| БрМЭЦМі: |
| БОЮФРДздгкoschinaЃЌБОЮФжївЊНщЩмСЫдкcassandraМЏШКИєЖЮЪБМфГіЯжrtьИпЕФЮЪЬтКѓЕФвЛаЉЧЈвЦЗНАИвдМАЗНАИЕФЯъЯИЙ§ГЬЕШЃЌЯЃЭћФмЖдФњгаЫљАяжњЁЃ |
|
ЧЈвЦБГОА
cassandraМЏШКИєЖЮЪБМфГіЯжrtьИпЕФЮЪЬтЃЌДјРДЕФгАЯьОЭЪЧЧыЧѓcassandraЖЬЪБМфФкГіЯжДѓСПГЌЪБЃЌетИіЮЪЬтЗЂЩњвбОДяЕНСЫЦНОљСНжмвЛДЮЕФЦЕТЪЃЌвбОгАЯьЕНе§ГЃвЕЮёСЫЁЃЖјГіЯжетаЉЮЪЬтЕФдвђжївЊгавдЯТ3ЕуЃК
ЕБГѕЩшМЦБэЕФЪБКђpartition keyЩшМЦЕФВЛЪЧКмКЯРэЃЌЕБЪ§ОнСПЩЯШЅЃЈзюДѓЕФЕЅБэааЪ§ДяЕНАйвкМЖЃЉжЎКѓЃЌГіЯжСЫвЛаЉЪ§ОнСПБШНЯДѓЕФpartitionЁЃЕЅpartitionзюЖрЕФЪ§ОнСПДяЕНСЫЩЯАйЭђааЃЈcassandraВЛжЇГжmysqlЕФlimit
m, nЕФВщбЏЃЉЃЌЕБВщбЏетИіpartitionЕФЪ§ОнЪБЃЌЛсДјРДБШНЯДѓЕФбЙСІЁЃ
cassandraБОЩэЕФФЙБЎЛњжЦЃЌcassandraЕФвЛДѓЬиадОЭЪЧПьЫйаДШыЃЌШчЙћгіЕНdeleteвЛЬѕМЧТМЪБЃЌcassandraВЂВЛЛсЪЕЪБЕФЖдетЬѕМЧТМзіЮяРэЩОГ§ЃЌЖјЪЧдкетааМЧТМЩЯЬэМгвЛИіТпМЩОГ§ЕФБъжОЮЛЃЌЖјЯТДЮВщбЏЛсloadГіетаЉвбОЩОГ§СЫЕФМЧТМЃЌдйзіЙ§ТЫЁЃетбљОЭПЩФмДјРДМАЪБФГИіpartitionЕФВщбЏГіЕФЪ§ОнСПВЛДѓЃЌЕЋЪЧФЙБЎБШНЯЖрЕФЪБКђЛсДјРДбЯжиЕФадФмЮЪЬтЁЃ
ЙЋЫОdbaвВВЛЭЦМіЪЙгУcassandraЃЌГіЯжЮЪЬтЕФЪБКђЃЌФбгкЖЈЮЛНтОіЮЪЬтЁЃЫљвдОіЖЈНЋcassandraЪ§ОнПтЧЈвЦжСЩчЧјБШНЯГЩЪьЕФЙиЯЕаЭЪ§ОнПтmysqlЁЃ
ЧЈвЦЗНАИ
ећИіЧЈвЦЗНАИжївЊЗжЮЊвдЯТ5ИіВНжшЃК
ШЋСПЧЈвЦЃКАсЧЈЕБЧАПтжаЫљгаЕФРњЪЗЪ§ОнЃЈИУЙ§ГЬЛсАсЕєПтжаДѓВПЗжЪ§ОнЃЉ
діСПЧЈвЦЃКМЧТМШЋСПЧЈвЦПЊЪМЕФЪБМфЃЌАсЧЈШЋСПЧЈвЦЙ§ГЬжаБфИќСЫЕФЪ§Он
