| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФжївЊЭЈЙ§ЪОР§НщЩмMySQLжаЕФЕЅСаЫїв§ЁЂзщКЯЫїв§ЕФДДНЈгыЪЙгУЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
Ыїв§гаКмЖрЃЌЧвАДВЛЭЌЕФЗжРрЗНЪНЃЌгжгаКмЖржжЗжРрЁЃВЛЭЌЕФЪ§ОнПтЃЌЖдЫїв§ЕФжЇГжЧщПівВВЛОЁЯрЭЌЁЃ
Ыїв§ЕФДДНЈЃК
НЈБэЪБДДНЈЃК
CREATE TABLE
БэУћ(
зжЖЮУћ Ъ§ОнРраЭ [ЭъећаддМЪјЬѕМў],
ЁЁЃЌ
[UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[Ыїв§Ућ](зжЖЮУћ1 [(ГЄЖШ)] [ASC | DESC]) [USING Ыїв§ЗНЗЈ]
); |
ЫЕУїЃК
UNIQUE:ПЩбЁЁЃБэЪОЫїв§ЮЊЮЈвЛадЫїв§ЁЃ
FULLTEXT:ПЩбЁЁЃБэЪОЫїв§ЮЊШЋЮФЫїв§ЁЃ
SPATIAL:ПЩбЁЁЃБэЪОЫїв§ЮЊПеМфЫїв§ЁЃ
INDEXКЭKEY:гУгкжИЖЈзжЖЮЮЊЫїв§ЃЌСНепбЁдёЦфжажЎвЛОЭПЩвдСЫЃЌзїгУЪЧ вЛбљЕФЁЃ
Ыїв§Ућ:ПЩбЁЁЃИјДДНЈЕФЫїв§ШЁвЛИіаТУћГЦЁЃ
зжЖЮУћ1:жИЖЈЫїв§ЖдгІЕФзжЖЮЕФУћГЦЃЌИУзжЖЮБиаыЪЧЧАУцЖЈвхКУЕФзжЖЮЁЃ
ГЄЖШ:ПЩбЁЁЃжИЫїв§ЕФГЄЖШЃЌБиаыЪЧзжЗћДЎРраЭВХПЩвдЪЙгУЁЃ
ASC:ПЩбЁЁЃБэЪОЩ§ађХХСаЁЃ
DESC:ПЩбЁЁЃБэЪОНЕађХХСаЁЃ
зЂЃКЫїв§ЗНЗЈФЌШЯЪЙгУBTREEЁЃ
ЕЅСаЫїв§(ЪОР§)ЃК
CREATE TABLE projectfile (
id INT AUTO_INCREMENT COMMENT 'ИНМўid',
fileuploadercode VARCHAR(128) COMMENT 'ИНМўЩЯДЋепcode',
projectid INT COMMENT 'ЯюФПid;ДЫСаЪмprojectБэжаЕФidСадМЪј',
filename VARCHAR (512) COMMENT 'ИНМўУћ',
fileurl VARCHAR (512) COMMENT 'ИНМўЯТдиЕижЗ',
filesize BIGINT COMMENT 'ИНМўДѓаЁЃЌЕЅЮЛByte',
-- жїМќБОЩэвВЪЧвЛжжЫїв§ЃЈзЂ:вВПЩвддкЩЯУцЕФДДНЈзжЖЮЪБЪЙИУзжЖЮжїМќзддіЃЉ
PRIMARY KEY (id),
