| БрМЭЦМі: |
ЮФеТЯъЯИНщЩмСЫAnalyticDBЕФМмЙЙбнНјЃЌєЫКЭMPPв§ЧцЃЌаўЮфДцДЂв§ЧцвдМАЗжВМЪНMetaЗўЮёЕШЯрЙиФкШнЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
ЬтМЧ
ЗжЮіаЭЪ§ОнПтAnalyticDB(ЯТЮФМђГЦADBЃЉЃЌЪЧАЂРяАЭАЭзджїбаЗЂЁЂЮЈвЛОЙ§ГЌДѓЙцФЃвдМАКЫаФвЕЮёбщжЄЕФPBМЖЪЕЪБЪ§ОнВжПтЁЃНижЙФПЧАЃЌЯжгаЭтВПжЇГХПЭЛЇМШАќРЈДЋЭГЕФДѓжааЭЦѓвЕКЭеўИЎЛњЙЙЃЌвВАќРЈжкЖрЕФЛЅСЊЭјЙЋЫОЃЌИВИЧЭтВПЪЎМИИіаавЕЁЃЭЌЪБЃЌADBдкАЂРяФкВПГаНгзХЙуИцгЊЯњЁЂЩЬМвЪ§ОнЗўЮёЁЂВЫФёЮяСїЁЂКаТэаТСуЪлЕШжкЖрКЫаФвЕЮёЕФИпВЂЗЂЕЭбгЪБЕФЗжЮіДІРэЁЃ
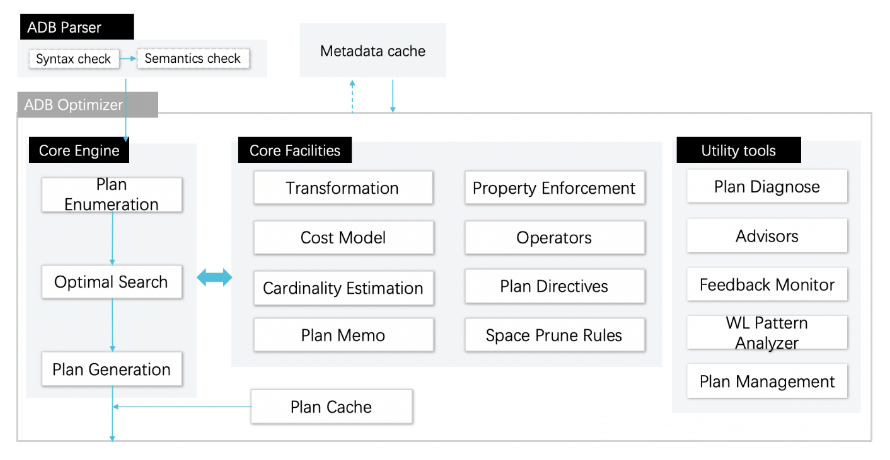
МмЙЙбнНј
вЛ.НгШыВуКЭSQL Parser
1.ШЋУцВЩгУздбаParserзщМў-FastSQL
гЩгкРњЪЗдвђЃЌADBЕФИїФЃПщжадјгаЖрИіParserзщМўЃЌР§ШчЕБЪБДцДЂНкЕугУЕФЪЧDruid, НгШыВуSQLНтЮігУЕФЪЧAntlr
Parser, ЕМжТSQLМцШнадФбЬсЩ§ЁЃЖдгквЛИіЩЯЯпЖрФъЁЂЗўЮёгкФкЭтжкЖрЪ§ОнвЕЮёЕФADBРДЫЕЃЌЪьЯЄЪ§ОнПтЕФЭЌбЇЖМжЊЕРЃЌЬцЛЛParserФбЖШжЎДѓЃЌПАБШЗЩаажаЛЛв§ЧцЁЃ
ОЙ§АыФъЖрЕФХЌСІЃЌADBЭъГЩСЫНЋЩЯЪіМИДѓParserзщМўЭГвЛЩ§МЖЬцЛЛЮЊFastSQL ( Base
on DruidЃЌОЙ§ПЊдДЩчЧј8ФъЕФЭъЩЦЃЌгяЗЈжЇГжвбОЗЧГЃЭъБИ)ЁЃЩ§МЖЮЊFastSQLКѓЃЌдкSQLМцШнадДѓЗљЖШЬсЩ§ЁЂИДдгГЁОАНтЮіЫйЖШЬсЩ§30-100БЖЕФЭЌЪБЃЌ
FastSQLЛЙФмЮоЗьНсКЯгХЛЏЦїЃЌЬсЙЉГЃСПелЕўЁЂКЏЪ§БфЛЛЁЂБэДяЪНзЊЛЛЁЂКЏЪ§РраЭЭЦЖЯЁЂГЃСПЭЦЖЯЁЂгявхШЅжиЕШЙІФмжЇГжЃЌЗНБугХЛЏЦїЩњГЩзюгХЕФжДааМЦЛЎЁЃ
2.ЪЕЪБаДШыадФмЬсЩ§10БЖ
дкADB v2.7.4АцБОПЊЪМЃЌдкSQL ParserЩЯзіСЫЩюЖШММЪѕгХЛЏЃЌДѓЗљЖШЬсЩ§СЫINSERTЛЗНкЕФадФмЃЌдкЪЕМЪЩњВњЛЗОГжаадФм10БЖадФмЬсЩ§ЃЌвддЦЩЯ4*C4ЮЊР§ЃЌitemБэПЩвдбЙВтЕН15w
TPSЁЃ
3.КЃСПЪ§ОнСїЪНЗЕЛи