Ъ§ОнБШЖдЃКЭЈЙ§НгПкБШЖдcassandraКЭmysqlжаЕФЪ§ОнЃЌзюжеЪ§ОнвЛжТадДяЕНвЛЖЈ99.99%вдЩЯ
ПЊЫЋаДЃКЭЈЙ§Ъ§ОнБШЖдШЗБЃШЋСПЧЈвЦКЭдіСПЧЈвЦУЛЮЪЬтвдКѓЃЌДђПЊЫЋаДЁЃШчЙћЫЋаДгаЮЪЬтЃЌЪ§ОнБШЖдЛЙПЩвдЗЂЯжЫЋаДжаЕФЮЪЬтЁЃ
ЧаmysqlЖСЃКШЗБЃЫЋаДУЛЮЪЬтвдКѓЃЌШЛКѓИљОнЗўЮёЕФживЊадМЖБ№ЃЌж№ВНАДЗўЮёЧаmysqlЖСЁЃЫљгаЗўЮёЧаmysqlЖСвдКѓЃЌШЗБЃУЛЮЪЬтКѓЙиБеcassandraаДЃЌзюжеЯТЯпcassandraЁЃ
mysqlЕФЗжПтЗжБэЗНАИ
ЗжЖрЩйеХБэЃПдкDBAЕФЭЦМіЯТЃЌЕЅБэЕФЪ§ОнзюКУВЛвЊГЌЙ§200wЃЌЙРЫуСЫЯТзюДѓвЛеХБэЪ§ОнСП100вкзѓгвЃЌдйПМТЧЕНЪ§ОнЮДРДЪ§ОндіГЄЕФЧщПіЃЌзюДѓЕФетеХБэЗжСЫ8192еХБэЃЌЕЅБэЕФЪ§ОнСП120wзѓгвЃЌзмЙВЗжСЫ4ИіЮяРэПтЃЌУПИіПт2048еХБэЁЃ
зжЖЮЖдгІЕФЮЪЬтЃП етРяашвЊШЈКтвЛИіЮЪЬтЃЌcassandraгаListЁЂSetЁЂMapЕШНсЙЙЃЌЕНmysqlетБпдѕУДДцЃПетРяПЩвдИљОнздМКЪЕМЪЧщПібЁдёЃЌ
МЏКЯНсЙЙЕФзЊГЩjsonжЎКѓГЄЖШЖМдк1000ИізжЗћвдФкЕФЃЌПЩвджБНгзЊГЩjsonгУvarcharРДБЃДцЃЌгХЕуЃКДІРэЦ№РДМђЕЅЁЃШБЕуЃКашвЊПМТЧМЏКЯЕФЪ§ОндіГЄЮЪЬтЁЃ
зЊГЩjsonжЎКѓГЄЖШБШНЯГЄЃЌВПЗжвбОДяЕНЩЯЭђИізжЗћСЫЃЌгУЕЅЖРЕФвЛеХБэРДБЃДцЁЃгХЕуЃКВЛгУПМТЧМЏКЯЕФЪ§ОндіГЄЮЪЬтЁЃШБЕуЃКДІРэЦ№РДТщЗГЃЌашвЊЖюЭтЮЌЛЄаТЕФБэЁЃ
mysqlЗжЦЌМќЕФбЁдёЃЌЮвУЧетРяжБНгВЩгУЕФcassandraЕФpartition keyЁЃ
mysqlБэЕФжїМќКЭcassandraБэБЃГжвЛжТЁЃ
ШЋСПЧЈвЦЗНАИЕїба
copyЕМГіЃКЭЈЙ§cqlshЬсЙЉЕФcopyУќСюЃЌАбkeyspaceЕМГіЕНЮФМўЁЃ ШБЯнЃК
дкВтЪдЙ§ГЬжаЃЌЕМГіЫйЖШДѓИХ4500ааУПУыЃЌдкЕМГіЙ§ГЬжаХМЖћЛсгаГЌЪБЃЌЕМГіШчЙћжаЖЯЃЌВЛФмДгжаЖЯДІМЬајЁЃ
ШчЙћkeyspaceБШНЯДѓЃЌдђЩњГЩЕФЮФМўБШНЯДѓЁЃЫљвдетжжЗНЪНВЛПМТЧ
