| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌБОЮФжївЊНщЩмСЫЪєадЭМЕФзщГЩВПЗжЃЌЪєадЭМФЃаЭЕФЛљБОИХФюЃЌЭМаЮжаБщРњЕФТЗОЖЃЌNeo4jЕФФЃЪНЕШЃЌЯЃЭћФмЖдФњгаЫљАяжњЁЃ |
|
дкЩюШыбЇЯАЭМаЮЪ§ОнПтжЎЧАЃЌЪзЯШРэНтЪєадЭМЕФЛљБОИХФюЁЃвЛИіЪєадЭМЪЧгЩЖЅЕуЃЈVertexЃЉЃЌБпЃЈEdgeЃЉЃЌБъЧЉЃЈLableЃЉЃЌЙиЯЕРраЭКЭЪєадЃЈPropertyЃЉзщГЩЕФгаЯђЭМЁЃЖЅЕувВГЦзїНкЕуЃЈNodeЃЉЃЌБпвВГЦзїЙиЯЕЃЈRelationshipЃЉЃЛдкЭМаЮжаЃЌНкЕуКЭЙиЯЕЪЧзюживЊЕФЪЕЬхЃЌЫљгаЕФНкЕуЪЧЖРСЂДцдкЕФЃЌЮЊНкЕуЩшжУБъЧЉЃЌФЧУДгЕгаЯрЭЌБъЧЉЕФНкЕуЪєгквЛИіЗжзщЃЌвЛИіМЏКЯЃЛЙиЯЕЭЈЙ§ЙиЯЕРраЭРДЗжзщЃЌРраЭЯрЭЌЕФЙиЯЕЪєгкЭЌвЛИіМЏКЯЁЃЙиЯЕЪЧгаЯђЕФЃЌЙиЯЕЕФСНЖЫЪЧЦ№ЪМНкЕуКЭНсЪјНкЕуЃЌЭЈЙ§гаЯђЕФМ§ЭЗРДБъЪЖЗНЯђЃЌНкЕужЎМфЕФЫЋЯђЙиЯЕЭЈЙ§СНИіЗНЯђЯрЗДЕФЙиЯЕРДБъЪЖЁЃНкЕуПЩгаСуИіЃЌвЛИіЛђЖрИіБъЧЉЃЌЕЋЪЧЙиЯЕБиаыЩшжУЙиЯЕРраЭЃЌВЂЧвжЛФмЩшжУвЛИіЙиЯЕРраЭЁЃNeo4jЭМаЮЪ§ОнПтЕФВщбЏгябдЪЧCypherЃЌгУгкВйзїЪєадЭМЃЌЪЧЭМаЮгябджаЪТЪЕЩЯЕФБъзМЁЃ
вЛЁЂЭМаЮЪ§ОнПтЕФЛљБОИХФю
Neo4jДДНЈЕФЭМЃЈGraphЃЉЛљгкЪєадЭМФЃаЭЃЌдкИУФЃаЭжаЃЌУПИіЪЕЬхЖМгаIDЃЈIdentityЃЉЮЈвЛБъЪЖЃЌУПИіНкЕугЩБъЧЉЃЈLableЃЉЗжзщЃЌУПИіЙиЯЕЖМгавЛИіЮЈвЛЕФРраЭЃЌЪєадЭМФЃаЭЕФЛљБОИХФюгаЃК
ЪЕЬхЃЈEntityЃЉЪЧжИНкЕуЃЈNodeЃЉКЭЙиЯЕЃЈRelationshipЃЉЃЛТЗОЖЃЈPathЃЉЪЧжИгЩЦ№ЪМНкЕуКЭжежЙНкЕужЎМфЕФЪЕЬхЃЈНкЕуКЭЙиЯЕЃЉЙЙГЩЕФгаађзщКЯЃЛ
УПИіЪЕЬхЖМгавЛИіЮЈвЛЕФIDЃЛ
УПИіЪЕЬхЖМгаСуИіЃЌвЛИіЛђЖрИіЪєадЃЌвЛИіЪЕЬхЕФЪєадМќЪЧЮЈвЛЕФЃЛ
УПИіНкЕуЖМгаСуИіЃЌвЛИіЛђЖрИіБъЧЉЃЌЪєгквЛИіЛђЖрИіЗжзщЃЛ
УПИіЙиЯЕЖМжЛгавЛИіРраЭЃЌгУгкСЌНгСНИіНкЕуЃЛ
БъМЧЃЈTokenЃЉЪЧЗЧПеЕФзжЗћДЎЃЌгУгкБъЪЖБъЧЉЃЈLableЃЉЃЌЙиЯЕРраЭЃЈRelationship TypeЃЉЃЌЛђЪєадМќЃЈProperty
KeyЃЉЃЛ
БъЧЉЃКгУгкБъМЧНкЕуЕФЗжзщЃЌЖрИіНкЕуПЩвдгаЯрЭЌЕФБъЧЉЃЌвЛИіНкЕуПЩвдгаЖрИіLableЃЌLableгУгкЖдНкЕуНјааЗжзщЃЛ
ЙиЯЕРраЭЃКгУгкБъМЧЙиЯЕЕФРраЭЃЌЖрИіЙиЯЕПЩвдгаЯрЭЌЕФЙиЯЕРраЭЃЛ