-- жїЭтМќдМЪјЃЈзЂ:projectБэжаЕФidзжЖЮдМЪјСЫДЫБэжаЕФprojectidзжЖЮЃЉ
FOREIGN KEY (projectid) REFERENCES project (id),
-- ИјprojectidзжЖЮДДНЈСЫЮЈвЛЫїв§(зЂ:вВПЩвддкЩЯУцЕФДДНЈзжЖЮЪБЪЙгУuniqueРДДДНЈЮЈвЛЫїв§)
UNIQUE INDEX (projectid),
-- ИјfileuploadercodeзжЖЮДДНЈЦеЭЈЫїв§
INDEX (fileuploadercode)
-- жИЖЈЪЙгУINNODBДцДЂв§Чц(ИУв§ЧцжЇГжЪТЮё)ЁЂutf8зжЗћБрТы
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT
'ЯюФПИНМўБэ';
|
зЂЃКетРяжЛЮЊЪОР§ШчКЮДДНЈЫїв§ЃЌЦфЫћЕФКЯРэаджЎРрЕФЯШЗХвЛБпЁЃ
зщКЯЫїв§(ЪОР§)ЃК
CREATE TABLE
projectfile (
id INT AUTO_INCREMENT COMMENT 'ИНМўid',
fileuploadercode VARCHAR(128) COMMENT 'ИНМўЩЯДЋепcode',
projectid INT COMMENT 'ЯюФПid;ДЫСаЪмprojectБэжаЕФidСадМЪј',
filename VARCHAR (512) COMMENT 'ИНМўУћ',
fileurl VARCHAR (512) COMMENT 'ИНМўЯТдиЕижЗ',
filesize BIGINT COMMENT 'ИНМўДѓаЁЃЌЕЅЮЛByte',
-- жїМќБОЩэвВЪЧвЛжжЫїв§ЃЈзЂ:вВПЩвддкЩЯУцЕФДДНЈзжЖЮЪБЪЙИУзжЖЮжїМќзддіЃЉ
PRIMARY KEY (id),
-- ДДНЈзщКЯЫїв§
INDEX (fileuploadercode,projectid)
-- жИЖЈЪЙгУINNODBДцДЂв§Чц(ИУв§ЧцжЇГжЪТЮё)ЁЂutf8зжЗћБрТы
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT
'ЯюФПИНМўБэ';
|
НЈБэКѓДДНЈЃК
| ALTER TABLE БэУћ
ADD [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[Ыїв§Ућ] (зжЖЮУћ1 [(ГЄЖШ)] [ASC | DESC]) [USING Ыїв§ЗНЗЈ]ЃЛ
|
Лђ
| CREATE [UNIQUE
| FULLTEXT | SPATIAL] INDEX Ыїв§Ућ ON БэУћ(зжЖЮУћ) [USING
Ыїв§ЗНЗЈ]ЃЛ |
ЪОР§вЛЃК
