| БрМЭЦМі: |
ЮФеТЯъЯИНщЩмСЫЕЮЕЮздбаЕФЗжВМЪН
KV ДцДЂ Fusion ЕФЛљДЁЩЯЙЙНЈвЛИіФмТњзуЮвУЧвЕЮёГЁОАЕФNewSQL ЁЃ
БОЮФРДздinfoqЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛ. гіЕНЕФЮЪЬт
ЕЮЕЮЕФвЕЮёПьЫйГжајЗЂеЙЃЌЪ§ОнСПКЭЧыЧѓСПМБОчдіГЄЃЌЖдДцДЂЯЕЭГЕШбЙСІгыШеОудіЁЃЫфШЛЗжПтЗжБэдквЛЖЈГЬЖШЩЯПЩвдНтОіЪ§ОнСПКЭЧыЧѓдіМгЕФашЧѓЃЌЕЋЪЧгЩгкЕЮЕЮЖрЬѕвЕЮёЯпЃЈПьГЕЃЌзЈГЕЃЌСНТжГЕЕШЃЉЕФвЕЮёПьЫйБфЛЏЃЌЪ§ОнПтМгзжЖЮМгЫїв§ЕФашЧѓЗЧГЃЦЕЗБЃЌЗжПтЗжБэЗНАИЖдгкЦЕЗБЕФ
Schema БфИќВйзїВЂВЛгбКУЃЌЛсЕМжТ DBA ШЮЮёЗБжиЃЌБфИќжмЦкГЄЃЌВЂЧвЖдОоДѓЕФБэВйзїЛЙЛсЖдЯпЩЯгавЛЖЈгАЯьЁЃЭЌЪБЃЌЗжПтЗжБэЗНАИЖдЖўМЖЫїв§жЇГжВЛгбКУЛђепИљБОВЛжЇГжЁЃ
МјгкЩЯЪіЧщПіЃЌNewSQL Ъ§ОнПтЗНАИОЭГЩЮЊЮвУЧНтОівЕЮёЮЪЬтЕФвЛИіЗНЯђЁЃ
Жў. ПЊдДВњЦЗЕїба
зюПЊЪМЃЌЮвУЧЕїбаСЫПЊдДЕФЗжВМЪН NewSQL ЗНАИЃКTiDBЁЃЫфШЛ TiDB ЪЧЗЧГЃгХауЕФ NewSQL
ВњЦЗЃЌЕЋЪЧЖдгкЮвУЧЕФвЕЮёГЁОАРДЫЕЃЌTiDB ВЂВЛЪЧЗЧГЃЪЪКЯЃЌдвђШчЯТЃК
ЮвУЧашвЊвЛПюИпЭЬЭТЃЌЕЭбгГйЕФЪ§ОнПтНтОіЗНАИЃЌЕЋЪЧ TiDB гЩгквЊТњзуЪТЮёЃЌ2pc ЗНАИЬьШЛЮоЗЈТњзуЕЭбгГйЃЈ100ms
вдФкЕФ 99rtЃЌЩѕжС 50ms ФкЕФ 99rtЃЉ
