| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмСЫPostgreSQLЕФдДДњТыЃЌЫЕУїСЫPostgreSQL
9.1ЕФШЋЬхНсЙЙЃЌЛЙгаЫЕУїСЫДњТыЪї,ШЛКѓЛЙЪЙгУСЫЕїЪдЦїРДзЗзйPostgreSQLЕФЖЏзїЁЃ
|
|
PostgreSQLЕФЪЙгУаЮЬЌ
PostgreSQLВЩгУC/S(ПЭЛЇЛњ/ЗўЮёЦї)ФЃЪННсЙЙЁЃгІгУВуЭЈЙ§INETЛђепUnix SocketРћгУМШЖЈЕФавщгыЪ§ОнПтЗўЮёЦїНјааЭЈаХЁЃ
СэЭтЃЌЛЙгавЛжжЁЎStandalone BackendЁЏЪЙгУЕФЗНЪН, ЫфШЛЭЈЙ§етжжЗНЪНвВПЩвдЦєЖЏЗўЮёЦїЃЌЕЋЪЧвЛАужЛдкЪ§ОнПтЕФГѕЪМЛЏ(PostgreSQLЕФclusterЕФГѕЪМЛЏЃЌЯрЕБгкЦфЫћЪ§ОнПтЕФinstanceЕФГѕЪМЛЏ)ЁЂНєМБЮЌЛЄЕФЪБКђЪЙгУЃЌЫљвдМђЕЅРДЫЕПЩвдШЯЮЊPostgreSQLЪЧЪЙгУC/SЕФаЮЪННјааЗУЮЪЕФЁЃ
PostgreSQLАбПЭЛЇЖЫГЦЮЊЧАЖЫ(Frontend),АбЗўЮёЦїЖЫГЩЮЊКѓЖЫ(Backend),
КѓЖЫгаИДЪ§ИіНјГЬЙЙГЩЃЌетИідкКѓУцЛсНјааЫЕУїЁЃ
ЧАЖЫКЭКѓЖЫЭЈаХЕФавщдкPostgreSQLЕФЙйЗНЮФЕЕжаЕФЁЖЧАЖЫКЭКѓЖЫЕФЭЈаХавщЁЗвЛеТжагаЯъЯИЕФЫЕУїЁЃМђЕЅРДЫЕЃЌДѓЬхЕФЙЄзїФЃЪНЪЧЃКЧАЖЫЯђКѓЖЫЗЂЫЭВщбЏЕФSQLЮФЃЌШЛКѓКѓЖЫЭЈЙ§ИДЪ§ИіБЈЮФАбНсЙћЗЕЛиИјЧАЖЫЁЃ
гЩгкашвЊНјааСЌНгЕФГѕЪМЛЏЁЂДэЮѓЕШИїжжИїбљДІРэЃЌPostgreSQLЕФавщЕФДІРэвВЪЧЯрЕБИДдгЃЌШчЙћвЊздМКДгЭЗЪЕЯжетаЉавщЕФДІРэЕФЛАЃЌЛЙЪЧЯрЕБТщЗГЕФЃЌЫљвдPostgreSQLБОЩэЬсЙЉСЫCгябдаДЕФlibpqетбљвЛИіавщДІРэПтЃЌРћгУетИіПтПЩвдБШНЯЧсЫЩЕиКЭКѓЖЫНјааЭЈаХЁЃPostgreSQLЕФЛАГ§СЫCвдЭтЃЌЛЙжЇГжPerlКЭPHPЕШЦфЫћгябдЃЌетаЉгябддкФкВПвВЕїгУСЫlibpq.
вВгаВЛЪЙгУlibpqЖјжБНггыPostgreSQLЭЈаХЕФПтЁЃБШНЯОпгаДњБэадЕФЪЧJava, PostgreSQLЕФJDBCЧ§ЖЏЪЧВЛвРРЕгкlibpqжБНггыPostgreSQLЭЈаХЕФ.
СэЭтКѓЖЫЕФЛАЃЌБШНЯКЫаФЕФЪЧНјааЪ§ОнПтДІРэЕФЪ§ОнПтв§Чц(Database Engine)ЁЃ Ъ§ОнПтв§ЧцПЩвдЖдгУЛЇЫљБраДЕФКЏЪ§НјааНтЮіКЭДІРэЃЌгУЛЇШчЙћФмЙЛРћгУКУетИіЙІФмЕФЛАЃЌПЩвдШсШэЕиРЉеЙPostgreSQLЕФЙІФмЁЃ
БШНЯОГЃЪЙгУЕФЪЧДцДЂЙ§ГЬ(PostgreSQLжаГЦЮЊгУЛЇздЖЈвхКЏЪ§)ЃЌPostgreSQLжЇГжЕФгУЛЇЖЈвхКЏЪ§ЕФгябдШчЯТЃК
гябд ЖдгІЕФздЖЈвхКЏЪ§
C CКЏЪ§
SQL SQL КЏЪ§
РрЫЦOracleЕФPL/SQLЕФгябд PL/pgSQL
Perl PL/Perl
Python PL/Python |
PostgreSQLЕФЛАЃЌгУЛЇПЩвдздЖЈвхгябдДІРэв§ЧцЁЃИїжжЗўЮёЦїНХБОгябдЕФНтЮів§ЧцЃЌвдЕкШ§ЗНЕФаЮЪНДцдкЃЌжївЊЕФДІРэгябдгаRubyЁЂJavaвдМАPHPЕШЁЃ
PostgreSQLЕФНсЙЙ
етРяЕФЛАЃЌдйЯъЯИПДПДPostgreSQLЕФНсЙЙЁЃ КѓЖЫгЩМИИіНјГЬЙЙГЩЁЃ
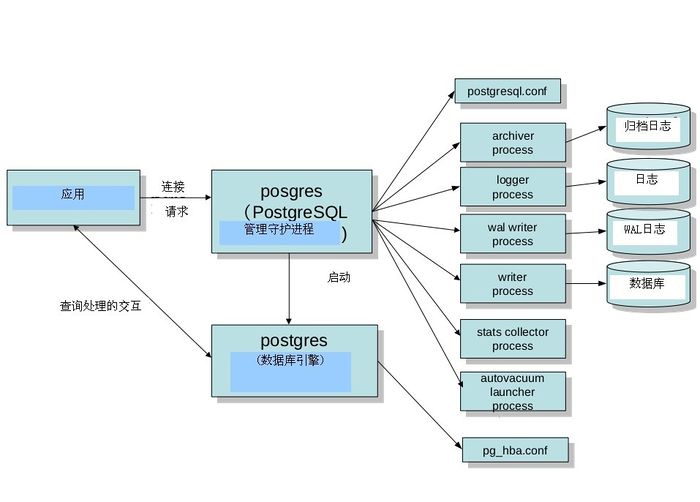
