| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмСЫcassandraАВзАЛЗОГХфжУЃЌДюНЈМЏШКЕФЙ§ГЬЃЌCQLЕФЪЙгУвдМАЕШЃЌЯЃЭћФмЖдФњгаЫљАяжњЁЃ |
|
1ЛљБОАВзА
1.1дкЛљгкRHELЕФЯЕЭГжаАВзАCassandra
1.1.1БивЊЬѕМў
YUMАќЙмРэЦї
RootЛђsudoШЈЯо
JRE6ЛђепJRE7
JNA(Java native Access)ЃЈЩњВњЛЗОГашвЊЃЉ
1.1.2ВНжш
АВзАХфжУJRE(Тд)
ЬэМгШэМўАќВжПтЕНYUMЕФШэМўПт
НЋвдЯТФкШнЬэМгНј/etc/yum.repos.d/datastax.repoЮФМўМДПЩЃК
[datastax]
name = DataStax Repo for ApacheCassandra
baseurl =http://rpm.datastax.com/community
enabled = 1
gpgcheck = 0 |
АВзА2.0АцзюаТЕФШэМўАќ
АВзАJNA
ОЙ§ЩЯЪіВНжшМДАВзАКУСЫCassandraЃЌЫцКѓБуПЩЖдЦфНјааХфжУЁЃвдДЫЗНЪНАВзАЕФCassandraЛсДДНЈвЛИіУћЮЊcassandraЕФгУЛЇЃЌcassandraвдДЫгУЛЇЦєЖЏЗўЮёЁЃ
1.2дкШЮвтЛљгкLinuxЕФЯЕЭГжаАВзАCassandra
1.2.1БивЊЬѕМў
JRE6ЛђепJRE7
JNA(Java native Access) ЃЈЩњВњЛЗОГашвЊЃЉ
1.2.2ВНжш
АВзАХфжУJRE(Тд)
ЯТдиCassandraЖўНјжЦ tarball
гЩвГУцЪжЙЄЯТдиЖдгІАцБОЕФCassandraЃЌЛђепЭЈЙ§
curl -OLhttp://downloads.datastax.com /community/dsc.tar.gz
УќСюздЖЏЯТдизюаТЕФDataStaxCommunityЃЌвВПЩгЩвГУцЪжЙЄЯТдиЖдгІАцБОЁЃ
НтбЙtarball
tar ЈCxzvf dsc-cassandra-2.0.0-bin.tar.gz
ИљОнЯТдиЕФАцБОвВПЩФмЪЧЃКtar ЈCxzvf apache-cassandra-2.0.0-bin.tar.gz
АВзАХфжУJNA
2 ЯТдиjna.jarЁЃ
2 НЋЯТдиЕФjna.jarЬэМгНјCassandraАВзАФПТМЕФlibФПТМЯТЛђНЋЦфЬэМгНјCLASSPATHЛЗОГБфСПжа
2 дк/etc/security/limits.confЮФМўжаМгШыШчЯТааЃК
$USER soft memlock unlimited
$USER hard memlock unlimited
Цфжа$USERЮЊдЫааcassandraЕФгУЛЇ
ДДНЈЪ§ОнФПТМКЭШежОФПТМВЂжИЖЈИјгУгкдЫааcassandraЗўЮёЕФОпгаЯргІЖСаДШЈЯоЕФгУЛЇ
$ sudo mkdir/var/lib/cassandra
$ sudo mkdir/var/log/cassandra
$ sudo chown-R $USER: $GROUP /var/lib/cassandra
$ sudo chown-R $USER: $GROUP /var/log/Cassandra |
CassandraХфжУЮФМўжаФЌШЯЪЙгУЩЯЪіФПТМЗжБ№зїЮЊЪ§ОнФПТМКЭШежОФПТМЃЌПЩДДНЈВЛЭЌЕФФПТМЃЌИГгшЖдгІЕФШЈЯоЃЌВЂдкХфжУЮФМўжажиаТжИЖЈвдИФБфФЌШЯааЮЊЁЃ
жСДЫвбАВзАКУСЫCassandraЃЌЫцКѓБуПЩЖдЦфНјааХфжУЁЃ
2МђЕЅХфжУ
CassandraЕФжїХфжУЮФМўЮЊcassandra.yamlЃЌЦфЮЛжУЫцCassandraАВзАЗНЪНВЛЭЌЖјВЛЭЌЁЃ
ЖдгкCassandraPackageАВзАЃК/etc/cassandra/conf
ЖдгкCassandraBinaryАВзАЃК<install_location>/conf
ЖдгкDataStaxEnterprise PackagedАВзАЃК/etc/dse/cassandra
ЖдгкDataStaxEnterpriseBinaryАВзАЃК<install_location>/resources/cassandra/conf
ХфжУЮФМўжаЕФХфжУВЮЪ§БЛЗжЮЊШчЯТМИИізщ
Initialization propertiesЃКПижЦМЏШКФкЕФНкЕуШчКЮХфжУЃЌАќРЈНкЕуМфЭЈбЖЃЌЪ§ОнЗжЧјМАИДжЦВМжУЁЃ
Global row and key caches propertiesЃКгУгкЛКДцБэЕФВЮЪ§ЕФХфжУВЮЪ§ЁЃ
Performance tuning propertiesЃКЕїећадФмКЭЯЕЭГзЪдДЕФРћгУЃЌАќРЈФкДцЁЂДХХЬI/OЁЂCPUЁЂЖСКЭаДЁЃ
Binary and RPC protocol timeout propertiesЃКгУгкЖўНјжЦавщЕФГЌЪБЩшжУЁЃ
Remote procedure call tuningЃЈRPCЃЉpropertiesЃКгУгкХфжУКЭЕїећRPCsЃЈПЭЛЇЖЫСЌНгЃЉ
Fault detection propertiesЃКгУгкДІРэдЫааЧщПіНЯВюЛђепЪЇАмЕФНкЕуЁЃ
Automatic backup propertiesЃКгУгкздЖЏЛЏБИЗнЁЃ
Security propertiesЃКгУгкЗўЮёЦїЖЫКЭПЭЛЇЖЫЕФАВШЋЩшжУ
УПИізщАќЖМКЌШєИЩОпЬхЕФВЮЪ§
Р§ШчЃЌЖдгкаТАВзАЕФCassandraПЩФмЛсаоИФХфжУЮФМўжаЕФЯТУцМИИіВЮЪ§
data_file_directoriesЃКЪ§ОнФПТМЃЌЖдгкАќЗНЪНЃЈШчdebЛђrpmЃЉАВзАЕФCassandraЃЌИУФПТМЛсдкАВзАЙ§ГЬжаздЖЏДДНЈВЂОпгае§ШЗЕФШЈЯоЃЌФЌШЯЮЛжУЮЊ/var/lib/cassandra/dataЁЃ
commitlog_directoryЃКcommit logФПТМЃЌЖдгкАќЗНЪНАВзАЕФCassandraЃЌИУФПТМЛсдкАВзАЙ§ГЬжаздЖЏДДНЈВЂОпгае§ШЗЕФШЈЯоЃЌФЌШЯЮЛжУЮЊ/var/lib/cassandra/commitlogЁЃ
saved_caches_directoryЃКБЃДцЕФЛКДцФПТМЃЌЖдгкАќЗНЪНАВзАЕФCassandraЃЌИУФПТМЛсдкАВзАЙ§ГЬжаздЖЏДДНЈВЂОпгае§ШЗЕФШЈЯоЃЌФЌШЯЮЛжУЮЊ/var/lib/cassandra/saved_cachesЁЃ
ШчЙћвдЖўНјжЦЗНЪНЛђдДТыЗНЪНАВзАCassandraашздааДДНЈЯргІФПТМЃЌИГгше§ШЗЕФШЈЯоЁЃгжЛђепВЛЯыЪЙгУФЌШЯЕФЮЛжУЃЌвВПЩвдздааДДНЈаТЕФФПТМЃЌИГгше§ШЗЕФШЈЯоЃЌВЂдкХфжУЮФМўжажИЖЈЁЃБШШчЃК
data_file_directories:/data/cassandra/data
commitlog_directory:/data/cassandra/commitlog
saved_caches_directory:/data/cassandra/saved_caches |
СэЭтЃЌЖдгкАќЗНЪНАВзАЕФCassandraЃЌЛЙЛсдкАВзАЙ§ГЬжаздЖЏДДНЈ
/var/log/cassandra ФПТМВЂИГгше§ШЗЕФШЈЯоЁЃ ФЌШЯЧщПіЯТCassandraНЋЦфШежОаДНјИУФПТМЕФsystem.logЮФМўжаЁЃПЩЭЈЙ§аоИФlog4j-server.properiesЮФМў
ЃЈгыcassandra.yamlЮЛгкЭЌвЛФПТМЃЉжаЕФlog4j.appender.R.FileРДИФБфФЌШЯааЮЊЃЌ
БШШчЃКlog4j.appender.R.File=/data/cassandra/system.log
ЛЙПЩФмвЊаоИФJVMМЖБ№ЕФВЮЪ§ЃЌИУВПЗжЕФВЮЪ§ПЩдкcassandra-env.sh
ЮФМўЃЈ гыcassandra.yamlЮЛгкЭЌвЛФПТМЃЉжаЩшжУЁЃ
3ЦєЖЏМАМђЕЅЪЙгУ
3.1ЦєЖЏCassandra
ЖдгкЖўНјжЦАќАВзАЗНЪН
жДааbin/cassandraЈCfЃЌЧАЬЈЦєЖЏcassandraЃЌcassandraЛсНЋШежОЪфГіЕНБъзМЪфГіжаЁЃШєУЛдкЪфГіжаПДЕНЁАerrorЁБЁЂЁАfatalЁБЛђепРрЫЦЁАjava
stack traceЁБЕФФкШнБэУїcassandraПЩе§ГЃЙЄзїЁЃПЩЭЈЙ§ЁАControl-CЁАЭЃжЙcasandraЁЃ
жДааbin/cassandraЃЌКѓЬЈЦєЖЏcassandraЁЃ
ПЩЭЈЙ§killЛђpkillУќСюЭЃжЙcassandra
ЖдгкYUMАВзАЗНЪН
жДааsudoservice Cassandra startЦєЖЏcassandra
жДааsudoservice Cassandra stop ЭЃжЙcassandra
3.2ЪЙгУcqlsh
жДааbin/cqlshЃЌГіЯжШчЯТЬсЪОдђБэУїСЌНгГЩЙІЃЈашpython2.7ЃЉЃК
Connected toTest Cluster at localhost:9160.
[cqlsh 4.0.0 |Cassandra 2.0.0 | CQL
spec 3.1.0 | Thrift protocol 19.37.0]
Use HELP forhelp.