ЪєадМќЃКгУгкЮЈвЛБъЪЖвЛИіЪєадЃЛ
ЪєадЃЈPropertyЃЉЪЧвЛИіМќжЕЖдЃЈKey/Value PairЃЉЃЌУПИіНкЕуЛђЙиЯЕПЩвдгавЛИіЛђЖрИіЪєадЃЛЪєаджЕПЩвдЪЧБъСПРраЭЃЌЛђетБъСПРраЭЕФСаБэЃЈЪ§зщЃЉЃЛ
ЖўЁЂЭМаЮЪОР§
дкЯТУцЕФЭМаЮжаЃЌДцдкШ§ИіНкЕуКЭСНИіЙиЯЕЙВ5ИіЪЕЬхЃЛPersonКЭMovieЪЧLableЃЌACTED_IDКЭDIRECTEDЪЧЙиЯЕРраЭЃЌnameЃЌtitleЃЌrolesЕШЪЧНкЕуКЭЙиЯЕЕФЪєадЁЃ
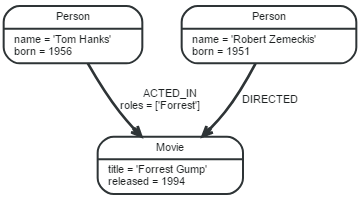
ЪЕЬхАќРЈНкЕуКЭЙиЯЕЃЌНкЕугаБъЧЉКЭЪєадЃЌЙиЯЕЪЧгаЯђЕФЃЌСДНгСНИіНкЕуЃЌОпгаЪєадКЭЙиЯЕРраЭЁЃ
1ЃЌЪЕЬх
дкЪОР§ЭМаЮжаЃЌАќКЌШ§ИіНкЕуЃЌЗжБ№ЪЧЃК
АќКЌСНИіЙиЯЕЃЌЗжБ№ЪЧЃК
СНИіЙиЯЕРраЭЃКACTED_INКЭDIRECTEDЃЌ
СНИіЙиЯЕЃКСЌНгnameЪєадЮЊTom HankНкЕуКЭMovieНкЕуЕФЙиЯЕЃЌСЌНгnameЪєадЮЊForrest
GumpЕФНкЕуКЭMovieНкЕуЕФЙиЯЕЁЃ
ЦфжавЛИіЙиЯЕШчЯТЭМЃК

2ЃЌБъЧЉЃЈLableЃЉ
дкЭМаЮНсЙЙжаЃЌБъЧЉгУгкЖдНкЕуНјааЗжзщЃЌЯрЕБгкНкЕуЕФРраЭЃЌгЕгаЯрЭЌБъЧЉЕФНкЕуЪєгкЭЌвЛИіЗжзщЁЃвЛИіНкЕуПЩвдгЕгаСуИіЃЌвЛИіЛђЖрИіБъЧЉЃЌвђДЫЃЌвЛИіНкЕуПЩвдЪєгкЖрИіЗжзщЁЃЖдЗжзщНјааВщбЏЃЌФмЙЛЫѕаЁВщбЏЕФНкЕуЗЖЮЇЃЌЬсИпВщбЏЕФадФмЁЃ
дкЪОР§ЭМаЮжаЃЌгаСНИіБъЧЉPersonКЭMovieЃЌСНИіНкЕуЪЧPersonЃЌвЛИіНкЕуЪЧMovieЃЌБъЧЉгаЕуЯёНкЕуЕФРраЭЃЌЕЋЪЧЃЌУПИіНкЕуПЩвдгаЖрИіБъЧЉЁЃ
3ЃЌЪєадЃЈPropertyЃЉ
ЪєадЪЧвЛИіМќжЕЖдЃЈKey/ValueЃЉЃЌгУгкЮЊНкЕуЛђЙиЯЕЬсЙЉаХЯЂЁЃвЛАуЧщПіЯТЃЌУПИіНкЕуЖМгЩnameЪєадЃЌгУгкУќУћНкЕуЁЃ
дкЪОР§ЭМаЮжаЃЌPersonНкЕугаСНИіЪєадnameКЭbornЃЌMovieНкЕугаСНИіЪєадЃКtitleКЭreleasedЃЌ
ЙиЯЕРраЭACTED_INгавЛИіЪєадЃКrolesЃЌИУЪєаджЕЪЧвЛИіЪ§зщЃЌЖјЙиЯЕРраЭЮЊDIRECTEDЕФЙиЯЕУЛгаЪєад
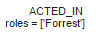
Ш§ЁЂБщРњЃЈTraversalЃЉ
БщРњвЛИіЭМаЮЃЌЪЧжИбизХЙиЯЕМАЦфЗНЯђЃЌЗУЮЪЭМаЮЕФНкЕуЁЃЙиЯЕЪЧгаЯђЕФЃЌСЌНгСНИіНкЕуЃЌДгЦ№ЪМНкЕубизХЙиЯЕЃЌвЛВНвЛВНЕМКНЃЈnavigateЃЉЕННсЪјНкЕуЕФЙ§ГЬНазіБщРњЃЌБщРњОЙ§ЕФНкЕуКЭЙиЯЕЕФгаађзщКЯГЦзїТЗОЖЃЈPathЃЉЁЃ
