЃЌЖј
RocksDB ЪЧвЛИіЗЧГЃгХауЕФПЊдДЕФЕЅЛњДцДЂв§ЧцЃЌПЩвдТњзуЮвУЧЖдЕЅЛњв§ЧцЕФИїжжвЊЧѓЃЌЖјЧвЛЙга Facebook
ЕФЭХЖгдкзіГжајЕФгХЛЏЃЌетбљЮвУЧжЛЭЖШыКмЩйЕФОЋСІЃЌОЭФмЯэЪмЕНвЛИіЪЎЗжЧПДѓЧвдкВЛЖЯНјВНЕФЕЅЛњв§ЧцЁЃЕБШЛЃЌЮвУЧвВЮЊ
RocksDB ЙБЯзСЫвЛаЉДњТыЃЌЯЃЭћетИіЯюФПФмдНзідНКУЁЃетРяПЩвдМђЕЅЕФШЯЮЊ RocksDB ЪЧвЛИіЕЅЛњЕФ
Key-Value MapЁЃ
Raft
КУСЫЃЌЭђРяГЄеїЕквЛВНвбОТѕГіШЅСЫЃЌЮвУЧвбОЮЊЪ§ОневЕНвЛИіИпаЇПЩППЕФБОЕиДцДЂЗНАИЁЃЫзЛАЫЕЃЌЭђЪТПЊЭЗФбЃЌШЛКѓжаМфФбЃЌзюКѓНсЮВФбЁЃНгЯТРДЮвУЧУцСйвЛМўИќФбЕФЪТЧщЃКШчКЮБЃжЄЕЅЛњЪЇаЇЕФЧщПіЯТЃЌЪ§ОнВЛЖЊЪЇЃЌВЛГіДэЃПМђЕЅРДЫЕЃЌЮвУЧашвЊЯыАьЗЈАбЪ§ОнИДжЦЕНЖрЬЈЛњЦїЩЯЃЌетбљвЛЬЈЛњЦїЙвСЫЃЌЮвУЧЛЙгаЦфЫћЕФЛњЦїЩЯЕФИББОЃЛИДдгРДЫЕЃЌЮвУЧЛЙашвЊетИіИДжЦЗНАИЪЧПЩППЁЂИпаЇВЂЧвФмДІРэИББОЪЇаЇЕФЧщПіЁЃЬ§ЩЯШЅБШНЯФбЃЌЕЋЪЧКУдкЮвУЧга
Raft авщЁЃRaft ЪЧвЛИівЛжТадЫуЗЈЃЌЫќКЭ Paxos ЕШМлЃЌЕЋЪЧИќМгвзгкРэНтЁЃRaft ЕФТлЮФЃЌИааЫШЄЕФПЩвдПДвЛЯТЁЃБОЮФжЛЛсЖд
Raft зівЛИіМђвЊЕФНщЩмЃЌЯИНкЮЪЬтПЩвдВЮПМТлЮФЁЃСэЭтЬсвЛЕуЃЌRaft ТлЮФжЛЪЧвЛИіЛљБОЗНАИЃЌбЯИёАДееТлЮФЪЕЯжЃЌадФмЛсКмВюЃЌЮвУЧЖд
Raft авщЕФЪЕЯжзіСЫДѓСПЕФгХЛЏ.
Raft ЪЧвЛИівЛжТадавщЃЌЬсЙЉМИИіживЊЕФЙІФмЃК
Leader бЁОй
ГЩдББфИќ
ШежОИДжЦ
TiKV РћгУ Raft РДзіЪ§ОнИДжЦЃЌУПИіЪ§ОнБфИќЖМЛсТфЕиЮЊвЛЬѕ Raft ШежОЃЌЭЈЙ§ Raft
ЕФШежОИДжЦЙІФмЃЌНЋЪ§ОнАВШЋПЩППЕиЭЌВНЕН Group ЕФЖрЪ§НкЕужаЁЃ
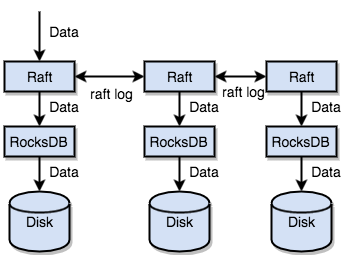
ЕНетРяЮвУЧзмНсвЛЯТЃЌЭЈЙ§ЕЅЛњЕФ RocksDBЃЌЮвУЧПЩвдНЋЪ§ОнПьЫйЕиДцДЂдкДХХЬЩЯЃЛЭЈЙ§ RaftЃЌЮвУЧПЩвдНЋЪ§ОнИДжЦЕНЖрЬЈЛњЦїЩЯЃЌвдЗРЕЅЛњЪЇаЇЁЃЪ§ОнЕФаДШыЪЧЭЈЙ§
Raft етвЛВуЕФНгПкаДШыЃЌЖјВЛЪЧжБНгаД RocksDBЁЃЭЈЙ§ЪЕЯж RaftЃЌЮвУЧгЕгаСЫвЛИіЗжВМЪНЕФ
KVЃЌЯждкдйвВВЛгУЕЃаФФГЬЈЛњЦїЙвЕєСЫЁЃ
Region
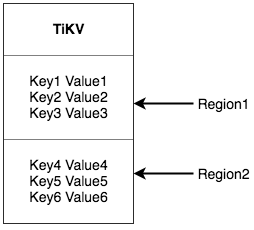
НВЕНетРяЃЌЮвУЧПЩвдЬсЕНвЛИі ЗЧГЃживЊЕФИХФюЃКRegionЁЃетИіИХФюЪЧРэНтКѓајвЛЯЕСаЛњжЦЕФЛљДЁЃЌЧызаЯИдФЖСетвЛНкЁЃ
ЧАУцЬсЕНЃЌЮвУЧНЋ TiKV ПДзівЛИіОоДѓЕФгаађЕФ KV MapЃЌФЧУДЮЊСЫЪЕЯжДцДЂЕФЫЎЦНРЉеЙЃЌЮвУЧашвЊНЋЪ§ОнЗжЩЂдкЖрЬЈЛњЦїЩЯЁЃетРяЬсЕНЕФЪ§ОнЗжЩЂдкЖрЬЈЛњЦїЩЯКЭ
Raft ЕФЪ§ОнИДжЦВЛЪЧвЛИіИХФюЃЌдкетвЛНкЮвУЧЯШЭќМЧ RaftЃЌМйЩшЫљгаЕФЪ§ОнЖМжЛгавЛИіИББОЃЌетбљИќШнвзРэНтЁЃ
ЖдгквЛИі KV ЯЕЭГЃЌНЋЪ§ОнЗжЩЂдкЖрЬЈЛњЦїЩЯгаСНжжБШНЯЕфаЭЕФЗНАИЃКвЛжжЪЧАДее Key зі HashЃЌИљОн
Hash жЕбЁдёЖдгІЕФДцДЂНкЕуЃЛСэвЛжжЪЧЗж RangeЃЌФГвЛЖЮСЌајЕФ Key ЖМБЃДцдквЛИіДцДЂНкЕуЩЯЁЃTiKV
бЁдёСЫЕкЖўжжЗНЪНЃЌНЋећИі Key-Value ПеМфЗжГЩКмЖрЖЮЃЌУПвЛЖЮЪЧвЛЯЕСаСЌајЕФ KeyЃЌЮвУЧНЋУПвЛЖЮНазівЛИі
RegionЃЌВЂЧвЮвУЧЛсОЁСПБЃГжУПИі Region жаБЃДцЕФЪ§ОнВЛГЌЙ§вЛЖЈЕФДѓаЁ(етИіДѓаЁПЩвдХфжУЃЌФПЧАФЌШЯЪЧ
64mb)ЁЃУПвЛИі Region ЖМПЩвдгУ StartKey ЕН EndKey етбљвЛИізѓБегвПЊЧјМфРДУшЪіЁЃ
зЂвтЃЌетРяЕФ Region ЛЙЪЧКЭ SQL жаЕФБэУЛЪВУДЙиЯЕЃЁ ЧыИїЮЛМЬајЭќМЧ SQLЃЌжЛЬИ KVЁЃ
НЋЪ§ОнЛЎЗжГЩ Region КѓЃЌЮвУЧНЋЛсзі СНМўживЊЕФЪТЧщЃК
вд Region ЮЊЕЅЮЛЃЌНЋЪ§ОнЗжЩЂдкМЏШКжаЫљгаЕФНкЕуЩЯЃЌВЂЧвОЁСПБЃжЄУПИіНкЕуЩЯЗўЮёЕФ Region
Ъ§СПВюВЛЖр
вд Region ЮЊЕЅЮЛзі Raft ЕФИДжЦКЭГЩдБЙмРэ
етСНЕуЗЧГЃживЊЃЌЮвУЧвЛЕувЛЕуРДЫЕЁЃ
ЯШПДЕквЛЕуЃЌЪ§ОнАДее Key ЧаЗжГЩКмЖр RegionЃЌУПИі Region ЕФЪ§ОнжЛЛсБЃДцдквЛИіНкЕуЩЯУцЁЃЮвУЧЕФЯЕЭГЛсгавЛИізщМўРДИКд№НЋ