ПЩдкcqlshУќСюЬсЪОЗћЯТЪфШыhelpЛђЃПЛёЕУАяжњЃЌЪфШыexitЛђquitЭЫГіcqlshЃЌУќСюФЌШЯвдЁА;ЁБНсЪјЁЃ
ВщПДkeyspace
ДДНЈkeyspace
| CREATEKEYSPACE
mykeyspace WITH REPLICATION = { 'class' : 'SimpleStrategy','replication_factor'
: 2 }; |
ЧаЛЛkeyspace
ДДНЈБэ
CREATE TABLEusers
(
user_id int PRIMARY KEY,
fname text,
lname text
); |
ВщПДБэ
ВхШыЪ§Он
INSERT INTOusers
(user_id, fname, lname)
VALUES (1745, 'john', 'smith');
INSERT INTOusers (user_id, fname, lname)
VALUES (1744, 'john', 'doe');
INSERT INTOusers (user_id, fname, lname)
VALUES (1746, 'john', 'smith'); |
ВщбЏЪ§Он
НЈСЂЫїв§КѓЪЙгУWHEREДгОфВщев
CREATE INDEXON
users (lname);ЁЂ
SELECT * FROMusers WHERE lname = 'smith'; |
ЩОГ§Бэ
жСДЫвбОгЕгаСЫЕЅНкЕуЕФCassandraЃЌЧвФмЙЛЭЈЙ§cqlshСЌНгжСcassandraВЂЪЙгУCQLжДааВйзїЁЃЯТУцЖдCassandraзїНјвЛВННщЩмЁЃ
4ДюНЈМЏШК
4.1ЕЅЪ§ОнжааФМЏШК
4.1.1ЧАжУЙЄзї
дкУПИіНкЕуЩЯзАХфCassandra
ЮЊМЏШКШЗЖЈУћГЦ
ЛёШЁУПИіНкЕуЕФIP
ШЗЖЈгУРДзіжжзгЕФНкЕуЃЈCassandraЭЈЙ§жжзгНкЕуРДевЕНБЫДЫВЂСЫНтЛЗЕФЭиЦЫЃЉ
ШЗЖЈsnitchЃЈгУгкШЗЖЈЯђ/ДгФФИіЪ§ОнжааФКЭЭјМмаДШы/ЖСШЁЪ§ОнЁЃгаВЛЭЌЕФРраЭПЩбЁЃЉ
4.1.2ОпЬхХфжУ
1.МйЖЈЪЙгУвдЯТвбОАВзАСЫCassandraЕФНкЕуХфжУМЏШК(зЪдДгаЯоЃЌетРяжЛгУСНЬЈЛњЦїРДЫЕУїЙ§ГЬЁЃецЪЕЛЗОГЯТзюКУЪЧгаЖрЬЈЛњЦїЃЌЧввЛИіМЏШКжазюКУгавЛИівдЩЯЕФжжзг)
node0192.168.83.35 (seed)
node1192.168.83.37
2.МйЖЈНкЕуЫљдкЛњЦїгаЗРЛ№ЧНЃЌзЂвтПЊЗХCassandraЫљЪЙгУЕФЖЫПк
3.ШєCassandraе§дЫаадђЯШЙиБеЃЌКѓЧхГ§Ъ§ОнЁЃ
| $ sudo servicecassandra
stop |
ЛђепЃЈИљОнАВзАЗНЪНЖјВЛЭЌЃЉ
$ ps auwx |grep
cassandra
$ sudo kill <pid> |
4.ЧхГ§Ъ§Он
| $ sudo rm -rf/var/lib/cassandra/* |
5.аоИФcassandra.yamlЮФМўжаЕФЯргІФкШн
cluster_name:'MyDemoCluster'
num_tokens:256
seed_provider:
- class_name:org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.83.35"
listen_address:192.168.83.35
rpc_address:0.0.0.0
endpoint_snitch:SimpleSnitch |
ШєЪЧНЈСЂШЋаТЕФЛЙВЛАќКЌЪ§ОнЕФМЏШКдђМгЩЯauto_bootstrap:false
6.ЪЃгрНкЕуЕФХфжУгыГ§СЫlisten_addressгІЕБЮЊздЩэIPЭтЃЌЦфЫћХфжУгыЩЯЪіЯрЭЌ
7.ЯШЦєЖЏж№ИіЦєЖЏseedНкЕуЃЌдйж№ИіЦєЖЏЪЃгрНкЕу
| $ sudo servicecassandra
start |
Лђеп
$ cd<install_location>
$ bin/Cassandra |
8.ЪЙгУnodetoolstatusУќСюВщПДМЏШКЪЧЗёГЩЙІдЫаа
4.2ЖрЪ§ОнжааФМЏШК
етРяЃЌЪ§ОнжааФжИЕФОЭЪЧвЛзщНкЕуЃЌгыИДжЦзщЪЧЭЌвхДЪЁЃЖрЪ§ОнжааФМЏШКжаЃЌЪ§ОнПЩвддкВЛЭЌЪ§ОнжааФМфздЖЏЁЂЭИУїИДжЦЁЃ
4.2.1ЧАжУЙЄзї
гыЕЅНкЕуМЏШКХфжУЛљБОЯрЭЌЃЌВЛЭЌЕФЪЧЛЙашвЊШЗЖЈЪ§ОнжааФКЭЭјМмЕФУќУћЁЃ
4.2.2ОпЬхХфжУ
1.МйЖЈдквдЯТвбОАВзАСЫCassandraЕФНкЕуХфжУМЏШК
node0 192.168.83.35(seed1)
node1 192.168.83.36
node2 192.168.83.37
node3 192.180.83.35(seed2)
node4 192.180.83.36
node5 192.168.83.37 |
2.ШєШчЗРЛ№ЧНЃЌдђЯШПЊЗХЯргІЖЫПкЃЈЭЌЩЯЃЉ
3.ШєCassandraе§дЫаадђЯШЙиБеЃЈЭЌЩЯЃЉ
4.ЧхГ§Ъ§ОнЃЈЭЌЩЯЃЉ
5.аоИФcassandra.yamlЮФМўжаЕФЯргІФкШн
ЁЭЌЩЯЁ
endpoint_snitch:PropertyFileSnitch
ШєЪЧНЈСЂШЋаТЕФЛЙВЛАќКЌЪ§ОнЕФМЏШКдђМгЩЯauto_bootstrap:false
6.ЪЃгрНкЕуЕФХфжУгыГ§СЫlisten_addressгІЕБЮЊздЩэIPЭтЃЌЦфЫћХфжУгыЩЯЪіЯрЭЌ
7.ВНжш5жажИЖЈendpoint_snitchЮЊPropertyFileSnitchЫљвдвЊБрМЖдгІЕФcassandra-topologies.propertiesХфжУЮФМўЃЈШєendpoint_snitchжИЖЈЮЊGossipingPropertyFileSnitchдђвЊБрМcassandra-rackdc.propertiesЃЌжИЖЈЮЊYamlFileNetworkTopologySnitchдђвЊБрМcassandra-topology.yamlЃЉ
# CassandraNode
IP=Data Center:Rack
192.168.83.35=DC1:RAC1
192.168.83.36=DC2:RAC1
192.168.83.37=DC1:RAC1
192.180.83.35 =DC2:RAC1
192.180.83.36=DC1:RAC1
192.168.83.37=DC2:RAC1 |
жЎКѓЛЙвЊЮЊЮЛжУЕФНкЕуЩшжУвЛИіФЌШЯЕФЪ§ОнжааФКЭЭјМмУћ
# default forunknown
nodes
default=DC1:RAC1 |
8.ж№ИіЦєЖЏжжзгНкЕуЃЌжЎКѓж№ИіЦєЖЏЪЃгрНкЕуЃЈЭЌЩЯЃЉ
9.бщжЄЛЗЪЧЗёГЩЙІЦєЖЏЃЈЭЌЩЯЃЉ
5ЪЙгУCQL
CQL:CassandraQuery Language
МЄЛюCQLЃКcqlshЁЂDataStaxJava DriverЁЂThriftЗНЗЈ
set_cql_versionЁЂPythonЧ§ЖЏжаЕФconnect()ЕїгУЁЃ
ЪЙгУcqlsh
bin/cqlsh hostport ЈCu username ЈCp password
ДДНЈkeyspace
keyspaceЮЊБэУќУћПеМфЃЌжИУїНкЕужаЪ§ОнШчКЮИДжЦЃЌвЛАувЛИігІгУЖдгІвЛИі
keyspaceЁЃcassandraжаЕФИДжЦПижЦвдЕЅИіkeyspaceЮЊЛљДЁЁЃ
CREATEKEYSPACE demodb WITH REPLICATION
=
{'class' : 'SimpleStrategy','replication_factor':
3};
classжИУїИДжЦВпТдЃЌreplication_factorжИУїИДжЦЕФЗнЪ§
ЪЙгУkeyspace
ИќаТkeyspace
ALTER KEYSPACEdemodb
WITH REPLICATION = { 'class' : 'SimpleStrategy',
'replication_factor' : 2};
ALTER KEYSPACEdemodb WITH REPLICATION ={'class'
: 'NetworkTopologyStrategy', 'dc1' : 3, 'dc2':
2}; |
жЎКѓдкУПИіЪмгАЯьЕФНкЕужДааnodetoolrepair demodb
ДДНЈБэ
use demodb
CREATE TABLEusers (
user_name varchar,
password varchar,
gender varchar,
session_token varchar,
state varchar,
birth_year bigint,
PRIMARY KEY (user_name)); |
ЪЙгУИДКЯprimary keyДДНЈБэ
CREATE TABLEemp
(
empID int,
deptID int,
first_name varchar,
last_name varchar,
PRIMARY KEY (empID, deptID)); |
ВхШыЪ§Он
| INSERT INTOemp
(empID, deptID, first_name, last_name) VALUES
(104, 15, 'jane', 'smith'); |
ВщбЏБэЃЈвдЯЕЭГБэЮЊР§ЃЉ
systemЪЧCassandraЕФЯЕЭГПтЃЌЕБЧАКЌschema_keyspacesЁЂlocalЁЂ
peersЁЂschema_columnsКЭschema_columnfamiliesМИИіБэЃЌЗжБ№АќКЌkeyspaceаХЯЂЃЌБОЕиНкЕуаХЯЂЁЂМЏШКНкЕуаХЯЂЁЂcolumnsаХЯЂКЭcolumnfamiliesаХЯЂ
use system
SELECT * from schema_keyspaces;ЛёШЁЕНЕБЧАНкЕужаЕФeyspace
SELECT * FROMpeersЛёШЁНкЕуЫљдкМЏШКаХЯЂ
ЬсШЁВЂХХађВщбЏНсЙћ
SELECT * FROMemp WHERE empID IN (103,104) ORDER BY
deptID DESC;
ЪЙгУkeyspaceЯоЖЈЗћ
ОГЃЪЙгУUSE keyspacenameРДЧаЛЛkeyspaceПЩФмВЛЗНБуЃЌПЩЪЙгУkeyspaceЯоЖЈЗћжИЖЈБэЫљЪєЕФkeyspaceЃЌШч
SELECT * fromsystem.schema_keyspaces;
ПЩдкALTER TABLECЁЂREATE TABLEЁЂDELETEЁЂINSERTЁЂ
SELECTЁЂTRUNCATEЁЂUPDATEжаЪЙгУ
жИЖЈcolumnЕФЙ§ЦкЪБМф
| INSERT INTOemp
(empID, deptID, first_name, last_name) VALUES
(105, 17, 'jane', 'smith')USING TTL 60; |
ЦфжаUSING TTL 60жИУїИУЬѕЪ§Он60УыКѓЙ§ЦкЃЌНьЪБЛсБЛздЖЏЩОГ§ЁЃСэЭтжИЖЈСЫTTLЕФЪ§ОнcolumnsЛсдкcompactionКЭrepairВйзїжаБЛздЖЏЩОГ§ЁЃжИЖЈTTLЛсга8зжНкЖюЭтПЊЯњЁЃ
ВщбЏЙ§ЦкЪБМф
| SELECT TTL(last_name)from
emp; |
ИќаТЙ§ЦкЪБМф
INSERT INTOemp (empID, deptID, first_name,
last_name) VALUES (105, 17, 'miaomiao', 'han')USING
TTL 3600;вВМДЃЌвдаТЕФTTLжиВхвЛБщЪ§ОнМДПЩЁЃЃЈжИЖЈВхШыЕФећЬѕЪ§ОнЕФЙ§ЦкЪБМфЃЉ
ЛђепUPDATA emp USINGTTL 3600 SET last_name=