ЮвУЧЕФЖрЪ§вЕЮёЃЌВЂВЛеце§ашвЊЗжВМЪНЪТЮёЃЌЛђепЫЕПЩвдЭЈЙ§ЦфЫћВЙГЅЛњжЦЃЌШЦЙ§ЗжВМЪНЪТЮёЁЃетЪЧгЩгквЕЮёГЁОАОіЖЈЕФЁЃ
TiDB Ш§ИББОЕФДцДЂПеМфГЩБОЯрЖдБШНЯИпЁЃ
ЮвУЧФкВПвЛаЉРыЯпЪ§ОнЕМШыдкЯпЯЕЭГЕФГЁОАЃЌВЛФмжБНгКЭ TiDB ДђЭЈЁЃ
ЛљгквдЩЯдвђЃЌЮвУЧПЊЦєСЫздбаЗћКЯздМКвЕЮёашЧѓЕФ NewSQL жЎТЗЁЃ
Ш§. ЮвУЧЕФЛљДЁ
ЮвУЧВЂУЛгаДђЫуДг 0 ПЊЗЂвЛИіЭъБИЕФ NewSQL ЯЕЭГЃЌЖјЪЧдкздбаЕФЗжВМЪН KV ДцДЂ Fusion
ЕФЛљДЁЩЯЙЙНЈвЛИіФмТњзуЮвУЧвЕЮёГЁОАЕФ NewSQLЁЃFusion ЪЧВЩгУСЫ Codis МмЙЙЃЌМцШн
Redis авщКЭЪ§ОнНсЙЙЃЌЪЙгУ RocksDB зїЮЊДцДЂв§ЧцЕФ NoSQL Ъ§ОнПтЁЃFusion
дкЕЮЕЮФкВПвбОгаМИАйИівЕЮёдкЪЙгУЃЌЪЧЕЮЕЮжївЊЕФдкЯпДцДЂжЎвЛЁЃ
Fusion ЕФМмЙЙЭМШчЯТЃК
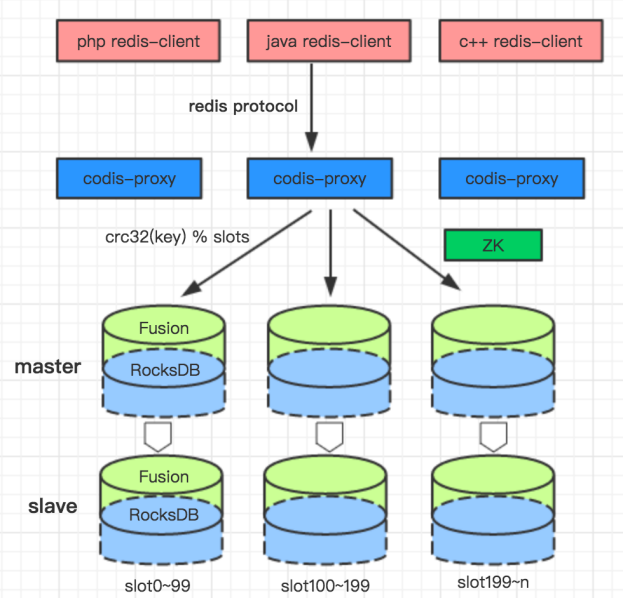
ЮвУЧВЩгУ hash ЗжЦЌЕФЗНЪНРДзіЪ§Он shardingЁЃДгЩЯЭљЯТПДЃЌгУЛЇЭЈЙ§ Redis авщЕФПЭЛЇЖЫОЭПЩвдЗУЮЪ
FusionЃЌгУЛЇЕФЗУЮЪЧыЧѓЗЂЕН proxyЃЌдйгЩ proxy зЊЗЂЪ§ОнЕНКѓЖЫ Fusion ЕФЪ§ОнНкЕуЁЃproxy
ЕНКѓЖЫЪ§ОнНкЕуЕФзЊЗЂЃЌЪЧИљОнЧыЧѓЕФ key МЦЫу hash жЕЃЌШЛКѓЖд slot ЗжЦЌЪ§ШЁгрЃЌЕУЕНвЛИіЙЬЖЈЕФ
slotidЃЌУПИі slotid ЛсЙЬЖЈЕФгГЩфЕНвЛИіДцДЂНкЕуЃЌвдДЫНтОіЪ§ОнТЗгЩЮЪЬтЁЃ