-- МйЩшНЈБэЪБfileuploadercodeзжЖЮУЛДДНЈЫїв§
(зЂ:ЭЌвЛИізжЖЮПЩвдДДНЈЖрИіЫїв§ЃЌЕЋвЛАуЧщПіЯТвтвхВЛДѓ)
-- ИјprojectfileБэжаЕФfileuploadercodeДДНЈЫїв§
ALTER TABLE projectfile ADD UNIQUE INDEX (fileuploadercode);
|
ЪОР§ЖўЃК
| ALTER TABLE projectfile
ADD INDEX (fileuploadercode, projectid); |
ЪОР§Ш§ЃК
-- НЋidСаЩшжУЮЊжїМќ
ALTER TABLE index_demo ADD PRIMARY KEY(id) ;
-- НЋidСаЩшжУЮЊздді
ALTER TABLE index_demo MODIFY id INT auto_increment;
|
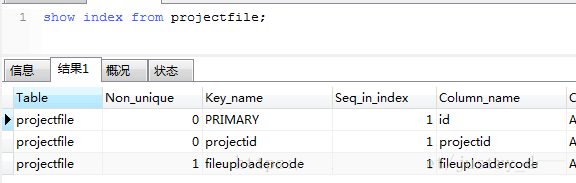
ВщПДвбДДНЈЕФЫїв§ЃК
show index from БэУћ;
ЬсЪО:ЮвУЧвВПЩвджБНгЪЙгУЙЄОпВщПД
ЪОР§ЃК
Ыїв§ЕФЩОГ§ЃК
DROP INDEX Ыїв§Ућ ON БэУћ
Лђ
ALTER TABLE БэУћ DROP INDEXЫїв§Ућ
ЪОР§вЛЃК
| drop index fileuploadercode1
on projectfile; |
ЪОР§ЖўЃК
| alter table projectfile
drop index s2123; |
ВщПДSQLгяОфЖдЫїв§ЕФЪЙгУЧщПі(МД:ВщбЏSQLЕФВщбЏжДааМЦЛЎQEP)ЃК
дкselectгяОфЧАМгЩЯEXPLAINМДПЩЁЃ
ЪОР§ЃК
| EXPLAIN SELECT
* FROM `index_demo` ii WHERE ii.e_name = 'Jane';
|
ЗжЮіИУSQLЕФадФмЮЊЃК

ЬсЪОЃКЮвУЧвВПЩвдЪЙгУSQLЙЄОпВщПДЃЌШчЃКnavicatжаЕФЁАНтЪЭЁБбЁЯюМДПЩВщПДЁЃ
ЫЕУїЃК
idЃКSELECTЪЖБ№ЗћЁЃетЪЧSELECTЕФВщбЏађСаКХЁЃ
select_typeЃКSELECTРраЭЁЃ
SIMPLEЃК МђЕЅSELECT(ВЛЪЙгУUNIONЛђзгВщбЏ)
PRIMARYЃК зюЭтУцЕФSELECT
UNIONЃКUNIONжаЕФЕкЖўИіЛђКѓУцЕФSELECTгяОф
DEPENDENT UNIONЃКUNIONжаЕФЕкЖўИіЛђКѓУцЕФSELECTгяОфЃЌШЁОігкЭтУцЕФВщбЏ
UNION RESULTЃКUNIONЕФНсЙћ
SUBQUERYЃКзгВщбЏжаЕФЕквЛИіSELECT