sstableloaderЗНЪНЃКетжжЗНЪННіжЇГжДгвЛИіcassandraМЏШКЧЈвЦЕНСэвЛИіcassandraМЏШКЁЃЫљвдИУЗНЪНвВВЛПМТЧ
tokenЛЗБщРњЗНЪНЃКcassandraМЧТМЕФДцДЂдРэЪЧВЩгУЕФвЛжТадhashЕФВпТд
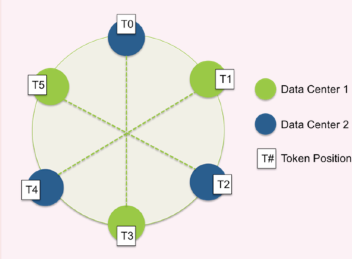
ећИіЛЗЕФЗЖЮЇЪЧ[Long.MIN_VALUE, Long.MAX_VALUE]ЃЌБэЕФУПЬѕМЧТМЖМЪЧЭЈЙ§partition
keyНјааhashМЦЫуЃЌШЛКѓШЗЖЈТфЕНФФИіЮЛжУЁЃ
Р§ШчгаетбљвЛеХБэЃК
| CREATE TABLE
test_table ( a text, b INT, c INT, d text, PRIMARY
KEY ( ( a, b ), c ) ); |
ЭЈЙ§вдЯТСНИіcqlОЭПЩвдБщРњИУеХБэ:
cqlsh:> select
token(a,b), c, d from test_table where token(a,b)
>= -9223372036854775808 limit 50;
token(a, b) | c | d
----------------------+---+----
-9087493578437596993 | 2 | d1
...
-8987733732583272758 | 9 | x1
(50 rows)
cqlsh:> select token(a,b), c, d from test_table
where token(a,b) >= -8987733732583272758
limit 50 |
бЛЗвдЩЯСНИіЙ§ГЬЃЌжБЕНtoken(a, b) = LONG.MAX_VALUEЃЌБэЪОећИіБэБщРњЭъГЩЁЃзюжеВЩгУСЫИУЗНЪНЁЃвдЩЯМИИіЗНАИЖМгавЛИіЙВЭЌЕФЮЪЬтЃЌдкЧЈвЦЙ§ГЬжаЃЌЪ§ОнгаБфИќЃЌетжжЧщПіашвЊЖюЭтПМТЧЁЃ
ШЋСПЧЈвЦЯъЯИЙ§ГЬ
зюжеВЩгУСЫвдЩЯЗНАИ3ЃЌЭЈЙ§БщРњcassandraБэЕФtokenЛЗЕФЗНЪНЃЌБщРњБэЕФЫљгаЪ§ОнЃЌАбЪ§ОнАсЕНmysqlжаЁЃОпЬхШчЯТЃК
АбећИіtokenЛЗЗжЮЊ2048ЖЮЃЌетУДзіЕФФПЕФЪЧЮЊСЫЃЌАбУПеХБэЕФвЛИіДѓЕФЧЈвЦШЮЮёЃЌЛЎЗжЮЊ2048ИіаЁШЮЮё,ЕБЕЅИіЧЈвЦШЮЮёГіЯжЮЪЬтЕФЪБКђЃЌВЛгУЫљгаЪ§ОнжиЭЗдйРДЃЌ