Potgres(ГЃзЄНјГЬ)
ЙмРэКѓЖЫЕФГЃзЄНјГЬЃЌвВГЦЮЊЁЏpostmasterЁЏЁЃЦфФЌШЯМрЬ§UNIX Domain SocketКЭTCP/IPЃЈWindowsЕШЃЌвЛВПЗжЕФЦНЬЈжЛМрЬ§tcp/ipЃЉЕФ5432ЖЫПкЃЌЕШД§РДздЧАЖЫЕФЕФСЌНгДІРэЁЃМрЬ§ЕФЖЫПкКХПЩвддкPostgreSQLЕФЩшжУЮФМўpostgresql.confРяУцПЩвдИФЁЃ
вЛЕЉгаЧАЖЫСЌНгЙ§РДЃЌpostgresЛсЭЈЙ§fork(2)ЩњГЩзгНјГЬЁЃУЛгаFork(2)ЕФwindowsЦНЬЈЕФЛАЃЌдђРћгУcreateProcess()ЩњГЩаТЕФНјГЬЁЃетжжЧщаЮЕФЛАЃЌКЭfork(2)ВЛЭЌЕФЪЧЃЌИИНјГЬЕФЪ§ОнВЛЛсБЛМЬГаЙ§РДЃЌЫљвдашвЊРћгУЙВЯэФкДцАбИИНјГЬЕФЪ§ОнМЬГаЙ§РДЁЃ
Postgres(згНјГЬ)
згНјГЬИљОнpg_hba.confЖЈвхЕФАВШЋВпТдРДХаЖЯЪЧЗёдЪаэНјааСЌНгЃЌИљОнВпТдЃЌЛсОмОјФГаЉЬиЖЈЕФIPМАЭјТчЃЌЛђепвВПЩвджЛдЪаэФГаЉЬиЖЈЕФгУЛЇЛђепЖдФГаЉЪ§ОнПтНјааСЌНгЁЃ
PostgresЛсНгЪмЧАЖЫЙ§РДЕФВщбЏЃЌШЛКѓЖдЪ§ОнПтНјааМьЫїЃЌзюКУАбНсЙћЗЕЛиЃЌгаЪБвВЛсЖдЪ§ОнПтНјааИќаТЁЃИќаТЕФЪ§ОнЭЌЪБЛЙЛсМЧТМдкЪТЮёШежОРяУцЃЈPostgreSQLГЦЮЊWALШежОЃЉЃЌетИіжївЊЪЧЕБЭЃЕчЕФЪБКђЃЌЗўЮёЦїЕБЛњЃЌжиаТЦєЖЏЕФЪБКђНјааЛжИДДІРэЕФЪБКђЪЙгУЕФЁЃСэЭтЃЌАбШежОЙщЕЕБЃДцЦ№РДЃЌПЩдкашвЊНјааЛжИДЕФЪБКђЪЙгУЁЃдкPostgreSQL
9.0вдКѓЃЌЭЈЙ§АбWALШежОДЋЫЭЦфЫћЕФpostgreSQLЃЌПЩвдЪЕЪБЕУНјааЪ§ОнПтИДжЦЃЌетОЭЪЧЫљЮНЕФЁЎЪ§ОнПтИДжЦЁЏЙІФмЁЃ
ЦфЫћЕФНјГЬ
PostgresжЎЭтЛЙгавЛаЉИЈжњЕФНјГЬЁЃетаЉНјГЬЖМЪЧгЩГЃзЄpostgresЦєЖЏЕФНјГЬЁЃ
Writer process
Writer processдкЪЪЕБЕФЪБМфЕуАбЙВЯэФкДцЩЯЕФЛКДцаДЭљДХХЬЁЃЭЈЙ§етИіНјГЬЃЌПЩвдЗРжЙдкМьВщЕуЕФЪБКђ(checkpoint),ДѓСПЕФЭљДХХЬаДЖјЕМжТадФмЖёЛЏЃЌЪЙЕУЗўЮёЦїПЩвдБЃГжБШНЯЮШЖЈЕФадФмЁЃBackground
writerЦ№РДвдКѓОЭвЛжБГЃзЄФкДцЃЌЕЋЪЧВЂЗЧвЛжБдкЙЄзїЃЌЫќЛсдкЙЄзївЛЖЮЪБМфКѓНјааанУпЃЌанУпЕФЪБМфМфИєЭЈЙ§postgresql.confРяУцЕФВЮЪ§bgwriter_delayЩшжУЃЌФЌШЯЪЧ200ЮЂУыЁЃ
етИіНјГЬЕФСэЭтвЛИіживЊЕФЙІФмЪЧЖЈЦкжДааМьВщЕу(checkpoint)ЁЃ
МьВщЕуЕФЪБКђЃЌЛсАбЙВЯэФкДцЩЯЕФЛКДцФкШнЭљЪ§ОнПтЮФМўаДЃЌЪЙЕУФкДцКЭЮФМўЕФзДЬЌвЛжТЁЃЭЈЙ§етбљЃЌПЩвддкЯЕЭГБРРЃЕФЪБКђПЩвдЫѕЖЬДгWALЛжИДЕФЪБМфЃЌСэЭтвВПЩвдЗРжЙWALЮоЯоЕФдіГЄЁЃ
ПЩвдЭЈЙ§postgresql.confЕФcheckpoint_segmentsЁЂcheckpoint_timeoutжИЖЈжДааМьВщЕуЕФЪБМфМфИєЁЃ
WAL writer process
WAL writer processАбЙВЯэФкДцЩЯЕФWALЛКДцдкЪЪЕБЕФЪБМфЕуЭљДХХЬаДЃЌЭЈЙ§етбљЃЌПЩвдМѕЧсКѓЖЫНјГЬдкаДздМКЕФWALЛКДцЪБЕФбЙСІЃЌЬсИпадФмЁЃСэЭтЃЌЗЧЭЌВНЬсНЛЩшЮЊtrueЕФЪБКђЃЌПЩвдБЃжЄдквЛЖЈЕФЪБМфМфИєФкЃЌАбWALЛКДцЩЯЕФФкШнаДШыWALШежОЮФМўЁЃ