'han' where empid=105 and deptid=17; ЃЈжИЖЈsetжИУїЕФЪ§ОнЕФЙ§ЦкЪБМфЃЉ
ВщбЏаДШыЪБМф
SELECTWRITETIME(first_name) from emp;ПЩВщЕФИУЪ§ОнКЮЪББЛВхШыЁЃ
ЬэМгcolumns
ALTER TABLEemp ADD address varchar;
ИќИФcolumnЪ§ОнРраЭ
ALTER TABLEemp ALTER address TYPE text;
вЦГ§Ъ§Он
2 жИЖЈЙ§ЦкЪБМфЃЈЭЌЩЯЃЉ
2 ЩОГ§tableЛђkeyspace
DROP TABLE table_name
DROP KEYSPACE keyspace_name;
2 ЩОГ§columnsКЭrows
DELETE last_name FROM emp WHEREempid=104 and deptid=15;
DELETE FROM emp WHERE empid=104 anddeptid=15;
ЪЙгУcollectionРраЭ
2 setРраЭ
CREATE TABLE
users (
user_id text PRIMARY KEY,
first_name text,
last_name text,
emails set<text>
);
n INSERT INTO users (user_id, first_name, last_name,
emails) VALUES('frodo','Frodo', 'Baggins', {'f@baggins.com',
'baggins@gmail.com'});
n UPDATE users SET emails = emails + {'fb@friendsofmordor.org'}
WHEREuser_id = 'frodo';
n UPDATE users SET emails = emails - {'fb@friendsofmordor.org'}
WHEREuser_id = 'frodo';
n UPDATE users SET emails = {} WHERE user_id =
'frodo';
n DELETE emails FROM users WHERE user_id = 'frodo'; |
2 listРраЭ
n ALTER TABLE
users ADD top_places list<text>;
n UPDATE users SET top_places = [ 'rivendell',
'rohan' ] WHERE user_id= 'frodo';
n UPDATE users SET top_places = [ 'the shire'
] + top_places WHEREuser_id = 'frodo';
n UPDATE users SET top_places = top_places + [
'mordor' ] WHEREuser_id = 'frodo';
n UPDATE users SET top_places[2] = 'riddermark'
WHERE user_id ='frodo';
n DELETE top_places[3] FROM users WHERE user_id
= 'frodo';
n UPDATE users SET top_places = top_places - ['rivendell']
WHEREuser_id = 'frodo'; |
2 mapРраЭ
n ALTER TABLE
users ADD todo map<timestamp, text>;
n UPDATE users SET todo =
{ '2012-9-24' : 'entermordor',
'2012-10-2 12:00' : 'throwring into mount doom'
}
WHERE user_id = 'frodo';
n UPDATE users SET todo['2012-10-2 12:00'] = 'throw
my precious intomount doom'WHERE user_id = 'frodo';
n INSERT INTO users (user_id,todo) VALUES ('miaohan',
{ '2013-9-22 12:01' : 'birthday wishes to Bilbo',
'2013-10-1 18:00' : 'Check into Inn of Prancing
Pony' });
n DELETE todo['2012-9-24'] FROM users WHERE user_id
= 'frodo';
n UPDATE users USING TTL 60 SET todo['2012-10-1']
= 'find water' WHEREuser_id = 'frodo'; |
зЂЃЛПЩЮЊЩЯЪіШ§жжМЏКЯРраЭЕФУПИідЊЫиЩшжУЕЅЖРЕФЙ§ЦкЪБМфЁЃ
ДДНЈКЭЪЙгУЫїв§
CREATE INDEXlast_name_key
ON users(last_name);
SELECT * FROMusers WHERE last_name = 'Baggins'ЃЈашДДНЈСЫЫїв§ВХФмдкWHEREжаЪЙгУИУСаНјааВщбЏЃЌднЮоЖрСаЫїв§ЃЌашж№СаЗжБ№НЈСЂЫїв§ЃЉ |
ЧсСПМЖЪТЮё
ЪЙгУIFДгОфЪЕЯж
n INSERT INTO
emp(empid,deptid,address,first_name,last_name)
VALUES(102,14,'luoyang','Jane Doe','li') IF NOT
EXISTS;
n UPDATE emp SET address = 'luoyang' WHERE empid
= 103 and deptid = 16IF last_name='zhang'; |
ЪЙгУcounter
гУгкМЧТМЬиЖЈЪБМфЛђДІРэЕФДЮЪ§ЁЃЖдгІЕФcolumnашЪЙгУcounterЪ§ОнРраЭЃЌИУРрЪ§ОнвЛАуДцДЂгкзЈУХЕФБэжаЃЌЧвЪЙгУUPDATEдиШыВЂдіМѕcounterжЕЃЌВЛЪЙгУINSERTВхШыcounterжЕЁЃжЛФмдкдЪ§жЕЕФЛљДЁЩЯдіМѕЃЌВЛФмЮЊжБНгжИЖЈвЛИіЪ§жЕЁЃ
CREATEKEYSPACE
counterks WITH REPLICATION = { 'class' : 'SimpleStrategy','replication_factor'
: 3 };
CREATE TABLEcounterks.page_view_counts
(counter_valuecounter,
url_name varchar,
page_name varchar,
PRIMARY KEY (url_name, page_name)
);
UPDATEcounterks.page_view_counts
SET counter_value = counter_value + 1
WHERE url_name='www.datastax.com' ANDpage_name='home'; |
ШєдРДВЛДцдкWHEREЬѕМўжажИЖЈЕФФкШнЃЌИУЬѕгяОфЛсНЋБэжаЕФurl_nameжЕжУЮЊ'www.datastax.com'НЋpage_nameжУЮЊЁЏhomeЁЏ,НЋcounter_valueжИЖЈЮЊФЌШЯГѕЪМжЕ0Мг1ЁЃШєWHEREЬѕМўжажИЖЈЕФФкШнДцдкЃЌдђНЋcounter_valueжУЮЊдРДЕФcounter_valueМг1
UPDATEcounterks.page_view_counts
SET counter_value = counter_value + 2
WHERE url_name='www.baidu.com' ANDpage_name='map'; |
6АВШЋ
Ш§ЗНУцАВШЋВпТд
Client-to-node/node-to-nodeМгУмЃЈSSLЃЉЃКМгУмДЋЪфЕФЪ§Он
ЛљгкЕЧТМеЫЛЇ/УмТыЕФШЯжЄЃКШЗЖЈЫПЩвдЪЙгУЪ§ОнПт
ЖдЯѓЪкШЈЙмРэЃКШЗЖЈгУЛЇПЩдкдкЪ§ОнПтЩЯИЩЪВУД
6.1 SSLМгУм
6.1.1Client-to-node
зМБИжЄЪщ
ЮЊУПИіНкЕуВњЩњЫНдП/ЙЋдПЖд
| keytool-genkey
-alias cassandra_vms00780 -keystore ~/keys/.keystore |
ЕМГіЙЋдПВПЗжЕНЕЅЖРЕФжЄЪщЮФМўЃЌВЂПНБДИУЮФМўЕНЦфЫћЫљгаНкЕу
| keytool-export
-alias cassandra_vms00780 -file ~keys/cassandra_vms00780.cer
-keystore ~/keys/.keystore |
НЋУПИіНкЕуЕФжЄЪщЬэМгЕНЫљгаНкЕуЕФаХШЮПтжа
| keytool-import
-v -trustcacerts -alias cassandra_vms00780 -file
cassandra_vms00780.cerЈCkeystore ~/keys/ .truststore |
БЃжЄНЋ.keystoreКЭtruststoreЮФМўЗжЗЂЕНЫљгаНкЕу
ШЗШЯ.keystoreЮФМўжЛЖдCassandradaemonПЩЖС
БрМХфжУЮФМў
ХфжУcassandra.yamlЮФМўжаclient_encryption_optionsВПЗжЕФВЮЪ§
client_encryption_options:
enabled: true
keystore: ~keys/.keystore## .keystore fileТЗОЖ
keystore_password:<keystore password> ##
ВњЩњkeystoreЪБгУЕФУмТы
truststore: ~keys/.truststore
truststore_password:<truststore password>
require_client_auth:<true or false> |
6.1.2node-to-node
зМБИжЄЪщ
ЭЌЩЯ
БрМХфжУЮФМў
ХфжУcassandra.yamlЮФМўжаserver_encryption_optionsВПЗжЕФВЮЪ§
server_encryption_options:
internode_encryption: <internode_option:all/none/dc/rack>
keystore: ~keys/.keystore
keystore_password: <keystore password>
truststore:~keys/.truststore
truststore_password: <truststorepassword>
require_client_auth: <true or false> |
6.1.3дкcqlshжаЪЙгУSSL
ПЩдкжїФПТМвРОнбљР§ЮФМўcqlshrc.sampleДДНЈ.cqlshrcЮФМў
[authentication]
username = cassandra
password = cassandra
[connection]
hostname = localhost
port = 9160
factory =cqlshlib.ssl.ssl_transport_factory
[ssl]
certfile =~/keys/cassandra.cer
validate = true
[certfiles]
192.168.1.3 =~/keys/cassandra01.cert
192.168.1.4 =~/keys/cassandra02.cert |
6.2ФкВПШЯжЄ
ЛљгкCassandraПижЦЕФЕЧТМеЫЛЇКЭУмТы
ШЯжЄгУЕФЕЧТМУћКЭОbcryptЩЂСаЕФУмТыДцДЂгк system_auth.credentialsБэжа
6.2.1ХфжУ
ЕквЛВН
ШєвЊЪЙгУЛљгкгУЛЇУћ/УмТыЕФШЯжЄЛњжЦЃЌашвЊЯШХфжУ cassandra.yamlЮФМўжаauthenticatorЕФжЕЮЊ
PasswordAuthenticatorЃЈИУВЮЪ§ФЌШЯжЕЮЊAllowAllAuthenticatorЃЌМДЃЌВЛНјааШЮКЮШЯжЄЃЉЁЃетбљcassandra
Лсдкsystem_auth.userДДНЈвЛИіГЌМЖгУЛЇЃЌ гУЛЇУћКЭУмТыОљЮЊcassandraЁЃжЎКѓЃЌ