жЛашвЊАбГіЮЪЬтЕФвЛИіаЁШЮЮёжиХмОЭКУСЫЁЃетРяВЩгУЖрЯпГЬЁЃ
ЧЈвЦФЃЪНЃКжївЊгаsingleКЭbatchСНжжФЃЪНЃК
singleФЃЪНЃКж№вЛinsertжСmysqlЁЃЪ§ОнСПВЛДѓЕФЧщПібЁдёЃЌЕЅБэвкМЖБ№вдЯТбЁдёЃЌдк64ИіЯпГЬЧщПіЯТЃЌ16ИіЯпГЬЖСcassandraЕФЧщПіЯТЃЌЫйЖШПЩвдДяЕН1.5wааУПУыЁЃ
batchФЃЪНЃКbatch insertжСmysqlЁЃЪ§ОнСПБШНЯДѓЕФЧщПіЯТбЁдёЃЌЕЅБэЙ§вкЕФЧщПіЯТбЁдёЁЃзюДѓЕФвЛеХ100вкЪ§ОнСПЕФБэЃЌЧЈвЦЙ§ГЬЪЕМЪЩЯЗхжЕЫйЖШжЛга1.6wааУПУыЕФЫйЖШЁЃетЪЧвђЮЊcassandraЖСетВПЗжДяЕНЦПОБСЫЁЃБОЩэЯпЩЯгІгУКФЕєСЫВПЗжзЪдДЁЃШчЙћcassandraЖСУЛгаДяЕНЦПОБЃЌЫйЖШЗБЖЪЧУЛЮЪЬтЕФЁЃ
ЧЈвЦадФмЮЪЬтЃКетЪБКђcassandraКЭmysqlКЭгІгУЛњЦїБОЩэЖМПЩФмГЩЮЊЦПОБЕуЃЌЪ§ОнСПБШНЯДѓЃЌОЁСПВЩгУадФмКУвЛЕуЕФЛњЦїЁЃЮвУЧЕБЪБЧЈвЦЕФЪБКђЃЌВЩгУЕФвЛЬЈ40КЫЁЂ100G+ФкДцЕФЛњЦїЁЃ
ИУЙ§ГЬгіЕНЕФвЛаЉЮЪЬтЃК
вьГЃДІРэЮЪЬтЃКгЩгкБОЩэcassandraКЭmysqlЕФзжЖЮЯожЦгавЛЖЈЧјБ№ЁЃдкетИіЙ§ГЬПЯЖЈЛсгіЕНВПЗжМЧТМвђЮЊФГСаВЛЗћКЯmysqlСаЕФЯожЦЃЌЕМжТаДШыЪЇАмЃЌаДШыЪЇАмЕФМЧТМЛсМЧТМЕНЮФМўЁЃетвЛЙ§ГЬзюКУЪЧдкВтЪдЙ§ГЬжаИВИЧЕФдНШЋдНКУЁЃОпЬхЕФвЛаЉcaseШчЯТЃК
cassandra textГЄЖШГЌЙ§mysqlЕФЯожЦГЄЖШ
cassandraЮЊnullЕФЧщПіЃЌmysqlзжЖЮЩшжУЮЊis not null(етжжЧщПіашвЊДДНЈБэЕФЪБКђЖрПМТЧ)
cassandraЕФtimestampРраЭГЌЙ§СЫmysqlЕФdatetimeЕФЗЖЮЇЃЈeg:1693106-07-01
00:00:00ЃЉ
cassandraЕФdecimailРраЭГЌЙ§СЫmysqlЕФdecimailЗЖЮЇЃЈeg:6232182630000136384.0ЃЉ