гаСЫвЛИіИпВЂЗЂЃЌЕЭбгГйЃЌДѓШнСПЕФДцДЂВуКѓЃЌЮвУЧвЊзіЕФОЭЪЧдкжЎЩЯЙЙНЈ MySQL авщвдМАЖўМЖЫїв§ЁЃ
ашЧѓ
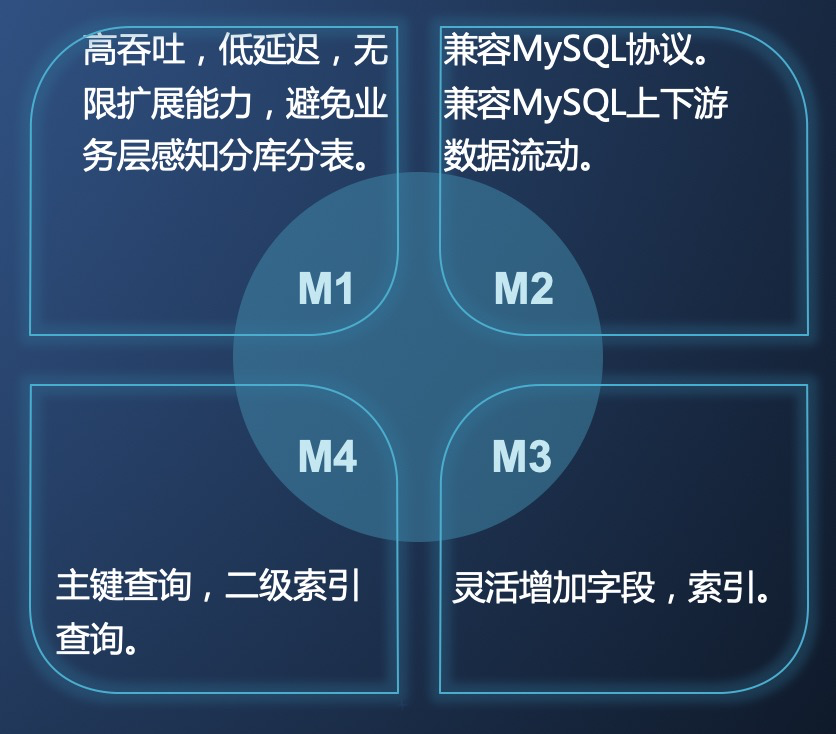
злКЯПМТЧДѓЖрЪ§гУЛЇЖдашЧѓЃЌЮвУЧећРэСЫЮвУЧЕФ NewSQL ашвЊЬсЙЉЕФМИИіКЫаФФмСІЃК
ИпЭЬЭТЃЌЕЭбгГйЃЌДѓШнСП
МцШн MySQL авщМАЯТгЮЩњЬЌ
жЇГжжїМќВщбЏКЭЖўМЖЫїв§ВщбЏ
Schema БфИќСщЛюЃЌВЛгАЯьЯпЩЯЗўЮёЮШЖЈадЁЃ
МмЙЙЩшМЦ
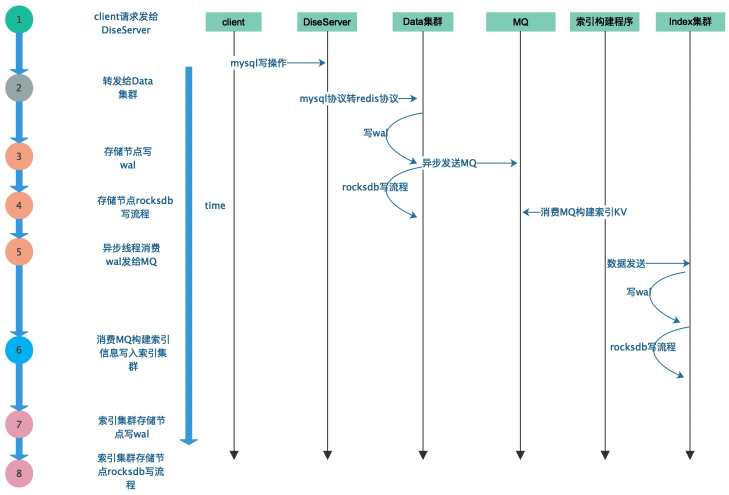
Fusion-NewSQL гЩЯТУцМИИіВПЗжзщГЩЃК
1. НтЮі MySQL авщЕФ DiseServer
2. ДцДЂЪ§ОнЕФ Fusion МЏШК -Data МЏШК
3. ДцДЂЫїв§аХЯЂЕФ Fusion МЏШК -Index МЏШК
4. ИКд№ Schema ЕФЙмРэХфжУжааФ -ConfigServer
5. вьВНЙЙНЈЫїв§ГЬађ -Consumer ИКд№ЯћЗб Data МЏШКаДЕН MQ жаЕФ MySQL-Binlog
ИёЪНЪ§ОнЃЌИљОн schema аХЯЂЃЌЩњГЩЫїв§Ъ§ОнаДШы Index МЏШКЁЃ
6. ЭтВПвРРЕЃЌMQЃЌZookeeper
МмЙЙЭМШчЯТЃК
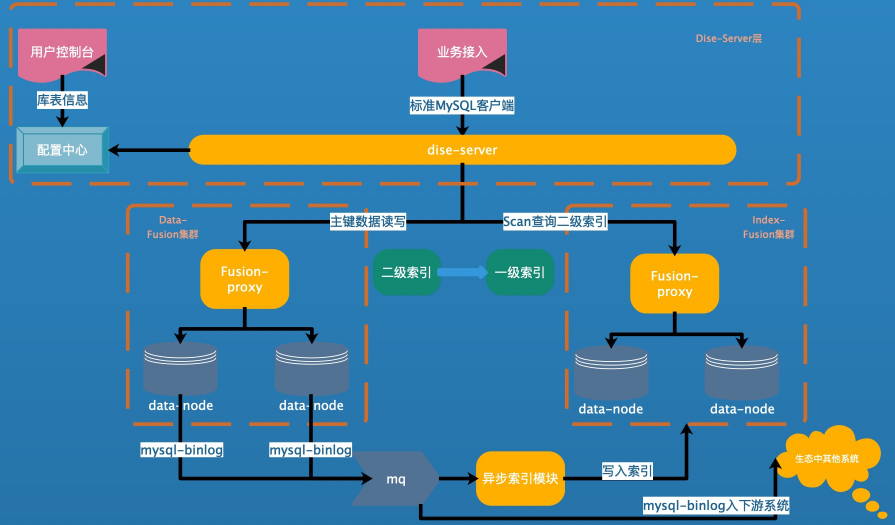
ММЪѕЬєеНМАЗНАИ
1.SQL БэзЊ Hashmap
MySQL ЕФБэНсЙЙЪ§ОнШчКЮзЊГЩ Redis ЕФЪ§ОнНсЙЙЪЧЮвУЧУцСйЕФЕквЛИіЮЪЬтЁЃ
ШчЯТЭМЃК
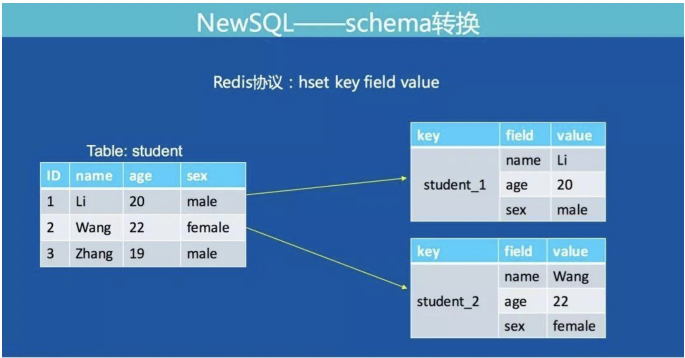
ЮвУЧНЋ MySQL БэЕФвЛааМЧТМзЊГЩ Redis ЕФвЛИі Hashmap НсЙЙЁЃHashmap ЕФ