Region ОЁПЩФмОљдШЕФЩЂВМдкМЏШКжаЫљгаЕФНкЕуЩЯЃЌетбљвЛЗНУцЪЕЯжСЫДцДЂШнСПЕФЫЎЦНРЉеЙЃЈдіМгаТЕФНсЕуКѓЃЌЛсздЖЏНЋЦфЫћНкЕуЩЯЕФ
Region ЕїЖШЙ§РДЃЉЃЌСэвЛЗНУцвВЪЕЯжСЫИКдиОљКтЃЈВЛЛсГіЯжФГИіНкЕугаКмЖрЪ§ОнЃЌЦфЫћНкЕуЩЯУЛЪВУДЪ§ОнЕФЧщПіЃЉЁЃЭЌЪБЮЊСЫБЃжЄЩЯВуПЭЛЇЖЫФмЙЛЗУЮЪЫљашвЊЕФЪ§ОнЃЌЮвУЧЕФЯЕЭГжавВЛсгавЛИізщМўМЧТМ
Region дкНкЕуЩЯУцЕФЗжВМЧщПіЃЌвВОЭЪЧЭЈЙ§ШЮвтвЛИі Key ОЭФмВщбЏЕНетИі Key дкФФИі Region
жаЃЌвдМАетИі Region ФПЧАдкФФИіНкЕуЩЯЁЃжСгкЪЧФФИізщМўИКд№етСНЯюЙЄзїЃЌЛсдкКѓајНщЩмЁЃ
ЖдгкЕкЖўЕуЃЌTiKV ЪЧвд Region ЮЊЕЅЮЛзіЪ§ОнЕФИДжЦЃЌвВОЭЪЧвЛИі Region ЕФЪ§ОнЛсБЃДцЖрИіИББОЃЌЮвУЧНЋУПвЛИіИББОНазівЛИі
ReplicaЁЃReplica жЎМфЪЧЭЈЙ§ Raft РДБЃГжЪ§ОнЕФвЛжТЃЈжегкЬсЕНСЫ RaftЃЉЃЌвЛИі
Region ЕФЖрИі Replica ЛсБЃДцдкВЛЭЌЕФНкЕуЩЯЃЌЙЙГЩвЛИі Raft GroupЁЃЦфжавЛИі
Replica ЛсзїЮЊетИі Group ЕФ LeaderЃЌЦфЫћЕФ Replica зїЮЊ FollowerЁЃЫљгаЕФЖСКЭаДЖМЪЧЭЈЙ§
Leader НјааЃЌдйгЩ Leader ИДжЦИј FollowerЁЃ ДѓМвРэНтСЫ Region жЎКѓЃЌгІИУПЩвдРэНтЯТУцетеХЭМЃК
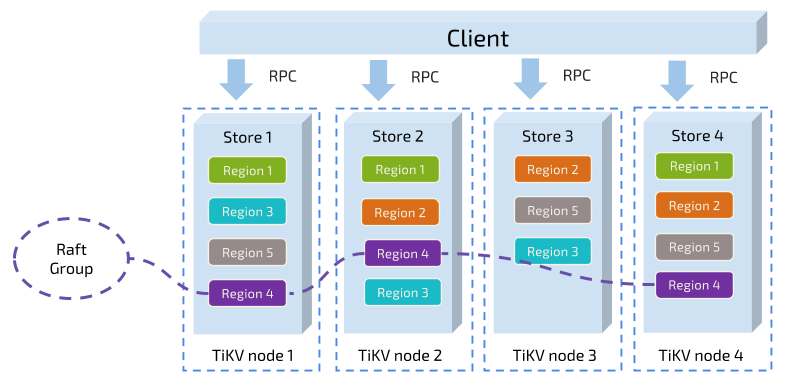
ЮвУЧвд Region ЮЊЕЅЮЛзіЪ§ОнЕФЗжЩЂКЭИДжЦЃЌОЭгаСЫвЛИіЗжВМЪНЕФОпБИвЛЖЈШнджФмСІЕФ KeyValue
ЯЕЭГЃЌВЛгУдйЕЃаФЪ§ОнДцВЛЯТЃЌЛђепЪЧДХХЬЙЪеЯЖЊЪЇЪ§ОнЕФЮЪЬтЁЃетвбОКм CoolЃЌЕЋЪЧЛЙВЛЙЛЭъУРЃЌЮвУЧашвЊИќЖрЕФЙІФмЁЃ
MVCC
КмЖрЪ§ОнПтЖМЛсЪЕЯжЖрАцБОПижЦЃЈMVCCЃЉЃЌTiKV вВВЛР§ЭтЁЃЩшЯыетбљЕФГЁОАЃЌСНИі Client ЭЌЪБШЅаоИФвЛИі
Key ЕФ ValueЃЌШчЙћУЛга MVCCЃЌОЭашвЊЖдЪ§ОнЩЯЫјЃЌдкЗжВМЪНГЁОАЯТЃЌПЩФмЛсДјРДадФмвдМАЫРЫјЮЪЬтЁЃ
TiKV ЕФ MVCC ЪЕЯжЪЧЭЈЙ§дк Key КѓУцЬэМг Version РДЪЕЯжЃЌМђЕЅРДЫЕЃЌУЛга MVCC
жЎЧАЃЌПЩвдАб TiKV ПДзіетбљЕФЃК
Key1 -> Value
Key2 -> Value
ЁЁ
KeyN -> Value |
гаСЫ MVCC жЎКѓЃЌTiKV ЕФ Key ХХСаЪЧетбљЕФЃК
Key1-Version3
-> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
ЁЁ
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
ЁЁ
KeyN-Version2 -> Value
KeyN-Version1 -> Value
ЁЁ |
зЂвтЃЌЖдгкЭЌвЛИі Key ЕФЖрИіАцБОЃЌЮвУЧАбАцБОКХНЯДѓЕФЗХдкЧАУцЃЌАцБОКХаЁЕФЗХдкКѓУцЃЈЛивфвЛЯТ Key-Value
вЛНкЮвУЧНщЩмЙ§ЕФ Key ЪЧгаађЕФХХСаЃЉЃЌетбљЕБгУЛЇЭЈЙ§вЛИі Key + Version РДЛёШЁ Value
ЕФЪБКђЃЌПЩвдНЋ Key КЭ Version ЙЙдьГі MVCC ЕФ KeyЃЌвВОЭЪЧ Key-VersionЁЃШЛКѓПЩвджБНг
Seek(Key-Version)ЃЌЖЈЮЛЕНЕквЛИіДѓгкЕШгкетИі Key-Version ЕФЮЛжУЁЃ
ЪТЮё
TiKV ЕФЪТЮёВЩгУЕФЪЧ Percolator ФЃаЭЃЌВЂЧвзіСЫДѓСПЕФгХЛЏЁЃЪТЮёЕФЯИНкетРяВЛЯъЪіЃЌДѓМвПЩвдВЮПМТлЮФвдМАЮвУЧЕФЦфЫћЮФеТЁЃетРяжЛЬсвЛЕуЃЌTiKV
ЕФЪТЮёВЩгУРжЙлЫјЃЌЪТЮёЕФжДааЙ§ГЬжаЃЌВЛЛсМьВтаДаДГхЭЛЃЌжЛгадкЬсНЛЙ§ГЬжаЃЌВХЛсзіГхЭЛМьВтЃЌГхЭЛЕФЫЋЗНжаБШНЯдчЭъГЩЬсНЛЕФЛсаДШыГЩЙІЃЌСэвЛЗНЛсГЂЪджиаТжДааећИіЪТЮёЁЃЕБвЕЮёЕФаДШыГхЭЛВЛбЯжиЕФЧщПіЯТЃЌетжжФЃаЭадФмЛсКмКУЃЌБШШчЫцЛњИќаТБэжаФГвЛааЕФЪ§ОнЃЌВЂЧвБэКмДѓЁЃЕЋЪЧШчЙћвЕЮёЕФаДШыГхЭЛбЯжиЃЌадФмОЭЛсКмВюЃЌОйвЛИіМЋЖЫЕФР§згЃЌОЭЪЧМЦЪ§ЦїЃЌЖрИіПЭЛЇЖЫЭЌЪБаоИФЩйСПааЃЌЕМжТГхЭЛбЯжиЕФЃЌдьГЩДѓСПЕФЮоаЇжиЪдЁЃ
ЦфЫћ
ЕНетРяЃЌЮвУЧвбОСЫНтСЫ TiKV ЕФЛљБОИХФюКЭвЛаЉЯИНкЃЌРэНтСЫетИіЗжВМЪНДјЪТЮёЕФ KV в§ЧцЕФЗжВуНсЙЙвдМАШчКЮЪЕЯжЖрИББОШнДэЁЃЯТвЛНкЛсНщЩмШчКЮдк