DEPENDENT SUBQUERYЃКзгВщбЏжаЕФЕквЛИіSELECTЃЌШЁОігкЭтУцЕФВщбЏ
DERIVEDЃКЕМГіБэЕФSELECT(FROMзгОфЕФзгВщбЏ)
tableЃКБэУћ
typeЃКСЊНгРраЭЁЃЪЧSQLадФмЕФЗЧГЃживЊЕФвЛИіжИБъЃЌНсЙћжЕДгКУЕНЛЕвРДЮЪЧЃКsystem >
const > eq_ref > ref
> fulltext > ref_or_null > index_merge
> unique_subquery > index_subquery > range
> index > ALLЁЃ
вЛАуРДЫЕЃЌЕУБЃжЄВщбЏжСЩйДяЕНrangeМЖБ№ЁЃ
systemЃКБэНігавЛаа(=ЯЕЭГБэ)ЁЃетЪЧconstСЊНгРраЭЕФвЛИіЬиР§ЁЃ
constЃКБэзюЖргавЛИіЦЅХфааЃЌЫќНЋдкВщбЏПЊЪМЪББЛЖСШЁЁЃвђЮЊНігавЛааЃЌдкетааЕФСажЕПЩБЛгХЛЏЦїЪЃгрВПЗжШЯЮЊЪЧГЃЪ§ЁЃconstгУгкгУГЃЪ§жЕБШНЯPRIMARY
KEYЛђUNIQUEЫїв§ЕФЫљгаВПЗжЪБЁЃ
eq_refЃКЖдгкУПИіРДздгкЧАУцЕФБэЕФаазщКЯЃЌДгИУБэжаЖСШЁвЛааЁЃетПЩФмЪЧзюКУЕФСЊНгРраЭЃЌГ§СЫconstРраЭЁЃЫќгУдквЛИіЫїв§ЕФЫљгаВПЗжБЛСЊНгЪЙгУВЂЧвЫїв§ЪЧUNIQUEЛђPRIMARY
KEYЁЃeq_refПЩвдгУгкЪЙгУ= ВйзїЗћБШНЯЕФДјЫїв§ЕФСаЁЃБШНЯжЕПЩвдЮЊГЃСПЛђвЛИіЪЙгУдкИУБэЧАУцЫљЖСШЁЕФБэЕФСаЕФБэДяЪНЁЃ
refЃКЖдгкУПИіРДздгкЧАУцЕФБэЕФаазщКЯЃЌЫљгагаЦЅХфЫїв§жЕЕФааНЋДгетеХБэжаЖСШЁЁЃШчЙћСЊНгжЛЪЙгУМќЕФзюзѓБпЕФЧАзКЃЌЛђШчЙћМќВЛЪЧUNIQUEЛђPRIMARY
KEY(ЛЛОфЛАЫЕЃЌШчЙћСЊНгВЛФмЛљгкЙиМќзжбЁдёЕЅИіааЕФЛА)ЃЌдђЪЙгУrefЁЃШчЙћЪЙгУЕФМќНіНіЦЅХфЩйСПааЃЌИУСЊНгРраЭЪЧВЛДэЕФЁЃrefПЩвдгУгкЪЙгУ=Лђ<=>ВйзїЗћЕФДјЫїв§ЕФСаЁЃ
ref_or_nullЃКИУСЊНгРраЭШчЭЌrefЃЌЕЋЪЧЬэМгСЫMySQLПЩвдзЈУХЫбЫїАќКЌNULLжЕЕФааЁЃдкНтОізгВщбЏжаОГЃЪЙгУИУСЊНгРраЭЕФгХЛЏЁЃ
index_mergeЃКИУСЊНгРраЭБэЪОЪЙгУСЫЫїв§КЯВЂгХЛЏЗНЗЈЁЃдкетжжЧщПіЯТЃЌkeyСаАќКЌСЫЪЙгУЕФЫїв§ЕФЧхЕЅЃЌkey_lenАќКЌСЫЪЙгУЕФЫїв§ЕФзюГЄЕФЙиМќдЊЫиЁЃ