дкADB v2.7вдЧАЕФАцБОЃЌМЦЫуПђМмЗЕЛиЕФЪ§ОнЃЌашвЊдкФкДцжаЖбЛ§ЃЌЕШД§ШЋВПжДааЭъВХЗЕЛиЕНПЭЛЇЖЫЁЃдкВЂЗЂДѓЛђепНсЙћДѓЪБЃЌПЩФмгаФкДцвчГіЕФЗчЯеЁЃДг2.7АцБОПЊЪМЃЌФЌШЯВЩгУСїЪНЗЕЛиЃЌЪ§ОнЪЕЪБЗЕЛиПЭЛЇЖЫЃЌФмНЕЕЭбгЪБЃЌМЋДѓЕФЬсЩ§СЫДѓНсЙћМЏЗЕЛиЕФЕїгУЮШЖЈадЁЃ
Жў. Query Optimizer
2018ФъЃЌвЛЗНУцдЦЩЯдЦЯТвЕЮёШЋУцДгADBЩЯвЛДњЕФLMв§ЧцЃЌЧЈвЦжСєЫКЭMPPв§ЧцЃЌСэвЛЗНУцдНРДдНЖрЕФПЭЛЇВЛЯЃЭћзпРыЯпЛђепСїМЦЫуЧхЯДЃЌЪЕЪБЪ§ВжГЁОАБХЗЂЃЌЭЌЪБдНРДдНЖрздЖЏЩњГЩSQLЕФПЩЪгЛЏЙЄОпПЊЪМЖдНгADBЃЌЖдгХЛЏЦїЭХЖгЬсГіСЫМЋИпЬєеНЁЃ
ЮЊСЫгІЖдетаЉЬєеНЃЌдкетвЛФъРягХЛЏЦїЭХЖгДгЮоЕНгаЃЌж№НЅзщНЈЦ№РДвЛжЇОЋСЗЕФЙњМЪЛЏЭХЖгЁЃдкВЛЖЯДђдьФЅКЯЙ§ГЬжаЃЌADBгХЛЏЦїетвЛФъЕФеЖЛёШчЯТЃК
1.НЈСЂВЂЭъЩЦRBO PlusгХЛЏЦї
ВЛЭЌгкДЋЭГRBOгХЛЏЦїЃЌдкRBO PlusЩшМЦжаЪЕЯжСЫЯТСаЙиМќЬиадЃК
1). в§ШыДњМлФЃаЭКЭЙРЫуЃЌРћгУADBЕФИпаЇДцДЂНгПкЃЌв§Шыdynamic selectivity &
cardinalityЙРЫугХЛЏjoin reorder, ЪЙЕУADBПЩвдгІЖдЖрДя10+БэjoinЕФИДдгВщбЏГЁОА.
2). еыЖдMPPЬиБ№гХЛЏdata shufflingЃЌaggregationЕШжДааМЦЛЎЃЌЯрЖдгкLMв§ЧцвЕЮёГЁОАадФмНгНќСуЛиЭЫЁЃ
3). ДгЙІФмКЭадФмСНИіЮЌЖШЃЌЖдИїжжГЃМћвдМАИДдгЙиСЊзгВщбЏГЁОАНјааСЫЩюЖШгХЛЏЃЌЩшМЦСЫвЛЯЕСаЙиСЊЙцдђЫуЗЈЃЌдкИїжжБъзМbenchmarkжаЯргІЕФВщбЏжаЃЌВПЗжГЁОАup
to 20XЬсЩ§ЁЃ
4). еыЖдГЌЖЬЪБбг(ms)ЕуВщЃЌЩшМЦСЫparameterized plan cacheЃЌНЋетаЉГЁОАЕФгХЛЏЪБМфГЩБОНЕЕЭ10БЖвдЩЯЁЃ
2.ДђдьCBOгХЛЏЦї
УцЖддНРДдНИДдгЕФвЕЮёВщбЏГЁОАЃЌRBOМАRBO PlusгаЦфЯргІЕФОжЯоКЭЬєеНЃЌCBOГЩЮЊADBгХЛЏЦїТѕЯђЭЈгУЩЬвЕгХЛЏЦїЕФЙиМќЃЌЮвУЧУЛгаВЩгУЫфЙуЗКЪЙгУЕЋОжЯоадвВКмЖрЕФCalciteгХЛЏЦїЃЌЖјЪЧзХЪжДђдьзджїПЩПиЕФCBOгХЛЏЦїЃЌЬсЩ§ADBЕФКЫаФОКељСІЃК
1) НЈСЂИпаЇЕФЭГМЦаХЯЂЪеМЏЬхЯЕЃЌЦНКтзМШЗадгыЪеМЏДњМлЃЌЮЊCBOЬсЙЉЁАЛљДЁаХЯЂЩшЪЉЁБЃЛ