Ъ§ОнвХТЉЮЪЬтЃКгЩгкВПЗжБэЕФзжЖЮБШНЯЖрЃЌДњТыжазжЖЮзЊЛЛЕФЪБКђзюКУзаЯИвЛЕуЁЃЮвУЧетБпгіЕНЙ§зжЖЮДэТвЁЂзжЖЮТЉЕєЕШЮЪЬтЁЃдйМгЩЯИУЙ§ГЬУЛгаВтЪдНгШыЃЌздМКПЊЗЂЩЯЯпСЫЃЌЪ§ОнЧЈвЦЭъГЩКѓВХЗЂЯжзжЖЮТЉЕєЃЌШЛКѓгжжиЭЗдйРДЃЌЦфжазюДѓЕФвЛеХБэЃЌДгЭЗЧЈвЛДЮВюВЛЖрашвЊЛЈЕє2жмЕФЪБМфЁЃЯждкЛиЙ§ЭЗШЅПДЃЌетеХБэЕБГѕЧЈвЦЕФЪБКђЃЌЛЙВЛжЙЗЕЙЄвЛДЮЁЃетИіЙ§ГЬЪЕМЪЩЯЪЧЗЧГЃРЫЗбЪБМфЕФЁЃ
Т§ВщбЏЮЪЬтЃКдкзюДѓЕФвЛеХБэЕФЧЈвЦЙ§ГЬжаЃЌГЌЪББШЦфЫћаЁБэвЊбЯживЛаЉЁЃВЂЧвдкХмЕФЙ§ГЬжаЗЂЯжЃЌЫйЖШдНХмдНТ§ЃЌХХВщЗЂЯжЪЧВПЗжЯпГЬгіЕНСЫФГИіtokenВщбЏЪМжеГЌЪБЕФЧщПіЁЃШЛКѓЯпГЬвЛжБЫРбЛЗВщбЏВщtokenЁЃЕБАбcassandraГЌЪБЪБМфЩшжУЮЊ30sЪБЃЌетжжЧщПігаЫљИФЩЦЃЌЕЋЛЙДцдкМЋИіБ№tokenДцдкИУЮЪЬтЁЃДЫДІгавЛЕуЦцЙжЕФЪЧЃЌЭЈЙ§ЕЧТМЕНЯпЩЯcassandraЛњЦїЃЌЭЈЙ§cqlshжБНгВщбЏЃЌЪ§ОнЪЧФмЙЛВщбЏГіРДЕФЁЃзюжеДІРэЗНАИЪЧеыЖдИУtokenМгСЫ5ДЮжиЪдЃЌШчЙћЛЙЪЧВЛГЩЙІЃЌдђМЧТМШежОЕЅЖРДІРэЁЃ
діСПЧЈвЦЯъЯИЙ§ГЬ
МЧТМШЋСПЧЈвЦПЊЪМЕФЪБМфЃЌвдМАМЧТМетЖЮЪБМфЫљгаБфИќЕФaccountЃЈвЛИіuserАќКЌЖрИіaccountЃЉЃЌАбетВПЗжЪ§ОнЗЂЭљkafkaЁЃдйЭЈЙ§ЖюЭтЕФдіСПЧЈвЦГЬађЯћЗбkakfaЕФЗНЪНАбетВПЗжЪ§ОнАсЕНmysqlЃЌбЛЗЭљИДИУЙ§ГЬЃЌжБЕНmysqlжаЕФЪ§ОнзЗЩЯcassandraжаЕФЪ§ОнЁЃ
ЯћЗбСНИіkafkaЖгСаЃЌвЛИіЮЊШЋСПЧЈвЦетЖЮЪБМфРыЯпБфИќЕФaccountЖгСаЃЌСэвЛИіЪЧЕБЧАвЕЮёЪЕЪББфИќЕФaccountЖгСаЁЃ
ДІРэЙ§ГЬжаашвЊПМТЧСНИіЖгСажаaccountГхЭЛЕФЮЪЬтЃЌПЩвдИљОнaccountidНјааМгЫјЁЃ
Ц№ГѕЪЧАДееuserЮЌЖШЃЌНјаадіСПЧЈвЦЁЃЪЕМЪЩЯЯпКѓЗЂЯжЃЌАДееuserЮЌЖШАсЧЈЫйЖШИљБОзЗВЛЩЯе§ГЃвЕЮёЪ§ОнБфИќЕФЫйЖШЁЃШЛКѓбЁдёСЫБШuserЕЭвЛИіЮЌЖШЕФaccountЃЈвЛИіuserАќКЌЖрИіaccountЃЉНјааЧЈвЦЁЃ