key гЩБэУћ + жїМќжЕзщГЩЃЌТњзуСЫШЋОжЮЈвЛЕФЬиадЁЃЯТЭМеЙЪОСЫ MySQL ЭЈЙ§жїМќВщбЏзЊЛЛЮЊ Redis
авщЕФЗНЪНЃК
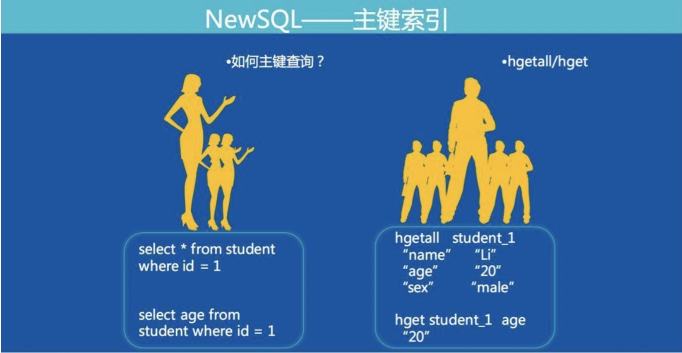
Г§СЫЪ§ОнЃЌЫїв§вВашвЊДцДЂдк Fusion-NewSQL жаЃЌКЭЪ§ОнДцГЩ hashmap ВЛЭЌЃЌЫїв§ДцДЂГЩ
key-value НсЙЙЁЃИљОнЫїв§РраЭВЛЭЌЃЌзщГЩ key-value ЕФИёЪНЛЙгавЛЕуЯИЮЂЕФВюБ№ (ЯТУцЕФИёЪНЮЊСЫПДЦ№РДжБЙлЃЌЪЕМЪЩЯЗжИєЗћЃЌindexname
ЖМЪЧзіЙ§БрТыЕФ)ЃК
1. ЮЈвЛЫїв§ЃК
Key: table_indexname_indexColumnsValue Value: Rowkey
2. ЗЧЮЈвЛЫїв§ЃК
Key: table_indexname_indexColumnsValue_Rowkey ValueЃКnull
дьГЩетжжВювьЕФдвђОЭЪЧЗЧЮЈвЛЫїв§дкМгШы Rowkey жЎЧАЕФВПЗжЪЧгаПЩФмжиИДЕФЃЌЮоЗЈШЋОжЮЈвЛЁЃСэЭтЃЌЮЈвЛЫїв§ВЛНЋ
Rowkey БрТыдк key жаЃЌЪЧвђЮЊдкВщбЏгяОфЪЧЕЅДПЕФЁА=ЁБВщбЏЕФЪБКђжБНг get ВйзїОЭПЩвдевЕНЖдгІЕФ
Rowkey ФкШнЃЌЖјВЛашвЊЭЈЙ§ scanЃЌетбљЕФаЇТЪИќИпЁЃ
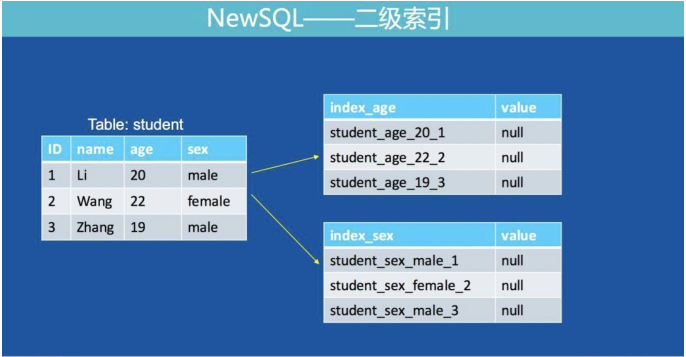
КѓУцЛсдкВщбЏСїГЬжажиЕуНВЪіШчКЮЭЈЙ§ЖўМЖЫїв§ВщбЏЕНЪ§ОнЁЃ
2. Ъ§ОнКЭЫїв§вЛжТад
вђЮЊЪ§ОнКЭЫїв§ЗжБ№ДцДЂдкВЛЭЌ Fusion МЏШКЃЌЪ§ОнКЭЫїв§ЕФвЛжТадБЃжЄОЭГЩСЫ Fusion-New