KV ЕФДцДЂФЃаЭжЎЩЯЃЌЙЙНЈ SQL ВуЁЃ
ЙиЯЕФЃаЭЕН Key-Value ФЃаЭЕФгГЩф
дкетЮвУЧНЋЙиЯЕФЃаЭМђЕЅРэНтЮЊ Table КЭ SQL гяОфЃЌФЧУДЮЪЬтБфЮЊШчКЮдк
KV НсЙЙЩЯБЃДц Table вдМАШчКЮдк KV НсЙЙЩЯдЫаа SQL гяОфЁЃ МйЩшЮвУЧгаетбљвЛИіБэЕФЖЈвхЃК
CREATE TABLE
User {
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
Key idxAge (age)
}; |
SQL КЭ KV НсЙЙжЎМфДцдкОоДѓЕФЧјБ№ЃЌФЧУДШчКЮФмЙЛЗНБуИпаЇЕиНјаагГЩфЃЌОЭГЩЮЊвЛИіКмживЊЕФЮЪЬтЁЃвЛИіКУЕФгГЩфЗНАИБиаыгаРћгкЖдЪ§ОнВйзїЕФашЧѓЁЃФЧУДЮвУЧЯШПДвЛЯТЖдЪ§ОнЕФВйзїгаФФаЉашЧѓЃЌЗжБ№гаФФаЉЬиЕуЁЃ
ЖдгквЛИі Table РДЫЕЃЌашвЊДцДЂЕФЪ§ОнАќРЈШ§ВПЗжЃК
БэЕФдЊаХЯЂ
Table жаЕФ Row
Ыїв§Ъ§Он
БэЕФдЊаХЯЂЮвУЧднЪБВЛЬжТлЃЌЛсгазЈУХЕФеТНкРДНщЩмЁЃ Ждгк RowЃЌПЩвдбЁдёааДцЛђепСаДцЃЌетСНжжИїгагХШБЕуЁЃTiDB
УцЯђЕФЪзвЊФПБъЪЧ OLTP вЕЮёЃЌетРрвЕЮёашвЊжЇГжПьЫйЕиЖСШЁЁЂБЃДцЁЂаоИФЁЂЩОГ§вЛааЪ§ОнЃЌЫљвдВЩгУааДцЪЧБШНЯКЯЪЪЕФЁЃ
Ждгк IndexЃЌTiDB ВЛжЙашвЊжЇГж Primary IndexЃЌЛЙашвЊжЇГж Secondary
IndexЁЃIndex ЕФзїгУЕФИЈжњВщбЏЃЌЬсЩ§ВщбЏадФмЃЌвдМАБЃжЄФГаЉ ConstraintЁЃВщбЏЕФЪБКђгаСНжжФЃЪНЃЌвЛжжЪЧЕуВщЃЌБШШчЭЈЙ§
Primary Key Лђеп Unique Key ЕФЕШжЕЬѕМўНјааВщбЏЃЌШч select name
from user where id=1; ЃЌетжжашвЊЭЈЙ§Ыїв§ПьЫйЖЈЮЛЕНФГвЛааЪ§ОнЃЛСэвЛжжЪЧ Range
ВщбЏЃЌШч select name from user where age > 30 and age
< 35;ЃЌетИіЪБКђашвЊЭЈЙ§idxAgeЫїв§ВщбЏ age дк 30 КЭ 35 жЎМфЕФФЧаЉЪ§ОнЁЃIndex
ЛЙЗжЮЊ Unique Index КЭ ЗЧ Unique IndexЃЌетСНжжЖМашвЊжЇГжЁЃ
ЗжЮіЭъашвЊДцДЂЕФЪ§ОнЕФЬиЕуЃЌЮвУЧдйПДПДЖдетаЉЪ§ОнЕФВйзїашЧѓЃЌжївЊПМТЧ Insert/Update/Delete/Select
етЫФжжгяОфЁЃ
Ждгк Insert гяОфЃЌашвЊНЋ Row аДШы KVЃЌВЂЧвНЈСЂКУЫїв§Ъ§ОнЁЃ
Ждгк Update гяОфЃЌашвЊНЋ Row ИќаТЕФЭЌЪБЃЌИќаТЫїв§Ъ§ОнЃЈШчЙћгаБивЊЃЉЁЃ
Ждгк Delete гяОфЃЌашвЊдкЩОГ§ Row ЕФЭЌЪБЃЌНЋЫїв§вВЩОГ§ЁЃ
ЩЯУцШ§ИігяОфДІРэЦ№РДЖМКмМђЕЅЁЃЖдгк Select гяОфЃЌЧщПіЛсИДдгвЛаЉЁЃЪзЯШЮвУЧашвЊФмЙЛМђЕЅПьЫйЕиЖСШЁвЛааЪ§ОнЃЌЫљвдУПИі
Row ашвЊгавЛИі ID ЃЈЯдЪОЛђвўЪНЕФ IDЃЉЁЃЦфДЮПЩФмЛсЖСШЁСЌајЖрааЪ§ОнЃЌБШШч Select *
from user;ЁЃзюКѓЛЙгаЭЈЙ§Ыїв§ЖСШЁЪ§ОнЕФашЧѓЃЌЖдЫїв§ЕФЪЙгУПЩФмЪЧЕуВщЛђепЪЧЗЖЮЇВщбЏЁЃ
ДѓжТЕФашЧѓвбОЗжЮіЭъСЫЃЌЯждкШУЮвУЧПДПДЪжРягаЪВУДПЩвдгУЕФЃКвЛИіШЋОжгаађЕФЗжВМЪН Key-Value
в§ЧцЁЃШЋОжгаађетвЛЕуживЊЃЌПЩвдАяжњЮвУЧНтОіВЛЩйЮЪЬтЁЃБШШчЖдгкПьЫйЛёШЁвЛааЪ§ОнЃЌМйЩшЮвУЧФмЙЛЙЙдьГіФГвЛИіЛђепФГМИИі
KeyЃЌЖЈЮЛЕНетвЛааЃЌЮвУЧОЭФмРћгУ TiKV ЬсЙЉЕФ Seek ЗНЗЈПьЫйЖЈЮЛЕНетвЛааЪ§ОнЫљдкЮЛжУЁЃдйБШШчЖдгкЩЈУшШЋБэЕФашЧѓЃЌШчЙћФмЙЛгГЩфЮЊвЛИі
Key ЕФ RangeЃЌДг StartKey ЩЈУшЕН EndKeyЃЌФЧУДОЭПЩвдМђЕЅЕФЭЈЙ§етжжЗНЪНЛёЕУШЋБэЪ§ОнЁЃВйзї
Index Ъ§ОнвВЪЧРрЫЦЕФЫМТЗЁЃНгЯТРДШУЮвУЧПДПД TiDB ЪЧШчКЮзіЕФЁЃ
TiDB ЖдУПИіБэЗжХфвЛИі TableIDЃЌУПвЛИіЫїв§ЖМЛсЗжХфвЛИі IndexIDЃЌУПвЛааЗжХфвЛИі
RowIDЃЈШчЙћБэгаећЪ§аЭЕФ Primary KeyЃЌФЧУДЛсгУ Primary Key ЕФжЕЕБзі RowIDЃЉЃЌЦфжа
TableID дкећИіМЏШКФкЮЈвЛЃЌIndexID/RowID дкБэФкЮЈвЛЃЌетаЉ ID ЖМЪЧ int64
РраЭЁЃ
УПааЪ§ОнАДееШчЯТЙцдђНјааБрТыГЩ Key-Value pairЃК
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4] |
Цфжа Key ЕФ tablePrefix/recordPrefixSep ЖМЪЧЬиЖЈЕФзжЗћДЎГЃСПЃЌгУгкдк