2) ЙЙНЈCascadesМмЙЙЕФCBOПђМмЃЌНЋЦфДђдьГЩПЩРЉеЙЕФгХЛЏЦНЬЈЁЃ
Ш§. єЫКЭMPPв§Чц
етвЛФъЃЌADBМмЙЙШЋУцДгЩЯвЛДњЕФLMв§ЧцЧаЛЛжСєЫКЭMPPв§ЧцЃЌєЫКЭв§ЧцвЛЗНУцМШвЊжЇГХЭъГЩЧаЛЛЃЌТњзуПЭЛЇИќСщЛюздгЩВщбЏЕФжиШЮЃЌгжвЊЭЈЙ§ДѓЗљЖШЕФадФмгХЛЏРДЯћГ§в§ЧцЧаЛЛДјРДЕФФГаЉГЁОАЯТЕФадФмПЊЯњЁЃ
1.ШЋBinaryМЦЫу
ЛљгкBinary ЕФМЦЫуЃЌЪЁШЅShuffle ЕФађСаЛЏКЭЗДађСаЛЏПЊЯњЃЌВЂЧвгыДцДЂЩюЖШАѓЖЈЃЌзіЕНДцДЂМЦЫувЛЬхЛЏЃЌећИіМЦЫуЙ§ГЬУЛгаЖргрЕФађСаЛЏКЭЗДађСаЛЏПЊЯњЁЃ
2.ФкВПГиЛЏ
ЭЈЙ§ЖЈГЄЕФФкДцЧаЦЌЭъГЩГиЛЏЃЌдкМЦЫуЙ§ГЬжаМѕЩйСЫСЌајФкДцРЉШнДјРДЕФЯћКФЃЌЭЌЪБЭЈЙ§ГиЛЏЭъШЋзджїЙмПиФкДцЃЌБмУтСЫдкИДдгSQLГЁОАЯТЕФGCЯћКФЁЃ
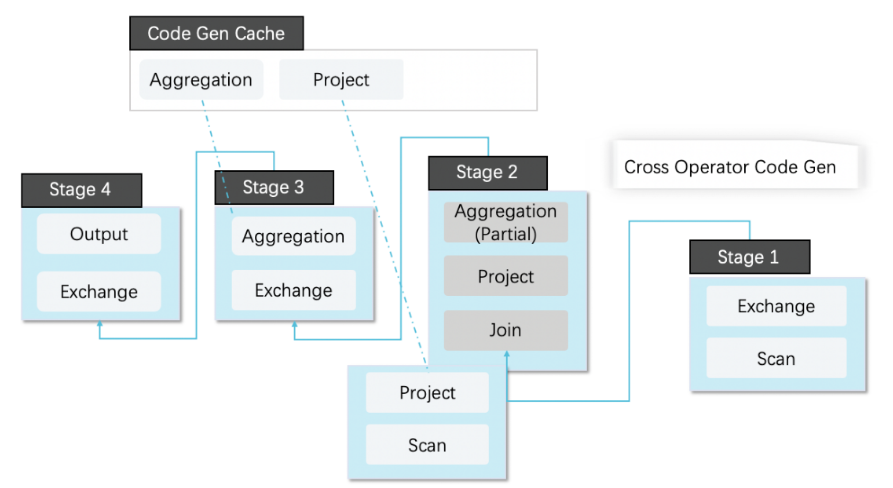
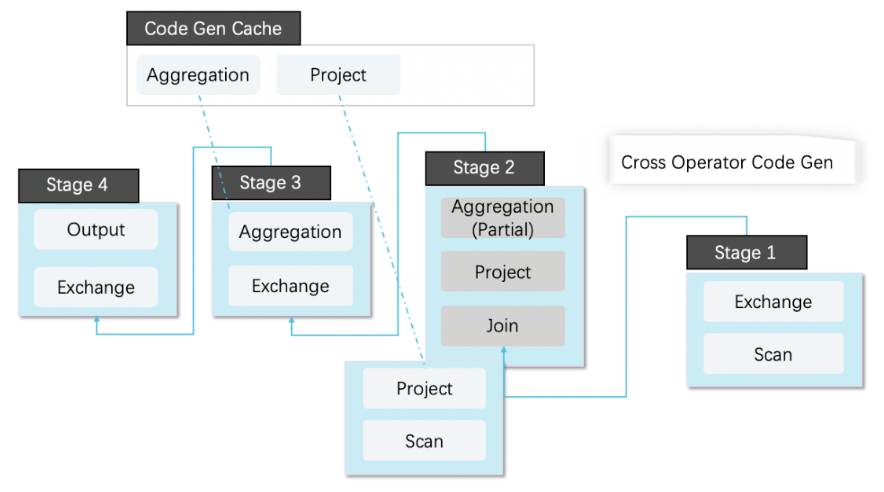
3.CodeGenЩюЖШгХЛЏ
1). CacheЪЙгУЃЌЭЈЙ§ЖдЫузгЃЌБэДяЪНЕФCodeGenГЃСПГщШЁЃЌЛКДцCodeGenЩњГЩЕФДњТыЃЌдкИпВЂЗЂГЁОАЯТБмУтСЫУПДЮЖМашвЊЖЏЬЌБрвыДњТыЕФПЊЯњЃЌЮЊжЇГжИпВЂЗЂКЭQPSЕФвЕЮёДђКУСЫЛљДЁЁЃ
2). ЭЈЙ§ЫузгШкКЯМѕЩйЫузгжЎМфЮяЛЏЕФПЊЯњЁЃ
4.ЦфЫќгХЛЏ
1). АДСаМЦЫуЃЌЭЈЙ§СаЪНМЦЫугыJVMЭХЖгКЯзїв§ШыJDK11жЇГжаТЕФSIMDжИСюМЏНјааМЦЫугХЛЏ
2). здЖЏЫуЗЈгХЛЏЃЌИљОнЪ§ОнЗжВМЃЌЪ§ОнВЩбљздЖЏгХЛЏВПЗжжДааЫуЗЈКЭФкДцЃЛ
3). ЫузгздЪЪгІЕФSpillЃЌжЇГжЖЏЬЌЕФФкДцЗжХфКЭЧРеМЃЌжЇГжjoinЃЌaggЕШЫузгТфХЬЃЛ
4). в§ШыаТЕФађСаЛЏКЭЗДађСаПђМмЬцЛЛдгаЕФJSONавщЃЌв§ШыаТЕФNettyЬцЛЛдгаJetty
5). жЇГждЫааЪБЭГМЦаХЯЂЪеМЏЃЌАќРЈЫузгМЖЃЌstageМЖЃЌqueryМЖЕФФкДцЁЂcpu costЭГМЦЃЌжЇГжВПЗжздЖЏЪЖБ№Т§SQLЁЃ
ЫФ. аўЮфДцДЂв§Чц
ЮЊСЫТњзувЕЮёИпВЂЗЂаДШыЁЂЕЭбгЪБЕФВщбЏЃЌADBзіСЫЖСаДЗжРыМмЙЙЩшМЦЁЃдкРњЪЗЕФАцБОжаЃЌЖСаДЗжЮіМмЙЙЯТга2ИіЮЪЬтЃК1.