ЯЕЭГУцСйЕФвЛИіЙиМќЕуЃЌдкУЛгаЗжВМЪНЪТЮёЕФЧщПіЯТЃЌЮвУЧЕБЧАбЁдёСЫБЃжЄЪ§ОнЫїв§ЕФзюжевЛжТадЁЃгУЛЇаДШыЪ§ОндкЪ§ОнМЏШКжаПЊЦє
RocksDB ЕФЕЅЛњЪТЮяЃЌЭЌЪБАДСДНгБЃађЃЌетбљЪ§ОнСїШы MQ ЕФЪБКђОЭЪЧгаађЕФЁЃвьВНФЃПщДг MQ
жаЯћЗбГіРДдйХњСПаДШыЕНЫїв§МЏШКЃЌећИіСїГЬОЭБЃжЄЕФЫїв§Ъ§ОнЕФЙЙНЈгыЪ§ОнМЏШКецЪЕЕФЫГађвЛжТЁЃЕБШЛЃЌетжаМфДцдквЛИіЪБМфДАПкЕФЪ§ОнВЛвЛжТЃЌетИіЪБМфШЁОігк
MQ ЕФЭЬЭТФмСІЁЃ
3. ЖўМЖЫїв§ВщбЏ
ЯТУцЪЧвЛИіЪЙгУЖўМЖЫїв§ВщбЏЪ§ОнЕФАИР§ЃК
dise-server ЛсИљОнгУЛЇВщбЏЬѕМўКЭЕБЧАЫљгаЫїв§зіЦЅХфЃЌевЕНЗћКЯЕФЫїв§ЃЌШЛКѓЭЈЙ§ Redis
ЕФ scan УќСюЃЌАДЧАзКЫбЫї index МЏШКЕФЪ§ОнЃЌЛёШЁЗћКЯЬѕМўЕФжїМќЁЃ
ШчЯТЭМЃК
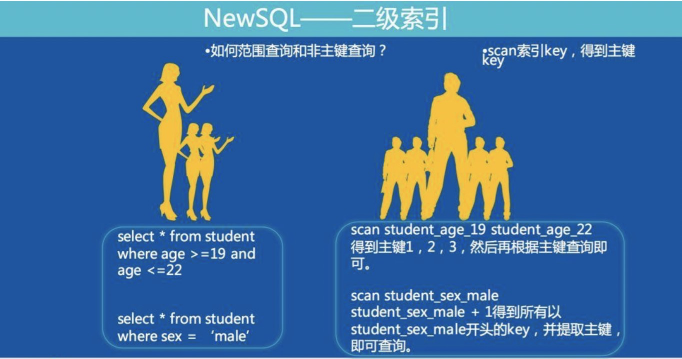
ЭЈЙ§жїМќЃЌПЩвджБНгЕН Data МЏШКВщЕНЯргІЕФЪ§ОнЁЃ
ИљОнЩЯУцЫїв§Ъ§ОнЕФИёЪНПЩвдПДЕНЃЌscan ЗЖЮЇЕФЪБКђЃЌЧАзКБиаыЙЬЖЈЃЌгГЩфЕН SQL гяОфЕНЪБКђЃЌвтЮЖзХ
where ЕНЬѕМўжаЃЌЗЖЮЇВщбЏжЛФмгавЛИізжЖЮЃЌЖјВЛФмЖрИізжЖЮЁЃ
БШШчЃК

Ыїв§ЪЧ age КЭ name СНИізжЖЮЕФСЊКЯЫїв§ЁЃ
ШчЙћВщбЏгяОфШчЯТЃК
select * from student where age > 20 and name >ЁЎWЁЏ;
scan ОЭУЛгаАьЗЈШЗЖЈЧАзКЃЌвВОЭЮоЗЈЭЈЙ§ index_age_name етИіЫїв§ВщбЏЕНТњзуЬѕМўЕФЪ§ОнЃЌЫљвдЪЙгУ