Archive process
Archive processАбWALШежОзЊвЦЕНЙщЕЕШежОРяЁЃШчЙћБЃДцСЫЛљДЁБИЗнвдМАЙщЕЕШежОЃЌМДЪЙЪЕдкДХХЬЭъШЋЫ№ЛЕЕФЪБКђЃЌвВПЩвдЛиИДЪ§ОнПтЕНзюаТЕФзДЬЌЁЃ
stats collector process
ЭГМЦаХЯЂЕФЪеМЏНјГЬЁЃЪеМЏКУЭГМЦБэЕФЗУЮЪДЮЪ§ЃЌДХХЬЕФЗУЮЪДЮЪ§ЕШаХЯЂЁЃЪеМЏЕНЕФаХЯЂГ§СЫФмБЛautovaccumРћгУЃЌЛЙПЩвдИјЦфЫћЪ§ОнПтЙмРэдБзїЮЊЪ§ОнПтЙмРэЕФВЮПМаХЯЂЁЃ
Logger process
АбpostgresqlЕФЛюЖЏзДЬЌаДЕНШежОаХЯЂЮФМўЃЈВЂЗЧЪТЮёШежОЃЉЃЌдкжИЖЈЕФЪБМфМфИєРяУцЃЌЖдШежОЮФМўНјааrotate.
AutovacuumЦєЖЏНјГЬ
autovacuum launcher processЪЧвРРЕгкpostmasterМфНгЦєЖЏvacuumНјГЬЁЃЖјЦфздЩэЪЧВЛжБНгЦєЖЏздЖЏvacuumНјГЬЕФЁЃЭЈЙ§етбљПЩвдЬсИпЯЕЭГЕФПЩППадЁЃ
здЖЏvacuumНјГЬ
autovacuum worker processНјГЬЪЕМЪжДааvacuumЕФШЮЮёЁЃгаЪБКђЛсЭЌЪБЦєЖЏЖрИіvacuumНјГЬЁЃ
wal sender / wal receiver
wal sender НјГЬКЭwal receiverНјГЬЪЧЪЕЯжpostgresqlИДжЦ(streaming
replication)ЕФНјГЬЁЃWal senderНјГЬЭЈЙ§ЭјТчДЋЫЭWALШежОЃЌЖјЦфЫћPostgreSQLЪЕР§ЕФwal
receiverНјГЬдђНгЪеЯргІЕФШежОЁЃWal receiverНјГЬЕФЫожїPostgreSQLЃЈвВГЦЮЊStandbyЃЉНгЪмЕНWALШежОКѓЃЌдкздЩэЕФЪ§ОнПтЩЯЛЙдЃЌЩњГЩвЛИіКЭЗЂЫЭЖЫЕФPostgreSQL(вВГЦЮЊMaster)ЭъШЋвЛбљЕФЪ§ОнПтЁЃ
КѓЖЫЕФДІРэСїГЬ
ЯТУцПДПДЪ§ОнПтв§ЧцpostgresзгНјГЬЕФДІРэИХвЊЁЃЮЊСЫМђЕЅЦ№МћЯТУцЕФЫЕУїжаЃЌАбbackend processМђГЦЮЊbackendЁЃBackendЕФmainКЏЪ§ЪЧPostgresMain
(tcop/postgres.c)ЁЃ
НгЪеЧАЖЫЗЂЫЭЙ§РДЕФВщбЏ(SQLЮФ)
SQLЮФЪЧЕЅДПЕФЮФзжЃЌЕчФдЪЧШЯЪЖВЛСЫЕФЃЌЫљвдвЊзЊЛЛГЩБШНЯШнвзДІРэЕФФкВПаЮЪНЙЙЮФЪїparser tree,етИіДІРэЕФГЦЮЊЙЙЮФНтЮіЁЃЙЙЮФНтЮіЕФФЃПщГЦЮЊparser.етИіНзЖЮжЛФмЙЛЪЙгУЮФзжзжУцЩЯЕУРДЕФаХЯЂЃЌЫљвджЛвЊУЛгяЗЈДэЮѓжЎРрЕФДэЮѓЃЌМДЪЙЪЧselectВЛДцдкЕФБэвВВЛЛсБЈДэЁЃетИіНзЖЮЕФЙЙЮФЪїБЛГЦЮЊraw
parse tree. ЙЙЮФДІРэЕФШыПкдкraw_parser (parser/parser.c)ЁЃ
ЙЙЮФЪїНтЮіЭъвдКѓЃЌЛсзЊЛЛЮЊВщбЏЪї(Query tree)ЁЃетИіЪБКђЃЌЛсЗУЮЪЪ§ОнПтЃЌМьВщБэЪЧЗёДцдкЃЌШчЙћДцдкЕФЛАЃЌдђАбБэУћзЊЛЛЮЊOIDЁЃетИіДІРэГЦЮЊЗжЮіДІРэ(Analyze),
НјааЗжЮіДІРэЕФФЃПщЪЧanalyzerЁЃ СэЭтЃЌPostgreSQLЕФДњТыРяУцЬсЕНЙЙЮФЪїparser