ХфжУsystem_authетИіkeyspaceЕФ replication factorЮЊНЯДѓЕФжЕ ЃЈЯъМћЕк5еТЪЙгУДДНЈЁЂИќаТkeyspaceВПЗжЕФФкШнЃЉ
ШЯжЄгяОф
ALTER USER
| ALTER USERuser_name
WITH PASSWORD 'password' (NOSUPERUSER| SUPERUSER) |
зЂЃКSUPERUSERПЩИќИФЦфЫћгУЛЇЕФУмТыКЭSUPERUSERзДЬЌ
(NOSUPERUSERЛђ SUPERUSER)ЃЌЕЋВЛФмИФБфздМКЕФSUPERUSERзДЬЌЁЃЦеЭЈгУЛЇжЛФмИќИФздМКЕФУмТыЁЃ
CREATE USER
| CREATE USERuser_name
WITH PASSWORD 'password' (NOSUPERUSER| SUPERUSER) |
жЛгаSUPERUSERПЩДДНЈгУЛЇЃЌДДНЈЕФгУЛЇФЌШЯЮЊNOSUPERUSER
DROP USER
жЛгаSUPERUSERПЩЩОГ§гУЛЇЃЌгУЛЇВЛФмздМКЩОГ§здМКЁЃ
LIST USERS
LIST USERSЃЈЮЊЪВУДУЛгаНсЙћЃПЃПЃПЃЉ
СаГігУЛЇ
ИќИФФЌШЯSUPERUSER
ЪЙгУФЌШЯSUPERUSERвВМДcassandraЕЧТМ
| ./cqlsh -ucassandra
-p Cassandra |
аТНЈСэвЛSUPERUSERЃЌжЎКѓЩОГ§дcassandraSUPERUSER
create userus_yanzhaozhang
with password 'cassandra' superuser;
drop usercassandra; |
жиЦєcassandraЃЌЪЙгУаТЕФSUPERUSERЕЧТМЃЌжДааКѓајВйзїЁЃ
6.2.2ЪЙгУcqlshЕЧТМ
ШєЪЙгУcqlshЕЧТМЃЌПЩНЋШЯжЄаХЯЂДцДЂгк.cqlshrcЮФБОЮФМўЃЌЗХжУдкгУЛЇжїФПТМжаЃЌвдУтжиИДТМШыЕЧТМаХЯЂЁЃзЂвтЖдИУЮФБОЮФМўЩшжУЖдгІЕФШЈЯовдЗРаХЯЂаЙТЖЁЃ
[authentication]
username = example_username
password = example_password |
6.3ФкВПЪкШЈ
ЖдЯѓШЈЯоЙмРэЛљгкФкВПЪкШЈЃЌгыЙиЯЕаЭЪ§ОнПтGRANT/REVOKEгяЗЈРрЫЦЁЃ
ЪзЯШвЊХфжУcassandra.yamlжаauthorizerЕФжЕЮЊCassandraAuthorizer
(ФЌШЯЮЊAllowAllAuthorizerЃЌ дЪаэШЮКЮгУЛЇЕФШЮКЮЖЏзї)ЃЌЩшЖЈЮЊИУжЕКѓЛсНЋЪкШЈаХЯЂДцДЂдк
system_auth.permissionsБэжаЁЃ
жЎКѓЃЌХфжУsystem_authетИіkeyspaceЕФreplicationfactorЮЊНЯДѓЕФжЕЁЃ
ЭЈЙ§ЩшжУpermissions_validity_in_msбЁЯюЕїећШЈЯогааЇЦкЁЃ
гяЗЈ
GRANTpermission_name PERMISSION
| ( GRANT ALLPERMISSIONS ) ON resource TO user_name
REVOKE (permission_name PERMISSION )
| ( REVOKE ALLPERMISSIONS )
ON resourceFROM user_name
LISTpermission_name PERMISSION
| ( LIST ALLPERMISSIONS )
ON resource OF user_name
NORECURSIVE
Цфжаpermission_nameЮЊ
ALL
ALTER
AUTHORIZE
CREATE
DROP
MODIFY
SELECT
resourceЮЊ
ALL KEYSPACES
KEYSPACE keyspace_name
TABLE keyspace_name.table_name
6.4ХфжУЗРЛ№ЧНЖЫПкЗУЮЪ
ашдкЗРЛ№ЧНВпТджаПЊЗХвЛЯТЖЫПк
ЙЋЙВЖЫПк
n 22 sshЖЫПк
n 8888 OpsCenter websiteЖЫПк
CassandraНкЕуМфЖЫПк
n 1024+ JMX reconnection/loopbackЖЫПк
n 7000 CassandМЏШКФкНкЕуМфЭЈбЖЖЫПк
n 7199 Cassandra JMX МрПиЖЫПк
n 9160 CassandraПЭЛЇЖЫЖЫПк
Cassandra OpsCenter ЖЫПк
n 61620 OpsCenterМрПиЖЫПк
n 61621 OpsCenterДњРэЖЫПк
7МмЙЙ
7.1ЙЃИХ
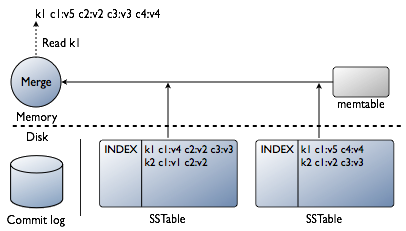
ЕуЖдЕуЗжВМЪНЯЕЭГЃЌМЏШКжаИїНкЕуЦНЕШЃЌЪ§ОнЗжВМгкМЏШКжаИїНкЕуЃЌИїНкЕуМфУПУыНЛЛЛвЛДЮаХЯЂЁЃУПИіНкЕуЕФcommit
logВЖЛёаДВйзїРДШЗБЃЪ§ОнГжОУадЁЃЪ§ОнЯШБЛаДШыmemtable-ФкДцжаЕФЪ§ОнНсЙЙЃЌД§ИУНсЙЙТњКѓЪ§ОнБЛаДШыSSTable-гВХЬжаЕФЪ§ОнЮФМўЁЃЫљгаЕФаДФкШнБЛздЖЏдкМЏШКжаЗжЧјВЂИДжЦЁЃ
CassandraЪ§ОнПтУцЯђааЁЃЪкШЈгУЛЇПЩСЌНгжСШЮвтЪ§ОнжааФЕФШЮвтНкЕуЃЌВЂЭЈЙ§РрЫЦSQLЕФCQLВщбЏЪ§ОнЁЃМЏШКжаЃЌвЛИігІгУвЛАуАќКЌвЛИіkeyspaceЃЌвЛИіkeyspaceжаАќКЌЖрИіБэЁЃ
ПЭЛЇЖЫСЌНгЕНФГвЛНкЕуЗЂЦ№ЖСЛђаДЧыЧѓЪБЃЌИУНкЕуГфЕБПЭЛЇЖЫгІгУгыгЕгаЯргІЪ§ОнЕФНкЕуМфЕФаЕїеп(coordinatorЃЉвдИљОнМЏШКХфжУШЗЖЈЛЗжаЕФФФИіНкЕуЕБЛёШЁетИіЧыЧѓЁЃ
ЙиМќДЪ
GossipЃКЕуЖдЕуЭЈаХавщЃЌгУвдCassandraМЏШКжаНкЕуМфНЛЛЛЮЛжУКЭзДЬЌаХЯЂЁЃ
PartitionerЃКОіЖЈШчКЮдкМЏШКжаЕФНкЕуМфЗжЗЂЪ§ОнЃЌвВМДдкФФИіНкЕуЗХжУЪ§ОнЕФЕквЛИіreplicaЁЃ
Replica placement strategyЃКОіЖЈдкФФаЉНкЕуЗХжУЪ§ОнЕФЦфЫћreplicaЁЃCassandraдкМЏШКжаЕФЖрИіНкЕуДцДЂЪ§ОнЕФЖрЗнПНБД-replicasРДШЗБЃПЩППКЭШнДэЁЃ
SnitchЃКЖЈвхСЫИДжЦВпТдгУРДЗХжУreplicasКЭТЗгЩЧыЧѓЫљЪЙгУЕФЭиЦЫаХЯЂ
cassandra.yamlЮФМўЃКCassandraжїХфжУЮФМў
system:CassandraЕФЯЕЭГkeyspaceЃЌДцЗХtableЁЂkeyspaceЕФЪєадаХЯЂЕШЁЃЖјЪєадаХЯЂПЩЭЈЙ§CQLЛђЦфЫћЧ§ЖЏЩшжУЁЃ
7.2НкЕуМфЭЈаХ
CassandraЪЙгУЕуЖдЕуЭЈбЖавщgossipдкМЏШКжаЕФНкЕуМфНЛЛЛЮЛжУКЭзДЬЌаХЯЂЁЃgossipНјГЬУПУыдЫаавЛДЮЃЌгыжСЖр3ИіЦфЫћНкЕуНЛЛЛаХЯЂЃЌетбљЫљгаНкЕуПЩКмПьСЫНтМЏШКжаЕФЦфЫћНкЕуаХЯЂЁЃ
ХфжУgossipЃЈдкcassandra.ymalжаЩшжУЃЉ
cluster_name:НкЕуЫљЪєМЏШКУћЃЌМЏШКжаУПИіНкЕугІЯрЭЌЁЃ
listen_addressЃКЙЉЦфЫћНкЕуСЌНгжСИУНкЕуЕФIPЕижЗЛђжїЛњУћЃЌЕБгЩlocalhostЩшЮЊЙЋЙВЕижЗЁЃ
seed_providerЃКЖККХЗжИєЕФIPЕижЗЃЈжжзгСаБэЃЉЃЌgossipЭЈЙ§жжзгНкЕубЇЯАЛЗЕФЭиЦЫЃЌМЏШКжаИїНкЕужжзгСаБэЕБЯрЭЌЁЃЖрЪ§ОнжааФМЏШКжаУПИіЪ§ОнжааФЕФжжзгСаБэЕБжСЩйАќКЌвЛИіИУжааФФкЕФНкЕуЁЃ
storage_portЃКНкЕуМфЭЈбЖЖЫПкЃЌМЏШКжаИїНкЕуЕБвЛжТЁЃ
initial_tokenЃКгУгкsingle-node-per-tokenНсЙЙЃЌНкЕудкЛЗПеМфжЛгЕгавЛЖЮСЌајЕФtokenЗЖЮЇЁЃ
num_tokensЃКгУгкvirtual nodesЃЌЖЈвхСЫНкЕудкЛЗПеМфЫљгЕгаЕФЫцЛњЗжХфЕФtokenЪ§ФПЁЃ
ЪЇАмМьВтгыЛжИД
gossipПЩМьВтЦфЫћНкЕуЪЧЗёе§ГЃвдБмУтНЋЧыЧѓТЗгЩжСВЛПЩДяЛђепадФмВюЕФНкЕуЃЈКѓепашХфжУЮЊdynamic
snitchЗНПЩЃЉЁЃ
ПЩЭЈЙ§ХфжУphi_convict_thresholdРДЕїећЪЇАмМьВтЕФУєИаЖШЁЃ
ЖдгкЪЇАмЕФНкЕуЃЌЦфЫћНкЕуЛсЭЈЙ§gossipЖЈЦкгыжЎСЊЯЕвдВщПДЪЧЗёЛжИДЖјЗЧМђЕЅНЋжЎвЦГ§ЁЃШєашЧПжЦЬэМгЛђвЦГ§МЏШКжаНкЕуашЪЙгУnodetoolЙЄОпЁЃ
вЛЕЉФГНкЕуБЛБъМЧЮЊЪЇАмЃЌЦфДэЙ§ЕФаДВйзїЛсгаЦфЫћreplicasДцДЂвЛЖЮЪБМфЃЈашПЊЦєhinted
handoffЃЌШєНкЕуЪЇАмЕФЪБМфГЌЙ§СЫmax_hint_window_in_msЃЌДэЙ§ЕФаДВЛдйБЛДцДЂЁЃЃЉDownЕєЕФНкЕуОЙ§вЛЖЮЪБМфЛжИДКѓашжДааrepairВйзїЃЌвЛАудкЫљгаНкЕудЫааnodetool
repairвдШЗБЃЪ§ОнвЛжТЁЃ
7.3Ъ§ОнИДжЦКЭЗжЗЂ
CassandraжаЗжЗЂЁЂИДжЦЭЌЪБНјааЁЃCassandraБЛЩшМЦЮЊЕуЖдЕуЯЕЭГЃЌЛсДДНЈЪ§ОнЕФЖрИіИББОДцДЂдкМЏШКжаЕФвЛзщНкЕужаЁЃCassandraжаЪ§ОнБЛзщжЏЮЊБэЃЌгЩprimary
keyБъЪЖЃЌprimary keyОіЖЈЪ§ОнНЋБЛДцДЂдкФФИіНкЕуЁЃ
ашжИЖЈЕФФкШн
Virtual nodesЃКжИЖЈЪ§ОнгыЮяРэНкЕуЕФЫљЪєЙиЯЕ
PartitionerЃКдкМЏШКФкЛЎЗжЪ§Он
ReplicationstrategyЃКОіЖЈШчКЮДІРэУПааЪ§ОнЕФreplicas
SnitchЃКЖЈвхreplicationstrategyЗХжУЪ§ОнЕФreplicasЪБЪЙгУЕФЭиЦЫаХЯЂ
вЛжТадЙўЯЃ
БэжаУПааЪ§ОнгЩprimary keyБъЪЖЃЌCassandraЮЊУПИіprimarykeyЗжХфвЛИіhashжЕЃЌМЏШКжаУПИіНкЕугЕгавЛИіЛђЖрИіhashжЕЧјМфЁЃетбљБуПЩИљОнprimary
keyЖдгІЕФhashжЕНЋИУЬѕЪ§ОнЗХдкАќКЌИУhashжЕЕФhashжЕЧјМфЖдгІЕФНкЕужаЁЃ
ащФтНкЕу
ЪЙгУащФтНгЕчЪгЪ§ОндкМЏШКжаЕФЗжВМ
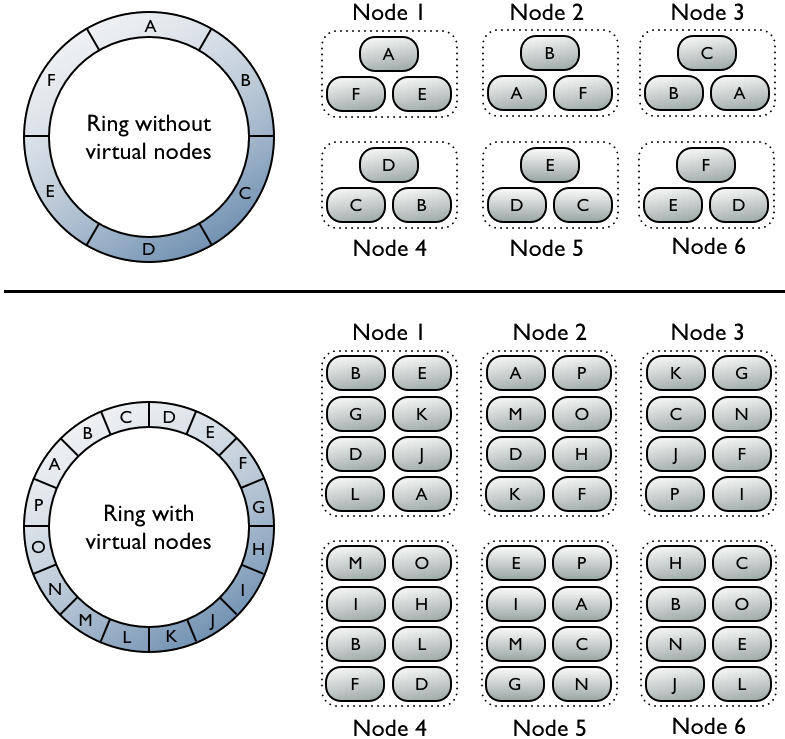
ШєВЛЪЙгУащФтНкЕудђашЪжЙЄЮЊМЏШКжаУПИіНкЕуМЦЫуКЭЗжХфвЛИіtokenЁЃУПИіtokenОіЖЈСЫНкЕудкЛЗжаЕФЮЛжУвдМАНкЕугІЕБГаЕЃЕФвЛЖЮСЌајЕФЪ§ОнhashжЕЕФЗЖЮЇЁЃШчЩЯЭМЩЯАыВПЗжЃЌУПИіНкЕуЗжХфСЫвЛИіЕЅЖРЕФtokenДњБэЛЗжаЕФвЛИіЮЛжУЃЌУПИіНкЕуДцДЂНЋrow