unique_subqueryЃКИУРраЭЬцЛЛСЫЯТУцаЮЪНЕФINзгВщбЏЕФrefЃКvalue IN (SELECT
primary_key FROMsingle_table WHERE some_expr);unique_subqueryЪЧвЛИіЫїв§ВщевКЏЪ§ЃЌПЩвдЭъШЋЬцЛЛзгВщбЏЃЌаЇТЪИќИпЁЃ
index_subqueryЃКИУСЊНгРраЭРрЫЦгкunique_subqueryЁЃПЩвдЬцЛЛINзгВщбЏЃЌЕЋжЛЪЪКЯЯТСааЮЪНЕФзгВщбЏжаЕФЗЧЮЈвЛЫїв§ЃКvalue
IN (SELECT key_column FROM single_table WHERE some_expr)
rangeЃКжЛМьЫїИјЖЈЗЖЮЇЕФааЃЌЪЙгУвЛИіЫїв§РДбЁдёааЁЃkeyСаЯдЪОЪЙгУСЫФФИіЫїв§ЁЃkey_lenАќКЌЫљЪЙгУЫїв§ЕФзюГЄЙиМќдЊЫиЁЃдкИУРраЭжаrefСаЮЊNULLЁЃЕБЪЙгУ=ЁЂ<>ЁЂ>ЁЂ>=ЁЂ<ЁЂ<=ЁЂIS
NULLЁЂ<=>ЁЂBETWEENЛђепINВйзїЗћЃЌгУГЃСПБШНЯЙиМќзжСаЪБЃЌПЩвдЪЙгУrange
indexЃКИУСЊНгРраЭгыALLЯрЭЌЃЌГ§СЫжЛгаЫїв§ЪїБЛЩЈУшЁЃетЭЈГЃБШALLПьЃЌвђЮЊЫїв§ЮФМўЭЈГЃБШЪ§ОнЮФМўаЁЁЃ
allЃКЖдгкУПИіРДздгкЯШЧАЕФБэЕФаазщКЯЃЌНјааЭъећЕФБэЩЈУшЁЃШчЙћБэЪЧЕквЛИіУЛБъМЧconstЕФБэЃЌетЭЈГЃВЛКУЃЌВЂЧвЭЈГЃдкЫќЧщПіЯТКмВюЁЃЭЈГЃПЩвддіМгИќЖрЕФЫїв§ЖјВЛвЊЪЙгУALLЃЌЪЙЕУааФмЛљгкЧАУцЕФБэжаЕФГЃЪ§жЕЛђСажЕБЛМьЫїГіЁЃ
possible_keysЃКpossible_keysСажИГіMySQLФмЪЙгУФФИіЫїв§дкИУБэжаевЕНааЁЃзЂвтЃЌИУСаЭъШЋЖРСЂгкEXPLAINЪфГіЫљЪОЕФБэЕФДЮађЁЃетвтЮЖзХдкpossible_keysжаЕФФГаЉМќЪЕМЪЩЯВЛФмАДЩњГЩЕФБэДЮађЪЙгУЁЃ
keyЃКkeyСаЯдЪОMySQLЪЕМЪОіЖЈЪЙгУЕФМќ(Ыїв§)ЁЃШчЙћУЛгабЁдёЫїв§ЃЌМќЪЧNULLЁЃвЊЯыЧПжЦMySQLЪЙгУЛђКіЪгpossible_keysСажаЕФЫїв§ЃЌдкВщбЏжаЪЙгУFORCE
INDEXЁЂUSE INDEXЛђепIGNORE INDEXЁЃ