KV аЮЪНДцДЂЕНЫїв§жЛФмТњзу where ЬѕМўжагавЛИізжЖЮЪЧЗЖЮЇВщбЏЁЃЕБШЛПЩвдЭЈЙ§НЋСЊКЯЫїв§ЗжПЊДцЗХЃЌЖрДЮНЛЛЅЫбЫїШЁНЛМЏЕФЗНЪННтОіЃЌЕЋЪЧетОЭКЭЮвУЧМѕЩй
RPC ДЮЪ§ЃЌНЕЕЭбгГйЕФЩшМЦГѕждЯрЮЅБГСЫЁЃЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧв§ШыСЫ Elastic Search
ЫбЫїв§ЧцЁЃ
МмЙЙЭМШчЯТЃК
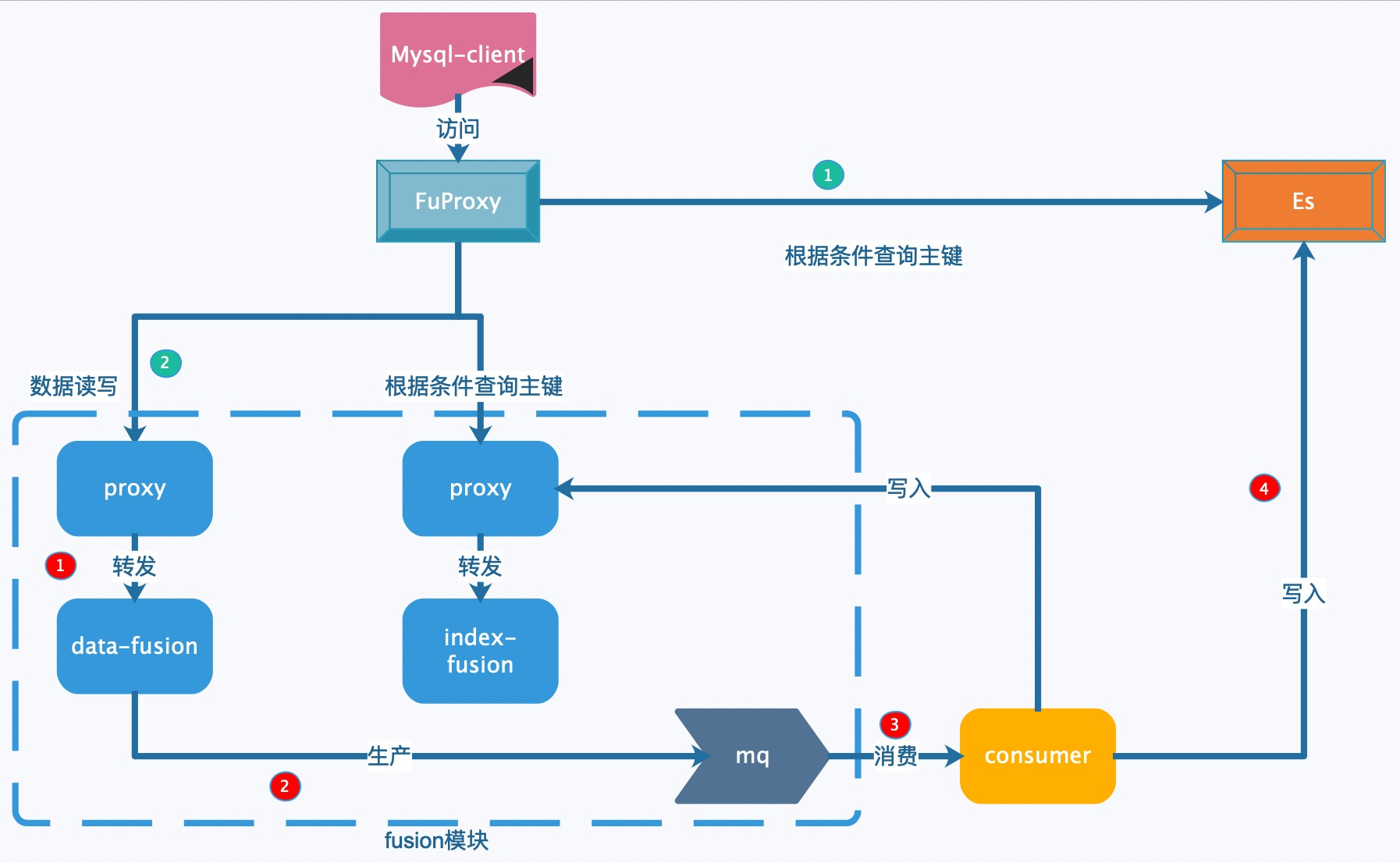
ЮвУЧНЈвщгУЛЇНЋашвЊИДдгВщбЏЕФзжЖЮЩшжУЮЊ ES Ыїв§ЃЌconsumer ЯћЗб MQ ЕФЪБКђНЋетаЉзжЖЮЪ§ОнаДвЛЗнЕН
ES жаЃЌетбљЖдгкЖдВщбЏЬѕМўМђЕЅЃЌбгГйУєИаЕФВщбЏЃЌЪЙгУ Index МЏШКЕФЪ§ОнЃЛЖдЬѕМўИДдгЃЌбгГйВЛУєИаЕФВщбЏЪЙгУ
ESЁЃетбљНтОіСЫЖўМЖЫїв§ЙІФмЗсИЛадЮЪЬтЁЃ
4. ЩњЬЌЙЙНЈ
вЛИіЕЅЖРЕФДцДЂВњЦЗНтОіЫљгаЮЪЬтЕФЪБДњдчвбОЙ§ШЅЃЌЪ§ОнЙТЕКЪЧУЛгаАьЗЈКмКУЗўЮёвЕЮёЕФЃЌШчКЮгыЕЮЕЮЯжгаИіИїИіЪ§ОнЯЕЭГДђЭЈЪ§ОнЃЌГЩСЫЮвУЧБиаыУцЖдЕФЮЪЬтЁЃЯТУцЗжЪ§ОнСїГіЕНЦфЫћЯЕЭГКЭДгЦфЫћЯЕЭГЕМШыСНИіЗНУцРДВћЪі
Fusion-NewSQL ЕФЪ§ОнСїЖЏЗНАИЁЃ
4.1. Fusion-NewSQL ЕНЦфЫћДцДЂЯЕЭГ
Fusion-NewSQL ЪЧвЛИіаТЯЕЭГЃЌУЛАьЗЈЖЬЪБМфШУИїИіЪ§ОнЯЕЭГЮЊЮвУЧзіЪЪХфЁЃМШШЛ Fusion-NewSQL
вбОгаСЫ Schema аХЯЂЃЌФЧУДЭЈЙ§МцШн MySQL ЕФ Binlog ИёЪНЃЌНЋ Fusion-NewSQL