Ъ§ОнБШЖд
ЮЊЪВУДгаИУВНжшЃПЮЊСЫШЗБЃcassandraКЭmysqlЪ§ОндДОЁПЩФмЕФвЛжТЁЃ
дкШЋСПЧЈвЦЭъГЩвдКѓЃЌдіСПЧЈвЦЙ§ГЬжаЃЌБуЩЯЯпСЫИУБШЖдЙІФмЁЃШчКЮБШЖдЃПЕБЯпЩЯвЕЮёВњЩњСЫЪ§ОнБфИќЃЌИљОнaccountidЃЌАбИУaccountidЯТЕФcassandraЕФЫљгаЪ§ОнКЭmysqlЕФЫљгаЪ§ОнЭЈЙ§ЕїНгПкЕФаЮЪНВщбЏГіРДНјааБШЖдЁЃОЋШЗЕНОпЬхзжЖЮЕФжЕ
дБОШЯЮЊШЋСПЧЈвЦКЭдіСПЧЈвЦЛљБОУЛЪВУДЮЪЬтСЫЃЌЕЋЪЧЭЈЙ§Ъ§ОнБШЖдЛЙЗЂЯжСЫВЛЩйЕФЪ§ОнВЛвЛжТЕиЗНЁЃХХВщЗЂЯжгаШЋСПЧЈвЦЙ§ГЬЕМжТЕФЃЌвВгадіСПЧЈвЦЙ§ГЬЕМжТЕФЃЌЖМЪЧДњТыbugЕМжТЁЃЗЂЯжСЫЮЪЬтШчЙћФГеХБэШЋСПЧЈвЦЙ§ГЬЖМГіСЫЮЪЬтЃЌГ§СЫашвЊжиаТШЋСПЧЈвЦИУБэЁЃВЂЧвдіСПЧЈвЦвВашвЊжиЭЗдйРДЁЃ
ЫљгаЕФБШЖдНсЙћДцШыЪ§ОнПтЃЌШЛКѓЖЈЪБШЮЮёЗЂЯжБШЖдВЛЙ§ЕФЪ§ОнЃЌдйАДееaccountЮЌЖШНјаадіСПЧЈвЦЁЃ
гіЕНЕФжївЊЮЪЬтШчЯТЃК
ЪБМфОЋЖШЕФЮЪЬтЃКcassandraЕФtimestampЪБМфДСОЋШЗЕНКСУыЃЈcassandraЕФвЛИіПЭЛЇЖЫЙЄОпDevCenterВщбЏГіРДЕФЪБМфжЛОЋШЗЕНУыЃЌКСУыВПЗжБЛНиЖЯСЫЃЌШчЙћЭЈЙ§ИУЙЄОпШтблБШЖдЃЌВЛШнвзЗЂЯжИУЮЪЬтЃЉЃЌЖјmysqlЕФdatetimeФЌШЯЬѕМўжЛОЋШЗЕНСЫУыЁЃ
decimalаЁЪ§ЮЛЮЪЬтЃКcassandraжаВЩгУЕФdecimalЃЌЖдгІmysqlЕФзжЖЮРраЭЪЧdecimal(18,2)ЃЌcassandraжаШчЙћЪЧ0Лђеп0.000ЃЌЧЈвЦЕНmysqlжаЛсБфГЩ0.00ЃЌашвЊзЂвтИУОЋЖШЮЪЬтЁЃ
СНеХБэРДБЃДцЭЌвЛЗнЪ§ОнЕМжТдрЪ§ОнЮЪЬтЃКгЩгкcassandraВщбЏгаКмЖрЯожЦЃЌЮЊСЫжЇГжЖржжВщбЏРраЭЁЃДДНЈСЫСНеХзжЖЮвЛФЃвЛбљЕФБэЃЌГ§СЫprimary