аДШыЕНПЩМћЪЧвьВНЕФ, ВПЗжГЁОАгаЖСаДЧПвЛжТадЕФЫпЧѓЁЃ2.діСПЪ§ОнаДШыНЯДѓЕФЧщПіЯТЃЌВщбЏБфТ§ЁЃЭЌбљЃЌНёФъДцДЂв§ЧцдкдіСПЪ§ОнЕФЪЕЪБадКЭадФмЩЯвВзіГіСЫжиДѓЭЛЦЦЁЃ
1.жЇГжЖСаДЧПвЛжТад
зюаТЕФADBАцБОжаЃЌЩшМЦСЫвЛЬзЭъБИЕФвЛжТадЖСаДЗжРыМмЙЙЃЌШчЯТЭМЫљЪОЃК
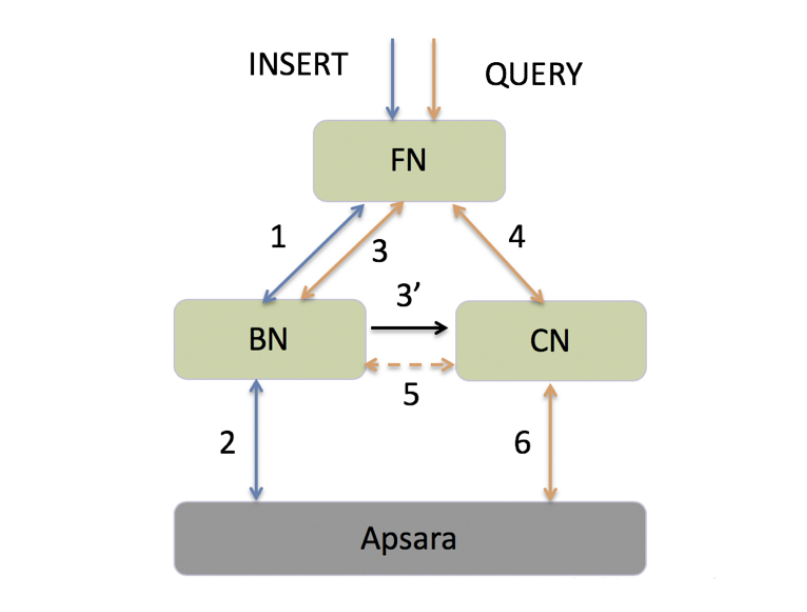
РЖЩЋЯпДњБэаДШыСДТЗЃЌГШЩЋЯпДњБэЖСШЁСДТЗЁЃвдвЛДЮаДШыКЭЖСШЁЮЊР§ЃЌЕБгУЛЇаТаДШыФГБэЕФЪ§ОнКѓЃЌСЂМДЗЂЦ№ВщбЏЃЌДЫЪБFNЛсЪеМЏИУБэдкЫљгаBNЩЯЕФзюаТаДШыАцБОКХ(step
3)ЃЌВЂНЋИУАцБОКХ(БъМЧЮЊV1)аХЯЂЫцЭЌВщбЏЧыЧѓвЛЭЌЗЂЭљЖдгІЕФCNНкЕу(step 4)ЃЌCNБШЖдИУБэдкБОЕиЕФЯћЗбАцБО(МЧЮЊV2)КЭЧыЧѓЕФАцБОКХЁЃ
ШєV1>V2ЃЌCNЯћЗбЕНИУзюаТаДШыЪ§Он(step 5)КѓЬсЙЉВщбЏЃЛШєV1
2.ЬсЩ§діСПЪ§ОнЧјЕФВщбЏадФм
дк ADB ЕФДцДЂНкЕуЖдгкЭЛЗЂЕФДѓХњСПЪЕЪБаДШыЃЌдкдіСПЪ§ОнЧјПЩФмЖЬЪБМфФкЛ§РлНЯЖрЪ§ОнЁЃШчЙћВщбЏЗЂЩњдкдіСПЪ§ОнЧјЃЌДѓСПЕФtable
scanЖСШЁЛсЭЯТ§ећИіЪ§ОнЗжЮіадФмЁЃЮЊДЫдіСПЪ§ОнЧјв§Шы RocksDB ЙЙНЈдіСПЪ§ОнЕФЫїв§ЃЌБЃжЄдіСПЪ§ОнЧјЕФЗУЮЪадФмЃЌЭЈЙ§LSM-Tree
ЕФЗжВуДцДЂНсЙћЃЌЬсЙЉСМКУЕФаДШыадФмЃЌМАНЯКУЕФВщбЏФмСІЁЃ
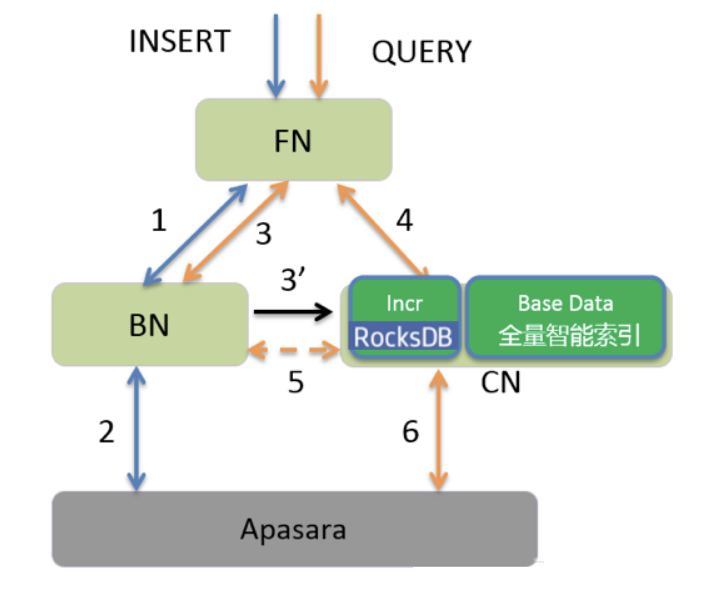
Юх. ЗжВМЪНMetaЗўЮё
РњЪЗАцБОдЊЪ§ОнЮШЖЈадЬєеНДѓЃЌИїФЃПщИїздЗУЮЪдЊЪ§ОнДцдкrace conditionЃЌmetaбЙСІДѓЃЌDDLЬхбщВюЁЃНёФъЮвУЧжиЙЙСЫдЊЪ§ОнФЃПщЃЌЩЯЯпGMSЗўЮёЬсЙЉдЊЪ§ОнЭГвЛЙмРэЃЌЭЌЪБЬсЙЉЗжВМЪНDDLФмСІЃЌВЂЭЈЙ§ЗжВМЪНЛКДцНЕЕЭmetaПтбЙСІЃЌЬсЙЉИпаЇдЊЪ§ОнЗУЮЪаЇТЪЁЃ
ШЋОждЊЪ§ОнЗўЮёЗЂВМ
1). Global Meta Service (GMS)ЩЯЯпЩњВњЃЌЬсЙЉЗжВМЪНDDLКЭЪ§ОнЕїЖШФмСІЃЌЭЌВННЈЩОБэЬсЩ§гУЛЇЬхбщЁЃ