дкЪ§ОнСДТЗжаЮБзАГЩ MySQLЃЌОЭПЩвджБНгЪЙгУ Mysql ЕФЯТгЮЪ§ОнСїЖЏСДТЗЁЃетбљЕФЗНЪНгУзюаЁЕФЙЄзїСПзюДѓГЬЖШзіЕНСЫМцШнЁЃ
4.2.Hive ЕН Fusion-NewSQL
Fusion-NewSQL ЛЙжЇГжНЋРыЯпЕФ Hive БэжаЕФЪ§ОнЭЈЙ§ Fusion-NewSQL ЬсЙЉЕФ
FastLoadЃЈDTSЃЉЙЄОпЃЌНЋ Hive БэЪ§ОнзЊШыЕН Fusion-NewSQLЃЌТњзуРыЯпЪ§ОнЕНдкЯпЕФЪ§ОнСїЖЏЁЃ
ШчЙћгУЛЇздМКЭъГЩЪ§ОнСїзЊЃЌвЛАуЛсЩЈУш Hive БэЃЌШЛКѓЙЙНЈ MySQL ЕФаДШыгяОфЃЌвЛЬѕЬѕНЋЪ§ОнаДШыЕН
Fusion-NewSQLЃЌ
СїГЬШчЯТУцетбљЃК
ДгЩЯУцЕФСїГЬПЩвдПДГіетжжЧЈвЦЗНЪНгаМИИіЮЪЬтЃК
1. УПЬѕ Hive Ъ§ОнЖМвЊОЙ§НЯГЄСДТЗЃЌЪ§ОнЕМШыКФЪБНЯГЄЁЃ
2. РыЯпЦНЬЈЕФЪ§ОнСПДѓЃЌЭЬЭТИпЃЌЪ§ОнЕМШыжБНгДѓЗљЬсЩ§дкЯпЯЕЭГЕФ QPSЃЌЖддкЯпЯЕЭГЕФЮШЖЈадгаНЯДѓгАЯьЁЃ
ДгЩЯУцЕФЭДЕуПЩвдПДГіРДЃЌжївЊЕФЮЪЬтЪЧРыЯпЪ§ОнЕМШыЪЙгУСЫдкЯпЯЕЭГИДдгЕФ IO СДТЗЁЃЫљвдШчКЮШЦЙ§дкЯпЕФГЄ
IO СДТЗЃЌзіХњСПЕМШыОЭГЩСЫНтОіетИіЮЪЬтЕФЙиМќЁЃЮвУЧЩшМЦСЫ Fastload Ъ§ОнЕМШыЦНЬЈЃЌШЦЙ§дкЯп
IO ТЗОЖ
СїГЬШчЯТЃК
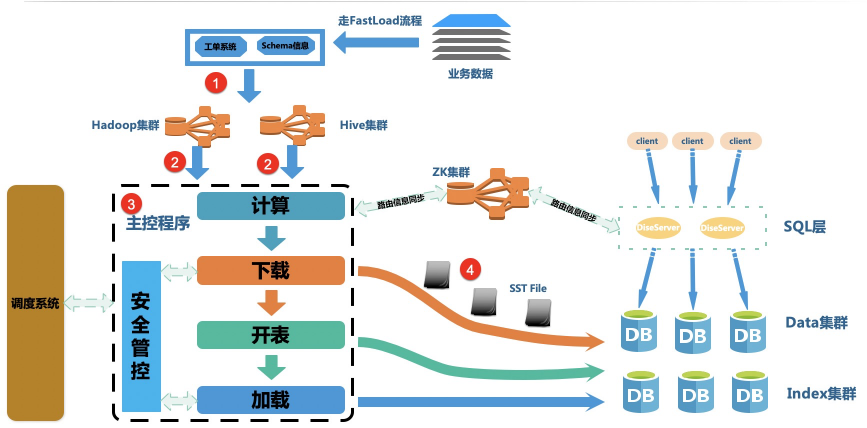
ЭЈЙ§ Hadoop ВЂааМЦЫуЃЌНЋашвЊЕМШыЕФ Hive Ъ§ОнжБНгЙЙНЈГЩ Fusion-NewSQL ФмЪЖБ№ЕФ