KV ПеМфФкЧјЗжЦфЫћЪ§ОнЁЃ
Ждгк Index Ъ§ОнЃЌЛсАДееШчЯТЙцдђБрТыГЩ Key-Value pairЃК
Key: tablePrefix{tableID}_indexPrefixSep
{indexID}_indexedColumnsValue
Value: rowID |
Index Ъ§ОнЛЙашвЊПМТЧ Unique Index КЭЗЧ Unique
Index СНжжЧщПіЃЌЖдгк Unique IndexЃЌПЩвдАДееЩЯЪіБрТыЙцдђЁЃЕЋЪЧЖдгкЗЧ Unique
IndexЃЌЭЈЙ§етжжБрТыВЂВЛФмЙЙдьГіЮЈвЛЕФ KeyЃЌвђЮЊЭЌвЛИі Index ЕФ tablePrefix{tableID}_indexPrefixSep{indexID}
ЖМвЛбљЃЌПЩФмгаЖрааЪ§ОнЕФ ColumnsValue ЪЧвЛбљЕФЃЌЫљвдЖдгкЗЧ Unique Index
ЕФБрТызіСЫвЛЕуЕїећЃК
Key: tablePrefix{tableID}_indexPrefixSep
{indexID}_indexedColumnsValue_rowID
Value: null |
етбљФмЙЛЖдЫїв§жаЕФУПааЪ§ОнЙЙдьГіЮЈвЛЕФ KeyЁЃ зЂвтЩЯЪіБрТыЙцдђжаЕФ
Key РяУцЕФИїжж xxPrefix ЖМЪЧзжЗћДЎГЃСПЃЌзїгУЖМЪЧЧјЗжУќУћПеМфЃЌвдУтВЛЭЌРраЭЕФЪ§ОнжЎМфЯрЛЅГхЭЛЃЌЖЈвхШчЯТЃК
var(
tablePrefix = []byte{'t'}
recordPrefixSep = []byte("_r")
indexPrefixSep = []byte("_i")
) |
СэЭтЧыДѓМвзЂвтЃЌЩЯЪіЗНАИжаЃЌЮоТлЪЧ Row ЛЙЪЧ Index ЕФ Key БрТыЗНАИЃЌвЛИі Table
ФкВПЫљгаЕФ Row ЖМгаЯрЭЌЕФЧАзКЃЌвЛИі Index ЕФЪ§ОнвВЖМгаЯрЭЌЕФЧАзКЁЃетбљОпЬхЯрЭЌЕФЧАзКЕФЪ§ОнЃЌдк
TiKV ЕФ Key ПеМфФкЃЌЪЧХХСадквЛЦ№ЁЃЭЌЪБжЛвЊЮвУЧаЁаФЕиЩшМЦКѓзКВПЗжЕФБрТыЗНАИЃЌБЃжЄБрТыЧАКЭБрТыКѓЕФБШНЯЙиЯЕВЛБфЃЌФЧУДОЭПЩвдНЋ
Row Лђеп Index Ъ§ОнгаађЕиБЃДцдк TiKV жаЁЃетжжБЃжЄБрТыЧАКЭБрТыКѓЕФБШНЯЙиЯЕВЛБф ЕФЗНАИЮвУЧГЦЮЊ
MemcomparableЃЌЖдгкШЮКЮРраЭЕФжЕЃЌСНИіЖдЯѓБрТыЧАЕФдЪМРраЭБШНЯНсЙћЃЌКЭБрТыГЩ byte
Ъ§зщКѓЃЈзЂвтЃЌTiKV жаЕФ Key КЭ Value ЖМЪЧдЪМЕФ byte Ъ§зщЃЉЕФБШНЯНсЙћБЃГжвЛжТЁЃОпЬхЕФБрТыЗНАИВЮМћ
TiDB ЕФ codec АќЁЃВЩгУетжжБрТыКѓЃЌвЛИіБэЕФЫљга Row Ъ§ОнОЭЛсАДее RowID ЕФЫГађХХСадк
TiKV ЕФ Key ПеМфжаЃЌФГвЛИі Index ЕФЪ§ОнвВЛсАДее Index ЕФ ColumnValue
ЫГађХХСадк Key ПеМфФкЁЃ
ЯждкЮвУЧНсКЯПЊЪМЬсЕНЕФашЧѓвдМА TiDB ЕФгГЩфЗНАИРДПДвЛЯТЃЌетИіЗНАИЪЧЗёФмТњзуашЧѓЁЃЪзЯШЮвУЧЭЈЙ§етИігГЩфЗНАИЃЌНЋ
Row КЭ Index Ъ§ОнЖМзЊЛЛЮЊ Key-Value Ъ§ОнЃЌЧвУПвЛааЁЂУПвЛЬѕЫїв§Ъ§ОнЖМЪЧгаЮЈвЛЕФ
KeyЁЃЦфДЮЃЌетжжгГЩфЗНАИЖдгкЕуВщЁЂЗЖЮЇВщбЏЖМКмгбКУЃЌЮвУЧПЩвдКмШнвзЕиЙЙдьГіФГааЁЂФГЬѕЫїв§ЫљЖдгІЕФ
KeyЃЌЛђепЪЧФГвЛПщЯрСкЕФааЁЂЯрСкЕФЫїв§жЕЫљЖдгІЕФ Key ЗЖЮЇЁЃзюКѓЃЌдкБЃжЄБэжаЕФвЛаЉ Constraint
ЕФЪБКђЃЌПЩвдЭЈЙ§ЙЙдьВЂМьВщФГИі Key ЪЧЗёДцдкРДХаЖЯЪЧЗёФмЙЛТњзуЯргІЕФ ConstraintЁЃ
жСДЫЮвУЧвбОСФЭъСЫШчКЮНЋ Table гГЩфЕН KV ЩЯУцЃЌетРядйОйИіМђЕЅЕФР§згЃЌБугкДѓМвРэНтЃЌЛЙЪЧвдЩЯУцЕФБэНсЙЙЮЊР§ЁЃМйЩшБэжага
3 ааЪ§ОнЃК
1, "TiDB",
"SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30 |
ФЧУДЪзЯШУПааЪ§ОнЖМЛсгГЩфЮЊвЛИі Key-Value pairЃЌзЂвтетИіБэгавЛИі
Int РраЭЕФ Primary KeyЃЌЫљвд RowID ЕФжЕМДЮЊетИі Primary Key ЕФжЕЁЃМйЩшетИіБэЕФ
Table ID ЮЊ 10ЃЌЦф Row ЕФЪ§ОнЮЊЃК
t10_r1 -->
["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine",
20]
t10_r3 --> ["PD", "Manager",
30] |
Г§СЫ Primary Key жЎЭтЃЌетИіБэЛЙгавЛИі IndexЃЌМйЩшетИі
Index ЕФ ID ЮЊ 1ЃЌдђЦфЪ§ОнЮЊЃК
t10_i1_10_1
--> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null |