treeЕФЪБКђЃЌИќЖрЕФЪБКђЪЧжИВщбЏЪїQuery treeЁЃЗжЮіДІРэЕФФЃПщЕФШыПкдкparse_analyze
(parser/analyze.c)
PostgreSQLЛЙЭЈЙ§ВщбЏгяОфЕФжиаДЪЕЯжЪгЭМ(view)КЭЙцдђ(rule), ЫљвдашвЊЕФЪБКђЃЌдкетИіНзЖЮЛсЖдВщбЏгяОфНјаажиаДЁЃетИіДІРэГЦЮЊжиаД(rewrite)ЃЌжиаДЕФШыПкдкQueryRewrite
(rewrite/rewriteHandler.c)ЁЃ
ЭЈЙ§НтЮіВщбЏЪїЃЌПЩвдЪЕМЪЩњГЩМЦЛЎЪїЁЃЩњГЩВщбЏЪїЕФДІРэГЦЮЊЁЎжДааМЦЛЎДІРэЁЏЃЌзюЙиМќЪЧвЊЩњГЩЙРМЦФмдкзюЖЬЕФЪБМфФкЭъГЩЕФМЦЛЎЪї(plan
tree)ЁЃетИіВНжшГЦЮЊЁЏВщбЏгХЛЏЁЏ(ВЛНаquery optimize, ЖјЪЧoptimize),
ЖјЭъГЩетИіДІРэЕФФЃПщГЦЮЊВщбЏгХЛЏЦї(ВЛНаquery optimizer,ЖјЪЧoptimizer, ЛђепГЦЮЊplanner)ЁЃжДааМЦЛЎДІРэЕФШыПкдкstandard_planner
(optimizer/plan/planner.c)ЁЃ
АДеежДааМЦЛЎРяУцЕФВНжшПЩвдЭъГЩВщбЏвЊДяЕНЕФФПЕФЁЃдЫаажДааМЦЛЎЪїРяУцВНжшЕФДІРэГЦЮЊжДааДІРэЁЎexecuteЁЏ,
ЭъГЩетИіДІРэЕФФЃПщГЦЮЊжДааЦїЁЎExecutorЁЏ, жДааЦїЕФШыПкЕижЗЮЊЃЌExecutorRun (executor/execMain.c)
жДааНсЙћЗЕЛиИјЧАЖЫЁЃ
ЗЕЛиЕНВНжшвЛжиИДжДааЁЃ
PostgreSQLЕФдДТы
ЯждкЛљБОЩЯРэНтСЫPostgreSQLЕФДѓЬхЕФНсЙЙЃЌЮвУЧдйРДПДПДPostgreSQLДњТыЕФНсЙЙЁЃ PostgreSQLГѕЦкЕФЪБКђЃЌДѓИХжЛга20ЭђаазѓгвЕФДњТыЃЌЯждквбОЗЂеЙЕН100ЭђааСЫЁЃетИіСПРДЫЕЃЌУЛгажИЕМЖСЦ№РДЪЧМЋЮЊФбРэНтЕФЃЌетРяАбДѓИХЕФДњТыНсЙЙЫЕУївЛЯТЃЌШУДѓМвЖддДТыЕФНсЙЙгаИіРэНтЁЃ
ЕквЛМЖФПТМНсЙЙ
НјШыPostgreSQLЕФдДТыФПТМКѓЃЌЕквЛМЖЕФНсЙЙШчЯТБэЫљЪОЁЃдкетвЛМЖРяЃЌЭЈЙ§жДааШчЯТУќСюconfigure;make;make
installПЩвдСЂМДНјааМђЕЅЕФАВзАЃЌЪЕМЪЩЯДгPostgreSQLдДТыАВзАЪЧМЋЮЊМђЕЅЕФЁЃ
ЮФМўФПТМ ЫЕУї
COPYRIGHT АцШЈаХЯЂ
GUNMakefile ЕквЛМЖФПТМЕФ Makefile
GUNMakefile.in Makefile ЕФГћаЮ
HISTORY аоИФРњЪЗ
INSTALL АВзАЗНЗЈМђвЊЫЕУї
Makefile MakefileФЃАц
README МђЕЅЫЕУї
aclocal.m4 config гУЕФЮФМўЕФвЛВПЗж
config/ config гУЕФЮФМўЕФФПТМ
configure configure ЮФМў
configure.in configure ЮФМўЕФГћаЮ
contrib/ contribution ГЬађ
doc/ ЮФЕЕФПТМ
src/ дДДњТыФПТМ |
PostgreSQL ЕФsrcЯТУцгаЁЃ
ЮФМўФПТМ ЫЕУї
DEVELOPERS УцЯђПЊЗЂШЫдБЕФзЂЪг
Makefile Makefile
Makefile.global make ЕФЩшЖЈжЕЃЈДгconfigureЩњГЩЕФЃЉ
Makefile.global.in ConfigureЪЙгУЕФMakefile.globalЕФГћаЮ
Makefile.port ЦНЬЈЯрЙиЕФmakeЕФЩшЖЈжЕЃЌЪЕМЪЪЧвЛИіЕНmakefile/MakefileЕФСЌНг.