2). БэЗжЧјЗжХфЫуЗЈИФНјЃЌЮЊМЦЫуЕїЖШгХЛЏЃЌжЇГжЖрБэзщГЁОАЯТЕФЪ§ОнОљдШЗжВМ
3). Ъ§ОнИќаТ(ЩЯЯп)ЃЌЪ§ОнжиЗжВМ(Rebalance)ЮШЖЈадДѓДѓЬсЩ§
Сљ. гВМўМгЫй
GPUЫфШЛвбОЙуЗКгУгкЭЈгУМЦЫуЃЌЕЋЪЧЭЈГЃЪЧгУгкЭМаЮДІРэЁЂЛњЦїбЇЯАКЭИпадФмМЦЫуЕШСьгђЁЃШчКЮНЋGPUЕФЧПДѓМЦЫуФмСІКЭADBНјаагаЛњНсКЯЃЌВЂВЛЪЧвЛИіШнвзНтОіЕФЮЪЬтЁЃвЊЯыгУКУGPUЃЌдкGPUзЪдДЙмРэЁЂДњТыЩњГЩЁЂЯдДцЙмРэЁЂЪ§ОнЙмРэЁЂжДааМЦЛЎгХЛЏЕШЗНБуЃЌОљгажюЖрЬєеНЁЃ
2018ФъЃЌADBв§ШыСЫGPUзїЮЊМЦЫуМгЫйв§ЧцЃЌдБОвРРЕРыЯпЗжЮів§ЧцЁЂИєЬьВХФмЭъГЩЕФМЦЫуЃЌЯждкжЛашвЊУыМЖбгГйМДПЩЭъГЩЃЌГЩЙІНЋЪ§ОнМлжЕдкЯпЛЏЃЌЮЊПЭЛЇДјРДСЫОоДѓЕФМлжЕЁЃ
1.GPUзЪдДЙмРэ
ШчКЮШУШЅЗУЮЪGPUзЪдДЪЧЪзЯШвЊНтОіЕФЮЪЬтЁЃ ADBЭЈЙ§jCUDAЕїгУCUDA APIЃЌгУгкЙмРэКЭХфжУGPUЩшБИЁЂGPU
kernelЕФЦєЖЏНгПкЗтзАЁЃИУФЃПщзїЮЊJavaКЭGPUжЎМфЕФЧХСКЃЌЪЙЕУJVMПЩвдКмЗНБуЕиЕїгУGPUзЪдДЁЃ
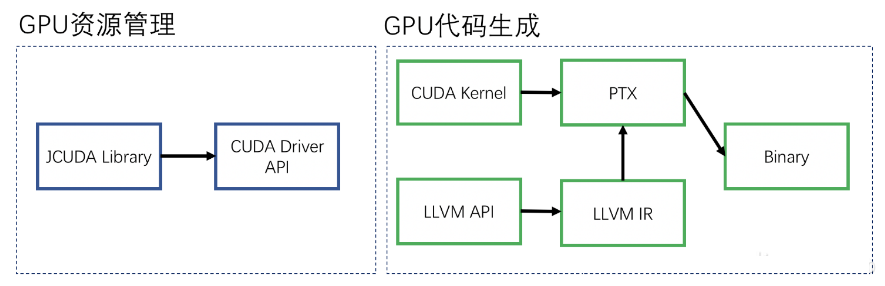
2.CodeGen
ADBЕФжДааМЦЛЎЪЧЮЊCPUзізМБИЕФЃЌЮоЗЈдкGPUЩЯжДааЁЃЖјЧвгЩгкGPUМмЙЙЕФЬиЪтадЃЌGPUЕФБрГЬФЃаЭвВКЭCPUВЛЭЌЁЃЮЊСЫНтОіетвЛЮЪЬтЃЌв§ШыаТЕФCodeGenФЃПщЁЃCodeGenЯШЪЧНшжњLLVM
APIНЋЮяРэМЦЛЎБрвыГЩLLVM IRЃЌIRОЙ§гХЛЏвдКѓЭЈЙ§зЊЛЛГЩPTXДњТыЁЃШЛКѓЕїгУCUDAНЋPTXДњТызЊЛЛГЩБОЕиПЩжДааДњТыЃЌВЂЦєЖЏЦфжаЕФGPUМЦЫуКЏЪ§ЁЃ
CodeGenПЩвдеыЖдВЛЭЌЕФДІРэЦїЩњГЩВЛЭЌЕФДњТыЃЌдкGPUВЛПЩгУЪБЃЌвВПЩвдзЊжСCPUНјаажДааЁЃЯрЖдДЋЭГЛ№ЩНФЃаЭЃЌADBЕФCodeGenФЃПщгааЇМѕЩйКЏЪ§ЕїгУЕФПЊЯњЁЂГфЗжРћгУGPUЕФВЂЗЂФмСІЁЃСэЭтCode
GeneratorРћгУСЫЫузгШкКЯЃЌШчgroup-byОлКЯЁЂjoinдйМгОлКЯЕФШкКЯЃЌДѓДѓМѕЩйжаМфНсЙћЃЈЬиБ№ЪЧJoinЕФСЌНгНсЙћЃЉЕФПНБДКЭЯдДцЕФеМгУЁЃ