key_lenЃКkey_lenСаЯдЪОMySQLОіЖЈЪЙгУЕФМќГЄЖШЁЃШчЙћМќЪЧNULLЃЌдђГЄЖШЮЊNULLЁЃзЂвтЭЈЙ§key_lenжЕЮвУЧПЩвдШЗЖЈMySQLНЋЪЕМЪЪЙгУвЛИіЖрВПЙиМќзжЕФМИИіВПЗжЁЃ
refЃКrefСаЯдЪОЪЙгУФФИіСаЛђГЃЪ§гыkeyвЛЦ№ДгБэжабЁдёааЁЃ
rowsЃКrowsСаЯдЪОMySQLШЯЮЊЫќжДааВщбЏЪББиаыМьВщЕФааЪ§ЁЃ
ExtraЃКИУСаАќКЌMySQLНтОіВщбЏЕФЯъЯИаХЯЂЁЃ
DistinctЃКMySQLЗЂЯжЕк1ИіЦЅХфааКѓЃЌЭЃжЙЮЊЕБЧАЕФаазщКЯЫбЫїИќЖрЕФааЁЃ
Not existsЃКMySQLФмЙЛЖдВщбЏНјааLEFT JOINгХЛЏЃЌЗЂЯж1ИіЦЅХфLEFT JOINБъзМЕФааКѓЃЌВЛдйЮЊЧАУцЕФЕФаазщКЯдкИУБэФкМьВщИќЖрЕФааЁЃ
range checked for each record (index map: #)ЃКMySQLУЛгаЗЂЯжКУЕФПЩвдЪЙгУЕФЫїв§ЃЌЕЋЗЂЯжШчЙћРДздЧАУцЕФБэЕФСажЕвбжЊЃЌПЩФмВПЗжЫїв§ПЩвдЪЙгУЁЃЖдЧАУцЕФБэЕФУПИіаазщКЯЃЌMySQLМьВщЪЧЗёПЩвдЪЙгУrangeЛђindex_mergeЗУЮЪЗНЗЈРДЫїШЁааЁЃ
Using filesortЃКMySQLашвЊЖюЭтЕФвЛДЮДЋЕнЃЌвдевГіШчКЮАДХХађЫГађМьЫїааЁЃЭЈЙ§ИљОнСЊНгРраЭфЏРРЫљгаааВЂЮЊЫљгаЦЅХфWHEREзгОфЕФааБЃДцХХађЙиМќзжКЭааЕФжИеыРДЭъГЩХХађЁЃШЛКѓЙиМќзжБЛХХађЃЌВЂАДХХађЫГађМьЫїааЁЃ
Using indexЃКДгжЛЪЙгУЫїв§ЪїжаЕФаХЯЂЖјВЛашвЊНјвЛВНЫбЫїЖСШЁЪЕМЪЕФааРДМьЫїБэжаЕФСааХЯЂЁЃЕБВщбЏжЛЪЙгУзїЮЊЕЅвЛЫїв§вЛВПЗжЕФСаЪБЃЌПЩвдЪЙгУИУВпТдЁЃ
Using temporaryЃКЮЊСЫНтОіВщбЏЃЌMySQLашвЊДДНЈвЛИіСйЪББэРДШнФЩНсЙћЁЃЕфаЭЧщПіШчВщбЏАќКЌПЩвдАДВЛЭЌЧщПіСаГіСаЕФGROUP
BYКЭORDER BYзгОфЪБЁЃ
Using whereЃКWHEREзгОфгУгкЯожЦФФвЛИіааЦЅХфЯТвЛИіБэЛђЗЂЫЭЕНПЭЛЇЁЃГ§ЗЧФузЈУХДгБэжаЫїШЁЛђМьВщЫљгаааЃЌШчЙћExtraжЕВЛЮЊUsing
whereВЂЧвБэСЊНгРраЭЮЊALLЛђindexЃЌВщбЏПЩФмЛсгавЛаЉДэЮѓЁЃ