sst ЮФМўЁЃFusion-NewSQL жБНгНЋ sst ЮФМўДгдЖЖЫЯТдиЕНБОЕиЃЌШЛКѓЪЙгУДцДЂНкЕуЭЈЙ§
Rocksdb ЬсЙЉ ingest ЙІФмЃЌжБНгНЋ sst ЮФМўМгдиЕН Fusion-NewSQL жаЃЌгУЛЇПЩвдЖСЕНМгдиЕН
sst ЮФМўжаЕФЪ§ОнЁЃЭЈЙ§етбљЕФдЄЯШЙЙНЈ sst ЮФМўЃЌжБНгЮФМўЭјТчДЋЪфКЭДцДЂв§ЧцжБНгМгдиЕФВНжшЃЌОЭБмУтСЫЪ§ОнЕМШызпдкЯп
IO ИДдгСїГЬЃЌНтОіСЫЮШЖЈадЮЪЬтЃЌЭЌЪБНЋЪ§ОнЕМШыКФЪБМѕЩйЕНдРДЕФ 1/10ЁЃ
змНс
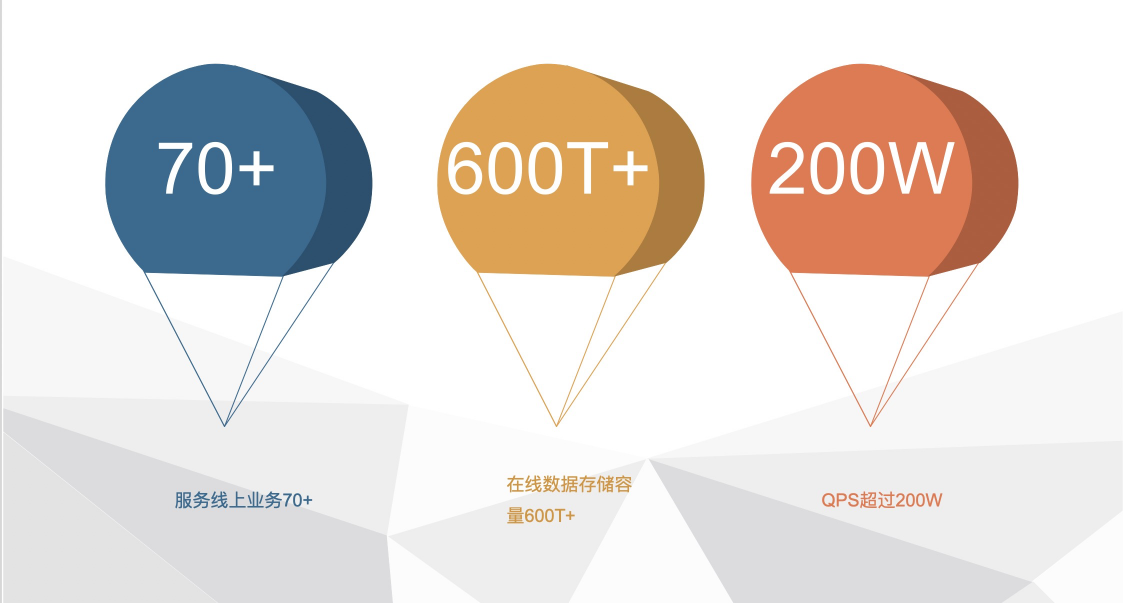
ЭЈЙ§НтОіЩЯУцЕФММЪѕЕуЃЌЮвУЧгУСЫНЯаЁЕФДњМлЃЌЙЙНЈСЫвЛИіЛљгк KV ДцДЂЕФ NewSQL ЯЕЭГЃЌВЂЧвПьЫйНЋ
Fusion-NewSQL ЯЕЭГНгШыЕНЕЮЕЮећЬхЕФЪ§ОнСДТЗжаЁЃЫфШЛетВЛЪЧвЛИіЭъБИЕФ NewSQL ЯЕЭГЃЌЕЋвбОПЩвдТњзуДѓЖрЪ§вЕЮёГЁОАЕФашвЊЃЌЧаЪЕЪЕЯжСЫ
20% ЙЄзїСПТњзу 80% ЙІФмЕФашЧѓЁЃЕБЧА Fusion-NewSQL вбОНгШыЖЉЕЅЁЂдЄЙРЁЂеЫЕЅЁЂгУЛЇжааФЁЂНЛвзв§ЧцЕШКЫаФвЕЮёЃЌзмЕФЪ§ОнШчЯТЭМЃК
КѓајЙЄзї
гаЯожЦЕФЪТЮяжЇГжЃЌБШШчШУвЕЮёЙцЛЎТфдквЛИіНкЕуЕФЪ§ОнПЩвджЇГжЕЅЛњПчааЪТЮёЃЛ
ЪЕЪБЫїв§ЬцДњвьВНЫїв§ЃЌТњзуМДаДМДЖСЁЃФПЧАвбОгавЛИіаДДЉ + ВЙГЅЛњжЦЕФЗНАИЃЌдкУЛгаЗжВМЪНЪТЮёЕФЧАЬсЯТТњзуе§ГЃзДЬЌЕФЪЕЪБЫїв§ЃЌвьГЃЧщПіЯТБЃжЄЪ§ОнЫїв§зюжевЛжТЕФЗНАИЃЛ
ИќЖрЕФ SQL авщКЭЙІФмжЇГжЁЃ
| 