3.ЯдДцЙмРэ
ADBПЊЗЂСЫVRAM ManagerгУгкЙмРэИїGPUЕФЯдДцЁЃгаБ№гкЯждкЪаУцЩЯЦфЫћGPUЪ§ОнПтЯЕЭГЪЙгУGPUЕФЗНЪНЃЌЮЊСЫЬсЩ§ЯдДцЕФРћгУТЪЁЂЬсЩ§ВЂЗЂФмСІЃЌНсКЯADBЖрЗжЧјЁЂЖрЯпГЬЕФЬиЕуЃЌЮвУЧЩшМЦЛљгкSlabЕФVRAM
ManagerРДЭГвЛЙмРэЫљгаЯдДцЩъЧыЁЃ
адФмВтЪдЯдЪОЗжХфЪБМфЦНОљЮЊ1msЃЌУїЯдПьгкGPUздДјЕФЯдДцЗжХфНгПкЕФ700msЃЌгаРћгкЬсИпЯЕЭГећЬхВЂЗЂЖШЁЃ
4.PlanгХЛЏ
SQLДгFNЗЂЫЭЕНCNЃЌTask ManagerЯШИљОнМЦЫуЕФЪ§ОнСПвдМАВщбЏЬиеїбЁдёгЩCPUЛЙЪЧGPUДІРэЃЌШЛКѓИљОнТпММЦЛЎЩњГЩЪЪКЯGPUжДааЕФЮяРэМЦЛЎЁЃGPU
EngineЪеЕНЮяРэМЦЛЎКѓЯШЖджДааМЦЛЎНјаажиаДЁЃШчЙћМЦЛЎЗћКЯШкКЯЬиеїЃЌдђЦєЖЏИДКЯЫузгШкКЯЃЌДгЖјДѓСПМѕЩйЫузгМфСйЪБЪ§ОнЕФДЋЪфГЩБОЁЃ
ВњЦЗЛЏФмСІЩ§МЖ
вЛ. взгУадЬсЩ§
1.ШЋУцЧаЛЛєЫКЭMPPв§Чц
Дг2.6.2АцБОПЊЪМЃЌМЏЭХФкКЭЙЋгадЦШЋВПФЌШЯMPPв§ЧцЃЌГЙЕзИцБ№ЩЯвЛДњLMв§ЧцЕФИїжжВщбЏЯожЦЁЃMPPЖдSQLаДЗЈжЇГжИќМгздгЩСщЛюЃЌADBПЭЛЇгРДFull
MPPЪБДњЁЃ
2.SQLМцШнадДѓЗљЖШЬсЩ§
НгШыВуЁЂДцДЂВуParserФЃПщШЋВПЩ§МЖЮЊFastSQLКѓЃЌ ЭтМгЧаЛЛMPPГЩЙІЃЌADB v2.7вдКѓЕФSQLМцШнадНЯРњЪЗАцБОгаСЫЗЧГЃДѓЬсЩ§ЁЃSQLЦфЫћгХЛЏЛЙАќРЈжЇГжСЫСїЪНКѓВЛдйЯожЦВщбЏНсЙћМЏЗЕЛиЁЂЗжвГМцШнMySQLЕШЕШЁЃ
3.здЖЏРЉЫѕШнЁЂЩ§НЕХф
6дТЗнЗЂВМСЫжиАѕЙІФм: здЖЏРЉЫѕШн+СщЛюЩ§НЕХфЁЃГ§СЫРЉЫѕЛљБОФмСІЭтЃЌПЭЛЇЛЙПЩвддкЙцИёжЎМфЧаЛЛЁЃР§ШчДг10c4
ЧаЛЛжС4c8, ПЩвдДг4c8ЧаЛЛжС10c4ЃЌЭЌЪБЪЕЪББэЛЙжЇГждкИпадФмSSDЪЕР§КЭДѓДцДЂSATAЪЕР§МфРДЛиЧаЛЛЁЃ
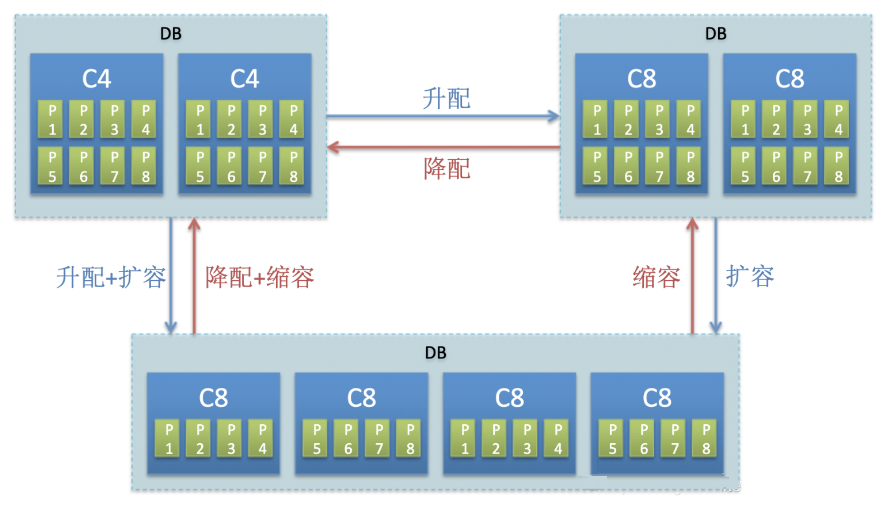
ЩЯЯпаЇЙћЃКХфжУЧаЛЛзіЕНЖСВЛжаЖЯЃЌаДШыжаЖЯдМ1-2ЗжжгЃЌКѓајЭЈЙ§ЖЏЬЌЦЏвЦЗжЧјЃЌаДШывВФмзіЕНЭъШЋВЛЭЃЗўЁЃ
4.аТАцПижЦЬЈКЭDMSЩЯЯп