ДѓМвПЩвдНсКЯЩЯУцЕФБрТыЙцдђРДРэНтетИіР§згЃЌЯЃЭћДѓМвФмРэНтЮвУЧЮЊЪВУДбЁдёСЫетИігГЩфЗНАИЃЌетбљзіЕФФПЕФЪЧЪВУДЁЃ
дЊаХЯЂЙмРэ
ЩЯНкНщЩмСЫБэжаЕФЪ§ОнКЭЫїв§ЪЧШчКЮгГЩфЮЊ KVЃЌБОНкНщЩмвЛЯТдЊаХЯЂЕФДцДЂЁЃDatabase/Table
ЖМгадЊаХЯЂЃЌвВОЭЪЧЦфЖЈвхвдМАИїЯюЪєадЃЌетаЉаХЯЂвВашвЊГжОУЛЏЃЌЮвУЧвВНЋетаЉаХЯЂДцДЂдк TiKV жаЁЃУПИі
Database/Table ЖМБЛЗжХфСЫвЛИіЮЈвЛЕФ IDЃЌетИі ID зїЮЊЮЈвЛБъЪЖЃЌВЂЧвдкБрТыЮЊ Key-Value
ЪБЃЌетИі ID ЖМЛсБрТыЕН Key жаЃЌдйМгЩЯ m_ ЧАзКЁЃетбљПЩвдЙЙдьГівЛИі KeyЃЌValue
жаДцДЂЕФЪЧађСаЛЏКѓЕФдЊаХЯЂЁЃ Г§ДЫжЎЭтЃЌЛЙгавЛИізЈУХЕФ Key-Value ДцДЂЕБЧА Schema
аХЯЂЕФАцБОЁЃTiDB ЪЙгУ Google F1 ЕФ Online Schema БфИќЫуЗЈЃЌгавЛИіКѓЬЈЯпГЬдкВЛЖЯЕФМьВщ
TiKV ЩЯУцДцДЂЕФ Schema АцБОЪЧЗёЗЂЩњБфЛЏЃЌВЂЧвБЃжЄдквЛЖЈЪБМфФквЛЖЈФмЙЛЛёШЁАцБОЕФБфЛЏЃЈШчЙћШЗЪЕЗЂЩњСЫБфЛЏЃЉЁЃ
SQL on KV МмЙЙ
TiDB ЕФећЬхМмЙЙШчЯТЭМЫљЪО
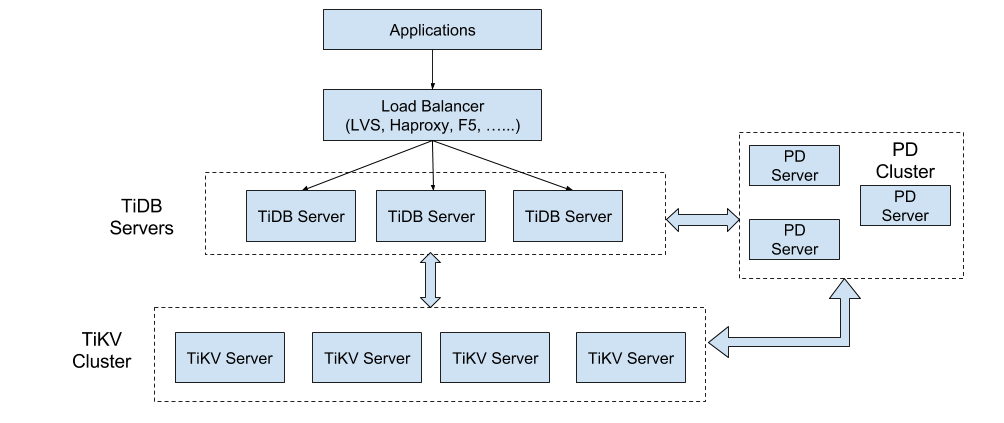
TiKV Cluster жївЊзїгУЪЧзїЮЊ KV в§ЧцДцДЂЪ§ОнЃЌЩЯУцвбОНщЩмЙ§СЫЯИНкЃЌетРяВЛдйЗѓЪіЁЃБОДЮжївЊНщЩм
SQL ВуЃЌвВОЭЪЧ TiDB Servers етвЛВуЃЌетвЛВуЕФНкЕуЖМЪЧЮозДЬЌЕФНкЕуЃЌБОЩэВЂВЛДцДЂЪ§ОнЃЌНкЕужЎМфЭъШЋЖдЕШЁЃTiDB
Server етвЛВузюживЊЕФЙЄзїЪЧДІРэгУЛЇЧыЧѓЃЌжДаа SQL дЫЫуТпМЃЌНгЯТРДЮвУЧзівЛаЉМђЕЅЕФНщЩмЁЃ
SQL дЫЫу
РэНтСЫ SQL ЕН KV ЕФгГЩфЗНАИжЎКѓЃЌЮвУЧПЩвдРэНтЙиЯЕЪ§ОнЪЧШчКЮБЃДцЕФЃЌНгЯТРДЮвУЧвЊРэНтШчКЮЪЙгУетаЉЪ§ОнРДТњзугУЛЇЕФВщбЏашЧѓЃЌвВОЭЪЧвЛИіВщбЏгяОфЪЧШчКЮВйзїЕзВуДцДЂЕФЪ§ОнЁЃ
ФмЯыЕНЕФзюМђЕЅЕФЗНАИОЭЪЧЭЈЙ§ЩЯвЛНкЫљЪіЕФгГЩфЗНАИЃЌНЋ SQL ВщбЏгГЩфЮЊЖд KV ЕФВщбЏЃЌдйЭЈЙ§ KV
НгПкЛёШЁЖдгІЕФЪ§ОнЃЌзюКѓжДааИїжжМЦЫуЁЃ БШШч Select count(*) from user where
name="TiDB"; етбљвЛИігяОфЃЌЮвУЧашвЊЖСШЁБэжаЫљгаЕФЪ§ОнЃЌШЛКѓМьВщ Name
зжЖЮЪЧЗёЪЧ TiDBЃЌШчЙћЪЧЕФЛАЃЌдђЗЕЛиетвЛааЁЃетбљвЛИіВйзїСїГЬзЊЛЛЮЊ KV ВйзїСїГЬЃК
ЙЙдьГі Key RangeЃКвЛИіБэжаЫљгаЕФ RowID ЖМдк [0, MaxInt64) етИіЗЖЮЇФкЃЌФЧУДЮвУЧгУ
0 КЭ MaxInt64 ИљОн Row ЕФ Key БрТыЙцдђЃЌОЭФмЙЙдьГівЛИі [StartKey,
EndKey) ЕФзѓБегвПЊЧјМф
ЩЈУш Key RangeЃКИљОнЩЯУцЙЙдьГіЕФ Key RangeЃЌЖСШЁ TiKV жаЕФЪ§Он
Й§ТЫЪ§ОнЃКЖдгкЖСЕНЕФУПвЛааЪ§ОнЃЌМЦЫу name="TiDB" етИіБэДяЪНЃЌШчЙћЮЊецЃЌдђЯђЩЯЗЕЛиетвЛааЃЌЗёдђЖЊЦњетвЛааЪ§Он
МЦЫу CountЃКЖдЗћКЯвЊЧѓЕФУПвЛааЃЌРлМЦЕН Count жЕЩЯУц етИіЗНАИПЯЖЈЪЧПЩвд Work ЕФЃЌЕЋЪЧВЂВЛФм
Work ЕФКмКУЃЌдвђЪЧЯдЖјвзМћЕФЃК
дкЩЈУшЪ§ОнЕФЪБКђЃЌУПвЛааЖМвЊЭЈЙ§ KV ВйзїЭЌ TiKV жаЖСШЁГіРДЃЌжСЩйгавЛДЮ RPC ПЊЯњЃЌШчЙћашвЊЩЈУшЕФЪ§ОнКмЖрЃЌФЧУДетИіПЊЯњЛсЗЧГЃДѓ
ВЂВЛЪЧЫљгаЕФааЖМгагУЃЌШчЙћВЛТњзуЬѕМўЃЌЦфЪЕПЩвдВЛЖСШЁГіРД
ЗћКЯвЊЧѓЕФааЕФжЕВЂУЛгаЪВУДвтвхЃЌЪЕМЪЩЯетРяжЛашвЊгаМИааЪ§ОнетИіаХЯЂОЭаа
ЗжВМЪН SQL дЫЫу
ШчКЮБмУтЩЯЪіШБЯнвВЪЧЯдЖјвзМћЕФЃЌЪзЯШЮвУЧашвЊНЋМЦЫуОЁСПППНќДцДЂНкЕуЃЌвдБмУтДѓСПЕФ RPC ЕїгУЁЃЦфДЮЃЌЮвУЧашвЊНЋ
Filter вВЯТЭЦЕНДцДЂНкЕуНјааМЦЫуЃЌетбљжЛашвЊЗЕЛигааЇЕФааЃЌБмУтЮовтвхЕФЭјТчДЋЪфЁЃзюКѓЃЌЮвУЧПЩвдНЋОлКЯКЏЪ§ЁЂGroupBy
вВЯТЭЦЕНДцДЂНкЕуЃЌНјаадЄОлКЯЃЌУПИіНкЕужЛашвЊЗЕЛивЛИі Count жЕМДПЩЃЌдйгЩ tidb-server
НЋ Count жЕ Sum Ц№РДЁЃ етРягавЛИіЪ§Онж№ВуЗЕЛиЕФЪОвтЭМЃК
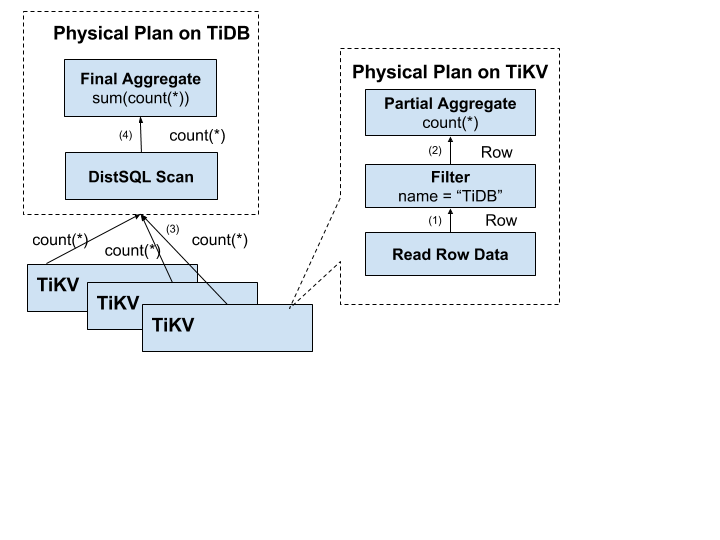
SQL ВуМмЙЙ