ЃЈДгconfigureЩњГЩЕФЃЉ
Makefile.shlib ЙВЯэПтгУЕФMakefile
backend/ КѓЖЫЕФдДТыФПТМ
bcc32.mak Win32 ЅнЉ`ЅШгУЄЮ Makefile (Borland C++ гУ)
bin/ psql ЕШ UNIXУќСюЕФДњТы
include/ ЭЗЮФМў
interfaces/ ЧАЖЫЯрЙиЕФПтЕФДњТы
makefiles/ ЦНЬЈЯрЙиЕФmake ЕФЩшжУжЕ
nls-global.mk аХЯЂФПТМгУЕФMakefileЮФМўЕФЙцдђ
pl/ ДцДЂЙ§ГЬгябдЕФДњТы
port/ ЦНЬЈвЦжВЯрЙиЕФДњТы
template/ ЦНЬЈЯрЙиЕФЩшжУжЕ
test/ ИїжжВтЪдНХБО
timezone/ ЪБЧјЯрЙиДњТы
tools/ ИїздПЊЗЂЙЄОпКЭЮФЕЕ
tutorial/ НЬГЬ
win32.mak Win32 ЅнЉ`ЅШгУЄЮ Makefile (Visual C++ гУ)
|
win32.mak Win32 ЅнЉ`ЅШгУЄЮ Makefile (Visual C++ гУ)
етРяБШНЯКЫаФЕФЪЧbackend,bin,interfaceетМИИіФПТМЁЃBackendЪЧЖдгІгкКѓЖЫЃЌbinКЭinterfaceЖдгІгкЧАЖЫЁЃ
binРяУцгаpgsql,initdb,pg_dumpЕШИїжжЙЄОпЕФДњТыЁЃinterfaceРяУцгаPostgreSQLЕФCгябдЕФПтlibpq,СэЭтПЩвддкCРяЧЖШыSQLЕФECPGУќСюЕФЯрЙиДњТыЁЃ
BackendФПТМЕФНсЙЙШчЯТЃК
ФПТМЮФМў ЫЕУї
Makefile makefile
access/ ИїжжДцДЂЗУЮЪЗНЗЈ(дкИїИізгФПТМЯТ) common(ЙВЭЌКЏЪ§)ЁЂgin (Generalized
Inverted IndexЭЈгУФцЯђЫїв§)
gist (Generalized Search TreeЭЈгУЫїв§)ЁЂ hash (ЙўЯЃЫїв§)ЁЂheap
(heapЕФЗУЮЪЗНЗЈ)ЁЂ
index (ЭЈгУЫїв§КЏЪ§)ЁЂ nbtree (BtreeКЏЪ§)ЁЂtransam (ЪТЮёДІРэ)
bootstrap/ Ъ§ОнПтЕФГѕЪМЛЏДІРэ(initdbЕФЪБКђ)
catalog/ ЯЕЭГФПТМ
commands/ SELECT/INSERT/UPDATE/DELETEвдЮЊЕФSQLЮФЕФДІРэ
executor/ жДааЦї(ЗУЮЪЕФжДаа)
foreign/ FDW(Foreign Data Wrapper)ДІРэ
lib/ ЙВЭЌКЏЪ§
libpq/ ЧАЖЫ/КѓЖЫЭЈаХДІРэ
main/ postgresЕФжїКЏЪ§
nodes/ ЙЙЮФЪїНкЕуЯрЙиЕФДІРэКЏЪ§
optimizer/ гХЛЏЦї
parser/ SQLЙЙЮФНтЮіЦї
port/ ЦНЬЈЯрЙиЕФДњТы
postmaster/ postmasterЕФжїКЏЪ§ (ГЃзЄpostgres)
replication/ streaming replication
regex/ е§дђДІРэ
rewrite/ ЙцдђМАЪгЭМЯрЙиЕФжиаДДІРэ
snowball/ ШЋЮФМьЫїЯрЙиЃЈгяИЩДІРэЃЉ
storage/ ЙВЯэФкДцЁЂДХХЬЩЯЕФДцДЂЁЂЛКДцЕШШЋВПвЛДЮ/ЖўДЮМЧТМЙмРэ(вдЯТЕФФПТМ)buffer/(ЛКДцЙмРэ)ЁЂ
file/(ЮФМў)ЁЂ
freespace/(Fee Space MapЙмРэ) ipc/(НјГЬМфЭЈаХ)ЁЂlarge_object
/(ДѓЖдЯѓЕФЗУЮЪКЏЪ§)ЁЂ
lmgr/(ЫјЙмРэ)ЁЂpage/(вГУцЗУЮЪЯрЙиКЏЪ§)ЁЂ smgr/(ДцДЂЙмРэЦї)
tcop/ postgres (Ъ§ОнПтв§ЧцЕФНјГЬ)ЕФжївЊВПЗж
tsearch/ ШЋЮФМьЫї
utils/ ИїжжФЃПщ(вдЯТФПТМ) adt/(ЧЖШыЕФЪ§ОнРраЭ)ЁЂcache/(ЛКДцЙмРэ)ЁЂ
error/(ДэЮѓДІРэ)ЁЂfmgr/(КЏЪ§ЙмРэ)ЁЂ
hash/(hashКЏЪ§)ЁЂ init/(Ъ§ОнПтГѕЪМЛЏЁЂpostgresЕФГѕЦкДІРэ)ЁЂ mb/(ЖрзжНкЮФзжДІРэ)ЁЂ
misc/(ЦфЫћ)ЁЂmmgr/(ФкДцЕФЙмРэКЏЪ§)ЁЂ resowner/(ВщбЏДІРэжаЕФЪ§Он(buffer
pinМАБэЫј)ЕФЙмРэ)ЁЂ
sort/(ХХађДІРэ)ЁЂtime/(ЪТЮёЕФ MVCC ЙмРэ) |
backendЕШЕФДњТыЕФЭЗЮФМўАќКЌдкincludeРяУцЁЃЦфзщжЏЫфШЛгыbackendЕФФПТМНсЙЙРрЫЦЃЌЕЋЪЧВЂЗЧЭъШЋЯрЭЌЃЌЛљБОЩЯРДЫЕЯТвЛМЖЕФзгФПТМВЛдйЩшЯТвЛМЖФПТМЁЃР§ШчbackendЕФФПТМЯТУцгаutilsетИіФПТМЃЌЖјutilЯТУцЛЙгаadtетИізгФПТМЃЌЕЋЪЧincludeРяУцЪЁТдСЫетИіФПТМЃЌБфГЩСЫБтЦНЕФНсЙЙЁЃ