keyгГЩфЮЊhashжЕжЎКѓТфдкИУНкЕугІЕБГаЕЃЕФЮЈвЛЕФвЛЖЮСЌајЕФhashжЕЗЖЮЇФкЕФЪ§ОнЁЃУПИіНкЕувВАќКЌРДздЦфЫћНкЕуЕФrowЕФИББОЁЃЖјЪЧгУащФтНкЕудЪаэУПИіНкЕугЕгаЖрИіНЯаЁЕФВЛСЌајЕФhashжЕЗЖЮЇЁЃШчЩЯЭМжаЯТАыВПЗжЃЌМЏШКжаЕФНкЕуЪЧгУСЫащФтНкЕуЃЌащФтНкЕуЫцЛњбЁдёЧвВЛСЌајЁЃЪ§ОнЕФДцЗХЮЛжУвВгЩrow
keyгГЩфЖјЕУЕФhashжЕШЗЖЈЃЌЕЋЪЧЪЧТфдкИќаЁЕФЗжЧјЗЖЮЇФкЁЃ
ЪЙгУащФтНкЕуЕФКУДІ
ЮоашЮЊУПИіНкЕуМЦЫуЁЂЗжХфtoken
ЬэМгвЦГ§НкЕуКѓЮоашжиаТЦНКтМЏШКИКди
жиНЈЫРЕєЕФНкЕуИќПь
ИФЩЦСЫдкЭЌвЛМЏШКЪЙгУвьжжЛњЦї
Ъ§ОнИДжЦ
CassandraдкЖрИіНкЕужаДцЗХreplicasвдБЃжЄПЩППадКЭШнДэадЁЃ
replicationstrategyОіЖЈЗХжУreplicasЕФНкЕуЁЃ replicasЕФзмЪ§гЩИДжЦвђзг-
replication factorШЗЖЈЃЌБШШчвђзгЮЊ2ДњБэУПаагаСНЗнПНБДЃЌУПЗнПНБДДцДЂдкВЛЭЌЕФНкЕужаЁЃЫљгаЕФreplicasЮожїДгжЎЗжЁЃreplication
factorЭЈГЃВЛФмГЌЙ§МЏШКжаНкЕузмЪ§ЁЃШЛЖјЃЌПЩЯждіМгreplication factoжЎКѓдкНЋНкЕудіжСЦкЭћЕФЪ§СПЁЃ
ЕБreplication factoГЌЙ§змНсЕуЪ§ЪБЃЌаДВйзїБЛОмОјЃЌЕЋЖСВйзїПЩНјааЃЌжЛвЊТњзуЦкЭћЕФвЛжТадМЖБ№ЁЃ
ЕБЧАгаСНжжПЩгУЕФИДжЦВпТдЃК
SimpleStrategyЃКНігУгкЕЅЪ§ОнжааФЃЌНЋЕквЛИіreplicaЗХдкгЩ
partitionerШЗЖЈЕФНкЕужаЃЌЦфгрЕФreplicasЗХдкЩЯЪіНкЕуЫГЪБеыЗНЯђЕФКѓајНкЕужаЁЃ
NetworkTopologyStrategyЃКПЩгУгкНЯИДдгЕФЖрЪ§ОнжааФЁЃПЩвджИЖЈдкУПИіЪ§ОнжааФЗжБ№ДцДЂЖрЩйЗнreplicasЁЃдкУПИіЪ§ОнжааФЗХжУreplicasЕФЗНЪНРрЫЦгкSimpleStrategyЃЌЕЋЧуЯђгкНЋreplicasЗХдкВЛЭЌrackЃЌвђЮЊЭЌвЛrackЕФНкЕуЧуЯђгкЭЌЪБЪЇАмЁЃХфжУУПИіЪ§ОнжааФЗжБ№ЗХжУЖрЩйreplicasЪБвЊПМТЧСНИіжївЊЗНУцЃК(1)ПЩТњзуБОЕиЖСЖјЗЧПчЪ§ОнжааФЖСЃЛ(2)ЪЇАмГЁОАЁЃСНжжГЃгУЕФХфжУЗНЪНЮЊ(1)УПИіЪ§ОнжааФСНЗнreplicasЃЌ(2)УПИіЪ§ОнжааФ3ЗнreplicasЁЃЕБШЛЃЌгУгкЬиЪтФПЕФЕФЗЧЖдГЦХфжУвВЪЧПЩвдЕФЃЌБШШчдкЖСВйзїНЯЦЕЗБЕФЪ§ОнжааФХфжУ3ЗнreplicasЖјдкгУгкЗжЮіЕФЪ§ОнжааФХфжУвЛЗнreplicasЁЃ
ИДжЦВпТддкДДНЈkeyspaceЪБжИЖЈЃЌШч
CREATEKEYSPACE Excelsior WITH REPLICATION
= { 'class' : 'SimpleStrategy','replication_factor'
: 3 };
CREATEKEYSPACE "Excalibur"
WITH REPLICATION = {'class' :'NetworkTopologyStrategy',
'dc1' : 3, 'dc2' : 2};
Цфжаdc1ЁЂdc2етаЉЪ§ОнжааФУћГЦвЊгыsnitchжаХфжУЕФУћГЦвЛжТЁЃ
7.4Partitioners
дкCassandraжаЃЌtableЕФУПаагЩЮЈвЛЕФprimarykeyБъЪЖЃЌpartitionerЪЕМЪЩЯЮЊвЛhashКЏЪ§гУвдМЦЫуprimary
keyЕФtokenЁЃCassandraвРОнетИіtokenжЕдкМЏШКжаЗХжУЖдгІЕФааЁЃ
Ш§жжpartitioner(дкcassandra.yamlжаЩшжУ)
Murmur3PartitionerЃКЕБЧАЕФФЌШЯжЕЃЌвРОнMurmurHashЙўЯЃжЕдкМЏШКжаОљдШЗжВМЪ§ОнЁЃ
RandomPartitionerЃКвРОнMD5ЙўЯЃжЕдкМЏШКжаОљдШЗжВМЪ§ОнЁЃ
ByteOrderedPartitionerЃКвРОнааkeyЕФзжНкДгзжУцЩЯдкМЏШКжаЫГађЗжВМЪ§ОнЁЃЃЈВЛЭЦМіЪЙгУЃЉ
Murmur3PartitionerКЭRandomPartitionerЪЙгУtokenЯђУПИіНкЕужИХЩЕШСПЕФЪ§ОнДгЖјНЋ
keyspaceжаЕФБэОљдШЗжВМдкЛЗжаЃЌМДЪЙВЛЭЌЕФБэЪЙгУВЛЭЌЕФprimary keyЁЃЖСаДЧыЧѓОљБЛОљдШЕФЗжВМЁЃ
ByteOrderedPartitionerдЪаэЭЈЙ§primary keyЫГађЩЈУшЃЈПЩЭЈЙ§indexДяЕНЭЌбљФПЕФЃЉЃЌЕЋвбв§Ц№ШчЯТЮЪЬт(1)НЯИДдгЕФИКдиОљКтЃЌ(2)ЫГађЕФаДвзЕМжТШШЕуЃЌ(3)ЖрБэВЛОљдШЕФИКдиОљКтЁЃ
зЂвтЃКШєЪЙгУащФтНкЕу(vnodes)дђЮоашЪжЙЄМЦЫуtokensЁЃ
ШєВЛЪЙгУащФтНкЕудђБиаыЪжЙЄМЦЫуtokens НЋЫљЕУЕФжЕжИХЩИјcassandra.ymalжїХфжУЮФМўжаЕФinitial_tokenВЮЪ§ЁЃ
7.5Snitches
ЬсЙЉЭјТчЭиЦЫаХЯЂЃЌгУвдШЗЖЈЯђ/ДгФФИіЪ§ОнжааФЛђепЭјМмаДШы/ЖСШЁЪ§ОнЁЃ
зЂвтЃК(1)ЫљгаНкЕуашгУЯрЭЌЕФsnitch;(2)МЏШКжавбВхШыЪ§ОнКѓгЩИќИФСЫsnitchдђашдЫаавЛДЮfullrepairЁЃ
Dynamic snitching
МрПиДгВЛЭЌreplicaЖСВйзїЕФадФмЃЌбЁдёадФмзюКУЕФreplicaЁЃdynamic snitchФЌШЯПЊЦєЃЌЫљгаЦфЫћsnitchЛсФЌШЯЪЙгУdynamic
snitch ВуЁЃ
SimpleSnitch
ФЌШЯжЕЃЌгУгкЕЅЪ§ОнжааФВПЪ№ЃЌВЛЪЙгУЪ§ОнжааФКЭЭјМмаХЯЂЁЃЪЙгУИУжЕЪБkeyspaceИДжЦВпТджаЮЈвЛашжИЖЈЕФЪЧreplication
factor
RackInferringSnitch
ИљОнЪ§ОнжааФКЭЭјМмШЗЖЈНкЕуЮЛжУЃЌЖјЪ§ОнжааФМАЭјМмаХЯЂгжгаНкЕуЕФIPЕижЗвўКЌжИЪОЁЃ
PropertyFileSnitch
ИљОнЪ§ОнжааФКЭЭјМмШЗЖЈНкЕуЮЛжУЃЌЖјЭјТчЭиЦЫаХЯЂгжгЩгУЛЇЖЈвхЕФХфжУЮФМў
cassandra-topology.properties ЛёШЁЁЃ дкНкЕуIPЕижЗИёЪНВЛЭГвЛЮоЗЈвўКЌжИЪОЪ§ОнжааФМАЭјМмаХЯЂЛђепИДдгЕФИДжЦзщжаЪЙгУИУжЕЁЃашзЂвтЕФЪЧЃК(
1)ХфжУЮФМўжаЪ§ОнжааФУћашгыkeyspaceжаИДжЦВпТджажИЖЈЕФЪ§ОнжааФУћГЦвЛжТЃЛ (2)ХфжУЮФМўжаашАќКЌМЏШКжаШЮвЛНкЕуЃЛ
ЃЈ3ЃЉМЏШКжаИїНкЕуФкcassandra-topology.propertiesХфжУЮФМўашЯрЭЌЁЃ
GossipingPropertyFileSnitch
дкcassandra-rackdc.propertiesХфжУЮФМўжаЖЈвхБОНкЕуЫљЪєЕФЪ§ОнжааФКЭЭјМмЃЌ
РћгУgossipавщгыЦфЫћНкЕуНЛЛЛИУаХЯЂЁЃШєДгPropertyFileSnitchЧажСИУжЕЃЌдђашж№НкЕуж№ДЮИќаТжЕЮЊ
GossipingPropertyFileSnitchвдШЗБЃgossipгаЪБМфДЋВЅаХЯЂЁЃ
EC2Snitch
гУгкВПЪ№дкAmazon EC2жаЧвЫљгаНкЕудкЕЅИіЧјгђжаЕФМЏШКЁЃ
EC2MultiRegionSnitch
гУгкВПЪ№дкAmazonEC2жаЃЌЧвНкЕуПчЖрИіЧјгђЕФМЏШКЁЃ
7.6ПЭЛЇЖЫЧыЧѓ
clientСЌНгжСНкЕуВЂЗЂГіread/writeЧыЧѓЪБЃЌ ИУnodeГфЕБclientЖЫгІгУгыАќКЌЧыЧѓЪ§ОнЕФНкЕу
(Лђreplica)жЎМфЕФаЕїепЃЌЫќРћгУХфжУЕФpartitionerКЭreplicaplacementВпТдШЗЖЈФЧИіНкЕуЕБЛёШЁЧыЧѓЁЃ
7.6.1аДЧыЧѓ
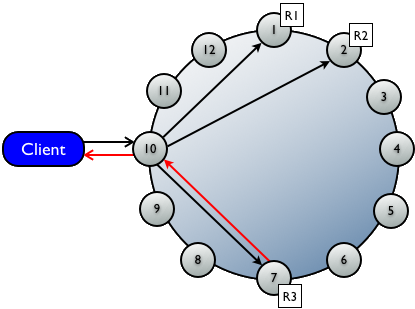
аЕїеп(coordinator)НЋwriteЧыЧѓЗЂЫЭЕНгЕгаЖдгІrowЕФЫљгаreplicaНкЕуЃЌ
жЛвЊНкЕуПЩгУБуЛёШЁВЂжДаааДЧыЧѓЁЃаДвЛжТадМЖБ№(write consistency level)ШЗЖЈвЊгаЖрЩйИі
replicaНкЕуБиаыЗЕЛиГЩЙІЕФШЗШЯаХЯЂЁЃГЩЙІвтЮЖзХЪ§ОнБЛе§ШЗаДШыСЫ commit logИіmemtableЁЃ
ЩЯР§ЮЊЕЅЪ§ОнжааФЃЌ11ИіНкЕуЃЌИДжЦвђзгЮЊ3ЃЌаДвЛжТадЕШМЖЮЊONEЕФаДЧщПіЁЃ
7.6.2ЖрЪ§ОнжааФЕФаДЧыЧѓ
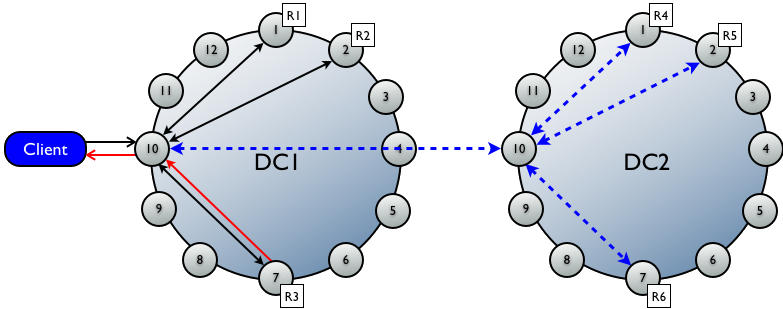
ЛљБОЭЌЩЯЃЌЕЋЛсдкИїЪ§ОнжааФЗжБ№бЁдёвЛИіаЕїепвд ДІРэИУЪ§ОнжааФФкЕФаДЧыЧѓЁЃгыclientжБНгСЌНгЕФ
coordinatorНкЕужЛашНЋаДЧыЧѓЗЂЫЭЕНдЖГЬЪ§ОнжааФЕФcoordinatorвЛИіНкЕуМДПЩЃЌ ЪЃгрЕФгЩИУcoordinatorЭъГЩЁЃШєвЛжТадМЖБ№ЩшжУЮЊONEЛђепLOCAL_QUORUMдђНігыжБНгаЕїепЮЛгкЭЌвЛЪ§ОнжааФЕФНкЕуашЗЕЛиГЩЙІШЗШЯЁЃ
ЩЯР§ЮЊЫЋЕЅЪ§ОнжааФЃЌИї11ИіНкЕуЃЌИДжЦвђзгЮЊ6ЃЌаДвЛжТадЕШМЖЮЊONEЕФаДЧщПіЁЃ
7.6.3ЖСЧыЧѓ
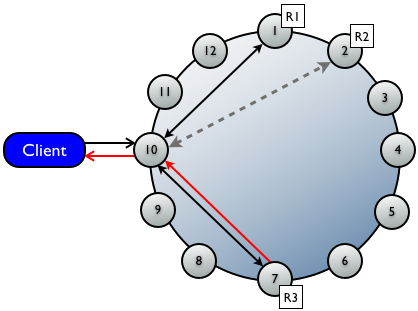
жБНгЖСЧыЧѓ
КѓЬЈЖСаоИДЧыЧѓ
гыжБНгЖСЧыЧѓСЊЯЕЕФreplicaЪ§ФПгЩвЛжТадМЖБ№ШЗЖЈЁЃКѓЬЈЖСаоИДЧыЧѓБЛЗЂЫЭЕНУЛгаЪеЕНжБНгЖСЧыЧѓЕФЖюЭтЕФreplicaЃЌвдШЗБЃЧыЧѓЕФrowдкЫљгаreplicaЩЯвЛжТЁЃ
аЕїепЪзЯШгывЛжТадМЖБ№ШЗЖЈЕФЫљгаreplicaСЊЯЕЃЌБЛСЊЯЕЕФНкЕуЗЕЛиЧыЧѓЕФЪ§ОнЃЌШєЖрИіНкЕуБЛСЊЯЕЃЌдђРДздИїreplicaЕФrowЛсдкФкДцжазїБШНЯЃЌШєВЛвЛжТЃЌдђаЕїепЪЙгУКЌзюаТЪ§ОнЕФreplicaЯђclientЗЕЛиНсЙћЁЃ
ЭЌЪБЃЌаЕїепдкКѓЬЈСЊЯЕКЭБШНЯРДздЦфгргЕгаЖдгІrowЕФreplicaЕФЪ§ОнЃЌШєВЛвЛжТЃЌЛсЯђЙ§ЪБЕФreplicaЗЂаДЧыЧѓгУзюаТЕФЪ§ОнНјааИќаТЁЃетвЛЙ§ГЬНаread
repairЁЃ
ЩЯР§ЮЊЕЅЪ§ОнжааФЃЌ11ИіНкЕуЃЌИДжЦвђзгЮЊ3ЃЌвЛжТадМЖБ№ЮЊQUORUMЕФЖСЧщПіЁЃ
8Ъ§ОнПтФкВП
8.1Ъ§ОнЙмРэ
ЪЙгУРрЫЦLog-StructuredMerge TreeЕФДцДЂНсЙЙЃЌЖјЗЧЕфаЭЕФЙиЯЕаЭЪ§ОнПтЪЙгУЕФB-TreeНсЙЙЁЃДцДЂв§ЧцСЌајЕФНЋЪ§ОнвдзЗМгЕФФЃЪНаДЮяДХХЬВЂГжајДцДЂЪ§ОнЁЃНкЕуМф/ФкЕФВйзїВЂаадЫааЁЃвђВЛЪЙгУB-TreeЙЪЮоашаЭЌПижЦЃЌдкаДЪБВЛБижДааИќаТЁЃCassandraдкSSDжаадФмБэЯжМЋМбЁЃ