ЩЯУцМИНкМђвЊНщЩмСЫ SQL ВуЕФвЛаЉЙІФмЃЌЯЃЭћДѓМвЖд SQL гяОфЕФДІРэгавЛИіЛљБОЕФСЫНтЁЃЪЕМЪЩЯ TiDB
ЕФ SQL ВувЊИДдгЕФЖрЃЌФЃПщвдМАВуДЮЗЧГЃЖрЃЌЯТУцетИіЭМСаГіСЫживЊЕФФЃПщвдМАЕїгУЙиЯЕЃК

гУЛЇЕФ SQL ЧыЧѓЛсжБНгЛђепЭЈЙ§ Load Balancer ЗЂЫЭЕН tidb-serverЃЌtidb-server
ЛсНтЮі MySQL Protocol PacketЃЌЛёШЁЧыЧѓФкШнЃЌШЛКѓзігяЗЈНтЮіЁЂВщбЏМЦЛЎжЦЖЈКЭгХЛЏЁЂжДааВщбЏМЦЛЎЛёШЁКЭДІРэЪ§ОнЁЃЪ§ОнШЋВПДцДЂдк
TiKV МЏШКжаЃЌЫљвддкетИіЙ§ГЬжа tidb-server ашвЊКЭ tikv-server НЛЛЅЃЌЛёШЁЪ§ОнЁЃзюКѓ
tidb-server ашвЊНЋВщбЏНсЙћЗЕЛиИјгУЛЇЁЃ
аЁНс
ЕНетРяЃЌЮвУЧвбОДг SQL ЕФНЧЖШСЫНтСЫЪ§ОнЪЧШчКЮДцДЂЃЌШчКЮгУгкМЦЫуЁЃSQL ВуИќЯъЯИЕФНщЩмЛсдкНёКѓЕФЮФеТжаИјГіЃЌБШШчгХЛЏЦїЕФЙЄзїдРэЃЌЗжВМЪНжДааПђМмЕФЯИНкЁЃ
ЯТвЛЦЊЮФеТЮвУЧНЋЛсНщЩмвЛаЉЙигк PD ЕФаХЯЂЃЌетВПЗжЛсБШНЯгавтЫМЃЌРяУцЕФКмЖрЖЋЮїЪЧдкЪЙгУ TiDB
Й§ГЬжаПДВЛЕНЃЌЕЋЪЧЖдећЬхМЏШКгжЗЧГЃживЊЁЃжївЊЛсЩцМАЕНМЏШКЕФЙмРэКЭЕїЖШЁЃ
ЮЊЪВУДвЊНјааЕїЖШ
ЯШЛивфвЛЯТЩЯУцДцДЂЬсЕНЕФвЛаЉаХЯЂЃЌTiKV МЏШКЪЧ TiDB Ъ§ОнПтЕФЗжВМЪН
KV ДцДЂв§ЧцЃЌЪ§Онвд Region ЮЊЕЅЮЛНјааИДжЦКЭЙмРэЃЌУПИі Region ЛсгаЖрИі ReplicaЃЈИББОЃЉЃЌетаЉ
Replica ЛсЗжВМдкВЛЭЌЕФ TiKV НкЕуЩЯЃЌЦфжа Leader ИКд№ЖС/аДЃЌFollower
ИКд№ЭЌВН Leader ЗЂРДЕФ raft logЁЃСЫНтСЫетаЉаХЯЂКѓЃЌЧыЫМПМЯТУцетаЉЮЪЬтЃК
ШчКЮБЃжЄЭЌвЛИі Region ЕФЖрИі Replica ЗжВМдкВЛЭЌЕФНкЕуЩЯЃПИќНјвЛВНЃЌШчЙћдквЛЬЈЛњЦїЩЯЦєЖЏЖрИі
TiKV ЪЕР§ЃЌЛсгаЪВУДЮЪЬтЃП
TiKV МЏШКНјааПчЛњЗПВПЪ№гУгкШнджЕФЪБКђЃЌШчКЮБЃжЄвЛИіЛњЗПЕєЯпЃЌВЛЛсЖЊЪЇ Raft Group ЕФЖрИі
ReplicaЃП
ЬэМгвЛИіНкЕуНјШы TiKV МЏШКжЎКѓЃЌШчКЮНЋМЏШКжаЦфЫћНкЕуЩЯЕФЪ§ОнАсЙ§РД?
ЕБвЛИіНкЕуЕєЯпЪБЃЌЛсГіЯжЪВУДЮЪЬтЃПећИіМЏШКашвЊзіЪВУДЪТЧщЃПШчЙћНкЕужЛЪЧЖЬднЕєЯпЃЈжиЦєЗўЮёЃЉЃЌФЧУДШчКЮДІРэЃПШчЙћНкЕуЪЧГЄЪБМфЕєЯпЃЈДХХЬЙЪеЯЃЌЪ§ОнШЋВПЖЊЪЇЃЉЃЌашвЊШчКЮДІРэЃП
МйЩшМЏШКашвЊУПИі Raft Group га N ИіИББОЃЌФЧУДЖдгкЕЅИі Raft Group РДЫЕЃЌReplica
Ъ§СППЩФмЛсВЛЙЛЖрЃЈР§ШчНкЕуЕєЯпЃЌЪЇШЅИББОЃЉЃЌвВПЩФмЛсЙ§гкЖрЃЈР§ШчЕєЯпЕФНкЕугжЛиИДе§ГЃЃЌздЖЏМгШыМЏШКЃЉЁЃФЧУДШчКЮЕїНк
Replica ИіЪ§ЃП
ЖС/аДЖМЪЧЭЈЙ§ Leader НјааЃЌШчЙћ Leader жЛМЏжадкЩйСПНкЕуЩЯЃЌЛсЖдМЏШКгаЪВУДгАЯьЃП
ВЂВЛЪЧЫљгаЕФ Region ЖМБЛЦЕЗБЕФЗУЮЪЃЌПЩФмЗУЮЪШШЕужЛдкЩйЪ§МИИі RegionЃЌетИіЪБКђЮвУЧашвЊзіЪВУДЃП
МЏШКдкзіИКдиОљКтЕФЪБКђЃЌЭљЭљашвЊАсЧЈЪ§ОнЃЌетжжЪ§ОнЕФЧЈвЦЛсВЛЛсеМгУДѓСПЕФЭјТчДјПэЁЂДХХЬ IO вдМА
CPUЃПНјЖјгАЯьдкЯпЗўЮёЃП
етаЉЮЪЬтЕЅЖРФУГіПЩФмЖМФмевЕНМђЕЅЕФНтОіЗНАИЃЌЕЋЪЧЛьдгдквЛЦ№ЃЌОЭВЛЬЋКУНтОіЁЃгаЕФЮЪЬтУВЫЦжЛашвЊПМТЧЕЅИі
Raft Group ФкВПЕФЧщПіЃЌБШШчИљОнИББОЪ§СПЪЧЗёзуЙЛЖрРДОіЖЈЪЧЗёашвЊЬэМгИББОЁЃЕЋЪЧЪЕМЪЩЯетИіИББОЬэМгдкФФРяЃЌЪЧашвЊПМТЧШЋОжЕФаХЯЂЁЃећИіЯЕЭГвВЪЧдкЖЏЬЌБфЛЏЃЌRegion
ЗжСбЁЂНкЕуМгШыЁЂНкЕуЪЇаЇЁЂЗУЮЪШШЕуБфЛЏЕШЧщПіЛсВЛЖЯЗЂЩњЃЌећИіЕїЖШЯЕЭГвВашвЊдкЖЏЬЌжаВЛЖЯЯђзюгХзДЬЌЧАНјЃЌШчЙћУЛгавЛИіеЦЮеШЋОжаХЯЂЃЌПЩвдЖдШЋОжНјааЕїЖШЃЌВЂЧвПЩвдХфжУЕФзщМўЃЌОЭКмФбТњзуетаЉашЧѓЁЃвђДЫЮвУЧашвЊвЛИіжааФНкЕуЃЌРДЖдЯЕЭГЕФећЬхзДПіНјааАбПиКЭЕїећЃЌЫљвдгаСЫ
PD етИіФЃПщЁЃ
ЕїЖШЕФашЧѓ
ЩЯУцТоСаСЫвЛДѓЖбЮЪЬтЃЌЮвУЧЯШНјааЗжРрКЭећРэЁЃзмЬхРДПДЃЌЮЪЬтгаСНДѓРрЃК
зїЮЊвЛИіЗжВМЪНИпПЩгУДцДЂЯЕЭГЃЌБиаыТњзуЕФашЧѓЃЌАќРЈЫФжжЃК
ИББОЪ§СПВЛФмЖрвВВЛФмЩй
ИББОашвЊЗжВМдкВЛЭЌЕФЛњЦїЩЯ