access/
bootstrap/
c.h
catalog/
commands/
dynloader.h
executor/
fmgr.h
foreign/
funcapi.h
getaddrinfo.h
getopt_long.h
lib/
libpq/
mb/
miscadmin.h
nodes/
optimizer/
parser/
pg_config.h
pg_config.h.in
pg_config.h.win32
pg_config_manual.h
pg_config_os.h
pg_trace.h
pgstat.h
pgtime.h
port/
port.h
portability/
postgres.h
postgres_ext.h
postgres_fe.h
postmaster/
regex/
rewrite/
rusagestub.h
snowball/
stamp-h
storage/
tcop/
tsearch/
utils/
windowapi.h |
ДњТыЕФдФЖСЗНЗЈ
гУЕїЪдЦїзЗзйДњТы
PostgreSQLФЧбљЕФХгДѓЯЕЭГЃЌгУблОІРДзЗзйдДТыВЂВЛШнвзЁЃетРяЭЦМігУgdbетбљЕФЪЕМЪЕїЪдЦїРДзЗзйДњТыЕФжДааСїГЬЁЃПЩФмгааЉШЫЮЗОхЕїЪдЦїЃЌЕЋЪЧШчЙћжЛЪЧМђЕЅзЗзйДњТыЕФжДааСїЕФЛАЃЌЛЙЪЧКмМђЕЅЕФЁЃ
ЕЋЪЧЖрЩйЛЙЪЧвЊзівЛаЉзМБИЕФЃЌPostgreSQLдкБрвыЕФЪБКђвЛЖЈвЊАбЕїЪдПЊЙиДђПЊЁЃЭЈГЃдкБрвыЕФЪБКђconfigureЕФЪБКђМгЩЯ--enable-debugЕФбЁЯюЃЌШЛКѓПЩФмЕФЛАПЩвдБрМsrc/Makefile.globalетИіЮФМў
CFLAGS = -O2
-Wall -Wmissing-prototypes -Wpointer-arith \
-Wdeclaration-after-statement -Wendif-labels -Wformat-security
\
-fno-strict-aliasing -fwrapv |
ЩЯУцЕФааЕФ"-O2"бЁЯюЩОГ§ЃЌШЛКѓМгЩЯ"-g"
CFLAGS = -g -Wall
-Wmissing-prototypes -Wpointer-arith \
-Wdeclaration-after-statement -Wendif-labels -Wformat-security
\
-fno-strict-aliasing -fwrapv |
"-O2"ЪЧБрвыЦїЕФгХЛЏбЁЯюЃЌШчЙћДђПЊСЫЃЌДњТыЕФжДааЫГађЛсИФБфЃЌЪЙЕУзЗзйЦ№ДњТыРДБШНЯРЇФбЃЌЫљвдвЊШЅГ§ЁЃЕБШЛетбљЕФЛАЃЌБрвыКѓЕФПЩжДааЮФМўЛсБШНЯДѓЃЌЖјЧвЛсБШНЯТ§ЃЌЩњВњЛЗОГВЛЬЋКЯЪЪЁЃДѓМвашвЊРэНтетИіВйзїНіНіЪЧдкбЇЯАЕФЪБКђЖјЩшжУЕФЁЃ
ЪЕМЪЪЙгУgdbЪдЪд
ЯТУцЪЕМЪЪЙгУgdbРДПДПДБШНЯМђЕЅЕуЕФselectЮФЁЃ
selectЮФжДааКѓЃЌжСexecutorЕФЦфжавЛИіКЏЪ§ExecSelectЭЃжЙЃЌШЛКѓЮвУЧЕїВщвЛЯТЪЕМЪЕїгУСЫФЧаЉКЏЪ§ЁЃ
ЪзЯШвдPostgreSQLЕФГЌМЖгУЛЇЕЧТМЁЃЮвЕФЛЗОГЪЧЪЙгУt-ishiiетИігУЛЇАВзАPostgreSQLЕФЃЌЭЈГЃвЛАуЪЙгУpostgresетИігУЛЇЃЌДѓМвдкдФЖСЕФЪБКђЬцЛЛвЛЯТМДПЩЁЃ
ШЛКѓЃЌгУpsqlКЭЪ§ОнПтНјааСЌНгЃЌСЌНгЕФзДЬЌПЩвдЭЈЙ§psУќСюЕїВщЁЃ
| $ ps x
3714 ? Ss 0:00 postgres: t-ishii test [local]
idle |
ПЩвдПДЕНЩЯУцЕФНјГЬЁЃетИіОЭЪЧКѓЖЫЕФНјГЬЁЃетИіЪЧКѓЖЫЕФНјГЬЃЌЛЙгаЦфЫћДѓСПгУЛЇЕФPostgreSQLЕФСЌНгвВЯдЪОГіРДЃЌБШНЯФбПДЧхГўЃЌЫљвдЛЙЪЧзМБИКУВтЪдЕФЛЗОГРДНјааВтЪдБШНЯКУЁЃ
ЦєЖЏgdbКѓЃЌИНМгЕНpsРяЯдЪОЕФНјГЬКХТыЁЃ
$ gdb postgres
3714
GNU gdb (GDB) 7.2
Copyright (C) 2010 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
<http://gnu.org/licenses/gpl.html>
This is free software: you are free to change
and redistribute it.