keyВЛвЛбљЁЃШЛКѓУПДЮдіЩОИФЕФЪБКђЃЌСНеХБэЗжБ№ЖМдіЩОИФЃЌЫфШЛетжжЗНЪНДјРДСЫВщбЏЩЯЕФБщРњЃЌЕЋЪЧВњЩњдрЪ§ОнЕФМИТЪЗЧГЃДѓЁЃдкБШЖдЕФЙ§ГЬжаЃЌЗЂЯжЭЌвЛЗнЪ§ОнСНеХБэЕФЪ§ОнСПЯрВюВЛаЁЃЌХХВщЗЂЯжгЩгкдчЦкДњТыbugЕМжТБэвЛаДГЩЙІЃЌБэЖўаДЪЇАметжжЧщПіЃЈКУдкЕФЪЧетаЉЪ§ОнЖМЪЧКмдчжЎЧАЕФЪ§ОнЃЌЫљвджБНгКіТдИУЮЪЬтЃЉЁЃЖјЧЈвЦжСmysqlЃЌжЛЧЈвЦвЛеХБэЙ§ШЅЁЃШчЙћСНеХБэЕФЪ§ОнВЛФмЭъШЋвЛжТЃЌБиШЛгаНгПкБэЯжВЛвЛжТЁЃЮвИіШЫЖдетжжвЛЗнЪ§ОнБЃДцСНЗнгУЗЈвВЪЧВЛЭЦМіЕФЃЌШчЙћВЛдкЮяРэВузіЯожЦЃЌжЛЭЈЙ§ДњТыТпМВуРДБЃжЄЪ§ОнЕФвЛжТадЃЌЪЧМИКѕВЛПЩФмЕФЪТЁЃ
ПезжЗћКЭNULLЕФЮЪЬтЃКcassandraжа""ПезжЗћДЎЕФЧщПіЯТзЊЛЛжСmysqlБфЮЊСЫNULLЃЌетжжЧщПіЛсДјРДНгПкЗЕЛиЕФЪ§ОнВЛвЛжТЕФЮЪЬтЃЌдкВЛШЗЖЈЯТгЮШчКЮЪЙгУИУЪ§ОнЕФЪБКђЃЌзюКУБЃжЄЭъШЋвЛжТЁЃ
зжЖЮТЉЕєЕФЮЪЬтЃКБШЖдЗЂЯжгаеХБэЕФвЛИізжЖЮТЉЕєСЫЃЌИљБОУЛгаЧЈвЦЙ§ШЅЃЌГ§СЫашвЊжиаТШЋСПЧЈвЦИУБэЁЃВЂЧвдіСПЧЈвЦвВашвЊжиЭЗдйРДЃЈОЁСПБмУтИУЮЪЬтЃЌИУЙ§ГЬЪЧЗЧГЃКФЪБЕФЃЉЁЃ
cassandraЪ§ОнВЛвЛжТЕФЮЪЬтЃКЭЌвЛЬѕselectВщбЏгяОфЃЌСЌајВщбЏСНДЮЗЕЛиЕФНсЙћЪ§ВЛвЛжТЁЃетИіБШР§дкЭђЗжжЎвЛ-ЧЇЗжжЎвЛЃЌДјРДЕФЮЪЬтОЭЪЧгаЕФЪ§ОнЪМжеЪЧБШНЯВЛЙ§ЕФЁЃ
гІгУБОЕиЪБжгВЛвЛжТЕМжТЕФЮЪЬтЃКЯжЯѓОЭЪЧЫцзХгІгУЕФЗЂАцЃЌФГеХБэЕФlastModifyTimeЕФЪБМфЃЌГіЯжСЫcassandraБШmysqlаЁЕФЧщПіЃЌЖјДгвЕЮёНЧЖШРДЫЕЃЌmysqlЕФЪБМфЪЧе§ШЗЕФЁЃДѓИХга5%ЕФетжжЧщПіЃЌВЂЧвВЛЛсНЕЯТШЅЁЃПЩФмЫцзХЯТвЛДЮЗЂАцЃЌИУЮЪЬтОЭЯћЪЇСЫЁЃНќ10ДЮЗЂАцга3ДЮГіЯжСЫИУЮЪЬтЃЌзюжеХХВщЗЂЯжЃЌгЩгкВПЪ№ЯпЩЯгІгУЛњЦїЕФБОЕиЪБжгЯрВю3УыЃЌЖјcassandraЛсвРРЕПЭЛЇЖЫЕФЪБМфЃЌДјРДЕФЮЪЬтОЭЪЧcassandraКѓЬсНЛЕФаДШыЃЌПЩФмБЛЯШЬсНЛЕФаДШыИВИЧЁЃЮЊЪВУДИУЮЪЬтЛсЫцзХЗЂАцЖјХМШЛГіЯжФиЃПвђЮЊгІгУЪЧВПЪ№дкШнЦїжаЃЌУПДЮЗЂАцЖМЛсЗжХфаТЕФШнЦїЁЃ