дкЪОР§ЭМаЮжаЃЌВщевTom HanksВЮбнЕФЕчгАЃЌБщРњЕФЙ§ГЬЪЧЃКДгTom HanksНкЕуПЊЪМЃЌбизХACTED_INЙиЯЕЃЌбАевБъЧЉЮЊMovieЕФФПБъНкЕуЁЃ
БщРњЕФТЗОЖШчЭМЃК

ЫФЁЂЭМаЮЪ§ОнПтЕФФЃЪН
Neo4jЕФФЃЪНЃЈSchemaЃЉЭЈГЃЪЧжИЫїв§ЃЌдМЪјКЭЭГМЦЃЌЭЈЙ§ДДНЈФЃЪНЃЌNeo4jФмЙЛЛёЕУВщбЏадФмЕФЬсЩ§КЭНЈФЃЕФБуРћЃЛNeo4jЪ§ОнПтЕФФЃЪНПЩбЁЕФЃЌвВПЩвдЪЧЮоФЃЪНЕФЁЃ
1ЃЌЫїв§
ЭМаЮЪ§ОнПтвВФмДДНЈЫїв§ЃЌгУгкЬсИпЭМаЮЪ§ОнПтЕФВщбЏадФмЁЃКЭЙиЯЕаЭЪ§ОнПтвЛбљЃЌЫїв§ЪЧЭМаЮЪ§ОнЕФвЛИіШпгрИББОЃЌЭЈЙ§ЖюЭтЕФДцДЂПеМфКЭЮўЩќЪ§ОнаДВйзїЕФадФмЃЌРДЬсИпЪ§ОнЫбЫїЕФадФмЃЌБмУтДДНЈВЛБивЊЕФЫїв§ЃЌетбљФмЙЛМѕЩйЪ§ОнИќаТЕФадФмЫ№ЪЇЁЃ
Neo4jдкЭМаЮНкЕуЕФвЛИіЛђЖрИіЪєадЩЯДДНЈЫїв§ЃЌдкЫїв§ДДНЈЭъГЩжЎКѓЃЌЕБЭМаЮЪ§ОнИќаТЪБЃЌNeo4jИКд№Ыїв§ЕФздЖЏИќаТЃЌЫїв§ЕФЪ§ОнЪЧЪЕЪБЭЌВНЕФЃЛдкВщбЏБЛЫїв§ЕФЪєадЪБЃЌNeo4jздЖЏгІгУЫїв§ЃЌвдЛёЕУВщбЏадФмЕФЬсЩ§ЁЃ
Р§ШчЃЌЪЙгУCypherДДНЈЫїв§ЃК
CREATE INDEX
ON :Person(firstname)
CREATE INDEX ON :Person(firstname, surname) |
2ЃЌдМЪј
дкЭМаЮЪ§ОнПтжаЃЌФмЙЛДДНЈЫФжжРраЭЕФдМЪјЃК
НкЕуЪєаджЕЮЈвЛдМЪјЃЈUnique node propertyЃЉЃКШчЙћНкЕуОпгажИЖЈЕФБъЧЉКЭжИЖЈЕФЪєадЃЌФЧУДетаЉНкЕуЕФЪєаджЕЪЧЮЈвЛЕФ
НкЕуЪєадДцдкдМЪјЃЈNode property existenceЃЉЃКДДНЈЕФНкЕуБиаыДцдкБъЧЉКЭжИЖЈЕФЪєад
ЙиЯЕЪєадДцдкдМЪјЃЈRelationship property existenceЃЉЃКДДНЈЕФЙиЯЕДцдкРраЭКЭжИЖЈЕФЪєад
НкЕуМќдМЪјЃЈNode KeyЃЉЃКдкжИЖЈЕФБъЧЉжаЕФНкЕужаЃЌжИЖЈЕФЪєадБиаыДцдкЃЌВЂЧвЪєаджЕЕФзщКЯЪЧЮЈвЛЕФ
Р§ШчЃЌЪЙгУCypherДДНЈдМЪјЃК
CREATE CONSTRAINT
ON (book:Book) ASSERT book.isbn IS UNIQUE;
CREATE CONSTRAINT ON (book:Book) ASSERT exists(book.isbn);
CREATE CONSTRAINT ON ()-[like:LIKED]-() ASSERT
exists(like.day);
CREATE CONSTRAINT ON (n:Person) ASSERT (n.firstname,
n.surname) IS NODE KEY; |
3ЃЌЭГМЦаХЯЂ