ИпЭЬЭТСПКЭЕЭбгГй
ВйзїВЂаадЫааЃЌЭЬЭТСПКЭбгГйЯрЛЅЖРСЂЁЃlog-structuredЩшМЦБмУтбЏХЬПЊЯњЁЃШЅГ§on-diskЪ§ОнаоИФЃЌЪЁЪБЧвбгГЄSSDЪйУќЁЃЮоon-diskаЭЕФЪ§ОнаоИФЙЪЮоашЫјЖЈаДЧыЧѓетбљЕФаЭЌПижЦЁЃЮожїЁЂДгЃЌдкЫљгаНкЕудЫааЭЌбљЕФДњТыЁЃ
ЕЅЖРЕФБэФПТМ
/var/lib/cassandra/data/ks1/cf1 /ks1-cf1-ja-1-Data.db
Цфжа/var/lib/cassandra/data/ЮЊcassandra.yamlжажИЖЈЕФЪ§ОнЮФМўФПТМЁЃks1ЮЊkeyspaceУћcf1/ЮЊcolumnfamiliesУћЁЃетбљПЩНЋБэСЌНгжСбЁЖЈЕФФПБъЮЛжУвдБугкНЋЛюдОЕФБэвЦЕНИќПьЕФДцДЂНщжЪЃЌЛђепНЋБэЗжВЛЕНЖрИіПЩгУЕФДцДЂЩшБИвдОљКтИКди
8.2ЙигкаД
ИДжЦЕФНЧЩЋ
ЭЈЙ§дкЖрИіЭЌМЖНкЕуДДНЈЪ§ОнЕФЖрИіИББОБЃжЄПЩППадКЭШнДэЁЃБэЪЧЗЧЙиЯЕаЭЕФЃЌЮоашЙ§ЖрЖюЭтЙЄзїРДЮЌЛЄЙиСЊЕФБэЕФЭъећадЃЌвђДЫаДВйзїНЯЙиЯЕаЭЪ§ОнПтПьКмЖрЁЃ
аДЙ§ГЬ
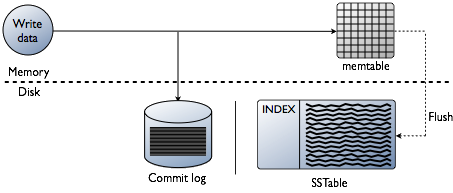
ЯШНЋЪ§ОнаДНјФкДцжаЕФЪ§ОнНсЙЙmemtableЃЌЭЌЪБзЗМгЕНДХХЬжаЕФcommitlogжаЁЃБэЪЙгУЕФдНЖрЃЌЖдгІЕФmemtableгІдНДѓЃЌcassandraЖЏЬЌЕФЮЊmemtableЗжХфФкДцЃЌвВПЩздМКЪжЙЄжИЖЈЁЃmemtableФкШнГЌГіжИЖЈШнСПКѓmemtableЪ§ОнЃЈАќРЈЫїв§ЃЉБЛЗХНјНЋБЛЫЂШыДХХЬЕФЖгСаЃЌПЩЭЈЙ§memtable_flush_queue_sizeХфжУЖгСаГЄЖШЁЃШєНЋБЛЫЂШыДХХЬЕФЪ§ОнГЌГіСЫЖгСаГЄЖШЃЌcassandraЛсЫјЖЈаДЁЃmemtableБэжаЕФЪ§ОнгЩСЌајЕФI/OЫЂНјДХХЬжаЕФSSTableЃЌжЎКѓcommit
logБЛЧхПеЁЃУПИіБэгаЖРСЂЕФmemtableКЭSSTableЁЃ
8.3ЙигкИќаТЁЂЩОГ§КЭhinted handoff writes
ИќаТЃЈcassandraжаВхШыжиИДЕФprimarykeyвВБЛПДзіЪЧИќаТВйзїЃЉ
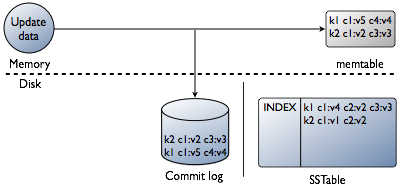

ВЛжБНгдкДХХЬжадЕиИќаТЖјЪЧЯШдкmemtableНјааЫљгаЕФИќаТЁЃзюКѓИќаТФкШнБЛЫЂШыДХХЬДцДЂдкаТЕФSSTableжаЃЌНіЕБcolumnЕФЪБМфДСБШМШДцЕФcolumnИќаТЪБВХИВИЧдРДЕФЪ§ОнЁЃ
ЩОГ§
ВЛЛсСЂМДДгДХХЬвЦГ§ЩОГ§ЕФЪ§Он
БЛЩОГ§ЕФЪ§ОнЛсБЛtombstoneБъМЧвджИЖЈЦфзДЬЌЃЌЫќЛсДцдквЛЖЈЕФЪБМф
ЃЈгЩgc_grace_secondsжИЖЈЃЉЃЌГЌГіИУЪБМфКѓcompactionНјГЬгРОУЩОГ§ИУcolumnЁЃ
ШєВЛР§ааадЕФжДааНкЕуrepairВйзїЃЌБЛЩОГ§ЕФcolumnПЩФмжиаТГіЯж
ШєЩОГ§ЦкМфНкЕуdownЕєЃЌБЛБъМЧЮЊtombstoneЕФcolumnЛсЗЂЫЭаХКХИјCassandraЪЙЦфжиЗЂЩОГ§ЧыЧѓИјИУreplicaНкЕуЁЃШєreplicaдкgc_grace_secondsЦкМфИДЛюЃЌЛсзюжеЪмЕНЩОГ§ЧыЧѓЃЌШєreplicaдкgc_grace_secondsжЎКѓИДЛюЃЌНкЕуПЩФмДэЙ§ЩОГ§ЧыЧѓЃЌЖјдкНкЕуЛжИДКѓСЂМДЩОГ§Ъ§ОнЁЃашЖЈЦкжДааНкЕуаоИДВйзїРДБмУтЩОГ§Ъ§ОнжиЯжЁЃ
hinted handoff writes
дкВЛвЊЧѓвЛжТадЪБШЗБЃаДЕФИпПЩгУЃЌдкcassandra.yamlжаПЊЦєИУЙІФмЁЃжДааwriteВйзїЪБШєгЕгаЖдгІrowЕФreplica
downЕєСЫЛђепЮоЛигІЃЌдђаЕїепЛсдкБОЕиЕФsystem.hintsБэжаДцДЂвЛИіhintЃЌжИЪОИУаДВйзїашдкВЛПЩгУЕФreplicaЛжИДКѓжиаТжДааЁЃФЌШЯhintsБЃДц3аЁЪБЃЌПЩЭЈЙ§max_hint_window_in_msИФБфИУжЕЁЃ
ЬсЪОЕФwriteВЛМЦШыconsistencylevelжаЕФONEЃЌQUORUMЛђALLЃЌЕЋМЦШыANYЁЃ
ANYвЛжТадМЖБ№ПЩШЗБЃcassandraдкЫљгаreplicaВЛПЩгУЪБШдПЩНгЪмwriteЃЌВЂЧвдкЪЪЕБЕФreplicaПЩгУЧвЪеЕНhintжиЗХКѓИУwriteВйзїПЩЖСЁЃ
вЦГ§НкЕуКѓНкЕуЖдгІЕФhintsздЖЏвЦГ§ЃЌЩОГ§БэКѓЖдгІЕФhintsвВЛсБЛвЦГ§ЁЃ
ШдашЖЈЦкжДааrepairЃЈБмУтгВМўЙЪеЯдьГЩЕФЪ§ОнЖЊЪЇЃЉ
8.4ЙигкЖС
ДгSSDВЂааЫцЛњЖСШЁЃЌбгЪБМЋЕЭЃЈВЛЭЦМіcassandraЪЙгУзЊХЬЪНгВХЬЃЉЁЃ
вдpartition keyЖС/аДЃЌЯћГ§СЫЙиЯЕаЭЪ§ОнПтжаИДдгЕФВщбЏЁЃ
ЖСSSTable
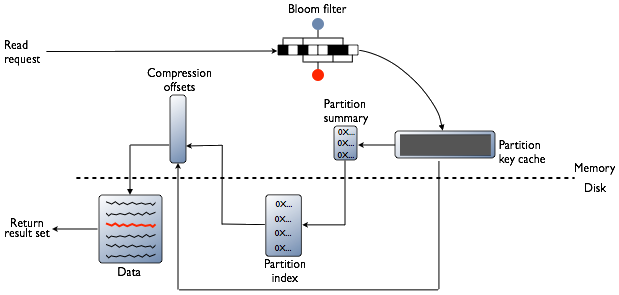
ЪзЯШМьВщBloom filterЃЌУПИіSSTableЖМгавЛИіBloomfilter
ЃЌгУвддкНјааШЮКЮДХХЬI/OЧАМьВщЧыЧѓЕФ partition keyЖдгІЕФЪ§ОндкSSTableжаДцдкЕФПЩФмадЁЃ
ШєЪ§ОнКмПЩФмДцдкЃЌдђМьВщ Partition key cache(Cassandra Бэpartition
indexЕФЛКДц)ЃЌжЎКѓИљОнindexЬѕФПЪЧЗёдкcacheжаевЕНЖјжДааВЛЭЌВНжшЃК
евЕН
Дгcompression offset mapжаВщевгЕгаЖдгІЪ§ОнЕФбЙЫѕПьЁЃ
ДгДХХЬШЁГібЙЫѕЕФЪ§ОнЃЌЗЕЛиНсЙћМЏЁЃ
ЮДевЕН
ЫбЫїPartition summaryЃЈpartition indexЕФбљБОМЏЃЉШЗЖЈindexЬѕФПдкДХХЬжаЕФНќЫЦЮЛжУЁЃ
ДгДХХЬжаSSTableФкШЁГіindexЬѕФПЁЃ
Дгcompression offset mapжаВщевгЕгаЖдгІЪ§ОнЕФбЙЫѕПьЁЃ
ДгДХХЬШЁГібЙЫѕЕФЪ§ОнЃЌЗЕЛиНсЙћМЏЁЃ
ЛиЙЫВхШы/ИќаТЪ§Он
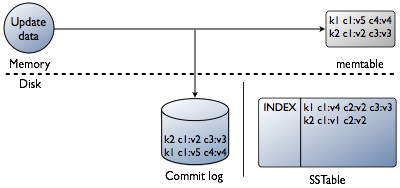

ЖСЕФЙ§ГЬ
гЩinsert/updateЙ§ГЬПЩжЊЃЌreadЧыЧѓЕНДяФГвЛНкЕуКѓЃЌБиаыНсКЯЫљгаАќКЌЧыЧѓЕФrowжаЕФcolumnЕФSSTableвдМАmemtableРДВњЩњЧыЧѓЕФЪ§ОнЁЃ
Р§ШчЃЌвЊИќаТАќКЌгУЛЇЪ§ОнЕФФГИіrowжаЕФemail СаЃЌcassandraВЂВЛжиаДећИіrowЕНаТЕФЪ§ОнЮФМўЃЌЖјНіНіНЋаТЕФemailаДНјаТЕФЪ§ОнЮФМўЃЌusernameЕШШдДІгкОЩЕФЪ§ОнЮФМўжаЁЃЩЯЭМжаКьЯпБэЪОCassandraашвЊећКЯЕФrowЕФЦЌЖЮгУвдВњЩњгУЛЇЧыЧѓЕФНсЙћЁЃЮЊНкЪЁCPUКЭДХХЬI/OЃЌCassandraЛсЛКДцКЯВЂКѓЕФНсЙћЃЌЧвПЩжБНгдкИУcacheжаИќаТrowЖјВЛгУжиаТКЯВЂЁЃ
8.5ЙигкЪТЮёКЭаЭЌПижЦ
ВЛжЇГжRDBMSжаОпгаЛиЙіКЭЫјЖЈЛњжЦЕФACIDЪТЮёЃЌЕЋЬсЙЉСЫвЛЖЈГЬЖШЕФдзгадЃЈааМЖЃЉЁЂИєРыадЃЈааМЖЃЉЁЂГжОУадКЭeventual/tunable
РраЭЕФвЛжТадЃЈвђВЛжЇГжСЌНгКЭЭтМќЃЌЙЪВЛЬсЙЉACIDГЁОАЯТЕФвЛжТадЃЉЁЃ
дзгад
row-levelЃЌЖдвЛИіrowЕФВхШы/ИќаТБЛЕБзівЛИідзгВйзїЁЃВЛжЇГжвЊУДЖМзівЊУДЖМВЛзіЕФЖрааВхШы/ИќаТЁЃВЛжЇГждквЛИіreplicaЩЯwriteГЩЙІЖјдкЦфЫћreplicaЩЯwriteЪЇАмЕФЛиЙіЁЃгУЪБМфДСШЗЖЈcolumnЕФзюаТИќаТЁЃШєЖрИіsessionЭЌЪБИќаТЭЌбљЕФcolumnдђЪЙгУзюНќЕФИќаТЁЃ
вЛжТад
l TuneableвЛжТад
ЬсЙЉpartitionШнДэЁЃгУЛЇПЩвдвдЕЅИіВйзїЮЊЛљДЁОіЖЈашЖрЩйИіНкЕуНгЪеDMLВйзїЛђЯьгІSELECTВйзїЁЃ
l LinearizableвЛжТад
l ЧсСПЪТЮё(compare-and-set)ЕФвЛЯЕСаИєРыМЖБ№ЁЃ дкtuneableвЛжТадВЛзувдТњзувЊЧѓЪБЪЙгУЃЌ
ШчжДааЮоМфЖЯЕФЯрМЬВйзїЛђЭЌЪБ/ВЛЭЌЪБдЫаавЛИіВйзїВњЩњЭЌбљЕФНсЙћЁЃ Cassandra2.0ЪЙгУРрЫЦ2-phase
commit ЕФPaxos consensusавщЪЕЯж LinearizableвЛжТадЁЃ ЃЈЮЊжЇГжИУвЛжТадв§ШыСЫSERIALРраЭЕФconsistency
levelМАдкCQLжаЪЙгУСЫДјIFДгОфЕФЧсСПЪТЮёЃЉ
ИєРыад
Cassandra2.0ПЊЪМжЇГжrow-levelЕФИєРыадЁЃЖдааЕФаДВйзїдкЭъГЩжЎЧАЖдЦфЫћгУЛЇВЛПЩМћЁЃ
ГжОУад
ЭЌЪБНЋЪ§ОнаДШыФкДцжаЕФmemtableМАДХХЬжаЕФcommit logЁЃЗўЮёЦїЙЪеЯЪБШєmemtableЩаЮДЫЂШыДХХЬЃЌдкЙЪеЯЛжИДКѓПЩжиЗХcommit
logЛжИДЖЊЪЇЪ§ОнЁЃетЬсЙЉСЫБОЕиГжОУадЁЃЪ§ОндкЦфЫћНкЕуЕФИББОМгЧПСЫГжОУадЁЃ
ЧсСПЪТЮё
Cassandra2.0жав§ШыЃЌУжВЙTuneableвЛжТадЁЃ
n INSERT INTO
emp(empid,deptid,address,first_name,last_name)
VALUES(102,14,'luoyang','Jane Doe','li') IF NOT
EXISTS;
n UPDATE emp SET address = 'luoyang' WHERE empid
= 103 and deptid = 16IF last_name='zhang'; |
8.6ХфжУЪ§ОнвЛжТад
CassandraжаЃЌвЛжТадМЖБ№ПЩХфжУЃЌвдШЗЖЈЧыЧѓЕФЪ§ОнШчКЮдкВЛЭЌЕФreplicaБЃГжвЛжТадЃЌДгЖјЦНКтЯьгІЪБМфКЭЪ§ОнОЋШЗадЁЃ
аДвЛжТад
жИУїдкЗЕЛиШЗШЯжСПЭЛЇЖЫЧАЃЌwriteВйзїБиаыГЩЙІЕФreplicaЪ§ЁЃ
l ANYЃКwriteжСЩйдквЛИіreplicaГЩЙІЁЃМДЪЙЫљгаreplica
ЖМdownЕєЃЌ дкаДhinted handoffКѓwriteШдГЩЙІЁЃдкreplicaЛжИДКѓИУwriteПЩЖСЁЃ
l ONEЃКwriteБиаыГЩЙІаДШыжСЩйвЛИі replicaЕФcommit