Using sort_union(...), Using union(...), Using intersect(...)ЃКетаЉКЏЪ§ЫЕУїШчКЮЮЊindex_mergeСЊНгРраЭКЯВЂЫїв§ЩЈУшЁЃ
Using index for group-byЃКРрЫЦгкЗУЮЪБэЕФUsing indexЗНЪНЃЌUsing
index for group-byБэЪОMySQLЗЂЯжСЫвЛИіЫїв§ЃЌПЩвдгУРДВщбЏGROUP BYЛђDISTINCTВщбЏЕФЫљгаСаЃЌЖјВЛвЊЖюЭтЫбЫїгВХЬЗУЮЪЪЕМЪЕФБэЁЃВЂЧвЃЌАДзюгааЇЕФЗНЪНЪЙгУЫїв§ЃЌвдБуЖдгкУПИізщЃЌжЛЖСШЁЩйСПЫїв§ЬѕФПЁЃ
ЕЅСаЫїв§ЕФЪЙгУЃК
зМБИЙЄзїЃК
ИјidМгжїМќЫїв§ЃК

дйЗжБ№ИјnameЁЂcityЁЂcountryЁЂaddressМгЩЯЦеЭЈЫїв§ЃК
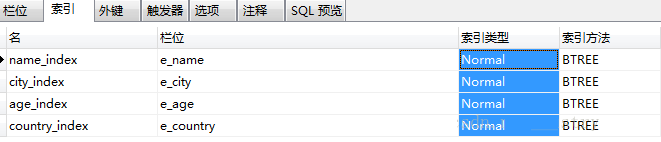
зЂЃКвдЩЯЮхИіЫїв§ЖМЪЧЕЅСаЫїв§ЁЃ
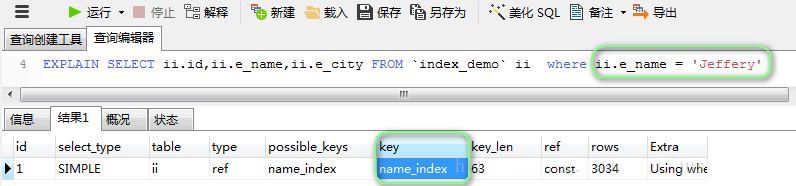
ЪЙгУЧщПіЃК
жЛЩцМАЕНЦфжаЕФвЛИізжЖЮЪБЃЌЖМФмЪЙгУЕНЫїв§(вдe_nameЮЊР§):
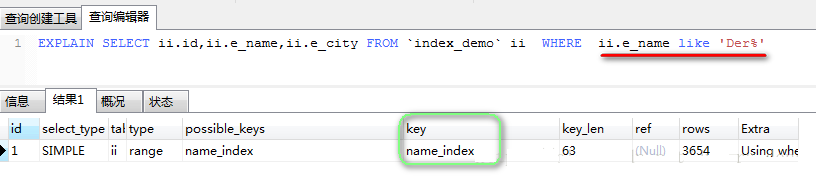
зЂЃКФЃК§ВщбЏЪБЃЌ%ШчЙћдкЧАУцЃЌФЧУДВЛЛсЪЙгУЫїв§ЁЃ
ЩцМАЕНЖрИіЫїв§зжЖЮЪБ,ШчЙћетаЉЫїв§зжЖЮжаЃЌДцдкжїМќЫїв§ЃЌФЧУДжЛЛсЪЙгУИУЫїв§ЃЈМД:MYSQLгХЛЏЦїЛсбЁГіВЂЯШжДаазюЁАбЯЁБЕФЫїв§ЃЉ:
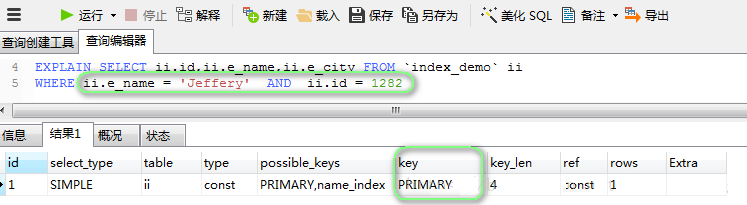
ЬсЪОЃКpossible_keyжаЃЌжЛЪЧSQLгяОфРяЩцМАЕНЕФЫїв§ЃЛkeyжаВХЪЧЪЕМЪЩЯжДааВщбЏВйзїЪБЪЙгУЕНСЫЕФЫїв§ЁЃ
ЩцМАЕНЖрИіЫїв§зжЖЮЪБ,ШчЙћетаЉЫїв§зжЖЮжаЃЌВЛДцдкжїМќЫїв§ЕФЛАЃЌФЧУДОЭЛсЪЙгУИУЪЙгУЕФЫїв§ЃЈзЂЃКШчЙћЭЈЙ§ЦфжаЕФВПЗжЫїв§ОЭФмзМШЗЖЈЮЛЕФЛАЃЌФЧУДЦфгрЕФЫїв§ОЭВЛдйБЛЪЙгУЃЉ:

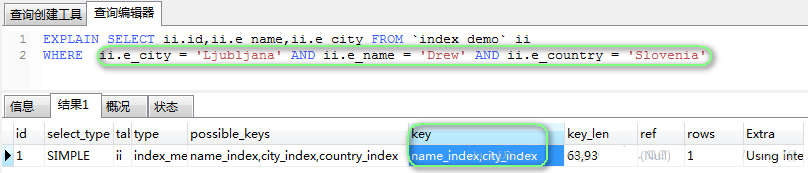
зЂЃКЖрИіЫїв§ЪБЃЌЯШЪЙгУФФИіЫїв§КѓЪЙгУФФИіЫїв§ЃЌЪЧгЩMySQLЕФгХЛЏЦїОЙ§вЛаЉСаМЦЫуКѓзїГіЕФОёдёЁЃ
ЕБЖдЫїв§зжЖЮНјаа>ЃЌ<ЃЌ>=ЃЌ <=ЃЌnot