ЕБЪЙгУCypherВщбЏЭМаЮЪ§ОнПтЪБЃЌCypherНХБОБЛБрвыГЩвЛИіжДааМЦЛЎЃЌжДааИУжДааМЦЛЎЛёЕУВщбЏНсЙћЁЃЮЊСЫЩњГЩвЛИіадФмгХЛЏЕФжДааМЦЛЎЃЌNeo4jашвЊЪеМЏЭГМЦаХЯЂвдЖдВщбЏНјаагХЛЏЁЃЕБЭГМЦаХЯЂБфЛЏЕНвЛЖЈЕФИГжЕЪБЃЌNeo4jашвЊжиаТЩњГЩжДааМЦЛЎЃЌвдБЃжЄCypherВщбЏЪЧадФмгХЛЏЕФЃЌNeo4jДцДЂЕФЭГМЦаХЯЂАќРЈЃК
The number of nodes with a certain label.
Selectivity per index.
The number of relationships by type.
The number of relationships by type, ending or starting
from a node with a specific label.
ФЌШЯЧщПіЯТЃЌNeo4jздЖЏИќаТЭГМЦаХЯЂЃЌЕЋЪЧЃЌЭГМЦаХЯЂЕФИќаТВЛЪЧЪЕЪБЕФЃЌИќаТЭГМЦаХЯЂПЩФмЪЧвЛИіЗЧГЃКФЪБЕФВйзїЃЌвђДЫЃЌNeo4jдкКѓЬЈдЫааЃЌВЂЧвжЛгаЕББфЛЏЕФЪ§ОнДяЕНвЛЖЈЕФуажЕЪБЃЌВХЛсИќаТЭГМЦаХЯЂЁЃ
Neo4j keeps the statistics up to date in two different
ways. For label counts for example, the number is
updated whenever you set or remove a label from a
node. For indexes, Neo4j needs to scan the full index
to produce the selectivity number. Since this is potentially
a very time-consuming operation, these numbers are
collected in the background when enough data on the
index has been changed.
Neo4jАбжДааМЦЛЎБЛЛКДцЦ№РДЃЌдкЭГМЦаХЯЂБфЛЏжЎЧАЃЌжДааМЦЛЎВЛЛсБЛжиаТЩњГЩЁЃЭЈЙ§ХфжУбЁЯюЃЌNeo4jФмЙЛПижЦжДааМЦЛЎЕФжиаТЩњГЩЃК
dbms.index_sampling.background_enabledЃКЪЧЗёдкКѓЬЈЭГМЦЫїв§аХЯЂЃЌгЩгкCypherВщбЏЕФжДааМЦЛЎЪЧИљОнЭГМЦаХЯЂЩњГЩЕФЃЌМАЪБИќаТЫїв§ЕФЭГМЦЪ§ОнЖдЩњГЩадФмгХЛЏЕФжДааМЦЛЎЗЧГЃживЊЃЛ
dbms.index_sampling.update_percentageЃКдкИќаТЫїв§ЕФЭГМЦаХЯЂжЎЧАЃЌЫїв§жагаЖрДѓБШР§ЕФЪ§ОнБЛИќаТЃЛ
cypher.statistics_divergence_thresholdЃКЕБЭГМЦаХЯЂБфЛЏЪБЃЌNeo4jВЛЛсСЂМДИќаТCypherВщбЏЕФжДааМЦЛЎЃЛжЛгаЕБЭГМЦаХЯЂБфЛЏЕНвЛЖЈЕФГЬЖШЪБЃЌNeo4jВХЛсжиаТЩњГЩжДааМЦЛЎЁЃ
| 