аТМгНкЕуКѓЃЌПЩвдНЋЦфЫћНкЕуЩЯЕФИББОЧЈвЦЙ§РД
НкЕуЯТЯпКѓЃЌашвЊНЋИУНкЕуЕФЪ§ОнЧЈвЦзп
зїЮЊвЛИіСМКУЕФЗжВМЪНЯЕЭГЃЌашвЊгХЛЏЕФЕиЗНЃЌАќРЈЃК
ЮЌГжећИіМЏШКЕФ Leader ЗжВМОљдШ
ЮЌГжУПИіНкЕуЕФДЂДцШнСПОљдШ
ЮЌГжЗУЮЪШШЕуЗжВМОљдШ
ПижЦ Balance ЕФЫйЖШЃЌБмУтгАЯьдкЯпЗўЮё
ЙмРэНкЕузДЬЌЃЌАќРЈЪжЖЏЩЯЯп/ЯТЯпНкЕуЃЌвдМАздЖЏЯТЯпЪЇаЇНкЕу
ТњзуЕквЛРрашЧѓКѓЃЌећИіЯЕЭГНЋОпБИЖрИББОШнДэЁЂЖЏЬЌРЉШн/ЫѕШнЁЂШнШЬНкЕуЕєЯпвдМАздЖЏДэЮѓЛжИДЕФЙІФмЁЃТњзуЕкЖўРрашЧѓКѓЃЌПЩвдЪЙЕУећЬхЯЕЭГЕФИКдиИќМгОљдШЁЂЧвПЩвдЗНБуЕФЙмРэЁЃ
ЮЊСЫТњзуетаЉашЧѓЃЌЪзЯШЮвУЧашвЊЪеМЏзуЙЛЕФаХЯЂЃЌБШШчУПИіНкЕуЕФзДЬЌЁЂУПИі Raft Group ЕФаХЯЂЁЂвЕЮёЗУЮЪВйзїЕФЭГМЦЕШЃЛЦфДЮашвЊЩшжУвЛаЉВпТдЃЌPD
ИљОнетаЉаХЯЂвдМАЕїЖШЕФВпТдЃЌжЦЖЈГіОЁСПТњзуЧАУцЫљЪіашЧѓЕФЕїЖШМЦЛЎЃЛзюКѓашвЊвЛаЉЛљБОЕФВйзїЃЌРДЭъГЩЕїЖШМЦЛЎЁЃ
ЕїЖШЕФЛљБОВйзї
ЮвУЧЯШРДНщЩмзюМђЕЅЕФвЛЕуЃЌвВОЭЪЧЕїЖШЕФЛљБОВйзїЃЌвВОЭЪЧЮЊСЫТњзуЕїЖШЕФВпТдЃЌЮвУЧгаФФаЉЙІФмПЩвдгУЁЃетЪЧећИіЕїЖШЕФЛљДЁЃЌСЫНтСЫЪжРягаЪВУДбљЕФДИзгЃЌВХжЊЕРгУЪВУДбљЕФзЫЪЦШЅдвЖЄзгЁЃ
ЩЯЪіЕїЖШашЧѓПДЫЦИДдгЃЌЕЋЪЧећРэЯТРДзюжеТфЕиЕФЮоЗЧЪЧЯТУцШ§МўЪТЃК
діМгвЛИі Replica
ЩОГ§вЛИі Replica
НЋ Leader НЧЩЋдквЛИі Raft Group ЕФВЛЭЌ Replica жЎМф transfer
ИеКУ Raft авщФмЙЛТњзуетШ§жжашЧѓЃЌЭЈЙ§ AddReplicaЁЂRemoveReplicaЁЂTransferLeader
етШ§ИіУќСюЃЌПЩвджЇГХЩЯЪіШ§жжЛљБОВйзїЁЃ
аХЯЂЪеМЏ
ЕїЖШвРРЕгкећИіМЏШКаХЯЂЕФЪеМЏЃЌМђЕЅРДЫЕЃЌЮвУЧашвЊжЊЕРУПИі TiKV НкЕуЕФзДЬЌвдМАУПИі Region
ЕФзДЬЌЁЃTiKV МЏШКЛсЯђ PD ЛуБЈСНРрЯћЯЂЃК
УПИі TiKV НкЕуЛсЖЈЦкЯђ PD ЛуБЈНкЕуЕФећЬхаХЯЂ
TiKV НкЕуЃЈStoreЃЉгы PD жЎМфДцдкаФЬјАќЃЌвЛЗНУц PD ЭЈЙ§аФЬјАќМьВтУПИі Store
ЪЧЗёДцЛюЃЌвдМАЪЧЗёгааТМгШыЕФ StoreЃЛСэвЛЗНУцЃЌаФЬјАќжавВЛсаЏДјетИі Store ЕФзДЬЌаХЯЂЃЌжївЊАќРЈЃК
змДХХЬШнСП
ПЩгУДХХЬШнСП
ГадиЕФ Region Ъ§СП
Ъ§ОнаДШыЫйЖШ
ЗЂЫЭ/НгЪмЕФ Snapshot Ъ§СПЃЈReplica жЎМфПЩФмЛсЭЈЙ§ Snapshot ЭЌВНЪ§ОнЃЉ
ЪЧЗёЙ§ди
БъЧЉаХЯЂЃЈБъЧЉЪЧОпБИВуМЖЙиЯЕЕФвЛЯЕСа TagЃЉ
УПИі Raft Group ЕФ Leader ЛсЖЈЦкЯђ PD ЛуБЈаХЯЂ
УПИі Raft Group ЕФ Leader КЭ PD жЎМфДцдкаФЬјАќЃЌгУгкЛуБЈетИі Region
ЕФзДЬЌЃЌжївЊАќРЈЯТУцМИЕуаХЯЂЃК
Leader ЕФЮЛжУ
Followers ЕФЮЛжУ
ЕєЯп Replica ЕФИіЪ§
Ъ§ОнаДШы/ЖСШЁЕФЫйЖШ
PD ВЛЖЯЕФЭЈЙ§етСНРраФЬјЯћЯЂЪеМЏећИіМЏШКЕФаХЯЂЃЌдйвдетаЉаХЯЂзїЮЊОіВпЕФвРОнЁЃГ§ДЫжЎЭтЃЌPD ЛЙПЩвдЭЈЙ§ЙмРэНгПкНгЪмЖюЭтЕФаХЯЂЃЌгУРДзіИќзМШЗЕФОіВпЁЃБШШчЕБФГИі
Store ЕФаФЬјАќжаЖЯЕФЪБКђЃЌPD ВЂВЛФмХаЖЯетИіНкЕуЪЧСйЪБЪЇаЇЛЙЪЧгРОУЪЇаЇЃЌжЛФмОЙ§вЛЖЮЪБМфЕФЕШД§ЃЈФЌШЯЪЧ
30 ЗжжгЃЉЃЌШчЙћвЛжБУЛгааФЬјАќЃЌОЭШЯЮЊЪЧ Store вбОЯТЯпЃЌдйОіЖЈашвЊНЋетИі Store ЩЯУцЕФ
Region ЖМЕїЖШзпЁЃЕЋЪЧгаЕФЪБКђЃЌЪЧдЫЮЌШЫдБжїЖЏНЋФГЬЈЛњЦїЯТЯпЃЌетИіЪБКђЃЌПЩвдЭЈЙ§ PD ЕФЙмРэНгПкЭЈжЊ
PD ИУ Store ВЛПЩгУЃЌPD ОЭПЩвдТэЩЯХаЖЯашвЊНЋетИі Store ЩЯУцЕФ Region ЖМЕїЖШзпЁЃ
ЕїЖШЕФВпТд
PD ЪеМЏСЫетаЉаХЯЂКѓЃЌЛЙашвЊвЛаЉВпТдРДжЦЖЈОпЬхЕФЕїЖШМЦЛЎЁЃ
вЛИі Region ЕФ Replica Ъ§СПе§ШЗ
ЕБ PD ЭЈЙ§ФГИі Region Leader ЕФаФЬјАќЗЂЯжетИі Region ЕФ Replica
Ъ§СПВЛТњзувЊЧѓЪБЃЌашвЊЭЈЙ§ Add/Remove Replica ВйзїЕїећ Replica Ъ§СПЁЃГіЯжетжжЧщПіЕФПЩФмдвђЪЧЃК
ФГИіНкЕуЕєЯпЃЌЩЯУцЕФЪ§ОнШЋВПЖЊЪЇЃЌЕМжТвЛаЉ Region ЕФ Replica Ъ§СПВЛзу