There is NO WARRANTY, to the extent permitted
by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-vine-linux".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /usr/local/pgsql/bin/postgres...done.
Attaching to program: /usr/local/pgsql/bin/postgres,
process 3714
Reading symbols from /lib64/libdl.so.2...done.
Loaded symbols for /lib64/libdl.so.2
Reading symbols from /lib64/libm.so.6...done.
Loaded symbols for /lib64/libm.so.6
Reading symbols from /lib64/libc.so.6...done.
Loaded symbols for /lib64/libc.so.6
Reading symbols from /lib64/ld-linux-x86-64.so.2...done.
Loaded symbols for /lib64/ld-linux-x86-64.so.2
Reading symbols from /lib64/libnss_files.so.2...done.
Loaded symbols for /lib64/libnss_files.so.2
0x00007fad266f82e2 in __libc_recv (fd=<value
optimized out>, buf=0xbe9900,
n=8192, flags=<value optimized out>)
at ../sysdeps/unix/sysv/linux/x86_64/recv.c:30
30 ../sysdeps/unix/sysv/linux/x86_64/recv.c:
in ../sysdeps/unix/sysv/linux/x86_64/recv.c
(gdb) |
(gdb) ЪЧgdbЕФУќСюааЁЃдкетИізДЬЌЯТЃЌПЩвдНгЪмgdbЕФУќСюЃЌШчЙћЪфШыbУќСюЕФЛАЃЌдкExecResultПЩвдЩшжУЖЯЕуЁЃ
(gdb) b ExecResult
Breakpoint 1, ExecResult (node=0xd13eb0) at nodeResult.c:75
(gdb) |
psqlЦєЖЏвдКѓДгжеЖЫжДааselect 1,ЪфШывдКѓЃЌКѓЖЫОЭЛсжДааИУУќСюЁЃетИіЪБКђЃЌpostgresНјГЬвбОднЭЃЃЌЫљвдpsqlЛсЖЏВЛСЫЁЃвЊМЬајжДааЕФЛАЃЌПЩдкgdbРяжДаа"c"УќСюЁЃжДааСЫвдКѓЃЌОЭЛсдкExecResult
ДІЭЃжЙЁЃ
| Continuing.
Breakpoint 1, ExecResult (node=0xd13eb0) at
nodeResult.c:75
75 econtext = node->ps.ps_ExprContext;
(gdb) |
ЕНExecSelectЮЊжЙЕФКЏЪ§ЕФЕїгУТЗОЖПЩвдгУbtЕФУќСюЯдЪОГіРДЁЃ
(gdb) bt
#0 ExecResult (node=0xd13eb0) at nodeResult.c:75
#1 0x00000000005b92a4 in ExecProcNode (node=0xd13eb0)
at execProcnode.c:367
#2 0x00000000005b71bb in ExecutePlan (estate=0xd13da0,
planstate=0xd13eb0,
operation=CMD_SELECT, sendTuples=1 '\001', numberTuples=0,
direction=ForwardScanDirection, dest=0xcf9938)
at execMain.c:1439
#3 0x00000000005b5835 in standard_ExecutorRun
(queryDesc=0xc62820,
direction=ForwardScanDirection, count=0) at execMain.c:313
#4 0x00000000005b5729 in ExecutorRun (queryDesc=0xc62820,
direction=ForwardScanDirection, count=0) at execMain.c:261
#5 0x00000000006d2f79 in PortalRunSelect (portal=0xc60810,
forward=1 '\001', count=0, dest=0xcf9938) at pquery.c:943
#6 0x00000000006d2c4e in PortalRun (portal=0xc60810,
count=9223372036854775807, isTopLevel=1 '\001',
dest=0xcf9938,
altdest=0xcf9938, completionTag=0x7fffa4b0eeb0
"") at pquery.c:787
#7 0x00000000006cd135 in exec_simple_query
(query_string=0xcf8420 "select 1;")
at postgres.c:1018
#8 0x00000000006d1144 in PostgresMain (argc=2,