logКЭmemtableЁЃ
l TWOЃКжСЩйСНИі
l THREEЃКжСЩйШ§Иі
l QUORUMЃКжСЩй(replication_factor/ 2) + 1Иі
l LOCAL_QUORUMЃКжСЩй(replication_factor/ 2) + 1ИіЃЌЧвгыаЕїепДІгкЭЌвЛЪ§ОнжааФ
l EACH_QUORUMЃКЫљгаЪ§ОнжааФЃЌжСЩй(replication_factor/ 2) +
1Иі
l ALLЃКШЋВП
l SERIALЃКжСЩй(replication_factor/ 2) + 1ИіЃЌгУгкДяГЩЧсСПЪТЮёЕФlinearizable
consistency
ашзЂвтЕФЪЧЃКЪЕМЪЩЯwriteЛЙЪЧЛсБЛЗЂЕНЫљгаЯрЙиЕФreplicaжаЃЌвЛжТадМЖБ№жЛЪЧШЗЖЈБиашвЊЗДРЁЕФreplicaЪ§ЁЃ
ЖСвЛжТад
жИУїдкЗЕЛиЪ§ОнжЕПЭЛЇЖЫЧАЃЌашвЊЯргІreadЧыЧѓЕФЯрЙиreplicaЪ§ЁЃCassandraДгетаЉЪ§СПЕФreplicaжаИљОнЪБМфДСМьВщзюаТЕФЪ§ОнЁЃМЖБ№ЭЌаДвЛжТадЁЃ
ПЩЭЈЙ§cqlshУќСюCONSISTENCYЩшжУkeyspaceЕФвЛжТадЃЌвВПЩБрГЬЩшжУвЛжТадЁЃ
9Вйзї
9.1МрПиCassandraМЏШК
ЙЄОпЃКnodetool utilityЁЂDataStaxOpsCenterЁЂ
JConsole
nodetool utilityЃКCassandraЗЂааАцИНДјЕФУќСюааЙЄОпЃЌ
гУгкМрПиКЭГЃЙцЪ§ОнПтВйзїЁЃвЛаЉГЃгУУќСюШч statusЁЂcfstatsЁЂcfhistogramsЁЂnetstatsЁЂtpstatsЕШЁЃ
DataStax OpsCenterЃКЭМаЮгУЛЇНчУцЙЄОпЃЌДгжабыПижЦЬЈМрПиКЭЙмРэМЏШКжаЫљгаНкЕуЁЃ
JConsoleЃКJMXМцШнЙЄОпгУвдМрПиjavaгІгУГЬађЃЌЬсЙЉOverviewЁЂ
MemoryЁЂThreadЁЂClassesЁЂVM summaryЁЂMbeansЗНУцЕФаХЯЂЁЃ
9.2ЕїећBloom filters
Bloom filtersгУвддкжДааI/OЧАШЗЖЈSSTableЪЧЗёКЌЬиЖЈЕФrowЁЃгУгкindexЩЈУшЖјВЛгУгкrangeЩЈУшЁЃЭЈЙ§bloom_filter_fp_chanceВЮЪ§ХфжУЦфЪєаджЕЃЌЗЖЮЇЮЊ0жС1.0(ЙиБе)ЃЌжЕдНДѓдђЪЙгУЕФФкДцдНЩйЃЌЕЋвВвтЮЖзХШєSSTableгЩНЯЖрЫщЦЌдђЕМжТНЯИпЕФДХХЬI/OЁЃФЌШЯжЕвРРЕгкcompaction_strategyРраЭЁЃжЕЕФЩшжУвРРЕЙЄзїИККЩЃЌШчЃЌШєашдквЛЬиЖЈБэЩЯдЫааЗБжиЕФscanдђашНЋbloom_filter_fp_chanceЩшжУИпвЛЕуЁЃ
ЭЈЙ§ШчЯТгяОфЩшжУЃК
ALTER TABLEaddamsFamily WITH bloom_filter_fp_chance
= 0.1;
ЩшжУКУКѓашЪЙгУInitiatecompaction ЛђUpgrade
SSTablesЗНЪНжЎвЛжиаТВњЩњBloom filterЁЃ
9.3Ъ§ОнЛКДц
СНРрcacheЃКpartitionkey cacheКЭrow cache
partition key cacheЃКCassandraБэpartition indexЕФcache
row cacheЃКвЛИіrowЪзДЮБЛЗУЮЪКѓећИіro w(КЯВЂздЖрИіЖдгІЕФSSTableМАmemtable)
БЛЗХдкrow cacheжавдБугкКѓајЖдИФrowЕФЗУЮЪФмжБНггЩФкДцЛёШЁЪ§ОнЁЃ
ЖдгкКмЩйЗУЮЪЕФarchiveБэЕБНћгУЛКДцЁЃ
ПЊЦєгыХфжУcache
ПЊЦє
CREATE TABLEusers
(
userid text PRIMARY KEY,
first_name text,
last_name text,
)
WITH caching ='all'; |
ХфжУ
дкcassandra.yamlжаЃЌЕїећЯТСаВЮЪ§ЃЛ
l key_cache_keys_to_save
l key_cache_save_period
l key_cache_size_in_mb
l row_cache_keys_to_save
l row_cache_size_in_mb
l row_cache_save_period
l row_cache_provider |
ЙЄзїдРэЃК
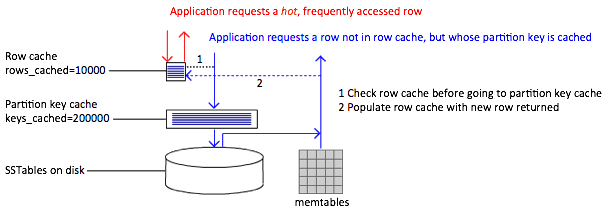
ЕквЛИіreadВйзїжБНгУќжаrowcacheЃЌДгФкДцШЁГіЪ§ОнЁЃЕкЖўИіreadВйзїЮЊУќжа
row cacheЃЌЕЋУќжаpartition key cacheЃЌ ВЂгЩДЫећКЯЫљгаЯрЙиЕФSSTableМАmemtableжаЕФЦЌЖЮЮЊЧыЧѓЕФrowЃЌЗЕЛиrowВЂаДНјrow
cacheЁЃ
cacheЪЙгУгХЛЏНЈвщ
НЋКмЩйЧыЧѓЕФЪ§ОнЛђrowКмГЄЕФЪ§ОнЗХдкcacheНЯаЁЛђВЛЪЙгУcacheЕФБэжа
гУНЯЖрЕФНкЕуВПЪ№ИїНкЕуИКдиНЯЧсЕФМЏШК
ТпМЩЯНЋreadГэУмЕФЪ§ОнЗжПЊдкРыЩЂЕФБэжа
9.4ХфжУmemtableЭЬЭТСП
ПЩИФЩЦwriteадФмЁЃCassandraдкcommit logspace thresholdГЌГіЪБНЋmemtablesФкШнЫЂНјДХХЬДДНЈSSTableЁЃдкcassandra.ymalжаХфжУcommit
log space thresholdРДЕїећmemtableЭЬЭТСПЁЃХфжУЕФжЕвРРЕгкЪ§ОнКЭwriteИКдиЁЃЯТСаСНжжЧщПіПЩПМТЧдіМгЭЬЭТСПЃК
writeИКдиАќКЌДѓСПдкаЁЪ§ОнМЏЩЯЕФИќаТВйзї
ЮШЖЈГжајЕФаДВйзї
9.5CompactionгыCompression
9.5.1Compaction
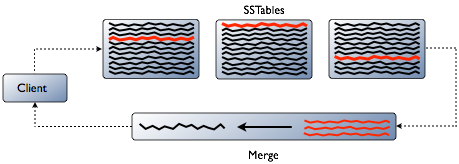
жмЦкадЕФКѓЬЈНјГЬЁЃCompactionЦкМфCassandraЭЈЙ§
ећКЯrowЦЌЖЮКЯВЂSSTableЁЂвЦГ§Й§ЦкЕФtombstonesЁЂжиНЈЫїв§ЕШЃЌВЂдкаТSSTableКЯВЂЭъГЩКѓвЦГ§ОЩЕФSSTableЁЃ
СНРрCompaction
SizeTieredCompactionStrategy
ЪеМЏГпДчЯрНќЕФSSTableКЯВЂЮЊвЛИіНЯДѓЕФSSTableЁЃ
LeveledCompactionStrategy
ДДНЈЯрЖдНЯаЁЕФSSTableЃЌГпДчБЛЙЬЖЈЮЊВЛЭЌЕШМЖЃЈL0ЁЂL1ЁЂL2ЁЁЃЉЃЌЭЌвЛМЖФкSSTableДѓаЁЯрЭЌЃЌУПВювЛИіЕШМЖГпДчВю10БЖЁЃSSTableДгНЯаЁЕФЕШМЖж№НЅКЯВЂжСНЯИпЕФЕШМЖЁЃ
CompactionВйзїЛсСйЪБдіМгДХХЬI/OЃЌЕЋЭъГЩКѓПЩИФЩЦreadадФмЁЃ
ПЊЦєгыХфжУCompaction
ЪЙгУCQLгяОфCREATE/ALTER TABLE
l ALTER TABLE
users WITH
compaction = { 'class' : 'LeveledCompactionStrategy',
'sstable_size_in_mb' : 10 }
l ALTER TABLE users
WITH compaction ={'class' : 'SizeTieredCompactionStrategy','min_threshold'
: 6 } |
ИќЖрЪєадВЮМћCQL keyspace and table properties.
ХфжУcassandra.yamlЮФМў
l snapshot_before_compaction
l in_memory_compaction_limit_in_mb
l multithreaded_compaction
l compaction_preheat_key_cache
l concurrent_compactors
l compaction_throughput_mb_per_sec |
9.5.2Compression
ЭЈЙ§МѕЩйЪ§ОнЬхЛ§КЭДХХЬI/OРДзюДѓЛЏДцДЂФмСІЁЃДѓДѓЬсЩ§ЖСадФмЧв ВЛЛсЯёДЋЭГЙиЯЕаЭЪ§ОнПтжаЕФCompressionВйзїНЕЕЭwriteадФмЁЃ
ЪВУДЪБКђжДааCompression
ЪЪгУгкгЕгаДѓСПЕФrowЧвУПИіrowгыЦфЫћrowгавЛбљЕФcolumnЛђОЁПЩФмЖрЯрЭЌЕФcolumnЕФБэЁЃдНЯрЫЦбЙЫѕБШдНИпЃЌадФмЬсЩ§дНУїЯдЁЃrowОпгаВювьНЯДѓЕФcolumnМЏЕФБэВЛЪЪгкCompressionЁЃШчDynamicБэЁЃ
ХфжУКУcompressionКѓКѓајДДНЈЕФSSTableБЛбЙЫѕЃЌ жЎЧАвбОДцдкЕФSSTableВЛБЛСЂМДбЙЫѕжБЕНе§ГЃЕФ
CassandracompactionНјГЬПЊЪМЁЃПЩЪЙгУnodetool upgradesstables
УќСюЧПжЦбЙЫѕМШДцЕФSSTable
ХфжУCompression
НћгУ
CREATE TABLEDogTypes
(
block_id uuid,
species text,
alias text,
population varint,
PRIMARY KEY (block_id)
)
WITH compression = {'sstable_compression' : ''
}; |
ПЊЦє
CREATE TABLEDogTypes
(
block_id uuid,
species text,
alias text,
population varint,
PRIMARY KEY (block_id)
)
WITH compression = {'sstable_compression' : 'LZ4Compressor'
}; |
Еїећ
ALTER TABLECatTypes
WITH compression = { 'sstable_compression' :'DeflateCompressor',
'chunk_length_kb' : 64 } |
9.6ЕїећJavaзЪдД
адФмЯТНЕЛђФкДцЯћКФЙ§ЖрЪБашПМТЧЕїећJavaзЪдДЁЃгаСНИіЮФМўгУгкCassandraжаЛЗОГЩшжУЃК
comf/cassandra-env.shЃКХфжУJVM
binЁЂcassandra-in.shЃКХфжУCassandraЛЗОГБфСП
ЕїећHeapГпДчЪБMAX_HEAP_SIZEгыHEAP_NEWSIZEвЊЭЌЪБЩшжУЃЌЧАепЩшжУJVMзюДѓheapГпДчЃЌКѓепЩшжУаТЩњДњЕФГпДчЃЌаТЩњДњГпДчдНДѓРЌЛјЛиЪеднЭЃЪБМфдНГЄЃЌЗДжЎРЌЛјЛиЪеЯћКФдНДѓЁЃ
ЕБЧАФЌШЯХфжУЃК

heapДѓаЁВЂЗЧдНДѓдНКУЃКЪзЯШJava6ДІРэ8GBвдЩЯЕФРЌЛјЪеМЏЕФФмСІЛсбИЫйЫѕМѕЃЛЦфДЮЛсМѕЩйВйзїЯЕЭГЛКДцвГЫљФмЪЙгУЕФФкДцЁЃ
Cassandra1.2вдКѓАцБОBloomfilterКЭcompression
offset mapЪЧoff-heapЕФЃЌВЛЫудкJVMЕФheapжЎФкЁЃ Cassandra2.0Кѓpartition
summaryвВ ЪЧoff-heapЕФЁЃШєдкCassandraжаЪЙгУ JNAПтЃЌrow cacheвВЛсЩ§МЖЮЊoff-heapЁЃ
етаЉПЩАяМѕЩйheapДѓаЁЃЌ діЧПJVM GCадФмЃЌДгЖјдіМгCassandraИпаЇДІРэУПИіНкЕужаЪ§ОнЕФФмСІЁЃ