ФГИіЕєЯпНкЕугжЛжИДЗўЮёЃЌздЖЏНгШыМЏШКЃЌетбљжЎЧАвбОВЙзуСЫ Replica ЕФ Region ЕФ Replica
Ъ§СПЖрЙ§ЃЌашвЊЩОГ§ФГИі Replica
ЙмРэдБЕїећСЫИББОВпТдЃЌаоИФСЫ max-replicas ЕФХфжУ
вЛИі Raft Group жаЕФЖрИі Replica ВЛдкЭЌвЛИіЮЛжУ
зЂвтЕкЖўЕуЃЌЁКвЛИі Raft Group жаЕФЖрИі Replica ВЛдкЭЌвЛИіЮЛжУЁЛЃЌетРягУЕФЪЧЁКЭЌвЛИіЮЛжУЁЛЖјВЛЪЧЁКЭЌвЛИіНкЕуЁЛЁЃдквЛАуЧщПіЯТЃЌPD
жЛЛсБЃжЄЖрИі Replica ВЛТфдквЛИіНкЕуЩЯЃЌвдБмУтЕЅИіНкЕуЪЇаЇЕМжТЖрИі Replica ЖЊЪЇЁЃдкЪЕМЪВПЪ№жаЃЌЛЙПЩФмГіЯжЯТУцетаЉашЧѓЃК
ЖрИіНкЕуВПЪ№дкЭЌвЛЬЈЮяРэЛњЦїЩЯ
TiKV НкЕуЗжВМдкЖрИіЛњМмЩЯЃЌЯЃЭћЕЅИіЛњМмЕєЕчЪБЃЌвВФмБЃжЄЯЕЭГПЩгУад
TiKV НкЕуЗжВМдкЖрИі IDC жаЃЌЯЃЭћЕЅИіЛњЗПЕєЕчЪБЃЌвВФмБЃжЄЯЕЭГПЩгУ
етаЉашЧѓБОжЪЩЯЖМЪЧФГвЛИіНкЕуОпБИЙВЭЌЕФЮЛжУЪєадЃЌЙЙГЩвЛИізюаЁЕФШнДэЕЅдЊЃЌЮвУЧЯЃЭћетИіЕЅдЊФкВПВЛЛсДцдквЛИі
Region ЕФЖрИі ReplicaЁЃетИіЪБКђЃЌПЩвдИјНкЕуХфжУ lables ВЂЧвЭЈЙ§дк PD ЩЯХфжУ
location-labels РДжИУїФФаЉ lable ЪЧЮЛжУБъЪЖЃЌашвЊдк Replica ЗжХфЕФЪБКђОЁСПБЃжЄВЛЛсгавЛИі
Region ЕФЖрИі Replica ЫљдкНсЕугаЯрЭЌЕФЮЛжУБъЪЖЁЃ
ИББОдк Store жЎМфЕФЗжВМОљдШЗжХф
ЧАУцЫЕЙ§ЃЌУПИіИББОжаДцДЂЕФЪ§ОнШнСПЩЯЯоЪЧЙЬЖЈЕФЃЌЫљвдЮвУЧЮЌГжУПИіНкЕуЩЯУцЃЌИББОЪ§СПЕФОљКтЃЌЛсЪЙЕУзмЬхЕФИКдиИќОљКтЁЃ
Leader Ъ§СПдк Store жЎМфОљдШЗжХф
Raft авщвЊЖСШЁКЭаДШыЖМЭЈЙ§ Leader НјааЃЌЫљвдМЦЫуЕФИКдижївЊдк Leader ЩЯУцЃЌPD
ЛсОЁПЩФмНЋ Leader дкНкЕуМфЗжЩЂПЊЁЃ
ЗУЮЪШШЕуЪ§СПдк Store жЎМфОљдШЗжХф
УПИі Store вдМА Region Leader дкЩЯБЈаХЯЂЪБаЏДјСЫЕБЧАЗУЮЪИКдиЕФаХЯЂЃЌБШШч Key
ЕФЖСШЁ/аДШыЫйЖШЁЃPD ЛсМьВтГіЗУЮЪШШЕуЃЌЧвНЋЦфдкНкЕужЎМфЗжЩЂПЊЁЃ
ИїИі Store ЕФДцДЂПеМфеМгУДѓжТЯрЕШ
УПИі Store ЦєЖЏЕФЪБКђЖМЛсжИЖЈвЛИі Capacity ВЮЪ§ЃЌБэУїетИі Store ЕФДцДЂПеМфЩЯЯоЃЌPD
дкзіЕїЖШЕФЪБКђЃЌЛсПМТЧНкЕуЕФДцДЂПеМфЪЃгрСПЁЃ
ПижЦЕїЖШЫйЖШЃЌБмУтгАЯьдкЯпЗўЮё
ЕїЖШВйзїашвЊКФЗб CPUЁЂФкДцЁЂДХХЬ IO вдМАЭјТчДјПэЃЌЮвУЧашвЊБмУтЖдЯпЩЯЗўЮёдьГЩЬЋДѓгАЯьЁЃPD
ЛсЖдЕБЧАе§дкНјааЕФВйзїЪ§СПНјааПижЦЃЌФЌШЯЕФЫйЖШПижЦЪЧБШНЯБЃЪиЕФЃЌШчЙћЯЃЭћМгПьЕїЖШ(БШШчвбОЭЃЗўЮёЩ§МЖЃЌдіМгаТНкЕуЃЌЯЃЭћОЁПьЕїЖШ)ЃЌФЧУДПЩвдЭЈЙ§
pd-ctl ЪжЖЏМгПьЕїЖШЫйЖШЁЃ
жЇГжЪжЖЏЯТЯпНкЕу
ЕБЭЈЙ§ pd-ctl ЪжЖЏЯТЯпНкЕуКѓЃЌPD ЛсдквЛЖЈЕФЫйТЪПижЦЯТЃЌНЋНкЕуЩЯЕФЪ§ОнЕїЖШзпЁЃЕБЕїЖШЭъГЩКѓЃЌОЭЛсНЋетИіНкЕужУЮЊЯТЯпзДЬЌЁЃ
ЕїЖШЕФЪЕЯж
СЫНтСЫЩЯУцетаЉаХЯЂКѓЃЌНгЯТРДЮвУЧПДвЛЯТећИіЕїЖШЕФСїГЬЁЃ
PD ВЛЖЯЕФЭЈЙ§ Store Лђеп Leader ЕФаФЬјАќЪеМЏаХЯЂЃЌЛёЕУећИіМЏШКЕФЯъЯИЪ§ОнЃЌВЂЧвИљОнетаЉаХЯЂвдМАЕїЖШВпТдЩњГЩЕїЖШВйзїађСаЃЌУПДЮЪеЕН
Region Leader ЗЂРДЕФаФЬјАќЪБЃЌPD ЖМЛсМьВщЪЧЗёгаЖдетИі Region Д§НјааЕФВйзїЃЌЭЈЙ§аФЬјАќЕФЛиИДЯћЯЂЃЌНЋашвЊНјааЕФВйзїЗЕЛиИј
Region LeaderЃЌВЂдкКѓУцЕФаФЬјАќжаМрВтжДааНсЙћЁЃзЂвтетРяЕФВйзїжЛЪЧИј Region Leader
ЕФНЈвщЃЌВЂВЛБЃжЄвЛЖЈФмЕУЕНжДааЃЌОпЬхЪЧЗёЛсжДаавдМАЪВУДЪБКђжДааЃЌгЩ Region Leader здМКИљОнЕБЧАздЩэзДЬЌРДЖЈЁЃ
змНс
БОЦЊЮФеТНВЕФЖЋЮїЃЌДѓМвПЩФмЦНЪБКмЩйЛсдкЦфЫћЮФеТжаПДЕНЃЌУПвЛИіЩшМЦЖМгаБГКѓЕФПМСПЃЌЯЃЭћДѓМвФмСЫНтЕНвЛИіЗжВМЪНДцДЂЯЕЭГдкзіЕїЖШЕФЪБКђЃЌашвЊПМТЧФФаЉЖЋЮїЃЌШчКЮНЋВпТдЁЂЪЕЯжНјааНтёюЃЌИќСщЛюЕФжЇГжВпТдЕФРЉеЙЁЃ
| 