ЙЋгадЦаТАцЕФПижЦЬЈеЙЪОЕФФкШнИќМгЗсИЛЃЌжЇГжПижЦЬЈДђЕуЃЌВщПДгУЛЇЛЯёЃЛдіМгСЫИќЖрКЭгУЛЇНЛЛЅЕФЕиЗНЁЃгУЛЇЙмРэЃЌaclКЭзгеЫКХЪкШЈИќМгБуНнЕШЁЃDMSШЋаТИФАцЃЌЬхбщДѓЗљЖШЬсЩ§ЃЌЗНБуЕМШыЕМГіЃЌжЇГжSQLЬсЪОКЭSQLМЧвфЙІФмЁЃ
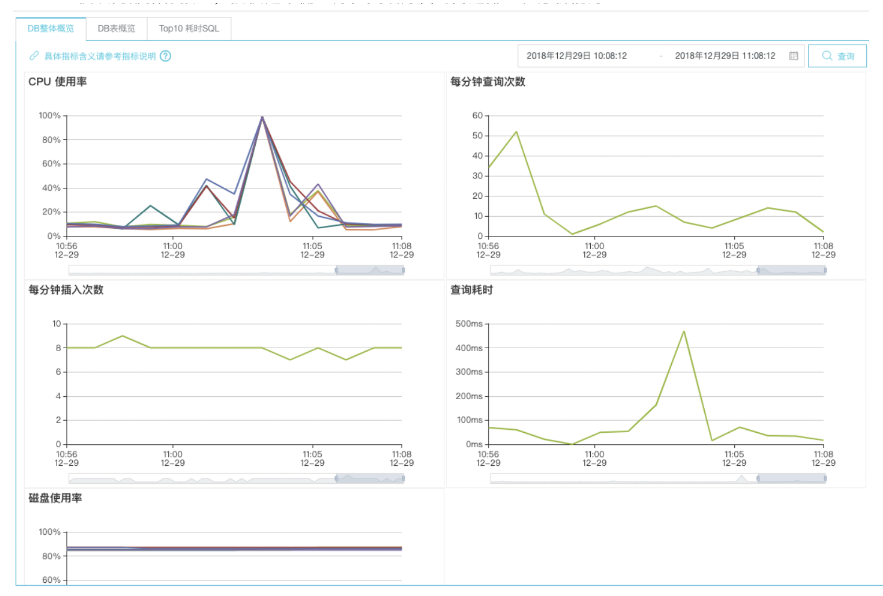
5.ЗЂВМУцЯђгУЛЇВрЕФМрПиИцОЏЯЕЭГ
ЮЊЬсЩ§ПЭЛЇЕФзджњЛЏЗўЮёФмСІЃЌгУЛЇВрЕФМрПижЇГжЕФжИБъгаCPUЪЙгУСПЁЂВщбЏКЭаДШыСПЁЂЪ§ОнЧуаБЁЂTop Slow
SQLЕШЁЃ
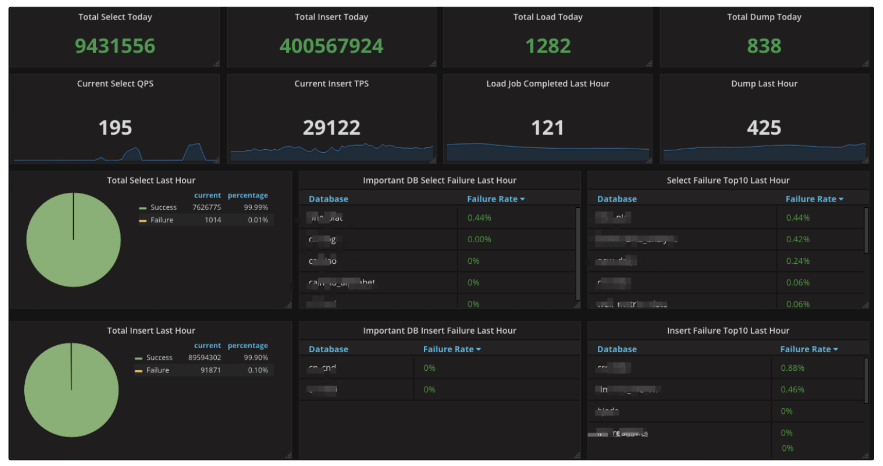
6.ШЋЭјЪ§ОнПтМрПиДѓХЬЩЯЯп
етЪЧШЋЭјЪ§ОнПтЕФблОІЃЌЕЏФкдЦЩЯЪ§ОнПтдЫаазДПівЛРРЮовХЁЃЭЈЙ§ЖдЪ§ОнПтКЭЯЕЭГВуИїжжжИБъЕФТёЕуЗжЮіЃЌЪБПЬМрПизХЪ§ОнПтЕФдЫаазДПіЃЌШчЯТЭМЫљЪО(demoЪ§Он)ЃЌЭЌЪБжЇГжНЋвьГЃжИБъЭЦЫЭПЭЛЇЖЄЖЄШКЃЌДѓЗљЖШЬсЩ§СЫдЫгЊжЕАраЇТЪЁЃ
7.ЗЂВМПЩгУЧј
етвЛФъЙЋЙВдЦЗЂВМЖрПЩгУЧјжЇГжЃЌГЙЕзНтОіЕЅИіregionТєПеЕФЮЪЬтЃЌЦѓвЕПЭЛЇЛЙПЩвдгабЁдёЕФРћгУПЩгУЧјзіЗўЮёШнджЁЃ
Жў. ЗЂВМаТЕФКЫаФЙІФм
1.ЯђСПЗжЮі
НёФъ9дТе§ЪНЗЂВМЯђСПЗжЮіФмСІЃЌЪЙЕУНсЙЙЛЏгыЗЧНсЙЙЛЏЪ§ОнОпБИШкКЯЗжЮіЕФФмСІЁЃЛљгкЯђСПОлРрЙцТЩЕФЯђСПЗжЧјЙцдђЃЌАДееОлРрНсЙћЗжЧјЃЌШУОрРыЯрНќЕФЯђСПОЭНќДцДЂЁЃдкФГзЈгадЦЯюФПРяЃЌжЇГж1:10вкЕФШЫСГЪЖБ№ЃЌQPSЙ§ЭђЃЌбгГйдк100КСУыФкЃЌЪ§ОнСПДяЕНЪ§TBМЖБ№ЁЃ
ЭЌЪБЪзДЮжЇГХвјЬЉЁЂКаТэЕШаТСуЪлГЁОАЕФШЫСГЪЖБ№ЁЂЫуЗЈЭЦМіЁЂгыНсЙЙЛЏЪ§ОнЪЕЪБШкКЯЗжЮіЃЌКСУыМЖДђЭЈЯпЩЯЯпЯТЛсдБЬхЯЕЃЌжЇГХЪЕЪБЪ§ОнЛЏЯпЯТЛЅЖЏЁЂгЊЯњЁЃ
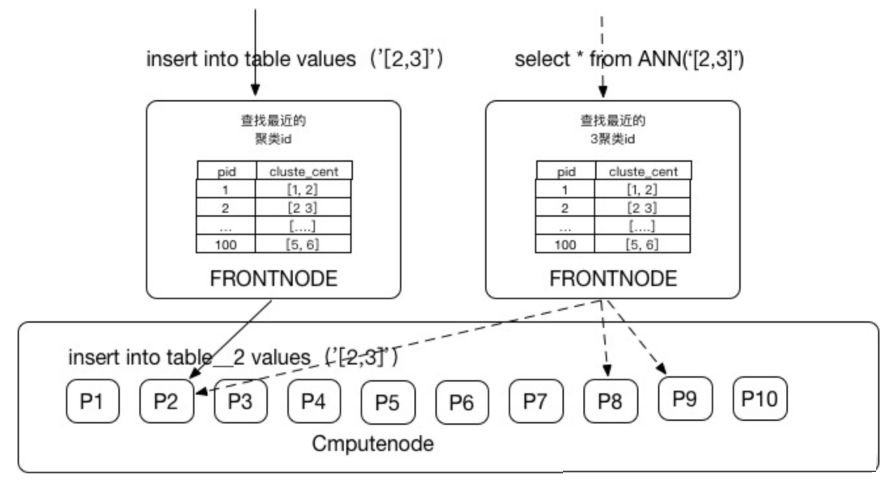
2.ШЋЮФМьЫї