inЃЌbetween ЁЁ and ЁЁЃЌКЏЪ§(Ыїв§зжЖЮ)ЃЌlikeФЃК§ВщбЏ%дкзжЖЮЧАЪБЃЌВЛЛсЪЙгУИУЫїв§
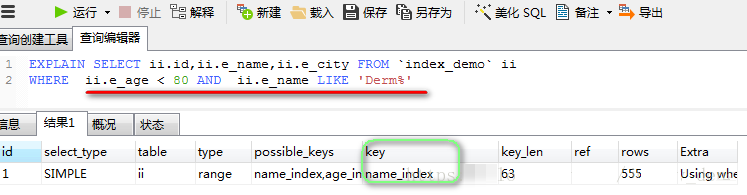
зЂЃКетРяЖдe_ageзжЖЮНјааСЫ ЁА<ЁБ ЃЌЫљвдЪЕМЪВщбЏЪБЃЌВЂУЛгаЪЙгУe_ageЕФЫїв§ЁЃ
ЬсЪОЃКдкЪЕМЪЪЙгУЪБЃЌШчЙћЩцМАЕНЖрСаЃЌЮвУЧвЛАуЖМВЛЛсНЋетаЉСавЛ вЛДДНЈЮЊЕЅСаЫїв§ЃЌЖјЪЧНЋетаЉСаДДНЈЮЊзщКЯЫїв§ЁЃ
зщКЯЫїв§ЕФЪЙгУЃК
зюзѓддђЃК
МйЩшзщКЯЫїв§ЮЊЃКa,b,cЕФЛА;ФЧУДЕБSQLжаЖдгІгаЃКaЛђaЃЌbЛђaЃЌbЃЌcЕФЪБКђЃЌПЩГЦЮЊЭъШЋТњзузюзѓддђЃЛЕБSQLжаЖдгІжЛгаaЃЌcЕФЪБКђЃЌПЩГЦЮЊВПЗжТњзузюзѓддђЃЛЕБSQLжаУЛгаaЕФЪБКђЃЌПЩГЦЮЊВЛТњзузюзѓддђЁЃ
зЂЃКSQLгяОфжаЕФЖдгІЬѕМўЕФЯШКѓЫГађЮоЙиЁЃ
зМБИЙЄзїЃК

ДДНЈСЫзщКЯЫїв§:e_nameЃЌe_ageЃЌe_countryЃЌe_cityЁЃ
ЪЙгУЧщПіЃК
ЭъШЋТњзузюзѓддђЃК

зЂЃКгыЬѕМўЕФЯШКѓЮоЙиЃЌМДЃКЯТУцетбљЕФЛАЃЌвВЪЧЛсЭъећЕФзпзщКЯЫїв§ЕФЃК

ВПЗжТњзузюзѓддђЃК

зЂЃКДЫSQLжаЃЌжЛгаe_nameКЭe_countryТњзуВПЗжзюзѓддђ(e_nameТњзу)ЃЌЫљвдЕНe_nameзжЖЮЪБЛсзпзщКЯЫљвдЃЌЕЋЪЧ
жЛЛсзпЕНe_nameФЧРяЃЌЕНe_countryЪБОЭВЛЛсЪЙгУзщКЯЫїв§СЫЁЃ
ВЛТњзузюзѓддђЃК
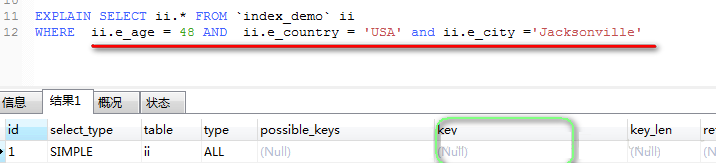
Тњзу(ВПЗжТњзу)зюзѓддђЕФзжЖЮРяЃЌгазжЖЮВЛТњзуЁАЫїв§ЁБздЩэЕФЪЙгУЙцЗЖЃК
ЫЕУїЃКШчЙћSQLгяОфРяЕФзжЖЮРяЃЌТњзуСЫзюзѓддђЃЌЕЋЪЧВЛТњзуЁАЫїв§ЁБздЩэЕФЪЙгУЙцЗЖЃЌФЧУДзщКЯЫїв§зпЕНетРяжЎКѓЃЌ
ВЛЛсдйЭљЯТзпСЫЁЃ
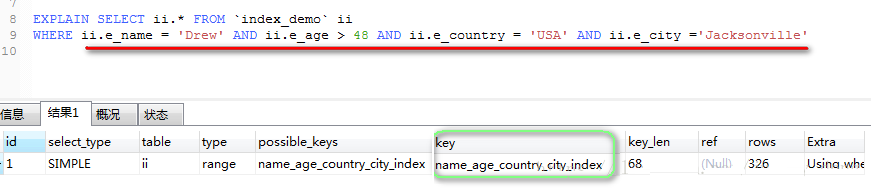
ШчЭМЫљЪОЃКгЩгкe_ageзжЖЮЪЙгУСЫЁА>ЁБЗћКХЃЌВЛЗћКЯЁАЫїв§ЁБздЩэЕФЪЙгУЙцЗЖЃЌФЧУДЕБЁАe_nameЁБзпЭъзщКЯЫїв§КѓЃЌ
зпЕНЁАe_ageЁБЪБЃЌИУзжЖЮМАЦфКѓУцЕФзжЖЮВЛЛсдйзпзщКЯЫїв§СЫЁЃ
| 