ПЊЫЋаД
ОЙ§вдЩЯВНжшЃЌЛљБОПЩвдШЯЮЊcassandraКЭmysqlЕФЪ§ОнЪЧвЛжТЕФЁЃШЛКѓДђПЊЫЋаДЃЌдйЙиБедіСПЧЈвЦЁЃетЪБКђШчЙћЫЋаДгаЮЪЬтЃЌЭЈЙ§БШЖдГЬађвВФмЙЛЗЂЯжЁЃ
ЧаmysqlЖС
ЫЋаДДѓИХвЛжмКѓЃЌУЛЪВУДЮЪЬтЕФЛАЃЌОЭПЩвдж№ВНАДЗўЮёЧаmysqlЖСЃЌШЛКѓОЭПЩвдЯТЯпcassandraЪ§ОнПтСЫЁЃ
змНс
cassandraЕФЪЙгУЃК
БэЕФЩшМЦЃКЬиБ№ашвЊзЂвтpartition keyЕФЩшМЦЃЌОЁСПвЊБЃжЄЕЅИіpartitionЕФЪ§ОнСПВЛвЊЬЋДѓЁЃ
ФЙБЎЛњжЦЃКашвЊзЂвтcassandraЕФБОЩэЕФФЙБЎЛњжЦЃЌжївЊВњЩњЕФФЙБЎЕФЧщПіЃЌжївЊЪЧdeleteВйзїКЭinsert
nullзжЖЮетСНжжЧщПіЁЃЮвУЧетРядјОвђЮЊФГИігУЛЇЦЕЗБВйзїздМКappЕФФГИіЖЏзїЃЌЕМжТЪ§ОнПтетБпЦЕЗБЕФЖдЭЌвЛИіpartition
keyжДааdeleteВйзїдйinsertВйзїЁЃгУЛЇжДааВйзїНгНќЩЯАйДЮКѓЃЌЕМжТИУpartitionВњЩњДѓСПФЙБЎЃЌзюжеВщбЏЧыЧѓДђЕНИУpartition
keyЁЃдьГЩТ§ВщбЏЃЌгІгУГЌЪБжиЪдЃЌЕМжТcassandra cpuьЩ§ЃЌзюжеЕМжТЦфЫћpartition
keyвВЪмЕНгАЯьЃЌДѓСПВщбЏГЌЪБЁЃ
cassandraПЭЛЇЖЫЪБжгВЛвЛжТЕФЮЪЬтЃЌПЩФмЕМжТаДШыЮоаЇЁЃ
ЧЈвЦЯрЙиЃК
ШЋСПЧЈвЦКЭдіСПЧЈвЦЃЌзюКУдкЩЯЯпжЎЧАВтЪдГфЗжЃЌЧЇЭђзЂвтзжЖЮТЉЕєДэЮЛЕФЮЪЬтЃЌОЁПЩФмЕФШУВтЪдВЮгыЁЃдке§ЪНЧЈвЦжЎЧАЃЌзюКУдкЯпЩЯДДНЈвЛИідЄБИПтЃЌЯШПЩвддЄХмвЛДЮЁЃОЁПЩФмЕФЗЂЯжЯпЩЯе§ЪНЧЈвЦЪБгіЕНЕФЮЪЬтЁЃЗёдђе§ЪНЧЈвЦЕФЪБКђгіЮЪЬтЕФЪБКђЃЌаоИДЪЧБШНЯТщЗГЕФЁЃ
дкЧаЛђЙиБеЖСаДЙ§ГЬжаЃЌвЛЖЈвЊгаЛиЙіМЦЛЎЁЃ
| 