argv=0xc42da0,
username=0xc42c40 "t-ishii") at postgres.c:3926
#9 0x0000000000683ced in BackendRun (port=0xc65600)
at postmaster.c:3600
#10 0x00000000006833dc in BackendStartup (port=0xc65600)
at postmaster.c:3285
#11 0x0000000000680759 in ServerLoop () at postmaster.c:1454
#12 0x000000000067ff4d in PostmasterMain (argc=3,
argv=0xc40e00)
at postmaster.c:1115
#13 0x00000000005f7a39 in main (argc=3, argv=0xc40e00)
at main.c:199
(gdb) |
ЫЕУївЛЯТПДЕФЗНЗЈЃЌЗЂЦ№ЕїгУЕФКЏЪ§дкЯТУцЃЌБЛЕїгУЕФКЏЪ§дкЩЯУцЁЃвВОЭЪЧExecProcNodeЕїгУСЫExecResultЃЌExecutePlanЕїгУСЫExecProcNodeЃЌExecutorRunЕїгУСЫExecProcNodeЃЌетбљЕФаЮЪНРДаДЁЃЬиБ№ЪЧжаМфЕФЕк7ааЁЃ
#7 0x00000000006cd135
in exec_simple_query
(query_string=0xcf8420 "select 1;")
at postgres.c:1018 |
етбљПЩвдЧхГўПДЕНдкДІРэSELECTЮФЁЃ:)заЯИПДgdbЕФЪфГіЃЌПЩвдЗЂЯжетаЉЯИНкЁЃ
gdbЪЧдДТыЕїЪдЦїЃЌЫљвдПЩвдПДЕНКЭдДДњТыЕФЖдгІЙиЯЕЁЃР§ШчlistУќСюПЩвдПДЕНЯждкжДааЕФааИННќЕФДњТыЁЃ
(gdb) list
70 TupleTableSlot *resultSlot;
71 PlanState *outerPlan;
72 ExprContext *econtext;
73 ExprDoneCond isDone;
74
75 econtext = node->ps.ps_ExprContext;
76
77 /*
78 * check constant qualifications like (2 >
1), if not already done
79 */ |
РћгУupУќСюПЩвдЭљЩЯУцЕФКЏЪ§вЦЖЏЁЃЯТУцгУlistУќСюЃЌПЩвдШЗШЯЪЕМЪЕїгУExecSelect ЕФЕиЗНЁЃ
(gdb) up
#1 0x00000000005b92a4 in ExecProcNode (node=0xd13eb0)
at execProcnode.c:367
367 result = ExecResult((ResultState *) node);
(gdb) list
362 {
363 /*
364 * control nodes
365 */
366 case T_ResultState:
367 result = ExecResult((ResultState *) node);
368 break;
369
370 case T_ModifyTableState:
371 result = ExecModifyTable((ModifyTableState
*) node); |
РћгУdownПЩвдЭљЯТУцЕФКЏЪ§вЦЖЏЁЃРћгУupКЭdownЕФзщКЯЃЌПЩвдЕїВщКЏЪ§ЕФЕїгУЙиЯЕЁЃ
вЊЭЫГіgdbЕФЛАПЩвдгУquitЁЃ
ЕНСЫетРяgdbОЭНсЪјСЫЃЌЕЋЪЧКѓЖЫНјГЬВЂВЛЛсжежЙЁЃ
ЪЙгУtagРДЬјзЊЕНЯргІЕФКЏЪ§ЖЈвхЮФМў
ЮвУЧвбОЪЙгУСЫgdbРДЕїВщpostgreSQLЕФдЫааЃЌСэЭтгУgdbЕФlistРДзЗзйдДТыЕФЛАЛЙЪЧЯрЕБаСПрЕФЃЌвЛАуРДЫЕгУemacsЕШБрМЦївЛЦ№ЕїВщКЭфЏРРДњТыЃЌПЩвддкБпЕїЪдБпВщПДДњТыЁЃ
ЕБШЛЃЌдкgdbФЃЪНЯТвВПЩвдЪЙгУЁЃетИіЪБКђЃЌР§ШчШчЙћЯыПДПД'exec_simple_query'ЕФЖЈвхЕФЛАЃЌЪЙгУemacsЕФtagsУќСюПЩвдСЂПЬЬјзЊЕНКЏЪ§ЖЈвхЕФЕиЗНЁЃвЊЪЙгУtagsЕФЛАЃЌашвЊЩњВњtagsЮФМўЃЌPostgreSQLЕФЛАЃЌДјгаЩњВњtagsЮФМўЕФНХБОЁЃ
$ cd /usr/local/src/postgresql-9.1.1/src
$ tools/make_etags (ЪЙгУemacsЕФГЁКЯ)
$ tools/make_tags (ЪЙгУviЕФГЁКЯ) |
етбљОЭПЩвдРЁЃ ШЛКѓдкemacsжаЃЌдкexec_simple_query ДІжДаа'ESC-.'(АДСЫESCМќКѓЪфШыЖККХ.)ЃЌМДПЩДђПЊЙтБъЫљдкЮФзжЫљдкЕФexec_simple_queryКЏЪ§ЕФЖЈвхЮФМўЁЃ
змНс
вЊЭъШЋРэНтPostgreSQLЕФЛАЃЌЭЈЙ§ЕїВщдДДњТыЛЙЪЧБШНЯгааЇЙћЕФЁЃвЊРэНтДњТыЕФЛАЃЌПЩвдАДееФПЕФздМКзЗМгБивЊЕФЙІФмЃЌИФБфвЛаЉЙІФмЕФааЮЊЃЌДѓМвПЩвдзюДѓЯоЖШЕФЕФЯэЪмПЊдДДјРДЕФКУДІЁЃ | 