ADB v2.7.4АцБОКѓЃЌЭЈЙ§SQLгябдЬсЙЉШЋЮФМьЫїЙІФмЃЌНЋГЃгУЕФНсЙЙЛЏЪ§ОнЗжЮіВйзїЃЌгыСщЛюЕФЗЧНсЙЙЛЏЪ§ОнЗжЮіВйзїЭГвЛЃЌЪЙгУЭЌвЛЬзSQLгябдВйзїЖржжРраЭЪ§ОнЃЌНЕЕЭСЫбЇЯАКЭПЊЗЂГЩБОЁЃвЛЗНУцЬсЙЉНсЙЙЛЏЪ§ОнЁЂЗЧНсЙЙЛЏЮФБОЕФШкКЯМьЫїЁЂЖрФЃЗжЮіФмСІЃЌСэвЛЗНУцЛљгкMPP+DAGММЪѕЬсЙЉСЫЭъЩЦЕФЗжВМЪНМЦЫуФмСІЃЌЭЌЪБФкжУСЫРДздЬдБІЁЂЬьУЈЫбЫїЕФжЧФмЗжДЪзщМўЃЌЗжДЪаЇЙћИќКУЃЌЫйЖШИќПьЁЃ
3.аТЪ§ОнРраЭ JSON & Decimal
дк2.7АцБОЃЌе§ЪНЗЂВМJSONЪ§ОнРраЭЃЌЭъећЕФжЇГжСЫАќРЈObjectЁЂNULLЁЂArrayдкФкЕФЫљгаJSONРраЭЕФМьЫїЗжЮіЃЌЮЊвЕЮёЬсЙЉСЫ
Schema lessЕФМЋДѓСщЛюадЃЌЭЌЪБвВЬсЙЉСЫПьЫйЕФМьЫїадФмЁЃЮЊСЫИќКУЗНБуН№ШкПЭЛЇЃЌЭЌбљдк2.7АцБОРяЃЌADBе§ЪНЗЂВМDecimalЪ§ОнРраЭЃЌЯђДЋЭГЪ§ОнПтЕФЪ§ОнРраЭМцШнадЩЯгжТѕГіСЫживЊЕФвЛВНЁЃ
Ш§. ЩњЬЌНЈЩш
1.Ъ§ОнНгШы
ПЭЛЇЪ§ОнЭљЭљгаЖржжЖрбљЃЌДцДЂдкИїжжЕиЗНЁЃЮЊСЫзЗЧѓИќЕЭГЩБОЁЂИќИпаЇТЪЕФЪ§ОнНгШыФмСІЃЌДђдьЪЕЪБЪ§ВжЕФФмСІЃЌADBНёФъдкЪ§ОнНгШыЩЯзіСЫжюЖрЕФЭъЩЦЁЃ
1). Copy From OSS & MaxCompute ПЊЗЂЭъГЩЃЌдЊЕЉКѓЩЯЯпЁЃ
2). ADB UploaderЗЂВМЃЌЗНБуБОЕиЮФМўПьЫйЕМШыЁЃ
3). ADBЗЂВМLogstashВхМўЃЌЗНБуШежОЪ§ОнformatКѓжБНгаДШыADBЃЌжаМфЮоашОЙ§MQЛђепHUBЁЃ
4). ADB Client SDKЗЂВМВЂПЊдДЃЌПЭЛЇЖЫаДШыБрГЬТпММђЛЏЃЌОлКЯаДШыадФмДѓЗљЖШЬсЩ§ЁЃ
5). BatchБэЕМШыЮШЖЈадДѓДѓЬсЩ§ЃЌЭЌЪБЭъГЩMaxCompute SDKЩ§МЖКЭOpenMRЧаЛЛЁЃ
6). Connector ServiceЩЯЯпЃЌЬсЙЉЭГвЛЪ§ОндДНгШыВу
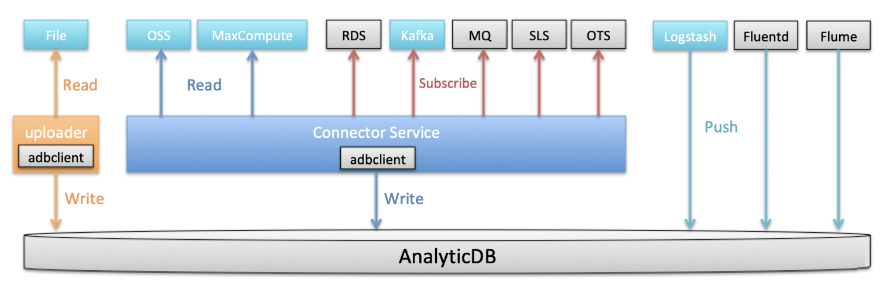
НгЯТРДADBМЦЛЎЛљгкЯжгаПђМмНгШыИќЖрЪ§ОндДЃЈЭМжаЛвЩЋВПЗжЃЉ
2.аавЕдЦНгШы
ЭъГЩН№ШкдЦЁЂЮяСїдЦЁЂОлЪЏЫўШ§ДѓаавЕдЦНгШыЃЌЪЙЕУН№ШкЁЂЮяСїЁЂЕчЩЬжааЁЦѓвЕвВФмЯэЪмЕНЕЭГЩБОЕФЪЕЪБЪ§ОнЗжЮіФмСІЃЌЬсЩ§ЦѓвЕОЋЯИЛЏЪ§ОндЫгЊЕФЫЎЦНЁЃ | 