ШєGCЦЕЗЂЗЂЩњЧвдкЪЪЖШЕФЪБМфЭъГЩБэУїJVM GCбЙСІЙ§ДѓЃЌДЫЪБашзїГідіМгНкЕуЁЂНЕЕЭcacheДѓаЁЁЂЕїећJVMжагаЙиGCЕФВЮЪ§ЕШВЙОШДыЪЉЁЃ
JavaManagement Extensions (JMX)ЬсЙЉСЫЙмРэКЭМрПиJavaгІгУКЭЗўЮёЕФИїжжЙЄОпЁЃ
ШчJConsole,ЁЂthe nodetool utilityКЭ DataStax OpsCenterетаЉJMXМцШнЙЄОпЁЃ
comf/cassandra-env.shжаЦфЫћЯрЙиВЮЪ§
com.sun.management.jmxremote.port
com.sun.management.jmxremote.ssl
com.sun.management.jmxremote.authenticate
-Djava.rmi.server.hostname
9.7аоИД node
ЪЙгУnodetoolЕФrepairУќСюЃЌаоИДгыИјЖЈЕФЪ§Он ЗЖЮЇЯрЙиЕФreplicaМфЕФВЛвЛжТадЁЃдкЯТЪєЧщаЮдЫаааоИДЃК
ЙцТЩЕФЁЂМЦЛЎЕФМЏШКЮЌЛЄВйзїЦкМфЃЈГ§ЗЧУЛгажДааЙ§deleteЃЉ
НкЕуЛжИДКѓ
дкАќКЌНЯЩйБЛЗУЮЪЕФЪ§ОнЕФНкЕуЩЯ
дкdownЕєЕФНкЕуИќаТЪ§Он
дЫааНкЕуаоИДЕФЗНеыЃК
ГЃЙцаоИДВйзїжДааДЮЪ§гЩgc_graceжЕгВадЙцЖЈЁЃашдкИУЪБМфФкдкУПИіНкЕужСЩйдЫаавЛДЮаоИДВйзїЁЃ
ЭЌЪБдкЖргквЛИіЕФНкЕудЫааГЃЙцаоИДЪБашНїЩїЃЌзюКУдкЕЭЗхЦкЙцТЩдЫаааоИДЁЃ
дкКмЩйdeleteЛђoverwriteЪ§ОнЕФЯЕЭГжаЃЌПЩдіМгgc_graceЕФжЕЁЃ
аоИДВйзїЯћКФДХХЬI/OЃЌПЩЭЈЙ§ЯТЪіЭООЖМѕЧсЃК
ЪЙгУnodetoolЕФcompactionthrottlingбЁЯюЁЃ
ЪЙгУnodetoolsnapshotжЎКѓДгsnapshotжДаааоИДЁЃ
аоИДВйзїЛсЕМжТoverstreamingЃЈЮЪЬтдД гкCassandraФкВПMerkletreesЪ§ОнНсЙЙЃЉЁЃ
БШШчжЛгавЛИіЫ№ЛЕЕФpartitionЕЋШДашЗЂЫЭКмЖрЕФstreamЃЌ ЧвШєНкЕужаДцдкЕФpartitionдНЖрЮЪЬтдНбЯ
жиЁЃетЛсв§Ц№ДХХЬПеМфРЫЗбКЭВЛ БивЊЕФcompactionЁЃПЩЪЙгУsubrange аоИДРДМѕЧсoverstreamingЁЃsubrange
repairжЛаоИДЪєгкНкЕуЕФВПЗжЪ§ОнЁЃ
9.8ЬэМг/вЦГ§НкЕуЛђЪ§ОнжааФ
дкМШДцМЏШКжаЬэМгНкЕу
вдЪЙгУvnodesЕФНкЕуЮЊР§ЃЈЭЦМіДЫжжЗНЪНЃЌащФтНкЕуЯрЙиФкШнМћЕк7НкЃЉ
1. дкаТНкЕуАВзАCassandraЃЌЙиБеcassandraЃЌЧхГ§Ъ§ОнЁЃ
2. дкcassandra.yamlКЭcassandra-topology.propertiesжаХфжУШчЯТЪєадЃК
l cluster_name
l listern_address/broadcast_address
l endpoint_snitch
l num_tokens
l seed_provider
3. ж№ИіЦєЖЏаТНкЕужаЕФcassandraЃЌВЛЭЌНкЕуЕФГѕЪМЛЏжЎМфБЃГжСНЗжжгЕФМфИєЁЃ
ПЩгУnodetool netstatsМрПиЦєЖЏКЭЪ§ОнСїДІРэ
4. Д§ЫљгааТНкЕудЫааЦ№РДКѓж№ИідкУПИіжЎЧАвбДцдкЕФНкЕужДааnodetool
cleanupРДвЦГ§ВЛдйЪєгкетаЉНкЕуЕФkeyЁЃдкЯТвЛИіНкЕужДааnodetool cleanupЧАБиаыЕШЩЯвЛИіНкЕужа
ЕФnodetool cleanupНсЪјЁЃСэЭтcleanupВйзїПЩПМТЧдкЕЭЗхЦкНјааЁЃ
ЯђМШДцМЏШКжаЬэМгЪ§ОнжааФ
вдЪЙгУvnodesЕФНкЕуЙЙГЩЕФМЏШКЮЊР§
1. ШЗБЃkeyspaceЪЙгУNetworkTopologyStrategyИДжЦВпТд
2. ЖдгкУПИіаТНкЕудкcassandra.yamlжаЩшжУШчЯТЪєад
l auto_bootstrap: false.
l ЩшжУЦфЫћгыЫљЪєМЏШКЦЅХфЕФЪєадЃЈВЮМћЩЯвЛВПЗжЃКдкМШДцМЏШКжаЬэМгНкЕуЃЉ
3. ИљОнЩшжУЕФsnitchРраЭдкИїаТНкЕуХфжУЖдгІЕФжИУїЭјТчЭиЦЫЕФХфжУЮФМўЃЈЮоашжиЦєЃЉ
4. ШЗБЃЪЙгУЕФПЭЛЇЖЫВЛЛсздЖЏЬНВтаТЕФНкЕуЁЃ
5. ШєЪЙгУQUORUMвЛжТадМЖБ№ЃЌашМьВщLOCAL_QUORUM
ЛђEACH_QUORUMвЛжТадМЖБ№ЪЧЗёТњзуЖрЪ§ОнжааФЕФвЊЧѓ
6. ж№ИідкУПИіНкЕуПЊЦєcassandraЁЃзЂвтГѕЪМЛЏЪБМфМфИєЁЃ
7. ЫљгаНкЕудЫааЦ№РДКѓжДааЯТСаВйзї
ЬцЛЛЫРЕєЕФНкЕу
вдЪЙгУvnodesЕФНкЕуЙЙГЩЕФМЏШКЮЊР§
1. гУnodetool statusУќСюШЗШЯЛЗжаЫРЕєЕФНкЕуЃЌДгЪфГіжаМЧТМИУНкЕуЕФHOST IDЁЃ
2. ЬэМгВЂЦєЖЏаТЕФЬцДњНкЕуЃЈВЮМћЃКдкМШДцМЏШКжаЬэМгНкЕуЃЉ
3. ЪЙгУnodetool removenodeУќСюИљОнМЧТМЕФЫРЭіНкЕуЕФHOST IDДгМЏШКжавЦГ§ЫРЕєЕФНкЕуЁЃ
вЦГ§Ъ§ОнжааФ
1. ШЗШЯУЛгаclientе§дкЯђЪ§ОнжааФФкЕФШЮКЮНкЕуаДЪ§Он
2. дкЪ§ОнжааФФкЕФИїНкЕужажДааnodetool repairвдШЗБЃЪ§ОнДгИУжааФЕУЕНе§ШЗЕФДЋВЅЁЃИќИФЫљгаЕФkeyspaceЪєадШЗБЃВЛдйв§гУМДНЋвЦГ§ЕФЪ§ОнжааФЁЃ
3. дкЪ§ОнжааФФкЕФИїНкЕуЗжБ№дЫааnodetool decommission
9БИЗнЛжИД
CassandraЭЈЙ§ЮЊДХХЬжаЕФЪ§ОнЮФМўЃЈSSTableЮФМўЃЉДДНЈПьееРДБИЗнЪ§ОнЁЃПЩЮЊЕЅИіБэЁЂЕЅИіkeyspaceЁЂЫљгаkeyspaceДДНЈПьееЁЃПЩгУВЂааSSHЙЄОпЮЊећИіМЏШКДДНЈПьееЁЃДДНЈЪБВЛБЃжЄЫљгаreplicaвЛжТЃЌЕЋдкЛжИДПьееЪБ
CassandraРћгУФкНЈЕФвЛжТадЛњжЦБЃГжвЛжТадЁЃДДНЈСЫЯЕЭГЗЖЮЇЕФПьееКѓПЩПЊЦєдіСПБИЗнжЛБИЗнздЩЯДЮПьеевдРДБфЛЏСЫЕФЪ§ОнЃЈУПЕБвЛИіSSTableБЛflushКѓЃЌвЛИіЖдгІЕФгВСДНгБЛПНБДжСгы/snapshotЭЌМЖЕФ/backupsзгФПТМ(ашЪЙгУJNA)ЃЉЁЃ
ШєдкCassandraжаЪЙгУСЫJNAЃЌдђПьееЭЈЙ§гВСДНгДДНЈЁЃЗёдђЛсвђНЋЮФМўПНБДжСВЛЭЌЕФЮЛжУЖјдіМгДХХЬI/OЁЃ
9.1ДДНЈПьее
дкУПИіНкЕужДааnodetoolsnapshotУќСюЮЊНкЕуДДНЈПьееЁЃвВПЩЭЈЙ§ВЂааSSHЙЄОпЃЈШчpsshЃЉдЫааnodetool
snapshotДДНЈШЋОжЕФПьееЁЃ
$ nodetool -h localhost -p 7199 snapshot demdb
жДааУќСюКѓЪзЯШЛсНЋФкДцжаЕФЪ§ОнЫЂНјДХХЬЃЌжЎКѓЮЊУПИі keyspaceЕФSSTableЮФМўДДНЈгВСДНгЁЃ
ПьееЕФФЌШЯЮЛжУЮЊ/var/lib/cassandra/data/<keyspace_name>
/<table_name>/snapshotsЁЃ Цфжа/var/lib/cassandra/dataВПЗжвРОнЪ§ОнФПТМЩшжУЖјВЛЭЌЁЃ
вЊБЃжЄПеМфГфзуЃЌДДНЈКѓПЩПМТЧвЦжСЦфЫћЮЛжУЁЃ
9.2ЩОГ§Пьее
ДДНЈаТЕФПьееВЂВЛЛсздЖЏЩОГ§ОЩЕФПьееЃЌашдкДДНЈаТПьееЧАЭЈЙ§nodetool clearsnapshotУќСювЦГ§ОЩЕФПьееЁЃ
$ nodetool -h localhost -p 7199 clearsnapshot
ЭЌбљПЩЭЈЙ§ВЂааSSHЙЄОпЃЈШчpsshЃЉдЫаа nodetoolclearsnapshotвЛДЮЩОГ§ЫљгаНкЕуЕФПьееЁЃ
9.3ЦєгУдіСПБИЗн
ФЌШЯВЛПЊЦєЃЌПЩЭЈЙ§дкИїНкЕуЕФcassandra.yamlХфжУЮФМўжаЩшжУ
incremental_backupsЮЊtrueРДПЊЦєдіСПБИЗнЁЃПЊЦєКѓЛсЮЊУПИіаТЕФБЛЫЂШыЕФSSTableДДНЈвЛИігВСДНгВЂПНБДжСЪ§ОнФПТМЕФ/backupsзгФПТМЁЃ
CassandraВЛЛсздЖЏЩОГ§діСПБИЗнЮФМўЃЌДДНЈаТЕФПьееЧАашЪжЙЄвЦГ§ОЩЕФдіСПБИЗнЮФМўЁЃ
9.4ДгПьееЛжИДЪ§Он
ашЫљгаЕФПьееЮФМўЃЌШєЪЙгУСЫдіСПБИЗнЛЙашПьееДДНЈжЎКѓЫљгаЕФдіСПБИЗнЮФМўЁЃЭЈГЃЃЌдкДгПьееЛжИДЪ§ОнЧАашЯШtruncateБэЁЃЃЈШєБИЗнЗЂЩњдкdeleteЧАЖјЛжИДЗЂЩњдкdeleteКѓЧвУЛtruncateБэЪБЃЌдђВЛФмЕУЕНзюдЪМЕФЪ§ОнЃЌвђЮЊжБЕНcompactionВйзїЗЂЩњЧАБЛБъМЧЮЊtombstoneЕФЪ§ОнгыдЪМЪ§ОнДІгкВЛЭЌЕФSSTableжаЃЌЫљвдЛжИДАќКЌдЪМЪ§ОнЕФSSTableВЛЛсвЦГ§БЛБъМЧБЛtombstoneЕФЪ§ОнЃЌетаЉЪ§ОнШдШЛЯдЪОЮЊНЋБЛЩОГ§ЃЉЁЃ
ПЩвдгУШчЯТЗНЪНДгПьееЛжИДЪ§Он
ЪЙгУsstableloaderЙЄОп
ЯШПНБДsnapshotФПТМжаЕФПьееЮФМўжСЯргІЪ§ОнФПТМЁЃжЎКѓЭЈЙ§ JConsoleЕїгУcolumn
family MBean жаЕФJMXЗНЗЈloadNewSSTables()ЛђепЪЙгУnodetool
refreshУќСюЖјВЛЕїгУЩЯЪіЗНЗЈЁЃ
ЪЙгУжиЦєНкЕуЕФЗНЪН
1. ШєЛжИДЕЅНкЕудђЯШЙиБеИУНкЕуЃЌШєЛжИДећИіМЏШКдђашЯШЙиБеЫљгаНкЕу
2. ЧхГ§/var/lib/cassandra/commitlogжаЕФЫљгаЮФМў
3. ЩОГ§<data_directory_location>/
<keyspace_name>/<table_name>жаЫљга*.dbЮФМў
4. ПНБДзюаТ<data_directory_location>
/<keyspace_name>/<table_name> /snapshots/
<snapshot_name> ЕФПьееЮФМўжС<data_directory_location>
/ <keyspace_name> /<table_name> /snapshots/<snapshot_name>
5. ШєЪЙгУСЫдіСПБИЗндђЛЙашПНБД<data_directory_location>
/<keyspace_name>/<table_name> /backupsжаЕФФкШнжС
<data_directory_location> /<keyspace_name>/<table_name>
6. жиЦєНкЕу
7. дЫааnodetool repair
| 








